基于自适应学习率的深度信念网设计与应用
2017-09-11乔俊飞王功明李晓理韩红桂柴伟
乔俊飞 王功明 李晓理 韩红桂 柴伟
基于自适应学习率的深度信念网设计与应用
乔俊飞1,2王功明1,2李晓理1韩红桂1,2柴伟1,2
针对深度信念网(Deep belief network,DBN)预训练耗时长的问题,提出了一种基于自适应学习率的DBN(Adaptive learning rate DBN,ALRDBN).ALRDBN将自适应学习率引入到对比差度(Contrastive divergence,CD)算法中,通过自动调整学习步长来提高CD算法的收敛速度.然后设计基于自适应学习率的权值训练方法,通过网络性能分析给出学习率变化系数的范围.最后,通过一系列的实验对所设计的ALRDBN进行测试,仿真实验结果表明,ALRDBN的收敛速度得到了提高且预测精度也有所改善.
深度信念网,自适应学习率,对比差度,收敛速度,性能分析
深度学习网络是人工神经网络的延伸,在某种意义上等同于含有多个隐层的多层感知器(Multilayer perceptron,MLP),近年来在语音识别、计算机视觉以及大数据处理等方面取得了较大的进展.深度学习通过提取底层特征信息来获取更加抽象的高层表示,以揭示数据的分布式特征表示[1],目前应用较为广泛的深度学习网络主要是深度信念网(Deep belief network,DBN),已经在多个领域得到了成功的推广和应用[2−8].DBN是由多个受限玻尔兹曼机(Restricted Boltzmann machine,RBM)顺序叠加构成,采用无监督贪心算法对所有RBM逐一进行预训练,然后再利用有监督的误差反传方法对整个网络权值进行微调[9].DBN的无监督预训练相当于传统神经网络中有监督训练之前的权值随机初始化,这样可以将初始权值确定在一个较好的范围,有利于克服由随机初始化权值导致陷入局部最优的问题[10].
尽管DBN已经在多个领域实现较好的应用,但是在理论和学习算法方面仍存在许多难以解决的问题,其中面临的最大挑战就是其预训练阶段耗时长的问题[11].Lopes等通过合理地选取学习参数提高了RBM的收敛速度[12],BN整体学习速度方面效果不佳;经过近几年的研究,一种基于图像处理单元(Graphic processing unit,GPU)的硬件加速器被应用到DBN算法运算中,并取得了显著的加速收敛效果[13−15],该方法的主要问题是硬件设备成本和维护费用太高,不经济并且也没有从算法的角度提高收敛速度.随着大数据时代的到来,处理数据的信息量会呈指数级增长,传统DBN无法快速收敛甚至会难以完成学习任务,因此如何既快速又经济地完成对大量数据的充分学习是DBN今后发展的一个方向[16].
针对传统DBN预训练耗时长的问题,文中将一种基于自适应学习率[13]的思想引入到深度信念网(Adaptive learning rate DBN,ALRDBN).根据对比差度(Contrastive divergence,CD)[17]算法中参数每次迭代方向的异同来动态调整学习率,从而成功避开了固定学习率所带来的欠学习和陷入局部最优的问题[12],并通过网络性能分析,给出自适应学习率的动态调整系数取值范围的选取方法.同时将所设计的ALRDBN应用于MNIST数据库手写数字识别、大气二氧化碳浓度变化预测以及洛伦兹混沌时间序列预测等实验,结果表明ALRDBN在学习过程中能够以更快的速度实现收敛,同时预测精度也略有提高.
文中第1节介绍ALRDBN的结构及学习过程;第2节进行网络性能分析,并给出自适应学习率动态调整系数取值范围的选取方法;第3节对网络的性能进行仿真实验,并对结果进行分析;第4节给出总结与展望.
1 自适应学习率深度信念网
1.1 ALRDBN结构
与传统的DBN结构类似,ALRDBN由若干个RBM顺序叠加构成,上一个RBM的输出作为下一个RBM 的输入.考虑到网络的过拟合和泛化能力等因素,在处理中等规模的数据时DBN隐含层层数一般选用2至3层,为了方便起见,故ALRDBN隐含层选用2层,网络结构如图1所示.双向箭头表示相邻两层之间为双向全连接,同一层神经元之间没有连接.
从图1可以看出,DBN学习过程相对复杂,分为两个阶段:预训练阶段和微调阶段,在预训练阶段,首先使用CD算法对构成DBN的所有RBM逐一进行无监督训练;在微调阶段,将整个网络展开成一个前向型网络,再使用误差反传方法对整个网络权值进行有监督的微调.
1.2 ALRDBN预训练过程
RBM是一种能量生成模型,由可视层(输入层)和隐含层(输出层)组成,两层之间采用双向全连接,同一层之间没有连接,如图2所示.

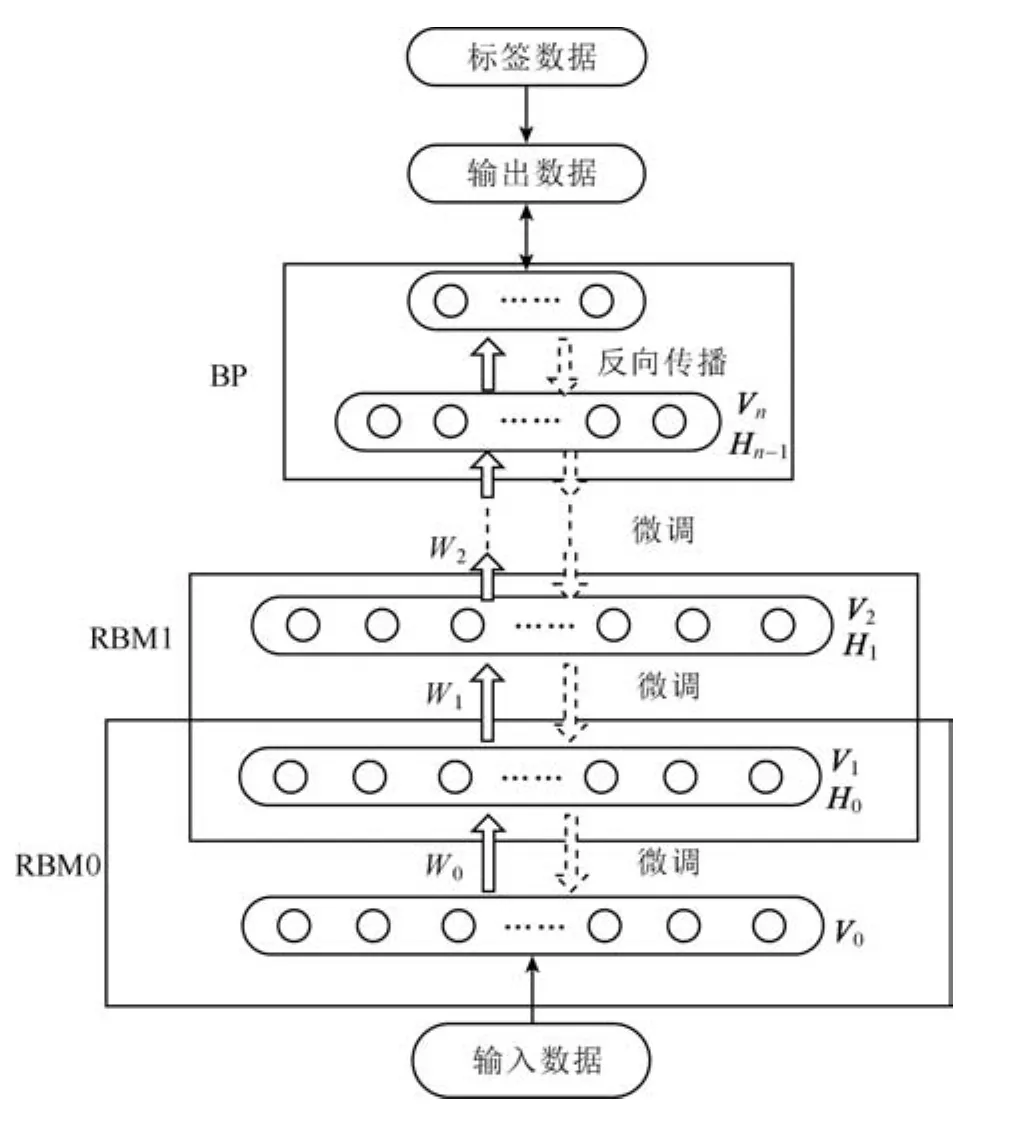
图1 ALRDBN结构Fig.1 The structure of ALRDBN

图2 受限玻尔兹曼机Fig.2 Restricted Boltzmann machine
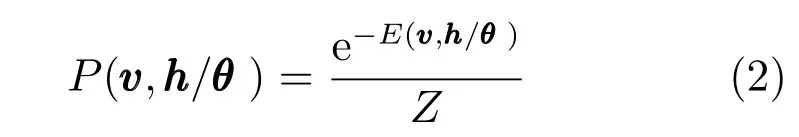
其中,Z是配分函数,可以看作为可视层和隐含层所有状态下的能量函数之和,如式(3)所示.
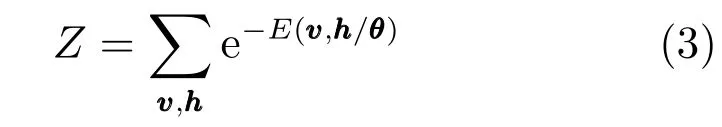
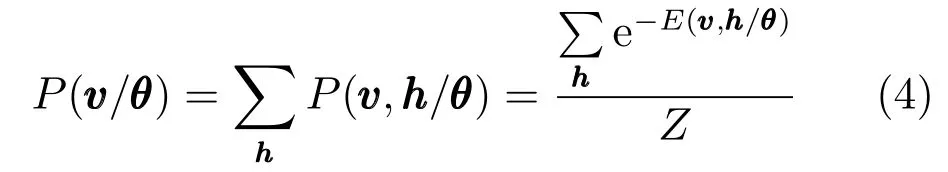
由RBM 的结构可以看出,从可视层到隐含层的映射以及对可视层的重构实质就是对神经元的激活,因此神经元的状态用0或1表示,0表示神经元处于关闭状态,1表示神经元处于开启状态.无论是可视层还是隐含层,同一层的节点之间是相互独立的,那么在给定可视层状态的情况下,隐含层第j个单元h被开启的概率可表示为


其中

判断激活和开始的标准常通过设定一个阈值[17]来实现,如式(8)所示.
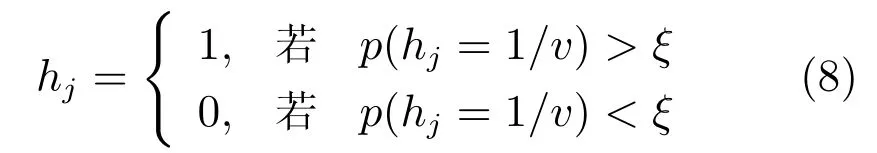
其中,ξ为一个介于0.5到1的常数.
重复式(5)和式(8)即为一个Gibbs采样过程,具有k个连续Gibbs采样的CD算法如图3所示.

图3 CD-k算法Fig.3 The algorithm of CD-k
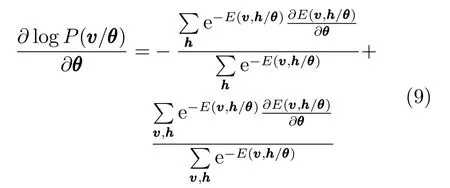
由贝叶斯定理可知
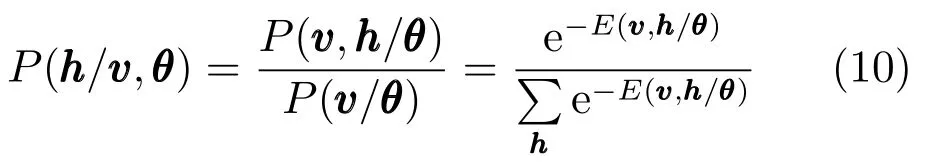
故,式(9)可表示为
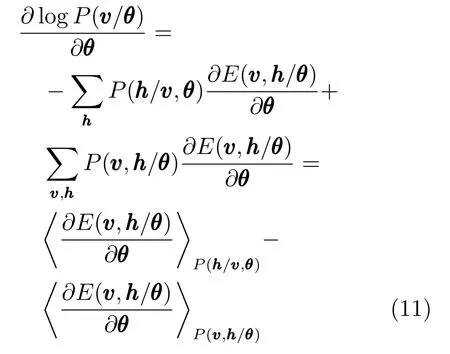
其中,h·iP表示求关于分布P的数学期望.
对于每一个训练样本,可以分别用“data”和“model” 来表示这两个概率分布,则对数似然函数对连接权值Wij、可视层单元的偏置ai和隐含层单元的偏置bj的偏导数分别为
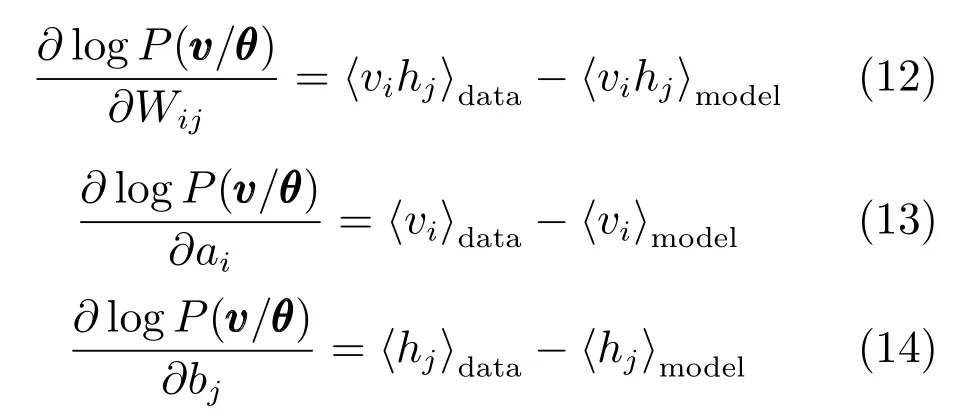
由于h·imodel的计算既费时且工作量又大,因此将Gibbs的采样个数缩至k个(CD-k准则),根据CD-k准则,参数集 θ∈{Wij,ai,bj}的更新公式为

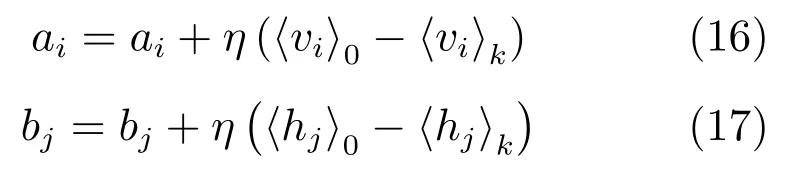
其中,η为学习率,大量研究工作证明,将k的值取1即能达到可视层和隐含层的平稳分布[12].
1.3 学习率自适应调整方法
在CD-k算法中,由于每个RBM 均需要多次迭代,且每次迭代后的参数更新方向不尽相同,所以固定的学习率会导致算法出现“早熟”现象或难以收敛,因此如何做到使算法根据合适的梯度来自适应地控制学习速度成为关键.根据RBM 训练过程连续两次迭代后的参数更新方向的异同设计ALRDBN算法,自适应学习率更新机制[15]为
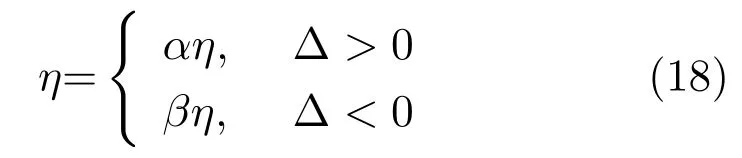
1)收敛速度在很大程度上是指受限玻尔兹曼机(RBM)无监督学习速度,而RBM 无监督学习是指从可视层接收的原始数据到隐含层所表示的抽象数据的过程,这一过程被称为Encoder,然后再经过一个Decoder过程来解决人们所期望的回归或者分类问题.自适应学习率以变步长的方式自动调节学习因子加速了单个RBM的Encoder过程,而ALRDBN是由多个RBM 顺序叠加组成的,上一个RBM的Encoder过程的输出作为下一个RBM的Encoder过程的输入,以此类推.Hinton教授在论文《Reducing the dimensionality of data with neural networks》中指出分层降维能够达到高维数据维数呈现指数下降的效果.同理,由于ALRDBN在功能上也是由多个RBM进行的分层表述,所以在单个RBM运用自适应学习率加速收敛的情况下,多个RBM分层表述能够产生收敛速度指数提高的效果.分层表述过程中Encoder和Decoder的网络结构如图4所示.
2)受限玻尔兹曼机(RBM)的权值学习过程是一种无监督的网络权值学习过程,它有别于以往的BP网络和RBF网络等的有监督学习过程.在以往的BP网络权值学习过程中学习率也有采取自适应形式的,也就是说学习率为非定值.但是BP网络通常是根据误差的大小来动态调整学习率的变化(如当误差较大时常常加大学习率来减小误差,当误差较小时常常减小学习率来防止震荡或者减小模型的误差).由于RBM是无监督学习网络,它的权值训练过程中学习率也采用自适应学习的方式调整,所以很难找到如BP算法类似结论,因为它是无监督的.无监督训练阶段,在误差曲面寻找最优点的过程中,这种学习率自适应调整方法能够既准确又迅速的找到满足目标函数的最优解.具体来说,自适应学习率算法能够根据误差曲面的凹凸性来自适应地增大或减小学习率,实现在预训练阶段加速收敛的效果.另外,在有监督微调阶段,自适应学习率算法能够有效地克服误差校正信号越来越微弱的缺点,避开了算法在寻优过程中处于循环波动和陷入局部最优的情况.

图4 ALRDBN分层表述结构Fig.4 Hierarchical representation structure of ALRDBN
3)在有监督训练阶段,图5是ALRDBN网络中来自输出层的误差反传过程.其中,表示第d组训练样本作用下最后一个隐含层中第i个神经元的输入状态,WWW 表示输出层和最后一个隐含层之间的连接权值,S表示输出层的输入,D表示训练样本个数和分别表示第d组训练样本作用下输出层第j个神经元的实际输出和期望输出,那么对应的误差可表示为,损失函数可定义为

那么损失函数对权值的导数为

其中

由式(20)可知,权值更新过程中误差校正信号为

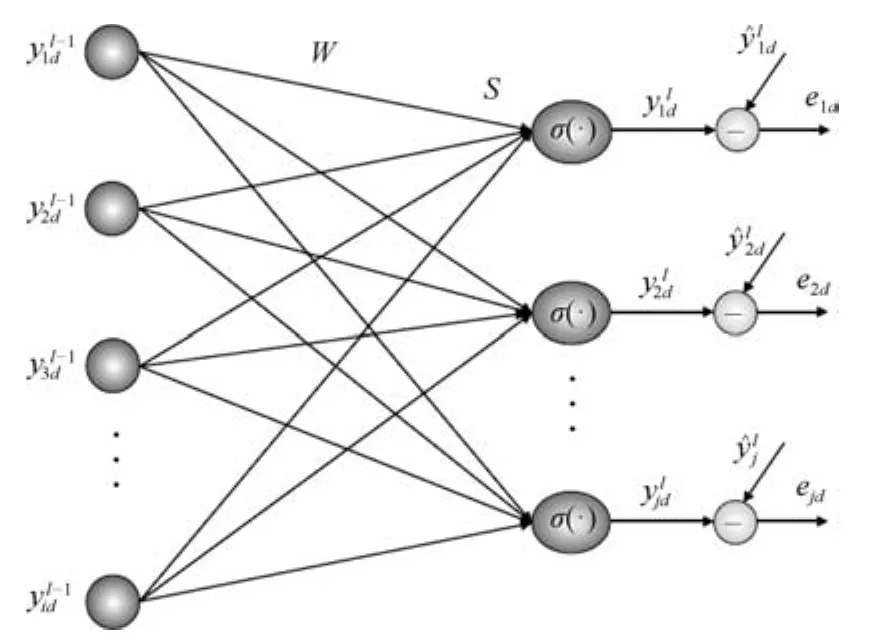
图5 ALRDBN顶层的反传误差Fig.5 Error back-propagated from top layer of ALRDBN
传统固定学习率算法的一个缺点就是,权值更新过程中的每一步调节并不总是朝着损失函数减小的方向进行,致使收敛速度大大降低.但是当学习率η以式(18)所示的规律自适应变化时,由式(22)可知,有监督学习阶段误差校正信号会根据连续两次更新方向的异同自适应地变化,能够克服传统固定学习率算法的这一缺点,从而加速收敛速度.同理可知,偏置项ai和bj寻优过程也会以相同的自适应方法加速收敛.
综上分析可知,基于自适应学习率算法下的权值更新思想是,如果连续两步的学习同时降低hvihji0与 hvihjik之间的差值,则学习率增大;相反地,如果增大了hvihji0与 hvihjik之间的差值则学习率减小[18−19].这种确定学习率变化系数的ALRDBN不仅能够提高网络的鲁棒性,还能够加速收敛过程.
2 网络性能分析
ALRDBN预训练过程是利用变学习率对每个RBM进行无监督学习,以期望提取更多的输入信息特征.不失一般性,将式(7)中Sigmoid函数的上下渐近线推广到AL和AH,和分别表示可视层的输入信息和重构状态,和分别表示隐含层状态,此时一次Gibbs采样过程中可视层和隐含层的状态表示如下
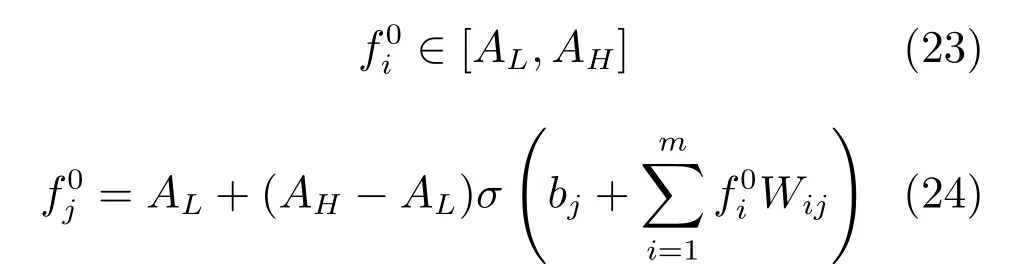

ALRDBN算法是一种对极大似然的近似,构成ALRDBN的所有RBM被逐一训练,上一个RBM的输出作为下一个RBM 的输入,在每个RBM的一次Gibbs采样过程中,网络输出与采样过程的中间状态有关.同时,自适应学习率对误差曲面最小点搜索的准确性起决定性作用,α过大或过小都会影响到算法的收敛速度和精度,甚至使网络不稳定.故通过以上论述,给出如下性能分析:
对于由3个隐含层构成的ALRDBN,若整个网络稳定,顶层RBM输出状态范围为,必满足且α与 ξ正相关.
另一方面,若网络稳定,则每个RBM的可视层和隐含层状态均满足有界性,即当第1个RBM的可视层输入为时,顶层RBM 的输出范围为].又因为Sigmoid函数是单调递增的,且随着被开启的神经元个数不断增加,可得


从式(8)可知,当ξ增大时隐含层神经元被开启的概率减小,Gibbs采样过程中所得到的可视层和隐含层神经元状态采样值的稀疏性[20−22]越明显,那么连续两次Gibbs迭代之后权值更新方向一致的概率增大,即
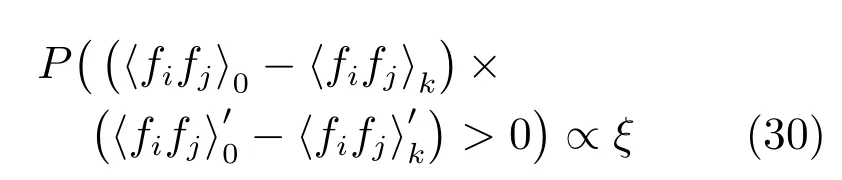
根据式(15)~(17)可知,当权值调整处于误差曲面比较平坦的区域时,加大学习率可以在不影响精度的情况下加快收敛速度,则有

由式(30)和(31)可知,ξ与α的数学定性关系式为

同时,在一个Gibbs采样过程中权值更新一次,而中间状态的二值化采样要进行两次,并且每次更新的权值与状态采样成正比,所以得到ξ与α的近似关系式如下:

ξ是对隐含层神经元状态(开启或者关闭)进行判别的概率阈值,取值范围是[0.5,1],在实际应用中常取值为0.7,由式(33)可得α的取值范围是[1,2],同理可知,β的取值范围是[0,1].
3 实验及分析
为了验证所提方法的有效性,本节对手写数字识别、CO2浓度预测和Lorenz时间序列预测等进行了仿真研究.为了消除其他无关因素对实验效果的影响,从而客观地反映所提方法的有效性,所有仿真实验的编译软件和计算机运行环境设置情况如下:编译软件为Matlab 8.2版本,计算机处理器为Intel(R)Core(TM)i7-4790,主频为3.6GHz,RAM为8GB.
3.1 手写数字识别
该实验数据源于MNIST手写数据库,该数据库拥有6万个训练图像和1万个测试图像,其中的数字都是手写体,每一个数字均用很多数量的手写方式来显示.随着模式识别和数据挖掘技术的不断发展,很多理论方法应用到该数据库中,所以该数据库被视为一种理想的、标准的测试新方法的经典对象.
取5000个样本用于训练,1000个样本用于测试.每张样本图像为0~9手写体的阿拉伯数字,像素为28×28,故可视层神经元个数设定为784个,每个神经元接收每张图像中的一个像素点.5000个样本分为50批次进行训练,每批次包含100个样本,每个RBM 迭代50次,故每层神经元个数默认为100个,学习率增大和减小系数的根据经验取值为:α=1.5,β=0.5.实验中根据RBM的分布,进行一次Gibbs采样后所获样本与原数据的差异称为重构误差,重构误差变化曲线能直观地反映出无监督学习的效果和收敛速度,重构误差可表示为


图6 顶层RBM的重构误差Fig.6 The reconstruction error of top RBM

图7 ALRDBN错误识别原图像Fig.7 The original images with classi fi cation mistakes of ALRDBN
由图6可以看出,重构误差一开始呈现急速下降趋势,当迭代到第30次时基本达到稳定(收敛),由此可以看出自适应学习率提高了算法的收敛速度;图7和图8显示,对1000个样本进行测试后产生了68处错误.
为了更好地展现ALRDBN的快速收敛性以及更高的识别精度,在相同的实验环境和设置下将ALRDBN与其他算法相比较,结果如表1所示,图9是隐含层神经元数与收敛时间的关系曲线.
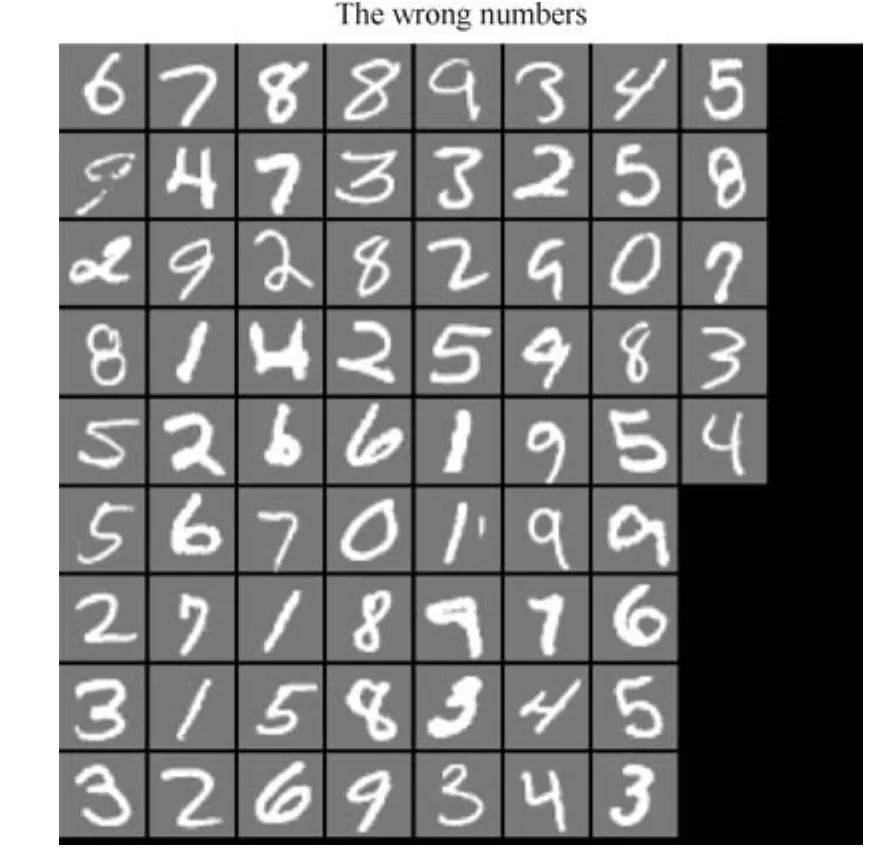
图8 ALRDBN错误识别图像Fig.8 The images with classi fi cation mistakes of ALRDBN
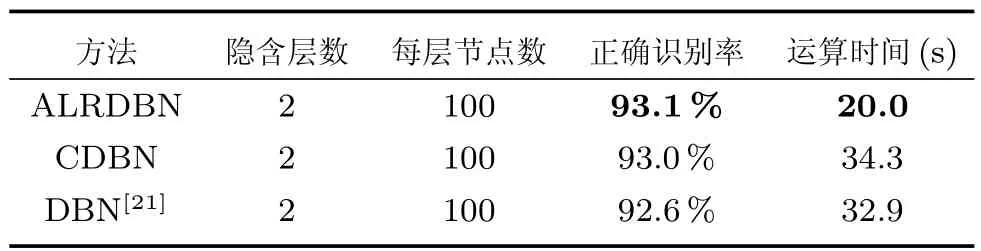
表1 MNIST手写数字实验结果对比Table 1 Result comparison of MNIST experiment
图9 隐含层神经元数对收敛时间的影响Fig.9 E ff ect of the number of hidden neurons on convergence time
由表1可以看出,在隐含层个数和每层神经元个数相同的情况下,ALRDBN的收敛速度最快,且对手写数字识别的正确率略有提高.同时,从图9可知,在相同的隐含层神经元数条件下ALRDBN的收敛时间最快.该MNIST手写数字识别实验证明,ALRDBN具有相对较好的学习能力和较快的收敛速度.
同时,为了更充分地说明学习率增大和减小系数α和β对加快算法收敛的影响,在确保其他实验参数不变以及ALRDBN性能稳定的前提下,将α和β取若干组不同的值并再次实验.图10是不同的α和β对应的算法收敛时间.可以看出,当α和β在第2节所确定的范围内取值时,算法收敛速度变化很微弱,收敛时间基本维持在20s左右,此时ALRDBN处于平稳状态.当α和β的取值超出稳定范围时,算法收敛时间出现跳跃式增加,此时ALRDBN处于不稳定状态.由此可见,第2节所确定的学习率增大和减小系数α和β的取值范围在理论和应用上得到了有效的验证.

图10 α和β对收敛时间的影响Fig.10 In fl uence of α and β on convergence time
3.2 预测大气CO2浓度变化
环境问题一直是世界各国关心的焦点之一,而CO2浓度的变化恰恰能反映出环境质量的好坏.大气中CO2浓度的增加导致全球变暖;反过来,气候的变化也会影响到碳循环,从而影响到大气中的CO2浓度.大气中CO2浓度的增加一方面取决于人为排放的增加(这也取决于世界人口增长速度、能源需求量的增加速度和开发速度以及替代能源的开发速度等等),另一方面又取决于自然CO2贮库对人为排放的CO2的响应,特别是生物圈和海洋的响应.因此为了客观地反映空气中CO2的浓度变化情况,选取西太平洋某海域的一个海岛CO2的浓度变化进行预测.实验使用此海岛1965年到1980的CO2浓度数据共187组,前100组数据作为训练样本对网络进行训练,后87组数据作为测试样本对网络进行测试,网络使用3个历史数据作为输入来进行一步预测.为了较好地学习到CO2数据的内在特征提高预测效果,采用的ALRDBN网络结构为3-20-40-1,每个RBM训练次数为200次,学习率增大和减小系数的根据经验取值为:α=0.5,β=1.5.有监督的微调阶段训练步数为10000次,仿真结果如图11、图12和图13所示.

图11 ALRDBN训练结果Fig.11 The training results of ALRDBN

图12ALRDBN测试结果Fig.12 The test results of ALRDBN
图11 是对网络的训练结果,图12是对网络的预测结果,可以看出该海岛所在地区CO2浓度在不同季节有规律地变化,这主要是由不同季节海岛居民的有规律活动引起的,但总体上呈现出逐年上升的趋势,这也符合当今全球CO2浓度逐年走高的现实情况(温室效应导致的全球变暖).图13是有监督阶段均方根误差的变化曲线,可以看出,一开始均方根误差急速下降后出现波动,这是因为一开始无监督学习过程中某两次参数更新方向不同而导致的,随着迭代次数的增加,学习率以自适应的方式不断加大,从而加速了学习过程.当迭代到1000次时基本趋于稳定,这说明自适应学习率提高了无监督学习算法的收敛速度并最终实现收敛.

图13 ALRDBN训练RMSEFig.13 The training RMSE of ALRDBN
为了更进一步说明实验效果,在相同的实验环境和参数设置下将ALRDBN与其他算法相比较,结果如表2和图14所示.
图14 隐含层神经元数对收敛时间的影响Fig.14 E ff ect of the number of hidden neurons on convergence time
表2 CO2浓度变化实验结果对比Table 2 Result comparison of CO2forecasting
由表2可以看出,BP网络在采用3-6-1的结构时网络性能相对稳定在一定的范围,这说明BP网络耗时且易陷入局部最优.在隐含层个数和每层神经元个数相同的情况下,深度神经网络中ALRDBN的运算速度(收敛速度)最快,同时均方根误差相对略有降低.实际经验表明,有规律的增加或者减少隐含层神经元个数可以获得优于表2的均方根误差.图14表明尽管随着隐含层神经元数的增加收敛时间延长,但是ALRDBN的收敛时间仍然是最快的.该CO2浓度变化预测实验证明,ALRDBN具有较快的收敛速度.另一方面,为了更充分地验证第2节所确定的α和β取值范围的有效性,在确保其他实验参数不变以及ALRDBN性能稳定的前提下,将α和β取若干组不同的值并再次实验.图15是不同的α和β对应的算法收敛时间,可以看出,当α和β在第2节所确定的范围内取值时算法收敛时间变化很微弱,ALRDBN处于平稳状态.当α和β的取值超出稳定范围时算法收敛时间出现跳跃式增加,此时ALRDBN处于不稳定状态.

图15 α和β对收敛时间的影响Fig.15 In fl uence of α and β on convergence time
3.3 Lorenz混沌时间序列预测
本实验目的是验证ALRDBN能够以较快的速度完成预测任务,即能够提高算法收敛的速度.混沌时间序列预测是检验神经网络结构和方法有效性的基准问题之一,Lorenz效应因其相位图酷似蝴蝶又称蝴蝶效应.实验中,取1500个样本用于训练,1000个样本用于测试,在网络中使用3输入进行一步预测,即用t−2,t−1和t时刻的信息预测t+1时刻的信息,ALRDBN网络结构为3-3-3-1每个RBM的迭代100次,微调阶段训练步数为5000次,实验结果如图16、图17和图18所示.
图16和图17分别是ALRDBN对Lorenz混沌时间序列的训练结果和预测结果,可以看出,ALRDBN很好地学习了Lorenz时序状态,并实现了较好的预测.图18是ALRDBN在有监督微调过程中均方根误差变化曲线,从图中可以看出,均方根误差一开始急速下降,这是因为无监督学习过程的初始阶段参数更新方向一致,学习率以自适应的方式不断加大,从而加速了学习过程.当迭代到500次左右时均方根误差基本趋于稳定,最终训练误差为0.0326.这说明基于自适应学习率算法收敛速度较快.为了更进一步展现实验效果,在相同的实验环境和参数设置下将ALRDBN与其他算法相比较,结果如表3和图19所示.由图19和表3可以看出,在隐含层个数和每层神经元个数以及网络总神经元个数相同的情况下,ALRDBN的收敛速度最快,同时均方根误差也略有降低.

图16 ALRDBN训练结果Fig.16 The training results of ALRDBN
图17 ALRDBN测试结果Fig.17 The test results of ALRDBN
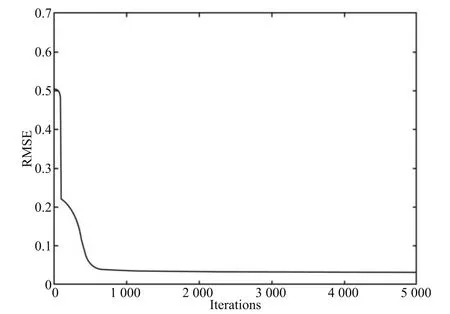
图18 ALRDBN训练RMSEFig.18 The training RMSE of ALRDBN
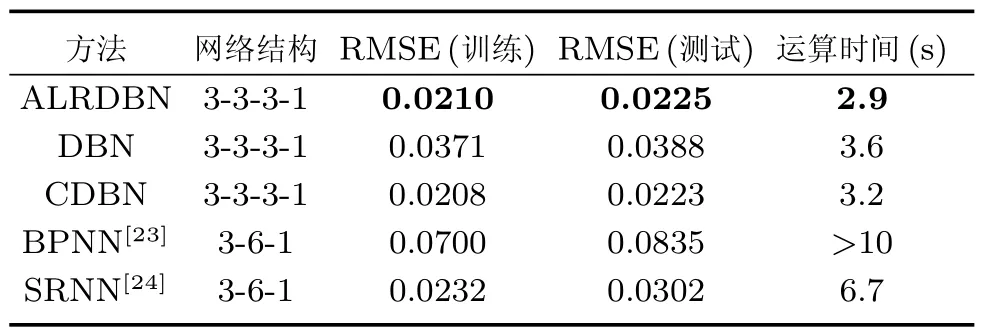
表3 Lorenz时序预测实验结果对比Table 3 Result comparison of Lorenz forecasting

图19 隐含层神经元数对收敛时间的影响Fig.19 E ff ect of the number of hidden neurons on convergence time
相应的,为了更充分的验证第2节所确定的α和β取值范围的有效性,在确保其他实验参数不变以及ALRDBN性能稳定的前提下,将α和β取若干组不同的值并再次实验.图20是不同的α和β对应的算法收敛时间,可以看出,当α和β在第2节所确定的范围内取值时算法收敛时间变化很微弱,ALRDBN处于平稳状态.当α和β的取值超出稳定范围时算法收敛时间出现跳跃式增加,此时ALRDBN处于不稳定状态.
4 总结与展望
针对DBN预训练耗时长的问题,文中将基于自适应学习率的思想引入到传统深度信念网中,提出了自适应学习率深度信念网的设计方法,并通过网络性能分析证明了网络的稳定性和有效性,同时给出了自适应学习率增大和减小系数的取值范围.最后,通过大量实验结果可以看出,该方法在提高算法收敛速度方面效果明显.
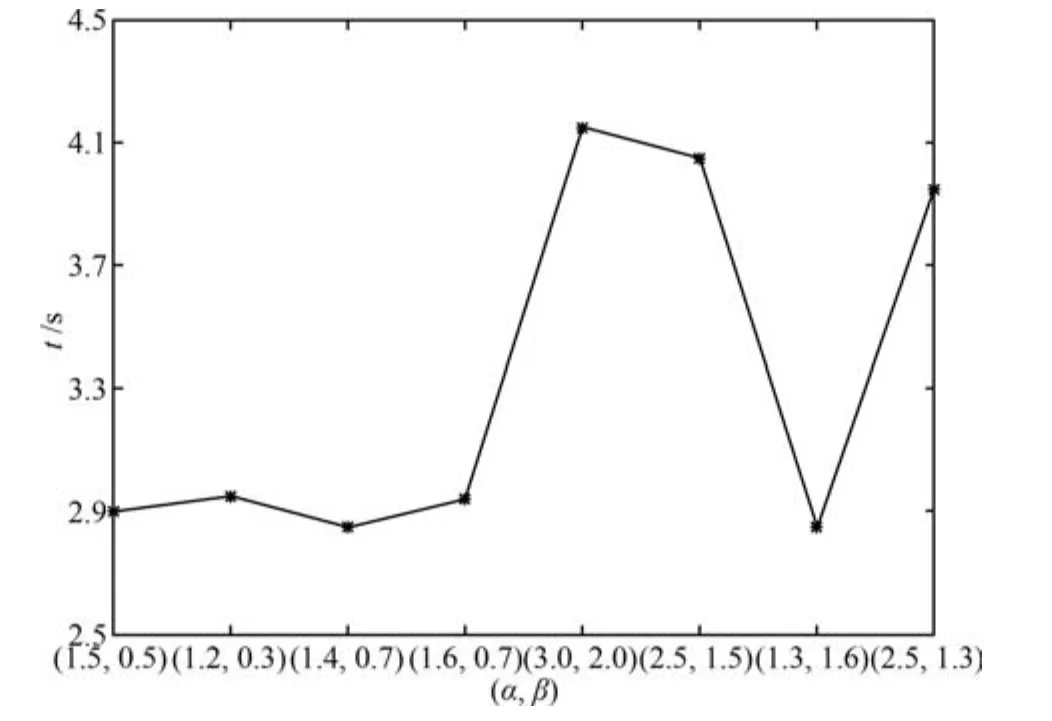
图20 α和β对收敛时间的影响Fig.20 In fl uence of α and β on convergence time
同时,文中也存在两方面的问题:1)在DBN隐含层个数和每层神经元个数的确定方面尚没有行之有效的统一理论方法,目前都是凭借经验设定,文中也是通过经验确定隐含层层数和每层神经元个数,这对DBN的应用效果带来很大的随机性.2)要想加快DBN的收敛速度,仅凭在学习算法上的改进(自适应学习率)是远远不够的,应该在考虑经济成本的基础之上试图更新硬件设备的性能来加速算法收敛.因此,如何解决这两个方面存在的问题将是DBN研究的一个热点方向,也是下一步工作的重点方向.
1 Bengio Y H,Delalleau O.On the expressive power of deep Architectures.In:Proceeding of the 22nd International Conference.Berlin Heidelberg,Germany:Springer-Verlag,2011.18−36
2 Hinton G E,Salakhutdinov R R.Reducing the dimensionality of data with neural networks.Science,2006,313(5786):504−507
3 Guo Xiao-Xiao,Li Cheng,Mei Qiao-Zhu.Deep learning applied to games.Acta Automatica Sinica,2016,42(5):676−684
(郭潇逍,李程,梅俏竹.深度学习在游戏中的应用.自动化学报,2016,42(5):676−684)
4 LeCun Y,Bengio Y,Hinton G.Deep learning.Nature,2015,521(7553):436−444
5 He Yu-Yao,Li Bao-Qi.A combinatory form learning rate scheduling for deep learning model.Acta Automatica Sinica,2016,42(6):953−958
(贺昱曜,李宝奇.一种组合型的深度学习模型学习率策略.自动化学报,2016,42(6):953−958)
6 Ma Shuai,Shen Tao,Wang Rui-Qi,Lai Hua,Yu Zheng-Tao.Terahertz spectroscopic identi fi cation with deep belief network.Spectroscopy and Spectral Analysis,2015,35(12):3325−3329
(马帅,沈韬,王瑞琦,赖华,余正涛.基于深层信念网络的太赫兹光谱识别.光谱学与光谱分析,2015,35(12):3325−3329)
7 Geng Zhi-Qiang,Zhang Yi-Kang.An improved deep belief network inspired by glia chains.Acta Automatica Sinica,2016,42(6):943−952
(耿志强,张怡康.一种基于胶质细胞链的改进深度信念网络模型.自动化学报,2016,42(6):943−952)
8 Abdel-Zaher A M,Eldeib A M.Breast cancer classi fi cation using deep belief networks.Expert Systems with Applications,2016,46:139−144
9 Rumelhart D E,Hinton G E,Williams R J.Learning representations by back-propagating errors.Nature,1986,323(6088):533−536
10 Mohamed A R,Dahl G E,Hinton G.Acoustic modeling using deep belief networks.IEEE Transactions on Audio,Speech,and Language Processing,2012,20(1):14−22
11 Bengio Y.Learning deep architectures for AI.Foundations and Trends in Machine Learning,2009,2(1):1−127
12 Lopes N,Ribeiro B.Improving convergence of restricted Boltzmann machines via a learning adaptive step size.Progress in Pattern Recognition,Image Analysis,Computer Vision,and Applications,Lecture Notes in Computer Science.Berlin Heidelberg:Springer,2012.511−518
13 Raina R,Madhavan A,Ng A Y.Large-scale deep unsupervised learning using graphics processors.In:Proceedings of the 26th Annual International Conference on Machine Learning.New York,NY,USA:ACM,2009.873−880
14 Ly D L,Paprotski V,Danny Y.Neural Networks on GPUs:Restricted Boltzmann Machines,Technical Report,University of Toronto,Canada,2009.
15 Lopes N,Ribeiro B.Towards adaptive learning with improved convergence of deep belief networks on graphics processing units.Pattern Recognition,2014,47(1):114−127
16 Le Roux N,Bengio Y.Representational power of restricted boltzmann machines and deep belief networks.Neural Computation,2008,20(6):1631−1649
17 Hinton G E.Training products of experts by minimizing contrastive divergence.Neural Computation,2002,14(8):1771−1800
18 Yu X H,Chen G A,Cheng S X.Dynamic learning rate optimization of the backpropagation algorithm.IEEE Transactions on Neural Networks,1995,6(3):669−677
19 Magoulas G D,Vrahatis M N,Androulakis G S.Improving the convergence of the backpropagation algorithm using learning rate adaptation methods.Neural Computation,1999,11(7):1769−1796
20 Lee H,Ekanadham C,Ng A.Sparse deep belief net model for visual area V2.In:Proceedings of the 2008 Advances in Neural Information Processing Systems.Cambridge,MA:MIT Press,2008.873−880
21 Ji N N,Zhang J S,Zhang C X.A sparse-response deep belief network based on rate distortion theory.Pattern Recognition,2014,47(9):3179−3191
22 Qiao Jun-Fei,Pan Guang-Yuan,Han Hong-Gui.Design and application of continuous deep belief network.Acta Automatica Sinica,2015,41(12):2138−2146
(乔俊飞,潘广源,韩红桂.一种连续型深度信念网的设计与应用.自动化学报,2015,41(12):2138−2146)
23 Chang L C,Chen P A,Chang F J.Reinforced two-stepahead weight adjustment technique for online training of recurrent neural networks.IEEE Transactions on Neural Networks and Learning Systems,2012,23(8):1269−1278
24 Chen Q L,Chai W,Qiao J F.A stable online selfconstructing recurrent neural network.Advances in Neural Networks―ISNN 2011.Berlin Heidelberg:Springer,2011,6677:122−131

乔俊飞 北京工业大学教授.主要研究方向为智能控制,神经网络分析与设计.E-mail:junfeq@bjut.edu.cn
(QIAO Jun-Fei Professor at Faculty of Information Technology,Beijing University of Technology.His research interest covers intelligent control,analysis and design of neural networks.)

王功明 北京工业大学博士研究生.主要研究方向为深度学习,神经网络结构设计和优化.本文通信作者.
E-mail:xiaowangqsd@163.com
(WANG Gong-Ming Ph.D.candidate at Faculty of Information Technology,Beijing University of Technology.His research interest covers deep learning,analysis and design of neural networks.Corresponding author of this paper.)

李晓理 北京工业大学教授.1997年获得大连理工大学控制理论与工程硕士学位,2000年获得东北大学博士学位.主要研究方向为多模型自适应控制,神经网络控制.
E-mail:lixiaolibjut@bjut.edu.cn
(LI Xiao-Li Professor at Faculty of Information Technology,Beijing University of Technology.He received his master degree in control theory and control engineering from Dalian University of Technology in 1997,and Ph.D.degree from Northeastern University in 2000,respectively.His research interest covers multiple model adaptive control and neural network control.)

韩红桂 北京工业大学教授.主要研究方向为污水处理工艺复杂建模与控制,神经网络分析与设计.
E-mail:rechardhan@sina.com
(HAN Hong-Gui Professor at Faculty of Information Technology,Beijing University of Technology.His research interest covers modelling and control in waste water treatment process,analysis and design of neural networks.)

柴伟 北京工业大学讲师.主要研究方向为系统辨识和状态估计研究.
E-mail:chaiwei@bjut.edu.cn
(CHAI Wei Lecturer at Faculty of Information Technology,Beijing University of Technology.His research interest covers system identi fi cation and state estimation.)
Design and Application of Deep Belief Network with Adaptive Learning Rate
QIAO Jun-Fei1,2WANG Gong-Ming1,2LI Xiao-Li1HAN Hong-Gui1,2CHAI Wei1,2
A deep belief network with adaptive learning rate(ALRDBN)is proposed to solve the time-consuming problem in the pre-training period of DBN.The ALRDBN introduces the idea of adaptive learning rate into contrastive divergence(CD)algorithm and accelerates its convergence by a self-adjusting learning rate.The training method of weights in this case is designed,in which the adjusting scope of the coefficient in learning rate is determined by performance analysis.Finally,a series of experiments are carried out to test the performance of ALRDBN,and the corresponding results show that the convergence rate is accelerated signi fi cantly and the accuracy of prediction is improved as well.
Deep belief network,adaptive learning rate,contrastive divergence,convergence rate,performance analysis
May 10,2016;accepted October 9,2016
乔俊飞,王功明,李晓理,韩红桂,柴伟.基于自适应学习率的深度信念网设计与应用.自动化学报,2017,43(8):1339−1349
Qiao Jun-Fei,Wang Gong-Ming,Li Xiao-Li,Han Hong-Gui,Chai Wei.Design and application of deep belief network with adaptive learning rate.Acta Automatica Sinica,2017,43(8):1339−1349
2016-05-10 录用日期2016-10-09
国家自然科学基金(61533002,61473034),国家杰出青年科学基金(61225016),内涵发展—引进人才科研启动费资助
Supported by National Natural Science Foundation of China(61533002,61473034),National Natural Science Fund for Distinguished Young Scholars(61225016),Connotation Development—Scienti fi c Research Start-up Funds of Talent Introduction
本文责任编委王占山
Recommended by Associate Editor WANG Zhan-Shan
1.北京工业大学信息学部北京 100124 2.计算智能与智能系统北京市重点实验室北京100124
1. Faculty of Information Technology,Beijing University of Technology,Beijing 100124 2. Beijing Key Laboratory of Computational Intelligence and Intelligent System,Beijing 100124
DOI10.16383/j.aas.2017.c160389
