用于隐马尔可夫模型语音带宽扩展的激励分段扩展方法
2017-10-21郭雷勇林胜义谭洪舟
郭雷勇,李 宇,林胜义,谭洪舟
(1.广东药科大学 医药信息工程学院,广州 510006; 2.中山大学 电子与信息工程学院,广州 510006)
(*通信作者电子邮箱guoleiyong@gdpu.edu.cn)
用于隐马尔可夫模型语音带宽扩展的激励分段扩展方法
郭雷勇1*,李 宇1,林胜义1,谭洪舟2
(1.广东药科大学 医药信息工程学院,广州 510006; 2.中山大学 电子与信息工程学院,广州 510006)
(*通信作者电子邮箱guoleiyong@gdpu.edu.cn)
语音带宽扩展通过人为恢复窄带语音的频谱带宽来提高语音听觉质量。针对源滤波器扩展模型的激励扩展问题,提出一种分段扩展方法。该方法在扩展带的低频段与高频段部分分别采用窄带激励源的高频部分与帧能量等效的白噪声作为激励信号,最后两者与原窄带激励组成宽带激励信号。基于隐马尔可夫模型(HMM)谱包络估计的宽带语音重构实验结果表明:该方法降低了重建语音的失真度,恢复重建的语音信号优于谱平移激励扩展方法。
语音带宽扩展;分段扩展;谱平移;激励信号;隐马尔可夫模型
0 引言
过去由于技术条件限制,传统窄带电话网络的语音信号都以8 kHz采样成数字信号进行处理与编码传输,其对应的编码标准有ITU(International Telecommunication Union)的G.729与GSM(Global System for Mobile Communication)等窄带语音编码标准。人类语音的主要信息都集中在频率为 0.1~3.4 kHz的范围内。窄带语音在保留大部分语音特性的前提下节省了带宽开销,适合长途电话通信,但也牺牲了一些处于高频部分的语音成份,如辅音等。然而语音信号在0.3~7.5 kHz频谱范围所包含的信息使声音听起来更加饱满与自然,这对通话的可理解性与舒适性有着重要的影响。长时间地使用窄带语音通话会令人产生听觉疲劳,但0.3~3.4 kHz范围的窄带电话网络带宽限制了语音通话质量的提高[1]。随着通信技术的发展,宽带语音通信已经实现商业应用,但原有的窄带通信系统在很长一段时间会继续使用,出现两种通信系统长期并存的状态。在窄带与宽带系统中进行语音通信,通过窄带语音的带宽扩展技术使得宽带系统的终端能够回放比窄带语音具有更丰富频谱成分的宽带语音,能增加通信业务的附加值。
一般来讲,窄带语音带宽扩展依据人体发音的信号与系统模型(线性源滤波器模型)作为扩展思路,利用分析-扩展-合成的框架实现。先把窄带语音通过线性预测分拆为激励信号与包络信号,并分别对它们进行扩展,再将扩展后的激励与包络信号合成为宽带语音。
依据是否带边信息,窄带语音带宽扩展可以分为盲与非盲两类方法。盲扩展方法仅传送窄带信号,并依据宽带信号的先验特征统计信息进行匹配,选择信号的备选扩展素材进行带宽扩展;非盲扩展方法则必须对语音进行宽带的16 kHz采样,并抽取3.4~7.5 kHz高频部分中有代表性的特征作为边信息,窄带信号与边信息同时传送到带宽终端并被用于带宽扩展。边信息包含宽带语音高频段的关键特征,这使得非盲方法有较好的扩展性能。
盲扩展方法依据语音信号的分析-合成策略,先把窄带语音通过线性预测分拆为激励信号与包络信号,并分别对它们进行扩展,再将扩展后的激励信号与包络信号合成为宽带语音,如文献[2-3]分别利用训练好的高斯混合模型(Gaussian Mixture Model, GMM)与隐马尔可夫模型(Hidden Markov Model, HMM)估计宽带语音包络。文献[4]通过选择与扩展带谱包络互信息大的窄带语音特征来估计宽带谱包络。深度学习神经网络分别被文献[5-6]用于映射窄带语音特征与宽带语音特征的关系。文献[7-8]利用Boltzmann机分别取代GMM来表示窄宽两带的频谱包络统计分布,进一步结合循环神经网络约束的Boltzmann机[8]可更充分利用语音帧间相关性来提高性能。这类基于深度学习的扩展方法以极高的复杂度代价来获得性能的提高。
文献[9]指出窄带与高频带之间的互信息与高频带的感知熵的比率,表明仅依靠窄带语音包络特征来提高扩展语音的质量是非常有限的。引入高频带部分的特征信息较好地补充了盲扩展方法的局限。带有边信息的非盲扩展方法除了对窄带语音作分析、扩展与合成外,对实时高频部分信号提取有效特征作为嵌入边信息,有效地提高了扩展质量。文献[10]对宽带语音的高频谱有音信息编码,然后嵌入到窄带频谱中低于听觉感知掩蔽曲线以下的区域中。该方法在不破坏窄带语音质量前提下传输边信息,避免了对其额外传输,可以兼容于现有窄带通信网络。标量科斯塔方案(Scalar Costa Scheme, SCS)是一种具有信息隐藏的数据通信模型,并且是其中一种次优的科斯塔方案[11]。依据该模型,文献[12]提出基于SCS模型的带宽扩展方法,该方法结合听觉掩蔽阈值与信道噪声估计来选择被嵌的子带。
谱平移或谱折叠[1]是激励信号常用的扩展方法,它把原窄带信号简单地“搬移/复制”到高频带区域,并没有考虑高频带区域的激励信号特点。文献[13]依据谐波主要集中在低频段0~2 kHz,提出了一种中频激励方法,其只选取窄带语音的2~4 kHz带宽内的激励信号进行扩展,避免了强谐波进入扩展带。
为了更精确地重建扩展带的激励信号,本文提出一种激励分段扩展方法。该方法的依据是语音的激励信号在有音区多为基频整数倍频率的正弦波,而在辅音区则近似白噪声。此外,通常情况下语音的辅音出现在能量较高的高频部分,次高频则是混合区域,因此所提出的激励分段扩展更加符合语音的频谱分布特点。
1 基于HMM的最小均分误差语音带宽扩展
基于HMM的贝叶斯最小均分误差(Minimum Mean-Square Error, MMSE)语音带宽扩展方法系统框图如图1所示。该方法分两条扩展支线,即图1上半部分进行谱包络扩展与宽带线性预测系数重构,下半部分实现激励信号扩展。 最终扩展后的激励信号输入到线性预测系数构成的合成滤波器得到重构宽带语音。
1.1 宽带语音线性预测系数重构
宽带语音的线性预测系数用于构成宽带语音的合成滤波器。其重构过程表示为:组合估计的扩展带谱包络与原窄带谱包络,组合后的谱包络通过逆傅立叶变换转为自相关函数,然后通过列文森-杜宾(Levison-Dubin)算法转换为线性预测系数。具体流程如图2所示。

图1 基于HMM的贝叶斯MMSE语音带宽扩展系统框图Fig. 1 Diagram of HMM based Bayesian MMSE voice bandwidth expansion system
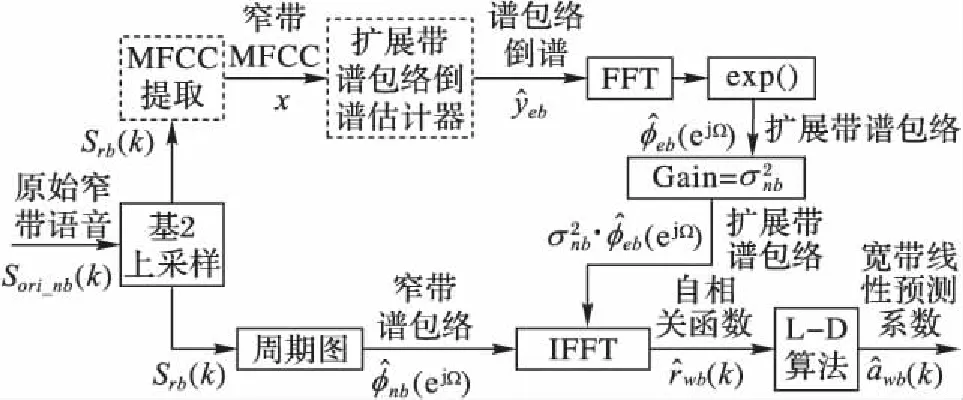
图2 宽带语音谱包络倒谱估计与合成滤波器线性预测系数估计框图Fig. 2 Diagram of wideband speech spectrum envelope cepstrum estimation and synthetic filter linear prediction coefficient estimation
1.2 扩展带包络估计
由于扩展带语音谱包络的估计谱包络的对数与倒谱之间是一对傅立叶变换对,因此扩展带语音谱包络的估计可先估计其对应的倒谱,然后对其倒谱作傅立叶变换与指数运算得到。倒谱用对数运算,这使得倒谱的MMSE估计器符合听觉感知特性。图2中扩展带谱包络倒谱估计器采用基于HMM的贝叶斯MMSE准则对当前语音帧输入窄带语音的Mel频率倒谱系数(Mel Frequency Cepstrum Coefficient, MFCC)特征进行估计,得到对应的扩展带谱包络倒谱系数向量,如图3所示。

图3 扩展带谱包络倒谱估计结构框图Fig. 3 Diagram of extended spectral envelope cepstrum estimation
图3中估计前先要训练HMM的各种参数,包括状态转移概率、观察概率以及隐含发射概率的状态类质心的确定。有很多文献陈述HMM参数集训练,这里不再赘述。


(1)
其中Rd为d维倒谱空间,p(y|X)可以通过HMM的Ns个状态{S1,S2,…,SNs}表示为:
(2)
依据联合概率公式有:
p(y,Si|X)=p(y|Si,x)P(Si|X)
(3)
式(2)、(3)代入式(1)可得到:
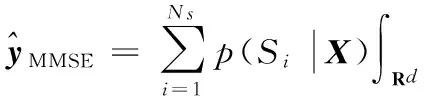
(4)
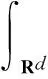
(5)
其中p(Si|X)可以依据训练好的HMM参数集合计算,具体参考文献[3]。
1.3 激励信号的谱平移扩展
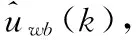
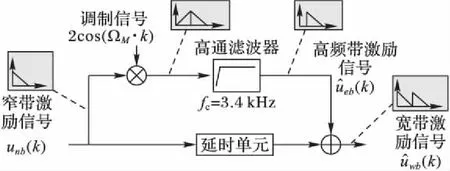
图4 基于谱平移的激励扩展信号框图Fig. 4 Diagram of excitation propagation signal based on spectrum shift
谱平移激励信号所合成的宽带语音有类似于金属摩擦的人造音,听起来缺乏自然度,重建的宽带语音的高频段能量高于原语音信号[14]。从图6中的语谱示意图可以看出,产生上述问题归根结底在于谱平移方法所产生的宽带激励信号中高频带激励信号是窄带激励信号复制,导致窄带与高频带之间的谐波结构没有对齐而使整个发音的完整性遭到破坏,加上高频带能量没有加以调整,因此使得人造的激励信号成分能量过大以致于合成的语音信号中产生人耳可闻的金属声。
2 激励分段扩展

(6)
其中:Nk为一帧内窄带激励信号的采样点数,μ为窄带激励信号的均值。整个激励方法流程如图5所示,其中所有高通滤波器都使用有限长单位脉冲响应(Finite Impulse Response, FIR)线性相位滤波器,具有相同的阶数49,则群延时为24,也就是滤波器产生的延时。
整个激励分段扩展算法如下:
1)由图1中的“分析滤波器”得到窄带激励信号unb(k)。
2)同时处理下面3个支路信号:
上支路:
①uwb1(k)=unb(k-24)。
中间支路:
①unbtemp1(k)=unb(k)·2cos(ΩM·k);
②uwb2(k)=unbtemp1(k)⊗Fhigh1(k)。
下支路:
①用式(6)求得σunb;
②uwbtemp1(k)=σunb·gnoise(k);
③uwb3(k)=uwbtemp2(k)⊗Fhigh2(k)。
3)合并输出:
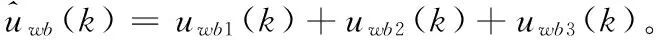
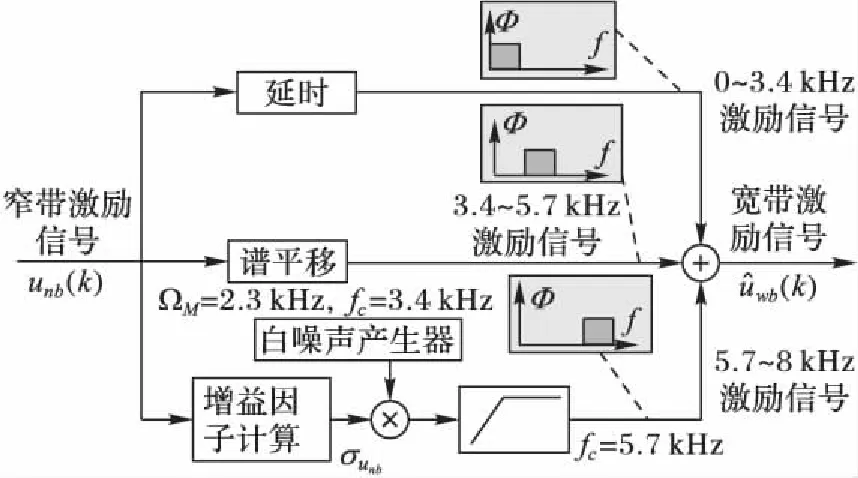
图5 激励分段扩展的信号原理图Fig. 5 Schematic diagram of excitation piecewise extension signal
3 实验设计和结果
3.1 实验条件
本文采用的实验平台为Matlab 2014。采用的语音库为CMU的ARCTIC数据库[15],选取其中100句的英文短句作为训练语音样本,选取另外10句不包含在训练样本中的英文短句作为测试语音样本。扩展系统实现中,取MFCC作为特征矢量,其提取采用Mel滤波器组个数为15,即窄带语音的语音特征为15维的MFCC。高频带谱包络倒谱CC设定为8维矢量,因此HMM模型的状态数为8。训练采用LBG(Linde-Buzo-Gray)算法,码书大小为500。基2上采样后的窄带语音一帧为400采样点,频带扩展后的宽带语音每帧也为400采样点。
3.2 实验结果与分析
3.2.1 语谱图分析
实验采用HMM-MMSE谱包络扩展下得到的合成滤波器系数,激励信号扩展分别采用本文的分段扩展与谱平移扩展。各自得到的宽带激励信号输入宽带合成滤波器得到重构的宽带语音。以语音库中一句英语短句作为处理语料,结果如图6所示。图左上角椭圆区域属于6.5~7.5 kHz的高频部分。原宽带语音存在一些不规则成分。激励分段扩展方法所恢复的能量要比谱平移方法更加接近于原信号,特别是圈右侧图中的那个竖条频谱。中频3.5~5 kHz部分的椭圆区域,两种方法实际上都是谱平移,但所平移的部分不同。此区域分布着一些带谐波的频谱以及一些能量低的辅音或者无音部分。谱平移方法在恢复谐波区域的同时,提高了辅音或者无音区域的能量。本文方法更加接近原宽带语音的语谱分布。
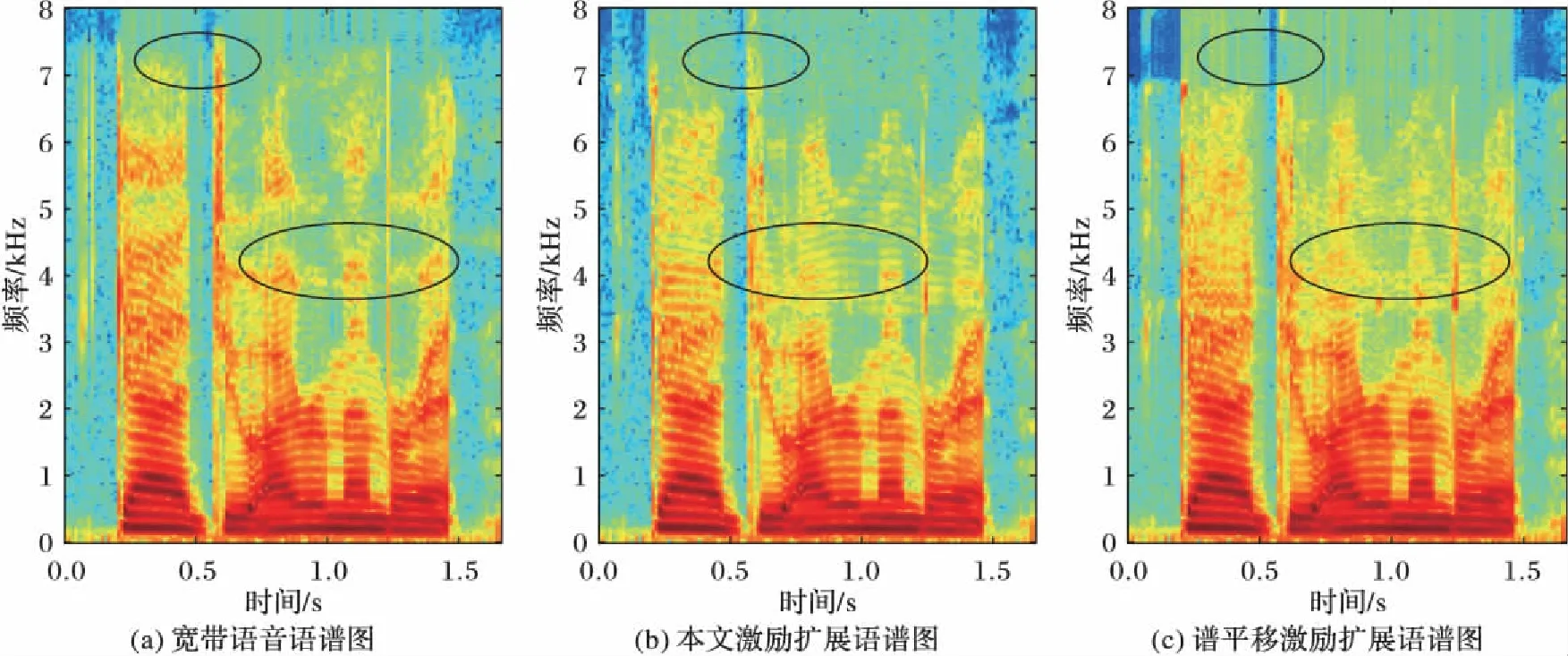
图6 原宽带语音与两种激励扩展方法得到的宽带语谱图Fig. 6 Wideband speech spectrum obtained from original wideband speech and two excitation extension methods
3.2.2 失真评测
实验采用对数谱失真(Log-Spectral Distortion, LSD)、语音质量感知评估(Perceptual Evaluation Of Speech Quality, PESQ)与倒谱距离(Cepstrum Distance, CD)分别对提出的分段激励扩展方法进行评测。谱包络扩展采用HMM-MMSE方法。对数谱失真LSD通过计算合成宽带语音与原宽带语音之间的对数频谱差异值来反映待测语音的失真度大小。计算所得LSD值越小,则反映出待测语音的失真度越小,表明扩展合成语音出现人造杂音的现象越少。LSD可以定义[16]为:
LSD=
(7)
其中:CX(k,l)max{|X(k,l)|,ε},|X(k,l)|为原宽带语音的短时幅度谱,|(k,l)|为待测语音的短时幅度谱,L为帧数,l和k分别为帧索引和频谱索引。
PESQ是国际电信联盟提出的一种通过客观评价方法来模拟主观评价的一种打分方法[15],取值范围在0.5~4.5,语音质量越好其分值越大。PESQ评测需要参考语音,参考语音的最高得分为4.5,被测语音值都会低于4.5。依据文献[17]中PESQ的计算方法计算10条扩展合成语音的平均PESQ值。
倒谱距离CD是计算语音与合成语音间倒谱差的一种语音测度。平均CD定义[18]为:
(8)
其中:ck为倒谱系数,D为倒谱的阶数。
三种指标的评测结果如表1所示。由表1可知所提出的激励分段扩展会稍微降低失真的客观评价指标LSD与CD,并且略微提高表示主观评价的PESQ,因为语音带宽扩展的质量主要由包络扩展好坏决定。相对而言,激励扩展影响语音扩展的质量较弱。

表1 原宽带语音与频带扩展语音的CDM测度平均值Tab. 1 Average CDM measure of the original wideband speech and the band extended speech
4 结语
在源滤波器语音带宽扩展方案中,激励信号扩展是其中一个重要问题。本文在现有谱平移扩展基础上提出对激励信号进行分段扩展,并基于HMM源滤波器带宽扩展方法进行了带宽扩展实验。客观测试及语谱图实验结果表明,相比传统的谱平移扩展方法,所提出的激励分段扩展可提高重建语音的质量。目前语音通信系统的窄带传输网络(如2G无线、PSTN)仍在使用,而支持16 kHz采样的通话终端已经普及。通过终端的语带宽扩展方法来提高通话质量,是一种低成本减轻窄带传输所造成的话音质量下降的有效方法。
References)
[1] JAX P, VARY P. Bandwidth extension of speech signals: a catalyst for the introduction of wideband speech coding? [J]. IEEE Communications Magazine, 2006, 44(5): 106-111.
[2] PARK K-Y, KIM H S. Narrowband to wideband conversion of speech using GMM based transformation [C]// ICASSP ’00: Proceedings of the 2000 IEEE International Conference on Acoustics, Speech, and Signal Processing. Washington, DC: IEEE Computer Society, 2000, 3:1843-1846.
[3] JAX P, VARY P. On artificial bandwidth extension of telephone speech [J]. Signal Processing, 2003, 83(8): 1707-1719.
[4] 张勇,胡瑞敏.基于高斯混合模型的语音带宽扩展算法的研究[J].声学学报,2009,34(5):471-480. (ZHANG Y, HU R M. Research on speech bandwidth extension algorithm based on Gauss mixture model [J]. Journal of Acoustics, 2009, 34(5): 471-480.)
[5] WANG Y, ZHAO S, LIU W, et al. Speech bandwidth expansion based on deep neural networks [C]// InterSpeech-2015: Proceedings of the 16th Annual Conference of the International Speech Communication Association. [S.l.]: ISCA, 2015: 2593-2597.
[6] LI K, LEE C-H. A deep neural network approach to speech bandwidth expansion [C]// Proceedings of the 2015 IEEE International Conference on Acoustics, Speech and Signal Processing. Piscataway, NJ: IEEE, 2015: 4395-4399.
[7] WANG Y, ZHAO S, LI J, et al. Speech bandwidth extension using recurrent temporal restricted Boltzmann machines [J]. IEEE Signal Processing Letters, 2016, 23(12): 1877-1881.
[8] 王迎雪, 赵胜辉, 于莹莹,等. 基于受限玻尔兹曼机的语音带宽扩展[J].电子与信息学报,2016,38(7):1717-1723. (WANG Y X, ZHAO S H, YU Y Y, et al. Speech bandwidth extension based on restricted Boltzmann machine [J]. Journal of Ectronic and Information, 2016, 38 (7): 1717-1723)
[9] NILSSON M, GUSTAFTSON H, ANDERSEN S V, et al. Gaussian mixture model based mutual information estimation between frequency bands in speech [C]// ICASSP ’02: Proceedings of the 2002 IEEE International Conference on Acoustics, Speech, and Signal Processing. Washington, DC: IEEE Computer Society, 2002, 1: 525-528.
[10] DING H. Wideband audio over narrowband low-resolution media [C]// ICASSP ’04: Proceedings of the 2004 IEEE International Conference on Acoustics, Speech, and Signal Processing. Washington, DC: IEEE Computer Society, 2004, 1: 489-492.
[11] EGGERS J J, BAUML R, TZSCHOPPE R, et al. Scalar Costa scheme for information embedding [J]. IEEE Transactions on Signal Processing, 2003, 51(4): 1003-1019.
[12] SAGI A, MALAH D. Bandwidth extension of telephone speech ai-ded by data embedding [J]. EURASIP Journal on Advances in Sig-
nal Processing, 2007, 2007(1): 064921.
[13] 张勇,刘轶.窄带语音带宽扩展算法研究[J].声学学报,2014,39(6):764-773. (ZHANG Y, LIU Y. Research on narrowband speech bandwidth extension algorithm [J]. Acta Acustica, 2014, 39(6): 764-773.)
[14] LIU X, BAO C-C. Audio bandwidth extension based on temporal smoothing cepstral coefficients [J]. EURASIP Journal on Audio, Speech, and Music Processing, 2014, 2014: 41.
[15] KOMINEK J, BLACK A W. The CMU Arctic speech databases [C]// SSW5-2004: Proceedings of the Fifth ISCA ITRW on Speech Synthesis. [S.l.]: ISCA, 2004: 223-224.
[16] COHEN I, BENESTY J, GANNOT S. Speech Processing in Modern Communication: Challenges and Perspectives [M]. Berlin: Springer-Verlag, 2010: 32.
[17] International Telecommunication Union. ITU-T Recommendation P.862, Perceptual Evaluation of Speech Quality (PESQ), an objective method for end-to-end speech quality assessment of narrowband telephone networks and speech codecs [S]. Geneva, Switzerland: International Telecommunication Union, 2001.
[18] KITAWAKI N, NAGABUCHI H, ITOH K. Objective quality evaluation for low-bit-rate speech coding systems [J]. IEEE Journal on Selected Areas in Communications, 1988, 6(2): 242-248.
This work is partially supported by the National Natural Science Foundation of China (61473322,81570904).
GUOLeiyong, born in 1973, Ph. D, lecturer. His research interests include voice bandwidth expansion, Internet of things perception.
LIYu, born in 1973, Ph. D, associate professor. His research interests include speech signal processing, interleaved sampling system distortion correction.
LINShengyi, born in 1990, M. S., engineer. His research interests include speech signal bandwidth expansion and coding.
TANHongzhou, born in 1965, Ph. D., professor. His research interests include communication signals and systems, integrated circuit design.
ExcitationpiecewiseexpansionmethodforspeechbandwidthexpansionbasedonhiddenMarkovmodel
GUO Leiyong1*, LI Yu1, LIN Shengyi1, TAN Hongzhou2
(1.CollegeofMedicalInformationEngineering,GuangdongPharmaceuticalUniversity,GuangzhouGuangdong510006,China;2.SchoolofElectronicsandInformationTechnology,SunYat-SenUniversity,GuangzhouGuangdong510006,China)
Speech bandwidth expansion is used to enhance the auditory quality by artificially recovering the lost components in the high-band spectrum of narrow-band speech. Aiming at the problem of excitation expansion in speech source-filter extension model, a piecewise extension method was proposed. The higher spectrum part in the narrow-band excitation source and the white noise with the equivalent narrow-band excitation frame energy were used as the excitation sources for the lower and upper part of the extension band respectively. At last, the wideband excitation signal was composed of the above two and the original narrow band one. Experimental results of the wide band speech reconstruction with Hidden Markov Model (HMM) based spectrum envelope estimation show that the proposed method is superior to spectrum shift excitation expansion method.
speech bandwidth extension; piecewise extension; spectrum shift; excitation signal; Hidden Markov Model (HMM)
TN912.3
A
2017- 02- 28;
2017- 04- 13。
国家自然科学基金资助项目 (61473322,81570904)。
郭雷勇(1973—),男,湖南郴州人,讲师,博士,主要研究方向:语音带宽扩展、物联网感知; 李宇(1977—),男,广东增城人,副教授,博士,主要研究方向:语音信号处理、交织采样系统失真修正; 林胜义(1990—),男,广东汕头人,工程师,硕士,研究方向:语音信号带宽扩展与编码; 谭洪舟(1965—),男,重庆人,教授,博士生导师,博士,研究方向:通信信号与系统、集成电路设计。
1001- 9081(2017)08- 2416- 05
10.11772/j.issn.1001- 9081.2017.08.2416
