基于行为和结构特征的相似语义工作流检索
2017-09-15孙晋永古天龙闻立杰钱俊彦
孙晋永 古天龙 闻立杰 钱俊彦 孟 瑜
1(西安电子科技大学计算机学院 西安 710071)2(广西可信软件重点实验室(桂林电子科技大学) 广西桂林 541004)3 (清华大学软件学院 北京 100084)
基于行为和结构特征的相似语义工作流检索
孙晋永1,2古天龙2闻立杰3钱俊彦2孟 瑜2
1(西安电子科技大学计算机学院 西安 710071)2(广西可信软件重点实验室(桂林电子科技大学) 广西桂林 541004)3(清华大学软件学院 北京 100084)
(sunjy@guet.edu.cn)
相似语义工作流检索是语义工作流重用的首要任务.现有的相似语义工作流检索方法仅关注结构特征,忽略了行为特征,影响了检索到的相似语义工作流的整体质量,提高了语义工作流重用的代价.为此,提出一种结合行为和结构特征的2阶段相似语义工作流检索算法.使用任务紧邻关系集表达语义工作流的执行行为,结合领域知识构造语义工作流库的任务紧邻关系树索引和数据索引.针对查询语义工作流,先基于任务紧邻关系树索引和数据索引进行过滤得到候选语义工作流集;然后使用图匹配相似性算法对候选语义工作流集进行验证,得到排序的候选语义工作流集.实验结果表明,较主流的语义工作流检索算法,该方法的检索性能有较大提升,可以为工作流重用提供更高质量的语义工作流.
工作流重用;语义工作流;相似性检索;结构特征;行为特征;任务紧邻关系树索引
业务过程运行的效率和质量是现代企业和组织在竞争中保持优势的关键因素之一.随着业务过程管理的广泛应用,大量业务过程被积累下来.工作流重用是现代企业和组织提高业务过程管理效率的重要方式.近年来,研究者提出了基于知识的工作流管理,将基于事例推理(case-based reasoning, CBR)引入业务工作流管理中,提出了面向过程CBR(process-oriented CBR, POCBR).POCBR使用工作流案例记录过去的工作流建模和执行活动的经验知识,进行推理以支持领域专家创建、修正和重用工作流.
基于知识的工作流管理需要以领域知识为背景.语义工作流[1]作为一种基于知识的工作流,为工作流重用提供了更充足的语义和数据或资源信息,可以提高工作流重用的效率.当前语义工作流重用是工作流重用研究的热点之一.目前语义工作流的应用已经从最初的业务过程领域扩展到电子商务、医疗、软件开发和科学分析等领域.
从语义工作流库中检索出满足需求的相似语义工作流是语义工作流重用研究的首要任务.然而现有的相似语义工作流检索方法仅关注结构特征,忽略了行为特征,影响了检索语义工作流的整体质量,也提高了语义工作流重用的代价.Bergmann等人[1]将基于图结构匹配的相似性方法用于语义工作流案例检索.该方法采用遍历语义工作流库的方式进行检索,计算量较大.对于小规模工作流库,该方法可以得出满意的检索性能;对于规模较大的语义工作流库,实际上是不可行的.索引技术是解决大规模数据库检索问题的有效方法.但语义工作流所对应的语义标注有向图是稀疏图,其中的频繁子图并不多,并且频繁子图不能覆盖所有的工作流模型[2].从而图索引的检索技术不能直接用于相似语义工作流检索.
Forbus等人[3]提出一种用于相似性检索的MACFAC(many are called, but few are chosen)模型.该模型由2个阶段构成:1)MAC阶段使用计算量较小的非结构匹配算法从项目池中过滤出候选项目集;2)FAC阶段使用结构匹配算法从候选项目集中找出最匹配的项目.Bergmann等人[4]提出基于MACFAC模型的语义工作流检索方法.MAC阶段基于语义工作流的语义特征和语法特征进行过滤,FAC阶段使用图检索方法选出最匹配的语义工作流.接着,Bergmann等人[5]在MAC阶段建立路径索引:Path-k(k为路径长度)进行语义工作流过滤.Müller等人[6]使用聚类方法建立索引结构,提出了基于排队的检索算法.Müller等人[7]还提出了用于POCBR的相似语义工作流检索语言POQL,可以表达泛化的检索项目.Jin等人[8]使用标签Petri网建模业务过程,提出了基于变迁路径索引LnP(n为路径长度,与路径索引Path-k[5]的本质相同).以上检索方法仅关注语义工作流或业务过程模型的结构特征,没有考虑它们的执行行为,因而检索的准确性有待提高.
Zha等人[9]提出了基于标签Petri网建模的过程模型的变迁紧邻关系(transition adjacency relation, TAR)的概念.变迁紧邻关系集(transition adjacency relations set, TARS)是过程模型的所有TAR的集合.Jin等人[10]构造基于标签Petri网的过程模型的行为特征索引TARIndex,提出了2阶段的过程模型检索方法.该方法关注了业务模型的执行行为,但不能区分循环和顺序结构.Weidlich等人[11]指出在过程模型检索的一致性检查中应该考虑业务过程的数据和资源.由于标签Petri网不含数据流,故针对标签Petri网的检索方法不能直接用于相似语义工作流检索.
鉴于执行行为等价的语义工作流,其结构可能差异较大;而结构相似度高的语义工作流,其执行行为却可能差异较大.因而在相似语义工作流检索时,仅考虑结构特征或行为特征中的1种,得到的检索语义工作流结果集的整体质量自然不高,进而会提高语义工作流重用的代价.目前,对结合结构和行为特征的语义工作流检索研究还很少,特别是需要考虑领域知识时.因此本文以考虑领域知识的语义工作流为研究对象,引入任务紧邻关系树索引的概念,研究结合结构和行为特征的2阶段相似语义工作流检索方法,以期得到整体质量更高的检索语义工作流结果集,为语义工作流重用提供更高质量的候选语义工作流.
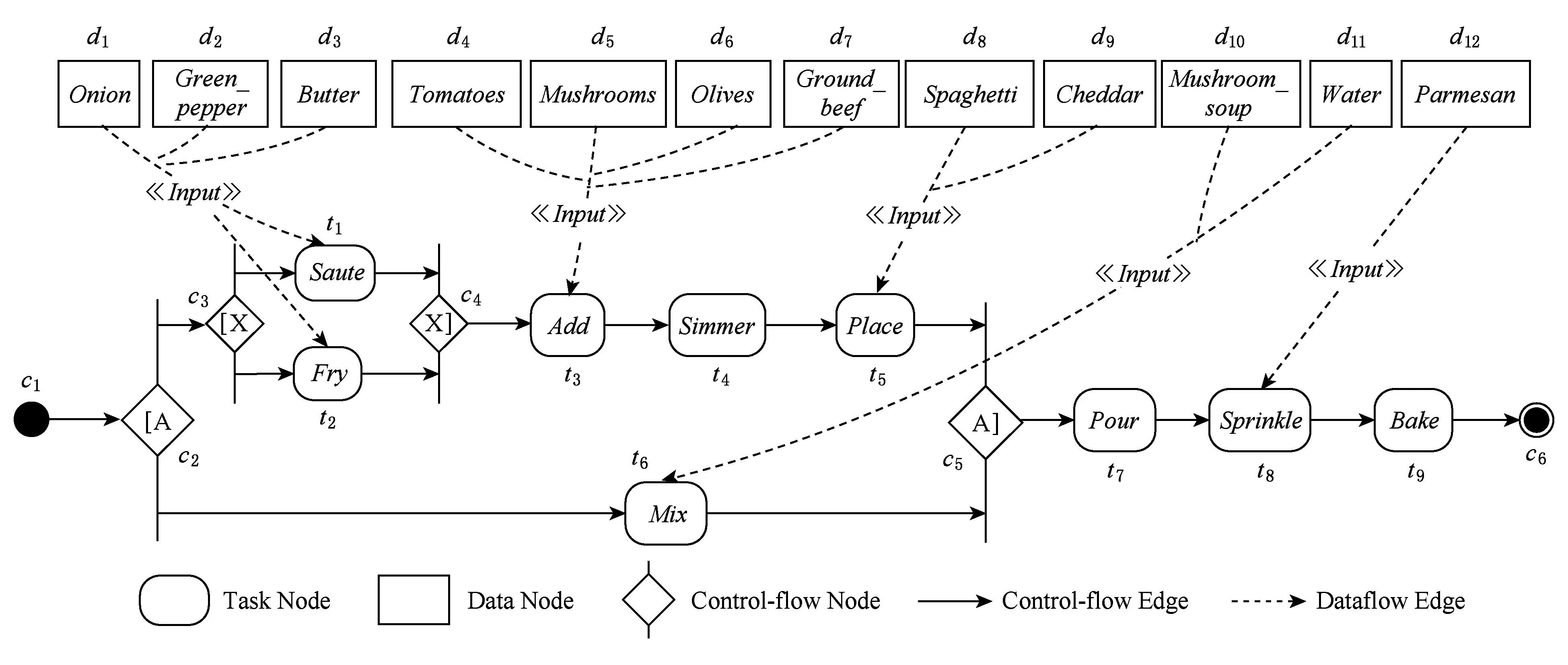
Fig. 1 The semantic workflow SW1图1 语义工作流SW1
本文的主要贡献如下:
1) 提出语义工作流的任务紧邻关系概念,构造了结合领域知识的任务紧邻关系树索引TARTree-Index,用于过滤得到具有指定行为特征的语义工作流;
2) 构造了结合领域知识的数据索引DataIndex,用于过滤得到包含指定数据的语义工作流;
3) 提出了使用TARTreeIndex和DataIndex进行过滤,图匹配相似性算法进行验证的2阶段相似语义工作流检索算法;
4) 通过实验比较得出,本文算法以可接受的代价改善了相似语义工作流的检索性能.
1 预备知识
语义工作流最初由Bergmann等人[1]提出.为工作流的任务结点及其输入输出数据对象增加语义描述,为边增加语义描述使得工作流同时包含控制流、数据流和语义约束,得到了语义工作流.与传统工作流相比,语义工作流不但描述了业务过程中的任务及其连接关系,而且描述了任务的语义、数据或资源以及任务间连接关系的语义等重要信息.语义工作流可以表达业务工作流和科学工作流[1].
1.1 语义工作流
定义1. 语义工作流[1,12].语义工作流可以形式化为语义标注有向图SW=(N,E,S,τ).其中,N=NT∪NC∪ND,NT是任务节点的集合;NC是控制流节点(路由节点)的集合;ND是数据节点集合.E⊆N×N是边的集合;S:N∪E→Σ将节点或边映射为语义描述;Σ是一个与领域相关的语义元数据语言.τ:N∪E→Ω将每个节点或边映射为1个类型,Ω={task node,data node,control-flow node,control-flow edge,dataflow edge}.
为了表述简便,本文仅把以控制流为中心的业务工作流作为研究对象,将其表示为语义工作流,探讨相似语义工作流的检索方法.
例1. 图1是描述意大利面食Baked Spaghetti的烹饪过程的语义工作流SW1[13].
在图1中,控制流边的语义描述为Control-flow,为了简洁,图1中省略了它们.输入数据流边的语义描述为Input.任务节点以其语义描述指示的方式消耗了输入数据对象,生成了输出数据对象,这个过程与函数映射类似.由于任务节点及其输入数据对象的语义描述均基于准确的领域知识,故可以仅使用它和输入数据对象的语义描述来刻画它,而省略它的输出数据对象.如在图1中省略了任务节点的输出数据对象.
由定义1,SW1可表示为:SW1=(N1,E1,S1,τ1),其中,
N1=NT,1∪NC,1∪ND,1,
NT,1={t1,t2,t3,t4,t5,t6,t7,t8,t9};
NC,1={c1,c2,c3,c4,c5,c6};
ND,1={d1,d2,d3,d4,d5,d6,d7,
d8,d9,d10,d11,d12};
E1={(c1,c2),(c2,c3),(c2,t6),(c3,t1),
(c3,t2),(t1,c4),(t2,c4),(c4,t3),(t3,t4),
(t4,t5),(t5,c5),(t6,c5),(c5,t7),(t7,t8),
(t8,t9),(t9,c6),(d1,t1),(d2,t1),(d3,t1),
(d1,t2),(d2,t2),(d3,t2),(d4,t3),(d5,t3),
(d6,t3),(d7,t3),(d8,t5),(d9,t5),(d10,t6),
(d11,t6),(d12,t8)};
S1={(t1,Saute),(t2,Fry),(t3,Add),(t4,Simmer),
(t5,Place),(t6,Mix),(t7,Pour),(t8,Sprinkle),
(t9,Bake),(d1,Onion),(d2,Green_pepper),
(d3,Butter),(d4,Tomatoes),(d5,Mushrooms),
(d6,Olives),(d7,Ground_beef),(d8,Spaghetti),
(d9,Cheddar),(d10,Mushroom_soup),
(d11,Water),(d12,Parmesan),
(c1,Start),(c2,AndSplit),(c3,XORSplit),
(c4,XORJoin),(c5,AndJoin),(c6,End),
((c1,c2),Control-flow),((c2,c3),Control-flow),
((c2,t6),Control-flow),((c3,t1),Control-flow),
((c3,t2),Control-flow),((t1,c4),Control-flow),
((t2,c4),Control-flow),((c4,t3),Control-flow),
((t3,t4),Control-flow),(t4,t5),Control-flow),
((t5,c5),Control-flow),((t6,c5),Control-flow),
((c5,t7),Control-flow),((t7,t8),Control-flow),
((t8,t9),Control-flow),((t9,c6),Control-flow),
((d1,t1),Input),((d2,t1),Input),((d3,t1),Input),
((d1,t2),Input),((d2,t2),Input),((d3,t2),Input),
(d4,t3),Input),((d5,t3),Input),((d6,t3),Input),
((d7,t3),Input),((d8,t5),Input),((d9,t5),Input),
((d10,t6),Input),((d11,t6),Input),
((d12,t8),Input)};
τ1={(t1,TN),(t2,TN),(t3,TN),(t4,TN),
(t5,TN),(t6,TN),(t7,TN),(t8,TN),(t9,TN),
(d1,DN),(d2,DN),(d3,DN),(d4,DN),(d5,DN),
(d6,DN),(d7,DN),(d8,DN),(d9,DN),(d10,DN),
(d11,DN),(d12,DN),(c1,CN),(c2,CN),
(c3,CN),(c4,CN),(c5,CN),(c6,CN),
((c1,c2),CE),((c2,c3),CE),((c2,t6),CE),
((c3,t1),CE),((c3,t2),CE),((t1,c4),CE),
((t2,c4),CE),((c4,t3),CE),((t3,t4),CE),
(t4,t5),CE),((t5,c5),CE),((t6,c5),CE),
((c5,t7),CE),((t7,t8),CE),((t8,t9),CE),
((t9,c6),CE),((d1,t1),DE),((d2,t1),DE),
((d3,t1),DE),((d1,t2),DE),((d2,t2),DE),
((d3,t2),DE),((d4,t3),DE),((d5,t3),DE),
((d6,t3),DE),((d7,t3),DE),((d8,t5),DE),
((d9,t5),DE),((d10,t6),DE),
((d11,t6),DE),((d12,t8),DE)}.
τ1中的TN指代task node类型,CN指代control-flow node类型,DN指代data node类型,CE指代control-flow edge类型,DE指代dataflow edge类型.
为了限定问题的范围,本文假定所研究的语义工作流是块结构化的(block-structured).当一个语义工作流中的顺序结构、选择结构和循环结构都具有明确的开始和结束的块表示时,称该语义工作流是块结构化的[14].在下文中,如不特别指出,所提到的语义工作流均指的是块结构化的语义工作流.
1.2 任务紧邻关系
借鉴标签Petri网的变迁紧邻关系[9],本文提出语义工作流的任务紧邻关系(TAR)和任务紧邻关系集(TARS)概念.
定义2. 任务紧邻关系.假定TrS是块结构化的语义工作流SW=(N,E,S,τ)的所有可能轨迹的集合,a,b为SW的1个任务紧邻关系,其中a,b∈NT,NT是任务节点的集合,当且仅当存在1个轨迹trace=t1,t2,…,tn满足trace∈TrS,ti=a并且ti+1=b(i∈{1,2,…,n-1}).SW的所有TAR的集合记为SW的任务紧邻关系集TARS.
与标签Petri网的变迁紧邻关系相似,任务紧邻关系不能区分循环和顺序结构.但与路径索引中的路径集合[5]相比,任务紧邻关系集TARS较好地刻画了语义工作流的执行行为,更能反映语义工作流的本质,因而适合用于构造基于行为特征的索引.由于语义工作流中存在路由节点,对于较复杂的语义工作流,直接根据其结构获取TARS一般是很困难的.Mcmillan等人[15]最先提出使用完全有限前缀来展开Petri网系统.该算法有着较高的效率和比较小的展开规模,在解决Petri网状态空间爆炸问题方面有比较出色的表现.Esparza等人[16]对此进行了改进,提出了一种规模更小的展开方法,即完全前缀展开.更多相关概念和示例详见文献[15-18].
例2. 图2为图1所示的语义工作流SW1的完全前缀展开.
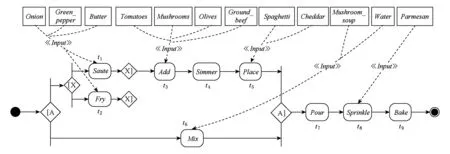
Fig. 2 The complete prefix unfolding of the semantic workflow SW1图2 语义工作流SW1的完全前缀展开
易得,SW1的TARStarS1={t1,t3,t2,t3,t3,t4,t4,t5,t1,t6,t6,t1,t2,t6,t6,t2,t3,t6,t6,t3,t4,t6,t6,t4,t5,t6,t6,t5,t5,t7,t6,t7,t7,t8,t8,t9}.
2 2阶段的相似语义工作流检索方法
在进行相似语义工作流检索时,一般需要检索出包含指定数据对象或满足指定行为和结构特征的相似语义工作流.例如可能有如下的需求或者这些需求的组合.
R1:找出包含某个任务节点的相似语义工作流;
R2:找出包含某个任务紧邻关系的相似语义工作流;
R3:找出包含某些输入数据对象或者不含另一些输入数据对象的相似语义工作流;
R4:找出包含某个语义工作流片段的相似语义工作流.
易得,需求R1~R3是需求R4的子问题,从而本文以需求R4为主要检索需求.针对R4,提出了基于MACFAC模型的2阶段相似语义工作流检索方法.第1阶段,即MAC阶段包含2步过滤操作:1)针对具体语义工作流库,结合领域任务本体构造任务紧邻关系树索引TARTreeIndex,结合领域数据本体构造数据索引DataIndex.2)计算查询语义工作流的TARS,基于TARTreeIndex对语义工作流库进行过滤获取包含此TARS的粗选语义工作流集合;接着基于DataIndex对粗选语义工作流集合进行过滤,获取包含查询语义工作流的输入数据的精选语义工作流集合,称之为候选语义工作流集合.第2阶段,即FAC阶段利用基于图编辑距离的图匹配[20]相似性方法对候选语义工作流集合进行验证,根据相似性对候选语义工作流进行排序.
2.1 任务紧邻关系树索引TARTreeIndex
在相似语义工作流检索中,大多数情况下检索不到执行行为完全一致的语义工作流,这时检索到执行行为足够相似的语义工作流往往是最佳选择.在基于知识的语义工作流环境中,任务紧邻关系之间不再仅仅是相同或者不同这2种情况,而是还可能有包含或被包含关系、既不包含或也不被包含关系.
定义3. 任务紧邻关系的包含关系.对于语义工作流SW1=(N1,E1,S1,τ1),SW2=(N2,E2,S2,τ2),任务节点a,b∈NT,1⊂N1,任务节点c,d∈NT,2⊂N2,tar1=a,b,tar2=c,d分别是SW1,SW2的任务紧邻关系,C1,C2,C3,C4分别是a,b,c,d的语义描述所对应的领域任务本体概念.如果C1C3且C2C4,则称任务紧邻关系c,d包含a,b,记为a,bc,d或tar1tar2,称tar2为父TAR,称tar1为子TAR.
任务紧邻关系的包含关系也可以称为任务紧邻关系的泛化关系.如果tar1tar2,则称tar2是tar1的泛化,tar1是tar2的特化.在相似语义工作流检索中,如果包含指定TAR的语义工作流不存在,则可以根据TAR的包含关系选择检索包含该TAR的父TAR或子TAR的语义工作流.为了简化,本文优先选择父TAR.当父TAR不存在时,选择1个子TAR来执行检索.
定义4. 任务紧邻关系的相似性.对于语义工作流SW1=(N1,E1,S1,τ1),SW2=(N2,E2,S2,τ2),任务节点a,b∈NT,1⊂N1,任务节点c,d∈NT,2⊂N2,tar1=a,b,tar2=c,d分别是SW1,SW2的任务紧邻关系,C1,C2,C3,C4分别是a,b,c,d的语义描述所对应的领域任务本体概念.如果tar1tar2,则sim(tar1,tar2)=1;否则
sim(tar1,tar2)=(sim(C1,C3)+
sim(C2,C4))
(1)
其中,sim(Ci,Cj)的计算方法可参考文献[21],Ci,Cj(i,j∈{1,2})为领域任务本体概念.
定义4用于计算当前TAR与父TAR或子TAR的相似性.只有相似性超过给定阈值的父TAR或子TAR才会被选择替换当前TAR.
定义5. 任务紧邻关系树.语义工作流的任务紧邻关系树TARTree是基于任务紧邻关系的包含关系建立的一棵多叉树.它的每个节点为形如(tar,tar.list)的项,建立了从tar到语义工作流集合的映射.其中tar为任务紧邻关系,tar.list为含有tar的语义工作流集合.
一棵任务紧邻关系树TARTree的片段如图3所示.TARTree中TAR之间的包含关系对语义工作流重用中可重用组件的选取具有参考价值.
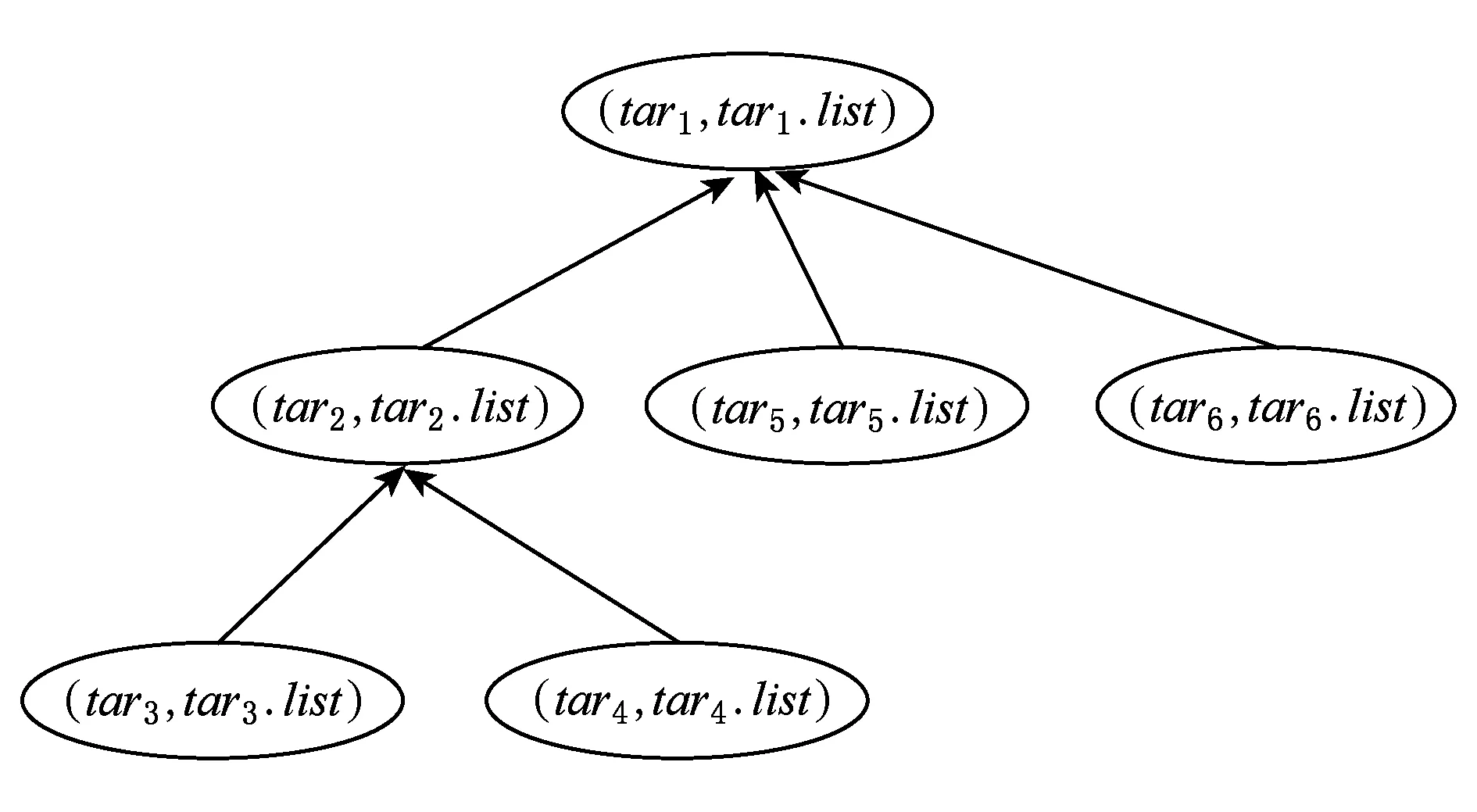
Fig. 3 A segment of TARTree图3 任务紧邻关系树的片段
定义6. 任务紧邻关系树索引.语义工作流的任务紧邻关系树索引TARTreeIndex是任务紧邻关系树TARTree的集合.TARTreeIndex用于获取包含指定任务紧邻关系集合的语义工作流的集合.
任务紧邻关系树索引TARTreeIndex构造算法的伪代码如算法1所示:
算法1. 任务紧邻关系树索引TARTreeIndex构造算法.
输入:语义工作流库SWB、领域任务本体TaskOnto;
输出:任务紧邻关系树索引tarTreeIndex.
①tarTreeIndex=∅;
② ifSWB==∅ then
③ returntarTreeIndex;
④ end if
⑤ foreachSW∈SWBdo
⑥tarS=computeTARS(SW);
⑦ foreachtar∈tarSdo
⑧ iftarTreeIndex==∅ then
⑨tree1.root=newnode(tar),tree1.root.list.add(SW),tarTreeIndex=tarTreeIndex∪{tree1};
⑩ elsen1=newnode(tar),n1.list.add(SW),insertTARTreeIndex(SW,n1);

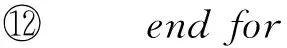


函数1.insertTARTreeIndex(SW,tarNode)的伪代码.
输入:语义工作流SW、任务紧邻关系树节点tarNode;
输出:任务紧邻关系树索引tarTreeIndex.
① foreachtree∈tarTreeIndexdo
② iftarNode.tartree.root.tarortree.root.tartarNode.tarthen
③tree2.root=tarNode,tarTreeIndex=tarTreeIndex∪{tree2};
④ else iftarNode.tar==tree.root.tarthen
⑤tree.root.list.add(tarNode.list);
⑥ else iftarNode.tartree.root.tarthen
⑦insertTARTree(tree.root,SW,tarNode);
⑧ else iftree.root.tartarNode.tarthen
⑨tarNode.childList.add(tree.root.list);
⑩ end if


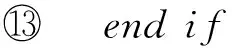
函数2.insertTARTree(treeRoot,SW,tarNode)的伪代码.
输入:任务紧邻关系树的根节点treeRoot、语义工作流SW、任务紧邻关系树节点tarNode;
输出:任务紧邻关系树索引tarTreeIndex.
① iftreeRoot.childList==∅ then
②treeRoot.childList.add(tarNode);
③ else foreachchild∈treeRoot.childListdo
④ ifchild.tartarNode.tarthen
⑤tarNode.childList.add(child),treeRoot.childList.add(tarNode),treeRoot.childList.delete(child);
⑥ else iftarNode.tarchild.tarthen
⑦insertTARTree(child,SW,tarNode);
⑧ elsetreeRoot.childList.add(tarNode);
⑨ end if
⑩ end if
算法1中,函数computeTARS(SW)用于计算语义工作流SW的TARStarS,函数insertTARTree-Index(SW,tarNode)用于将SW的TAR节点tarNode插入索引tarTreeIndex中,函数insertTARTree(treeRoot,SW,tarNode)用于将SW的TAR节点tarNode插入以treeRoot为根节点的任务紧邻关系树TARTree中.在构造tarTreeIndex的过程中,tarS中的每个TAR被插入到1个TARTree中或者成为1个新TARTree的根节点.
当有新语义工作流加入语义工作流库时,tarTreeIndex的更新过程与其建立过程基本一致,也是基于TAR的包含关系将新语义工作流的TARS插入到tarTreeIndex中.当某一语义工作流从库中删除时,需要进行TARTree相应节点的删除,这可以立刻执行或当需要删除的语义工作流达到一定数量时,一次性删除所有相应的节点.
基于TARTreeIndex检索与某个查询语义工作流相似的语义工作流,实质上可转化为在语义工作流库中检索与查询语义工作流执行行为相似的语义工作流.算法的伪代码如算法2所示:
算法2. 检索与某个查询语义工作流相似的语义工作流.
输入:语义工作流库SWB、任务紧邻关系树索引tarTreeIndex、查询语义工作流SWq、任务紧邻关系的相似性阈值θ1;
输出:与SWq的执行行为相似的语义工作流集WFS.
①WFS=∅;
②tarSq=computeTARS(SWq);
③ foreachtar∈tarSqdo
④tarNode=newnode(tar),tarNode.list.add(SW),insertTARTreeIndex(null,tarNode);
⑤ if ∃treeNode∈tarTreeIndexsuch thattreeNode.tar=tarNode.tarthen
⑥WFS=WFS∪treeNode.list;
⑦ else iftarNode.parent.list≠∅ then
⑧WFS=WFS∪tarNode.parent.list;
⑨ else iftarNode.childList≠∅ then
⑩ selectchildsuch thatchild.list≠∅ andsim(tarNode.tar,child.tar)≥θ1,WFS=WFS∪child.list;

算法2的检索过程与将新语义工作流入库相似,只是在向TARTree插入相应节点时,将TAR所属的语义工作流置为null,如算法2的行④.这样检索得到的语义工作流集即为所求的集合,而不包含查询语义工作流本身.在检索后对TARTreeIndex进行的恢复操作是删除刚插入的TARNode节点,这点没有体现在算法2中.算法2首先检索至少包含tarSq中1个TAR的语义工作流集,然后对这些集合取并集.选择并集的目的是为了获取与SWq执行行为相似的语义工作流.在第⑤行,如果已经存在1个TAR节点treeNode,则treeNode.list即为所求的语义工作流集合;如果不存在这样1个TAR节点,则优先选择父TAR节点的语义工作流集合,次之选择某个子TAR节点的语义工作流集合.
2.2 数据索引DataIndex
定义7. 数据索引.语义工作流库的数据索引DataIndex,结构形如(data,data.list).其中data表示输入数据对象,data.list表示包含data的语义工作流集.
建立该索引的算法的伪代码如算法3所示:
算法3. 数据索引DataIndex构造算法.
输入:语义工作流库SWB;
输出:数据索引dataIndex.
①dataIndex=∅;
② ifSWB==∅ then
③ returndataIndex;
④ end if
⑤ foreachSW∈SWBdo
⑥dataS=computeDS(SW);
⑦ foreachdata∈dataSdo
⑧ ifdata∉dataIndexthen
⑨data.list.add(SW),dataIndex.add(data);
⑩ elsedata.list.add(SW);
算法3中,函数computeDS(SW)用于获取语义工作流SW的输入数据对象集dataS.数据索引dataIndex采用Map结构实现,其更新较简单.当检索包含某一数据对象data的相似语义工作流集合时,可以使用data作为key在dataIndex中检索,返回value为data.list;若不存在该data,则先在领域数据本体DataOnto中查找与它相似的父数据对象或子数据对象data′,然后查找包含data′的相似语义工作流集合.算法伪代码如算法4所示:
算法4. 检索包含某个查询语义工作流的输入数据对象的相似语义工作流.
输入:数据索引dataIndex、查询语义工作流SWq、领域数据本体DataOnto、数据对象的相似性阈值θ2;
输出:包含SWq的数据对象集的相似语义工作流集合WFS.
①WFS=∅;
②dataSq=computeDS(SWq);
③ foreachdata∈dataSqdo
④ ifdata∈dataIndexanddata.list≠∅ then
⑤WFS=WFS∪data.list;
⑥ else searchdata’sparentinDataOnto;
⑦ ifparent.list≠∅ then
⑧WFS=WFS∪parent.list;
⑨ else searchdata’schildListinDataOnto;
⑩ foreachchild∈childListdo

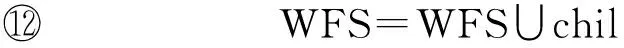




算法4中,对包含每个数据对象的语义工作流集合求并集操作是为了获取与SWq的输入数据对象相似的语义工作流.
2.3 2阶段的相似语义工作流检索方法
2.3.1 语义工作流过滤
对于查询语义工作流SWq,过滤操作可以由算法2和算法4实现.首先使用任务紧邻关系树索引TARTreeIndex进行粗选过滤操作,由算法2完成,得到语义工作流集WFS1;接着使用数据对象索引DataIndex对WFS1进行精选过滤操作,由算法4完成,得到语义工作流集WFS2,称WFS2为候选语义工作流集.
2.3.2 候选语义工作流集验证
在验证阶段,针对查询语义工作流SWq,使用语义工作流的图匹配相似性方法对候选语义工作流集WFS2进行验证,并按与SWq的相似程度进行排序.语义工作流的图匹配相似性基于图编辑距离得到,而图编辑距离反映了语义工作流间的结构特征差别.
定义8. 语义工作流的图编辑距离.对于语义工作流SW1=(N1,E1,S1,τ1),SW2=(N2,E2,S2,τ2),SW1与SW2的图编辑距离是将SW1转换成SW2所需的最小编辑操作数.编辑操作包括节点和边的替换、插入和删除操作.
Dijkman等人[20]给出了寻求过程模型的活动节点间最优匹配的方法,基于此确定节点和边的编辑操作(替换、插入和删除)次数,进而确定过程模型间的图编辑距离.最后根据图编辑距离计算图编辑相似性,称之为图匹配(graph matching)相似性.然而该方法省略了过程模型中的路由节点,无法真实反映过程模型原有的路由情况,从而得出的图匹配相似性也不够准确.在获取语义工作流的图匹配时,本文改进使用贪婪策略的图匹配方法[20],保留语义工作流中的路由节点,基于上下文相似性优先进行路由节点的匹配.来自2个语义工作流的路由节点的上下文相似性越高,则它们在最优匹配中出现的概率就越高.
定义9. 路由结点的上下文相似性.对于语义工作流SW1=(N1,E1,S1,τ1),SW2=(N2,E2,S2,τ2),假设路由节点u∈NC,1⊂N1,v∈NC,2⊂N2的直接前驱节点集合分别为Pu,Pv,直接后继节点集合分别为Su,Sv,如果u,v为相同类型的开节点或闭节点,则u,v的上下文相似性
simC(u,v)=k1×sim(Pu,Pv)+
(2)
其中,k1+k2=1,一般取k1=k2=0.5;否则simC(u,v)=0.
式(2)中,sim(Pu,Pv),sim(Su,Sv)由KM算法[22]计算得出.在获取语义工作流的图匹配时,优先进行语义工作流的路由节点的匹配,基于此再进行任务节点的匹配,最后得到所有节点间的映射.任务节点的相似性采用其语义描述的语义相似性.由于使用贪婪策略可能生成非最优匹配,但在MAC阶段的2步过滤操作后,这种概率大大降低.此处省略语义工作流的图匹配算法的伪代码.
第1阶段(MAC阶段)基于行为特征进行语义工作流过滤,获得执行行为相似的候选语义工作流集;第2阶段(FAC阶段)基于结构特征对候选语义工作流集进行验证,通过选择适当的图匹配相似性阈值可以获得不但执行行为相似而且结构特征也相似的语义工作流集.这样,在检索过程中把语义工作流的行为特征和结构特征结合起来,可以得到整体质量更高的检索语义工作流集,从而为语义工作流重用提供更高质量的备选语义工作流.
3 实验与结果分析
3.1 实验建立
本文的所有实验基于如下环境:Intel CoreTMCPU 2.2 GHz,4.0 GB RAM,Windows7 64位操作系统,JDK1.6环境的笔记本计算机.目前,基于知识的语义工作流的数据集还较少.本文的实验数据集选自WikiTaaable*http:wikitaaable.loria.fr的Recipe和Recipesource*http:www.recipesource.com,其中共有1 000多个意大利面食(pasta)食谱.实验中的领域任务本体TaskOnto来自WikiTaaable的Culinary actions ontology,领域数据对象本体DataOnto来自WikiTaaable的Food ontology.该数据集及上述本体是ICCBR会议为计算机烹饪比赛(computer cooking contest, CCC)建立的.
本文从数据集中随机选取50个意大利面食的食谱,根据定义1将食谱的烹饪说明(cooking instructions)表示成如图1所示的语义工作流[13],组成规模为50的语义工作流库.
3.2 实验结果对比
3.2.1 检索的准确率比较
本实验在语义工作流库中随机选取10个语义工作流并对之做一定的改动[21],组成大小为10的查询语义工作流集.取任务紧邻关系的相似性阈值θ1=0.6,数据对象的相似性阈值θ2=0.5,语义工作流的相似性阈值θ3=0.5.针对每个查询语义工作流分别执行检索,绘制本文的TARTreeIndex+Data-Index算法和Path-1算法[5]的P-R(precision-recall)曲线.这里取k=1,因为长度为1的路径索引可以获得较好的检索性能[5].将TARIndex算法[10]、基于贪婪策略的图匹配相似性算法[20]的研究方法应用于相似语义工作流检索,如采用忽略数据流的语义工作流的TARS、任务节点的语义相似性等.绘制由TARIndex算法和图匹配算法得到的P-R曲线,如图4所示:
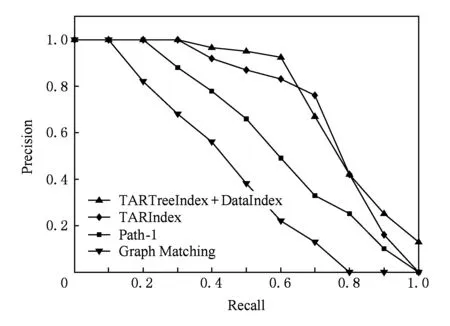
Fig. 4 P-R curves of four retrieval algorithms图4 4种检索算法的P-R曲线
由图4可以看出,TARTreeIndex+DataIndex算法和TARIndex算法的P-R曲线完全处于Path-1算法和图匹配算法的P-R曲线的上方,表明引入基于行为特征的索引确实提高了相似语义工作流的检索性能.TARIndex算法的P-R曲线在R=0.7处高于TARTreeIndex+DataIndex算法,这是由于语义工作流库中存在了2个执行行为足够相似而数据集有一定差异的可接受语义工作流.TARIndex算法忽略了数据流使得在排序的检索结果中这2个语义工作流相隔很近,而在考虑数据流的TARTree-Index+DataIndex算法的排序的检索结果中它们相隔较远.这样使得TARIndex算法在R=0.7处准确率P高于TARTreeIndex+DataIndex算法.但TARTreeIndex+DataIndex算法的P-R曲线的大部分处于TARIndex算法的P-R曲线的上方,表明结合结构特征并引入数据对象索引从整体上提高了相似语义工作流的检索性能.以上表明TARTree-Index+DataIndex算法的相似语义工作流检索性能好于其他3种算法.
3.2.2 检索时间比较
本实验从查询语义工作流集中任选5个语义工作流,在语义工作流库中语义工作流数量从10开始以步长10增加到50时,分别执行检索.记录每次的检索时间,并计算每个语义工作流数量的检索时间的平均值.将本文TARTreeIndex+DataIndex算法的检索时间与TARIndex算法、Path-1算法、图匹配算法的检索时间作比较,如图5所示:
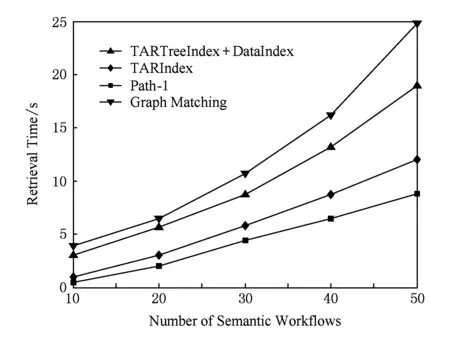
Fig. 5 Retrieval time of four retrieval algorithms图5 4种检索算法的检索时间
由图5看出,图匹配算法的检索时间多于其他3种算法,原因是该算法采用遍历语义工作流库的方法进行检索,这也说明了引入索引的必要性.而TARTreeIndex+DataIndex算法的检索时间多于TARIndex算法和Path-1算法,原因是构造任务紧邻关系树索引TARTreeIndex和数据索引DataIndex也增加了检索时间.因此,将索引TARTreeIndex和DataIndex离线构造并存储在文件中以及使用一定的缓存技术是必要的.
3.2.3 索引构造时间比较

Fig. 6 Index construction time of three retrieval algorithms图6 3种算法的索引构造时间
对于本文的TARTreeIndex+DataIndex算法,在语义工作流库中语义工作流数量从10开始以步长10增加到50时,本实验分别记录索引构造时间.将本文TARTreeIndex+DataIndex算法的索引构造时间与TARIndex算法、Path-1算法的索引构造时间作比较,如图6所示.
由图6看出,TARTreeIndex+DataIndex算法的索引构造时间多于TARIndex算法和Path-1算法,原因是构造索引TARTreeIndex和索引DataIndex使用的时间比构造索引TARIndex或Path-1要多.但由于索引TARTreeIndex和索引DataIndex都可以增量更新,当有新的语义工作流加入库中时,索引更新所用时间较少.
从以上实验可以看出,本文的结合行为和结构特征的2阶段相似语义工作流检索算法在检索性能上得到了改善,但检索时间和索引构造时间较长.其索引技术需要进一步完善以减少检索时间和索引构造时间.由于语义工作流的重用一般是离线完成的,因此也可以接受这种检索时间.从而本文提出的算法以可接受的代价改善了相似语义工作流的检索性能.
4 总结与展望
在未来的工作中,将致力于研究更高效的语义工作流行为特征索引,以进一步提高结合结构和行为特征的相似语义工作流检索算法的效率;设计以语义工作流修正代价最少为导向的相似语义工作流检索方法,以期为语义工作流重用提供更适于重用的检索语义工作流集.语义工作流库的内容及其组织结构对语义工作流的检索与修正效率有重要影响,因而语义工作流库维护也是未来的工作之一.
[1]Bergmann R, Gil Y. Similarity assessment and efficient retrieval of semantic workflows[J]. Information Systems, 2014, 40(1): 115-127
[2]Jin Tao, Wang Jianmin, Wen Lijie. Indexing technology for business process models[J]. Computer Integrated Manufacturing Systems, 2011, 17(8): 1580-1586 (in Chinese)(金涛, 王建民, 闻立杰. 业务过程模型库索引技术[J]. 计算机集成制造系统, 2011, 17(8): 1580-1586)
[3]Forbus K D, Gentner D, Law K. MACFAC: A model of similarity based retrieval[J]. Cognitive Science, 1995, 19(2): 141-205
[4]Bergmann R, Minor M, Islam S, et al. Scaling similarity-based retrieval of semantic workflows[C]Proc of ICCBR-Workshop on Process-oriented Case-Based Reasoning. Berlin: Springer, 2012: 15-24
[5]Kendall-Morwick J, Leake D. A study of two-phase retrieval for process-oriented case-based reasoning[G]Successful Case-Based Reasoning Applications-2. Berlin: Springer, 2014: 7-27
[6]Müller G, Bergmann R. A cluster-based approach to improve similarity-based retrieval for process-oriented case-based reasoning [J]. Frontiers in Artificial Intelligence & Applications, 2014, 263: 639-644
[7]Müller G, Bergmann R. POQL: A new query language for process-oriented case-based reasoning[COL]Proc of LWA 2015 Workshops: KDML, FGWM, IR, and FGDB. [2016-10-24]. http:ceur-ws.orgVol-1458F06_CRC59_Mueller.pdf
[8]Jin Tao, Wang Jianming, Wu Nianhua, et al. Efficient and accurate retrieval of business process models through indexing[G]LNCS 6426: Proc of Conf on the Move to Meaningful Internet Systems (OTM 2010). Berlin: Springer, 2010: 402-409
[9]Zha Haiping, Wang Jianmin, Wen Lijie, et al. A workflow net similarity measure based on transition adjacency relations [J]. Computers in Industry, 2010, 61(5): 463-471
[10]Jin Tao, Wang Jianmin, Wen Lijie. Efficient retrieval of similar workflow models based on behavior[G]Web Technologies and Applications. Berlin: Springer, 2012: 677-684
[11]Weidlich M, Mendling J, Weske M. Efficient consistency measurement based on behavioral profiles of process models [J]. IEEE Trans on Software Engineering, 2011, 37(3): 410-429
[12]Bergmann R, Müller G, Wittkowsky D. Workflow clustering using semantic similarity measures[G]Advances in Artificial Intelligence. Berlin: Springer, 2013: 13-24
[13]Dufour-Lussier V, Leber F, Lieber J, et al. Automatic case acquisition from texts for process-oriented case-based reasoning[J]. Information Systems, 2014, 40(1): 153-167
[14]Kiepuszewski B, Hofstede A H M, Bussler C J. On structured workflow modelling[G]Seminal Contributions to Information Systems Engineering. Berlin: Springer, 1999: 241-256
[15]Mcmillan K L, Probst D K. A technique of state space search based on unfolding[J]. Formal Methods in System Design, 1995, 6(1): 45-65
[16]Esparza J, Römer S, Vogler W. An improvement of McMillan's unfolding algorithm[G]Tools and Algorithms for the Construction and Analysis of Systems. Berlin: Springer, 1996: 87-106
[17]Engelfriet J. Branching processes of Petri nets[J]. Acta Informatica, 1991, 28(6): 575-591
[18]Du Yuyue, Sun Ya’nan, Liu Wei. Petri nets based recognition of model deviation domains and model repair[J]. Journal of Computer Research and Development, 2016, 53(8): 1766-1780 (in Chinese)(杜玉越, 孙亚男, 刘伟. 基于Petri网的模型偏差域识别与模型修正[J]. 计算机研究与发展, 2016, 53(8): 1766-1780)
[19]Song Jinfeng, Wen Lijie, Wang Jianmin. A similarity measure for process models based on the occurrence relations of tasks[J]. Journal of Computer Research and Development, 2017, 54(4): 832-843 (in Chinese) (宋金凤, 闻立杰, 王建民. 基于任务发生关系的流程模型相似性度量[J]. 计算机研究与发展, 2017, 54(4): 832-843)
[20]Dijkman R, Dumas M, Garcíabauelos L. Graph matching algorithms for business process model similarity search [C]Proc of the 7th Int Conf on Business Process Management. Berlin: Springer, 2009: 48-63
[21]Sun Jinyong,Gu Tianlong,Wen Lijie,et al. Similarity algorithm for semantic workflows used in process-oriented case-based reasoning[J]. Computer Integrated Manufacturing Systems 2016, 22(2): 381-394 (in Chinese)
(孙晋永, 古天龙, 闻立杰, 等. 用于面向过程的基于实例推理的语义工作流相似性算法[J]. 计算机集成制造系统, 2016, 22(2): 381-394)
[22]Munkres J. Algorithms for the assignment and transportation problems[J]. Journal of the Society for Industrial and Applied Mathematics, 1957, 5(1): 32-38

Sun Jinyong, born in 1978. Master. Student member of CCF. His main research interests include business process management and workflow technology, knowledge representation and reasoning, etc.

Gu Tianlong, born in 1964. PhD. Professor, PhD supervisor. His main research interests include formal methods, data and knowledge engineering, software engineer-ing, etc.

Wen Lijie, born in 1977. PhD, associate professor, PhD supervisor. His main research interests include process mining, process data management, workflow for big data analysis (wenlj@tsinghua.edu.cn).

Qian Junyan, born in 1973. PhD. Professor. Senior member of CCF. His main research interests include software engineering, model checking and program verification, etc (qjy2000@gmail.com).

Meng Yu, born in 1976. PhD candidate. Associate professor. Member of CCF. Her main research interests include intelligent planning, knowledge representation and reasoning, and formal method, etc (mengyu@guet.edu.cn).
Retrieval of Similar Semantic Workflows Based on Behavioral and Structural Characteristics
Sun Jinyong1,2, Gu Tianlong2, Wen Lijie3, Qian Junyan2, and Meng Yu2
1(SchoolofComputerScienceandTechnology,XidianUniversity,Xi’an710071)2(GuangxiKeyLaboratoryofTrustedSoftware(GuilinUniversityofElectronicTechnology),Guilin,Guangxi541004)3(SchoolofSoftware,TsinghuaUniversity,Beijing100084)
Workflow reuse is an important method for modern enterprises and organizations to improve the efficiency of business process management (BPM). Semantic workflows are domain knowledge-based workflows. The retrieval of similar semantic workflows is the first step for semantic workflow reuse. Existing retrieval algorithms of similar semantic workflows only focus on semantic workflows’ structural characteristics while ignoring their behavioral characteristics, which affects the overall quality of retrieved similar semantic workflows and increases the cost of semantic workflow reuse. To address this issue, a two-phase retrieval algorithm of similar semantic workflows is put forward based on behavioral and structural characteristics. A task adjacency relations (TARs) set is used to express a semantic workflow’s behavior. A TARs trees index named TARTreeIndex and a data index named DataIndex are constructed combined with domain knowledge for the semantic workflows case base. For a given query semantic workflow, firstly, candidate semantic workflows are obtained by filtering the semantic workflows case base with the TARTreeIndex and DataIndex, then candidate semantic workflows are verified and ranked with the graph matching similarity algorithm. Experiments show that the proposed algorithm improves the retrieval performance of similar semantic workflows compared with the existing popular retrieval algorithms for similar semantic workflows, so it can provide high-quality semantic workflows for semantic workflow reuse.
workflow reuse; semantic workflow; similarity-based retrieval; structural characteristics; behavioral characteristics; task adjacency relations trees index (TARTreeIndex)
2016-10-24;
2017-02-13
国家自然科学基金项目(61562015,61572146,U1501252);广西自然科学基金项目(2015GXNSFDA139038,2016GXNSFDA380006);广西可信软件重点实验室项目(KX201627);广西高等学校高水平创新团队及卓越学者计划项目;桂林电子科技大学创新团队项目;广西精密导航技术与应用重点实验室项目(DH201508) This work was supported by the National Natural Science Foundation of China (61562015, 61572146, U1501252), the Natural Science Foundation of Guangxi of China (2015GXNSFDA139038, 2016GXNSFDA380006), the Project of Guangxi Key Laboratory of Trusted Software (KX201627), the Project of High Level of Innovation Team of Colleges and Universities in Guangxi and Outstanding Scholars Program, and the Program for Innovative Research Team of Guilin University of Electronic Technology, and the Project of Guangxi Key Laboratory of Precision Navigation Technology and Application (DH201508).
古天龙(cctlgu@guet.edu.cn)
TP315; TP18
