基于大数据分析挖掘的地质文献推荐方法研究
2017-09-18张戈一胡博然常力恒朱月琴2吕鹏飞
张戈一,胡博然,常力恒,朱月琴2,,吕鹏飞
(1.中国矿业大学(北京),北京 100083;2.国土资源部地质信息技术重点实验室,北京 100037;3.中国地质调查局发展研究中心,北京 100037;4.中国地质大学(北京),北京 100083;5.中国地质图书馆,北京 100083;6.中国科学院大学,北京 100049)
基于大数据分析挖掘的地质文献推荐方法研究
张戈一1,2,胡博然3,4,常力恒3,朱月琴2,3,吕鹏飞5,6
(1.中国矿业大学(北京),北京 100083;2.国土资源部地质信息技术重点实验室,北京 100037;3.中国地质调查局发展研究中心,北京 100037;4.中国地质大学(北京),北京 100083;5.中国地质图书馆,北京 100083;6.中国科学院大学,北京 100049)
地质图书馆书籍多,数据资料庞大,然而却存在数据资料增长过快和难以发现读者兴趣点的问题。实现高效的图书馆借阅数据挖掘分析与推荐,是提高效率的重要手段。为此本文提出了基于大数据地质文献分析挖掘平台,包括聚类分析,中文分词,推荐系统,关联分析功能,再通过Hadoop集群多节点进行推荐,从而提高了工作的效率。
大数据技术;分词技术;推荐系统;并行计算
随着图书馆馆藏文献资源的不断丰富,读者往往遇到两类问题。第一类问题就是读者学习能力无法匹配信息量的爆炸增长,数据资料增长过快,全球新产生的数据平均每隔三年就会增长一倍。截至2010年底,清华图书馆机房有110台服务器,集中存储170 TB的数据资料,而国家图书馆资源总量更是470 TB。这些分布在不同系统中的形态不同、结构方式各异的资源,既包括传统文献,也包括各种类型的数字化资源,还包括其它虚拟馆藏等各种多媒体资源,各种资源的积累,给图书馆提供了海量数据[1]。第二类问题是读者如何从极度丰富的信息中发现自己的兴趣点。读者对地质图书文献有一定的需求,在线浏览的过程中,如何精准的找到自己想要的资料。大数据时代下,如何以“大数据”为基础,从大量的数据中方便快捷的发现用户的行为特征、定制自己的需求[2]。
1 大数据分析挖掘地质图书服务带来的机遇和挑战
1.1大数据分析挖掘带来的挑战
地质文献资料可以利用大数据分析挖掘技术,提供定制化。基于大数据分析挖掘的方式,通过数据的提取、清洗、转化,实现知识多维度、多层次的关联分析,建立读者文献关系网络,利用该网络了解用户的行为、业务需求,向用户做准确信息推送。大数据具有挖掘、发现、预测的能力,大数据背景下通过深层次的数据分析,包括关联分析,聚类分析,决策分析等方法,图书馆不仅可以了解当前读者需要什么服务,还能够准确分析和预测读者未来的服务需求,为未来需求提前做准备。在大数据时代,图书馆服务将很大程度上依靠数据分析、数据挖掘而形成的新规律、新知识,从而提升服务质量[3]。
1.2大数据分析挖掘的研究应用现状
大数据时代,人们在不断探求大数据与数字图书馆的融合点,国外学者在理念、技术和应用方面做了许多研究。Renaud借助大数据技术,探索学生与数字图书馆的交互过程,分析不同的交互维度、子维度及其相关指标对于数字图书馆交互功能的关联性[4]。在技术方面,美国加州大学洛杉矶分校的Brewster Kahle等正在着手构建一个巨大的数字化图书馆,那里收录了几乎所有曾经出版的书籍、电影以及各个方面的历史网页,使数字图书馆更好地融于互联网,更好地利用大数据。在国内研究方面也有许多相关成果和理念,曾建勋等[5]提出利用现有的大数据平台技术,在全国范围内推动图书馆大数据数字化平台建设。陈传夫等[6]阐明了大数据环境下应对非结构化数据管理的问题,应形成一种新型的、分布式的和整合式的资源集成平台。刘炜等[7]强调在大数据时代数字图书馆阐述了对于图书馆在Web上发布书目数据和规范数据的重要意义,认为关联数据与网络时代的图书情报工作关系密切。陈臣[8]提出大数据时代下的“小数据”具有更高的决策价值。陈茫等[9]阐述大数据技术已经对移动技术产生冲击,二者的结合更加深入人心。樊伟红等[10]重点探讨了图书馆大数据建立各种风险评估模型以及用户流失和价值分析等问题;王天泥[11]提出在图书馆领域应用“3A5步法”的新模式。Chen Ming等[12]探讨了图书馆大数据的存储、数据挖掘以及个性化服务等具体技术,提出以Hadoop+MapReduce并行架构的大数据应用方案。综上所述,通过大数据的方式进行地质文献的分析挖掘,推荐预测是切实可行的。
2 现有文献推荐推荐模型对比
现有的智能文献推荐方法,比较主流的有三种:基于内容推荐法、协同过滤推荐系统法和关联规则推荐法。三种推荐方式,对于源数据的种类不同,应用的方式也就不同。基于内容推荐法,其核心是内容过滤,扫描出推荐内容与读者需求内容的相似,从而对读者进行推荐。但由于这种系统不能发现用户的新要求,只能推荐用户以前阅读过程中出现的主题,因此该方法应用有所限制[13-17]。协同过滤推荐系统法:其核心是针对特定读者群体或者书籍群体,基于读者的协同过滤推荐,通过读者对于资源的评价,匹配不同读者的之间的相似度,寻找偏好相似的读者,对偏好相似的读者匹配的一种推荐方式;基于书籍的协同过滤推荐法是寻找书籍之间的相似度,对书籍相似度较大从而进行推荐的一种方式。但随着资源与读者数量的增加,对于计算机处理能力要求也随之增长,而且此类方法的性能发挥依靠读者的评价,应用难度比较大。基于关联分析的推荐系统法,其核心是数据匹配、聚类等数据挖掘方法[18-20]。综上所述,单独的推荐系统在高校图书馆的实际应用过程中暴露出了一系列的问题,例如:校内信息资源利用率不高、推荐输出不稳定、精准度较低等[15-17]。
3 基于大数据平台的地质文献推荐
大数据环境下推荐系统的主要可以从以下几个方面阐述:①数据处理需要更高的能力,数据量增多,数据维度广,数据稀疏性大,数据冗余多等问题,均需特殊关注;②地质图书馆的数据宜采用隐式反馈数据。读者看不到利益的情况下,需要额外的付出,很难获得主观评分,从而导致质量不高;③由于数据更新速度较快,需要以数据的增量为主,以便及时进行动态更新;④丰富的信息对准确性的提高提供了便利,在大数据环境下,同时面临这信息过载的问题,需要通过手段筛选出有用的信息[21](表1)。
3.1地质大数据分析挖掘平台
地质资料是地质工作人员长期积累形成的重要知识成果,由于地质资料的管理分散,使得资料用于共享,服务,使用等用途相对薄弱,制约了地质资料发挥其潜在的科研价值。针对此问题,我国地质领域开展了地质信息化研究,目的是对地质资料的集成集群和深度开发,使得地质资料从分散的各处得意集中到几台服务器上,从而实现信息共享,消除信息孤岛。Hadoop是大数据应用最广泛的开源分布式文件存储及处理框架[22]。Hadoop核心模块包括HDFS与MapReduce。Hadoop是一个较为稳定的管理平台,以HDFS、MapReduce为基础,用HDFS提供的分布式计算存储作为底层支持,能够运行数量庞大的PC server组成的集群。部署于平台上的软件,可以采取多种语言编辑,其中最基本的语言包括Java、Python、R语言等。在此基础上通过Java、R等语言建立了书籍借阅分析挖掘软件,其主要功能包括:聚类分析、关联挖掘、中文分词、推荐决策功能。聚类分析功能主要针对不同种类的书籍借阅数量往往不同的问题,根据聚类分析得出借阅该种类书籍的数量,数量用箱型线表示,说明借阅数量上下有波动,方便读者一次性借阅准确的数量。关联分析功能可以输出大部分读者借阅该种图书后,后续借阅图书的种类,对于读者借阅有指导性意义。功能界面如图1和图2所示。

表1 大数据环境下推荐系统与传统推荐系统的差异
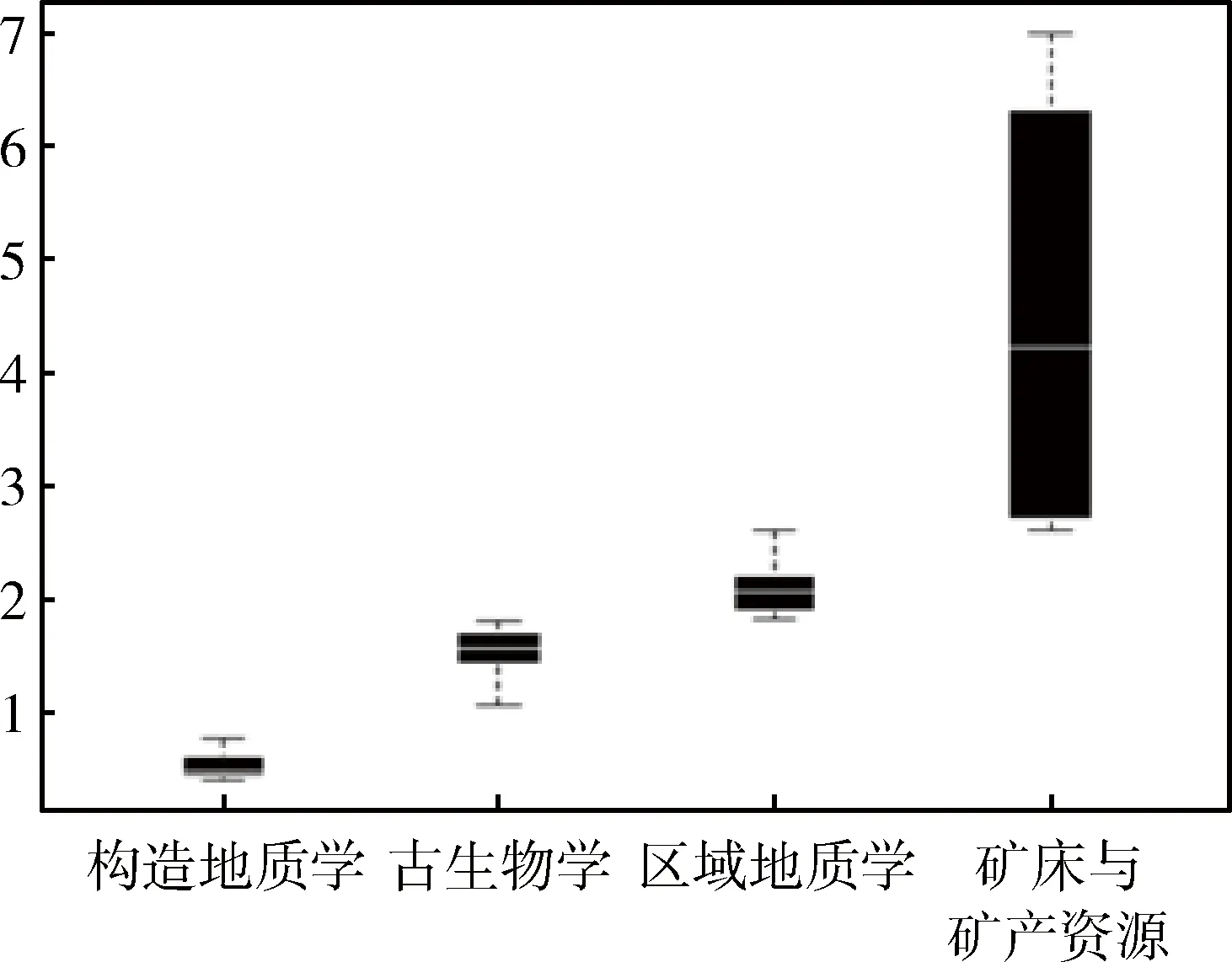
图1 聚类分析结果图
3.2地质数据来源
为了有效地通过数据挖掘来真实反映出读者的借阅需求,必须要求分析的数据样本量足够大。本文采用中国地质图书馆2014~2015年借阅记录共18 438条记录。中国地质图书馆图书管理自动化系统是以SYBASE进行开发的数据库系统,该系统包含大量的数据表,根据数据挖掘的需要设置限制条件,通SQL语句从众多的数据表中提取相关数据。其中2014年的借阅数据作为训练数据,2015年的借阅数据作为评价结果的测试数据。数据格式见表2。
3.3基于自然语言处理的文献信息预处理
中文自动分词语技术是重要的地质资料与地质文献智能分析挖掘的预处理技术。分词技术包括三种,基于统计的分词方法、基于理解的分词方法和基于匹配的分词方法。北京航空航天大学的CDWS是我国第一个实用的自动分词系统,此后分别由山西大学、北京航天航空大学、清华大学、复旦大学、哈尔滨工业大学、杭州大学、微软、北京大学、中国科学院等不同机构开发了一些比较著名的、有代表性的分词系统[23]。本文采取基于统计与匹配的混合分词方法。基于字典匹配的分词方法可以精确切分出现在词典中的词语,但是无法处理歧义字段;基于统计的分词方法可以处理未登录的专有名词和歧义字段,但是需要大量的词频计算耗费时间,并且准确率相比匹配法相对较低,将二者结合可以从一定程度上提高分词的效率。经处理后的分词词频部分结果统计如图3所示。
在提升分词效果方面,已有很多人致力于未登陆词识别的研究,并取得了较好的效果,具体处理方式分两类,即通过句法和语义分析处理和利用统计的方法来解决。例如杜丽萍等[24]提出的利用大规模语料库进行新词发现,用新词发现结果编纂用户词典,加载到分词系统中。新词发现的原理是确定2元待扩展种子,将2元待扩展种子扩展至2~n元,过滤候选新词,人工判定。其算法的关键点是通过计算PMI值将结果量化,方便进行筛选和比较。彭琦等[25]提出了基于词频歧义消解的中文分词方法,其核心思想是在歧义字段出现后,利用正则表达式,将歧义字段通过不同形式表达出来,比较二者的比值,若超过设定的阈值,则消除歧义。中国科学院计算技术研究所研制的中文词法分析系统实际使用的分词系统都是把使用词表的机械分词为一种初分手段,再利用其他的词类信息来进一步提高切分的准确率,包括未登录词的识别。而歧义切分和未登录词识别,则是分词技术的难点,也是现阶段所有自动分词算法热点问题。从中文分词的研究来看,至今还没有哪一种方法可以完全解决中文分词过程中遇到的所有问题,并且各种解决方法也各有优劣。
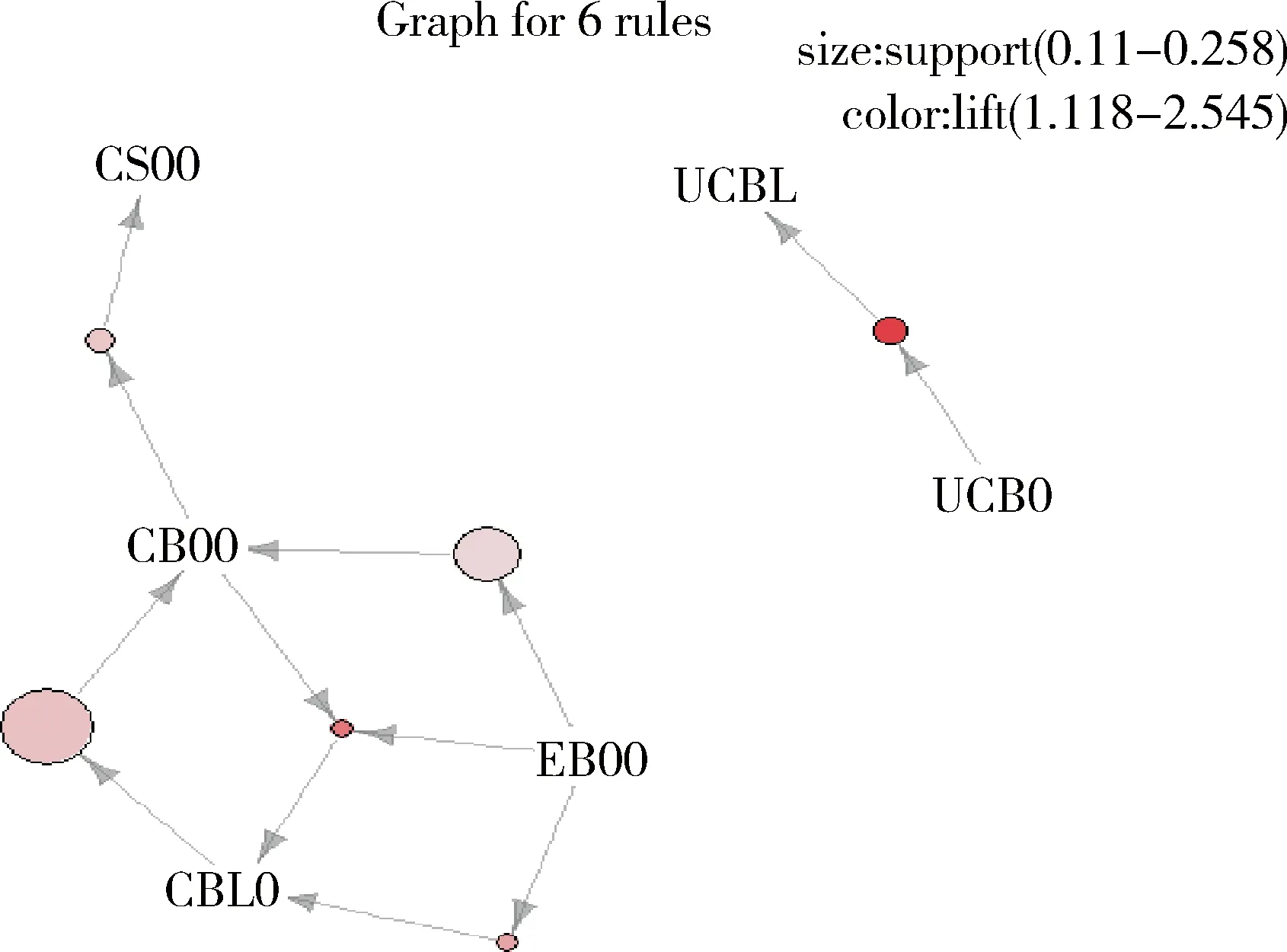
图2 关联分析结果图
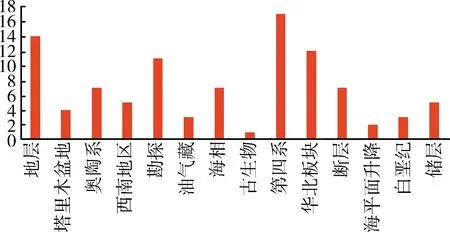
图3 词频统计结果图
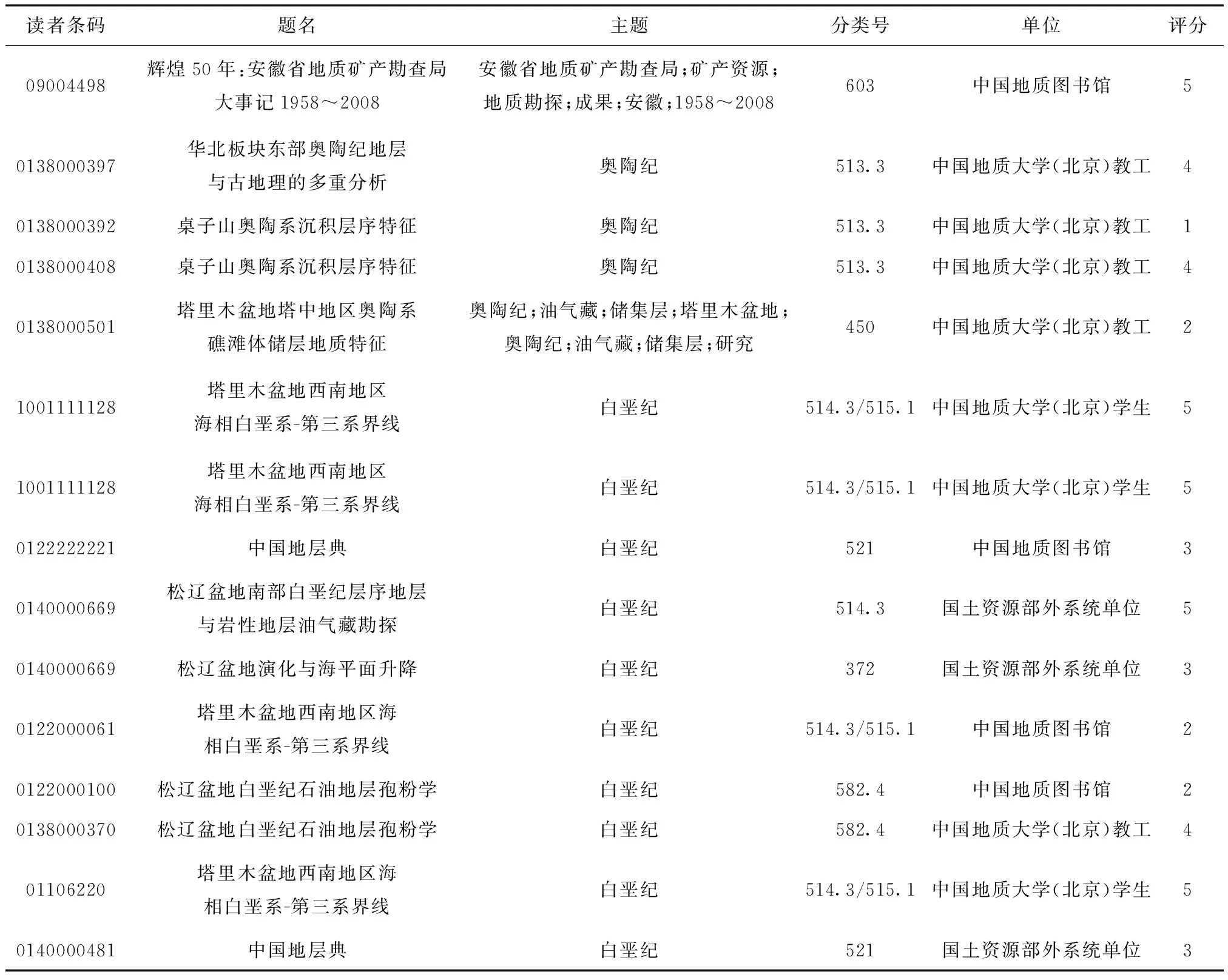
表2 原数据格式表
3.4地学文献推荐模型以及并行计算
耦合协同过滤和关联分析的算法[26]在论文中已经提及,为了进一步提高工作效率,在原有的推荐模型上,采取并行计算的方式。
由于原始数据并没有涉及到评分问题,或者有少许部分评分导致了推荐稀疏性的问题,为了解决此问题,统一采取人为规定还书时间与借书时间的差值作为评分的依据。书籍节约有效期一般为三个月,以三个月为期限,将对书籍的评分分为1~5,当借阅时间少于一个星期,定义为无兴趣书籍类型,借阅时间超过一星期,少于一个月定义为低阅读兴趣,依次类推,当书籍超过有效期,并由借阅者提出续借请求时,定义为最有兴趣图书。在耦合算法计算过程中,先通过分词结果中的关键词,匹配图书种类,如关键词“白垩纪”会匹配到具体类别“古生物学/微体古生物学”,关键词“海平面升降”会匹配到“沉积学、沉积岩岩石学”等(图5)。
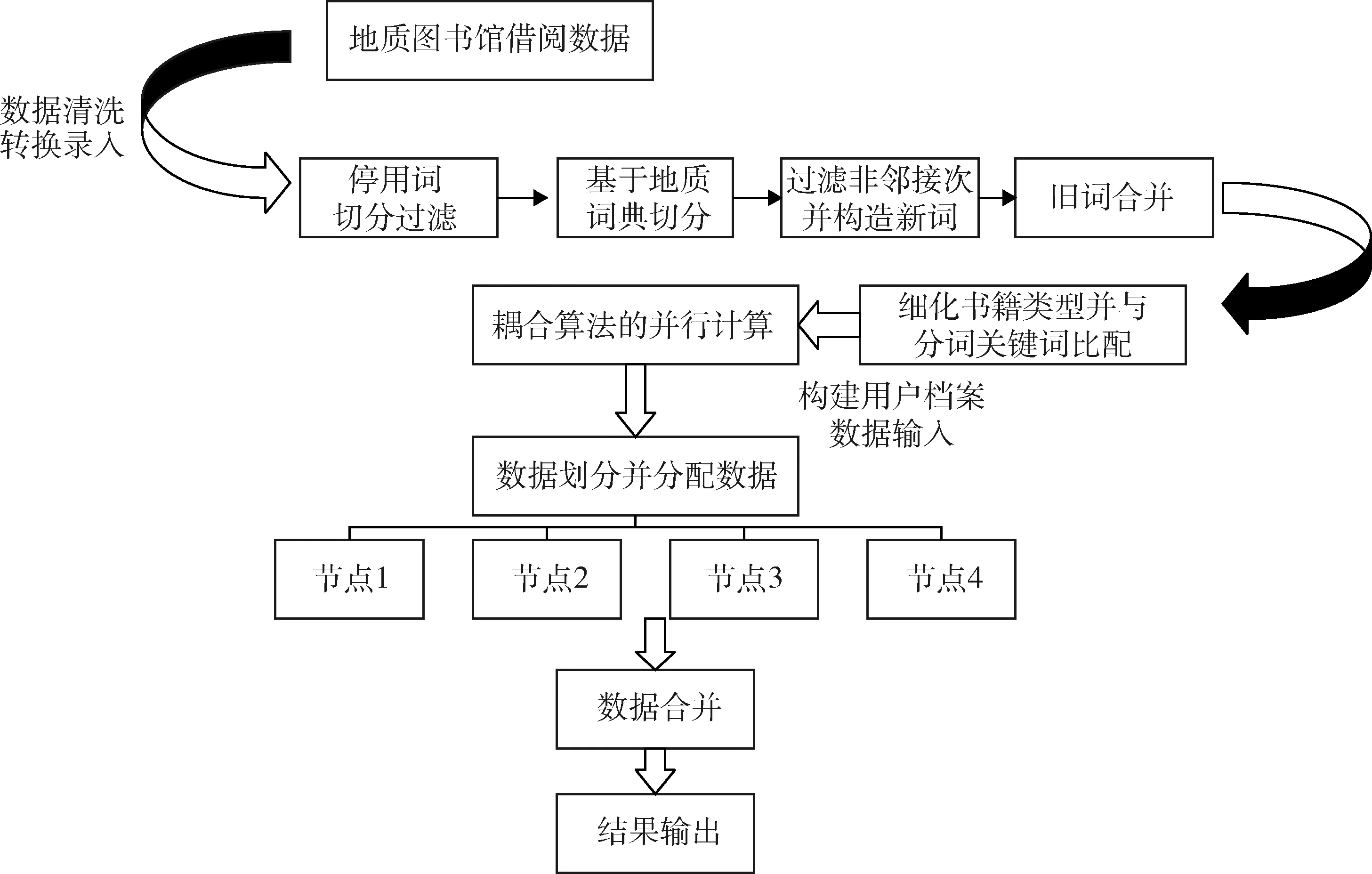
图4 算法流程框架模型
3.4.1 硬件环境
测试用到的硬件环境,其中window环境下采用单节点,基于Hadoop集群在电脑上部署的集群,其中,3台PC作为DataNode,1台PC作为NameNode。

图5 荐结果图

表3 硬件环境表
3.4.2 对比实验
为了对比推荐模型在单节点数和多节点数下的工作效率,将图书馆借阅元数据推荐系统最大节点数设置为4,在试验中用来实验的数据量分别为180条、1 800条、18 000条、36 000条、72 000条,每组数据实验三次,取平均值作为实验结果如图6所示。
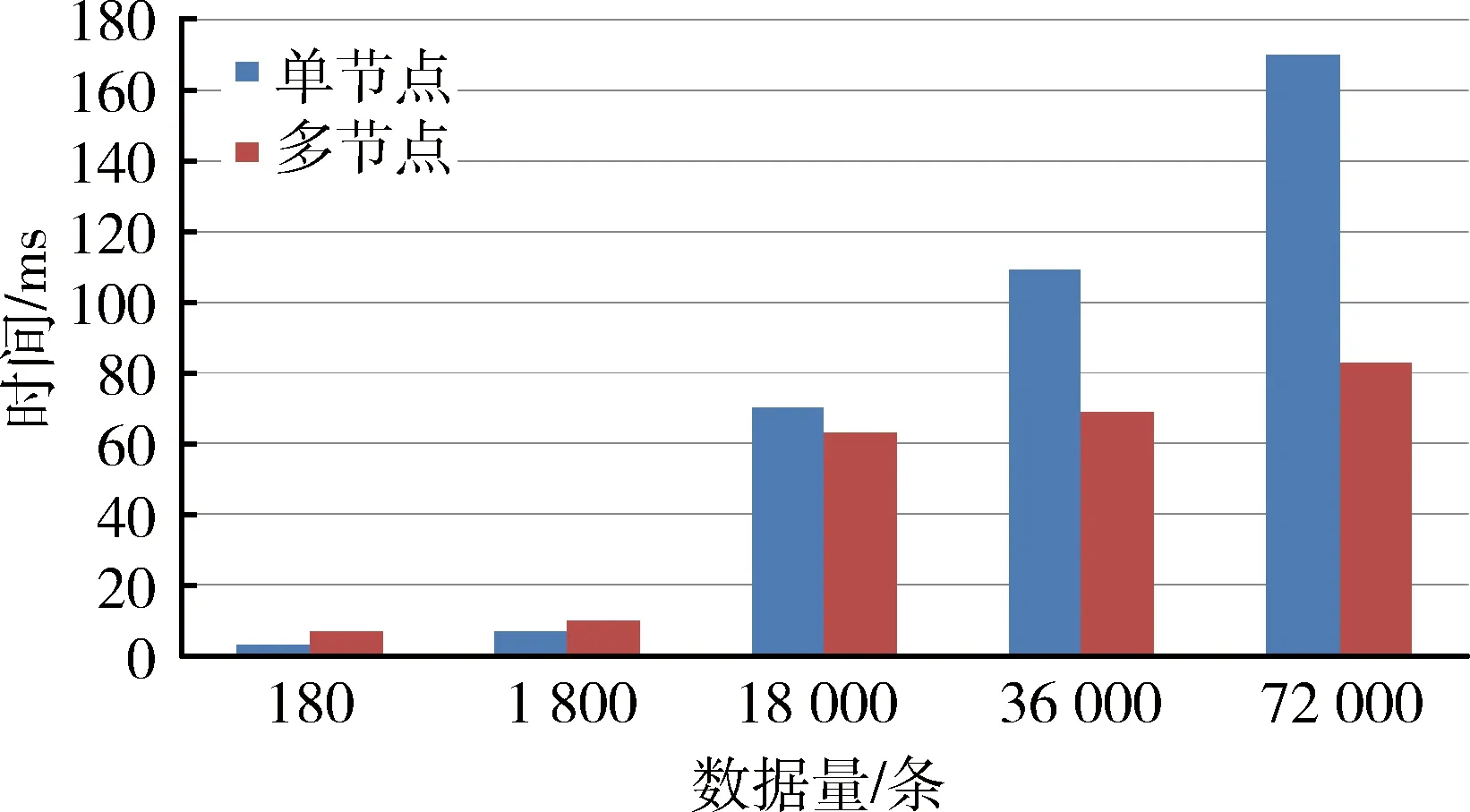
图6 对比实验结果图
从图6中可以看出来,在借阅数据分别为180条和1 800条的时候,单节点的运行速度是少于多节点的运行速度,是因为在做并行计算的过程中,单节点不涉及到数据分配到各个节点直接进行推荐算法的运行,时间相比多节点先分配再计算要短;当借阅数据超过18 000条时,单节点的算法的运行时间明显比多节点运行时间要长,而且随着数据量的不断增加,单节点的算法运行时间增加明显,也就是说,在大数据的环境下,并行计算具有明显的优势,提高了推荐系统的效率。
4 结论与展望
当数字图书馆朝着智能化方向发展,能给读者提供更灵活且针对性强的图书推荐服务。随着大数据技术的发展和应用,如果在大量样本或是全样本的学习下,这部分的研究应该能得到更大程度的提供。利用目前流行的Hadoop技术和自然语言处理技术,再进一步采集用户信息,构建用户智能信息模型的基础上,直接针对书籍全文信息构建基于用户的知识智能提取,达到服务的多粒度,如在更准确的提供书籍推荐的同时,也可以直接特定用户提供知识片段服务等等。
[1] 朱静薇,李红艳.大数据时代下图书馆的挑战及其应对策略[J].现代情报,2013,33(5):9-13.
[2] 周斌.大数据带给图书馆的机遇和挑战[J].内蒙古科技与经济,2017(4):152-154.
[3] 刘海鸥.面向云计算的大数据知识服务情景化推荐[J].图书馆建设,2014(7):31-35.
[4] Renaud Kiesgende RICHTER.Book review.:solar chimney power generating technology[J].Journal of Zhejiang University-Science A(Applied Physics & Engineering),2017,6:496.
[5] 曾建勋,邓胜利.国家科技图书文献中心资源建设与服务发展分析[J].中国图书馆学报,2011,37(2):30-35.
[6] 陈传夫,钱鸥,代钰珠.大数据时代的数字图书馆建设研究[J].图书情报工作,2014,58(7):40-45.
[7] 刘炜.关联数据:概念、技术及应用展望[J].大学图书馆学报,2011,29(2):5-12.
[8] 陈臣.基于小数据决策支持的图书馆个性化服务[J].图书与情报,2015(1):82-86.
[9] 陈茫,周力青,吕艳娥.大数据时代下的图书馆移动服务创新研究[J].图书与情报,2014(1):117-121.
[10] 樊伟红,李晨晖,张兴旺,等.图书馆需要怎样的“大数据”[J].图书馆杂志,2012(11):63-68, 77.
[11] 王天泥.大数据技术在图书馆阅读推广中的应用——以“3A5步”法为例[J].情报资料工作,2014,35(4):96-99.
[12] ChenMing, WangKai, Zhang Qingfei.Speed and Trend of China's Urbanization:a Comparative Study Based on Cross-Country Panel Data Model[J].China City Planning Review, 2015, 2:6-13.
[13] 徐敏,杨应全.高校图书馆资源联合共享的学科发展热点推荐平台研究[J].图书馆工作与研究,2012(2):37-40.
[14] 余肖生,程怡凡.基于关键词集合的信息搜索推荐研究[J].图书馆学研究,2012(7):65-68.
[15] 唐秋鸿,曹红兵,唐小新,等.高校图书馆个性化专题推荐研究[J].图书馆学研究,2012(13):53-58, 24.
[16] 董娟,郑春厚,李秀霞.基于复杂网络的图书馆个性化推荐服务[J].高校图书馆工作,2012(3):82-84.
[17] 王秀秀,武和平.基于“云计算”的数字学术资源整合策略与服务模式研究[J].电化教育研究,2012(6):72-74, 93.
[18] 黄晓斌.基于协同过滤的数字图书馆推荐系统研究[J].大学图书馆学报,2006,24(1):53-57.
[19] 李克潮,黎晓.个性化图书推荐研究[J].图书馆学研究,2011(20:65-69.
[20] 孔功胜.个性化推荐在图书馆信息服务系统中的应用[J].图书馆学刊,2011(10):120-122.
[21] 孟祥武,纪威宇,张玉洁.大数据环境下的推荐系统[J].北京邮电大学学报,2015,38(2):1-15.
[22] 伍锦程,韩媛,张涛.浅谈Hadoop和PostgreSQL在地质资料集群化中的适用性[J].图书情报导刊,2016,1(4):131-134.
[23] 朱月琴,谭永杰,张建通,等.基于Hadoop的地质大数据融合与挖掘技术框架[J].测绘学报,2015,44(S1):152-159.
[24] 杜丽萍,李晓戈,于根,等.基于互信息改进算法的新词发现对中文分词系统改进[J].北京大学学报:自然科学版,2016,52(1):35-40.
[25] 彭琦, 朱新华, 陈意山.一种基于词频歧义消解的通用中文分词法[J].广西师范大学学报:自然科学版, 2016, 34(1):59-65.
[26] 张戈一,朱月琴,吕鹏飞,等.耦合协同过滤推荐与关联分析的图书推荐方法研究[J].中国矿业,2017,26(S1):425-430.
Basicsbigdateanalysisanalyticexcavationgeologyreferencerecommendationmethodresearch
ZHANG Geyi1,2,HU Boran3,4,CHANG Liheng3,ZHU Yueqin2,3,LYU Pengfei5,6
(1.China University of Mining and Technology(Beijing),Beijing100083,China;2.Key Laboratory of Geological Information Technology of Ministry of Land and Resources,Beijing100037,China;3.Development and Research Center,China Geological Survey,Beijing100037,China;4.China University of Geosciences(Beijing),Beijing100083,China;5.China Geological Library,Beijing100083,China;6.University of Chinese Academy of Sciences,Beijing100049,China)
Geological library has a large number of books and data are huge.It is difficult to solve that data grows too fast and it is difficult to find the reader’s point.To achieve efficient library borrowing data mining analysis and recommendation,is an important means to improve efficiency.For this reason,this paper puts forward a large-scale data mining platform,including clustering analysis,Chinese word segmentation,recommendation system,correlation analysis function,and then through hadoop cluster multi-node recommendation,thus improving the efficiency of the work.
big date technology;word segmentation technology;recommended system;parallel computing
2017-07-09责任编辑:赵奎涛
国土资源部公益性行业科研专项项目资助(编号:201511079)
张戈一(1992-),男,汉族,硕士研究生,主要从事地质大数据分析挖掘、自然资源综合评价、数值模拟研究方面工作,E-mail:529324252@qq.com。
朱月琴(1975-),女,博士,高级工程师,主要从事地质大数据、地图综合与可视化研究工作,E-mail:yueqinzhu@163.com。
P208
:A
:1004-4051(2017)09-0092-06
