基于OSM的地表覆盖变化数据提取
2017-10-21李志盛周晓光任常青
李志盛,周晓光, 任常青
(1.中南大学 地球科学与信息物理学院,湖南 长沙 410083;2.国家测绘地理信息局 第一航测遥感院,陕西 西安 710054)
0 引 言
我国于2014年完成了全球陆表30 m分辨率的遥感制图产品的研制,现在迫切需要解决其持续更新问题。目前,获取地表覆盖增量信息的主要途径包括:①从遥感影像中获取;②整合利用网络化公开数据。利用遥感影像数据获取地表覆盖增量信息存在工作量大等问题[1-4],而网络化公开数据存在更新速度快、数据丰富、获取便利等优点,是获取地表覆盖变化信息的理想数据源。近年来,VGI发展迅速。其中OSM、Wikimapia等项目收集了丰富的空间数据。由于OSM提供免费的全球矢量数据,且其数据丰富[5-8],因此,本文选取OSM数据作为获取地表覆盖增量信息的数据源。
OSM数据包括26种基本类型,全球地表覆盖数据包括10种基本类型,OSM数据不能直接获得各类地表覆盖数据,因此需要对OSM数据进行类型转换才能得到。这就需要建立一套从OSM数据到地表覆盖数据的类型转换规则,并通过此规则从OSM数据中提取出10类地表覆盖数据。OSM部分数据存在多层重叠拓扑错误,此类数据在后期更新过程中会导致同一位置的数据被多次进行更新操作,增大数据处理工作量;由于数据过于碎片化,直接使用也会大大增加处理的工作量。鉴于以上原因,类型转换后的数据还需进一步聚类综合才能得到适合用于更新的地表覆盖数据。
1 总体思路
根据上文分析,首先利用OSM网站中提供的Primary features建立类型转换规则,根据规则从OSM数据提取出每个类别的地表覆盖数据;然后基于要素聚类提取聚集范围并栅格化获得地表覆盖数据;最后与GlobeLand30数据进行栅格运算得到地表覆盖增量数据。详细流程如图1所示。

图1 利用OSM数据提取地表覆盖增量信息的整体思路图Fig.1 The general idea of incremental data extraction for land cover data using OSM data
2 地表覆盖增量数据提取方法
从OSM数据中提取地表覆盖增量数据包括OSM到地表覆盖数据的类型转换、转换目标聚集范围提取和增量信息提取3个步骤。
2.1 类型转换
类型转换是将OSM数据的26类转换为10类地表覆盖数据,其主要通过建立映射规则来实现。地表覆盖类型选择的是国家基础地理信息中心发布的10个类型,分别是:耕地、森林、草地、灌木地、湿地、水体、苔原、人造地表、裸地、冰川和永久积雪。然而OSM数据没有采用传统的专题分层管理,只是通过tag标签中的key_value值描述地物属性[6]。根据tag标签中的key_value可以确定数据对应地表覆盖的类型。OSM数据中心提供了基本数据特征描述(Primary features),包含key_value值和对应的文字与图片描述。收集Primary features中所有的key_value值并确定所对应的地表覆盖类型,得到类型转换的规则。建立的部分规则实例见表1,表1中key、value值分别对应OSM数据中tag标签内的key、value值,target¬layer则表示key,value值对应的地表覆盖类型。

表1 OSM数据到地表覆盖数据类型转换规则实例Tab.1 Instance of type conversion rules for OSM data to land cover data
OSM原始数据入库后得到点(point)、线(polyline)、面(polygon)3个表。根据收集的规则从point、polyline 、polygon3个表提取出地表覆盖各个类型的数据,并存入相应的表中。类型转换规则如下:
If data.tag.key = rule.key && data.tag.value = rule.value then data ∈rule.targetlayer
式中,data表示入库后的数据,rule则表示表1规则中的1条规则。
具体处理流程如下:
1) 读取规则表中第i种地表覆盖类型对应的key、value值存入数组。
2) 遍历数组获得每一对key、value值,根据从point、polyline 、polygon3个总表中提取key、value字段与其相同的数据存入第i种地表覆盖类型对应的点、线、面表中,并在point、polyline 、polygon表中对此部分数据进行标记。
3) 返回第1)步获取下一种地表覆盖类型对应的转换规则,直到所有地表覆盖类型的数据都被提取完。
2.2 聚集范围提取
类型转换后得到的地表覆盖面数据仍存在碎片化、多层重叠等现象,用其直接提取地表覆盖增量数据会导致效率低、后期处理难度大等问题,因此,需要对该数据进行聚类处理。常见的空间聚类主要有以下几类:基于层次的方法[9-12]、基于格网的方法[13-14]、基于划分的方法[15-16]、基于密度的方法[17-23]和基于四叉树的方法[24-25]。其中,基于四叉树的方法和基于格网的方法相比其他几类聚类方法具有处理速度快的优点,同时此类方法的效率与数据量的关系不大,主要受空间划分单元个数的影响,聚类结果以单元格表示容易合并得到聚集范围[13-14,24-25]。因为基于四叉树的方法相比基于格网的方法效率更高[24-25],本文选择前者作为OSM数据聚集范围提取的方法。
1)聚类要素的四叉树剖分
设给定的聚类区域A有n个元素,记为F={f1,f2, f3…,fn}。首先将区域A平均分为4个单元格z0、z1、z2、z3,每个单元格都与F中元素进行相交计算,对与F元素相交的单元格继续剖分,并将剖分得到的单元格继续做相交计算。以此类推,直到单元格的边长小于期望的阈值。此时与F中元素相交的单元格存入集合G中。图2为剖分次数为1、3、5时的结果图。

图2 聚类要素的四叉树剖分Fig.2 Quadtree partition of clustering elements
2)单元格合并
四叉树剖分后,还需对最小划分的所有单元格进行合并得到目标多边形,其中最小单元格在集合G中的存储索引如图3所示。

图3 集合G存储索引Fig.3 Storage index of set G
为了提高效率,单元格合并分两步进行:第一步将相邻的单元格进行粗略合并,第二步将第一步合并得到的多边形进行精确合并。
第一步的合并流程如下:
1)设集合G中有m个单元格,记为G={g1,g2,g3…,gm},读取集合G中第i(i从0开始)个未被标记的单元格gi,首先将gi标记为merged,然后令多边形p等于gi。
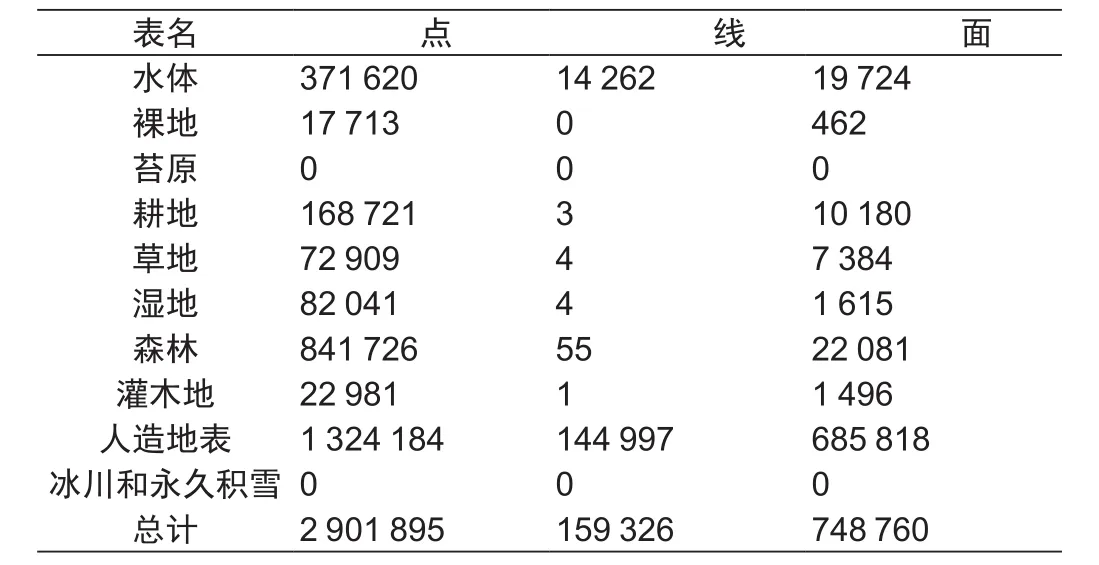
2) 读取存储在其后的单元格gj(i 3) 直到遍历完存储在gi后的所有单元格gi+1,gi+2…,gm,将最后合并的多边形存储在集合D中。 4) 重复步骤1),2)和3),直到i=m停止。 第一步能将大部分相邻的单元格进行合并,合并的结果会有一些相邻的多边形未合并的情况出现。如图4(b)所示,但是由于每次得到一个最终多边形只需要遍历一次存储在首个单元格gi之后的所有单元格,较大地提高了合并的效率。 第二步的合并和第一步很相似,不同之处在于每次两个多边形合并后继续遍历所有未标记的多边形,而不只是遍历存储在其后的多边形,以保证所有满足条件的多边形都能进行合并得到一个最终多边形,由于此时集合D中多边形的个数远远少于之前集合G单元格的个数,所以判断或者合并的工作量已经大大减少。合并的结果如图4(c)所示。 图4 单元格合并结果Fig.4 Cell merge result 单元格合并后可得到每个类型的地表覆盖矢量数据,分别栅格化后得到对应类型的栅格数据。将所有栅格数据进行叠加处理,重叠区域选择最大值,从而得到OSM地表覆盖数据。由于OSM数据的不完整性会导致部分区域无数据,如图5中的黑色区域,因此在与GlobeLand30数据做叠加运算之前,需先将GlobeLand30数据对应OSM地表覆盖数据中无数据区域的值设置为零。然后将两张栅格图像做差的栅格运算得到两张图像的不同区域,最后提取OSM地表覆盖数据中同一区域的数据得到增量数据。 图5 OSM地表覆盖数据Fig.5 OSM land cover data 为验证本文方法的可行性,以OSM网站于2016年7月23日发布的爱沙尼亚区域的数据做验证。数据入库后,利用收集的规则进行类型转换,统计结果见表2。 表2 爱沙尼亚OSM地表覆盖数据分类统计Tab.2 Classification statistics of OSM land cover data in Estonia 由表2可知,在OSM地表覆盖数据中,人造地表类型数据最多,同时耕地、森林、水体地表覆盖类型也拥有较多的数据,不同类型数据量差别较大。 图6 OSM地表覆盖、GlobeLand30和谷歌影像对比Fig.6 Comparison of OSM land cover data, GlobeLand30 and Google image 选取爱沙尼亚部分区域的转换后数据进行聚类、栅格化等处理得到的地表覆盖分类数据如图6(a)所示,通过与2010年的GlobeLand30数据做叠加运算得到地表覆盖增量数据如图6(d)所示,其中,黑色代表无数据的区域。截取图6(a)、(b)、(c)、(d)中的黄色矩形区域放大得到图7(a)、(b)、(c)、(d),其中,图7(b)GlobeLand30数据与谷歌影像进行对比可以发现GlobeLand30错把人造地表和草地分类到了耕地,而本文方法提取的地表覆盖数据更符合真实现状。继而可以得出结论基于OSM数据提取地表覆盖增量信息具有一定的可行性。 图7 OSM地表覆盖、GlobeLand30和谷歌影像局部对比Fig.7 Local comparison of OSM land cover data,GlobeLand30 and Google image 为了满足全球地表覆盖数据不断更新的需求,本文提出了一种基于OSM的地表覆盖增量数据提取方法。建立了一套OSM数据到地表覆盖数据的类型转换规则,然后针对类型转换后数据存在的目标零散等问题,采用聚类方法对转换数据进行聚集整合;继而对整合后的数据栅格化并与GlobeLand30数据进行叠加运算得到地表覆盖增量数据。最后使用爱沙尼亚区域的OSM数据,验证了本文方法的可行性。利用本文方法提取的地表覆盖增量数据具有现势性强、类别丰富和获取成本低等优点。在以下方面还需进一步研究:①OSM数据分布不均匀,要获得更加完整的增量数据,还需结合其他VGI数据一起处理;②OSM数据质量参差不齐,要排除质量较差的数据,还需计算出数据的信誉度作为过滤的依据[26-27]。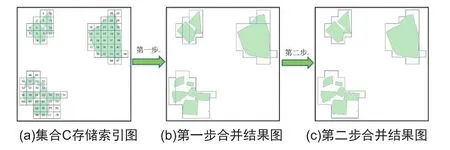
2.3 增量信息提取

3 实 验


4 结束语
