深度学习在图像描述中的应用
2017-09-28蔡晓龙
蔡晓龙
(青岛理工大学计算机工程学院,山东青岛266033)
深度学习在图像描述中的应用
蔡晓龙
(青岛理工大学计算机工程学院,山东青岛266033)
卷积神经网络在图像识别处理方面有着优秀的表现,但是只能处理单个输入,无法在多个输入之间建立联系。循环神经网络则在处理前后相关的序列信息上有着独特的优势。将两种神经网络算法联系起来,可以用于实现图像的语言序列描述,具体方法为:首先用卷积神经网络将图片的特征提取,后连接到LSTM模型,与输入的语言序列共同训练网络达到描述图像的目的。输入的数据应当根据需要做适当的预处理,以获得更好的表现。
循环神经网络;卷积神经网络;长短时间记忆模型;图像描述;数据预处理
Abstract:Convolutional neural network has a satisfactory performance in image recognition and processing,but can only deal with a single input,cannot be established between multiple inputs.Recurrent neural network has a unique advantage in dealing with sequence information.The two kinds neural network algorithm can be used to achieve the image sequence of language de⁃scription.Firstly,the convolution neural network is used to extract the feature of the image,and then connected to the LSTM model to train the network with the input language sequence to achieve the purpose of image caption.Input data should be prop⁃erly pretreated as needed to achieve better performance.
Key words:Recurrent Neural Network;Convolutional Neural Network;Long Short-Term Memory;image caption;data pre⁃processing
1 概述
全连接神经网络和卷积神经网络以其优异的特性在众多领域都取得了重要的研究成果,但是,也存在表现不佳的场景。它们都只能处理单个的输入,前一个输入和后一个输入是完全没有关系的[1]。但是,某些任务需要能够更好的处理序列的信息,即前面的输入和后面的输入是有关系的[2]。比如,当我们在理解一句话意思时,单独理解每个词是不够的,我们需要处理这些词连接起来的整个序列。为了达到这样的目的,就需要用到深度学习领域中另一类非常重要神经网络:循环神经网络[3](Recurrent Neural Network)。
循环神将网络(RNN)通过反向传播算法反向传播误差,它与神经网络相似,只不过与时间有关。具体的表现形式为网络会对前面的信息进行记忆并应用于当前输出的计算中,即隐藏层之间的节点不再是无连接而是有连接的,并且隐藏层的输入不仅包括输入层的输出还包括上一时刻隐藏层的输出。RNN同样通过随机梯度下降(Stochastic gradient descent)算法使得代价函数(损失函数)值达到最小。但是随着时间间隔不断增大时,RNN会丧失学习到连接很远的信息能力(梯度消失)。所以更通用的方案时采用长短时记忆(LSTM)或门限递归单元(GRU)结构。本文将使用LSTM模型与卷积神经网络结合用于图像描述[4]。
2 LSTM模型
2.1 LSTM输入预处理
由于神经网络的输入和输出都是向量,为了让语言模型能够被神经网络处理,我们必须把词序列转换为向量的形式,这样神经网络才能处理它。我们可以建立一个包含所有词的词典,每个词在词典里面有一个唯一的编号对词序列进行向量转化。如图1所示。
例如字符句子(图2)‘<START>a very clean and well decorat⁃ed empty bathroom <end> <NULL> <NULL> <NULL> <NULL> <NULL> <NULL> <NULL>’,转换为向量X[1,4,142, 510, 10, 667, 415,277,58,2,0,0,0,0,0,0,0]。本文中根据需要把句子长度设置为17,以<START>开始,<END>结束,不足的17个单词的以<NULL>填充。进一步为了方便向量化计算我们把每个词典编号再转换为向量。即,词典长度为1004,每个词我们随机生成一个服从高斯分布的长度为256的向量,把这个词典就变成了一个1004*256的矩阵。输入X就相应的转换为17*256的矩阵,用以循环神经网络的输入[5]。

图1 词典数字对应

图2 a very clean and well decorated empty bathroom.
2.2 LSTM运算模型说明
LSTM整体运算模型如图3所示,网络的输入Xt为X在t时刻的输入X[t],以及上一时刻t-1时刻LSTM隐藏层的输出ht-1。
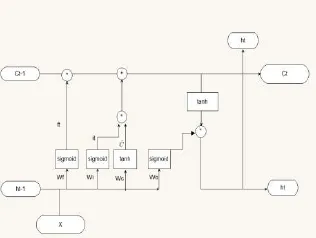
图3 LSTM整体运算模型
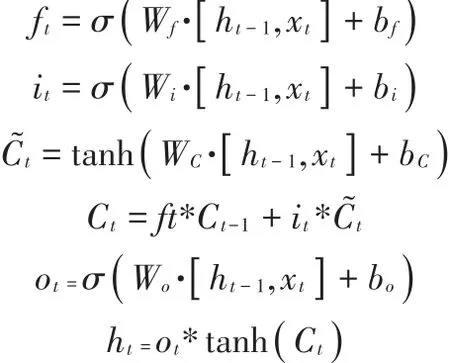
从图3可见ht的值向上传送用于求解t时刻的预测值,与Ct一起向右传送作为t+1时刻的输入。即每个时刻都有一个输出,每个时刻输出又是下一时刻的输入。
总的时间长度T为X的输入长度,每个时刻输入X[t],输出h[t],最终的h为T*隐藏层的节点数(本文以512为例),即h为16*512的矩阵。得到h后,h(16*512)W(512*1004)得到16*1004矩阵,每一个t*1004矩阵为一个预测集,最大的值为预测结果。把预测结果与真实值对比,通过反向传播算法求解梯度,优化网络[6]。
3 长短期记忆网络(LSTM)实例
3.1 实验模型
本文实验模型图为图4所示(RNN部分为LSTM算法)。训练网络的过程为:卷积神经网络部分将image输入,经网络运算提取特征后得到图片的特征向量;循环神经网络部分,将得到的图像特征向量与X经LSTM算法运算后输出为X的预测值,通过X的预测值与真实值比较调整优化LSTM模型。例如,我们将X的0-15的元素输入,得到的预测值为16*1004的矩阵,用SoftMax方法计算每一个1*1004中最大的概率值为预测值,将最大概率值的索引与X的1-16对应对比,即每一个输入的输出都应该是下一个值。如图5所示(h0为图像的特征向量):
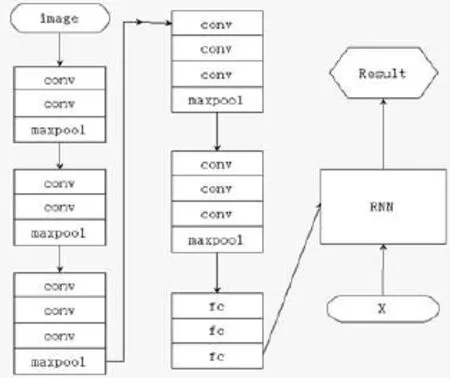
图4 实验模型
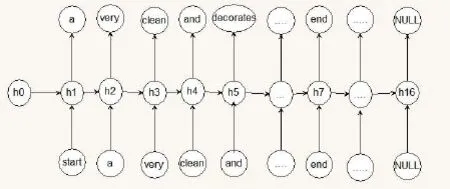
图5 文字输入方式
3.2 实验环境
Win10 Anaconda2-4.3.0.1-Windows-x86_64 ipython note⁃book
3.3 实验结果
图片生成描述如图6、图7(GT所在的行为实际图片的描述)。

图6

图7
模型数据集中的文字数据集为1004个词语,不足以描述各种图片,所以对于图片描述中的复杂词汇以“<UNK>”代替。从上面的三个图的实验测试结果可以看出,语言描述反映了一部分图像信息。
4 总结
由于卷积神经网络算法在图像处理方面的独特优势,我们用以提取图像的特征,结合预先处理好的词语序列矩阵,作为LSTM算法的输入数据,并使用向前传播算法与向后传播算法交替训练网络。由于实验条件限制,本文使用的图像数据为已训练好的VGG-16卷积神经网络模型提取的1*512的图像特征直接作为LSTM的输入,结合词序列矩阵训练LSTM模型。由于实验数据不足、训练时间短、实验模型简单等多种原因,由实验结果可以看出,模型对图像有一定的描述能力,但是仍然具有很大的提高精度的潜力。本文探讨的仅是一种用于计算机图像描述的方法,算法的进一步改进优化可作为后续的研究方向。
[1]Hinton G E.Learning Distributed Representations of Concepts[C].Proceedings of the 8th Annual Conference of the Cogni⁃tive Science Society.1986,12.
[2]Elman,J.L.Finding structure in time.CRL Technical Re⁃port 8801,Center for Research in Language,University of Cal⁃ifornia,San Diego,1988.
[3]Schuster M,Paliwal K K.Bidirectional recurrent neural net⁃works[J].Signal Processing,IEEE Transactions on,1997,45(11):2673-2681.
[4]Graves A,Mohamed A R,Hinton G.Speech Recognition with Deep Recurrent Neural Networks[J].Acoustics Speech&Signal Processing.icassp.international Conference on,2013:6645-6649.
[5]Jaeger H,Haas H.Harnessing nonlinearity:Predicting chaot⁃ic systems and saving energy in wireless communication[J].Science,2004,304(5667):78-80.
[6]Cho K,Van Merrienboer B,Gulcehre C,et al.Learning Phrase Representations using RNN Encoder-Decoder for Sta⁃tistical Machine Translation[J].Eprint Arxiv,2014.
The Application of Deep Learning in Image Caption
CAI Xiao-long
(Computer Engineering Institute,Qingdao Technological University,Qingdao 266033,China)
TP183
A
1009-3044(2017)24-0178-02
2017-07-15
蔡晓龙(1992—),男,山东烟台龙口人,硕士,主要研究方向为人工智能。
