基于K-means聚类算法的在线学习行为分析
2017-10-13刘训星
刘训星
基于K-means聚类算法的在线学习行为分析
刘训星
(宣城职业技术学院,安徽 宣城 242000)
K-means算法是基于距离作用相似性度量的聚类算法,论文介绍K-means聚类算法的3个基本参数。通过对学员学习行为记录数据,运用K-means聚类分析算法,可以构建出电大学员行为特征,有效的改善在线资源的配置。
用户行为;K-means聚类算法;初始聚类中心选取;行为特征
引 言
在信息快速发展的今天,网络技术快速发展和数字化学习资源建立,为我们学习方式带来了新的机遇和挑战,如何使用网络组织高效学习,则成为我们关注焦点。电大学员的学习方式也悄然发生改变,在线学习方式在电大教育模式中,扮演者重要的角色。电大学员就能根据自己工作和家庭的情况合理安排学习时间(灵活多变学习方式)、选择自己学习的内容(个性化的学习资源),同时有助于教师建立个性化教学设计、科学的学习行为评价模式、高效服务体系。国外学者主要集中在行为的理论[1]发展研究,国内学者不少在活动评价[2]方面研究。
文中首先采集了电大宣城分校服务器对有学籍学员在线学习原始数据,其次对获取进行预处理,选择有效数据,最后运用k-means聚类算法进行数据挖掘,获取在线学习行为模式。本课题的最大亮点是k-means聚类算法首次在电大在线学习行为模型中使用,通过对在线学习行为模式的数据挖掘分析,有效的提高电大在线教育教学质量。
1 在线学习行为
1.1 学员在线学习行为探讨
在线学习是课堂学习一种重要补充,学员利用在线学习平台,可以学习平台上丰富学习资源。在线学习注重媒体教学[3]和时空分离。在线学习行为主要有课件阅读、课程视频点播、论坛发帖讨论、教学在线直播、论坛答疑解惑、学习资料下载、在线完成作业、在线自我测试等。
1.2 学员在线学习行为分析
1.2.1.学员特征分析。学员在线学习受到很多方面影响,最主要的是心理因素和环境因素两个方面。心理因素:学习目的、掌握的学习方法、学员意志品质。环境因素:学习内容展现形式、学习辅助工具、学习平台更新和服务。
1.2.2.学习过程分析。学员根据在线学习平台的学习任务,制定各自在线学习目标(学习目标),在学习目标的指引下主动的进行学习(自主学习),为了解决在线学习过程问题,学员之间或学员与老师之间通过平台中论坛进行交流沟通(交流研讨),在学员进行学习过程中平台会及时将进度和评价并反馈给学员,学员依据平台评价认真反思及时调整学习方式方法(反思性学习),最后在线平台依据学员状况给出每个学员学习结果(学习结果)。在整个学习过程学员之间进行学习经验交流沟通和学习资源共享相互协作(团队协作)。
学员在线学习以自主学习、协同学习为主,还包括情景学习[4]。自主学习是以学员自己为主体,使用网络资源,进行探索、创造、实践来达到学习目标方式。协同学习是网络发展以中新趋势,学员们可以使用网络平台就学习内容进行交流沟通、分享学习资源,从而达到共同进步。情景学习内容丰富内涵深刻,是一种崭新的学习视角,是一种将从孤立学习到维系在具体情景中的过程、是一种学习个体走向学习共同体的过程、是一种从共同体边缘走向中心的过程。
2 K-means算法
2.1 算法
K-means算法[5]属于聚类方法中的一种划分方法,具有好伸缩性和很高的效率,比较适合大量数据处理。将对象分成若干组,以对象的相似度分组,结果得到多个不同聚类,相似度高对象就划分在同一聚类中。

(1)随机性地从n个模式{i1,i2,…ik}中选参数k。
(2)k个原型{W1,W1,…Wk}
(3)j∈{l,2,…,k},l∈{l,2,…,n}。
K-means算法流程
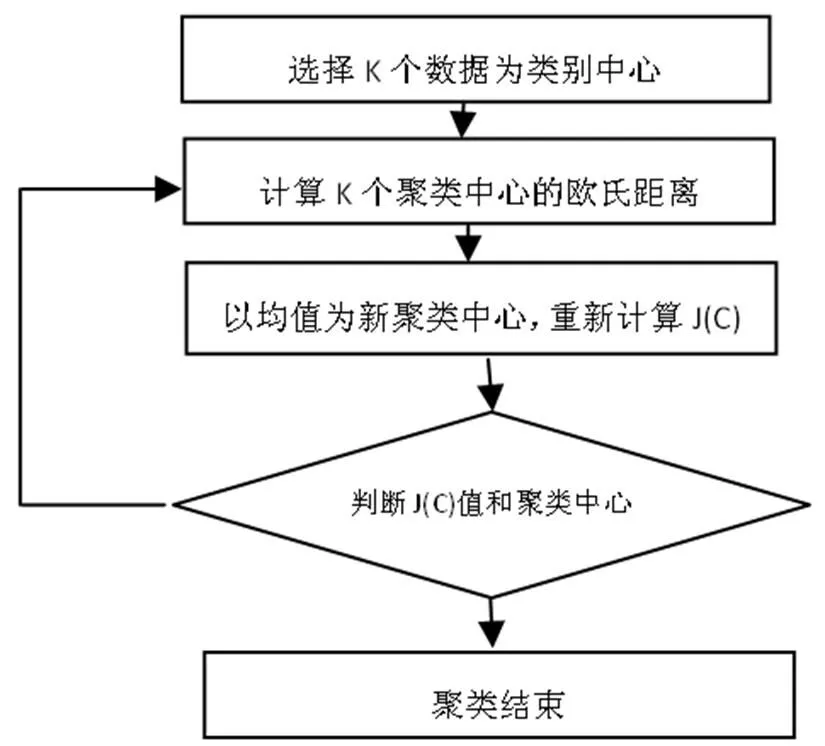
图1.K-means算法流程图
2.2 类别个数K
K-means算法中由于缺乏严格数学准则,类别个数K的选择饱受争议,学者们提出了许多启发式和贪婪准则。这其中最具有代表性的是,如图1所示,令K不停增加,J随着K的增加而减少,随着K值小到一定程度J增量为0,这时每个类数据自成一类。拐点A最靠近最优值。
然而不是所有情况下都能找到J-K关系曲线的拐点。对这些个别K的选择改进的算法是数据分析算法[6],该算法根据通过模式类分类和合并来反复修改改变聚类中心数量,从而得到理想合理类别数K。
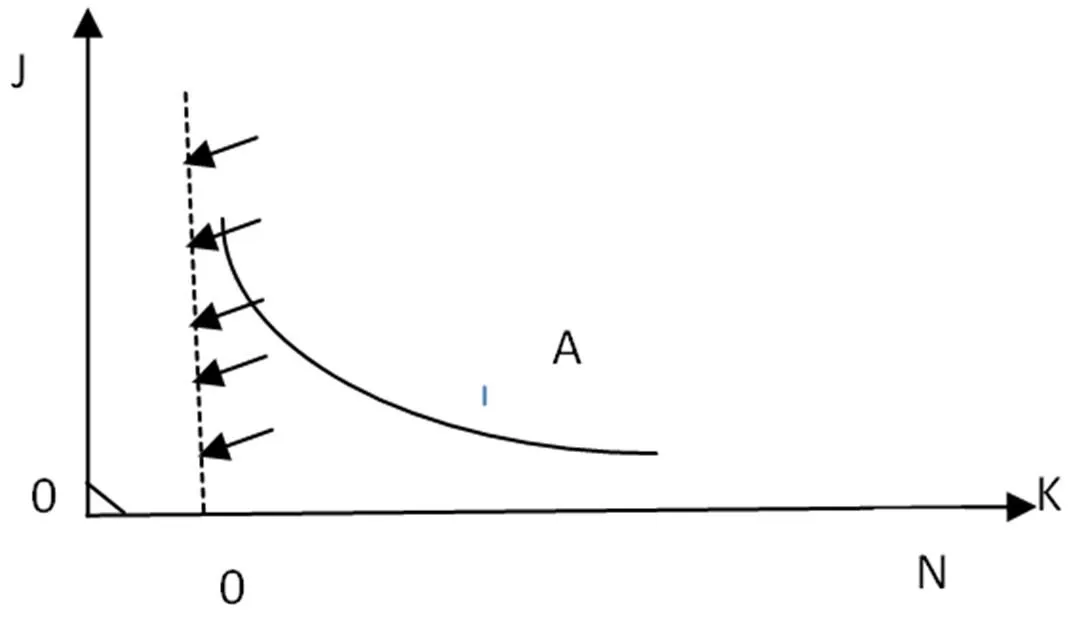
图2.J-K关系曲线
2.3 初始聚类中心的选取
由于K-means聚类算法是贪心算法,往往仅能获得局部的最佳。所以就有了初始聚类中心方案。经典方案是随机选取的,王成等人提出使用最大最小原则来选取初始聚类中心[7]。该方法最大的不同点在于是个确定性过程。模拟退火、生物遗传等优化也被用于聚类中心选择。

图3.多次重新启动K-means聚类算法图
2.4 相似性度量和距离矩阵
聚类分析就是针对对象两两之间的差异程度来划分的,然而相似度往往使用距离来衡量的。目前使用较广泛得是欧氏距离。
聚类结果的好坏通常可以使用聚类准则函数来判断,倘若选择的聚类准则函数选得好,聚类结果的质量自然就高,反之亦然。常用的聚类准则函数有下面三种:(1)加权平均距离和准则。(2)加权类距离和准则。(3)误差平方和准则。
3 实验结果
3.1 实验数据选取
3.1.1数据采集。采集电大宣城分校在线学习的数据,存放到excel表格中,为下一步数据预处理做好充分准备。
3.1.2数据预处理。首先对原始数据进行预处理,从而得到目标数据集。通过进一步分析找到关注的阅读、视频、论坛,资料,作业,在线测试等属性,得到电大学员网络学习行为描述相关性最大的集合。
数据重复记录[9]合并:在分析宣城电大在线学员上网行为的原始数据时。会存在某一用户大量充分的上网学习数据,为了能够统计出更准确的结果,我们将合并重复记录。将在某一段时间内,同一个IP地址产生的多条数据流记录,将该多条记录合并,然后对用户网络行为分析记录。
3.1.3数据选取。为了能够最佳分析结果,所以我们从中除掉那些不相干的多余属性,最终选择最能表现学习行为的数据属性。
3.2 K-means在线学习行为聚类分析结果
采集宣城电大在线学习系统中2015年8月1日,至2016年7月31日用户上网学习存在宣城电大在线存放sql server2005数据库中流量数据进行预处理的54729条记录。用户网上学习资源很多,我们只选择使用最多前6种。设置k值为6,设置3个数据字段,分别是学习时间、学习方式和ip地址。挖掘结果如图3、4、5所示。

图3.在线学习资源分布饼图
从图3看出电大宣城分校学员在线学习最主要的视频课程学习,其次完成作业。所在在教学资源设置过程中。(1)增加视频课程所占比例。(2)学员把22%时间用于完成作业,授课教师和班主任要及时批阅并及时反馈学员完成数量和质量。(3)学员只把9%的时间用在论坛上,要充分发挥论坛交流沟通作用,主要是两个方面。一方面学员之间交流学习经验。另一方面通过论坛答疑版块解决学习过程中疑难问题。
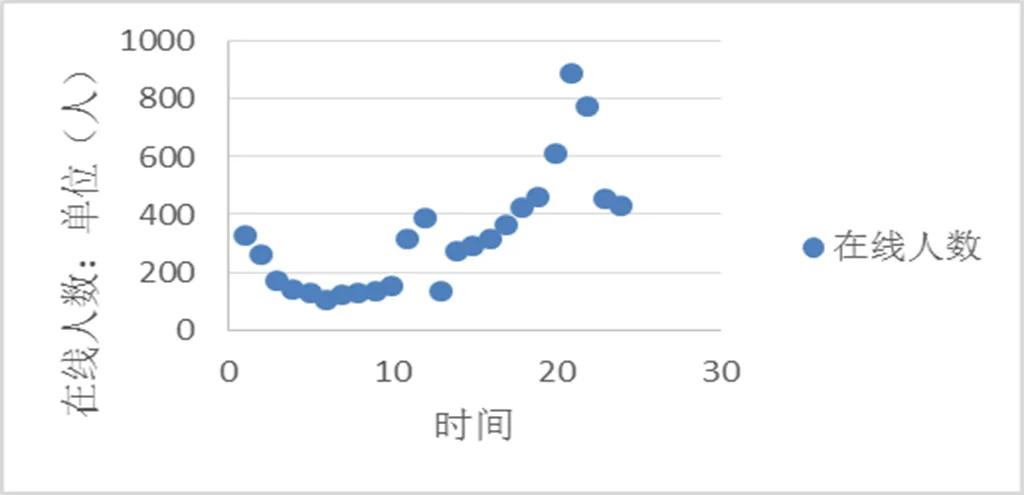
图4.各时间使用人数折线图
通过对图4分析11点至22点,最高峰出现在晚上8点到10点,低谷在早晨4点到6点。为了提高在线学习效果,首先保证晚上8点到10点服务器能够正常运行,服务器若要维护应当安排在清晨进行。同时晚上7点到9点要安排老师进行在线学习指导、答疑。

图5.工作日—双休日人数对比
通过对图5分析,(1)在9点-11点和14点-17点这两个时间段,在线学习人数显著下降,主要原因是在双休日这两个时间段电大宣城分校在开展面授课程。(2)在18点-20点人数显著增加,主要原因是在双休日这两个时间段安徽电大和电大宣城分校经常性安排网络直播课和在线答疑。(3)从整体来看,双休日与工作日在线人数有所下降,可能原因是双休日家庭生活任务需要处理。
结 语
通过使用K-means聚类算法分析出电大学员在线学习行为模式,就能够有助从宏观角度掌握电大在线学习平台使用状况、有助于微观了解具体每个学员学习行为,对电大在线学习平台的资源库建设和建立高效学习行为评价体系具有重要的意义。
随着数字化资源不断丰富、网络技术不断提高和智能化移动终端普及,在线学习将来成为电大教学中非常重要学习模式。将K-means聚类算法用到电大学员在线学习行为分析中是一种有意义的尝试,K-means聚类算法的聚类结果有助于电大师生提高在线学习效。
K-means聚类算法必须事先指定合理聚类的个数,否则就会出现聚类结果不合理。现在已有研究人员尝试利用类间和类内相异度改进K的值[10],从而减少孤立点和噪声点。
[1]Julia Y.K.Chan,Christopher F.Bauer.Identifying At-Risk Students in General Chemistry via Cluster Analysis of Affective Characteristics[J].Chemical Education Research,2014,(9):1417-1425.
[2]张杰,卓灵,朱韵攸.一种K-means聚类算法的改进与应用[J].网络与信息安全,2015,(1):125-127.
[3]高红艳,刘飞.基于局部相似性的K-means谱聚类算法[J].小型微型计算机系统,2014,(5):1133-1134.
[4]王勇,唐靖,饶勤菲,等.高效率的K-means最佳聚类数确定算法[J].计算机应用,2014,(5):1331-1335.
[5]王金亮,张月芬.系统聚类法在网络学习行为中的应用研究[J].中国教育信息化,2016,(8):90-93.
[6]王千,王成,冯振元,叶金凤.K-means聚类算法研究综述[J].电子设计工程,2012,(7):21-23.
[7]WANG Cheng,LI Jiao-jiao,BAI Jun-qing,et al.Max-Min K-means Clustering Algorithm and Application in Post-processing of Scientific Computing[C].//Napoli:ISEM,2011:7-9.
[8]曹永春,蔡正琦,邵亚斌.基于K-means的改进人工蜂群聚类算法[J].计算机应用,2014,(1):204-207.
[9]薛黎明,栾维新.聚类算法在高校网络用户行为分析中的应用[J].现代电子技术,2016,(7):30-32.
[10]吴淑苹.基于数据挖掘的教师网络学习行为分析与研究[J].教师教育研究,2013,(3):47-55.
(责任编校:京华,俊华)
2017-03-08
安徽广播电视大学青年教师科研基金项目“网络远程教育学习行为及效果的分析研究”(项目编号qn15-17)。
刘训星(1981-),男,安徽宣城人,硕士,宣城职业技术学院讲师,研究方向为数据挖掘、教育信息化。
G442
A
1673-2219(2017)06-0007-03
