基于现代汉语词典的情感词语识别研究
2017-10-13赵军民
赵军民,李 芳
(1.河南城建学院 计算机与数据科学学院,河南 平顶山 467036;2.景德镇陶瓷大学,江西 景德镇 333403)
基于现代汉语词典的情感词语识别研究
赵军民1,李 芳2
(1.河南城建学院 计算机与数据科学学院,河南 平顶山 467036;2.景德镇陶瓷大学,江西 景德镇 333403)
基于《现代汉语词典》对词语的释义,提出了一种新的情感词语识别方法。该方法结合多特征线性融合和多次循环策略,利用现有的情感词典识别并构建适用于跨领域的通用情感词典。首先基于已有情感词典资源构建候选的通用情感词表,然后使用多特征线性融合的方法计算候选通用情感词表在《现代汉语词典》中的情感倾向性,并利用多次循环的策略获得最终的通用情感词表。实验结果表明,本文提出的情感词语识别方法是有效的,在Precision、Recall及F-measure等方面都取得了较好的效果。
多特征线性融合;情感词典;情感词语;情感倾向
Abstract: Based on the interpretation of the words in "Modern Chinese Dictionary", a new recognition method for emotion words is proposed. This method combines the multiple characteristic linear fusion and the multiple cycle strategy to identify and construct universal dictionary of emotion words which is suitable for the cross domain by using the existing dictionary. First, based on the existing resources of dictionary to build a candidate's general vocabulary, and then use the multi-feature linear fusion method to calculate the emotional orientation of the candidate emotion words in Modern Chinese Dictionary, and use the strategy of multiple loops to obtain the final universal emotion words. The experimental results show that the method of identifying emotion words is effective and has achieved good results in Precision, Recall and F-measure.Keywords: multi-feature linear fusion; dictionary of feelings and emotions words; emotion words; emotional tendency
词语是有情感倾向的,语言学界把这种情感倾向称之为词语的感情色彩[1-2],即词语本身所附带的表达贬义或褒义态度的色彩。在汉语词汇集中,很多词汇具有这种情感倾向,具备很强的主观感情色彩。根据情感倾向的稳定性,可以把情感词语分为通用情感词语和语境情感词语两类:通用情感词语情感倾向在语用和语义上都非常稳定,感情色彩单一且不依赖于具体语言环境;语境情感词语情感倾向在不同的语用环境中会表现出不同的感情色彩。词语情感倾向识别的对象是那些具有情感倾向的名词、形容词、动词、副词以及成语和一些习惯用语,其任务是从文本中抽取出这些情感词语。随着微博、微信及其它网络上评论文本的不断增长,迫切需要计算机对这些评论文本进行情感倾向分析,使得情感分析研究成果具有广泛的应用。如:用户评论分析,帮助人们在购买物品之前进行了解;舆情监控,对网络上的舆论信息进行收集、反馈;信息预测,根据对网络上的新闻、帖子的分析,对某一事件的未来发展状况进行预测。
研究者对情感词语进行了大量研究,主要的研究方法可以分为两类:基于情感词典的方法和基于语料库统计的方法。基于情感词典的方法以词语之间的语义相似度来识别情感词语,该类方法以已知情感极性的词语为种子集,之后利用词典(如:Hownet[3])计算被识别词语与种子词语之间语义的相似性,并以此作为判断词语情感极性的依据。朱嫣岚等[4]提出了基于Hownet的语义相似度计算方法来计算词汇语义倾向性,该方法就属于基于情感词典的情感词语识别方法。基于语料库统计的方法主要根据统计特征或语义关联特征抽取情感词语。基于语料库统计的方法又可分为无监督机器学习(unsupervised learning)的方法和基于人工标注语料库学习(artificially label corpus learning)的方法。无监督机器学习方法利用语料库中的连词信息和词语间的共现信息来识别带有情感倾向的词语。Hatzivassilolou和Mckeown[5]等人以连接信息(如:and,but,or等)作为约束条件,采用对数线性回归模型(log-linear regression models)来判断具有关联的形容词的情感倾向性是否相同。基于人工标注语料库方法先对语料库进行情感倾向性标注,然后利用词语间的搭配信息、共现信息或语义信息,来判断词语的情感倾向性。Wiebe[6]在对语料库进行标注的基础上,根据词语间的搭配关系研究文本中情感词语的倾向性。
本文根据词语的情感倾向性是否在不同语境发生变化,将情感词语分为通用情感词语和语境情感词语。在《现代汉语词典》丰富的带有情感倾向性释义的词语释义信息基础上,利用特征线性融合方法计算词语释义的情感倾向性,并采用多次循环的策略,从已有的情感词典中抽取通用情感词语,进而构建了一个跨领域的通用情感词典。
1 基于词语释义的通用情感词语识别
词语的释义一定程度上决定着词语的感情倾向性,例如“骄傲”一词,有两种不同的感情倾向性,当解释为“自豪”时是褒义词,感情倾向性为正面的,当解释为“自满”时则是贬义词,感情倾向性为反面的。而“高雅”只有“高尚,不粗俗”一种释义,只表现为褒义色彩,没有贬义感情倾向。因此,可以借助于汉语词典对词语的解释来确定词语的情感倾向性。
1.1 《现代汉语词典》词语释义的标准和特点
《现代汉语词典》[7]最新版本(第六版)共收1.3万多个单字,条目6.9万多条。《现代汉语词典》对词语进行解释时既通俗易懂,又追求准确性、简洁性和完整性[8]。准确性要求对词语解释时使用含义明确的词语表达词义,不能存在歧义。简洁性要求对词语解释时要言简意赅,用词简练,用字较少,追求通俗易懂;完整性则要求对词语的解释要全面,例如“好”在第六版《现代汉语词典》中共有17种不同释义。另外,《现代汉语词典》在对词语进行解释时有如下两个特点:一是释义句子中常使用常见、简单的否定词,且这些否定词多数情况下只修饰距离其右边最近的情感词,例如“敷衍”一词的释义是“做事不负责或待人不恳切,只做表面上的应付”;二是释义句子中含有“但”、“但是”、“只是”等转折连词,使得连词前后释义的情感倾向性相反,但要表达的含义却在连词后面的分句上,后面分句决定着其情感倾向,例如“内秀”一词的释义是“看上去粗鲁、拙笨,但实际上聪明、细心”。正是《现代汉语词典》中对词语解释遵循的标准和具有的特点,为词语情感倾向性的计算带来了一定的方便,也为《现代汉语词典》用于识别通用情感词语提供了理论基础。
1.2词语情感倾向计算
根据情感词语的情感倾向是否因语境不同而变化,可以把情感词语分为通用情感词语和语境情感词语两类。通用情感词语所有释义的情感倾向一致,不会因不同的语言环境而发生变化,如“美丽、高尚、卑鄙”等词语。语境情感词语则相反,词语在不同的语言环境中可能呈现出不同的情感倾向,如“骄傲”一词在不同的语境中呈现截然相反的褒义和贬义。根据词语在《现代汉语词典》的释义,将通用情感词语和语境情感词语从候选情感词语中区分出来,进而构建一个通用情感词典。
本文采用情感词语、转折连词、否定词等词语释义的特征,利用多特征线性融合[9]的方法基于《现代汉语词典》计算词语释义的情感倾向性。计算时,首先对词语释义进行分词,对包含转折连词释义,特征融合时为避免因前后分句情感倾向相互抵消,而造成的情感倾向性的不准确,用转折词后面的分句代替整个释义句子,然后计算词语释义中的情感词语、否定词的特征值,进而利用多特征线性融合方法求得词语释义的情感倾向。
其计算公式为:
(1)
式中:p表示该词为褒义词,pi表示第i个褒义情感词的特征值,p的取值为1;d表示该词为贬义词,dj表示第j个贬义情感词的特征值,d的取值为-1。nega表示否定词特征,如果情感词语右边没有否定词的存在,释义的情感倾向与前面情感词语的情感倾向一致,此时nega=1。否则,情感词语右边存在否定词,释义的情感倾向就会发生变化,此时nega=-1。m表示褒义词的数量,n表示贬义词的数量。SO表示利用线性融合方法求得的词语释义的情感倾向,SO>0表示该释义有褒义倾向,SO<0表示该释义有贬义倾向,SO=0表示该释义没有情感倾向。
1.3通用情感词语识别
为提高通用情感词语识别准确率,本文采用了多次循环、逐步筛选的策略,利用HowNet情感词语集等现有的情感词典作为本文的候选情感词表A,即A为现有情感词典的并集,并假设候选情感词表A中所有词语均为通用情感词语,利用多特征线性融合方法计算A表中所有词语的情感倾向性,同时构建新的通用情感词表B,B初始状态为空集,如果情感词表A和情感词表B不同,说明候选情感词表A中非通用情感词语被过滤。然后,用B代替A,重新计算情感词表A词语的情感倾向,直到候选的情感词表A和新生成的通用情感词表B相同为止。至此,新生成的B表为通用情感词。
具体实现步骤为:
Step1:利用现有的情感词典构建本文的候选情感词表A,同时构建空的通用情感词表B,B=Φ;
Step2:对于候选情感词表A每个词,利用本文方法计算其所有释义的情感倾向性,同时将所有释义都相同词语作为通用情感词语加入表B中;
Step3:比较候选情感词表A与通用情感词表B,如果相同,执行Step4;否则,用B代替A,跳转至Step2继续执行;
Step4:将新生成的通用情感词表B作为最终结果,构建本文的通用情感词典。
算法流程如图1所示。

图1 通用情感词语识别流程
2 实验及分析
2.1实验数据
为了测试本文提出的通用情感词语识别方法的可行性,分别利用台湾大学(NTUSO)、同济大学、知网(HowNet)、香港中文大学(CUHK)4个已有的情感词语库进行试验。基于《现代汉语词典》提取出在《现代汉语词典》中出现过的词语作为候选情感词表。同时,为了构建更加广泛的通用情感词典,将以上4个现有的情感词典进行综合,剔除未在《现代汉语词典》中出现的词语条目,构建了一个更为全面的情感词典,该词典共包含情感词语条目9 549个,其中有褒义色彩的4 830个,有贬义色彩的4 719个。
具体的候选词表信息如表1所示。
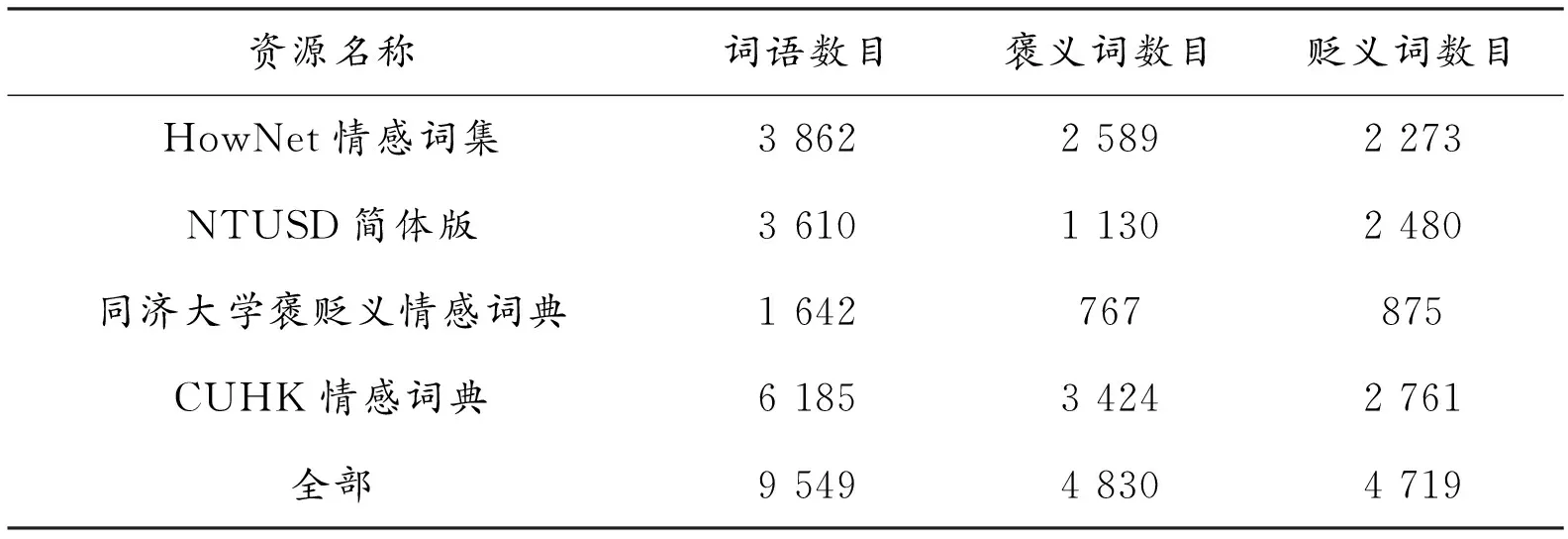
表1 不同候选情感词表情况
2.2词语释义情感倾向性分析
利用以上实验数据,分别对5种不同的情感词典进行试验,利用本文提出的方法分别在5种不同情感词典中通用情感词语的计算结果见图2。准确率(Precision)、召回率(Recall)和它们的几何平均值F度量(F-measure)是常用的算法评估指标。其计算公式为[10]:
Precision = 正确地识别为通用情感词语数目/候选通用情感词语数目:
召回率的计算公式为:Recall =正确地识别为通用情感词语数目/通用情感词语数目;
F度量的计算公式为:F-measure = 2*Precision*Recall / (Precision + Recall),F度量是Precision和Recall的几何平均值,其值越大说明算法性能越优。
本实验采用pooling评测方法,即随机抽取N个数据构成评测池(N取值为2 000),并根据给出的标准答案对实验结果进行自动评价。
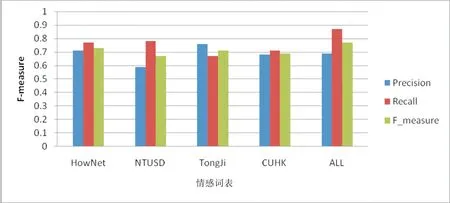
图2 基于不同情感词表的precision、recall、F-measure指标比较
由图2可以看出:基于多特征融合的情感倾向性识别方法在5个情感词表上得到的F值都超过了0.65,符合F-measure参数要求,说明本文提出的方法是有效的。其中,NTUSD词表得到的准确率为0.59,在5个词表中最低,这与词典中的噪音有很大关系。由于同济大学褒贬义情感词典的词语数目少,影响了实验效果,导致召回率为5个情感词表中最低。
本文方法综合了现有的4个情感词语词典,由于词表词语数目大大增加,致使准确率有所降低,但仅比最高的同济大学褒贬义情感词典低了0.06,但召回率和F值却有较大提高,在5个情感词表中最高,分别达到0.87和0.77。因此,本文提出的基于现有情感词典构建情感词表是可行的,为构建更加全面的通用情感词语奠定了基础。
2.3通用情感词语识别效果分析
从实验结果看,词语释义的倾向性识别存在错误。经分析,错误原因不是因为本文的方法有问题,而是有些情感词语的释义中不包含具有感情色彩的词语,即缺少情感词语特征,这样利用多特征融合的方法得出的SO=0,即词语释义的情感倾向性趋于中性。另外,候选情感词表就是错误的,也就是候选情感词表中的词不是有情感倾向的词语。为此,本文采用多次循环、逐步筛选的策略,以提高多特征融合的情感词语识别方法的准确率。
利用包含9 549个情感词语条目的综合情感词表进行实验时,Precision、Recall、F-measure及每次循环后词表中词条数目的变化情况见图3。其中,GPN表示某次循环后生成的候选情感词语词表中的词语数,VPN表示某次循环前后候选情感词语词表中不同词语的数目。
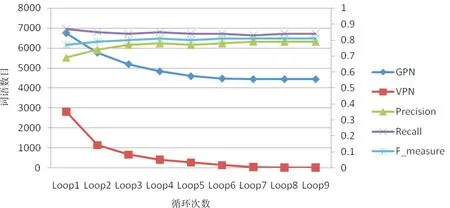
图3 循环过程中词表及释义倾向性结果的变化情况
从图3可以看出:第1次循环后筛选出的候选情感词语词表GPN包含近7 000个词语,经8次循环后趋于稳定。对于Precision指数,每次循环后该指数都在不断提高,第8次后比最开始提高了近15%。这也说明本文采用的多次循环、逐步筛选的策略是可行的,能够有效提高情感词语识别的准确率。最终,利用基于多特征融合的情感倾向性识别方法,构建了包含4 429个词语的通用情感词语词典,其中2 886个褒义词,1 543个贬义词。
3 结论
根据《现代汉语词典》中词语释义的特点,利用情感词语、转折连词、否定词等词语释义等特征,提出了基于多特征线性融合的情感倾向性识别方法。该方法综合了现有的HowNet、NTUSD、CUHK及同济大学的褒贬义情感词典,并根据是否在《现代汉语词典》出现,构建了包含9 549个条目的候选通用情感词语。采用多次循环、逐步筛选的策略结合《现代汉语词典》计算词语释义的情感倾向性,进而构建了跨领域通用情感词语词典。采用pooling评测方法进行了实验,经测试本文提出的方法在Precision、Recall及F-measure等方面都取得了较好效果,并最终构建了更为全面的通用情感词语词典,为情感词语识别进一步研究提供了基础。
[1] 符淮青. 现代汉语词汇[M] 北京:北京大学出版社,1985.
[2] 刘叔新. 汉语描述词汇学[M] 北京:商务印书馆,1990.
[3] 董振东,董强.知网和汉语研究[J].当代语言学,2001(1):33-44.
[4] 朱嫣岚,闵锦,周雅倩等. 基于 HowNet 的词汇语义倾向计算[J].中文信息学报,2006,20(1):14-20.
[5] Vasileios Hatzivassiloglou, Kathleen R. McKeown. Predicting the Semantic Orientation of Adjectives[C]. Proceedings of the 35th Annual Meeting of the Association for Computational Linguistics and the 8th Conference of the European Chapter of the ACL, 1997:174-181.
[6] Wiebe J, Bruce R, Bell M, et al. A corpus study of evaluative and speculative language[C]. Proceedings of the Second SIGdial Workshop on Discourse and Dialogue-Volume 16. Association for Computational Linguistics, 2001:1-10.
[7] 中国社会科学院语言研究所词典编辑室. 现代汉语词典(第6版)[M] 北京:商务印书馆,2012.
[8] 孟杰.《现代汉语词典》与《现代汉语规范词典》感情色彩词语研究[D]. 济南:山东师范大学,2008.
[9] 徐东亮, 董开坤,等. 于文本挖掘的聚类算法研究[J].微计算机信息,2011,27(2):168-169.
[10] LI L, WANG P, HUANG D, et al. Mining English-Chinese Named Entity Pairs from Comparable Corpora[J].ACM Transactions on Asian Language Information Processing (TALIP),2011,10(4):19.
ResearchonemotionwordsrecognitionbasedonModernChineseDictionary
ZHAO Jun-min1, LI Fang2
(1.DepartmentofComputerandDataScience,HenanUniversityofUrbanConstruction,Pingdingshan467036,China; 2.JingdezhenCeramicInstitute,Jingdezhen333403,China)
2017-06-15
国家语委“十二五”科研规划重点项目(ZDI125-23)
赵军民(1978—),男,河南平顶山人,博士,副教授。
1674-7046(2017)04-0080-06
10.14140/j.cnki.hncjxb.2017.04.015
TP391
A
