基于改进信息增益的人体动作识别视觉词典建立
2017-10-21吴峰,王颖
吴 峰,王 颖
(北京化工大学 信息科学与技术学院,北京 100029)
(*通信作者电子邮箱wangying@mail.buct.edu.cn)
基于改进信息增益的人体动作识别视觉词典建立
吴 峰,王 颖*
(北京化工大学 信息科学与技术学院,北京 100029)
(*通信作者电子邮箱wangying@mail.buct.edu.cn)
针对词袋(BoW)模型方法基于信息增益的视觉词典建立方法未考虑词频对动作识别的影响,为提高动作识别准确率,提出了基于改进信息增益建立视觉词典的方法。首先,基于3D Harris提取人体动作视频时空兴趣点并利用K均值聚类建立初始视觉词典;然后引入类内词频集中度和类间词频分散度改进信息增益,计算初始词典中词汇的改进信息增益,选择改进信息增益大的视觉词汇建立新的视觉词典;最后基于支持向量机(SVM)采用改进信息增益建立的视觉词典进行人体动作识别。采用KTH和Weizmann人体动作数据库进行实验验证。相比传统信息增益,两个数据库利用改进信息增益建立的视觉词典动作识别准确率分别提高了1.67%和3.45%。实验结果表明,提出的基于改进信息增益的视觉词典建立方法能够选择动作识别能力强的视觉词汇,提高动作识别准确率。
人体动作识别;词袋模型;信息增益;词频
0 引言
人体动作识别作为计算机视觉的一个重要研究方向,广泛应用于智能监控、人机交互、虚拟现实等领域[1]。词袋(Bag-of-Words, BoW)模型与局部特征相结合的人体动作识别方法[2-3]将人体动作局部特征表征为文本中的词汇,不同比例词汇的组合对应不同的动作。基于词袋模型的动作识别过程如图1所示:首先提取人体动作局部特征,将局部特征聚类映射为不同的视觉词汇;所有视觉词汇构成视觉词典;将视觉词汇在视频图像中出现的概率分布作为描述人体动作的特征向量输入分类器进行动作识别。该方法将大量局部特征映射为视觉词汇,降低了用于动作识别的特征维数,具有良好的抗噪性,近年来受到广泛关注。视觉词典将描述人体动作的局部特征表示成低维向量,其大小及识别能力会影响动作识别的准确率。视觉词典过小,表征不同动作信息的特征被聚类成同一视觉词汇导致视觉词典的识别力差;视觉词典过大,视频图像中的噪声易被误聚类为表征动作的视觉词汇导致视觉词典对噪声敏感。Lazebnik等[4]采用传统聚类方法通过统计不同聚类数目建立的视觉典的动作识别结果确定视觉词典大小。该方法需要大量的实验,且传统聚类方法仅基于特征向量的表观相似性建立视觉词典,导致视觉词典中一些词汇动作识别能力较弱。为提高视觉词典中视觉词汇的动作识别能力,Liu等[5]提出了基于最大互信息的聚类方法,通过融合传统聚类中心得到互信息最大的视觉词汇,但存在融合准则确定困难及计算复杂度高等问题。
与基于聚类法建立视觉词典不同,一些学者应用文本分类中信息熵、互信息、期望交叉熵、信息增益等特征选择方法[6-8]评价视觉词汇的动作识别能力,从初始视觉词典中选择动作识别能力强的视觉词汇建立视觉词典以提高动作识别准确率。Kim等[9]基于信息熵从初始视觉词典中选择对动作识别最有效的视觉词汇建立视觉词典。Yang等[10]基于信息增益建立视觉词典,提高了动作识别准确率。但传统信息增益仅考虑了视觉词汇出现与否对动作识别的作用,忽略了视觉词汇出现频率对动作识别的影响,不能选择最能表征人体动作的视觉词汇建立视觉词典。

图1 局部特征与词袋模型相结合的动作识别方法
Fig. 1 Actions recognition method based on local features and BoW model
为克服传统信息增益未考虑视觉词汇出现频率的不足,本文提出一种基于改进信息增益的视觉词典建立方法:引入描述视觉词汇出现频率的类内词频集中度、类间词频分散度两个参数对传统信息增益进行改进,以提高视觉词典中视觉词汇对动作的识别能力。
1 人体动作局部特征提取
时空兴趣点作为描述视频图像中表征时间和空间发生明显变化的局部特征点,常被用于人体动作识别。基于3D Harris[11]的时空兴趣点提取方法是Harris角点检测算法在时空域的扩展,具有抗噪性好、不易受到视角变化影响等优点。3D Harris时空兴趣点提取过程如下:
对于视频序列f,将其与高斯核函数作卷积得到图像序列的尺度空间L:
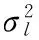
(1)
其中高斯核函数
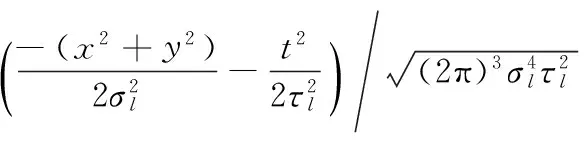
(2)
其中:x、y为图像的空间二维坐标,t为帧序,σl和τl为相互独立的图像空间和时间尺度。对尺度空间L分别在x、y、t方向求一阶导数Lx、Ly和Lt,利用一阶导数建立时空二阶矩阵μ:
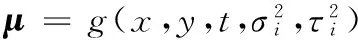
(3)
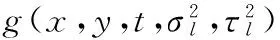
H=λ1λ2λ3-k(λ1+λ2+λ3)
(4)
式中:λ1、λ2和λ3为μ的特征值; 时空兴趣点为H取得局部极大值的点;k通常取值为0.005。
2基于改进信息增益建立视觉词典
基于词袋模型进行人体动作识别需将提取的时空兴趣点聚类建立初始视觉词典。基于信息增益进行特征选择能够选择初始视觉词典中最能表征人体动作的视觉词汇,但传统信息增益未考虑词频对动作识别的影响,本章将引入类内词频集中度和类间词频分散度改进信息增益,并利用改进信息增益建立视觉词典以进一步提高动作识别准确率。
2.1 传统视觉词汇信息增益
信息增益表征视觉词汇对动作识别所提供的信息量[12]。视觉词汇的信息增益越大,对动作识别提供的信息量越多。设Ci为某类动作,m为动作类别数,则视觉词汇t的信息增益IG(t)为:
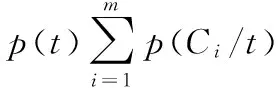
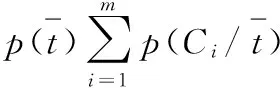
(5)
由式(5)知传统信息增益仅考虑了视觉词汇在训练样本中出现与否对动作识别的影响,当视觉词汇在训练样本中出现与不出现的视频数相同时,无论其出现频率高低,信息增益均相同。实际上,当视觉词汇在视频中出现的频率不同时,尽管信息增益相同,但其动作识别能力不同,导致传统信息增益无法对不同视觉词汇的动作识别能力作出准确评价。
用词频表征视觉词汇在动作视频中出现的频率。设视觉词汇t在某一个动作视频中出现a次,表征该动作视频的视觉词汇总数为b,则视觉词汇t在该动作视频中出现的词频TF(t)为:
TF(t)=a/b
(6)
表1给出了视觉词汇t1、t2和t3在跑步、挥手两类人体动作共计10个视频中(每类动作各有5个视频)的词频和传统信息增益。由于t1、t2和t3在训练视频每类动作中出现与不出现的视频数相同,它们的信息增益值亦相同,均为0.017。

表1 视觉词汇词频分布表Tab. 1 Term frequency distribution of visual words
但对比视觉词汇t1、t2,t1在跑步视频中的平均词频大于挥手视频中的平均词频,而t2在跑步、挥手两类视频中的平均词频几乎相同。因此t1相比t2能更好地识别跑步和挥手。同样,对比t1、t3,虽然它们在跑步、挥手视频中的平均词频相同,但t1在同一类的不同训练视频中词频大小更接近,而t3在跑步类的第二个训练视频中词频突然增大,表明该视觉词汇可能表征的是此视频中出现的噪声,因此t1相比t3能更好地识别跑步和挥手。
2.2 改进的视觉词汇信息增益
引入类内词频集中度、类间词频分散度这两个描述词频的参数改进传统信息增益,以选择动作识别力更强的视觉词汇。
2.2.1 类内词频集中度
类内词频集中度表征视觉词汇在相同动作类所有训练视频中的词频与平均词频的差异。视觉词汇t对应的类内词频集中度α(t)为:
(7)
2.2.2 类间词频分散度
类间词频分散度表征视觉词汇在不同类人体动作训练视频中的词频分布差异。视觉词汇t的类间词频分散度β(t)为:
(8)
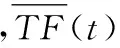
2.2.3 改进信息增益
为选取动作识别能力最大的视觉词汇,引入类内词频集中度、类间词频分散度改进信息增益,改进信息增益为:
IG′(t)=IG(t)×(β(t)/α(t))
(9)
由式(9)知,视觉词汇类内词频集中度越小,类间词频分散度越大,其改进信息增益值越大,动作识别能力越强。表1中视觉词汇t1的改进信息增益大于t3、t2,表明其动作识别能力更强。因此将改进信息增益作为评价指标,能够选择具有更强动作识别能力的视觉词汇建立视觉词典。
3 实验结果与分析
为验证本文提出的视觉词典建立方法对于人体动作识别的有效性,选取KTH和Weizmann单人动作数据库利用CPU 2.0 GHz、4 GB内存计算机基于Matlab 2014b平台进行实验验证。KTH数据库包含拳击、鼓掌、跑步、行走、挥手、慢跑6个常见动作,每种动作包含25个人在4个不同场景中的100个视频图像序列,视频帧速为25帧/s,每个动作视频的帧数为300~1 000不等。Weizmann数据库包括90段视频,分别为9个人的向前跳、向上跳、跑步、推举、弯腰、双手挥、单脚跳、横向动、单手挥、走路共10个动作。图2给出KTH和Weizmann数据库部分动作视频图像示例。
基于改进信息增益进行动作识别的总体流程如下:首先,提取所有训练视频人体动作视频时空兴趣点,采用HOG3D描述器[13]描述时空兴趣点;然后对时空兴趣点聚类建立初始视觉词典;计算视觉词典中所有视觉词汇的改进信息增益值并排序,选择满足条件的视觉词汇建立新的视觉词典;提取测试视频时空兴趣点,基于训练视频建立的视觉词典,得到测试人体动作视频的视觉词汇分布直方图,基于支持向量机(Support Vector Machine, SVM)方法进行动作识别。
两个数据库的人体动作视频的3D Harris时空兴趣点提取结果如图3所示。

图2 数据库不同动作示例Fig. 2 Different action samples of databases

图3 时空兴趣点提取结果Fig. 3 Results of spatio-temporal interest points extraction
KTH数据库每个动作选取80个动作视频为训练样本,其余20个视频为测试样本进行动作识别;Weizmann数据库则采用留一交叉验证确定训练视频样本和测试视频样本。对提取的训练视频中的时空兴趣点采用K均值聚类方法建立初始词典,不同初始视觉词典大小时KTH和Weizmann数据库的动作识别结果如表2所示。
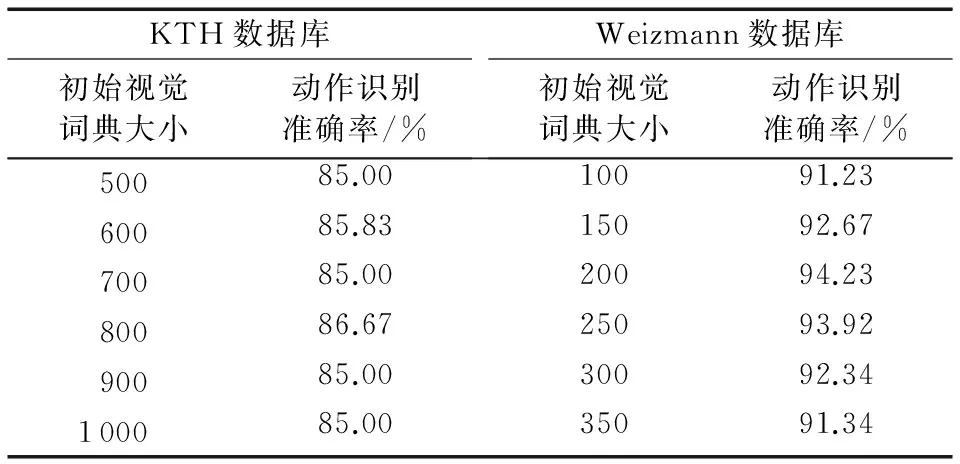
表2 不同大小初始视觉词典动作识别准确率Tab. 2 Accuracy of human actions recognition with different size of initial visual dictionary
由表2知,对于KTH和Weizmann数据库,当初始视觉词典大小为800和200时,人体动作识别准确率最高,因此选取初始词典大小分别为800和200。
计算并选取初始视觉词典中改进信息增益值大的视觉词汇建立新的视觉词典。图4给出了不同视觉词典大小时,基于改进信息增益、传统信息增益、期望交叉熵及互信息视觉词汇选择方法建立的视觉词典的动作识别结果。
由图4可知,采用改进信息增益建立视觉词典相比采用传统信息增益及其他特征选择方法建立的视觉词典进行动作识别,人体动作识别准确率得到提高,对于两个数据库,当视觉词典大小为650和160时最高动作识别准确率为89.17%和98.62%。
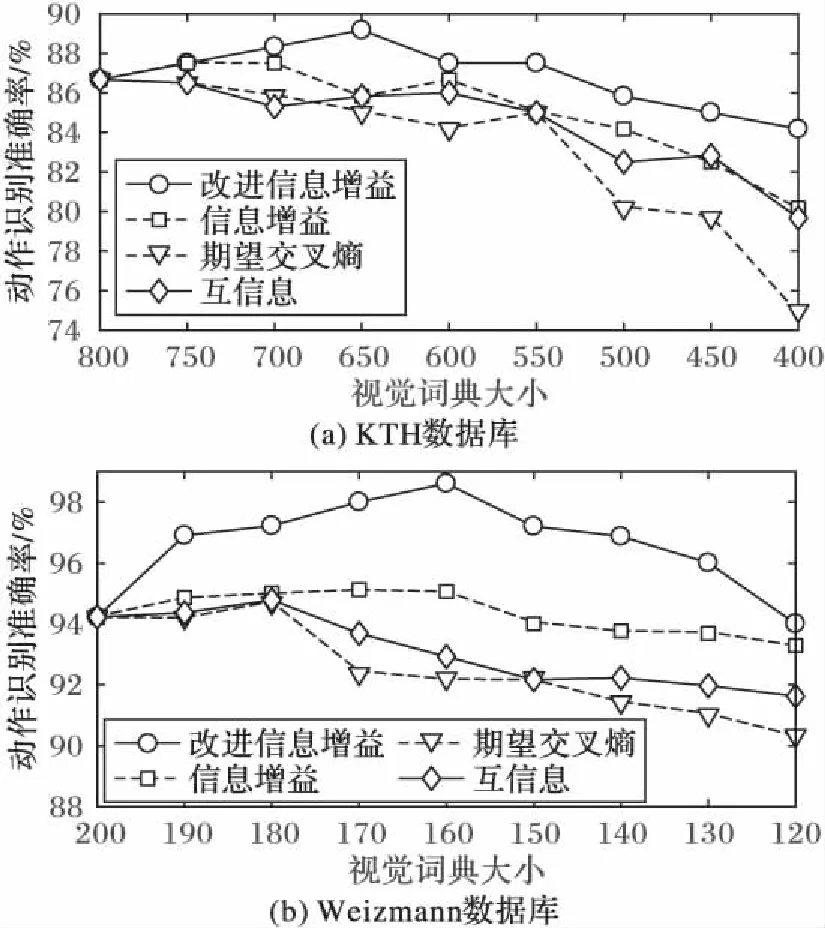
图4 不同特征选择方法及词典大小动作识别准确率比较Fig. 4 Comparision of human actions recognition accuracy with different method of feature selection and dictionary size
表3给出两个数据库采用不同动作识别方法得到的动作识别准确结果。
以KTH数据库为例,表4给出基于改进信息增益建立的视觉词典对不同类动作的最终识别结果。其中纵向为真实动作,横向为识别动作,对角线为各类动作的识别准确率,其他位置值为动作识别混淆率。
表3 不同动作识别方法的动作识别结果 %Tab. 3 Action recognition results with different methods %
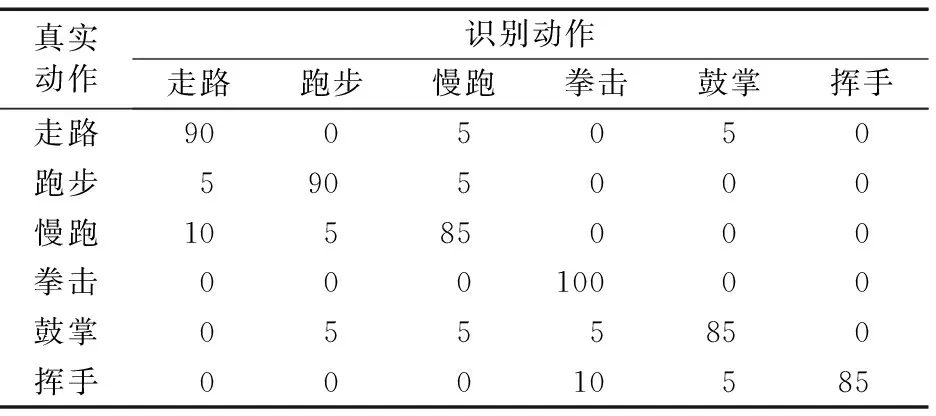
表4 KTH数据库各类动作的识别准确率 %Tab. 4 Accuracy of human actions recognition with different kinds of actions with KTH database %
4 结语
本文提出了一种基于改进信息增益建立视觉词典的方法。针对传统信息增益未考虑词频的不足,引入词频描述参数词频类内集中度及词频类间分散度改进信息增益,以提高视觉词典中视觉词汇对动作的表征能力。实验结果表明,相比传统信息增益及其他特征选择方法,本文提出的基于改进信息增益的视觉词典建立方法,能够选择更具有动作识别力的词汇建立视觉词典,提高了人体动作识别准确率。
References)
[1] 石祥滨,刘拴朋,张德园.基于关键帧的人体动作识别方法[J]. 系统仿真学报,2015,27(10):2401-2408. (SHI X B, LIU S P, ZHANG D Y. Human action recognition method based on key frames [J]. Journal of System Simulation, 2015, 27(10): 2401-2408.)
[2] KHAN R, BARAT C, MUSELET D, et al. Spatial orientations of visual word pairs to improve bag-of-visual-words model [C]// BMVC 2012: Procedings of the 2012 British Machine Vision Conference. Durham, UK: BMVA Press, 2012: 1-11.
[3] FARAKI M, PALHANG M, SANDERSON C. Log-Euclidean bag of words for human action recognition [J]. IET Computer Vision, 2016, 9(3): 331-339.
[4] LAZEBNIK S, SCHMID C, PONCE J. Beyond bags of features: spatial pyramid matching for recognizing natural scene categories [C]// CVPR ’06: Proceedings of the 2013 IEEE Conference on Computer Vision and Pattern Recognition. Washington, DC: IEEE Computer Society, 2006, 2: 2169-2178.
[5] LIU J, SHAH M. Learning human actions via information maximization [C]// CVPR ’08: Proceedings of the 2008 IEEE Conference on Computer Vision and Pattern Recognition. Washington, DC: IEEE Computer Society. Washington, DC: IEEE Computer Society, 2008: 2971-2978.
[6] LI Z, LU W, SUN Z, et al. A parallel feature selection method study for text classification [J]. Neural Computing & Applications, 2016, 27: 1-12.
[7] 贾隆嘉,孙铁利,杨凤芹,等.基于类空间密度的文本分类特征加权算法[J]. 吉林大学学报(信息科学版),2017,35(1):92-97. (JIA L J, SUN T L, YANG F Q, et al. Class space density based weighting scheme for automated text categorization[J]. Journal of Jilin University (Information Science Edition), 2017, 35(1): 92-97.)
[8] UYSAL A K. An improved global feature selection scheme for text classification [J]. Expert Systems with Applications, 2016, 43(C):82-92.
[9] KIM S, KWEON I S, LEE C W. Visual categorization robust to large intra-class variations using entropy-guided codebook [C]// Proceedings of the 2007 IEEE International Conference on Robotics and Automation. Piscataway, NJ: IEEE, 2007: 3793-3798.
[10] YANG J, JIANG Y-G, HAUPTMANN A G, et al. Evaluating bag-of-visual-words representations in scene classification [C]// MIR ’07: Proceedings of the International Workshop on Workshop on Multimedia Information Retrieval. New York: ACM, 2007: 197-206.
[11] LAPTEV I. On space-time interest points [J]. International Journal of Computer Vision, 2005, 64(2/3): 107-123.
[12] 李学明,李海瑞,薛亮,等.基于信息增益与信息熵的TFIDF算法[J].计算机工程,2012,38(8):37-40. (LI X M, LI H R, XUE L, et al. TFIDF algorithm based on information gain and information entropy [J]. Computer Engineering, 2012, 38(8): 37-40.)
[14] LAPTEV I, MARSZALEK M, SCHMID C, et al. Learning realistic human actions from movies [C]// CVPR ’08: Proceedings of the 2008 IEEE Conference on Computer Vision and Pattern Recognition. Washington, DC: IEEE Computer Society, 2008: 1-8.
[15] LERTNIPHONPHAN K, ARAMVITH S, CHALIDABHONGSE T H. Human action recognition using direction histograms of optical flow [C]// ISCIT 2011: Proceedings of the 2011 11th International Symposium on Communications and Information Technologies. Piscataway, NJ: IEEE, 2011: 574-579.
This work is partially supported by the National Natural Science Foundation of China (61340056).
WUFeng, born in 1992, M. S. candidate. His research interests include digital image processing, human actions recognition.
WANGYing, born in 1969, Ph. D., assoicate professor. Her research interests include photoelectric inspection, machine vision inspection, artificial intelligence detection.
Visualdictionaryconstructionforhumanactionsrecognitionbasedonimprovedinformationgain
WU Feng, WANG Ying*
(CollegeofInformationScienceandTechnology,BeijingUniversityofChemicalTechnology,Beijing100029)
Since term frequency is not considered by traditional information gain in Bag-of-Words (BoW) model, a new visual dictionary constructing method based on improved information gain was proposed to improve the human actions recognition accuracy. Firstly, spatio-temporal interest points of human action video were extracted by using 3D Harris, then clustered byK-means to construct initial visual dictionary. Secondly, concentration of term frequency within cluster and dispersion of term frequency between clusters were introduced to improve the information gain, which was used to compute the initial dictionary; then the visual words with larger information gain were selected to build a new visual dictionary. Finally, the human actions were recognized based on Support Vector Machine (SVM) using the improved information gain. The proposed method was verified by human actions recognition of KTH and Weizmann databases. Compared with the traditional information gain, the actions recognition accuracy was increased by 1.67% and 3.45% with the dictionary constructed by improved information gain. Experimental results show that the visual dictionary of human actions based on improved information gain increases the accuracy of human actions recognition by selecting more discriminate visual words.
human actions recognition; Bag-of-Words (BoW) model; information gain; term frequency
TP391.4; TN911.73
A
2017- 02- 24;
2017- 04- 12。
国家自然科学基金资助项目(61340056)。
吴峰(1992—),男,黑龙江绥化人,硕士研究生,主要研究方向:数字图像处理、人体动作识别; 王颖(1969—),女,天津人,副教授,主要研究方向:光电检测、机器视觉检测、人工智能检测。
1001- 9081(2017)08- 2240- 04
10.11772/j.issn.1001- 9081.2017.08.2240
