基于聚类挖掘算法的微博用户兴趣发现的实现
2017-10-12郑杰辉
◆郑杰辉
(厦门海洋职业技术学院 福建 361012)
基于聚类挖掘算法的微博用户兴趣发现的实现
◆郑杰辉
(厦门海洋职业技术学院 福建 361012)
社会媒体是用户分享与获取信息的重要平台,本文基于微博用户数据,运用数据挖掘中的聚类算法,提出了微博用户兴趣的发现方法,实现了微博好友的分组和好友推荐,为新媒体社交网络平台上的新闻推荐和精准营销,进行了有益的探索。在探索聚类算法的过程中,本文针对K-means算法的不足之处,结合粒子群算法的优势,提出了改进后的粒子群K-means算法,该算法在微博用户兴趣发现中提高了聚类的效果。
微博用户;聚类算法;PSO-kmeans;用户兴趣发现
0 引言
微博即微型博客,是一种以关注分享为模式的新兴社交媒体,其内容少、发布快、形式多样正好适应了人们对信息实时的、准确的、多样的分享交流需求。微博可以让用户在任意时刻、地点分享和浏览相关信息,其他用户也可以通过浏览微博平台上的信息来了解最新的热点问题和最有价值的信息。用户在使用微博的时候,浏览什么样的内容,关注什么样的好友是根据其兴趣、偏好、习惯来确定的。因此,对于有相似兴趣和爱好的用户,实施有效信息的推广以及精准营销等具有非常重要的价值。
1 数据挖掘技术
1.1 数据挖掘技术
伴随着数据库中数据量的飞速增长,数据量越来越大,形成了海量数据。这些海量数据中蕴含着大量的、潜在的知识,为了从海量数据中提取和挖掘有效的知识,数据挖掘技术应运而生。可以说,数据挖掘是综合了多个学科、多个领域而诞生的一种新的技术,通过数据挖掘提高对信息的处理效率,从而挖掘出数据背后潜在的知识和价值,为管理者提供有效的决策。当然,对于数据挖掘,目前还没有统一的界定,但是,在实践中,一般包含以下过程:
(1)确定业务对象。需要明确挖掘的数据所属领域,在此基础上确定挖掘的主题。
(2)数据准备。通过数据源获取需要挖掘的数据,然后对数据进行预处理,包括数据清洗、数据合并、数据转换等。
(3)数据挖掘。使用数据挖掘的相关算法和方法,如关联规则、分类、聚类等对数据进行挖掘,从数据中提取有价值的知识。
(4)知识的解释和评估。通过挖掘获取的结果是否有用,需要对知识进行解释和评估,使得这些知识能够被理解。
1.2 聚类分析
聚类分析是数据挖掘中重要的方法之一,是一种无需监督的自适应学习过程,该技术所分析的数据具有随机性、不确定性等。对数据进行聚类分析的方法有很多种类,可以分为:划分方法、层次方法、局部方法、模型方法等。针对划分方法,涉及到的算法有:K-means算法、Pam算法、Clara算法等;针对基于层次的方法,具体有自上而下和自下而上的聚类算法;基于模型的方法有统计学方法和神经元网络方法等。
1.3 聚类评价的比较
聚类评价可分为过程评价和结果评价,过程性评价要求聚类算法要具有较强的可伸缩性,要求算法能够针对不同大小的数据量、不同的数据类型等具备相应的处理能力;而结果评价主要评价聚类结果的好坏,可分为监督的、非监督的和相对的。
2 基于微博的用户兴趣的发现
2.1 微博用户兴趣群发现与分类模型
事实上,通过阅读微博用户发布的微博信息可以了解该微博用户的兴趣爱好,同时,也可以通过微博用户的基本信息获知该用户的喜好。本文利用微博用户关注的具有明显兴趣爱好标识来获取用户兴趣,进而构建用户兴趣分类模型。
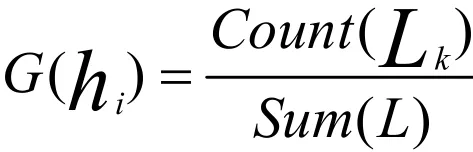
2.2 微博文本聚类关键技术
本文所研究的对象是微博文本,相对于简单的数值数据而言,文本是非结构化的数据。因此,在做文本聚类之前,需要对文本进行预处理,预处理包括:微博文本分词、停用词处理、特征选择、文本表示等,在此基础上,对微博用户兴趣数据进行标注,以便为用户的兴趣发现奠定良好的基础。
跟英文单词不同,中文中词与词之间是连续的,并且词的意义跟上下文环境有很大的关系,因此,在做下一步处理之前需要对中文进行分词。目前,分词的方法和实现的算法有很多,比如机械匹配法、约束矩阵法、理解切分法等。当然,在分词过程中,某些词是没有实际意义的,针对这些词,需要做停用词处理。
为了对文本进行特征选择,本文采用目前应用最为广泛的TF-IDF(Term Frequency - Inverse Document Frequency)。该方法能够科学地界定一个词在整个文本中的权重,权重越高,其区分能力越强,具体计算公式如下:
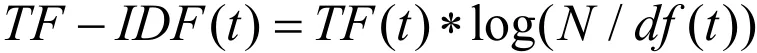
该公式中,t表示一个独立的词,TF(t)表示t在文本中出现的频率,N表示总的词条数目,DF(t)表示t在文本集合中出现过的次数。通过TF-IDF算法就可以实现文本的结构化表示。为了方便计算机进行有效识别和处理,需要对这些文本进行特定的表示,最常使用的是向量空间模型。基于该模型,对特征词进行权重的度量,同时需要进行归一化处理,这样度量的特征词更加准确,下面给出计算的公式:

2.3 基于数据挖掘的微博用户兴趣发现的实现
在上述工作的基础上,本节采用聚类算法作用于样本数据,实现微博用户兴趣的发现。
2.3.1样本数据特点
跟分类不同,聚类数据没有明显的结果标签,其聚类过程是一个没有监督的学习过程。由于本文针对微博文本进行聚类,因此采集到的样本数据具有以下特点:
(1)根据微博文章的特点,其字数一般介于100到1000之间,最为常见的约为300;
(2)微博文本经过预处理后,数据属于间断的、不连续的变量;
(3)微博文本数据类型非常丰富,因此没有标准的聚类评价方法;
(4)微博文本的样本变量之间的值波动范围一般比较大,所以,在调用聚类算法之前,需要进行归一化处理。
2.3.2聚类算法及其选择
目前,聚类算法有很多,不同的聚类算法有不同的优缺点和适用的场景。为了更好地对微博数据进行聚类,本文在传统k-means算法的基础上,针对粒子群(PSO)算法具有较强的全局搜索能力的特点,提出了改进的基于改进粒子群优化的k-means算法(PSO-kmeans)。在此基础上,分别运用 K-means和PSO-kmeans算法,发现聚类中心和数目,同时也充分体现了不同聚类算法的优势,形成更好地聚类结果。下面给出K-means算法的执行流程,具体如图1所示。
但是,K-means算法的缺点是族类k的设置比较随意,对样本的初始聚类中心敏感度较大,同时当数据量较大时执行效率比较低下。因此,在此引进PSO-kmeans算法。PSO-kmeans算法具体步骤如下:
(1)对粒子群进行初始化操作;
(2)执行粒子群算法进行粒子群迭代搜索;
(3)执行k-means算法,按类输出最终的聚类结果。
2.3.3算法实现过程
PSO-kmeans算法实现步骤如下:
输入:聚类数据集S、粒子群规模m、聚类数目b及最大迭代次数t;
处理原则:同一组数据相似度很高,不同组差异性很大;
输出:聚类中心对应的数据集S中的t组族。
具体过程:
(1)对粒子群进行初始化操作;
(2)执行PSO算法进行粒子群迭代搜索;
(3)执行K-means算法,按类输出最终的聚类结果。

图1 K-means聚类算法
具体流程如图2所示。
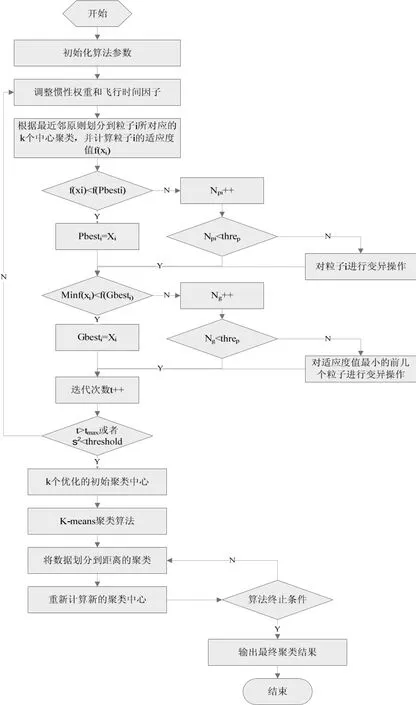
图2 PSO-kmeans算法执行流程
在该流程图中,Pbesti表示个体最优位置,Gbest表示群体最优位置,threp表示规定的阀值,σ2表示群体适应度方差,tmax表示最大迭代次数,Npi表示粒子i状态无法得到改善的累计次数,Ng表示粒子群的状态无法得到改善的累计次数。
3 实验设计及结果分析
3.1 实验过程设计
实验过程设计如图3所示。
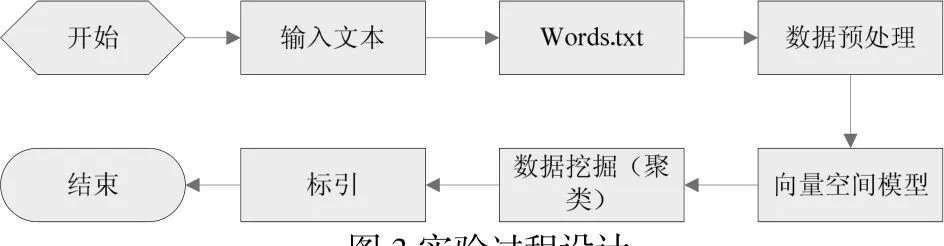
图3 实验过程设计
从整个实验过程来看,最为重要的是两个环节,其一是数据预处理,其二是数据挖掘,产生聚类结果。
3.2 实验数据处理
本文以新浪微博数据为处理对象,利用新浪微博API通过网络爬虫工具获取用户微博数据。获取数据后,对其进行预处理,包括去重、提取关联关系、过滤掉干扰信息等操作,使之形成有利于聚类分析的数据。
在此基础上,分别运用K-means和PSO-Kmeans算法对数据进行聚类分析,产生如表1所示的聚类结果。
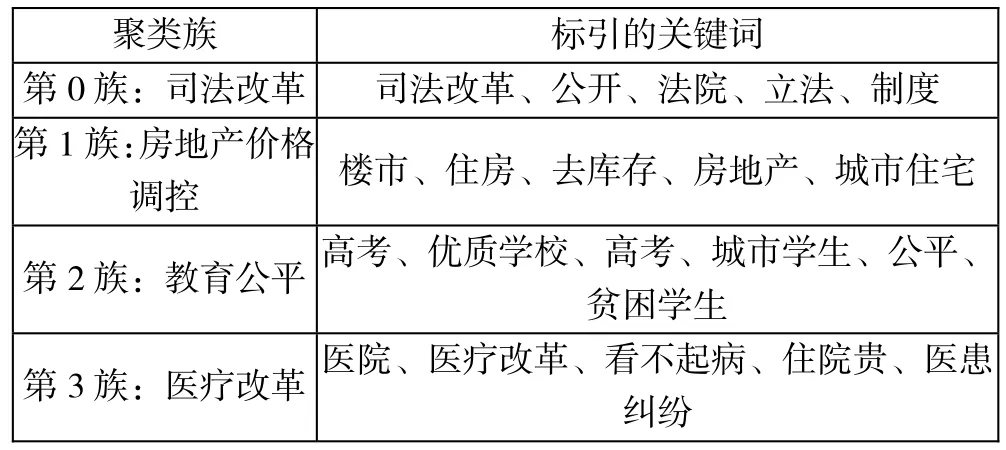
表1 聚类结果表

第4族:城镇化 城镇改革、推进城市发展、城镇经济、政府报告、宏观政策
3.3 实验结果分析
通过聚类结果对比发现两点,其一:从聚类算法的角度来看,PSO-Kmeans算法能够有效克服K-means算法的缺点,使得获得的聚类结果更好,波动性较低。其二:从聚类结果分析,通过这些聚类族就可以对有相同兴趣和喜好的用户进行分组,从而实现好友分组、好友推荐和精准营销等。
4 结束语
本文基于微博用户和微博数据的特点,提出了微博用户兴趣的发现方法,并运用数据挖掘中的聚类算法对微博数据进行深入分析和挖掘,得到相似的微博用户兴趣群体,为网络社交平台的数据挖掘提供了有益的探索和借鉴。
[1]石伟杰,徐雅斌.微博用户兴趣发现研究[J].现代图书情报技术,2015.
[2]牛朝林,高茂庭.基于模糊关联规则的微博用户潜在兴趣发现[J].计算机系统应用,2016.
[3]徐雅斌,刘超,武装.基于用户兴趣和推荐信任域的微博推荐[J].电信科学,2015.
[4]杨勇.基于 k-means算法在微博数据挖掘中的应用[D].天津工业大学,2015.
[5]曾珂.基于数据挖掘的微博用户兴趣群体发现与分类[D].华中师范大学,2014.
[6]宋巍,张宇,谢毓彬等.基于微博分类的用户兴趣识别[J].智能计算机与应用,2013.
