面向百度百科的化学知识图谱构建方法研究
2017-09-09钟亮
钟亮


摘 要:针对百度百科这一数据源,构建了化学知识图谱。首先,利用网络爬虫技术对数据进行采集与清洗;然后,采用中文分词、实体识别、实体关系识别等技术对知识图谱构建方法进行实证性研究,可视化实验所得实体及实体关系,并对实验结果进行了相关评价测试。最后,简要阐述了知识图谱的应用领域与发展优势。研究结果表明,实体关系识别的预测准确率较高。
关键词:百度百科; 知识图谱; 网络爬虫; 实体识别
DOIDOI:10.11907/rjdk.172205
中图分类号:TP319
文献标识码:A 文章编号文章编号:1672-7800(2017)008-0168-03
0 引言
知识图谱(Mapping Knowledge Domains)是显示科学知识发展进程与结构关系的谱系,具有“图”、“谱”的双重性质和特征:既是可视化的知识图形,又是序列化的知识谱系[1]。知识图谱可以绘制、挖掘、分析和显示科学技术知识以及它们之间的相互关系,是在大数据时代背景下产生的一种新型的海量知识管理与服务模式[2]。其研究目标是借助现代技术与理论使知识可视化,让人们更加方便、准确地获取知识。知识图谱作为知识的载体,能用图形化的方式将人们不易理解的信息形象地表示出来[3],通过内容分析、引文分析、自然语言处理等方法和可视化的方式显示知识结构及其相互关系,既符合人类的认知习惯,又充分利用了现代信息技术;使用户既能快速获取知识及其之间的逻辑关系,又能从海量文献中把握关键的知识点[4],还能从丰富的网络知识库中提取更多有效的知识进行关系补充,从而更好地把握学科知识结构。
随着互联网中用户生成内容和幵放链接数据等大量RDF数据被发布,互联网逐步从仅包含网页与网页之间超链接的文档万维网转变为包含大量描述各种实体和实体之间丰富关系的数据万维网。在此背景下,Google公司于2012年推出了Google Knowledge Graph[5],其初衷是用于改善搜索结果。紧随其后,国内外的其它互联网搜索引擎公司也纷纷构建了自己的知识图谱,例如微软的Probase[6]、搜狗的“知立方”、百度的“知心”、清华大学构建的XLore[7]、上海交通大学构建的Zhishi.me[8]和复旦大学GDM实验室的“知识工场”等。
1 数据源分析
研究通过网络爬虫对百度百科中与“化学”主题相关的词条信息进行抓取,为知识抽取模块产生原始数据基础。在进行爬虫抓取和知识抽取时应注意:百度百科中的基本单元为文章,一篇文章(消歧页面除外)对应一个实体,文章的标题(title,即词条名)通常为对应实体的名称;信息模块以表格的形式存在,用于表述文章对应实体的属性;百度百科中存在重定向机制,用于当用户以不同的检索条件检索到同一篇文章时的定位;当检索条件蕴含多种意义时进行所有意义的列举。
数据采集方式是运用Java语言,通过网络爬虫的方式进行的。其爬虫抓取策略为:多线程、深度优先遍历、广度优先遍历、反向连接数等策略,爬虫处理流程如图1所示。
利用该爬虫程序构建了以“化学”这一关键词为主题的百度百科数据集,并采用人工剔除的方式辅助筛选出了5 631个词条信息(包括词条名、词条内容与URL),其爬虫程序入口如图2所示。
2 知识图谱构建
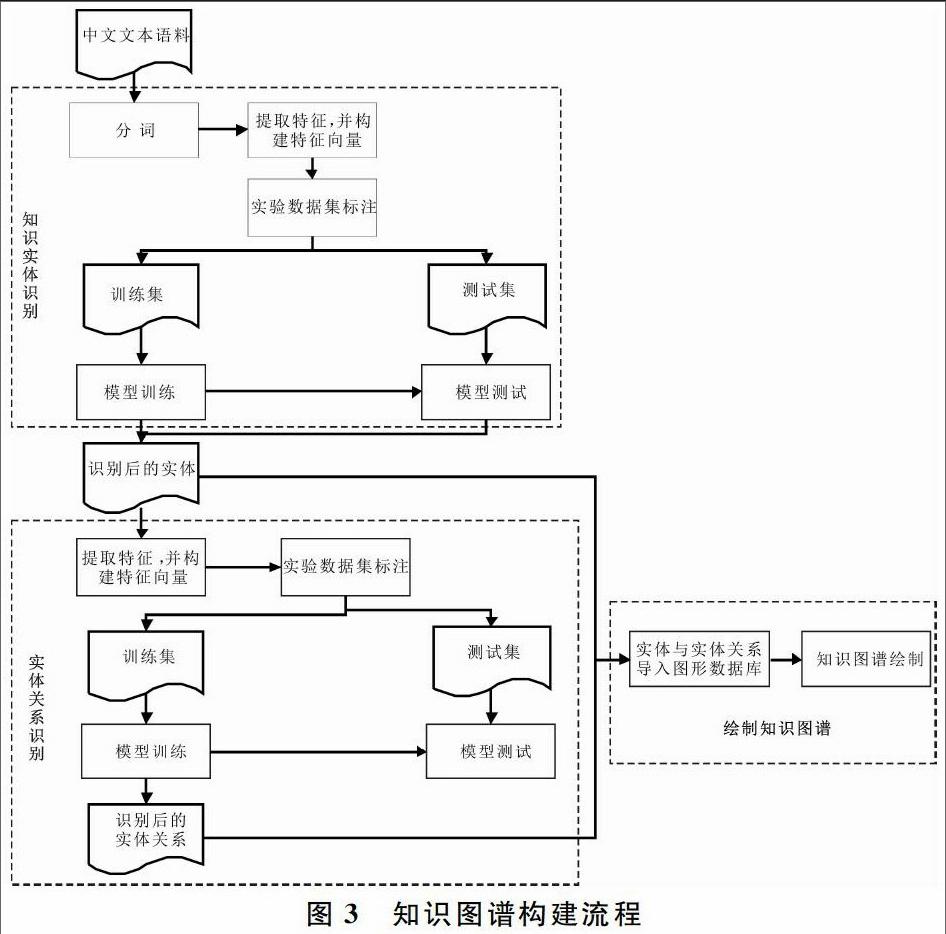
在知识图谱构建过程中,最重要的3个环节就是抽取知识实体、识别知识实体间关系与绘制知识图谱。其中尤以知识实体抽取和知识实体间关系的识别最为关键。将知识单元抽取、知识间关系的识别映射为实体识别和实体关系识别后,就可以得到知识图谱构建流程,如图3所示。
2.1 分词
实验研究选择R语言环境下的Rwordseg包进行分词。其中Rwordseg包是基于中科院的ICTCLAS中文分词分析算法编写而成的,可以实现中文分词、关键词提取、多级词性标注等功能,还可以导入自定义词典进行辅助分词。分词结果示例如图4所示。
2.2 知识实体识别
在知识实体识别之前,需要对数据进行预处理(包括语料的清洗、每个词的上下文窗口词提取、去除没有实际意义的词等),并进行特征选择(包括词特征、词性特征、词典特征、上下文窗口特征、每个词对应的TF-IDF值等),构建相应的特征向量。
特征选择过程中采用Python实现TF-IDF算法,其核心代码如下:
from sklearn.feature_extraction.text import TfidfTransformer
from sklearn.feature_extraction.text import CountVectorizer
將得到的词语转换为词频矩阵:
freWord = CountVectorizer()
统计每个词语的tf-idf权值:
transformer = TfidfTransformer()
计算出tf-idf(第一个fit_transform),并将其转换为tf-idf矩阵(第二个fit_transformer):
tfidf = transformer.fit_transform(freWord.fit_transform(data))
获取词袋模型中的所有词语:
word = freWord.get_feature_names()
得到权重:
weight = tfidf.toarray()
2.3 实体关系识别
在知识实体识别之后,可以利用已识别的实体进行实体间关系的识别。为了确保实体关系识别过程中所输入信息的准确性,仍需对实体识别结果进行预处理(包括实体对提取与实体对标注),最后针对预处理后的数据进行特征选择(包括实体特征、实体类型特征、实体相对位置特征、实体间距离特征、上下文窗口特征等)。endprint
2.4 实验结果分析
为了对实验结果进行评估,实验运用了人工神经网络算法(ANN)对实验数据进行训练和测试,实验评估纳入3个评价指标,分别是准确率、召回率与F-值,其计算公式如下:
准确率=正确识别的实体数(正确识别的实体关系数)识别出的实体总数(识别出的实体关系总数)×100%(1)
召回率=正确识别的实体数(正确识别的实体关系数)实际实体总数(实际实体关系总数)×100%(2)
F=2×准确率×召回率准确率+召回率×100%(3)
分析结果见表1。
实验结果结果表明,实验对知识实体识别和实体关系识别效果有所不同,在知识实体判别中,F-值只有74.9%,而对于实体关系的判别,F-值达到了82.4%。从实验具体过程来看,主要有以下两个原因:
①实验训练样本较小。研究只筛选出5 631个实体参与样本训练,影响了实验的实际效果。
②特征选择粒度存在问题。此次实验在对特征进行选择时,把词作为特征提取单元,其目的是为了使上下文窗口涵盖更多的信息。词与单个字符比较而言,虽然包含的信息较多,但是粒度也相对较粗,在分析过程中可能会丢失一些比较重要的字符集信息。
2.5 知识图谱绘制
实验获得的实体和实体关系可用来绘制知识图谱的知识单元和知识单元间的关系。研究采用NLPIR实体抽取系统中基于角色标注的实体抽取方法对实体进行抽取,并运用基于POS-CBOW的Word2vec语义扩展模型对实体关系进行抽取,知识单元与知识单元关系抽取示例如图5所示。
3 结语
研究构建了面向百度百科的化学知识图谱构建方法,具体构建过程包括知识实体抽取、实体间关系抽取和绘制知识图谱3个步骤。
知识图谱为互联网上海量、异构、动态的大数据表达、组织、管理以及利用提供了一种更为有效的方式,使得网络的智能化水平更高,更加接近于人类的认知思维。目前,知识图谱已在智能搜索、深度问答、社交网络以及一些垂直行业中有所应用[9]。但大规模知识图谱的应用场景和方式还比较有限,许多领域的应用也只是处于初级阶段,具有很大的可扩展空间。人们在挖掘需求、探索知识图谱的应用场景时,应充分考虑知识图谱的以下优势:①对海量、动态、异构的半结构化与非结构化数据的有效组织和表达能力;②借助强大知识库进行深度知识推理的能力;③与类脑科学、深度学习等领域相结合,逐步扩展人类认知能力。
在熟练掌握知识图谱相关理论与技术的基础上,敏锐感知人们的需求,可以为大规模知识图谱的应用找到更宽广的道路。
参考文献:
[1] 曾宜玲.浅析教育学知识图谱的有用性[J].文学教育:中,2017,13(2): 112-112.
[2] 刘则渊, 陈悦, 侯海燕,等.科学知识图谱: 方法与应用[M].北京:人民出版社, 2008.
[3] 陈悦, 刘则渊, 陈劲,等.科学知识图谱的发展历程[J].科学学研究,2008,26(3):449-460.
[4] 唐欽能, 高峰, 王金平.知识地图相关概念辨析及其研究进展[J].情报理论与实践,2011,34(1):121-125.
[5] STEINER T,VERBORGH R,GABARRO J, et al. Adding realtime coverage to the Google knowledge graph[C].The International Conference on Posters & Demonstrations Track. CEUR-WS.org, 2012: 65-68.
[6] WU W,LI H,WANG H, et al. Probase: a probabilistic taxonomy for text understanding[J]. In:SIGMOD,2012: 481-492.
[7] WANG Z,LI J,WANG Z,et al. XLore: a large-scale english-Chinese bilingual knowledge graph[C]. International Semantic Web Conference(Posters \\& Demos),2013: 121-124.
[8] XING NIU,XINRUO SUN,HAOFEN WANG,et al. Zhishi.me: weaving chinese linking open data[C]. International Conference on the Semantic Web. Springer-Verlag, 2011: 205-220.
[9] 徐增林, 盛泳潘, 贺丽荣, 等. 知识图谱技术综述[J].电子科技大学学报, 2016, 45(4): 589-606.endprint
