基于术语长度和语法特征的统计领域术语抽取
2017-10-17刘里肖迎元
刘里,肖迎元
(1.天津理工大学 计算机视觉与系统省部共建教育部重点实验室,天津 300384; 2.天津理工大学 天津市智能计算及软件新技术重点实验室,天津 300384)
基于术语长度和语法特征的统计领域术语抽取
刘里1,2,肖迎元1,2
(1.天津理工大学 计算机视觉与系统省部共建教育部重点实验室,天津 300384; 2.天津理工大学 天津市智能计算及软件新技术重点实验室,天津 300384)
针对领域术语抽取中含字长度较大的术语被错误切分的问题,本文提出一种基于术语长度和语法特征的统计领域术语抽取方法。本方法在利用机器学习抽取候选术语时,加入基于术语长度和语法特征的约束规则;在使用统计方法确定候选术语的领域性时,充分考虑词长比这一概念的重要性,将其作为判断术语领域性的重要权值。实验表明,提出的方法能够正确抽取含字长度较大的领域术语,抽取结果的准确率和召回率相比以往的方法有所提高。
自然语言处理; 术语抽取; 支持向量机; 术语长度; 语法特征; 词长比; 领域相关性; 领域一致性
Abstract:A statistical domain terminology extraction method based on word length and grammatical feature is proposed to resolve the incorrect segmentation of long terminology. Constraint rules based on word length and grammatical feature are added in when machine learning is utilized to extract candidate terminology. When a statistical method is used to determine the domain of candidate terminology, the importance of the concept of word length ratio is fully considered and is used as an important weight for judging the terminology domain. The experiment shows that long terminology can be correctly extracted through this method. Moreover, the precision and recall rate of the proposed extraction method are superior to those of traditional methods.
Keywords:natural language processing; terminology extraction; support vector machine; word length; grammatical feature; word length ratio; domain relevancy; domain consensus
术语是在特定专业领域中一般概念的词语指称[1]。领域术语抽取在自然语言处理领域有广泛的应用,是文本信息处理的重要基础,广泛应用于本体构建、文本挖掘、潜在语义分析等领域。现有的术语抽取方法可以分为三类:基于语言学的方法、基于统计的方法和混合方法。
基于语言学的方法主要通过语义词典、语言规则或者浅层解析技术来获取术语。常见的技术有基于知网、同义词词林[2]、领域词库[3]或者语序位置特征[4-5]抽取术语等。由于基于语言学知识的抽取方法主要是依靠模式匹配,存在以下三点不足:1)依赖人类的语言学知识,相似的问题不同的人处理方法不一样,导致处理结果不一致;2)效果与具体语种相关,目前该方法对英语等西方语言更适合一些;3)依赖规则或模板的质量,“精密”的模式需要语言学专家的参与,耗费大量的人力。
基于统计的方法是利用术语在语料中的统计信息进行抽取。常见的方法有词频逆文档频率(term frequency- inverse document frequency,TF- IDF)术语抽取算法[6]、C- value方法[7]、基于条件随机场的方法[8]、基于互信息和似然度的方法[9]、结合最大似然估计和k- means的抽取方法[10]等。这一类方法由于没有过多考虑语言学规则、语义信息,不受语言类型及句型的限制,所以实现简单,系统的健壮性较好,适用于各领域。但是此类方法仍然存在以下三点不足:1)所用信息数据粒度较粗,使得低频词不易提取,经常会提取到意义不完整的字符串,准确率不高;2)需要大规模的训练语料库支持,模型的训练效果直接依赖于语料的规模;3)需要处理大量的特征数据,对计算时间和空间的要求较高。
将语言学和统计方法结合起来,则能有效地改善术语抽取的性能,这就是混合方法的优势。例如:结合低频词检测和维基百科的方法、结合决策树与关键词共现信息的方法等[11-12]。
为了进一步提高领域术语抽取效果,本文提出了一种新的混合抽取方法,在统计方法的基础上结合术语长度信息和语法特征,能够更有针对性的抽取字数较多的领域术语。
1 术语抽取的理论依据及流程
1.1 术语抽取的理论依据
术语抽取的一个重要问题是候选术语抽取(包含未登陆词识别)。机器学习工具能够以较高的自动化程度抽取候选领域术语。然而,使用没有领域词典支持的分词工具,对含字长度较大的领域术语难以做出正确切分,这就使机器学习的抽取效果受到了限制。本文为了协助候选术语抽取工作,将术语长度和语法特征的统计结论应用到机器学习阶段。
研究术语系统中的用字、用词情况,能对术语抽取工作提供有用的计量参照。其中一种用字情况的统计称为术语含字长度,定义为术语包含的字数。目前,对术语含字长度的相关统计数据表明,领域术语中含字长度较大的术语占较多数:在研究人员所统计的语料库中,取值不小于4的术语数量占术语总数的比重超过80%[13]。常见词的含字长度集中在2~4,领域术语常常由多个相邻的词语组合而成。本文将此作为关于术语长度信息的统计结论。
对含字长度2以上的术语进行切分与词性标注后,发现非语素词、语气词和状态词几乎没有出现过,而叹词、成语、拟声词、代词、处所词和标点符号也极少出现(术语中的英文字符串可邻接或包含特定标点)。术语第一个词很少是助词、连词、后接成分,术语末尾的词很少是前接成分、方位词、连词和助词。另外,包含名词、动词、量词、后接成分、习用语、简称或英文单词的术语占了99%以上[14]。本文将此作为关于术语语法结构的统计结论。
将上述统计结论归结为如下机器学习可利用的约束规则,描述为
1)术语中不包含非语素词、语气词、状态词、叹词、成语、拟声词、代词、处所词和标点符号(英文字符串可邻接或包含特定标点);
2)术语不以助词、连词、后接成分开头;
3)术语不以前接成分、方位词、连词、助词结尾;
4)术语中至少包含一个名词、动词、量词、后接成分、习用语、简称或英文字符串;
5)对符合条件1)~ 4)的词语连接上下文,组合成新词,且确保新词符合条件1)~4),结合机器学习的语言规则对新词继续进行识别。
利用机器学习抽取候选术语,并加入了约束规则,目的是在没有领域词典支持的情况下达到较好的候选术语抽取效果。
候选术语需要进一步过滤才能得到最终的术语抽取结果。在语料库中,含字长度较大的领域术语容易成为低频词,不容易被统计方法获取到。本文利用提出的词长比的概念,提升含字长度大的术语的领域性权重,再结合经典的领域性算法,就能有效的提取出含字长度较大的领域术语,最终提高领域术语抽取的总体效果。
1.2 术语抽取的流程
本文术语抽取的基本流程是:利用支持向量机(support vector machine,SVM)结合约束规则在目标语料中抽取出候选术语集,然后利用结合词长比概念的领域性过滤得到最终结果。流程如图1所示,需要说明的是:
1)本文方法的输入是领域语料库,输出是领域术语集。其中领域语料库包括训练语料库、目标语料库和用于领域性过滤的平衡语料库。目标语料库由单个领域的文档组成,平衡语料库为了体现领域术语在领域文本与非领域文本中分布的差别,由多个不同领域的语料库组成。
2)输入的语料库都行进了预处理工作。预处理包括标准化处理、分词与词性标注。标准化处理是大多数中文信息处理的基础性工作,本文是指将语料库中的无用成分去除,仅保留纯文本。训练语料库与平衡语料库都包含正确的领域术语标注结果。
3)本文使用了文献[15]中的SVM模块进行机器学习。SVM训练的结果是一系列的语言规则。
4)使用SVM训练得到的语言规则对目标语料库进行候选术语抽取时,将本文1.1节归结的约束规则结合到语言规则中,提高候选术语抽取的效果。
5)对候选术语进行领域性过滤时,利用了词长比概念,提升含字长度大的术语的领域性权重,过滤效果更好。

图1 术语抽取流程Fig.1 Terminology extraction process
相对于常见的术语抽取方法,本文利用了术语含字长度、术语语法结构特征,并根据术语含字长度特征提出了词长比的概念。在抽取候选术语、确定术语领域性时充分利用了这几种理论,提高术语抽取效果。
2 候选术语抽取
选术语抽取由标准化处理、分词与词性标注、利用SVM和约束规则抽取候选术语3个步骤组成。
2.1 标准化处理
语料库预处理包括标准化处理,分词与词性标注。首先进行标准化处理,将选定的语料库标准化为统一的格式。本文对标准化的要求是:1)仅保留文本。去除图片、超链接、公式、HTML语言、空行等不需要的元素;2)只使用全角标点符号,将半角标点用全角标点替换;3)文本编码采用UTF- 8。
下文是一段文本经过标准化处理后的片段。以这段文本为例,介绍候选术语抽取工作:
12月31日,瑞星全球反病毒监测网率先截获一个主要偷窃网络游戏“传奇”玩家密码的木马病毒,并命名为“少女心事”(Trojan.PSW.Legend.Flash)病毒。据瑞星反病毒工程师介绍,该病毒会伪装成微软播放器可以播放的电影文件,并且会用很有诱惑力的名字比如“少女心事”、“爱情故事”等等,来欺骗用户下载运行。等用户点击运行后会显示 “意外错误,系统找不到Flash播放插件”,这时候用户就已经被感染。
2.2 分词与词性标注
使用NLPIR汉语分词系统(又名ICTCLAS 2016)[16]对文本进行分词与词性标注。下文是部分切分结果:
并且/c 会/v 用/p 很/d 有/vyou 诱惑力/n 的/ude1 名字/n 比如/v "/n 少女/n 心事/n "/n、/wn "/n 爱情/n 故事/n "/n 等等/udeng
2.3 利用SVM和约束规则抽取候选术语
该模块使用SVM进行候选术语抽取,即将SVM分类器作为术语的初级判别器。输入是经过分词和词性标注的语料,输出的是进行了候选术语标注的语料。SVM采用的语言规则由400个文档训练得到,并结合了本文1.1节的约束规则1)~ 5)。示例文本经过SVM抽取,得到了候选术语抽取结果(候选术语以“/term”标识),如下文所示:
12月/t 31日/t,/wd 瑞星全球反病毒监测网/n/term 率先/d 截获/v 一个/mq 主要/d 偷窃/v/term 网络游戏/n/term "/n 传奇/n/term "/n 玩家密码/n/term 的/ude1 木马病毒/n/term,/wd 并/cc 命名/v 为/p "/n 少女心事/n/term "/n(/wkz Trojan.PSW.Legend.Flash/x)/wky 病毒/n/term。/wj 据/p 瑞星反病毒工程师/n/term 介绍/v,/wd 该/rz 病毒/n/term 会/v 伪装/vd 成/v 微软播放器/n/term 可以/v 播放/v/term 的/ude1 电影文件/n/term,/wd 并且/c 会/v 用/p 很/d 有/vyou 诱惑力/n/term 的/ude1 名字/n/term 比如/v "/n 少女心事/n/term "/n、/wn "/n 爱情故事/n/term "/n 等等/udeng,/wd 来/vf 欺骗/v 用户/n/term 下载/v/term 运行/vi。/wj 等/v 用户/n/term 点击/n 运行/vi/term 后/f 会/v 显示/v "/n 意外/a/term 错误/n/term,/wd 系统/ad/term 找/v 不/d 到/v Flash/x 播放插件/n/term "/n,/wd 这时候/rzt 用户/n/term 就/d 已经/d 被/pbei 感染/v/term。/wj
可见,使用SVM结合约束规则在“电脑病毒”领域进行候选术语抽取,能够将大部分含字长度较大的候选领域术语准确的抽取出来,一定程度上修正了由于没有领域词典支持而对目标领域语料库产生的错误切分与标注现象。
此处产生的候选术语,包含大多数的领域术语,同时还包含部分非领域术语。如何将领域术语过滤出来,得到更精确的术语抽取最终结果,需要使用领域性过滤算法进行进一步处理。
3 基于词长比的术语领域性过滤算法
常用的领域性过滤算法,仅考虑术语的分布信息,对于含字长度较大的术语,由于这类术语常常带有词频低等语法特性,效果并不理想。词长比过滤算法在确定候选术语的领域性时,充分考虑术语词长比的重要性,将其作为领域性算法的重要权值。词长比过滤算法的三个重要参数是词长比、领域相关性和领域一致性。
3.1 词长比
结合本文关于术语含字长度的统计结论与领域性算法的运算需求,本文将词长比(word length ratio,WLR)定义为术语含字长度与语料库中词语平均含字长度的比值:

(1)

根据术语含字长度的特性,候选术语的词长比越大,领域隶属度越高,成为领域术语的可能性越大。由式(1)可知,词语的含字长度越大,其对应的WLR值越高。对于大部分中文语料来说,双字词占大多数,语料库中词语的平均含字长度接近2,双字词的WLR值就接近1。对于2个字以上的词,能够得到较高的WLR值;对于大量的单字词,其WLR值较小。将WLR值作为领域性的权值之一,就可以使术语长度特征在领域性中有所体现。
3.2 领域相关性
领域相关性(domain relevancy,DR)定义术语对领域的关联度。计算领域相关性,需要引入平衡语料库,利用词语在领域语料库中的概率和在平衡语料库中的概率差距来表示领域相关性。更确切的说,给定了n个领域的语料库(C1,C2,…,Cn),词语t对于语料库Ci的领域相关性定义为:

(2)
式中:tfi为词语t在语料库Ci中的词频,Cbalance-i为去除了Ci的平衡语料库,P(t|Ci)和P(t|Cbalance-i分别为t在Ci和Cbalance-i中出现的概率。其中:
(3)
式中:tfbalance-i为词语t在Cbalance-i中的词频,ni和nbalance-i分别为Ci和Cbalance-i中的文档数目。
从式(2)可以看出,如果词语在领域语料中出现的概率大于平衡语料中出现的概率,DR(t,Ci)>0,词语和该领域正相关。比如“瑞星反病毒工程师”在“电脑病毒”领域出现的概率大于在平衡语料出现的概率,其和“电脑病毒”领域正相关;相反,“名字”在“电脑病毒”领域出现的概率小于在平衡语料出现的概率,其和“电脑病毒”领域负相关。
3.3 领域一致性
领域一致性(domain consensus,DC)用来描述一个词在特定领域分布的均匀情况,这个标准对于获取高质量的领域术语起着重要作用,可以发现只在小部分文档中出现的词语。词语t在领域语料库Ci的分布情况在文档dj∈Ci的范围内可以被表示为变量DC(t,Ci),领域一致性定义为:
(4)
式中:freq(t,dj)表示词语t在文档dj中的频率。
DC的定义类似于信息熵(H(P(t,Cj)),熵H描述了t在Ci中的分布情况)。词语在语料库中分布的越均匀,也就是说词语在越多的文本中出现,DC值越高。如果词语仅在一个文本中出现,则DC=0。比如“裸奔”(指电脑在不安装杀毒软件的状态下运行)仅在一篇“电脑病毒”领域的文本中多次出现,但是在平衡语料的其他文本中没有出现,其DC=0。即使其DR值为正,也不能成为领域术语。
3.4 词长比过滤算法
词长比过滤借鉴并改进了文献[17]设计的术语相关性权值计算方法,将WLR、DR、DC三种信息结合起来计算术语的领域性(domain degree,DD)。词长比过滤算法:
DD(t,Ci)=
WLR(t,Ci)(αDR′(t,Ci)+(1-α)DC′(t,Ci))
(5)
式中:0<α<1,经过多次实验结果的对比,α取值为0.7时效果最好。WLR(t,Ci)为t在Ci中的词长比,DR′(t,Ci)和DC′(t,Ci)分别为经过标准化的DR与DC值,如下:
(6)
实际运算时,对每个候选术语分别计算WLR,DR和DC值,代入式(5)得到候选术语的领域性。
4 实验与分析
实验使用了两种语料库:官方TanCorp[18]语料库中的电脑病毒语料和从维基百科抽取到的领域网页语料库。TanCorp包含14 150个文本,其中“电脑病毒”领域包含了619个文本文件。维基百科网页语料库是一个开放领域语料库,包含“电脑病毒”领域语料,实验抽取了17 325个文本文件,其中“电脑病毒”领域包含了941个文本文件。
选择维基百科中的“电脑病毒”语料作为训练语料,进行人工术语标注,标注术语506个。TanCorp中的“电脑病毒”语料作为目标语料,TanCorp语料库作为平衡语料。对目标语料——TanCorp“电脑病毒”领域语料库进行人工标注,标注领域术语342个,以此作为参考评价试验结果。
4.1 本文方法的实验结果
采用维基百科语料库“电脑病毒”领域400个文档对SVM进行训练。将SVM使用的特征选定为词的字面描述、词性、词频和候选术语上下文信息的组合。训练完成生成一系列语言规则,再采用1.1节中的约束规则进行候选术语抽取。利用SVM抽取得到了535个候选术语。对候选术语进行词长比过滤得到最终结果。
为了说明词长比在领域性过滤中的作用,表1、2、3分别列举了DR、DC、DD值最高的10个词语。其中DR、DC的取值代表了未考虑词长比的过滤效果,而DD取值代表了加入词长比要素的过滤效果。需要说明的是:1)表中显示的结果已经经过四舍五入;2)经统计,TanCorp语料库词语的平均含字长度是1.90,每个候选术语的WLR值根据这个数据计算出来。

表1 DR得分最高的10个术语
由表1和表2可见,仅仅通过计算领域相关性和领域一致性,并没有使这个领域大多数典型的病毒名称得到较高的权值。由于这些术语的含字长度都较大,词长比赋予了它们较高的权值。从表3的结果可以看出,考虑到词长比因素之后,典型的“电脑病毒”领域的术语被正确的抽取了出来。
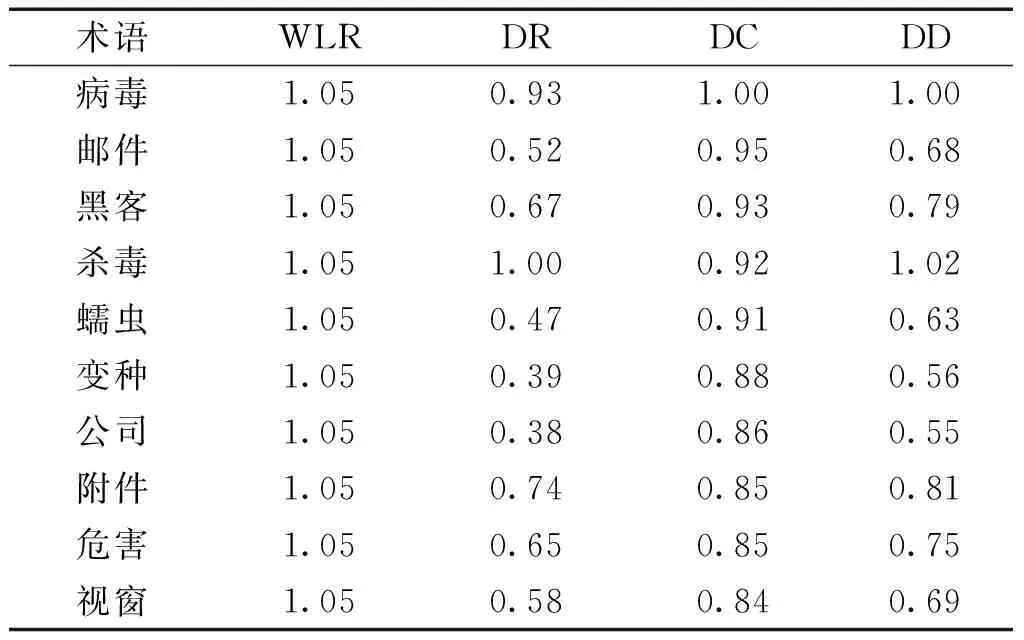
表2 DC得分最高的10个术语

表3 DD得分最高的10个术语
4.2 实验效果对比分析
将本文提出的术语抽取方法与常用的术语抽取方法进行比较,使用准确率P和召回率R作为指标进行评价:
(7)
式中:T1为抽取正确的术语数量,T2为抽取到的术语总数,T3为语料库中人工标注的术语总数。
实验对比了几种常见的术语抽取方法,包括基于语言特性统计模型(以领域相关性DR和领域一致性DC为抽取标准,简称DR+DC)的方法,互信息结合似然度的方法[9]和C- value方法[7],结果如表4所示。
在经过多次实验对比并参考相关研究之后,在基于语言特性统计模型方法的抽取实验中,将DR与DC的阈值分别为设定为0.3和0.4;参考这一标准,基于词长比过滤的抽取实验中,领域性DD阈值设置为0.3。
表4几种术语抽取方法的准确率和召回率比较
Table4Precisionandrecallcomparisonofterminologyextractionmethods

方法抽取总数抽取正确标注准确率/%召回率/%本文方法23921434289.562.6DR+DC21314834269.543.3互信息+似然度20914034267.040.1C-value19613334267.938.9
从表4的实验结果可以看出,本文提出的方法在与DR+DC方法、互信息+似然度方法和C- value对比中,准确率和召回率均有提高。术语长度信息和语法特征在基于统计的术语抽取中起到了显著作用。表5是实验中几种方法产生的部分错误结果。通过分析错误结果,可以得知具体是哪些细节影响了抽取效果。
表5几种方法的部分错误结果
Table5Partofmistakesappearinterminologyextractionmethods
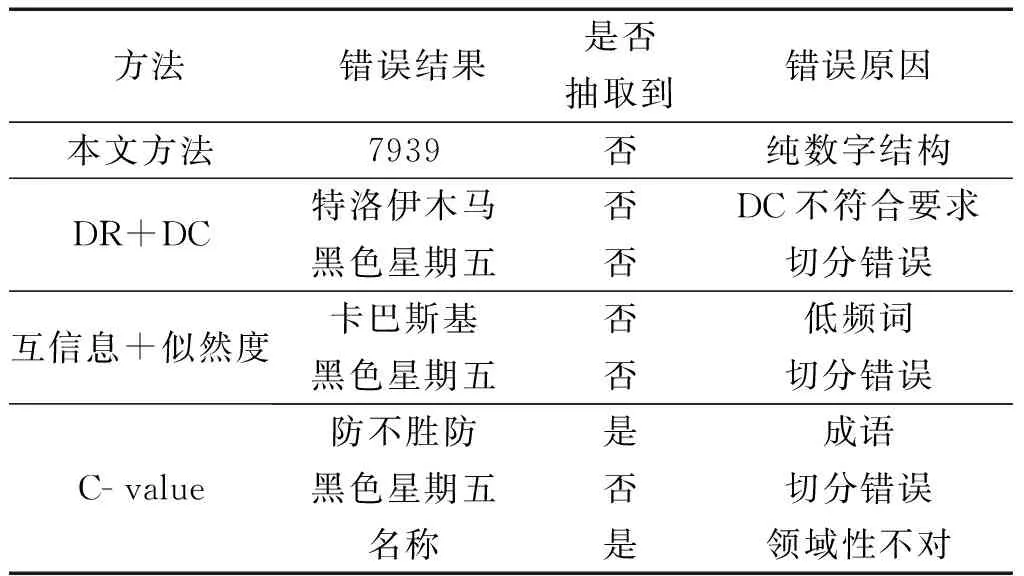
方法错误结果是否抽取到错误原因本文方法7939否纯数字结构DR+DC特洛伊木马黑色星期五否否DC不符合要求切分错误互信息+似然度卡巴斯基黑色星期五否否低频词切分错误C-value防不胜防是成语黑色星期五否切分错误名称是领域性不对
对表5的错误结果进行分析,得到以下结论:
1)本文的术语抽取方法有较高的准确率与召回率,其错误结果大多产生于候选术语抽取阶段,抽取规则没有覆盖到的内容。例如,由于纯数字结构,“7939”没有被作为候选术语保留下来。
2)基于语言特性统计模型抽取术语,只考虑术语的分布规律,准确率不理想。“特洛伊木马”的DC值没有满足阈值,只有进行词长比过滤才能得以保留,可见词长比的重要性;“黑色星期五”则是由于没有约束规则支持,在预处理阶段没有被正确切分出来。
3)互信息+似然度的方法对低频词的处理效果不理想。本实验采用的电脑病毒语料库存在部分低词频术语,比如“卡巴斯基”等,不能被成功抽取;由于没有约束规则支持,“黑色星期五”又一次出现了切分错误。
4)C- value方法因为没有约束规则支持,导致“防不胜防”类似的成语没有被去除;“黑色星期五”仍然被错误切分;同时,这种方法也没有经过机器学习步骤对术语的多个特征进行识别,抽取到了“电脑病毒”领域外的术语,比如“名称”。
综合以上,本文采用的基于术语长度信息和语法特征的约束规则,以及词长比过滤方法,在抽取领域术语的实验中发挥了显著作用。抽取结果有较高的准确率和召回率,优于其他几种常用的术语抽取方法。
5 结论
1)本方法将基于术语长度和语法特征的统计结论作为约束规则应用到机器学习中,再将词长比的概念结合经典的领域性算法,提升含字长度大的术语的领域性权重,能够较准确的抽取含字长度较大的候选领域术语。
2)以往的方法需要领域词典的支持才能对含字长度大的术语做出正确切分,然而大多领域并没有词典支持,本文提出的词长比的概念能够有效的应对这种情况。本方法能够更广泛的应用于多种领域的术语抽取中。
3)本方法在机器学习阶段添加的是统计得到的约束规则,规则的完善程度决定了抽取质量。规则的完善是逐步的,目前实验中也发现了规则没有覆盖到的情况,比如约束规则对纯数字结构的术语不能做出正确的识别。
在接下来的研究中,将进一步完善约束规则,提高候选术语抽取效果;同时,还会测试词长比概念与其他统计抽取方法结合产生的效果,探索最合适的方法组合。
[1] 于欣丽, 全如, 粟武宾, 等. GB/T 10112-1999, 术语工作原则与方法[S]. 北京: 国家质量技术监督局, 1999. YU Xinli, QUAN Ru, SU Wubin, et al. GB/T 10112-1999, Terminologywork- principles and methods[S]. Beijing: General Administration of Quality Supervision, Inspection and Quarantine of the People′s Republic of China, 1999.
[2] 曾聪, 张东站. 基于同义词词林和《知网》的短语主题提取[J]. 厦门大学学报:自然科学版, 2015, 54(2): 263-269. ZENG Cong, ZHANG Dongzhan. Phrase subject extraction based on synonyms and HowNet[J]. Journal of Xiamen University: natural science, 2015, 54(2): 263-269.
[3] KANG N, SINGH B, BUI C, et al. Knowledge- based extraction of adverse drug events from biomedical text[J]. BMC bioinformatics, 2014, 15(1): 64-64.
[4] SHAREF N M, NOAH S A, MURAD M A A. Linguistic rule- based translation of natural language question into sparql query for effective semantic question answering[J]. Journal of theoretical and applied information technology, 2015, 80(3): 557-575.
[5] 张莉, 刘昱显. 基于语序位置特征的汉英术语对自动抽取研究[J]. 南京大学学报: 自然科学, 2015(4): 707-713. ZHANG Li, LIU Yuxian. Research on automatic Chinese- English term extraction based on order and position feature of words[J]. Journal of Nanjing University: natural sciences, 2015(4): 707-713.
[6] BOLSHAKOVA E, LOUKACHEVITCH N, NOKEL. Topic models can improve domain term extraction[C]//Proceedings of the 35th European Conference on Advances in Information Retrieval. Berlin, 2013: 684-687.
[7] FRANTZI K, ANANIADOU S, MIMA H. Automatic recognition of multi- word terms: the C- value/NC- value method[J]. International journal on digital libraries, 2000, 3(2): 115-130.
[8] ESPINOSA A L, SAGGION H, RONZANO F. TALN- UPF: Taxonomy learning exploiting CRF- based hypernym extraction on encyclopedic definitions[C]//Proceedings of the 9th International Workshop on Semantic Evaluation (SemEval 2015). Denver, Colorado, 2015: 949-54.
[9] PANTEL P, LIN D. A statistical corpus- based term extractor[M]. Berlin, Springer, 2001: 36-46.
[10] GELBUKH A, SIDOROV G, LAVIN V E, et al. Automatic term extraction using log- likelihood based comparison with general reference corpus[J]. Natural language processing and information systems, 2010: 248-255.
[11] ITTOO A, BOUMA G. Term extraction from sparse, ungrammatical domain- specific documents[J]. Expert systems with applications, 2013, 40(7): 2530-2540.
[12] LOPEZ P, ROMARY L. HUMB: Automatic key term extraction from scientific articles in GROBID[C]//Proceedings of the 5th International Workshop on Semantic Evaluation. Los Angeles, California, 2010: 248-251.
[13] 李芸, 王强军. 信息技术领域术语字频、词频及术语长度统计[C]//第一届学生计算语言学研讨会论文集. 北京, 2002: 268-274. LI Yun, WANG Qiangjun. Character frequency, word frequency and length of term in the field of information technology[C]//Proceedings of the First Student Workshop on Computational Iinguistics (SWCL 2002). Beijing, 2002: 268-274.
[14] 周浪, 张亮, 冯冲, 等. 基于词频分布变化统计的术语抽取方法[J]. 计算机科学, 2009, 36(05): 177-180. ZHOU Lang, ZHANG Liang, FENG Chong, et al. Terminology extraction based on statistical word frequency distribution variety[J]. Computer science, 2009, 36(05): 177-180.
[15] CUNNINGHAM H, BONTCHEVA K, TABLAN V, et al. GATE[EB/OL]. Sheffield, The University of Sheffield, 2016. [2016-05-11]. https://gate.ac.uk/.
[16] 张华平. NLPIR汉语分词系统[EB/OL]. [2016-05-11]. http://ictclas.nlpir.org/.
[17] BRUNZEL M, SPILIOPOULOU M. Domain relevance on term weighting[M]. Berlin, Springer, 2007: 427-432.
[18] 谭松波, 王月粉. 中文文本分类语料库-TanCorpV1.0[EB/OL]. [2016-05-11]. http://www.datatang.com/data/11970.
Astatisticaldomainterminologyextractionmethodbasedonwordlengthandgrammaticalfeature
LIU Li1,2, XIAO Yingyuan1,2
(1.Key Laboratory of Computer Vision and System, Ministry of Education, Tianjin University of Technology, Tianjin 300384, China; 2.Tianjin Key Laboratory of Intelligence Computing and Novel Software Technology, Tianjin University of Technology, Tianjin 300384, China)
10.11990/jheu.201605037
http://www.cnki.net/kcms/detail/23.1390.u.20170427.1511.084.html
TP181
A
1006- 7043(2017)09- 1437- 07
2016-05-12. < class="emphasis_bold">网络出版日期
日期:2017-04-27.
国家自然科学基金项目(71501141,61301140);天津市科技特派员项目(15JCTPJC63800).
刘里(1983-), 男, 讲师,博士; 肖迎元(1969-), 男, 教授, 博士生导师.
刘里, E- mail: llwork@yeah.net.
本文引用格式:刘里,肖迎元. 基于术语长度和语法特征的统计领域术语抽取[J]. 哈尔滨工程大学学报, 2017, 38(9): 1437-1443.
LIU Li, XIAO Yingyuan. Extraction of terminology from statistical domains on the basis of word length and grammatical feature[J]. Journal of Harbin Engineering University, 2017, 38(9): 1437-1443.
