基于混合相似度和信任传播的位置推荐系统
2017-09-23戚文博张曦煌
戚文博 张曦煌
(江南大学物联网工程学院 江苏 无锡 214000)
基于混合相似度和信任传播的位置推荐系统
戚文博 张曦煌
(江南大学物联网工程学院 江苏 无锡 214000)
当前存在大量基于位置推荐的移动社交应用。提出一种基于CF算法的混合相似度和信任传播位置推荐系统的方案。方案中主要分三个考量要素,首先将用户偏好分为用户静态偏好和用户动态偏好,对于用户静态偏好主要是基于位置的种类信息和历史评价,而用户动态偏好主要是基于地理信息和二位云模型,最后用户的社会关系是基于信任传播的信息。该方法优势是不仅考虑用户偏好的多样性,而且通过信任传播可以有效缓解数据稀疏性问题。并应用Hadoop以提高计算平台的数据处理能力。该方案对比现有方法,基于CF算法的位置推荐预测用户对新位置的喜好更加准确且高效。
位置推荐 信任传播 协同过滤 MapReduce
0 引 言
随着移动互联网的飞速发展,基于定位的社交和服务类型的应用如雨后春笋般出现。位置推荐不仅仅可以帮助移动用户及时确定能够满足需要的新位置,而且用户可以通过评分系统得到客观的评估结果,可以体现出对模糊概念最直观的感受。位置推荐系统如今已被广泛应用于为用户提供及时的满足个性化需求的信息。
根据文献[1],可以将用户偏好分为静态偏好和动态偏好。举例,用户到地点A吃西餐,西餐被看作用户的静态偏好,地点A被看作用户的动态偏好,而且用户的动态偏好是由用户的静态偏好决定的。如用户是否要选择去一个地点吃西餐是由该用户的周边环境决定的,如时间、距离等因素。当用户有多个可选择的地点,那这些地点可以当作动态偏好。但是位置推荐大部分都是基于标签的CF算法,没有考虑到用户偏好的细节。
根据文献[2],地理上接近的位置具有相似的特征。用户已经访问的位置可以看成动态偏好,并且用户动态偏好依赖于静态偏好。所以如果用户静态偏好和已经访问过的位置是相近的,那么就称之为相似用户,几乎没有基于这个观点的位置推荐系统。
根据文献[3],在信任网络中,由于稀疏性问题,部分用户对项目评分数据很少,与网络中其他用户联系也很少。所以需要根据信任传播理论,来减少数据稀疏性问题,提高推荐系统的准确率。
云模型是一种处理定性概念与定量描述的不确定转换模型。移动互联的数据标定是基于用户看法,口味和意见,它是主观的、不严密的、模糊的。所以用云模型来处理不确定、模糊的用户喜好是一种合适的方式。根据文献[4],将云模型引入推荐算法,以至提高了相似度计算的覆盖范围,但这种方法高估了用户偏好相似度。
对于上述问题,本文提出了基于混合相似度和信任传播的位置推荐系统。分别有两个关键性的改进:第一个是我们把用户偏好分为静态偏好和动态偏好,第二个是根据信任传播理论,来减少数据稀疏性问题。首先,本方案利用衰减函数[10]、TF-IDF[6]和信息分类去评估用户静态偏好的相似度。另一方面,通过二维云模型导出用户动态偏好。最后,通过Mole Trust算法[9]得出用户社会关系相似度,且并行于Hadoop平台,来满足移动用户对于快速响应的需求。
1 相关研究
1.1 基于用户偏好的协同过滤
许多方法已经被成熟地应用在位置推荐上。例如文献[6]开发了一种LA-LDA算法导出用户偏好的新位置。文献[7]通过随机游走算法实现位置推荐。文献[8]通过核密度估算个性化地理因素对用户行为的影响。在上述方案中,主要利用协同过滤算法。然而大部分基于CF算法的位置推荐是低效的,可能在实时应用场景中失败。而且很少考虑到用户偏好的细节,他们只选择用标签来定义用户偏好。因此我们通过从位置分类信息中提取静态偏好,二维云模型来建模动态偏好,根据信任传播理论得出社会关系相似度来提高方案的精确度。此外我们将本方案并行在MapReduce框架来提高效率。
1.2 云模型
云模型定义如下:
设U是一个精确值表示的定量论域,C是U上的定性概念,若定量值x∈U,且x是定性概念C的一次随机实现。x对C的确定度μ(x)∈[0,1]是有稳定倾向的随机数。
μ:U→[0,1] ∀x∈Ux→μ(x)
(1)
x在论域U上的分布称为云,每一个x称为一个云滴。定性概念和定量描述之间的转换被执行在两个云发生器:正向云发生器(FCG)和逆向云发生器(BCG)。
基于云模型的CF算法可以在数据稀疏的状况下仍可以得到良好的推荐效果,然而它高估了某对有很少共同点用户的相似度。此外,一个位置点有经度和纬度两个属性,不能用一维BCG模型直接提取位置特点,因此需要应用二维云模型建模用户动态偏好。
1.3 信任传播理论
图1中表示一个简单信任网络,每一个节点对应一个用户,节点与节点之间的连线表示用户间的信任关系,连线的权重表示信任度。网络中有6个用户,用户1直接信任用户2、3、4。直接信任度为0.8、0.4、0.2。

图1 简单的信任网络
信任网络中,由于稀疏性问题,某些用户具有少量的信任用户,则对推荐精确度造成很大影响。根据信任传播理论,假设A信任B,B信任C,那么A在一定程度上也信任C。获得更多信任用户,需要通过直接信任用户的信任关系,得到非直接信任用户的间接信任度。
2 位置推荐算法
2.1 用户静态偏好相似度
用户可能在不同时间点访问一个位置许多次,因此首先评估用户对于历史访问记录的偏好。
计算用户对历史访问位置的偏好。rij代表ui对于历史访问地点lj的偏好程度,它被定义为:
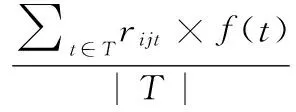
(2)
其中,T是用户ui对地点lj访问的时间t的集合,rijt是ui在时间点t访问lj的偏好度。f(t)是衰减函数,如下:
f(t)=e-λ(t0-t)
(3)
其中,t0是当前时间,t是用户访问地点的时间。λ是一个可变参数,不同的环境下有不同的值。
计算用户静态偏好。pi={pie1,pie2,…,pien}是用户ui的静态偏好集合,pie代表用户ui对地点元素e的静态偏好,定义如下:
(4)
其中,Lj是用户ui所访问的历史位置的集合,rile是用户ui对包含元素e的地点l访问后的喜好程度,Ei是被用户ui访问过的按照元素分类后地点的集合。Nu是所有用户的数量,Nue是访问过包含e元素地点用户的数量。
计算用户静态偏好相似度。esim(ui,uj)代表用户ui和uj的静态偏好相似度,定义如下:
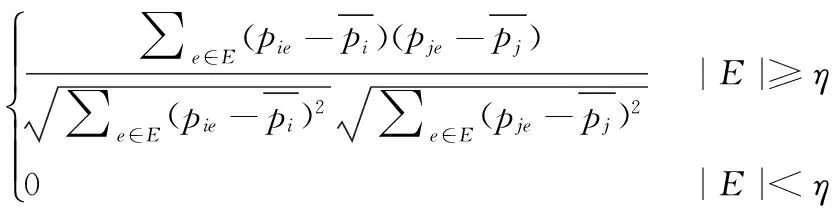
(5)
2.2 用户动态偏好相似度
用户是否访问某个位置取决于其周围的环境等因素。也就是说,用户访问某个地点在一定程度上是随机的。因此认为历史访问记录可以代表用户的动态偏好。位置信息有两个属性经度和纬度,如果把一个位置点作为云滴,可以通过二维逆向云发生器建模用户动态偏好[4]。
计算用户动态偏好相似度,lsim(ui,uj)表示用户ui和uj的用户动态偏好相似度,定义为:

(6)
其中Fui=(Flion,Fliat)和Fuj=(Fljon,Fljat)表示用户ui和uj各自的特征向;Flion=(Exlion,Enlion,Helion),Fliat=(Exliat,Enliat,Heliat)表示用户ui动态偏好的的特征向量;Fljon=(Exljon,Enljon,Heljon)和Fljat=(Exljat,Enljat,Heljat)表示用户uj的动态偏好的特征向量。只考虑用户动态偏好相似度范围在[0,1]内。
如果En和He的值相对较小并且Ex的值大于En和He,导致Ex覆盖了En和He的作用。因此估算基于二维云模型的用户动态偏好相似度之前应对特征向量进行归一化处理。
用户动态偏好基于用户静态偏好。只考虑当用户静态偏好相似度接近的情况下,估算用户动态偏好相似度。这样避免了对用户动态偏好过高的预期。
2.3 社会关系相似度
用户的社会关系相似度是基于信任传播的社交关系和访问位置的元素。例如,用户u1和u2的访问位置是L1={l1,l3,l4},L2={l2,l3,l7},l1={e1,e2},l2={e3,e5},l3={e1,e4},l4={e4,e5},l7={e2,e3}用户u1和u2访问的公共位置是l3,用户u1和u2的共同位置元素是{e1,e2,e4,e5},可以获得更加精确的用户的社会关系。
建立用户信任网络,我们通过Mole Trust算法得到非直接信任用户的间接信任度,tuv是用户u对用户v的间接信任度,如下:
(7)

在此设置一个阈值θt,把信任度不小于θt的用户作为用户u的信任用户。
T={v|tuv≥θt,v∈U}
(8)
确定社会关系相似度,tsim(ui,uj)表示ui和uj的社会关系相似度,如下:

(9)
其中α是在[0,1]范围内的调谐参数,Ti和Tj分别是用户ui和uj各自的的信任关系集,Ei和Ej是用户ui和uj各自的访问元素集合。α=1表示用户社交关系完全取决于共同的信任用户,否则α=0表示用户的社交关系完全取决于共同元素。显然,用户的社交关系相似度值的范围在[0,1]内。
应用TOPSIS法来计算参数α的值,方法总结如下:
(1) 假设评估对象数量是m,每个对象的评估因素数量是n。判断矩阵为:R=(rij),其中i=1,2,…,m,j=1,2,…,n。
(2) 判断矩阵R归一化为B,B的因子为:
(10)
(3) 定义正向理想解A+和负向理想解A-。
A+={max1≤i≤m(bij)|j=1,2,…,n}={1,1,…,1}
A-={min1≤i≤m(bij)|j=1,2,…,n}={0,0,…,0}
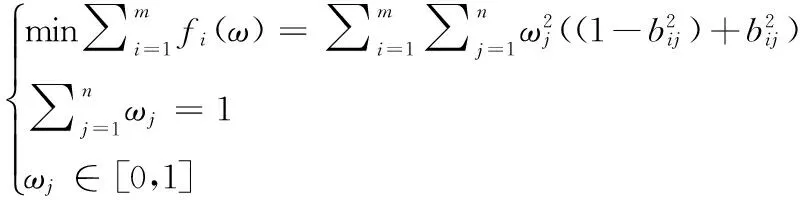
(11)
解决方案如下:

(12)
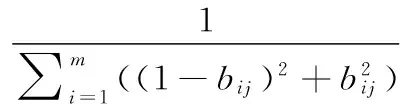
(13)
2.4 用户对位置的偏好
ur=(ui,uj)表示用户ui和uj的关系,其结合用户静态偏好,用户动态偏好和社会关系,定义如下:
ur(ui,uj)=β1csim(ui,uj)+β2lsim(ui,uj)+
(1-β1-β2)tsim(ui,uj)
(14)
其中两个加权参数β1和β2(0≤β1+β2≤1)表示用户动态偏好相似度和用户静态偏好相似度对比用户社交关系相似度的相对重要性,β1=1表示用户间关系完全依赖于用户静态偏好的相似性;β2=1说明用户间关系完全取决于用户动态偏好的相似性;β1=β2=0状态用户间关系只计算用户社交关系相似度。注意参数β1、β2的值取决于TOPSIS方法。
最后pij表示用户ui对新位置lj的偏好,可以使用基于用户的CF算法:
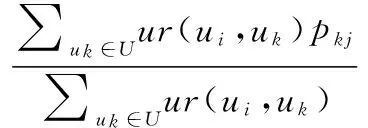
(15)
2.5 时间复杂度与MapReduce并行化
位置推荐的关键问题是CF算法需要大量计算量。令m和n分别作为用户数和位置数。|f|是用户的信任用户的数量。|esim|是用户静态偏好的相似度记录的数量。|Ln|是对于某个用户新位置的数量,方案的时间复杂度按算法执行步骤分析如下:
(1) 静态偏好相似性时间复杂度为O(m2)。
(2) 动态偏好相似性时间复杂度为O(|esim|)。
(3) 社会关系相似性时间复杂度为O(m|f|)。
(4) 用户对位置偏好时间复杂度为O(m|Ln|)。
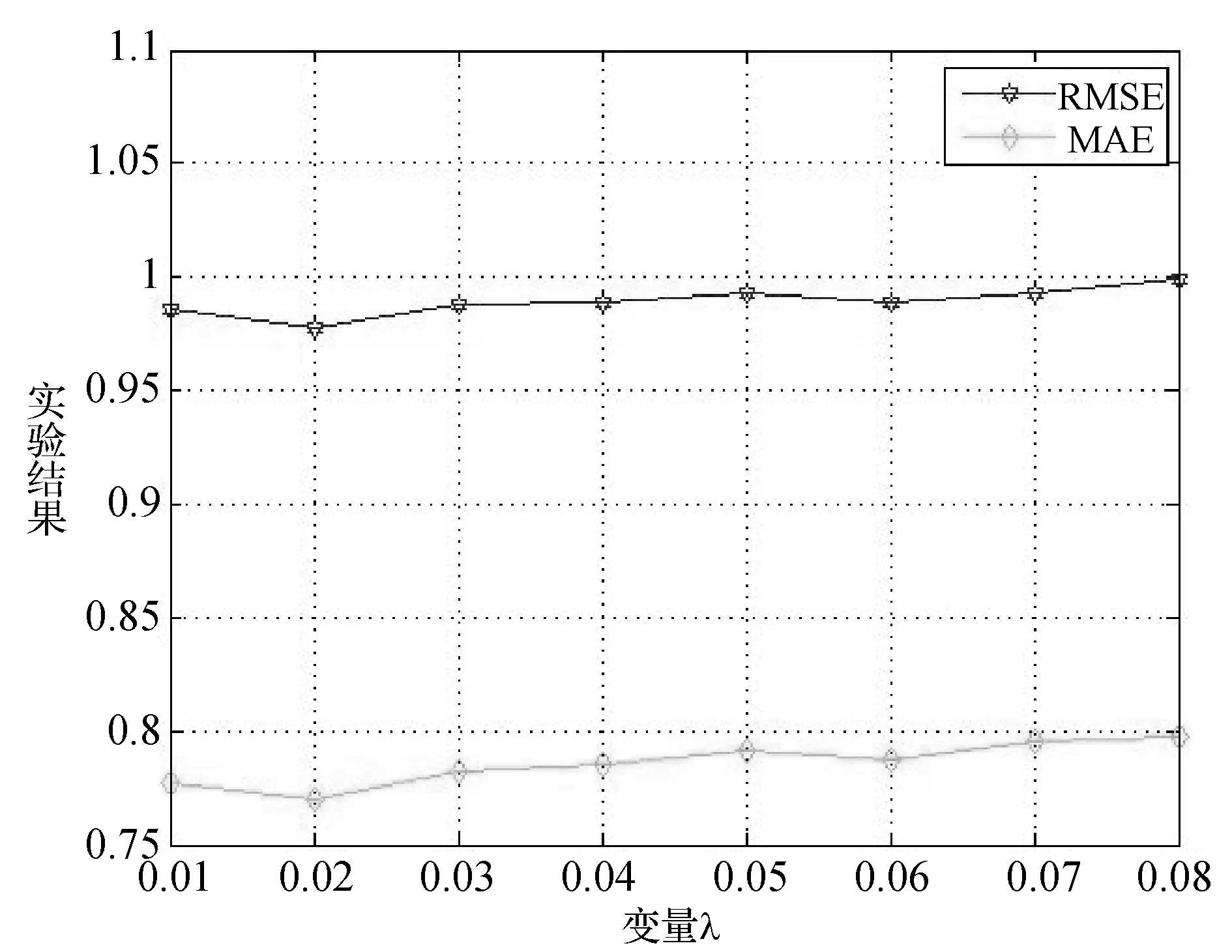
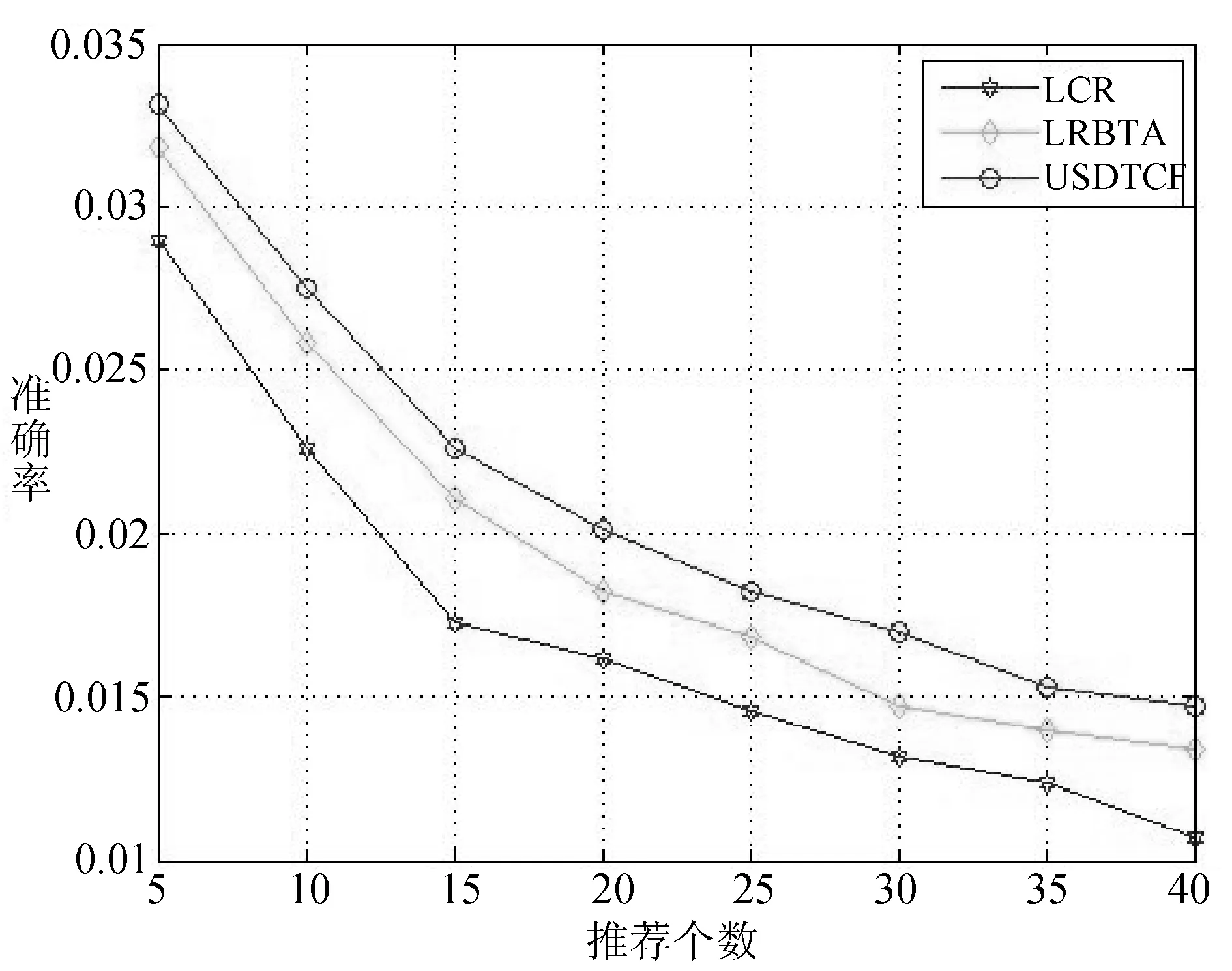
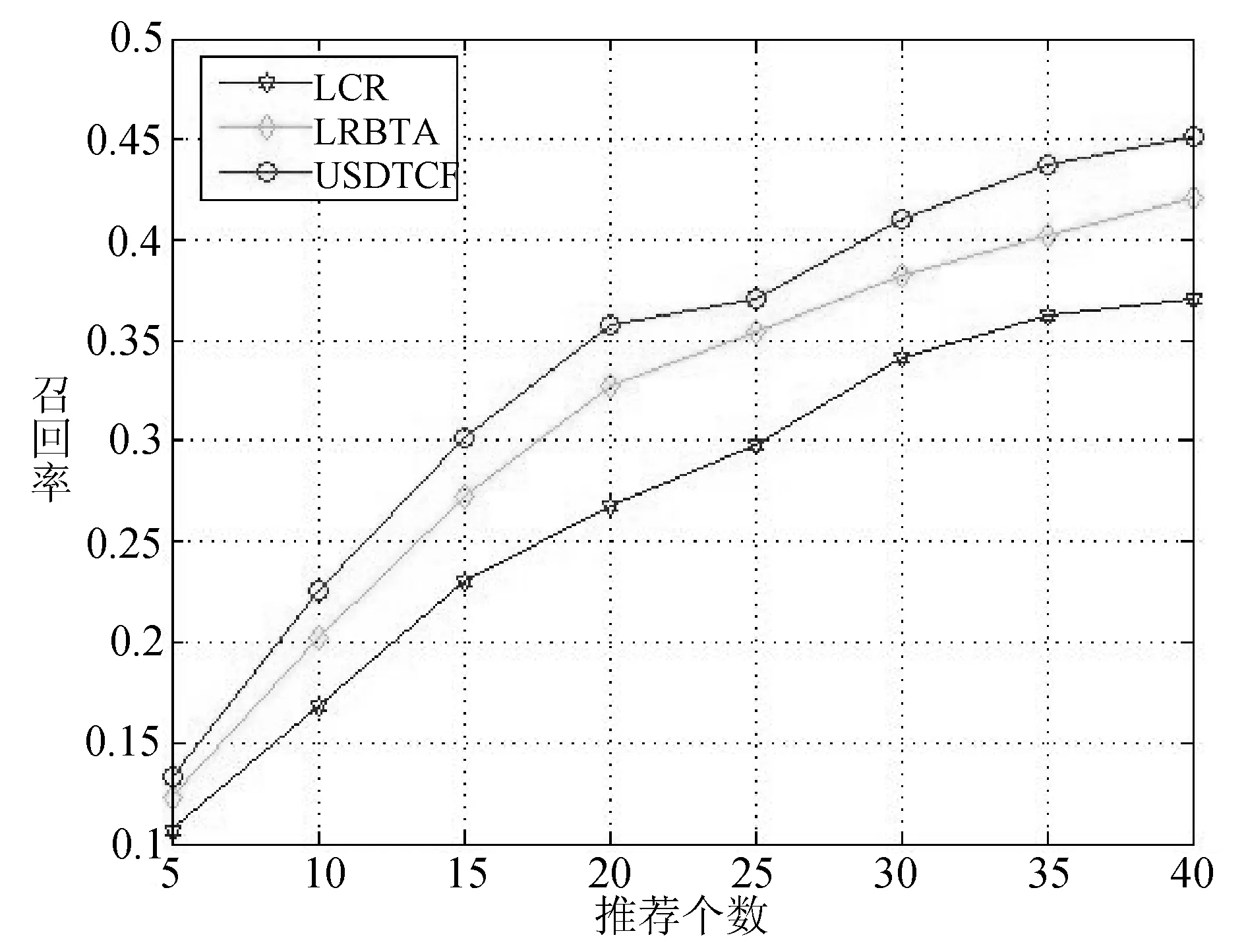
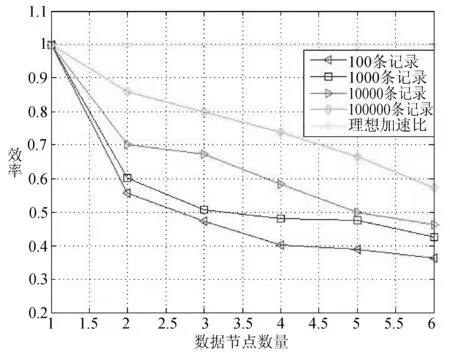
因为|f| 对于步骤(1)在Hadoop平台的并行化,主要研究两步来计算用户静态偏好相似度。第一步找出某对用户的每一个地点元素。Map1接受一组数据包括用户信息、位置元素、偏好值,被用户访问过的位置元素数量作为输入,并输出ui,ex,pix,|eui|,Reduce1接受Map1的输出,并输出ex,(u1,u2,p1x,p2x,|eu1|,|eu2|)。第二步程序计算用户静态偏好相似度,Map2接受Reduce1的输出作为输入,并输出(u1,u2),(ex,p1x,p2x,|eu1|,|eu2|)。Reduce2接受Map2的输出,并输出(u1,u2),csim(u1,u2),csim(u1,u2)是用户u1和u2的相似度。|e|是地点元素的个数。Uex是用户访问的元素ex的次数。这一步的时间复杂度为O(|e||Uex|2)。因为|e|< 3.1 实验环境 研究本方案的准确性和效率,在Hadoop集群上设置4个节点。一个节点作为命名节点其他三个作为数据节点。节点运行在4 GB内存,Inter Corei5 4590 3.3 GHz处理器和centos 6.5的PC机上。每个节点都可以支持最多2个Map或Reduce任务,需要设定相同数量的Map和Reduce任务。Map和Reduce任务不能同时执行,平台可以支持6个Map任务和6个Reduce任务。 3.2 数据集 Yelp数据集包括五个部分:商家数据、登录数据、评论数据、提示数据和用户数据。主要用到评论数据共1 125 458条记录,商家数据共42 153条记录,用户数据共252 898条记录。评论数据包含用户对位置的评级,社会关系包括在用户数据中,类别信息包含于商家数据中。根据评论时间来分配评论数据集为训练集和测试集,利用过去的评论数据来预测用户对位置的偏好。把80%有更早时间戳的评论数据当作训练集,剩余的评论数据作为测试集。 3.3 性能指标 衡量方案性能,需要用到平均绝对误差(MAE)、均方根误差(RMSE)、准确度、召回率、效率、加速比。N1是提取出用户正确偏好数量,N2是算法预测的用户偏好数量,N3是测试集中用户偏好总数量。准确度和召回率被定义为: (16) 加速比定义为: (17) n是节点数量,T1是单节点顺序执行的时间,Tn是n个节点并行执行的时间。当Sn=n时获得理想加速比。 效率表示每个节点的加速比: (18) 当En=1时获得理想效率。 3.4 结果分析 (1) 精度评估 如第2节所述,参数λ(式(3)中)、σ(式(5)中)、α、1-α(式(7)中)、β1、β2、1-β1-β2(式(12)中)可以用来调优方案的性能。而α、1-α、β1、β2、1-β1-β2随着λ和σ的变化而变化,给出λ和σ的值,α、1-α、β1、β2、1-β1-β2是可以由TOPSIS和实验数据集来确定。因此我们调优λ和σ以找到它们的最优值。 设置λ= 0.01,在0.1~0.8范围内调优σ。RMSE和MAE结果如图1所示。设置σ=0.55并且在0.01~0.08范围内调优λ, RMSE和MAE结果如图3所示。 图2 通过RMSE与MAE调优σ 图3 通过RMSE与MAE调优λ 从图2和图3,可以看到调整方案精度需要改变σ从0.1至0.8改变且λ从0.01至0.08变化。如图2,λ= 0.01是固定的,我们得到最低点的RMSE和MAE分别为σ= 0.6和σ= 0.4。在图3中,如果给定σ= 0.55,调优λ从0.01到0.08,得到当λ=0.02时方案的最佳RMSE和MAE。 同时调优λ和σ并找到它们的最优设置是:λ= 0.02,σ= 0.65,通过TOPSIS方法得到α= 0.568,1-α= 0.432和β1= 0.417,β2=0.294,1-β1-β2=0.289。根据实验结果,可以得出评估社会关系时共同的信任用户比共同的位置元素发挥更重要的作用。对于精确度方面用户静态偏好起到主导作用,但用户动态偏好和社会关系对于其影响也是不可忽视的。 针对位置推荐的准确度和召回率,本方案USDTCF算法与基于位置聚类LCR算法[9]、基于用户活动和社交信任LRBTA算法[5]进行比较,结果如图4、图5所示。 图4 USDTCF算法准确率比较 图5 USDTCF算法召回率比较 比较结果可知USDTCF算法综合考虑了用户动态偏好、用户静态偏好并基于信任传播理论考虑用户的社会关系,而FRBTA算法只考虑了用户单一偏好及用户间多种信任,LCR算法只考虑同一聚类下的其他地点进行推荐,并未考虑地点的分类元素和不同用户间的影响。USDTCF算法在准确率和召回率两个衡量标准上均优于LCR算法和LRBTA算法。 (2) 效率评估 验证并行在Mapreduce框架上的效率,Yelp数据集中取出4份用户评分副本作为实验数据集,包括的记录数为100、1 000、10 000和100 000。图6和图7为4种情况并行加速比和效率。 图6 MapReduce并行后加速比统计 图7 MapReduce并行后效率统计 从图6可以看出加速比的提高是和数据节点数量相关的,且数据集越大结果越接近理想加速比。从图7可以看出数据节点数增加则效率降低,且数据集越大结果越高效。实验结果表明并行在Mapreduce框架下对加速比和效率有重要影响。 通过对传统协同过滤进行改进得到基于混合相似度和信任传播的位置推荐算法。将用户偏好分为静态和动态两方面,并采用位置元素和二维云模型分别进行两次计算。其次基于信任传播理论运用Mole Trust算法计算出用户社会关系相似度。然后将用户静态偏好相似度、动态偏好相似度和社会关系相似度整合到CF算法中。最后并行在Hadoop平台上。实验部分也证明了USDTCF算法在各项指标中的结果。更进一步的工作是探索更加详尽的分类信息来预测用户对于位置的偏好,从而提高准确率。 [1] Meng X W, Wang F, Shi Y C, et al. Mobile user requirements acquisition techniques and their applications[J]. Journal of Software, 2014,47(4):1261-1263. [2] Tobler W R. A Computer Movie Simulating Urban Growth in the Detroit Region[J].Economic Geography,1970,46(Supp 1):234-240. [3] Lai C H, Liu D R, Lin C S. Novel personal and group-based trust models in collaborative filtering for document recommendation[J]. Information Sciences, 2013,239(1):31-49. [4] Wang G, Xu C, Li D. Generic normal cloud model[J]. Information Sciences, 2014,280(280):1-15. [5] 于亚新, 李玉龙, 刘欣,等. LBSNs中基于用户活动和社交信任的好友及位置推荐算法[J]. 小型微型计算机系统, 2014,35(10):2262-2266. [6] Yin H, Cui B, Chen L, et al. Modeling Location-Based User Rating Profiles for Personalized Recommendation[J]. Acm Transactions on Knowledge Discovery from Data, 2015,9(3):1-41. [7] Mourchid F, Koutbi M E, Wang J. LBRW: A Learning based Random Walk for Recommender Systems[J]. International Journal of Information Systems & Social Change, 2015, 6(3):15-34. [8] Ye M, Yin P, Lee W C, et al. Exploiting geographical influence for collaborative point-of-interest recommendation[C]//International ACM SIGIR Conference on Research and Development in Information Retrieval. ACM, 2011:325-334. [9] Zhang J D, Chow C Y, Li Y. CoRe: Exploiting the personalized influence of two-dimensional geographic coordinates for location recommendations[J].Information Sciences,2015, 293:163-181. [10] Zhang Y F, Zhang M, Liu Y Q, et al.Localized matrix factorization for recommendation based on matrix block diagonal forms[C]//Proc of the 22nd International Conference on World Wide Web,2013:1511-1520. [11] Ortega F,Bobadilla J,Hemando A,et a1.Incorporating Group Recommendations to Recommender Systems:Alternatives and Perfornance[J].Information Processing and Management,2013,49(4):895-901. [12] Sheng B, Sun H Q, Magnor M, et al. Video colorization using parallel optimization in feature space[J]. IEEE Transactions on Circuits and Systems for Video Technology,2014,24(3):407-417. LOCATIONRECOMMENDATIONSYSTEMBASEDONHYBRIDSIMILARITYANDTRUSTPROPAGATION Qi Wenbo Zhang Xihuang (SchoolofInternetofThingsEngineering,JiangnanUniversity,Wuxi214000,Jiangsu,China) Nowadays there are a large number of mobile social applications based on location recommendation. This paper proposes a method to provide a hybrid similarity and trust propagation location recommendation system based on CF algorithm. The scheme consists of three elements, and the user preference is divided into user static preferences and user dynamic preferences. Static user preference is mainly type information and historical evaluation based on the location, and the dynamic user preference is based on geographic information and two-dimensional cloud model. The users’ social relationship is based on the information that is propagated by trust. The advantage of this method is that not only the diversity of user preferences is considered, but also the data sparseness can be effectively alleviated by trust propagation. And apply Hadoop to improve the data processing ability of computing platform. Compared with the existing methods, the proposed location recommendation based on CF algorithm is more accurate and efficient to predict the users’ preferences for new locations. Location recommendation Trust propagation Collaborative filtering MapReduce TP391 A 10.3969/j.issn.1000-386x.2017.09.020 2016-12-19。戚文博,硕士生,主研领域:计算机应用技术。张曦煌,教授。3 实验及结果分析
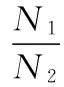
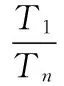
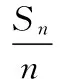


4 结 语
