基于改进KNN的案例匹配模块的设计与实现
2017-10-19,
,
(福建工程学院 信息科学与工程学院,福建 福州 350118)
基于改进KNN的案例匹配模块的设计与实现
谢开池,薛醒思
(福建工程学院 信息科学与工程学院,福建 福州 350118)
为了提高KNN检索策略的检索效率和检索结果的质量,提出一种改进的KNN检索策略。在引入图书馆领域本体和概念语义相似度度量技术的前提下,利用句法结构筛选不合理的案例以降低计算规模,从而提高案例的检索质量和效率,利用改进的微粒群算法优化概念语义相似度度量技术中的组合参数以提高KNN检索的结果质量。实验数据采用福州晓锋科技信息咨询有限公司提供的图书馆参考咨询测试数据。实验结果表明,相比于传统KNN和基于传统PSO的改进KNN方案有效地提高了案例匹配结果的查全率和查准率。
案例推理; KNN; 微粒群算法
图书馆虚拟咨询参考系统是一类智能决策支持系统(intelligent decision support systems,简称IDSS)[1],该系统利用基于知识库和案例库的推理技术确定用户决策所需的信息。案例推理技术[2](case based reasoning,简称CBR)是IDSS的核心技术之一,其目的是依据给定的决策问题和决策环境的特征描述,快速而有效地确定案例库中对求解的问题最有帮助的案例[3]。在案例推理技术中,如何制定一种高效的案例检索策略是目前亟需解决的关键问题[4]。针对该问题,李小展[5]提出了分阶段的最近邻策略,利用特征加权的产K nearest neighbourhood(KNN)逐步缩小案例检索范围,以此提高医疗辅助诊断系统的检索效率;费玉莲[6]采用计算概念之间的相关系数的语义距离求得概念间的相似度,再利用KNN求得源案例和目标案例相似度。但这些检索策略既没有全面考虑影响概念语义相似度的相关因素(语义关系、语义距离、节点深度和节点密度),且相似度匹配中参数仍存在人为因素,从而影响检索结果的质量。针对上述过程,提出一种基于图书馆领域本体知识库的KNN案例检索策略。首先,在引入图书馆领域本体[7]的基础上,利用本体的概念层次树结构对案例问句进行“主-谓-宾”三元组语义标注的案例标注,利用案例问句的“主-谓-宾”句式结构过滤案例库中不符合的案例集,减少候选案例集的规模,提高基于KNN的CBR技术的效率和结果质量。其次,通过改进的微粒群优化算法确定三类相似度度量技术最优的集成权重、K值及相似度阈值,并在匹配过程中综合考虑3类基于本体概念层次树的相似度度量技术,提高了案例检索的查准率和查全率。
1 相关概念与技术
定义1本体(Ontology):本体是一个共享概念化模型的形式化和显式的说明规范[8],其核心是本体能够解释计算机语义信息。文中本体可表示为一个三元组O=(C,R,A)。其中:C表示概念的集合,即某一领域的概念范畴;R表示概念间的关系,即该领域概念之间的关联;A表示公理集,即关于被建模领域中真假的论述。
定义2本体概念层次树:给定本体O,本体概念层次树是一个三元组T=(N,R,F)。其中:N={n1,n2,…,ne}是本体概念层次树中个概念节点的集合,ni(i=1,2,…,e)对应O中的概念ci(i=1,2,…,|C|);R=(ni,nj)i,j∈{1,2,…,e}是本体概念层次树中概念节点ni和nj之间的边集合,表示对应概念ci和cj之间的is-a关系;F={F1,F2,…}是本体概念层次树的层的集合。其中:令path(ni) 表示概念节点ni到根节点的最短路径长度,Fj={ni|ni⊆N,path(ni)=j,i∈[1,e],j=1,2,…}。
定义3图书馆参考咨询案例:图书馆参考咨询案例是一个五元组case=(caseId,question,predicate,keyword,answer) ,其中caseId表示图书馆参考咨询案例的编号;question表示该案例的问题;predicate表示该案例的谓语;keyword=(subject,object)表示该案例的关键词(分别是主语和谓语);answer表示该案例的问题答案。
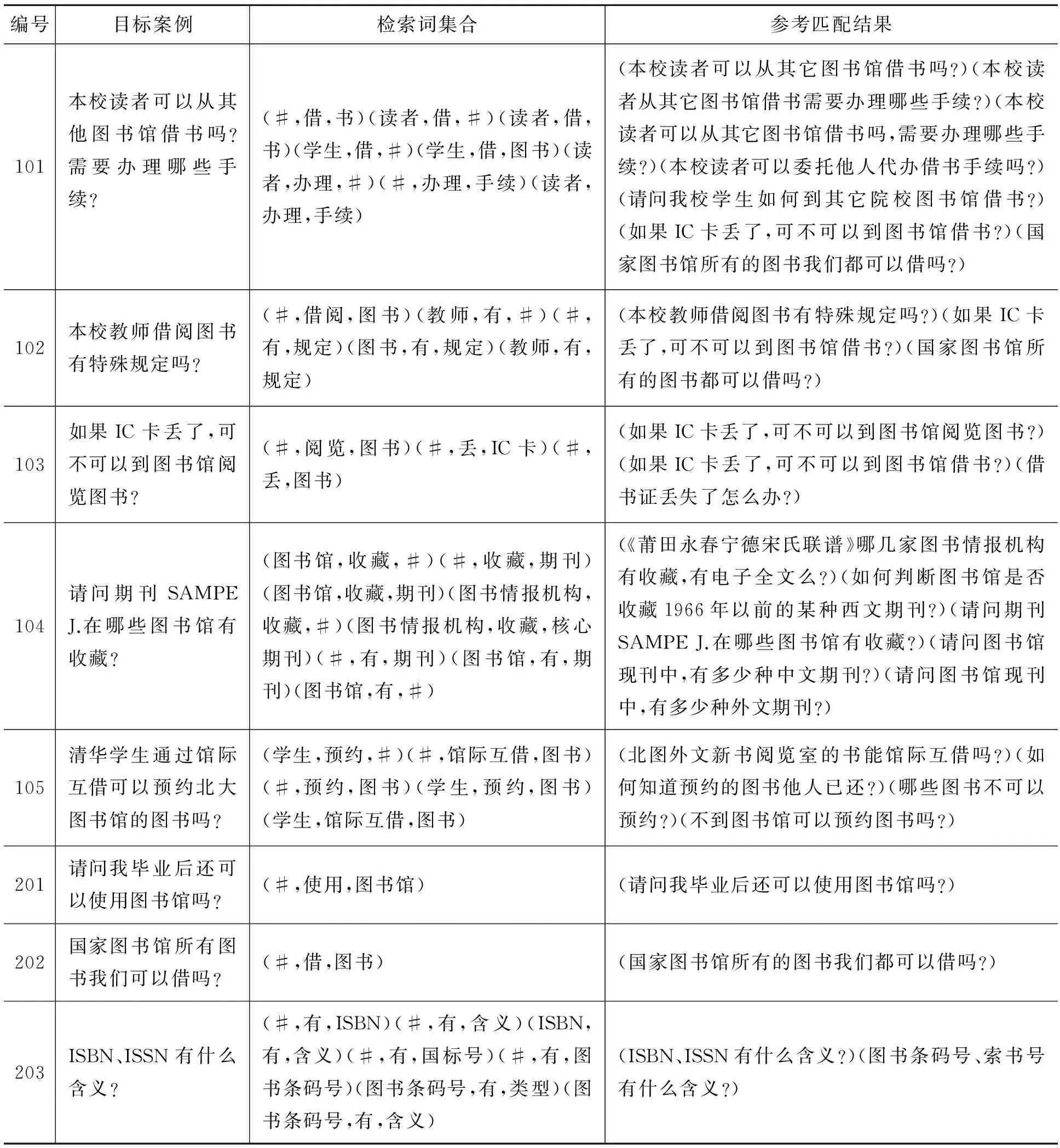
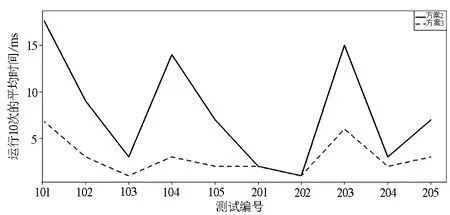
定义4图书馆参考咨询案例库:图书馆参考咨询案例库是指一种将已存在的图书馆参考咨询案例以一定的索引方式存储的知识库,表示为Case={case1,case2,…,casez},casez表示案例库中的第Z个历史案例(history case,简称HC),Z表示图书馆参考咨询案例的个数。在本文的工作中,尚未保存在案例库中的新案例称为目标案例(new case,简称NC),同时将图书馆参考咨询案例库分成训练集和测试集两部分,训练集表示为TrainCase={casei|casei⊆Case,i∈[1,numtrain],numtrain 定义5图书馆参考咨询案例检索词集合:给定num_q个检索词,图书馆参考咨询案例检索词集合定义如下:Q={q1,q2,..,qnum_q},其中qi=(subjecti,predicatei,objecti),i=1,2,…,num_q表示第i个检索词,subjecti、predicatei和objecti分别表示检索词的主语、谓语和宾语。 定义6图书馆参考咨询案例匹配结果质量度量技术:给定案例参考匹配结果Refer和案例匹配结果ReturnCase(指案例匹配的结果),图书馆参考咨询案例匹配结果的查全率r(ReturnCase,Refer)、查准率p(ReturnCase,Refer)、度量f(ReturnCase,Refer) 分别定义如下[9]: f(ReturnCase,Refer)= 公式(1)-(3)中:|Refer∩ReturnCase|表示匹配结果参考匹配结果的交集个数;|Refer|表示参考匹配结果的个数;|ReturnCase|表示匹配结果的个数。 定义7概念语义相似度和案例相似度:概念语义相似度是概念间可以互相替换的程度[10]。通过综合考虑两个概念的语义距离、节点深度和节点密度[11]来度量它们之间的概念语义相似度。 (1)语义距离是指在本体概念层次树中,概念ni和nj到两者最近共同父节点的路径长度distance(ni,nj)。如果distance(ni,nj)越小,即概念的语义距离越小,其相似度越大;反之则相似度越小。 (2)节点深度是指在本体概念层次树中某一概念节点ni所处层次集Fdepth(depth=1,2,…) 到根节点的路径长度depth。若两个节点ni和nj的层次数之和depth(ni)+depth(nj) 越大,对应的概念之间的相似度则越大;若两个节点的层次数之差|depth(ni)-depth(nj)| 越小,对应概念之间的相似度则越大。 (3)节点密度是指在本体概念层次树中,概念节点ni和nj的共同父节点拥有的子节点密度。则二者的节点密度定义如下: 其中:p是指以概念节点ni和nj的共同父节点为根节点的子树所包含的除根节点以外的节点个数;q是指节点ni、nj和它们共同父节点之间所构成树的最大层次差。 在研究中,给出两个概念节点ni和nj,它们之间的概念语义相似度度量公式定义如下[12]: 给定历史案例HC和目标案例NC,二者的案例相似度定义如下: 式中, simallconcept=max(simconcept(hcsubject, ncsubject),simconcept(hcsubject,ncobject))+ max(simconcept(hcobject,ncsubject), simconcept(hcobject,ncobject))+ max(simconcept(ncsubject,hcsubject), simconcept(ncsubject,hcobject))+ max(simconcept(ncobject,hcsubject), simconcept(ncobject,hcobject)) 其中:hcsubject表示历史案例中的主语;hcobject表示历史案例中的宾语;ncsubject表示目标案例的主语;ncobject表示目标案例的宾语;simconcept表示主宾间相似度,用公式(5)计算。 基于改进KNN的案例检索策略分两个步骤:基于改进PSO的参数训练步骤和案例测试步骤。已知检索词集合的前提下,首先利用改进PSO算法和案例训练集TrainCase寻优得到参数集合A;然后基于给定的案例测试集TestCase,利用训练的参数集合A和TestCase中某一案例检索,得到该案例的匹配案例集合。该技术的框架图如图1所示。 2.1 案例检索策略中确定参数集合的单目标优化模型 在案例检索过程中,如何确定KNN检索策略中由相似度权重、K值和阈值组成的最优参数集合,使得测试集中所有案例的检索结果质量最优是案例检索策略中的关键问题。基于明显的观察结果,结果案例的数量和结果案例间的相似度同案例匹配结果质量相关,因此针对该问题提出的单目标优化模型数学形式如下: 图1 基于改进KNN的案例检索策略框架图Fig.1 The framework of improved KNN-based case retrieval strategy 其中:X是参数集合向量(x1,x2,…,xn)T,xi(i=1,2,…,n-2) 是概念相似度影响因素i的权重,xn-1是KNN策略中K值,xn是用于过滤同目标案例相似度值太低的源案例的阈值;f(X) 是训练集中所有案例匹配结果的平均质量,其度量函数定义如下: 式中:valuel(l=1,2,…,numtrain) 表示训练集中案例casel的评价值,其计算公式如下: 2.2 改进的自适应惯性权重的微粒群优化算法 在设置了以上变量后,粒子的惯性权重依据以下原则赋值: (1)若f(k)(xi)>f(k)frontxavg,说明该粒子属于种群中优秀的粒子,该粒子的下一取值要趋近于收敛,w取值范围内的最小值0.4。 (2)若f(k)(xi) (3)若f(k)behindxavg≤f(k)(xi)≤f(k)frontxavg,说明该粒子处于中等水平,正在逐步寻优,因此其取值按如下改进的公式计算: 其中:wmax,wmin分别为初始惯性权重和终止惯性权重,本文wmax取值为0.9,wmin取值为0.4,k为当前迭代次数,itermax为最大迭代次数。 通过以上的改进,防止当前迭代中粒子适应度变差的粒子引导继续向更差的方向移动,有效的降低了无效迭代的次数。同时,收敛速度加快,结果更稳定。改进的自适应惯性权重的PSO算法流程如图2。 图2 改进的PSO算法流程图Fig.2 Comparison of the matching result’s quality by f-measure among three schemes 选用的测试数据集(图书馆参考咨询数据)是由福州晓峰科技信息咨询有限公司提供的图书馆领域的相关知识。在案例的句法结构信息中,动词是其他成分(主语,宾语等名词)的基础,能直接影响案例匹配的正确率[19]。依据上述内容将测试数据分为两类来评价案例匹配模块的结果质量:(1)测试案例仅含有一个动词;(2)测试案例有两个及以上的动词。 每个测试用例由目标案例、检索词集合及参考匹配结果组成,分别表示用户咨询问题、经过分词扩展模块后的检索词集合和由专家确定的标准匹配结果。表1给出了本文测试用例的详细描述。 表1 测试用例描述Tab.1 The description of test cases 续表 编号目标案例检索词集合参考匹配结果204如何查询外文引文索引文献的“收录号”?(#,查询,文献)(#,查询,收录号)(如何查询外文引文索引文献的“收录号”?)(如何查找国内外标准文献?)(如何找到与课题相关的文献?)205图书条码号、索书号有什么含义?(#,有,图书条码号)(#,有,含义)(图书条码号,有,含义)(#,有,索书号)(索书号,有,含义)图书条码号、索书号有什么含义? 改进PSO的算法参数如下: (1)基于本体的概念语义相似度度量的调节参数a用于调节概念相似度值,a取值越大概念相似度值语义距离趋近于1的速度越快[20],取值为1时相似度效果最好。 (2)粒子群种群规模及最大进化代数的设定与问题的规模成正比,设定值偏小会影响结果的质量,设定值偏大影响结果运行的效率。种群规模建议范围为[5,20],最大进化代数建议范围为[500,2 000]。由于本文的问题规模不大(仅有5个参数需要确定),因此种群规模及最大进化代数分别设置为10个个体和1 000次迭代。 (3)wmax是惯性权重w的初始值,wmin为粒子进化到最大迭代数的惯性权重值,当wmax=0.9,wmin=0.4时优化问题取得最好的效果[21],因此本文取值为wmax=0.9,wmin=0.4。 (4)学习因子c1,c2分别表示粒子个体向局部最优和全局最优位置移动的能力,一般设为相同的值,常见的设定为2[22]。 (5)随机因子r1,r2是也是影响粒子“自我学习”和“社会学习”的能力,一般取值为[0,1]之间的随机数[23]。 表2中的数据是基于句法结构过滤的KNN(方案1)、基于改进PSO的KNN(方案2)及基于句法结构和改进PSO的KNN(方案3)3种方法的匹配结果的f度量(查全率,查准率),其中本文的方法是在每个测试用例上独立运行10次后的平均f度量值。从表2可以看出,方法3的匹配结果的f度量值都明显优于方案1和方案2,说明基于改进PSO的KNN检索策略明显优于标准的KNN策略。此外,从方案3的f值比对中可以看出所有测试案例都远远高于方案2(至少高出25%),该数据证明利用句法结构(动词)过滤候选案例集可以很大程度的提高匹配的质量。 表2 通过f度量值比较3种方案的匹配结果质量Tab.2 Comparison of matching result’s quality by f-measure among three schemes 图3通过比较方案2和方案3得出有无句法结构过滤策略对所有案例测试独立运行10次后的平均运行时间(时间单位为ms)影响,从该图3可以看出经过句法结构过滤案例候选集的方案3的大部分远远低于未过滤案例候选集的方案2。本文测试案例库的规模为233个案例,若是案例库的规模更大,未预先经过句法结构过滤的方案其运行速度将非常慢,从而影响算法的效率。图4通过比较标准PSO和本文改进的PSO进化代数与独立运行10次后的平均适应度值的变化关系。从该图4可以得出标准的PSO算法无效进化代数多,且易陷入局部最优,无法收敛到全局最优解,而改进的PSO算法收敛的最优解略高于标准的PSO,在不到600代就达到了最优解。 图3 通过运行时间比较3种方案的匹配效率Fig.3 Comparison of matching efficiency under the running time among three schemes 图4 基于标准PSO和改进PSO的适应度值对比图Fig.4 The comparison of the fitness value between standard PSO and improved PSO 综上所述,本文提出的两个创新技术(利用句法结构过滤案例候选集和利用改进的PSO优化KNN参数)不仅能够确定的质量优于传统KNN和基于传统PSO的KNN方案的案例匹配结果,还能显著提高案例匹配过程的效率。因此,改进PSO的KNN检索策略在案例推理中能更高效率的获取到高质量的案例匹配结果。 针对KNN检索策略中检索效率低、缺乏隐含语义以及有人为因素的权重取值3个缺陷,提出了一种基于本体和微粒群算法的改进KNN检索策略。首先,基于图书馆领域本体的背景条件下,利用经过中文分词及查询扩展步骤得到的检索词集合中的谓语过滤案例库,得到初步案例候选集;然后为了避免相似度度量技术中参数设定包含人为因素影响,提出并设计了一种改进的微粒群优化算法,并利用改进PSO优化度量技术中的参数以提高案例匹配的准确率。实验数据采用的是福州晓锋科技信息咨询有限公司提供的图书馆参考咨询测试数据。实验结果表明,相比于传统KNN和基于传统PSO的KNN方案,本方案有效地提高了案例匹配结果的查全率和查准率。 [1] 杨斌宇.基于案例的推理在智能决策支持系统中的应用[D].长春:吉林大学,2004. [2] 王津津.案例推理在决策支持系统中的应用研究[D].合肥:合肥工业大学,2010. [3] 李锋刚,倪志伟,郜峦.基于案例推理和多策略相似性检索的中医处方自动生成[J].计算机应用研究,2010,27(2):544-547. [4] 张春晓.案例推理的认知改进策略及学习性能研究[D].北京:北京工业大学,2014. [5] 李小展.基于文本挖掘的医学诊疗案例推理系统的研究与应用[D].广州:广东工业大学,2011. [6] 费玉莲.面向电子商务的谈判支持系统研究[D].杭州:浙江工商大学,2011. [7] 李景.领域本体的构建方法与应用研究[D].北京:中国农业科学院,2009. [8] 崔巍.基于Peer-to-Peer网和地理ontology的系统集成和互操作研究[J].计算机工程与应用,2003,39(32):45-47. [9] 薛醒思.基于进化算法的本体匹配问题研究[D].西安:西安电子科技大学,2014. [10] 杨美荣,邵洪雨,史建锋,等.改进的领域本体概念相似度计算模型研究[J].情报科学,2014,32(5):72-77. [11] 唐中林.基于本体的概念相似度计算方法的研究[D].武汉:武汉理工大学,2013. [12] 陈沈焰,吴军华.基于本体的概念语义相似度计算及其应用[J].微电子学与计算机,2008(12):96-99. [13] 董颖,唐加福,许宝栋,等.一种求解非线性规划问题的混合粒子群优化算法[J].东北大学学报(自然科学版),2003,24(12):1141-1144. [14] 关圣涛,楚纪正,邵帅.粒子群优化算法在非线性模型预测控制中的研究应用[J].北京化工大学学报(自然科学版),2007,34(6):653-656. [15] 王书斌,单胜男,罗雄麟.基于T-S模糊模型与粒子群优化的非线性预测控制[J].化工学报,2012,63(S0):176-187. [16] Shi Yuhui,Eberhart R C.Fuzzy adaptive particle swarm optimization[C]∥Proceedings of the 2001 Congress on Evolutionary Computation.Washington D C:IEEE,2001:101-106. [17] 刘伟,周育人.一种改进惯性权重的PSO算法[J].计算机工程与应用,2009,45(7):46-48. [18] 申丹丹,石跃祥,周文杰,等.基于适应值引导的粒子群改进算法[J].计算机工程与应用,2015,51(14):63-66. [19] 龚小谨,罗振声,骆卫华.汉语句子谓语中心词的自动识别[J].中文信息学报,2003,17(2):7-13. [20] 张帆,钟金宏,黄玲.改进的领域本体概念相似度计算方法[J].计算机工程,2010,36(23):66-68. [21] 胡建秀,曾建潮.微粒群算法中惯性权重的调整策略[J].计算机工程,2007,33(11):193-195. [22] 黄少荣.粒子群优化算法综述[J].计算机工程与设计,2009,30(8):1977-1980. [23] 王杰文,李赫男.粒子群优化算法综述[J].现代计算机(专业版),2009,30(2):22-27. [24] 王家超.基于事例推理在甲型H1N1流感诊断中的应用研究[D].沈阳:东北大学,2010. (特约编辑:黄家瑜) DesignandimplementationofacasematchingmodulebasedonimprovedKNN Xie Kaichi,Xue Xingsi (College of Information Science and Engineering,Fujian University of Technology,Fuzhou 350118,China) To improve the efficiency and quality of case retrieval,an improved KNN retrieval strategy was proposed.By introducing library domain ontology and concept semantic similarity measurement technology,cases’ syntactic structure was employed to filter out the unreasonable cases to reduce the computation amount (search space) and improve the case retrieval (alignment’s) quality.Then,an improved particle swarm algorithm was presented to determine the optimal aggregating parameters in the similarity measure technologies to improve the case alignment’s quality.In the experiment,the testing cases were from Fuzhou Xiaofeng Science and Technology Information Consulting Ltd.,Co,.The experimental results show that compared with the traditional KNN and the traditional PSO-based KNN,the proposal can significantly improve the case alignment’s quality in terms of both recall and precision. case based reasoning;K nearest neighbourhood;particle swarm algorithm TP182 A 1672-4348(2017)04-0349-09 10.3969/j.issn.1672-4348.2017.04.009 2017-05-26 国家级大学生创新创业训练计划项目(201610388024) 薛醒思(1981-),男,福建福清人,副教授,博士,研究方向:智能计算和本体技术的研究与应用。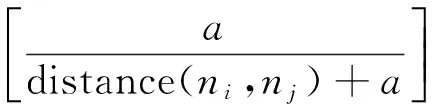




2 基于本体和微粒群算法的改进KNN技术


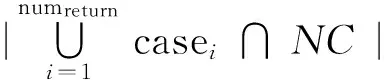
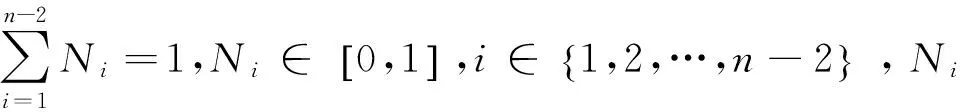


3 实验结果与分析




4 结论
