基于图像超分辨率的车牌识别研究
2017-09-28覃正优伍永
覃正优,伍永
(广西师范学院计算机与信息工程学院,南宁 530023)
基于图像超分辨率的车牌识别研究
覃正优,伍永
(广西师范学院计算机与信息工程学院,南宁 530023)
由于大多数情况下摄像机获取到的车牌图像的分辨率很低,导致有些车牌识别系统不能正确识别车牌图像。针对该问题,提出在经典模板匹配识别算法的基础上,结合Single Shot MultiBox Detector车牌检测方法,同时使用基于子像素卷积神经网络对车牌图像进行超分辨率,然后利用“字符轮廓检测+区域筛选合并”的方法分割字符。实验表明,重建后的整块车牌的识别率为63.2%,单个字符识别率为92.8%,所使用的方法有效提高车牌识别率和识别精度。也就是说,所提出的单幅图像超分辨率方法可以有效地促进车牌识别。
广西科技计划项目(No.桂科AB16380272)
0 引言
在日常生活中,通过交通视频监控设备获取的图像通常是低分辨率,它不能很好的满足后处理程序的要求(即车牌识别)。车牌上的相似字符往往因为紧密的轮廓而导致识别错误。一般车牌识别算法的识别精度受车牌图像的分辨率、光照、遮挡和损伤等因素的影响,容易出现识别误差。因此,从获取到的低分辨率的车牌图像中重建出相应的高分辨率图像在车牌识别应用中是非常有意义的。
超分辨率指的是由一张或多张低分辨率图像恢复相应的高分辨率图像的过程,该过程能够在低分辨率图像上添加更多的图像细节信息,也叫分辨率增强[1]。一般来说,超分辨率算法根据任务可以分为如下几类。第一类方法是基于预测模型。通常所定义的数学模型可以生成高分辨率图像。例如,插值方法是使用加权平均相邻的低分辨率像素来产生对应的高分辨率像素。由于插值强度与局部相邻像素相似,因此可以产生良好的平滑区域。然而,该方法并不能很好沿边缘和高频区域产生大的梯度[2]。第二类方法是基于边缘先验,这类方法是采用从边缘特征学习得到的图像先验信息来重建对应的高分辨率图像[3]。边缘信息是原始图像的重要结构,也是视觉感知的关键问题。通常在这类方法中,边缘特征是指边缘的深度、宽度或者梯度轮廓的参数[4-5]。因为先验信息是从边缘学习得到的,所以可以重建出具有高质量边缘的高分辨率图像。但是边缘先验在重建其他高频结构(如纹理)的模型时效率较低。第三类方法是基于图像统计,这类方法使用各种图像属性作为先验来预测高分辨率图像。通常,在重尾分布下,较大梯度的稀疏特征以及总差会被用于减少计算成本或者使得输入的低分辨率图像尽可能规则化。第四类方法是基于图像块。它们通常是通过学习高分辨率图像和低分辨率图像之间的映射函数来恢复更多的图像细节。有几种学习映射函数的方法,如加权平均[6],马尔可夫随机场[7],高斯过程回归[8]和稀疏表示[9]。已经有一些研究使用深度学习技术进行图像复原,将卷积神经网络应用于自然图像去噪和去除噪声模式(污垢/雨),这些复原问题或多或少是有由去燥驱动的[10-11]。因此,还有一类方法是基于深度学习的方法,这类方法很多情况下是利用网络直接学习低分辨率和高分辨率图像之间的端对端映射,在输入网络之前几乎没有预/后处理。基于深度学习的超分辨率方法结合了前四种方法的优点来重建高分辨率图像,所以结果比较令人满意。图像内容和纹理结构在研究中是非常重要的,当低分辨率和高分辨率图像之间的映射越充分,超分辨率结果越好。因此先决条件是训练图像符合测试图像,由于车牌图像规格统一,因此基于深度学习的单幅图像超分辨率方法可以很好地用来提高车牌图像的分辨率。
1 基于图像超分辨率的车牌识别设计
传统的车牌识别方法包括两个重要阶段:车牌检测和字符识别。我们可以用超分辨率方法对车牌图像里的车牌进行放大,以便于提高车牌检测率和识别性能。如图1所示,超分辨率是车牌检测和预处理之间的中间过程。

图1
1
1.1 车牌检测阶段
在车牌检测阶段,本文是利用文献[12]提供的方法,该方法是基于一个前向传播卷积神经网络,产生一系列固定大小的物体边框,以及每一个边框中包含物体实例(本文训练的模型中,仅包含背景和车牌2个类别)的可能性,之后进行一个非极大值抑制得到最终的类别预测。参考模型训练方法,训练出适合在不同分辨率车牌图像仍然能下进行准确的车牌检测定位的模型。利用模型,可以对本文实验的低分辨率车牌图像进行快速的车牌检测定位,切割出规格统一的车牌图像作为超分辨率阶段的输入。
1.2 超分辨率
通常会以两种方式将超分辨率引入到车牌识别算法中。一是利用超分辨率方法来放大源图像,另一种是放大用于识别的统一规格的车牌图像。当采用基于深度学习的超分辨率方法应用到整幅图像中,那么图像中会增加大量无用的图像信息,因为在原图像中,车牌区域往往是比较小的,这么一来网络的计算成本将会大大增加。由于车牌检测阶段通常是通过摄像机或从捕获到的图像自动获得统一的车牌图像,所以输出的车牌图像的质量将强烈的影响字符识别阶段。在本文中,我们选择另外一种方法。为了避免检测阶段的影响,先从原图像中定位并剪切出统一规格的车牌。然后,运用的超分辨率方法来放大,这么做的目的是为了减少算法的计算成本。因此,可以消除车牌检测的效率来独立地分析超分辨率操作在车牌识别系统中的影响。
对于车牌超分辨率,本文首先将低分辨率的车牌图像直接输入到一个三层的卷积神经网络,得到特征图像,然后再用一层子像素卷积层来提高特征图像,最后输出对应的高分辨率图像。
1.3 预处理及字符分割
超分辨率图像结果是作为预处理阶段的输入,预处理阶段包括它包括灰色变换,二值化,中值滤波,腐蚀和膨胀的操作。这些操作可以使得预处理阶段后的图像更容易被识别。
在字符分割过程,本文采用的是“字符轮廓检测+区域筛选合并”的方法。由于车牌上的颜色组成比较简单,主要是背景和字符的颜色,而且背景和字符的颜色具有较高的对比度,转换成灰度后图像的灰度直方图会有两个明显的峰。因此将经过预处理阶段后的车牌图像转换成了二值图像可以将背景与字符分离出来,然后对车牌二值图像进行轮廓检测,得到每个轮廓的外接矩形框[13]。最后再根据字符框的大小和长宽比的先验信息对矩形框进行筛选,得到车牌字符的外接框完成字符的分割定位。不同于英文字母与数字,车牌上的汉字有可能是不连通的,例如“鲁”、“苏”等可以拆分成不同的部分,在轮廓检测时会被分割成独立的连通区域,因此需要将其进行合并得到完整的汉字。关于合并的方法,本文采用筛选候选区域然后直接合并的方法[14]。尽管上述分割方法对一些低分辨率的模糊图像分割效果不是很理想,主要原因是这些低分辨率图像中有较强的噪声干扰,导致字符的边缘变得极为模糊,字符区域亮度跟背景较为接近。预处理后的二值图像后干扰区域的面积较大,造成字符与干扰成片地连通。同时部分车牌图像由于字符与背景亮暗过于接近,转换为二值图像后本来的字符区域与背景同时变成了黑色,无法进行轮廓检测。对于这个问题,由于本文在预处理之前对低分辨率的模糊车牌图像进行超分辨率操作,因此可以减小噪声干扰,增大字符与背景的对比度,使字符轮廓更加清晰,提高了分割正确率。
1.4 识别
模板匹配作为图像识别中经典的方法之一,从待识别的图像或图像区域中提取一些特征向量[15]。然后将这些向量与模板的相应特征向量逐一比较。因此,我们可以计算归一化的相关性。最大的相关性表示它们之间的最高相似性,利用这种关系将图像分成几个类别。另外,我们可以计算图像和模板特征之间的距离,通过最小距离方法确定图像类别。减法方法用来估计字符图像的最相似模板。最后,输出七个字符的车牌号码。
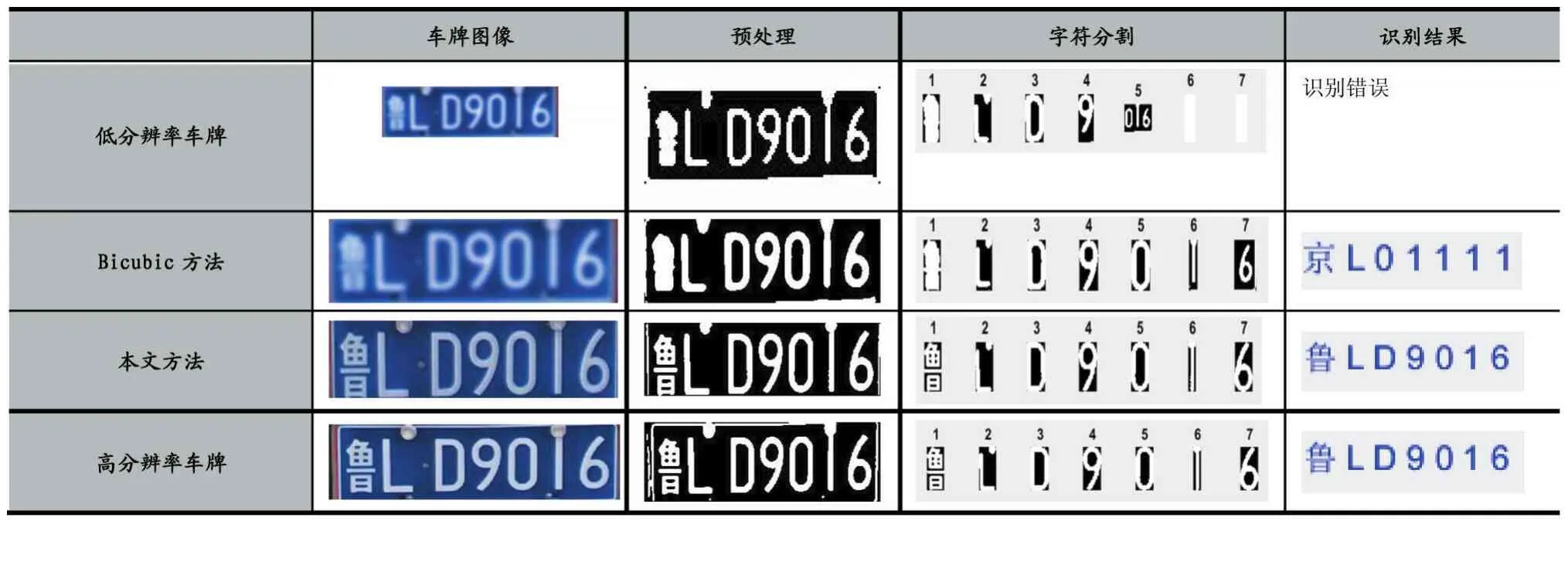
表1 比较不同车牌图像的识别结果
2 实验
车牌通常由7个字符组成,其中,第一个字符是汉字,第二个字符是字母,其他五个是字母或数字[16]。本文的模板库是由数字0~9,共10个,和大写字母A~Z,除去“I”和“O”两个字母,共 24个,以及 31个汉字字符,总共65个字符。在实验过程中,我们采用直接将Single Shot MultiBox Detector模型检测并归一化后的低分辨率图像输入到一个基于子像素卷积神经网络中,用来重建出相应的高分辨率图像。本文子像素卷积神经网络模型、Single Shot MultiBox Detector模型训练阶段是在GPU上使用Caffe深度学习框架进行仿真实验,其中子像素卷积神经网络模型训练时间大约需要十二小时。
2.1 数据集
在车牌检测阶段,Single Shot MultiBox Detector模型训练数据集,我们使用500张大小为512x512来自某小区、不同监控点、不同分辨率的车牌图像训练。
在超分辨率阶段,数据集是来源于某小区停车场卡口摄像机拍摄的高清图像,并经过人工截取出统一规格的车牌图像,共400张。在子像素卷积神经网络训练阶段,大小为10r×10r10r*10r的子图像是从原始的高分辨率车牌图像中提取出来的,其中放大倍数r=2。为了合成低分辨率车牌图像,采用高斯滤波和通过放大2倍数的子取样来模糊原始高分辨率车牌图像。[10]那么子图像就以步长为(10-∑mod(f,2))×2分别从原始高分辨率车牌图像和合成的低分率车牌图像中被提取处理,这确保了在原始高分辨率车牌图像中的所有像素都会出现,且仅一次作为训练数据的标记数据。
2.2 视觉效果比较
实验分别将低分辨率车牌图像、经Bicubic处理后的车牌图像、经过子像素卷积神经网络后重建的车牌图像、以及原始的高分辨率图像进行预处理,表1给出了预处理后的效果。对比结果,低分辨率车牌图像和经Bicubic处理后辨别不出汉字内容。我们提出的方法跟原始的高清车牌图像差不多,字符边缘相对清晰。
2.3 评价指标比较
峰值信噪比(PSNR)和结构相似性(SSIM)是超分辨率操作最常用的评价指标。在本文的实验中,我们对100张车牌图像进行统计比较。本文提出的基于子像素卷积神经网络重建后的车牌图像的PSNR平均值是39.40dB,而Bicubic方法得到的是28.41dB,平均高约0.99dB,单张图像最大高约1.25dB。在SSIM指标上,本文方法平均值是 0.8796,Bicubic方法的是0.8497,平均高约0.03。通过实验,可以看出通过本文提出的基于子像素卷积神经网络的超分辨率方法可以恢复车牌图像的细节,输出的车牌图像有利于进行下一个步骤。
2.4 车牌识别结果
根据图1中车牌识别步骤,识别结果见表1。输入低分辨率的车牌图像,由于车牌太小,预处理后的图像非常不清晰,不仅算法无法识别,而且人眼也无法识别,因此在字符分割过程中不能得到任何字符,导致识别结果出错。与之不同的是使用Bicubic方法和基于子像素卷积神经网络进行放大重建,重建后的车牌图像在分割过程中可以进行分割。由于使用Bicubic方法进行重建,车牌质量还是较差,因此在分割过程后,汉字辨别不出内容,导致得到了错误的识别结果。然而使用P超分辨率CNN网络进行放大重建后的车牌图像,每个步骤的输出图像与原始高分辨率车牌图像得到的结果几乎是相同的,识别结果也正确。实验结果证明,在车牌图像缩放时,本文提出的P超分辨率CNN方法,可以提高车牌的识别精度。
此外,在实验中,我们对100张车牌图像的700个字符的识别率进行统计比较。使用本文提出基于子像素卷积神经网络方法进行重建后的整块车牌的识别率为63.2%,单个字符识别率为92.8%,高于使用Bicubic方法进行重建的识别率。
3 结语
本文在经典模板匹配算法的基础上,结合了Single Shot MultiBox Detector车牌检测方法,同时使用基于子像素卷积神经网络对车牌图像进行超分辨率,利用“字符轮廓检测+区域筛选合并”的方法分割字符,有效了提高车牌识别率和识别精度。
[1]付芳梅.基于冗余字典学习的超分辨率研究[D].浙江:浙江师范大学,2014.
[2]Irani M,Peleg S.Improving Resolution by Image Registration[J].CVGIP:Graphical Models and Image Processing,1991,53(3):231-239.
[3]Fattal R.Image Upsampling Via Imposed Edge Statistics[J].Acm Siggraph,2007,26(3):95.
[4]Sun J,Sun J,Xu Z,Shum HY.:Image Super-Resolution Using Gradient Profile Prior[C].IEEE Computer Society Conference on Computer Vision&Pattern Recognition,2008.
[5]Qing Yan.Single Image Superresolution Based on Gradient Profile Sharpness[J].IEEE Transactions on Image Processing a Publication of the IEEE Signal Processing Society,2015,24(10):3187-3202.
[6]H Chang,DY Yeung,Y Xiong.Super-Resolution t高分辨率Ough Neighbor Embedding[C].IEEE Computer Society Conference on Computer Vision&Pattern Recognition,2004,1:I-275-I-282 Vol.1.
[7]Freeman,W.T.Jones,T.R.Pasztor,E.C..Example-Based Super-Resolution[J].IEEE Computer Graphics and Applications,2002,22(2):56-65.
[8]He H,Siu WC.Single Image Super-Resolution Using Gaussian Process Regression[C].IEEE Conference on Computer Vision&Pattern Recognition,2011,42(7):449-456.
[9]Purkait P,Chanda B:Image upscaling Using Multiple Dictionaries of Natural Image Patches[J].Springer Berlin Heidelberg,2012,7726:284-295.
[10]Dong C,Chen CL,He K,Tang X:Image Super-Resolution Using Deep Convolutional Networks[J].IEEE Transactions on Pattern Analysis&Machine Intelligence,2016,38(2):295-307.
[11]Kim J,Lee JK,Lee KM.Accurate Image Super-Resolution Using Very Deep Convolutional Networks[C].IEEE Conference on Computer Vision&Pattern Recognition,2016:1646-1654.
[12]Liu W,Anguelov D,Erhan D,Szegedy C,Reed S:SSD:Single Shot MultiBox Detector[C].European Conference on Computer Vision,2016,21-37.
[13]牛博雅.自然场景下的车牌检测与识别算法研究[D].北京:北京交通大学,2015.
[14]付芦静,钱军浩,钟云飞.基于汉字连通分量的印刷图像版面分割方法[J].北京:计算机工程与应用,2015,51(5):178-182.
[15]单瑾,曾丹.车牌的字符分割和字符识别的研究与实现.四川:成都电子机械高等专科学校学报[J],2011(1):24-27.
[16]王玉辉.基于粗糙集的车牌字符识别技术的研究.黑龙江:黑龙江科技信息[J],2016(10):63-63.
Research on License Plate Recognition Based on Image Super-Resolution
QIN Zheng-You,WU Yong
(College of Computer and Information Engineering,Institute of Guangxi Teachers Education University,Nanning 530023)
In most cases,the license plate image resolution is very low,so some license plate recognition systems that do not recognize the license number correctly.To solve the problem,proposes a method that based on the classical template matching algorithm,and combines the Sin⁃gle Shot MultiBox Detector method to detect the license plate in low resolution image.Then uses a sub-pixel convolution neural network to super-resolution the license plate image,uses character contour detection and regional screening merger method to split the character.Our experiments show that this method can improve the license plate recognition rate and recognition accuracy,which achieves the recognition rate of the whole license plate to 63.2%and the single character recognition rate to 92.8%。
1007-1423(2017)23-0059-05
10.3969/j.issn.1007-1423.2017.23.014
覃正优(1989-),女,广西柳城县人,硕士研究生,研究方向为图像处理
伍永(1993-),男,安徽安庆人,本科,研究方向为图像处理
2017-05-24
2017-07-30
低分辨率;超分辨率;子像素卷积神经网络;车牌识别
Low Resolution;Super-Resolution;Sub-Pixel Convolution Neural Network;License Plate Recognition
