基于异构星型网络分析的药物推荐改进算法HIC-MedRank
2017-10-21邹林霖李学明
邹林霖,李学明,2,李 雪,袁 洪,刘 星
(1.重庆大学 计算机学院,重庆 400044; 2.重庆大学 信息物理社会可信服务计算教育部重点实验室,重庆 400044;3.昆士兰大学 信息技术与电子工程学院,澳大利亚 布里斯班 4072; 4.中南大学 湘雅三医院心内科,长沙 410013)
(*通信作者电子邮箱lixuemin@cqu.edu.cn)
基于异构星型网络分析的药物推荐改进算法HIC-MedRank
邹林霖1,李学明1,2*,李 雪3,袁 洪4,刘 星4
(1.重庆大学 计算机学院,重庆 400044; 2.重庆大学 信息物理社会可信服务计算教育部重点实验室,重庆 400044;3.昆士兰大学 信息技术与电子工程学院,澳大利亚 布里斯班 4072; 4.中南大学 湘雅三医院心内科,长沙 410013)
(*通信作者电子邮箱lixuemin@cqu.edu.cn)
伴随着医疗文献数据库的快速增长,缺乏经验的初级医师在为患者开处方时难以阅读大量的医疗文献来获得科学的决策辅助。2013年提出的MedRank算法从Medline数据库中提取医学信息异构星型网络,基于“有疗效的药物是由好的文章提及的,好的文章是由优秀的作者写的并刊登在高水平的期刊上”的假设,旨在为各类疾病的患者推荐最具有疗效的药物。该算法仍然存在几个问题:1)模型输入的疾病不是独立的疾病;2)推荐的结果不是具体的药物;3)没有考虑文章的发表时间等其他因素;4)没有定义判定作者、期刊、文章是“好的”的标准。对以上问题进行了研究并提出HIC-MedRank算法,该算法纳入作者的H指数、期刊的影响因子、文章的引用数作为评判作者、期刊、文章是否优秀的指标,并综合考虑文章的发表时间、支持机构、发表类型等因素,为高血压合并慢性肾脏病(CKD)患者推荐最佳的降压药物。在Medline数据集上的实验结果显示HIC-MedRank推荐的药物比MedRank算法推荐的药物更为精准,与主治医师投票选择的药物较为一致,与美国成人高血压治疗指南(JNC)推荐的药物一致性达到80%。
异构信息网络;数据挖掘;临床决策支持;H指数;高血压;慢性肾脏病;药物推荐
0 引言
通过医学论坛丁香园的调研[1],4 858名中国医师中有55.9%的人在不知道如何作诊断决策时会选择查阅文献。可是伴随着医学文献数据库的快速增长,医师难以阅读大量的文献来获得与时俱进的医学知识,于是从医学文献数据库中挖掘出有用的医学知识就显得十分重要。
文献[2-3]从文献数据中挖掘知识以减少医疗错误;文献[4]使用临床决策支持系统、医疗误差等关键词从Medline数据库中获得知识以预防药物的不良反应;还有一些研究如文献[5-7]从数据库中挖掘疾病相关的药物推荐给临床医师,以辅助他们进行临床决策。在文献[7]中,Chen等通过分析异构信息网络提出了一种新的药物推荐算法——MedRank算法。
MedRank算法可以从Medline数据库中抽取出与疾病相关的文章、作者、期刊、临床试验及治疗方法这5个对象构成医学异构信息网络,通过分析该网络为给定疾病推荐排名前十的治疗方法。在实验中,该算法分别为艾滋病、2型糖尿病等5种疾病推荐出排名前十的治疗方法并与医生的调研结果进行比较,结果显示MedRank算法推荐的治疗方法得到医生的普遍认可。
然而,从更深入的医学和技术角度分析,MedRank算法仍然存在许多不足:第一,给定的疾病不是独立的疾病,患者的用药与所患疾病的合并症以及个人状态有关,所以输入的疾病应是经过细化之后的疾病名称。比如糖尿病可以根据病人患病的程度、年龄、是否肥胖等因素划分为多类别的糖尿病(1型糖尿病、2型糖尿病、妊娠糖尿病等),所以在为糖尿病患者推荐用药时,需输入具体的疾病:1型糖尿病或2型糖尿病,而不是笼统地输入“糖尿病”。第二,算法推荐的结果不是特定的药物,比如2型糖尿病的推荐用药,排在第一位的是“降糖药”,可是“降糖药”是其他推荐药物的总称。第三,既然要获得与时俱进的医学知识,较近年份的文章提及的药物应当给予更多重视,所以文章的发表时间应该纳入模型;此外文章的发表类型和研究类型决定着一篇文章的质量,也应该被考虑,因为在医学领域中“指元分析(Meta-analysis)”以及“随机对照试验(Randomized Controlled Trial, RCT)”类型的文章比其他类型的文章更得到医学界的认可,同样医学界对研究类型为“多中心研究(Multicenter Study)”“单盲研究(Single-Blind Method)”“双盲研究(Double-Blind Method)”等类型的文章也较为认可。第四,MedRank算法基于以下假设:一个好的治疗药物易于被好的医学文章提及且在临床试验阶段成功应用,而这篇好的文章则是由一些优秀的作者撰写并刊登在高水平的期刊上。可是文章中并没有给出如何判定文章是好的、作者是优秀的、期刊是高水平的标准。
因此,本文引入文章的引用数目、作者的H指数、期刊的影响因子来评估作者、文章、期刊的好坏。假设:
1)一篇文章是好的,如果它被其他文章高引用;
2)一个期刊是高水平的,如果它有很高的影响因子;
3)一个作者是优秀的,如果他/她的h篇文章被至少引用了h次;
4)一个治疗药物是有效的,如果它被许多好的文章提及,而这些文章出自优秀的作者之手并被刊登在高水平的期刊上。
同时还考虑了文章的发表时间、发表类型、研究类型,提出一个改进的药物推荐算法——HIC-MedRank(H-index, Impact factor, and Citation count-MedRank)。在实验中,选择高血压合并慢性肾脏病(Chronic Kidney Disease, CKD)为模型的输入(因为该疾病是一种影响全球几亿人健康的常见疾病[8]),各种类型的降压药物作为输出。最后,将排名前十的药物与医师调研的结果以及美国成人高血压治疗指南(The report of the Joint National Committee on Prevention, Detection, Evaluation, and Treatment of High Blood Pressure, JNC)进行比较,结果显示HIC-MedRank 算法推荐的药物比MedRank算法推荐的药物更精准,与指南一致性达到80%。
1 问题定义
以下将给出问题的定义并介绍相关的概念和符号。

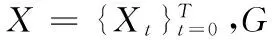
在现实生活中,许多网络都可以表示为星型网络,比如书目信息网络或者在线电影信息网络。如图1所示,“文章”对象是该星型网络的中心对象,“疾病”“作者”“期刊”“发表类型”“药物”就是属性对象,属性对象都与中心对象有关联。本文也将构建图中所示的网络模型作为医疗异构星型信息网络。
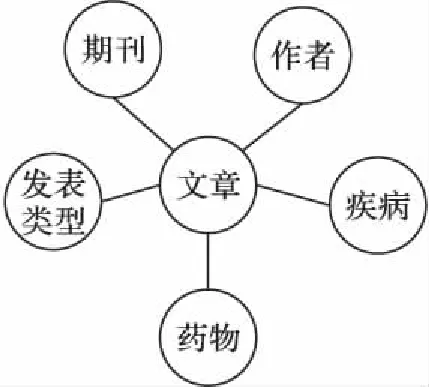
图1 星型网络模型Fig. 1 Star network model
定义3 疾病子网络。给定一个医疗星型信息网络G=〈V,E,W〉以及一种疾病d∈Xd,其中Xd∈V是“疾病”类型对象的集合。定义疾病子网络G′=〈V′,E′,W′〉⊆G使得V′=V-V″,其中:V″∈{x∈X0|∃/y([x,y]∈E∧y=d)},E′={[x,y]∈E|x,y∈V′},W′={wx,y∈W|[x,y]∈E′}。
因为本文的目标是为给定的疾病d将文献库中的药物进行排名,于是从文献库中提取跟d相关的文章构成集合V′。现在,将问题描述如下:
给定疾病子网络G′=[V′,E′,W′],如果有一个“药物”类型的对象集合Xs⊂V、一个排名函数R以及整数K,存在X′⊂Xs,|X′|=K使得∀x∈X′,∀y∈(Xs-X′),都有R(x)>R(y)。
2 HIC-MedRank算法
本文根据疾病从医学文献数据中提取相关的文章以及其他属性对象,构建医疗异构星型网络,网络的权重值将由作者H指数、期刊影响因子、文章引用数目以及文章发表时间等其他因素共同计算。在计算各对象排名时,类似于PageRank算法,一个类型的对象具有较高的排名值,如果它的邻居对象也具有较高的排名值。一个药物的排名值越大,那么其必由一些好的文章提及,这些文章是由优秀的作者写的并被刊登在高水平的期刊上。选择高血压合并慢性肾脏病作为模型输入,降压药作为模型输出,将HIC-MedRank算法分为“提取网络”“设置权重”“计算排名”三部分进行介绍。
2.1 提取网络
本节将介绍如何通过医学本体MeSH(Medical Subject Headings)词表从Medline数据库中提取医疗异构星型网络。
MeSH词表是一部医学词典,包含57 299个描述符,为当前医学信息提供规范化的说明。Medline是一个由NLM(National Library of Medicine)发布的医学文献数据库,它包含了许多文章的书目信息。每一篇文章的书目信息包含了文章的记录号(PubMed Unique IDentifier, PMID)、文章名、作者列表、期刊信息、发表类型以及MeSH词表标注的关键信息。该数据库可以以XML文件格式下载,湘雅三医院于2015年6月获得对数据库的访问权限。
扫描所有XML文件,当文章的书目信息中包含疾病对应的MeSH关键字时,将文章的PMID、作者、期刊、发表类型、研究类型、发表时间以及药物名称提取出来。本文方法只考虑8类主要的降压药物:血管紧张素转化酶抑制剂(Angiotension Converting Enzyme Inhibitors, ACEI)、血管紧张素受体阻滞剂(Angiotensin Receptor Blocker, ARB)、钙通道阻滞剂(Calcium Channel Blockers, CCB)、利尿剂、β受体阻滞剂、α受体阻滞剂、血管扩张剂、神经节阻滞药,而且只有当文章中提及的这些药物被MeSH词标注为“治疗用途(therapeutic use)”“药物治疗(drug therapy)”或者是“投药&剂量(administration & dosage)”,才能提取文章PMID,并将PMID与药物建立连接。而且为了保障文章的质量,本文只将文章发表类型为“指元分析(meta-analysis)” “随机对照试验(randomized controlled trial)” “实用性临床试验(pragmatic clinical trial)” “双生子研究(twin study)”“临床对照试验(controlled clinical trial)” “观察研究(observational study)” “对比研究(comparative study)”以及 “病例报告(case report)”这8种类型的文章提取到网络中。
对于Medline数据库中的每一篇文章,只有当它的发表类型、药物满足以上要求时,才能在“文章”“发表类型”或“降压药物”之间建立连接。
2.2 设置权重
本节将阐述如何获得与引入作者的H指数、期刊的影响因子、文章的引用数作为判断“文章是好的,作者是优秀的,期刊是高水平的”的标准,并讨论如何给医疗信息网络设置权重。
自1989年以来,引用数便作为衡量科学研究贡献的指标广泛使用[9],于是用其来评估一篇文章是否是好的文章。期刊的影响因子则在1955年就被Garfield博士[10]提出,在20世纪60年代被用来作为筛选期刊的工具,一个高水平的期刊必定有较高的影响因子。而作者的H指数于2005年才被Hirsch[11]提出,用来评估科研人员的研究水平。作者H指数的计算主要依靠两个部分:作者文章的发表数和其他科研人员对作者文章的引用数,其被定义为“一个研究人员的H指数为h,如果这个作者有h篇文章被至少引用了h次”[12]。本文假设一个好的作者其H指数也高。
上述三个指标可从许多数据库获得,比如Google Scholar、 Scopus、 Web of Science等。本文选择Web of Science爬取期刊的引用数和作者的H指数,期刊的影响因子则从期刊引用报告(Journal Citation Reports, JCR)获得。根据2.1节中提取的期刊ISSN号、文章名、作者姓名以及期刊名称从Web of Science网站和JCR中获得作者H指数、期刊影响因子、文章引用数,然后用最大最小规范化的方法将三种指标进行规范化加入到医疗信息网络中作为网络的权重。现在,医疗信息网络可以描述如下:
1)医疗信息网络:G=〈V,E,W〉;
2)对于医疗信息网络中的节点集合V,它包含5种类型的节点:“文章”类型的节点记为A,“期刊”类型的节点记为J,“作者”类型的节点记为S,“文章发表类型”的节点记为P,“药物”类型的节点记为O。假设每种类型节点的个数分别为|A|,|J|,|S|,|P|,|O|。V是所有类型节点的集合:V=A∪J∪S∪P∪O。
3)对于医疗信息网络中的边E和权重W:在网络中,每篇文章对应着许多作者,发表在一个期刊上,提及一种或多种药物,而对于不同的文章,它的连接是不一样的。假设有两种不同类型的节点xi、xj,它们之间有一条边e:〈xi,xj〉∈E。wxixj表示边e的权重,定义如下:
在上述定义中:p和q分别表示经过归一化处理后的期刊影响因子和作者H指数;k表示经过归一化处理之后的文章引用数;当发表类型P满足“Meta-analysis”或者“RCT”中的一种时,文章对象与其对应的发表类型之间的权重为1,其他时候为0。
另外,本文考虑了文章的发表时间以及研究类型,当文章的研究类型为“美国研究院(U.S. based institutes)”“前瞻性研究(prospective studies)”“随机分配(random allocation)”“多中心研究(multicenter study)”“双盲研究(double-blind method)”“单盲研究(single-blind method)”中的一种时,wAI=1,其他情况wAI=0。假设发表时间越近的文章,权重越大,符合指数增长。用t表示文章的发表年份,T表示当前年份,a表示增长率,则文章发表时间的权重则为wAT=ea(t-T)(e为自然常数)。如果t=T,则wAT=0。
最后,整个医疗信息网络的权重为Wxixj=wxixj+k+(wAI+wAT)/10,其中xi(xj)∈A,xj(xi)∈J∪S∪P∪O。
2.3 计算排名
在设置权重之后,仍然采用RankClus算法[13]和NetClus算法[14]中权威排名的计算公式计算各对象的排名值:
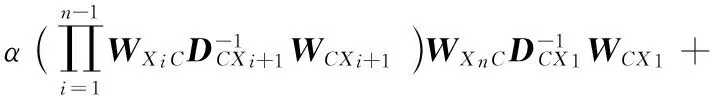
(1-α)U/|X1|
(1)
(2)
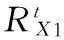
经过上述三部分的工作,可以得到各对象排名的情况,在药物对象的排名向量中选取排名前十的药物作为推荐药物。最后,HIC-MedRank算法可总结为如下所示:
输入d表示给定疾病;K表示排名个数;ξ表示收敛的阈值;
输出F表示前K的药物排名列表。
1)
根据给定疾病d,结合本体Mesh从医学文献数据库中提取医学信息异构星型网络G=〈V,E,W〉;
2)
从Web of Science网站上获得三种指标,归一化之后更新网络的权重矩阵
3)
将排名值Rx1初始化为1/|X1|
4)
while(difference<ξ或l>预设迭代次数)
Do
利用式(1)和式(2)计算l+1次迭代时X1的排名值;

l←l+1
5)
选取排名列表前K个药物作为推荐列表P←top-K(Rx1,K)
在该算法中,提取网络的时间复杂度取决于扫描Medline数据库构建网络的时间,假设Medline数据库中有N条记录,则提取网络的时间复杂度为O(N)。设置权重阶段需要从网页上爬取数据,爬取数据代码的时间复杂度为O(1);设置权重阶段的时间复杂度主要由作者、期刊、文章这三个对象的节点数决定,假设三个对象的节点数分别为|A|、|J|、|S|,那么设置权重阶段的时间复杂度为O(|A|)+O(|J|)+O(|S|)。在排名计算阶段,每一次迭代中每条边的权重都会计算两次,那么每一次迭代的时间复杂度为O(E),假设迭代l次,计算的开销则为O(l|E|)。最后算法总的时间复杂度为O(N)+O(|A|)+
O(|J|)+O(|S|)+O(l|E|)。
3 算法实验
本文从NLM官网(http://www.nlm.nih.gov/bsd/licensee/ access/medline_pubmed.html)获得Medline数据库的XML格式文件,并选择高血压合并慢性肾脏病(CKD)作为选定的疾病,因为高血压作为全球范围内最常见的慢性疾病,也是我国发病率高的疾病之一,据国家心血管病中心发布的报告[15]显示我国高血压患者至少有2亿。慢性肾脏病作为高血压主要的并发症之一,两者相互影响,导致人群患病率及致死率逐年增高。于是在实验中我们根据“人类(Human)”“高血压(Hypertension)”“ 慢性肾衰竭(Kidney Failure, Chronic和Kidney Insufficiency, Chronic)” 等关键字将与高血压合并慢性肾脏病相关的文章PMID、作者、期刊、发表类型、研究类型、发表时间以及药物名称提取出来,构成疾病子网络。表1显示了这个疾病子网络各类型对象的数目。

表1 CKD星型网络各对象的数目Tab. 1 Size of objects in CKD star network
接着,根据作者的姓名、期刊的ISSN号、文章名称和期刊名从Web of Science 上利用爬虫程序得到作者的H指数、期刊的影响因子和文章的引用数,待标准化之后更新网络权重。最后将算法中的参数设置为ξ=0.000 1,K=10并运行,最终得到高血压合并慢性肾脏病排名前十的药物如表2所示。作为比较,表2中也列出了MedRank算法得到的前十名推荐药物。
从表2可以看出,MedRank算法推荐的第一名是“Antihypertensive Agents(降压药)”,这个名词是后面推荐药物的总称,于医疗人员没有参考价值,而HIC-MedRank算法推荐的方案是具体的降压药物名称。之后,对HIC-MedRank算法推荐的前十名药物相关的支持文章数目、文章的发表年份以及三个指标的平均值进行了统计分析,统计结果如表3所示。
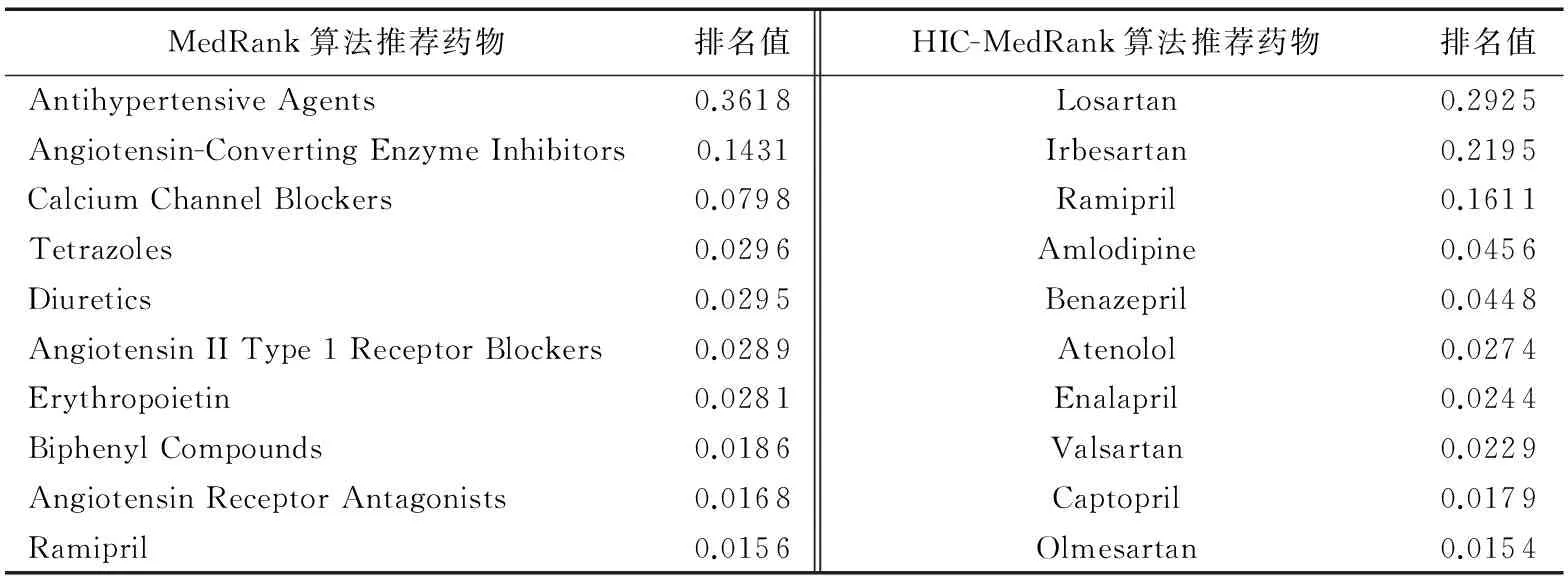
表2 MedRank和HIC-MedRank算法为高血压合并慢性肾脏病推荐的前十名降压药物Tab. 2 Top 10 influential medications for Hypertension with CKD recommended by MedRank and HIC-MedRank
表3中显示了与每一种药物相关的三种指标的平均值,从表中可以看出排名前十的药物它们对应的文章具有较高的引用率或者期刊的平均影响因子较高或者作者的平均H指数较高。在本文算法中,文章的引用数目影响较大,所以在结果中拥有最高平均文章引用数248.35的“Losartan”排名第一,而第二名“Irbesartan”的平均文章引用数仅为143.65。可见实验结果符合本文假设:一个治疗药物是有效的,如果它被许多好的文章提及,而这些文章出自优秀的作者之手并被刊登在高水平的期刊上。
图2展示了支持前十名药物的文章近十几年来发表的数目,图中有3个峰值:“Captopril”是第一个研究热点,研究时间从1979年至1993年;“Irbesartan”是第二个研究热点,研究时间从1997年至2008年;第三个是从2010年至今进行研究的“Olmesartan”。而在实际生活中,“Captopril”和“Irbesartan”的确是治疗高血压时使用广泛的药物[16],而“Olmesartan”会不会成为接下来流行使用的药物尚未可知,还待进一步研究。
与第一名药物Losartan关联的文章、作者、期刊以及发表类型如图3所示,其中空心圆节点代表作者,三角形节点代表文章,菱形节点代表期刊,实心圆节点代表药物,正方形节点代表发表类型。

表3 HIC-MedRank算法推荐的前十名药物相关的支持文章数、文章发表年份以及三个指标的平均值Tab. 3 Supporting articles’ count, publishing year and average of three indicators of top 10 recommended medications by HIC-MedRank algorithm
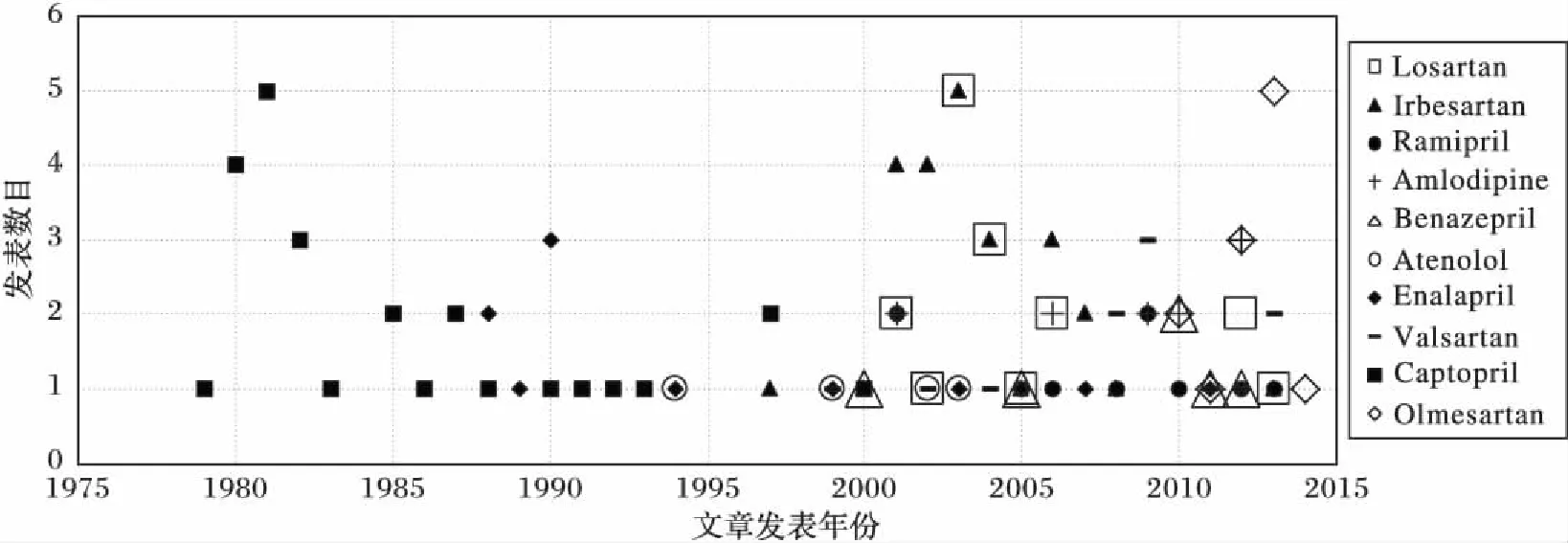
图2 前十名药物支持文章的发表年份和发表数目关系图Fig. 2 Relation between publication year and paper count per year of top 10 medications

图3 与Losartan药物相关的医疗信息网络Fig. 3 Medical information network of Losartan
4 结果评估
本章将对HIC-MedRank算法推荐的前十个降压药物进行评估,采用的方法是:1)与医生的调研结果进行比较;2)与美国成人高血压治疗指南进行比较。
4.1 HIC-MedRank算法vs. 医生排名
4.1.1 医生排名
为了评估算法结果,本文特定在全国范围内面向医生群体作了一次调研。调研问卷包含22个单项选择题和多个多项选择,内容涵盖:1)医生的基本信息(所处地区、医院等级、科室、职位、年龄、性别等);2)治疗高血压合并慢性肾脏病患者时倾向使用的降压药。
调研时间历时1个月,共收到中国大陆地区28个省反馈的375份有效问卷。回答问卷的医师有76.92%来自三级医院,32.5%的医师是主任或副主任级别,24.5%的是主治医师,剩余的是住院医师或医学研究生。本文将医师按照岗位级别划分为三类,每一类医师按照年龄进行高低排序并选择其中的前90名,统计他们第一倾向使用的药物,结果如表4所示。

表4 三个级别的医师的投票结果Tab. 4 Voting results of three level physicians
4.1.2 一致性测量
HIC-MedRank算法的推荐结果需要与医师的投票结果进行一致性比较,本文采用交叉度量 (intersection metric或AO)[17]的方式进行测量。
使用τ(i)(1≤i≤k)表示大小为k的列表中前i个值,根据文献[14]中的定义,两个列表之间的不一致性由以下两个公式计算:

(3)
(4)
最后,列表的一致性为:
AO(τ1,τ2)=1-δ(w)(τ1,τ2)
(5)
其中:⊕表示对称差,X⊕Y=(XY)∪(YX);τ1,τ2是两个排序列表。AO的取值范围为[0,1],0表示两个列表不一致,1表示两个列表完全一致。
将算法排名与各级别医师的投票结果使用上述公式进行两两一致性比较,结果如表5所示。
由于医生的投票具有很强的主观性,不同的医生治疗疾病使用的药物不尽相同,所以HIC-MedRank推荐的药物与医师的投票结果一致性在期望值以下。此外,本次调研范围只是在中国大陆,中国医生的反馈结果并不能代表全世界医生的意愿。所以接下来,本文将算法的推荐结果与更具权威的JNC指南进行比较。
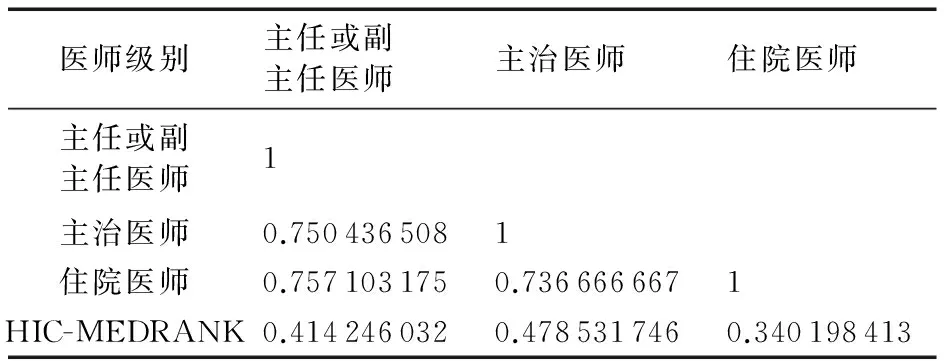
表5 HIC-MedRank算法结果与三个级别医师投票结果的一致性计算Tab. 5 AO score among system rankings and physicians’ rankings
4.2 HIC-MedRank算法vs. JNC
JNC指南是由美国预防、检测、评估与治疗高血压全国联合委员会发布的报告。在JNC第7次报告中,ACEI类和ARB类药物作为高血压合并肾脏病的推荐使用药物,这两类药物主要包含:Benazepril、Captopril、Enalapril, Fosinopril、Lisinopril、Moexipril、Quinapril、Perindopril、Ramipril、Trandolapril、Candesartan、Eprosartan、Irbesartan、Losartan、Olmesartan、Telmisartan、Valsartan等17种药物。将HIC-MedRank推荐的药物与指南比较,结果如表6所示,只有Amlodipine与Atenolol不在指南推荐药物之内。
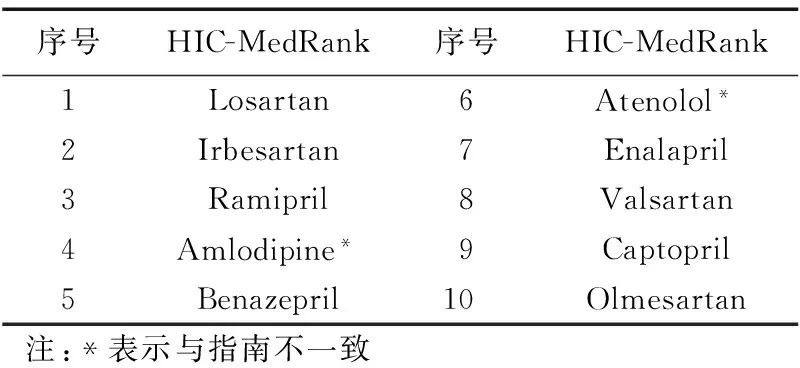
表6 算法推荐用药与JNC指南比较Tab. 6 Concordance evaluation compared with JNC7
5 结语
本文提出了一个改进的基于医学信息网络分析的药物推荐算法HIC-MedRank,不仅在MedRank算法上考虑了文章的发表时间、发表类型、研究类型等属性,还使用作者H指数、期刊影响因子、文章的引用数作为判断作者、期刊、文章是否优秀的指标。假设一篇文章是好的,如果它被其他文章引用频率很高;一个期刊是高水平的,如果该期刊有很高的影响因子;一个作者是优秀的,如果他/她的h篇文章被至少引用了h次;那么一个治疗药物是有效的,如果它被许多好的文章提及,而这些文章出自优秀的作者之手并被刊登在高水平的期刊上。最终HIC-MedRank推荐的用药比MedRank算法更精准,更易辅助医生进行临床决策,且推荐药物与JNC指南也较为一致。
然而,本文还存在许多不足之处。不少研究人员认为H指数并不能作为判断作者学术水平能力的指标,如果一个作者只写过1篇文章,即使这篇文章被引用了上千次,该作者的H指数也只能是1。所以有研究者于2006年提出评价作者科研能力的新指标——G指数,可以弥补H指数不能很好反映高被引用论文的缺陷[18]。此外本文研究还存在另外一个问题,在提取网络时,假定文章中提及到的药物是文章认为有效的药物,可是在实际生活中,文中提到的药物也许是无效药物,所以还需要从摘要或文章中进行文本、语义分析判断文中提到的药物是否是文章认为有效的药物,这个问题还待进一步研究与解决。
References)
[1] 丁香园调查派. 医疗决策支持:文献经久不衰[EB/OL]. [2016- 01- 25]. http://vote.dxy.cn/report/dxy/id/67390. (www.dxy.cn. Clinical decision support:literatures last a long time [EB/OL]. [2016- 01- 25]. http://vote.dxy.cn/report/dxy/id/67390.)
[2] AGHAZADEH S, ALIYEV A Q, EBRAHIMNEJAD M. The role of computerizing physician orders entry (CPOE) and implementing decision support system (CDSS) for decreasing medical errors [C]// AICT 2011: Proceedings of the 2011 5th International Conference on Application of Information and Communication Technologies. Piscataway, NJ: IEEE, 2011: 1-3.
[3] ELDER N C, DOVEY S M. Classification of medical errors and preventable adverse events in primary care: a synthesis of the literature [J]. Journal of Family Practice, 2002, 51(11): 927-932.
[4] BOM H S, PARK S H, CHOI J W, et al. Effects of clinical decision support system on reduction of adverse drug events: a meta-analysis [J]. Journal of Korean Society of Medical Informatics, 2002, 8(3): 55-60.
[5] REICHRATH J, BENS G, BONOWITZ A, et al. Treatment recommendations for pyoderma gangrenosum: an evidence-based review of the literature based on more than 350 patients [J]. Journal of the American Academy of Dermatology, 2005, 53(2): 273-283.
[6] AGARWAL P, SEARLS D B. Literature mining in support of drug discovery [J]. Briefings in Bioinformatics, 2008, 9(6): 479-492.
[7] CHEN L, LI X, HAN J. MedRank: discovering influential medical treatments from literature by information network analysis [C]// ADC 2013: Proceedings of the Twenty-Fourth Australasian Database Conference. Darlinghurst, Australia: Australian Computer Society, 2013: 3-12.
[8] LANCET T. Chronic kidney disease: refining diagnosis and management [J]. The Lancet, 2014, 384(9941): 378.
[9] LINDSEY D. Using citation counts as a measure of quality in science measuring what’s measurable rather than what’s valid [J]. Scientometrics, 1989, 15(3/4): 189-203.
[10] GARFIELD E. Journal impact factor: a brief review [J]. Canadian Medical Association Journal, 1999, 161(8): 979-980.
[11] HIRSCH J E. An index to quantify an individual’s scientific research output [J]. Proceedings of the National Academy of Sciences of the United States of America, 2005, 102(46): 16569-16572.
[12] BALL P. Index aims for fair ranking of scientists [J]. Nature, 2005, 436(7053): 900.
[13] SUN Y, HAN J, ZHAO P, et al. RankClus: integrating clustering with ranking for heterogeneous information network analysis [C]// EDBT 2009: Proceedings of the 12th International Conference on Extending Database Technology: Advances in Database Technology. New York: ACM, 2009: 565-576.
[14] SUN Y, YU Y, HAN J. Ranking-based clustering of heterogeneous information networks with star network schema [C]// KDD 2009: Proceedings of the 15th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining. New York: ACM, 2009: 797-806.
[15] 陈伟伟,高润霖,刘力生,等.中国心血管病报告2013概要[J].中国循环杂志,2014(7):487-491. (CHEN W W, GAO R L, LIU L S, et al. Outline of 2013 China cardiovascular disease report [J]. Chinese Circulation Journal, 2014(7): 487-491.)
[16] HUSAIN A, AZIM M S, MITRA M, et al. A review of pharmacological and pharmaceutical profile of Irbesartan [J]. Pharmacophore, 2011, 2(6): 276-86.
[17] FAGIN R, KUMAR R, SIVAKUMAR D. Comparing topklists [J]. SIAM Journal on Discrete Mathematics, 2003, 17(1): 134-160.
[18] EGGHE L. Theory and practice of theG-index [J]. Scientometrics, 2006, 69(1): 131-152.
This work is partially supported by the National High Technology Research and Development Program (863 Program) of China (2015AA015308), the National Science Foundation of China (81273594), the National Science and Technology Major Project (2012ZX09303014001).
ZOULinlin, born in 1990, M. S. candidate. Her research interests include machine learning, data mining.
LIXueming, born in 1967, Ph. D., professor. His research interests include data mining, big data, high performance computing.
LIXue, born in 1956, Ph. D., professor. His research interests include data mining, social computing, intelligent information systems.
YUANHong, born in 1957, Ph. D., chief physician, professor. His research interests include individualized treatment of hypertension, clinical cardiovascular pharmacology.
LIUXing, born in 1989, Ph. D. candidate, physician. Her research interests include big data of hypertension.
HIC-MedRankimproveddrugrecommendationalgorithmbasedonheterogeneousinformationnetwork
ZOU Linlin1, LI Xueming1,2*, LI Xue3, YUAN Hong4, LIU Xing4
(1.CollegeofComputerScience,ChongqingUniversity,Chongqing400044,China;KeyLaboratoryofDependableServiceComputinginCyberPhysicalSociety,MinistryofEducation,ChongqingUniversity,Chongqing400044,China;3.SchoolofInformationTechnologyandElectricalEngineering,UniversityofQueensland,Brisbane4072,Australia;4.DepartmentofCardiology,theThirdXiangyaHospital,CentralSouthUniversity,ChangshaHunan410013,China)
With the rapid growth of medical literature, it is difficult for physicians to maintain up-to-date knowledge by reading biomedical literatures. An algorithm named MedRank can be used to recommend influential medications from literature by analyzing information network, based on the assumption that “a good treatment is likely to be found in a good medical article published in a good journal, written by good author(s)”, recomending the most effective drugs for all types of disease patients. But the algorithm still has several problems: 1) the diseases, as the inputs, are not independent; 2) the outputs are not specific drugs; 3) some other factors such as the publication time of the article are not considered; 4) there is no definition of “good” for the articles, journals and authors. An improved algorithm named HIC-MedRank was proposed by introducing H-index of authors, impact factor of journals and citation count of articles as criterion for defining good authors, journals and articles, and recommended antihypertensive agents for the patients suffered from Hypertension with Chronic Kidney Disease (CKD) by considering published time, support institutions, publishing type and some other factors of articles. The experimental results on Medline datasets show that the recommendation drugs of HIC-MedRank algorithm are more precise than those of MedRank, and are more recognized by attending physicians. The consistency rate is up to 80% by comparing with the JNC guidelines.
heterogeneous information network; data mining; clinical decision support; H-index; hypertension; Chronic Kidney Disease (CKD); drug recommendation
TP391.4; TP181
A
2017- 02- 10;
2017- 03- 15。
国家863计划项目(2015AA015308);国家自然科学基金资助项目(81273594);国家科技重大专项(2012ZX09303014001)。
邹林霖(1990—),女,四川内江人,硕士研究生,主要研究方向:机器学习、数据挖掘; 李学明(1967—),男,重庆人,教授,博士,主要研究方向:数据挖掘、大数据、高性能计算; 李雪(1956—),男,重庆人,教授,博士,主要研究方向:数据挖掘、社会计算、智能信息系统;袁洪(1957—),男,湖南长沙人,主任医师,教授,博士,主要研究方向:高血压个体化治疗、临床心血管药理; 刘星(1989—),女,湖南长沙人,医师,博士研究生,主要研究方向:高血压大数据。
1001- 9081(2017)08- 2368- 06
10.11772/j.issn.1001- 9081.2017.08.2368
