面向海量地质文档的表格信息快速抽取方法研究
2017-09-18朱月琴李朝奎肖克炎范建福李秋平
李 杨,朱月琴,李朝奎,肖克炎,范建福,李秋平
(1.湖南科技大学地理空间信息技术国家地方联合工程实验室,湖南 湘潭 411201;2.国土资源部地质信息技术重点实验室,北京 100037;3.中国地质调查局发展研究中心,北京 100037;4.中国地质科学院矿产资源研究所,北京 100037;5.西北大学城市与环境学院,陕西 西安 710127)
面向海量地质文档的表格信息快速抽取方法研究
李 杨1,朱月琴2,3,李朝奎1,肖克炎4,范建福4,李秋平5
(1.湖南科技大学地理空间信息技术国家地方联合工程实验室,湖南 湘潭 411201;2.国土资源部地质信息技术重点实验室,北京 100037;3.中国地质调查局发展研究中心,北京 100037;4.中国地质科学院矿产资源研究所,北京 100037;5.西北大学城市与环境学院,陕西 西安 710127)
以Hadoop分布式系统架构中最核心的HDFS和MapReduce为基础,提出了一种面向海量地质文档的表格信息快速抽取的方法。为了提高地质文档表格信息抽取速度,首先利用关键词查找文档在HDFS中存储的根目录,其次利用Hadoop分布式集群中Map函数和Reduce函数实现单元格信息的抽取和信息还原显示,最后对重庆市矿产资源潜力评价成果数据中WORD文档进行表格快速抽取实验。实验证明,本文提出的地质文档表格信息快速抽取方法可以大幅缩减传统单机串行地质文档表格信息抽取所需的时间。
地质文档;表格信息;快速抽取
在文档中,以表格和文本相结合的方式进行信息展示,是当前生活和工作中一种较为简明、规范的文档表现形式[1],使阅读者能够快速抓取文档中的主要信息,很好的提高了工作效率。而当面对海量文档的时候,如何实现快速的表格文档自动化处理[2]一直是国内外专家学者关注和研究的问题。在全国矿产潜力评价成果数据由大量MapGIS格式的图件和数以百万计的地质文档组成,几乎所有的文档都是以表格和文本结合的形式呈现的,所以做到对这样海量的地质文档表格信息的快速抽取对今后矿产潜力评价具有深远的意义。
对于海量的地质文档,主要是对两个方面进行处理:文档中表格的分类;表格信息的提取。本文针对海量地质文档提出一种基于Hadoop云平台的文档中表格信息快速抽取的方法,在原有的单机串行表格信息提取的基础上实现在Hadoop上的MapReduce的并行编程,达到海量文档的表格信息快速抽取的目的。
本文的研究成果致力于对全国矿产预测成果中的文档成果进行表格信息的快速抽取,并对其进行分类、整理、汇总等工作,为后期通过已知矿产预测未知矿产做好前期资料准备工作。
1 表格信息快速提取研究现状分析
1.1表格信息提取
表格作为文档的一部分,在文档内容表现上起着至关重要的作用,是对文本内容的重要补充[3]。在日常生活和工作中得到了极其广泛的应用,例如金融系统的各种票据、申请表、邮政汇款单、公司销售报表等[4]。随着信息化的发展,将纸质文档电子化保存下来,通过版面分析、理解、OCR等技术提取表格中的信息[5],经过进一步加工整理存入数据库,方便以后对这些信息的查询、修改和统计等工作。Chen等[6]在识别表格文档类型和提取数据域信息中用到了水平线和垂直线检测的方法。Fan等[7]一种不需要事先提取数据域的方法提取字符数据。随着时间推移图像质量退化等因素使得这类方法无法正确获取表格数据域信息。还有一些研究表格识别的,可以进行多分类,从文档数据库中找到某个匹配的文档类型作为输入文档的类别,这类方法将文档的整体布局作为分类的参考依据。Lin等[8]利用邻接数据域之间的关系用于文档识别。Tang[9]在中根据表格由水平直线片段和垂直直线片段构成、获取表格信息的区域以表格线为参考提出了表格文档的独特性的概念。
1.2面向信息提取的并行算法研究现状
随着计算机软硬件技术的高速发展,并行计算的门槛被不断拉低。多核处理器、计算机集群等设备为并行计算提供了良好的硬件基础;同时,MPI、CUDA、OpenCL、OpenMP、MapReduce等并行编程模型库的广泛应用提高了并行编程的可扩展性。在此基础上,陈磊等[10]采用并行计算方法对视频、音频等监控设备的多元信息进行提取;柳家福等[11]利用GPU并行计算的优势提出了基于图形处理单元的高光谱岩矿信息快速提取方法;刘军志等[12]对分布式水文模型并行计算的研究现状进行了总结分析,并对其发展进行了讨论。
上述研究之所以要选用并行计算的方法,无非是因为其需要处理的数据量大,传统的串行方法无法满足其快速处理的需要。同样的,当地质文档达到海量时,采用并行计算的方法对其表格信息进行抽取,也能极大地缩短所需的时间。因此,本文研究内容采用Hadoop分布式集群的HDFS存储海量地质文档文件,MapReduce编程负责海量地质文档中表格信息的提取工作。
2 面向海量地质文档的表格信息快速抽取框架及关键技术
2.1面向海量地质文档的表格信息快速抽取框架
针对海量地质文档的表格信息快速抽取模型如图1所示。表格的来源主要由4个方面组成:WORD文档、PDF文档、JPG等图片以及WEB。
对于WORD、PDF等文档类型的文件来说,首先获取文档读取范围,判断读取范围内有无表格,若存在表格,则进行表格识别、表格定位、表格结构识别等工作,最后通过遍历单元格实现表格信息抽取工作。
对于JPG等图片文件,由于图片文件大多都是通过纸质表格扫描成图片格式的,其信息质量低影响信息抽取,是亟待解决的问题。首先,对图片文件进行灰度变换、图像平滑、边缘检测等操作,完成图像预处理去除干扰图像识别的噪音[13]。然后,进行表格特征识别、表格定位、表格结构识别等工作,完成表格信息抽取。
对于WEB表格,采用聚焦网络爬虫中的基于内容评价的爬行策略进行WEB网页的查找工作,然后对所得到的WEB表格判断真伪,剔除为表格,对真表格进行表格结构识别,并做表头和数据部分的拆分操作,最终完成表格信息抽取(图1)。
2.2关键技术及算法设计
2.2.1 不同来源的表格特征识别
根据上述不同的文件来源,本节分别针对上述文件的表格特征识别技术进行详细说明。
2.2.1.1 WORD表格特征的识别
在WORD文档中进行表格特征的识别较为困难的就是对复杂表头的表格进行处理(如下图所示),表头结构上存在包含关系。此类表头的上层对下层是一对多的关系,一般可以采用树形结构或图形结构来表示(图2)。
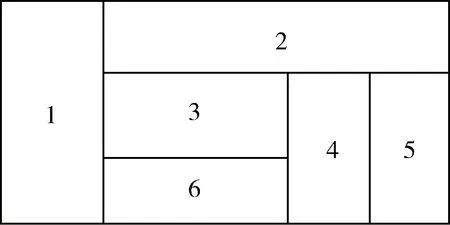
图2 复杂表格表头样式图
对于WORD文档中的表格来说,完成了表头的释义,即可对表格内容进行逐单元格的识别与表征。
2.2.1.2 WEB表格的特征识别
Html对表格有专门的标签定义,表格的主标签为,行标签为,列标签为,属性说明标签跨行(COLSPAN)、跨列(ROWSPAN)等[2]。但对于WEB表格的信息抽取较难处理的是伪表格的识别,例如导航栏、站点广告等是为了界面美观、易读,而不是为了表示真正的数据,这类表格称为伪表格[11]。
识别真伪表格,通常需要构造相应的分类算法,一般是根据表格的特点选取一定的特征量建立模型,目前性能较好的特征模型主要有DOM模型、集合特征模型等,然后利用机器学习模型完成表格真伪的判定,从而剔除伪表格。
2.2.1.3 PDF表格的特征识别
PDF对表格没有做特殊的定义,所以相对于WEB表格特征的提取,PDF的表格提取具有较大的难度。表格的基本信息有框线和文字两部分组成[13],因此对于PDF表格信息提取主要从框线和文字两个方面入手:基于框线的表格还原:此方法的难点在于框线信息的还原处理,当页面存在多个表格或有干扰线时,框线的合理分解具有较大难度;基于文字的栅格化处理:此方法依据文字位置来分析表格的特征。其基本原理是表格的行列之间存在明显的界限,对表格中的文字位置进行栅格化处理,还原出表格的原始框架特征。但对于具有跨行跨列的复杂表格来说,提取的准确率不高是其明显的缺陷。
2.2.1.4 基于JPG等图像的表格特征提取
对于JPG等图像类型的表格识别,关键在于图像的预处理与线条的识别。由于图像采集的原始文件的新旧差异以及采集过程中的环境因素影响,造成图像信息质量较低不利于表格的识别,需要通过灰度变换、图像平滑、边缘检测、二值化、倾斜矫正等算法去除图像中与表格无关的噪音。
2.2.2 面向海量地质文档的表格信息快速抽取
传统的单机串行运行环境难以满足海量地质文档的表格信息快速抽取的需要,如何在现有技术的基础上实现对面向海量地质文档的表格信息快速抽取,是地质大数据处理的关键环节。
Google公司在2004年提出了并发处理海量数据的MapReduce并行编程模型[14]。近年来,很多公司和科研机构都研发了基于MapReduce设计规范的海量数据并行处理系统[15],其中,Apache基金会开发的Hadoop分布式系统基础架构是MapReduce的一种开源实现,也是当前并行处理海量数据的标准式(1)。和传统的并行编程模型相比,它有效降低了并行编程的难度,提高了编程的效率[14]。
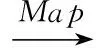
(1)
MapReduce合并了两个经典函数:映射[14](Mapping)和化简[14](Reducing)。
映射(Mapping)对集合里的每一个目标应用同一个操作。在主程序main函数中根据关键词(文件名的一部分或文件名后缀)查找文件存放路径,然后获取文档读取内容确定表格位置,将表格每一行作为一个键值对[17](key-value),Map阶段即是对键值对(iKey-iValue)进行逐单元格迭代拆分并记录成键值对(jKey-jValue),如式(1)前半段所示。此阶段由多个Mapper对同一表格的不同行进行相同的信息抽取操作,伪代码如下。
public class Map extends Mapper
public void map(Object key,Text value,Context context) throws IOException,InterruptedException {
//过滤表头行
String line=value.toString();
If(line.contains(“”)==true){
retune;
}
//根据单元格号记录其内容
}
}
合并(Reducing)遍历集合中的元素并返回一个综合结果[19]。如公式(1)后半段所示,将Map阶段返回的键值对(jKey-jValue)整合成键值对(mKey-mValue),伪代码如下:
public class Reduce extends Reducer
Text result = new Text ();
public void reduce(Text key,Iterable
//将各单元格还原至表样式并显示
}
}
3 面向海量地质文档的表格信息快速抽取实验
3.1实验环境
本文实验环境是在Apache基金会开发的Hadoop分布式系统架构为基础,采用开源的MapReduce并行编程模型进行开发。搭建了Hadoop分布式集群(Hadoop版本2.7.2),其中1个主控制节点(命名为hdmaster),另外3台工作节点(命名为hadoop002-hadoop004),Zookeeper3个(分别命名为zk01-zk03)。实验集群配置见表1。
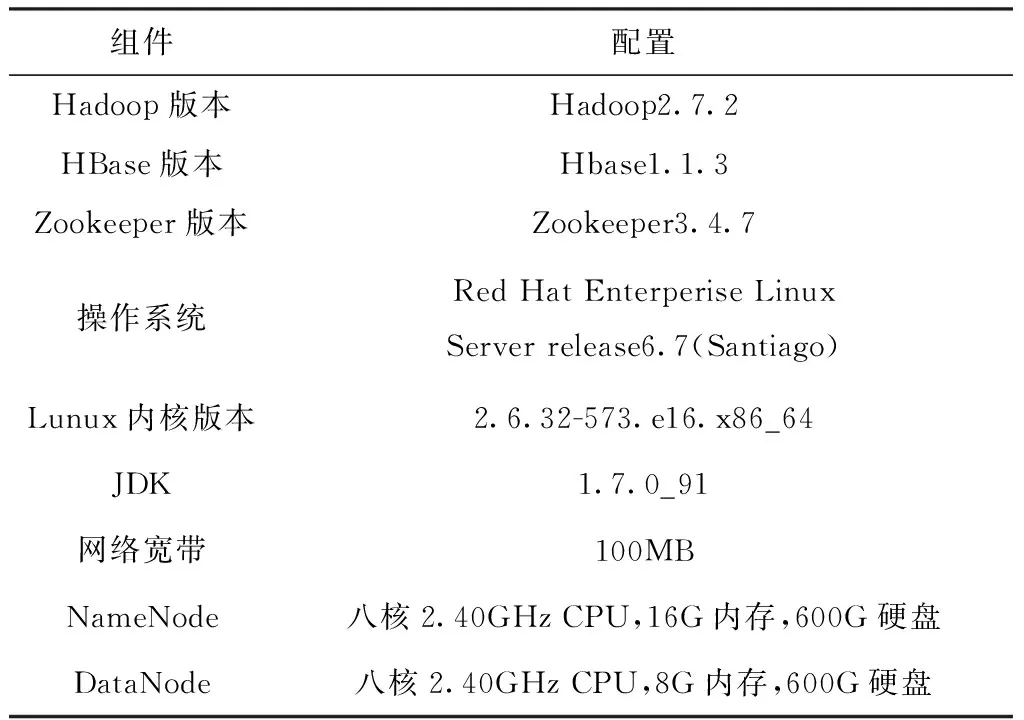
表1 Hadoop集群配置表
3.2实验结果
本实验对重庆市矿产资源潜力评价成果数据中的硫铁矿文档表格信息作为研究对象,选取了成矿要素图编图说明书作为标题关键字进行地质文档筛选,表格信息中“矿物组合”这一项进行信息快速抽取与整合工作。实验结果筛选出标题为“*成矿要素图编图说明书”的地质文档16个,对文档中的表格(原文档表格样式如表2所示)信息进行快速抽取与信息整合,并对表头进行规范化设置后其结果示意图如表3所示。
3.3对比分析
首先,对地质文档进行传统单机串行实验,实验结果如图3所示。
为验证海量地质文档表格快速抽取的实际效率,本文选取了重庆市矿产资源潜力评价成果数据中的WORD文档文件数据作为实验数据进行表格信息抽取工作。该计算实例中包括25个矿种,5 813个WORD文档,通过改变不同数量的文档,依次对该计算实例进行计算实验,计算结果见表4。
本实验结果为对不同数量的地质文档分别进行10次实验,剔除首次运行时间,并对其他9次结果去除特殊值后求其平均值所得。为了更明显看出结果的对比性,分别做如图4所示的基于Hadoop的MapReduce地质文档表格信息抽取时间、图5所示的传统单机串行文档表格信息抽取与MapReduce表格信息抽取结果对比图。
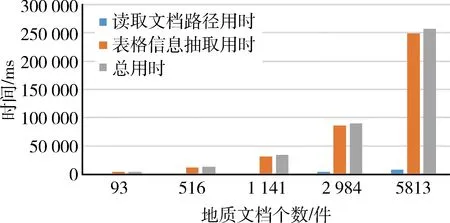
图3 传统单机串行文档表格信息抽取
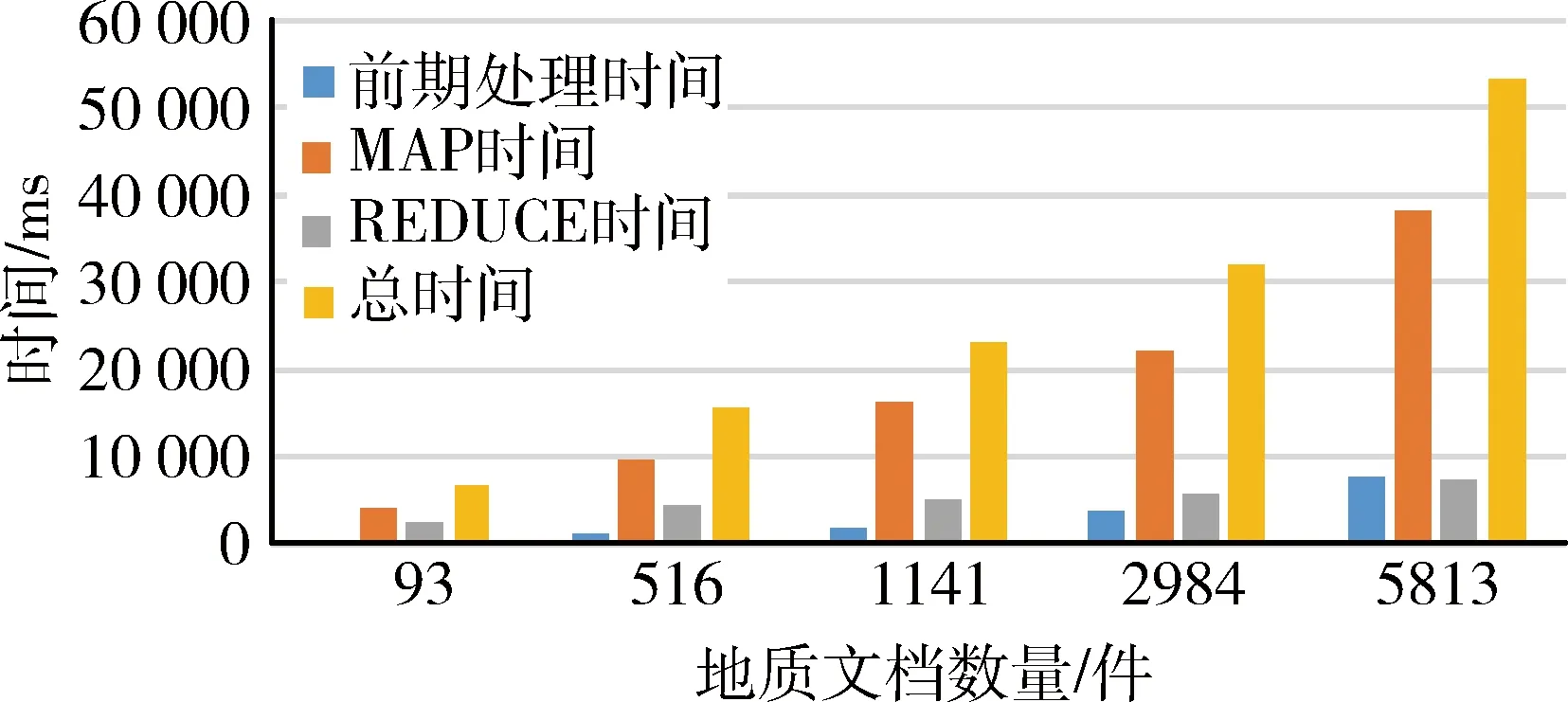
图4 基于Hadoop的MapReduce地质文档表格信息抽取时间
传统单机串行地质文档表格抽取结果与基于Hadoop的MapReduce地质文档表格抽取结果对比如图5所示,当文档数量较少时,由于MapReduce运行过程中需要Map和Reduce之间通信等原因,传统单机串行地质文档表格抽取所需时间占有一定的优势;随着地质文档数量增加,传统单机串行地质文档表格抽取压力不断增大,而基于Hadoop的MapReduce地质文档表格抽取具有较大优势,可很大的缩短表格信息抽取所需的时间。
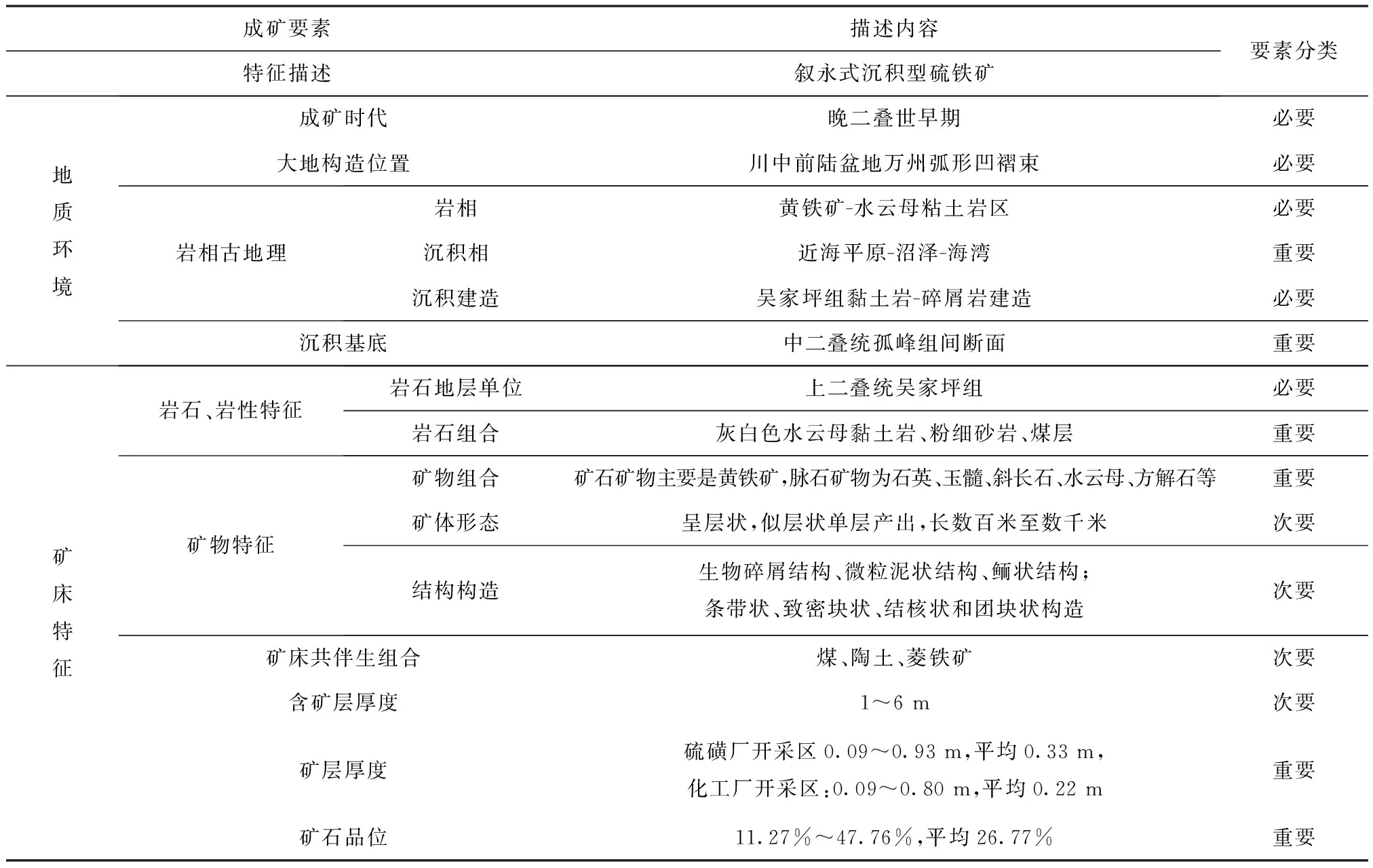
表2 原文档中表格样式示意图

表3 地质文档表格信息抽取结果示意图

表4 海量地质文档表格信息快速提取计算结果
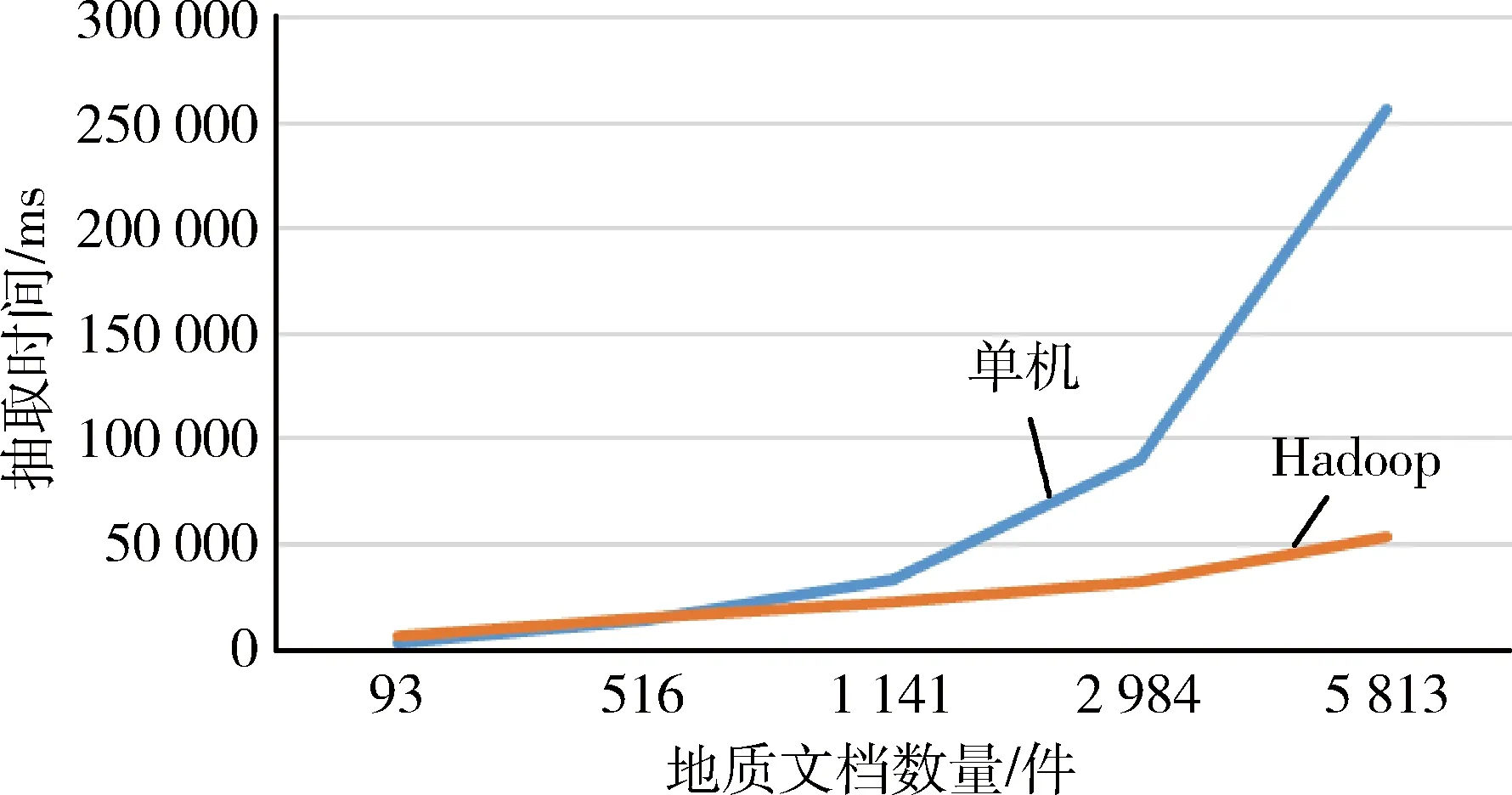
图5 传统单机串行文档表格信息抽取与MapReduce表格信息抽取结果对比图
4 结 论
为了提高地质文档表格信息抽取速度,本文以Hadoop分布式系统架构中最核心的HDFS和MapReduce为基础,提出了一种面向海量地质文档的表格信息快速抽取的方法。该方法首先利用关键词查找文档在HDFS中存储的根目录,其次利用Hadoop分布式集群中Map函数和Reduce函数实现单元格信息的抽取和表格还原显示。为验证该方法对文档表格信息抽取的速度,本文就该方法对重庆市矿产资源潜力评价成果数据中的文档成果进行了不同个数虚拟机和不同数据量的实验。实验结果表明,当文档个数达到一定数量时,该方法的表格信息抽取速度远大于传统的单机串行表格信息抽取速度,达到了地质文档表格信息快速抽取的目的。
[1] 秦振海,谭守标,徐超.基于WEB的表格信息抽取研究[J].计算机技术与发展,2010,20(2):217-220.
[2] 刘颖.基于WEB结构的表格信息抽取研究[D].合肥:合肥工业大学,2012.
[3] 赵洪,肖洪,薛德军,等.WEB表格信息抽取研究综述[J].现代图书情报技术,2008(3):24-31.
[4] 刘兵.表格文档图像分析方法研究[D].上海:上海交通大学,2013.
[5] 曾广朴,陶维安.基于信息量的WEB表格信息抽取方法[J].西南师范大学学报:自然科学版,2010,35(4):159-163.
[6] Chen,J.L.,Lee,H.J.An efficient algorithm for form structure extraction using strip projection[J].Pattern Recognition 1998,31(9):1353-1368.
[7] Fan,K.C.,Lu,J.M.,Wang,L.S.,et al.Extraction of characters from form documents by feature point clustering[J].Pattern Recognition,1995,16(9):963-970.
[8] Lin.J.Y.,Lee,C.W.,Chen,Z.Identification of business forms using relationships between adjacent frames[J].Machine Vision and Applications.1996.9(1):56-64.
[9] Tang Y.Y.,Lee.S.W.,Suen,C.Y.Automatic document processing:a survey[J].Pattern Recognition 1996,29(12):1931-1952.
[10] 陈磊.基于监控信号的多信息提取识别的并行计算方法[D].南京:南京理工大学,2015.
[11] 柳家福,吴泽彬,刘天石,等.基于GPU的高光谱遥感岩矿信息快速提取方法[J].中国科技论文,2014,9(10):1137-1143.
[12] 刘军志,朱阿兴,秦承志,等.分布式水文模型的并行计算研究进展[J].地理科学进展,2013,32(4):538-547.
[13] 闫丹凤.一种面向PDF文件的表格数据抽取方法的研究与实现[D].北京:北京邮电大学,2014.
[14] 徐飞,张素芹,姚红革.面向结构的WEB表格数据抽取系统[J].西安工业大学学报,2009,29(6):574-578.
[15] 李建江,崔健,王聃,等.MapReduce并行编程模型研究综述[J].电子学报,2011,11(11):2635-2642.
[16] 李伟卫,赵航,张阳,等.基于MapReduce的海量数据挖掘技术研究[J].计算机工程与应用,2013,49(20):112-117.
[17] 和亮,冯登国,王蕊,等.基于MapReduce的大规模在线社交网络蠕虫仿真[J].软件学报,2013,24(13):1666-1682.
[18] 梅华威,米增强,吴广磊.基于MapReduce模型的间歇性能源海量数据处理技术[J].电力系统自动化,2014,38(15):76-80.
[19] 潘巍,李战怀,伍赛,等.基于消息传递机制的MapReduce图算法研究[J].计算机学报,2011,34(10):1768-1784.
Studyontherapidextractionoftableinformationformassgeologicaldocuments
LI Yang1,ZHU Yueqin2,3,LI Chaokui1,XIAO Keyan4,FAN Jianfu4,LI Qiuping5
(1.National-Local Joint Engineering Laboratory of Geospatial Information Technology,Hunan University of Science and Technology,Xiangtan411201,China;2.Key Laboratory of Geological Information Technology of Ministry of Land and Resources,Beijing100037,China;3.Development and Research Center,China Geological Survey,Beijing100037,China;4.Institute of Mineral Resources,Chinese Academy of Geological Sciences,Beijing100037,China;5.College of Urban and Environmental Science,Northwest University,Xi’an710127,China)
Based on the most core HDFS and MapReduce in Hadoop distributed system architecture,a rapid extraction method of table information for massive geological documents is proposed.In order to improve the extraction speed of geological information document form,first of all,using the key WORDs to find documents stored in the HDFS root directory,then,using the Hadoop distributed cluster Map function and a Reduce function reduction cell information extraction and information,according to the mineral resources potential evaluation result data in Chongqing in WORD document form rapid extraction experiments.It is proved that the method of rapid extraction of geological document table information in this paper can greatly reduce the time needed to extract the information of the traditional single-machine serial geological document form.
geological document;table information;rapid extraction
2017-07-07责任编辑:赵奎涛
国土资源部公益性行业科研专项项目资助(编号:201511079)
李杨(1993-),男,硕士研究生,主要从事地质大数据技术研究工作,E-mail:Liyang_Click@outlook.com。
朱月琴(1975-),女,博士,高级工程师,主要从事地质大数据、地图综合与可视化研究工作,E-mail:yueqinzhu@163.com。
P208
:A
:1004-4051(2017)09-0098-06
