基于相似度匹配的软件缺陷预测方法研究
2017-09-09刘雅新吴高艳何鹏
刘雅新+吴高艳+何鹏


摘 要:针对跨项目缺陷预测(Cross-Project Defect Prediction,CPDP)中为目标项目选择合适的训练数据问题,在已有相似度匹配方法的基础上,引入项目情境信息,从而提出一种改进的CPDP预测模型。实验结果表明:引入项目的情境信息,有助于提高CPDP性能;所提方法的F-measure值比已有方法提高了15.04%和6.57%,但相比WPDP方法,仍有待提高。
關键词:软件质量保证;缺陷预测;相似度匹配;训练数据选择
DOIDOI:10.11907/rjdk.171465
中图分类号:TP301
文献标识码:A 文章编号文章编号:1672-7800(2017)008-0009-03
0 引言
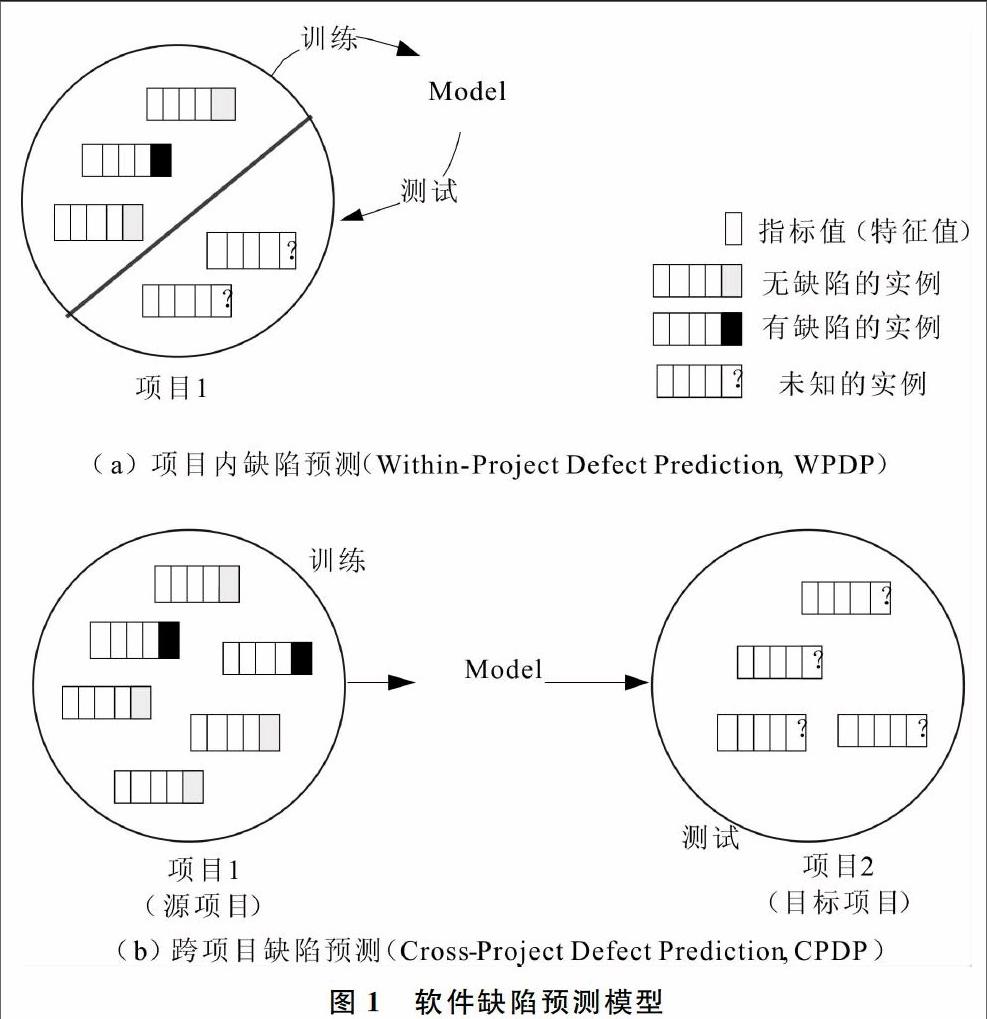
软件缺陷预测研究一直是软件工程领域中的热门方向,最早可以追溯到上世纪70年代。常规的方法是利用项目自身已有历史数据训练预测模型后,再用于后续版本的缺陷预测,即项目内缺陷预测(Within-Project Defect Prediction,简称WPDP),如图1(a)所示。然而,已有研究表明训练高质量的WPDP模型要求有充足的历史数据,这对一些新项目或还不活跃的软件项目便难以满足。
近些年来随着互联网的蓬勃发展,尤其是开源社区如 Github的兴起,互联网上可供获取的公开缺陷数据集越来越多,而且数量仍在不断增长。为有效利用互联网上已有的丰富数据资源,一些研究者提出利用其它软件项目的数据来训练,构建跨项目的缺陷预测模型(Cross-Project Defect Prediction, 简称CPDP),用于解决WPDP中训练数据受限的瓶颈[1-5],如图1(b)所示,为软件缺陷预测研究开辟了一条崭新的途径。
在CPDP早期研究中,都是将来自其它软件项目的所有数据作为训练集,并不涉及训练集的精简。常常出现因训练数据包含过多噪声,从而降低了模型准确性[5]。在某种程度上,数据的质量远比数量对CPDP性能的影响更大。然而,如何才能从大量的可供使用的缺陷数据中挑选出质量更高的部分用于预测模型训练,仍然是CPDP研究中急需解决的一个问题[6]。
针对以上问题,目前主要有两种思路。一种是通过特征降维的方法减少冗余指标信息,从而减少数据噪音来改善缺陷预测的性能和效率[7]。另一种方法则是本文将考虑的通过减少数据量来减少重复的无价值的实例[8]。在训练数据总量的精简方面,以往研究都只是根据数据的度量指标信息进行相似度匹配,再返回top-k个最相关的实例构成新的训练数据集,但它们并没有充分考虑项目的情境信息。实践中,每个项目的情境信息存在差异,例如项目的主题、服务对象、编程语言等。
本文在为CPDP预测选择合适跨项目训练数据集时,通过考虑项目的5个常规属性信息(包括项目主题、目标受众、编程语言、运行环境、开源认证),并利用自然语言处理中的TF-IDF技术将它们量化,从而得到每个项目的情境信息向量。最后,结合项目的情境信息与项目中实例特征值计算数据集的相似度。本文的主要贡献可归纳为:
(1)引入项目的情境信息,提出一种改进的基于相似度匹配的CPDP预测方法,并使CPDP预测性能得到改进。
(2)验证本文方法的CPDP预测模型在朴素贝叶斯分类器下效果最好。
1 跨项目缺陷预测(CPDP)
CPDP形象表示为利用其它项目组成的缺陷数据集S={P1,P2,…,Ps}对目标项目Pt作缺陷预测。假设一个项目P由n实例(类文件)组成,即P={I1,I2,…,Ii,…,In},实例Ii表示为Ii={fi1,fi2,…,fij,…,fim},fij为实例Ii在第j个度量指标上的值,m为用于度量实例的指标个数。一个项目数据集P中度量指标Fi对应的向量可表示为Fi={f1i,f2i,…,fji,…,fni},fji为第j个实例在该度量指标上的值,各实例指标值的分布特性可表示为Ci={SCi1,SCi2,…,SCik},SC为对应的度量指标值的分布特性(最大值、最小值、中位数、均值和标准方差)。因此,项目P可根据度量指标量化为V={C1,C2,…,Ck,…,Cm}。 这样,项目A和B之间的相似性可表示为:
Sim(A,B)metric=cos(VA,VB)=VA·VB|VA||VB|(1)
另外,假定每个项目情境信息按照主题、目标受众、编程语言、运行操作系统、认证顺序来进行量化表示,则可以表示为U=(ATt,ATia,ATpl,ATos,ATlic),其中ATi分别为上述属性前面几个字母的缩写。因此,项目A和B之间的属性相似性可表示为:
Sim(A,B)context=cos(UA,UB)=UA·UB|UA||UB|(2)
而表示项目情境信息的每个属性本身又为一个向量ATi=(wi1,wi2,…,wim), m为属性i中包括的元素种类,因此,项目情境信息相似性为所有5个属性向量下的余弦相似性总和,可用式(3)表示,系数α表示每个属性的比重系数,本文视每个属性具有相同的重要性,即α=0.2。
Sim(A,B)context=∑ni=1αicos(AATi,BATi)(3)
对于每个属性向量ATi中的wij,可通过修改后的tf,idf表示为式(4):
wij=(logfij+1)log#p#pj(4)
其中,fij为项目在属性i元素j上的频率,#p和#pj分别代表项目总数和具有元素j的项目数。结合式(3)和式(4),得到:
cos(AATi,BATi)=∑j∈Ai∩Bi(logfij+1)(logfij+1)(log#p#pj)2∑j∈Ai((logfij+1)·log#p#pj)2∑j∈Bi((logfij+1)·log#p#pj)2(5)endprint
最后,在跨项目数据集选择过程中,结合项目的两种信息,得到最终的相似度得分:Score(A,B)=Sim(A,B)metric+Sim(A,B)context(6)
对应算法实现描述如下:
算法1:基于相似度匹配的CPDP输入:
1.候选训练数据集S={P1,P2,…,Pl};
2.目标项目数据集Pt={I1,I2,…,Ii,…,In1};输出:
3.返回预测结果result。方法实现:
4.P是为Pt从候选集S中返回的最相似的数据集;
5.初始化P←Φ
6.for 每个项目Pi(Pi∈S) do;
7.// 对Pi,P进行相似度匹配
8.Set tempScore←Score(Pi,Pt)
9.end for
10.//取集合tempScore中与目标项目Pt最相似的项目
11.P←Max(tempScore);
12. //用选择的数据集P训练模型并对Pt进行预测
13.resultPtmodel(P);//CPDP预测14.返回result
2 实证分析
2.1 数据集
本次实验使用PROMISE提供的10个项目缺陷数据集,表1给出了每个项目的相关信息。数据集中每个实例表示一个类文件(.java),包括20个源代码度量指标用于量化实例,其中CK套件10个、Martins指标2个、QMOOM套件5个、McCabes CC指标2个,以及代码行LOC。
2.2 分类器与评价指标
本文采用朴素贝叶斯分类器(Nave Bayes)作为本次CPDP预测模型训练的分类器,Nave Bayes是一个基于条件概率最简单的分类器,其之所以被称之为“朴素”是因为它假设所有特征之间都是相互独立的。数学表示为P(X|Y)=∏ni=1P(xi|Y),X={x1,x2,…,xn}为一个特征向量,Y为分类变量。尽管现实中这种独立假设并不完全成立,但朴素贝叶斯已在很多实践研究中得到有效的应用[9]。在预测过程中,给定一个新的实例(类文件),朴素贝叶斯分类器通过计算该类在各个特征值上的条件概率的乘积来评估存在缺陷的概率,式(7)为基本的计算公式:
P(Y=k|X)=P(Y=k)∏iP(xi|Y=k)∑jP(Y=k)∏iP(xi|Y=k)(7)
预测过程中存在4种可能情况:假阳性(FP)、假阴性(FN)、真阳性(TP)与真阴性(TN)。根据4种预测结果可计算准确率(precision)、召回率(recall)和F-measure评价指标。准确率用来衡量有多少真实存在缺陷的实例被成功地预测。准确率越高,表明无缺陷实例被误认为有缺陷的情况会更少。
precision=TPTP+FP(8)
召回率用来衡量被预测为有缺陷的实例中有多少是真实存在缺陷。召回率越高,表明有缺陷实例被误认为无缺陷的情况会更少。
recall=TPTP+FN(9)
F-measure用来平衡准确率与召回率,为两者的加权平均值。F-measure 越接近1 表示预测效果越好。
F-measure=2*precision*recallprecision+recall(10)
2.3 实验结果
问题1:引入项目的情境信息,是否有助于提高CPDP性能?
实验结果如图2所示,不难发现,在为目标项目选择合适的跨项目数据集过程中,引入项目的情境信息后的CPDP模型性能比不使用时整体都有所提高,其中项目Synapse、Ant和Jedit三個项目性能改进最为显著,F-measure值改进幅度分别为0.32(86.7%)、0.222(66.2%)和0.207(64.3%)。因此,实验结果证实,引入项目的情境信息,有助于提高CPDP性能。
问题2:相比已有CPDP方法,本文所提方法是否性能更好?
为了进一步验证本文所提出的方法的有效性,引入文献[1]、[5]中提出的CPDP方法作为比较对象。此外,与WPDP方法进行对比,如图3所示。结果显示,本文所提方法相比两种基准方法baseline1和baseline2整体性能分布有所提高,表现为前者均值为0.512,两种基础方法的均值分别为0.445和0.481,改进比例分别为15.04%和6.57%,且最大值和最小值均有所提高。然而,本文方法相比于WPDP方法,仍然表现出一定差距。WPDP的均值为0.621,说明选用其它项目的数据训练出的模型仍不如目标项目自身的数据更可靠。尽管如此,但考虑到现实中,对于一些新项目或不活跃的项目,它们可供使用的历史数据并不多,在此数据不充分的情境下,即便是有WPDP方法,相信效果也依旧不佳。
本文不足之处:①实验数据只选取了10个项目,实验结论还有待在更多项目数据集上加以验证;②本文只考虑了5个项目属性用于表达情境信息,根据开源社区中提供的信息,表达项目情境的属性还有很多,有待进一步探索。
3 结语
本文围绕跨项目缺陷预测开展研究,针对为目标项目选择合适的训练数据问题,在以往通过项目实例度量指标相似度匹配的基础上,引入项目的情境信息,从而改进CPDP预测模型。实验结果表明:①引入项目的情境信息,有助于提高CPDP性能;②相比两种基准方法,笔者的方法整体性能有提高,分别提高15.04%和6.57%,但相比WPDP方法,依旧还有待提高。
参考文献:
[1] HE Z, SHU F, YANG Y, et al. An investigation on the feasibility of cross-project defect prediction[J]. Automated Software Engineering, 2012, 19(2):167-199.endprint
[2] TURHAN B, MENZIES T, BENER A B, et al. On the relative value of cross-company and within-company data for defect prediction[J]. Empirical Software Engineering, 2009, 14(5):540-578.
[3] RYU D, JANG J, BAIK J. A hybrid instance selection using nearest-neighbor for cross-project defect prediction [J]. Journal of Computer Science and Technology, 2015,30(5):969-980.
[4] ZIMMERMANN T, NAGAPPAN N, GALL H, et al. Cross-project defect prediction a large scale experiment on data vs.domain vs.process[C].Joint Meeting of the European Software Engineering Conference and the ACM International Symposium on Foundations of Software Engineering, Amsterdam, Netherlands, 2009:91-100.
[5] PETERS F, MENZIES T, MARCUS A. Better cross company defect prediction[C].Working Conference on Mining Software Repositories. San Francisco, USA, 2013:409-418.
[6] 王星, 何鵬, 陈丹,等. 跨项目缺陷预测中训练数据选择方法[J]. 计算机应用, 2016, 36(11):3165-3169.
[7] LU H, CUKIC B, CULP M. Software defect prediction using semi-supervised learning with dimension reduction[C].Ieee/acm International Conference on Automated Software Engineering. ACM, 2012:314-317.
[8] HERBOLD S. Training data selection for cross-project defect prediction[C].Proceedings of the 9th International Conference on Predictive Models in Software Engineering. 2013:1-10.
[9] HALL T,BEECHAM S,BOWES D,et al. A systematic literature review on fault prediction performance in software engineering[J].Software Engineering IEEE Transactions on,2012,38(6):1276-1304.endprint
