中国移动智能客服系统研究及实现*
2017-10-17胡珉冯俊兰王燕蒙闪云香
胡珉,冯俊兰,王燕蒙,闪云香
(中国移动通信有限公司研究院,北京 100053)
中国移动智能客服系统研究及实现*
胡珉,冯俊兰,王燕蒙,闪云香
(中国移动通信有限公司研究院,北京 100053)
根据中国移动客服知识网站、短信等自助服务渠道特点,深入研究客户语言特征,对客户自然语言表达进行语义识别,在此基础上实现客户问题与答案的智能匹配,并根据服务场景特征进行客户问题回复。构建了中国移动客服业务知识分类体系,为智能客服提供数据支持;研究及实现了智能应答系统,用于理解用户意图,精准回复用户,并适时地推荐相关问题给用户,提升满意度。
智能客服;本体;规则;搜索
随着人工智能及机器学习等技术的不断进步,智能应答技术及系统日臻成熟,达到了商用的水平。国际上,谷歌、微软、苹果等互联网公司都在这方面进行了深入的研究,微软开发了“小冰”,在闲聊方面获取了不少粉丝及交互数据;苹果“siri”系统已经成为了iPhone等终端设备的新型控制手段,向个人助理方向演进。国内,阿里巴巴、小i、科大讯飞等公司也大力发展自己的产品线。
由此可见,智能客服作为新型的市场引起高度的重视和极大的投入热情。智能客服可以辅助客服人员快速处理应答,提高客服人员并发处理效率及部分替代客服人员,降低企业成本。
1 中国移动智能客服现状
中国移动拥有超过8亿移动用户,客服人员4万。每天产生的客服问题也是海量的,包括查询、咨询、办理、投诉4大方面,每个方面都涉及各类移动业务知识,并且知识点之间也存在大量的关联关系。不仅如此,移动业务每个阶段都会推出新的业务和活动,导致客服容量需要不断地扩大,而与此同时,同样增加的用工成本却制约了客服中心的规模。传统的电话和短信客服也已经不能满足多变的客户需求,专业知识的爆炸及客服人员的成长周期制约了服务的质量及客服中心自更新的速度,急需通过技术创新等手段来改变客服现状。
现有的各省公司聊天机器人仅能完成初级的问题回答,用户意图识别不够正确,缺乏上下文语义理解,还不算是真正意义上的智能应答。因此,急需进行创新研发,引入自然语言处理、对话控制等技术,使之达到真正的智能化,同时,需要深入分析大量的客服日志,总结用户提问方式,采用机器自学习的方式逐步提高语义识别能力,从而向智能客服迈进。
2 中国移动智能客服系统研究及实现
根据中国移动业务体系的特点,构建了智能客服服务体系,如图 1所示。
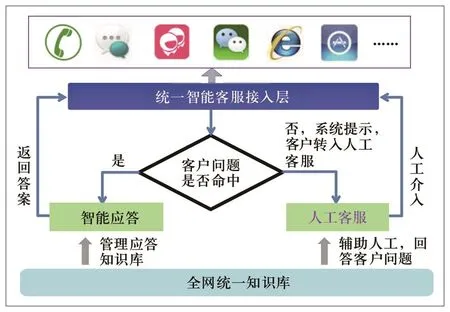
图1 中国移动智能客服服务体系
该体系具有如下特点。
(1) 全网统一知识库负责存储和管理整个服务体系的数据,数据格式统一,并且以三元组方式管理,方便快速定位到最小的知识单元。
(2) 智能应答和人工客服配合完成对用户问题的识别和反馈,提升系统响应率,提高用户满意度。
(3) 统一智能客服接入层完成对智能应答和人工客服统一的接口封装,以Http服务的方式实现多渠道的接入功能,包括APP、短信、飞信、微信、网站等。
2.1 知识分类体系梳理
客服服务基本本质就是用户提出问题,人或者机器根据已有的知识对用户的问题予以回答。因此,知识如何组织、构建就是最底层、最核心需要解决的问题,它关系到知识上下位关系描述和知识点本身描述两方面内容。
2.1.1 知识点上下位关系描述
根据知识属性将所有知识归类,并总结出一、二级目录。一级目录从对内/对外、个人/集团、业务类型等维度划分,整理出营业产品及服务(基础服务)、资费产品(资费与套餐)、4G专区等10个一级目录。二级目录则根据该目录下所属业务的情况,按业务的集中特性进行的划分。
如图2所示,对部分知识层级关系举例说明。
(1)对一级目录命名,并进行定义。如一级目录中营销活动,其是具有一定针对性和时效性、增加客户粘度、促进客户办理量的活动方案。
(2)对一级目录的内容进行划分,设计二级目录,并对二级目录进行定义。如营销活动分为优惠活动(各类促销、优惠活动)、营销宣传(涵盖10086信息群发、各类新旧媒体宣传)、外呼(通过10086向特定客户主动告知的项目)3个二级目录。
(3)针对二级目录涵盖的知识点范围进行划分。如优惠活动包含较常规套餐和功能更优惠的,短期或较长期对客户开展活动,如个人业务促销、集团业务促销、终端促销、资费促销、渠道促销。
根据对知识点范围的确定,可以将移动业务具体的知识点归入到对应一、二级目录,形成树形结构。
2.1.2 知识点本身描述
按业务特性制定了资费类、业务类、营销类、口径类、服务渠道类、宣传类、终端类7大模板,并将各类业务涉及的主要知识点整理出要素。
营销活动的要素点为例,营销活动知识点内部也分成一级要素、二级要素、三级要素等,这个根据知识点的结构可以进行自行定义,针对具体的要素点的取值,分为可选的和自填的,原则上,再设计模板的时候,尽量让要素点取值为可选,这样能够保证要素点取值的唯一性,避免引起要素点表达的歧义。
根据以上两步,现存的移动业务知识点都能被划分到一、二目录,并且知识点的描述都涵盖在7大模板里面,为后续的知识使用提供数据支撑。
2.2 中国移动业务本体形式描述
“本体论 (Ontology) ”原是哲学上的概念,在西方哲学史和中国哲学史中分别具有各自的含义。20世纪90年代初期,国际计算机界举行了多次关于本体的专题研讨会,本体成为包括知识工程、自然语言处理和知识表示在内的诸多人工智能研究团体的热门课题,其主要原因在于本体使人与人、人与机器、机器与机器之间的交流建立在对所交流领域的共识基础上。
建立中国移动业务本体的具体过程如下。
2.2.1 确定知识源
知识源是知识获取的重要步骤。中国移动业务具有可本体化的特征,层级性、要素化等,因此,被确定为知识源。
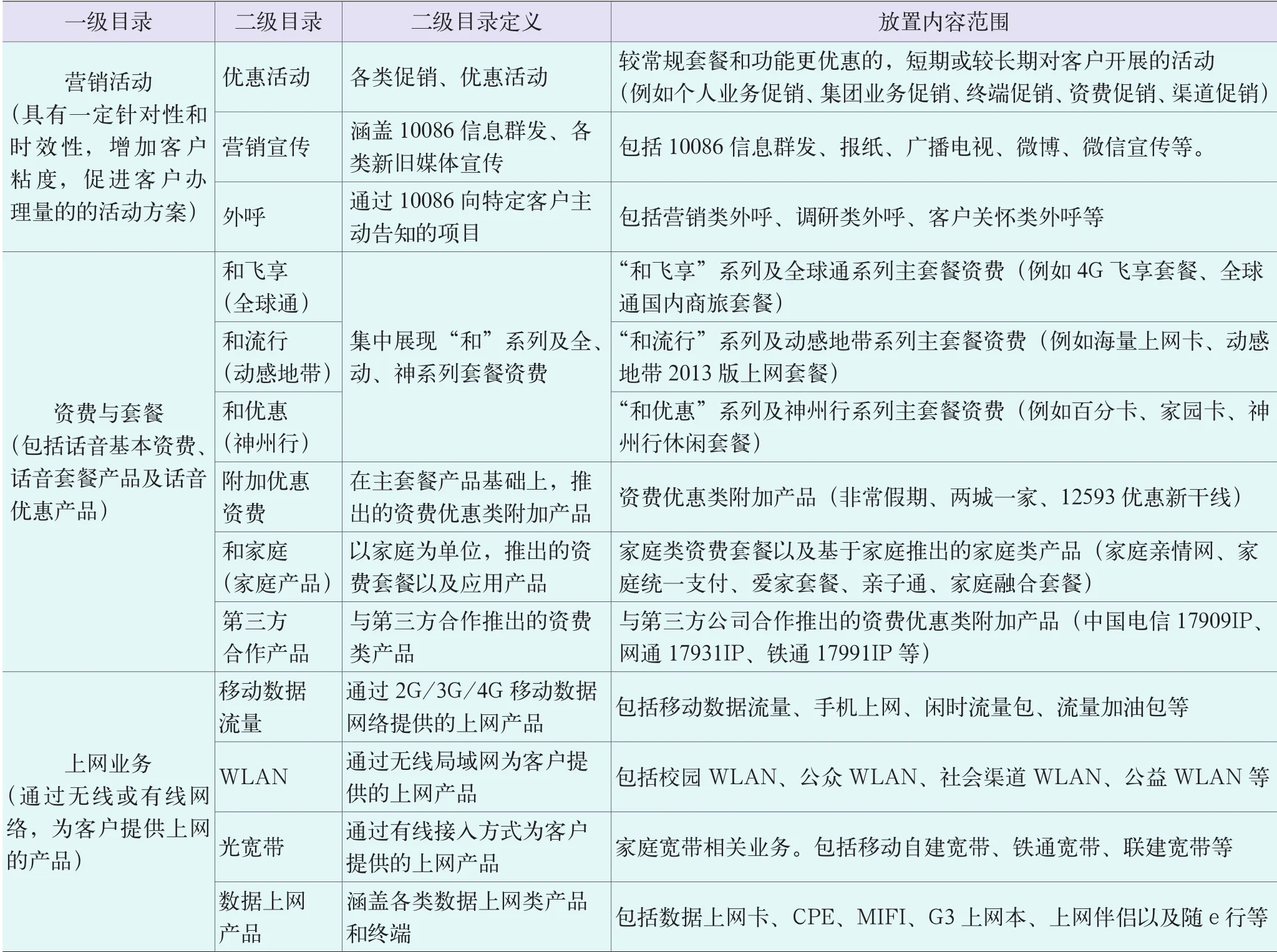
图2 知识层级关系
2.2.2 领域分析
领域分析也就是领域的概念化,识别领域中的概念、个体、关系和属性,把领域用这些概念、个体和关系等表示出来。
2.2.3 移动业务本体化
为了能够进行移动业务知识的本体化表示,我们将本体划分为:
(1) 知识类:知识类主要用于定义结构化知识的知识类型,该类型使用本体进行表示。
(2) 属性:属性主要用于描述知识类具有的属性。
(3) 关系:关系主要用于描述知识类和知识类、个体和个体之间的关系。
(4) 对象:对象对应于知识结构化中的知识,即一个类中的具体实例。
(5) 约束:约束主要用于约束类和属性。如属性的取值只能是正整数等。
以上几种本体的内容相互协作,建立知识的结构化表示和知识之间的关联关系表示,通过知识的关联关系,可以支持正向和反向的双向查找。
根据之前对移动业务知识的分类体系梳理,确定移动业务分为一、二级树形结构作为本体的域 (即大类、父类) 和类型 (即小类、子类),7大类模板作为本体的框架 (即描述一个模板所需要的各个知识要素<Property>点),具体的知识点作为本体的实例 (即具体的移动业务)。
设计出一类资源的描述结构化知识,具体包括以下内容。
(1)各类资源的分类结构,形成以isa和part-of关系为主干的资源组织层次结构。
(2)各类资源类的property列表,以及properties之间的逻辑公式。
(3)资源类别与实际资源之间的连接关系、约束,支持今后的精确搜索。如图3所示,定义了移动4G终端Schema,其中,
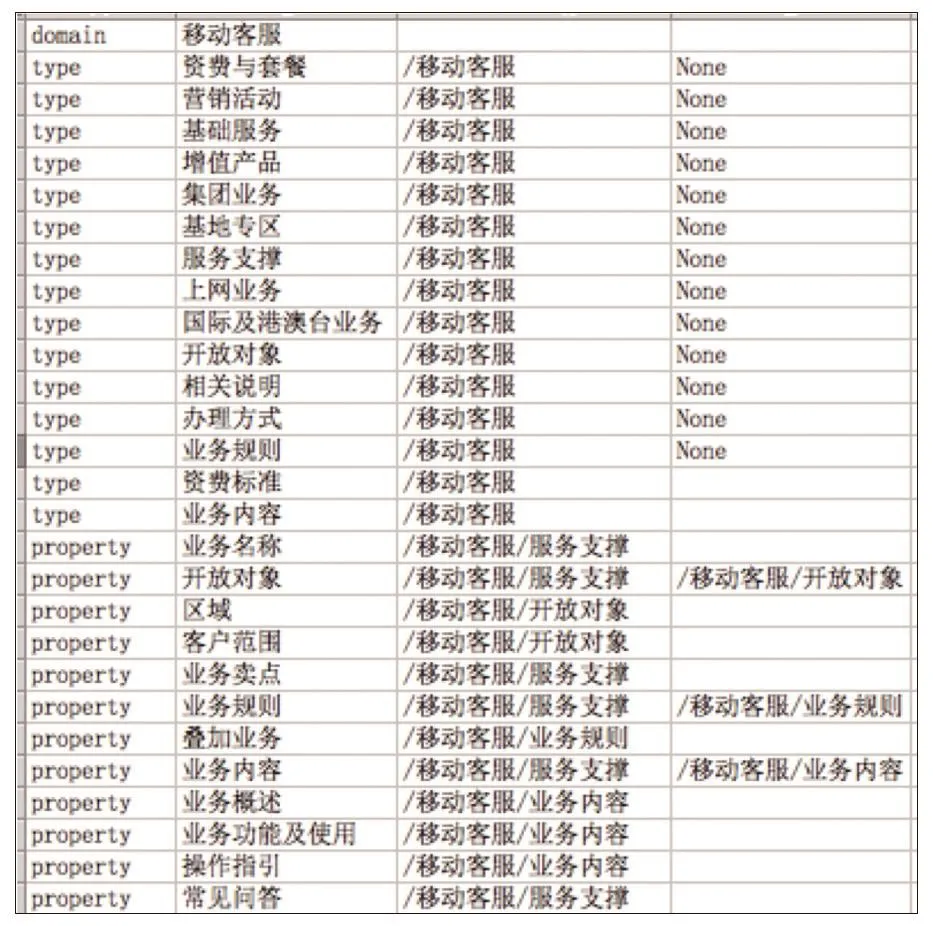
图3 移动4G终端本体Schema
Domain是“/移动客服”,“/移动客服/4G终端”的Type是“/移动客服/服务支撑”,它的Property的取值是“4G终端”。
2.3 智能应答系统研究及实现
2.3.1 智能应答系统实现
整个系统流程如图4所示。
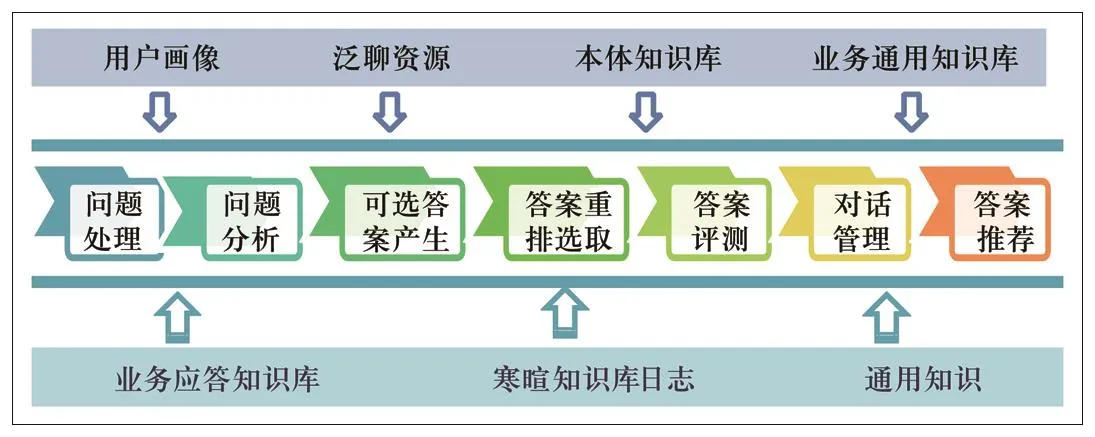
图4 智能应答系统框架
智能应答系统主要包括预处理纠错模块、问题分析模块、检索模块、推荐模块、情感分析模块、日志学习模块。整个过程包括Query预处理、索引、反馈3个过程。
2.3.1.1 预处理和问题分析过程
主要包括纠错模块和Query分析模块。纠错模块主要处理当用户敲击字符时,可能会产生的一些点击错误或者误操作,如直接输入拼音等,纠错模块将根据一系列算法对用户的Query进行纠错处理,生成标准的中文内容。
Query分析模块主要通过分类器识别、分析用户问题的意图。区分用户问题是移动业务咨询还是闲聊类问题。移动业务中,用户问题是简单问题还是复杂问题,问题中有哪些移动业务相关的专有名词、是查询业务还是要办理业务等。
在Query分析模块中,使用基于词向量的卷积神经网络模型对用户意图进行分类。其中词向量技术主要用于解决文本表示的问题,而卷积神经网络实现文本特征的删选和构建分类模型。我们选择的向量化方法是Google在2013年提出word2vec。选择word2vec的原因一方面是因为他相比其它向量表示方法使用起来更加高效,另外同LSA等经典模型相比,word2vec利用了词的上下文,语义信息更加地丰富。具体的词向量训练过程中,使用的数据包括移动客服日志和通用社交网络的语料,我们使用jieba分词和gensim的word2vec训练生成了300维的词向量。在分类模型的建立上,我们选择使用的是卷积神经网络CNN。CNN最大的优势在特征提取方面。由于CNN的特征检测层通过训练数据进行学习,避免了显示的特征抽取,而是隐式地从训练数据中进行学习;再者由于同一特征映射面上的神经元权值相同,所以网络可以并行学习,这也是卷积网络相对于神经元彼此相连网络的一大优势。总结一下相比于传统的Randomforest或是Xgboost等经典分类模型,CNN具有发现更多难以察觉的局部特征的能力,而不是像传统的方法最终的结果始终要受到特征工程好坏的限制。
2.3.1.2 索引过程
经过解析的Query首先经过Cache模块,Cache模块通过一个分布式的内存数据库实现,数据库中存储一些常用用户问题和标准问题的问答对,主要解决用户最常用的问题。例如“查流量”、“查话费”等。模板模块通过在分布式索引系统中配置了一些用户常用问法,来解决用户常见问题。检索模块主要根据Query分析模块分析得到的词,去分布式索引库中检索Query相关的问题。与此同时,为了更精准的理解用户以及扩大知识范围,Query通过推荐模块对用户进行相应的推荐,推荐模块通过业务逻辑树实现分层次的业务推荐。另外为了更好的完成与用户的会话信息,系统还会对用户Session进行维护,使之能够实现业务与操作的自动补全。
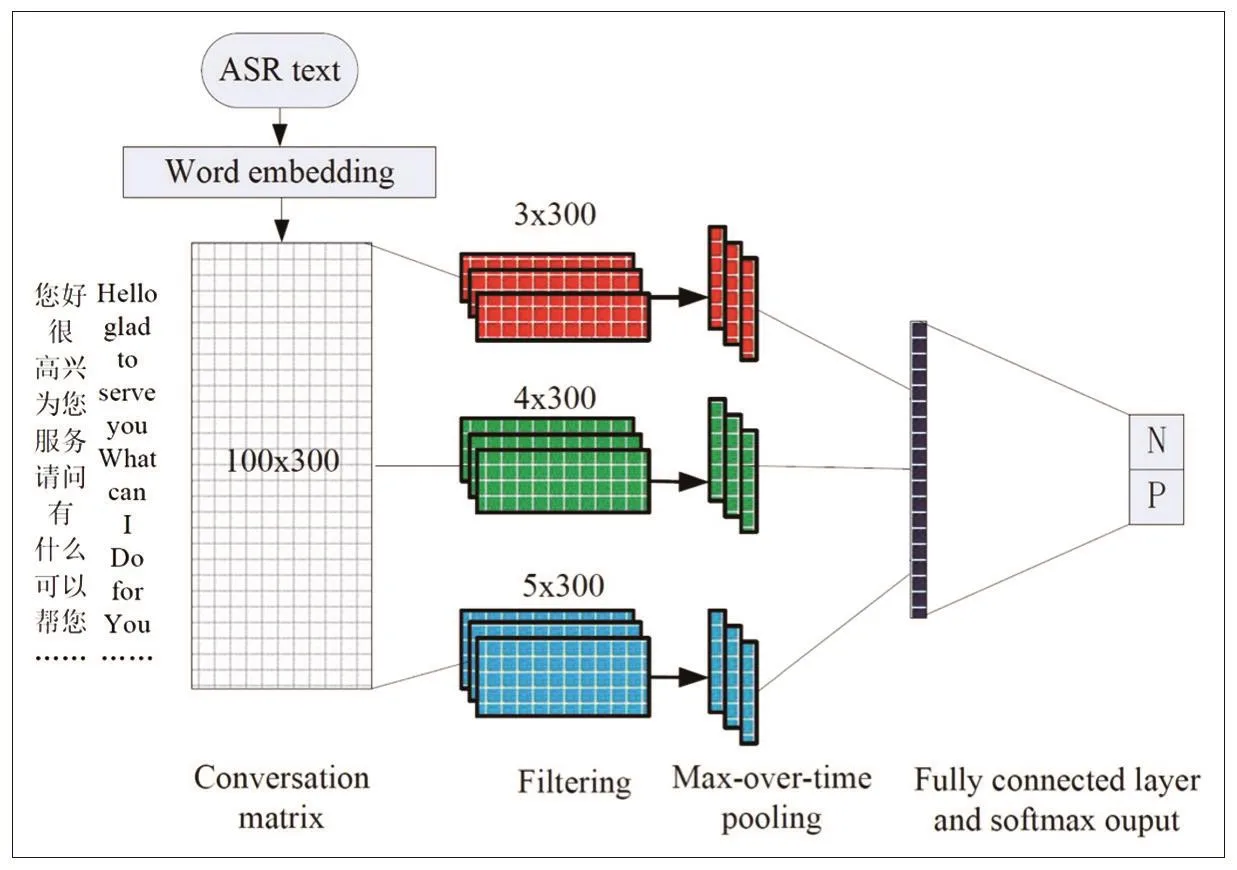
图5 卷积神经网络分类器
系统在完善业务相关问答的同时,也完成了对针对非业务问题的对话模块,可以通过分布式索引对一些基本知识进行检索。基于机器学习技术的情感分析模块可以对用户的情感进行判断,使系统能人性化的对用户的投诉等问题进行针对性的回答。
2.3.1.3 反馈过程
定期对日志进行自动化的解析,并对问答进行分析,通过机器学习算法对用户的问答进行训练和测试,以优化自动问答系统的回答准确率。
2.3.2 智能应答创新点
2.3.2.1 精准回答
为了实现精准回答,智能应答系统使用多层检索结构保证返回结果的准确性,首先通过分布式的内存数据库将用户常用问题进行检索,之后使用分布式多用户的全文搜索引擎作为搜索服务器以实现用户Query的高级检索,检索系统中索引了标准问题问答以及常见的用户问法Pattern,保证了系统给出答案的准确性。
2.3.2.2 上下文理解
系统通过用户ID维护对话Session,自动记录用户的相关信息,如要处理的业务以及要进行的操作,在Session总可以实现对用户业务和操作的自动补全。此外还包括对话上下文理解、对话流控制。完成对话内容的主题,观察跳转网络构建,由用户多观察输入激活,完成主题内容之间的跳转,自动实现对话内容理解与对话流控制。同时具有多用户状态管理功能,维护多用户对话记录上下文,追踪和控制多用户之间不同的状态。
2.3.2.3 智能推荐
为了使系统更加多样化的给出答案,系统对Query进行了推荐,该模块通过处理用户的问询,结合用户之前的提问内容,补全上下文信息,结合关键词匹配技术,为用户提供语义相关、多维度的移动业务,实现推荐信息最大化。同时开通了以业务逻辑树为主体的推荐平台,该平台通过提取业务关键词之间的逻辑关系,建立业务之间的多层分支结构,为推荐平台多维度、精细化语义匹配推荐算法的实现提供基础。
2.3.2.4 愉快聊天
系统通过已有数据进行特征提取,找到表示具有情感倾向性的特征词,通过机器学习方法对大量数据进行建模,训练模型,判断Query的情感倾向,以此判断当前用户的情感倾向性,如高兴、愤怒等,对用户进行针对性的回答。此外,系统通过分布式索引系统对基本知识如成语古诗等进行存储,支持用户的检索。
2.3.3 智能应答接口实现
智能应答系统的接口采用的是Http服务的方式,可以灵活的供各个平台调用,流程是由各个平台发送用户问题到本系统,本系统返回结果,问题与结果是1对N的,其中:
@ N=1时候,系统返回的是可信的。
@ N>1时候,系统返回多个Q-A对,选择第一个作为答案。
调用方式:
http://xxx.xxx.xxx.xxx/chatxx.php?q= 问题&uid=用户ID &b=品牌&l=地域&c=渠道。
其中:q=用户问题。uid=一个用户的终身ID。
3 结束语
3.1 主要贡献
智能客服是客服业务发展的必然趋势,构建好智能客服是一项十分艰难的工作。本文以数据为主线,按照数据流向将工作分为两部分。
(1)移动业务知识整理是数据产生的源头,该部分工作的主要贡献在于规范化数据的层次结构和规范化数据的描述方式。
(2)智能应答是数据的使用方,该部分工作的主要贡献在于通过搜索、规则、上下文管理等技术手段将数据以一问一答的方式提供给移动客户,方便客户进行查询、办理、咨询和投诉,同时,还提供寒暄、推荐等功能,提升用户粘度。
3.2 应用成果
目前,智能客服系统已经在中国移动线上部署运营。
客服知识库完成在中国移动客服基地的部署使用,涵盖全网一级知识点和全部智能应答知识点,很好地辅助移动客服人员回答各类业务问题。
智能应答完成了全国31个省近百个渠道(微信、短信、APP等)的上线及运营工作,月访问量超过6 000万,方便客户更好的了解自己的移动套餐、资费等消息,大大地增加客户的满意度。
3.3 下一步工作研究工作
(1)客服知识组织方面:进一步提高知识点自动结构化的准确率,减少人工审核的成本;实现自动化的关联分析,完善知识组织管理流程,实现知识点全生命周期的监控和管理。
(2)智能应答方面:不断扩大智能客服系统应用范围,搜集更多的用户交互日志,使用深度学习等先进算法分析、挖掘日志信息,从而提升系统的召回率和准确率;研究10086人工客服的语言特点,进一步优化上下文对话算法,提升用户粘度。
AbstractAccording to the characteristics of China mobile customer service's knowledge website, SMS and other self-service channels, we study thoroughly customers' language features and recognize the semantic of customers' natural language expression. On this basis, we make a wise matching between the customer questions and answers, and can reply customer's question correctly based on the service scenarios'characteristics. Build a China Mobile customer service knowledge classification system, which is used to provide data support for intelligent customer service; Research and implement an intelligent response system, which is used to understand users' intent, reply to the users' questions precisely, and recommend timely related issues to the user to enhance the users' satisfaction
Keywordsintelligent customer service; ontology; rule; search engine
Research and implement of China Mobile intelligent customer service system
HU Min, FENG Jun-lan, WANG Yan-meng, SHAN Yun-xiang
(China Mobile Research Institute, Beijing 100053, China)
TN929.5
A
1008-5599(2017)10-0039-06
2017-09-18
* 中国移动集团级一类科技创新成果,原成果名称为《全网知识库及智能应答系统研究与开发》。
