基于两层分类器的恶意网页快速检测系统研究
2017-09-08王正琦冯晓兵张驰
王正琦,冯晓兵,张驰
(1. 中国科学技术大学,安徽 合肥 230026;2. 中国科学院电磁空间信息重点实验室,安徽 合肥 230026)
基于两层分类器的恶意网页快速检测系统研究
王正琦1,2,冯晓兵1,2,张驰1,2
(1. 中国科学技术大学,安徽 合肥 230026;2. 中国科学院电磁空间信息重点实验室,安徽 合肥 230026)
针对当前传统静态恶意网页检测方案在面对海量的新增网页时面临的压力,引入了两段式的分析检测过程,并依次为每段检测提出相应的特征提取方案,通过层次化使用优化的朴素贝叶斯算法和支持向量机算法,设计并实现了一种兼顾效率和功能的恶意网页检测系统——TSMWD(two-step malicious Web page detection system)。第一层检测系统用于过滤大量的正常网页,其特点为效率高、速度快、更新迭代容易,真正率优先。第二层检测系统追求性能,对于检测的准确率要求较高,时间和资源的开销上适当放宽。实验结果表明,该架构能够在整体检测准确率基本不变的情况下,提高系统的检测速度,在时间一定的情况下,接纳更多的检测请求。
恶意网页检测;网络安全;机器学习;特征提取
1 引言
近年来,社会经济、科技、文化高速发展,互联网已逐步成为人们生活中不可或缺的重要一环。人们正逐渐从信息时代过渡到大数据时代。网络购物、在线付款、远程会议等各式的互联网应用层出不穷,随着互联网给人们的生活带来越来越多的便利,更多的人希望在网络中获取自己所需要的信息。因此,大量提供各式各样服务的网站与日俱增。中国互联网信息中心(CNNIC,China Internet Network Information Center)2016年发布的第37次《中国互联网络发展状况统计报告》[1]显示,自2014年以来,中国网站数量一直呈现明显的上升趋势。截至2016年6月,中国网站数量为4.54 M个,半年增长7.3%,如图1所示。
但是,互联网也是一把双刃剑。在方便人们生活、开拓人们视野的同时,许多不法分子也从中觅得了良机。他们或为了经济利益、或为了个人报复,借助互联网这个开放的公共平台在监管缺失的情况下进行大量的攻击行为。因此,互联网中充斥着各式各样的恶意网站、恶意软件、病毒木马等对用户个人隐私和财产安全造成巨大威胁的攻击形式,并且其传播速度和进化速度也变得越来越快,用户只要稍不留神,就会导致信息和财产的损失,并且受害的用户往往会成为攻击者的跳板,继续通过该受害用户攻击与之连接的其他用户。这种传播性极强的网络攻击行为的泛滥给当今的网络安全带来了巨大威胁,这种威胁不仅违背了网站运营商提供服务正当获利的初衷,更会使用户的操作系统程序遭到破坏,系统资源被非法控制,甚至敏感信息被盗取等,进而使用户对互联网产生一定的畏惧心理,严重影响了互联网的可信度,阻碍互联网的良性发展。
根据卡巴斯基安全实验室2016年发布的年度安全报告的统计数据[2],恶意网页出现在了87.36%的网络攻击中并且已经超越电脑病毒成为黑客们最常使用的获取非法收入的手段。除此以外,Google安全部门的研究表明[3],Google有大约1.3%的搜索结果是链接到挂马网页或钓鱼网页的。由此可见,恶意网页攻击已经超过传统的恶意攻击形式成为当前网络安全领域所面临的最大挑战,由于恶意网页一般通过脚本语言编写,具有形式灵活多变、传播速度快、影响范围广、隐蔽性高等特点,如何高效地检测出恶意网页已经成为当今网络安全领域一个亟待解决的研究课题。随着互联网的发展,每日新产生的网页数量也呈现爆炸式增长,海量的新网页不断涌入,为攻击者提供了极佳的隐蔽环境,由于受到资源和时间的限制,根据Sheng等[4]的研究,通过传统的检测方法,47%~83%的恶意网页需要12 h后才能被发现,而大约63%的钓鱼网站在出现2 h后就已经完成首次对用户的攻击行为。因此,面对每日大批涌现出的未知网页,为了更好地保障用户的上网安全,检测系统的准确率已经不再是瓶颈。如何在有限的时间内从海量的样本中筛选出新出现的恶意样本,成了恶意网页检测面临的最大挑战。
2 国内外研究现状
目前,国内外针对恶意网页的检测方法主要分为三大类:基于黑名单技术的识别方法、静态检测技术和动态检测技术。
2.1 基于黑名单技术的识别方法
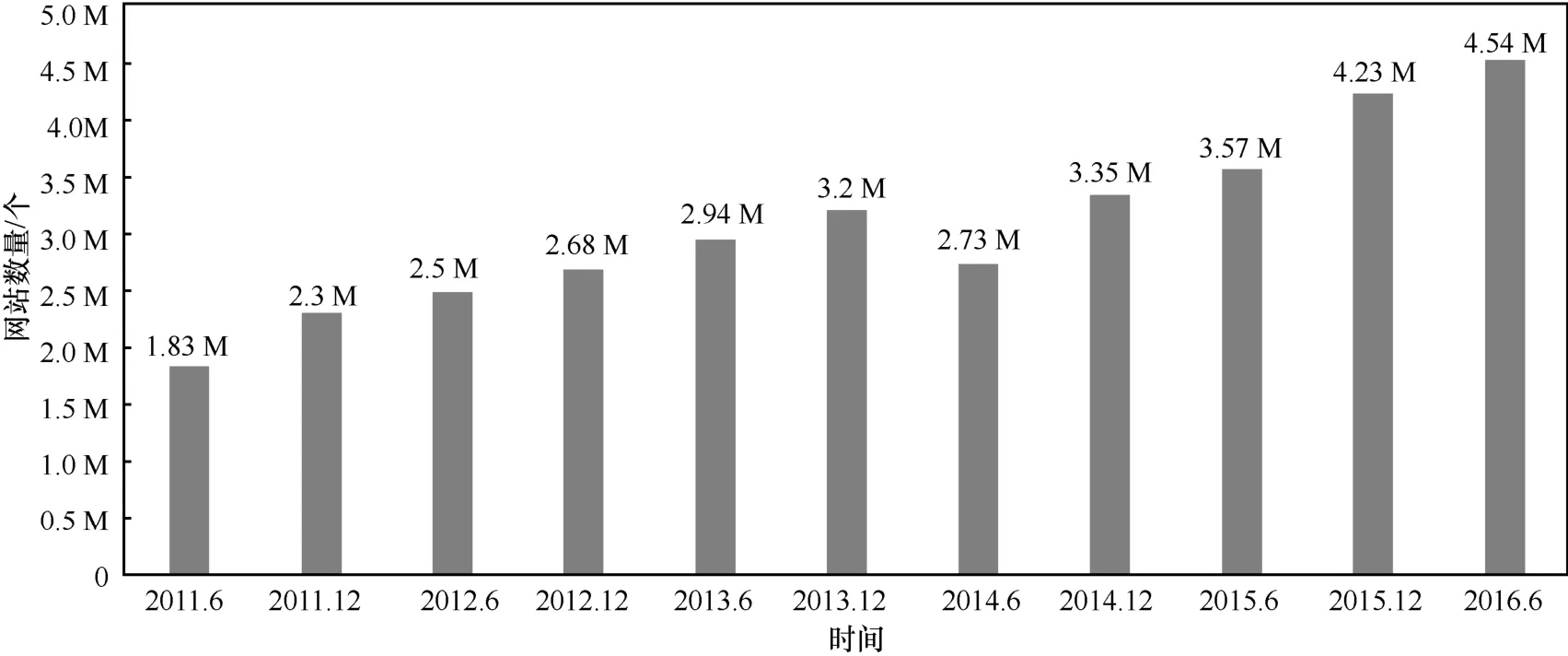
图1 中国网站数量
黑名单是一份基于恶意网页的URL、IP地址、域名信息或网页的关键词信息而生成的信息列表[5]。通过基于数据库查询的黑名单技术,人们可以准确地检测出之前已经被发现的恶意网页。每当访问一个网页时,首先在系统的数据库中查找该网页的对应信息,这样的查找仅针对网页的基本属性,而不会去解读网页本身的内容,因此只要将数据库中的内容进行遍历,一旦发现匹配成功即立刻提醒用户并进行拦截。该方案的优点十分明显,就是仅进行基础信息的匹配就可以得出结果,对于资源和时间的开销都非常小,很适用于一个成熟的恶意网页检测系统的前端,对于当前访问的网页先做一轮简单的筛选,假如该网页已经存在于黑名单中,则不必再进行后续的检测和分类。因其技术实现简单、使用方便,黑名单检测技术目前广泛应用于各类杀毒软件、安全系统解决方案中,如Google Safe Browsing[6]、 Malware Domain List[7]、PhishTank[8]等项目与系统。以Google Safe Browsing为例,它根据Google提供的搜索结果,不断更新其URL数据库,向用户提供服务,允许用户向其提供一个URL地址,以判断特定的URL是否在其所列举的黑名单上,如果存在,则向用户发出相应的警告。PhishTank向广大用户提供了一个可以自愿提交钓鱼网页的信息共享平台,任何用户可以向该平台提供恶意网页,经核实后收录到该开放平台的资源库中,人们可以根据该平台提供的列表过滤恶意网页,保障网络安全。
然而,黑名单检测技术有一个致命的缺陷,即该方法只能检测已经发现的恶意网页,对于刚刚新生成的恶意网页,由于还没有收录进相应列表,将不具备检测功能。Prakash等[9]针对该缺陷提出了一种名为PhishNet的改进方案,通过将已有的URL地址作为先验知识,对其进行分解和相似性匹配,来发现新的钓鱼网页,然而该扩展方案依然是建立在原有黑名单基础之上的扩展功能,对于某些钓鱼网页的衍生网页具有一定的检测功能,但对于新建立起的恶意网页来说,检测率仍然较低。同时黑名单检测技术由于时效性方面的缺陷,会导致大量用户在新生的恶意网页尚未被检测到之前已经受到相应的攻击。
2.2 静态检测技术
为了克服黑名单检测技术的不足,对于新出现的网页具备一定的检测能力,研究人员们在URL精确匹配的基础上,提出了基于网页内容、域名信息、URL地址等网页属性的相似性设计和启发式规则,对恶意网页进行识别和检测。静态检测技术实现的方案也有很多,可以采用基于模式匹配的方案[10]、基于启发式规则的识别方法[11]、基于机器学习的识别方法[12]等。它们的本质思路都是在获得该网页相关属性信息的基础上,不在仿真环境中实际运行该段代码,而是通过与以前样本的特征进行比较,通过不同的技术手段得出最终的结论。不同于黑名单检测技术,需要完成整个字段的精确匹配,静态检测技术不需要了解恶意网页的URL等详细信息,可以根据网页的属性依据现有的规则进行匹配,来识别出部分目前还未被列入黑名单的网页。因为其实现相对容易,代码执行效率较高,被广泛应用于一些主流的浏览器插件中。
著名网络检测系统Snort[13]运用的就是基于模式匹配的静态检测技术,它将已经检测到的恶意网页代码的某些片段或关键语句,通过某种数学手段生成唯一的特征标识码并存放在Snort特征库中,特征码通常具备一定的长度,来确保某个特征码专门用于标识某一类特定的恶意网页,同时也存有包含通配符的特征码,用来检测更多某种类型的变种恶意代码。特征码检测方案中包含完全匹配特征码检测和模糊匹配特征码检测,前者要求待测网页中存在和特征库中的恶意特征码完全相同的片段,后者则可以通过正则表达式等模糊匹配的方式来识别网页中特定格式的代码序列,为最终判决挖掘更多的有效信息。这类方案的缺点同样在于特征库的更新具有时效性,且随着特征库的内容越来越多,模糊匹配的要求越来越高,检测所需要的资源开销也在不断增加。
基于启发式规则的静态检测技术在很多浏览器插件中应用十分广泛。该类检测方法往往建立在对于恶意网页的某些统计特征(如关键词出现的频率、特殊符号所占的比例等)是唯一的假设基础上的。Lin等[14]在他们的实验中展示了这一过程,他们将大量的恶意网页样本划分为多个不同的类别,每一个类别中包括一个种类的恶意网页代码及其变形。接着对于每一个类别的恶意样本,提取其共性的特点,为之创建模板,每一个类别都对应有一个或多个不同的模板。当待测网页进入系统后,则根据其页面信息计算与各个模板之间的距离,当与某个模板的距离小于相应的阈值时,则可以认为该待测网页与该类模板相匹配,属于该类的恶意样本。Zhang等[15]提出了一套基于IE浏览器的工具插件Cantina,通过对网页搜索的返回结果和网页中敏感关键词出现的词频等其他统计信息进行分析,建立启发式规则库对网页进行检测。启发式规则的静态检测技术的缺陷在于,面对每日大量新出现的待测样本,简单的特征分布统计和启发式规则已经无法满足需求,主要体现在以下2个方面:首先误检率增高,因为启发式规则的局限性和模糊匹配技术的使用,存在很多正常样本由于某些代码片段匹配某些模板,从而被误判为恶意样本;其次该方案的规则更新较难,规则的提取依赖于大量的专业知识和人工总结,因此规则更新的成本较高。
基于模式匹配和启发式规则检测的局限性,研究人员进一步提出了更加系统的基于机器学习的分类方法。作为静态检测技术的一个分支,其检测的准确性虽不能与动态检测技术同日而语,但是通过对分类器算法的改进和特征提取的优化,基于机器学习检测方案的检测率相较于其他静态检测技术已经有了很大的提高,且由于网页检测的数据量十分庞大,对检测效率要求较高,也十分符合机器学习分类算法的使用场景,可以对分类器进行不断的优化与迭代,使其检测效果越来越好。Hou等[16]基于已有的恶意样本建立起一套特征提取方案,并将未知网页样本映射到已有类别中,如图2所示。
基于机器学习的恶意网页检测流程主要包括以下2个步骤。
1) 训练:通过训练样本训练出一个分类模型。每个训练样本都有一个分类的标签,即该样本是正常的还是恶意的。通过取足够数量的分类样本利用有监督学习算法,生成可以用来分类的数学模型。
2) 预测:根据待测样本所提取出的特征分布信息,经过训练好的分类器算法进行分类,判定出样本的所属类别。
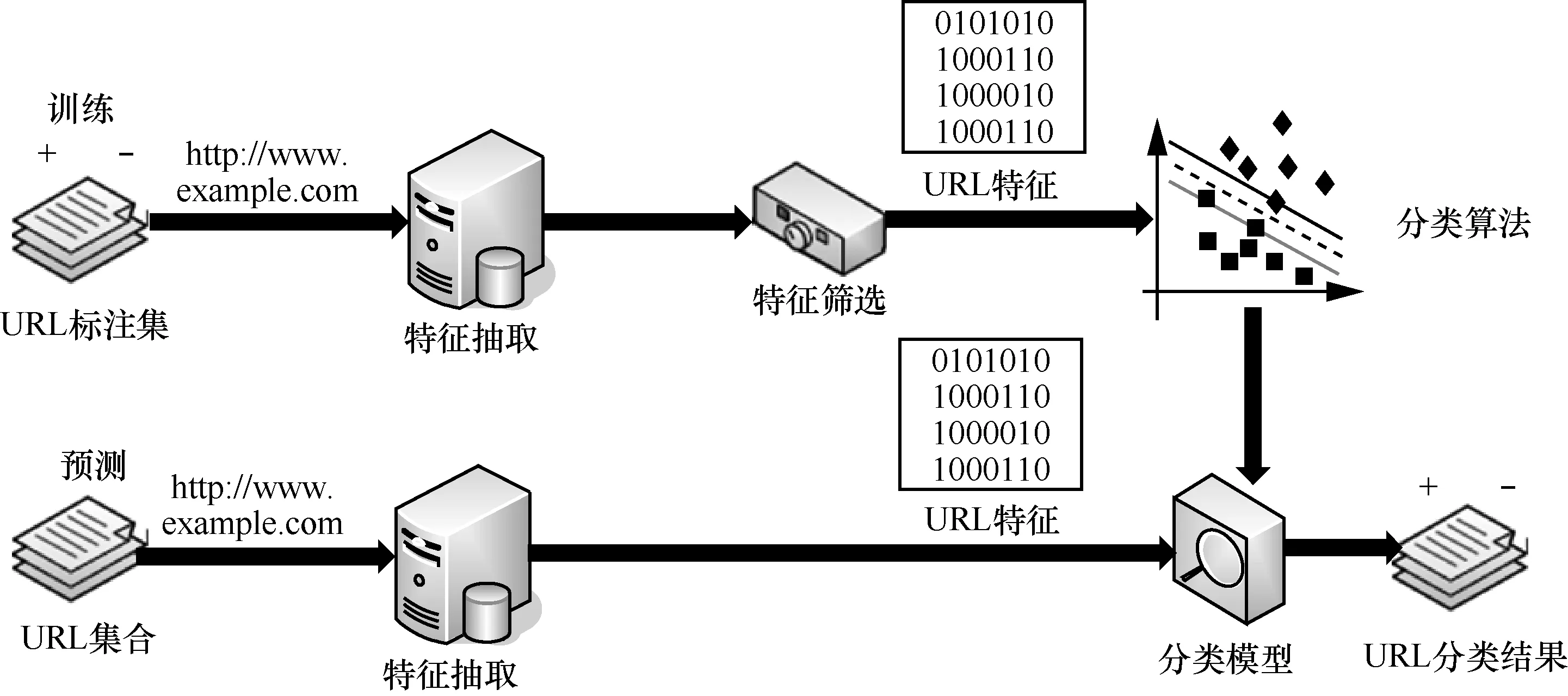
图2 基于机器学习的恶意网页检测流程
Justin等[17]提出了一套分类特征基于URL和主机(host)信息的轻量级分类器,并讨论了不同机器学习算法在此场景下的表现差异。Yoo等[18]提出了基于误用判决模块和异常判决模块的恶意网页检测系统,其中包含2个基于监督与半监督机器学习算法的不同类别的分类器,与传统机器学习算法相比,该方案在正常样本的误检率略微升高的情况下,显著提升了恶意样本的检测率,但是检测所消耗的系统资源也有所上升,对于使用条件的要求更为苛刻。Canali等[19]提出了一个基于URL地址的过滤器,补充在传统的恶意网页检测系统之前,用以提升检测速度,使现有系统更加适用于大数据量的场景。但由于该过滤器仅基于URL信息进行过滤,导致在检测速率提高的情况下检测效率有明显下降。目前基于机器学习的检测方法所面临的问题主要有两大类:首先是特征的优化和更新问题,因为分类算法的效率很大程度上取决于特征提取的代表性,且特征提取方案具有一定的时效性,当某一批特征的检测效率过高后,会导致新一批的恶意网页进行针对性的防范,因此特征的更新与升级是面临的困难之一;第二,随着互联网的发展,恶意网页的种类越来越多,每天所要检测的未知样本数量也逐渐增多,每个样本的特征分析时间越来越长,因此检测系统的工作负荷也越来越高,如何能够降低特征提取的复杂度,减少每个样本的检测时间也是亟待解决的问题。
2.3 动态检测技术
不同于上述的静态检测技术,动态检测技术主要是通过将捕捉到的HTML或JavaScript源码在虚拟环境中运行,将虚拟机用作诱饵,对待检测网页进行访问,并在访问的过程中实时检测该网页的动态行为(如超链接到其他网页、远程下载并执行可执行文件、创建注册表等),以此来判断待测网页是否属于恶意网页。该方案的优势在于对未知网页样本,不仅通过其显示出的文本特征进行分类,而是将其放入虚拟环境中直接运行,并且诱导其在虚拟机中脱去外壳,表现出其真实目的,因此检测的准确率极高。目前最具有代表性的动态检测方案是蜜罐检测技术[20],该方案由Holz和Koetter在蜜罐项目中提出,用于给未知样本提供运行环境,并在蜜罐中实时检测其每一步行为。传统的蜜罐技术有低交互式服务器蜜罐和高交互式服务器蜜网[21],它们实际上是将故意暴露出系统漏洞的服务器,用作诱饵以吸引攻击者对其进行攻击并分析攻击者的每一步行为。动态检测技术在恶意网页检测领域的应用保证了对可疑样本判决的准确性,但是动态检测技术的弊病也是显而易见的,无论是虚拟机脱壳引擎技术还是蜜罐检测技术,检测过程中的系统资源消耗和时间消耗都是十分巨大的,对于大样本集的使用场景,该方案的可行性较差。此外,对于具有长期潜伏特性的恶意样本,由于在虚拟机中并没有完成脱壳,其真实意图隐藏得很好,检测效果也会受到影响。
2.4 恶意网页检测评价指标
对于恶意网页检测系统的综合评价指标,主要分为两类,功能指标和性能指标。其中,功能指标主要用于对检测系统的分类效果进行评价;而性能指标主要用于对检测系统的分类效率进行评价。
恶意网页的分类问题,是一个二值分类问题,即检测系统要将未知样本分为正常样本和恶意样本两大类,因此,要使用二值分类的评价指标对系统的分类效果进行评价,对于恶意样本的判决能力和正常样本的判决能力要分别独立进行评定。系统的目的是为了挑选出存在于大量正常样本中的恶意样本,因此将恶意网页样本作为正样本,正常网页样本作为负样本,检测系统分类结果的示意如图3所示。检测系统的功能指标主要分为以下五大类。
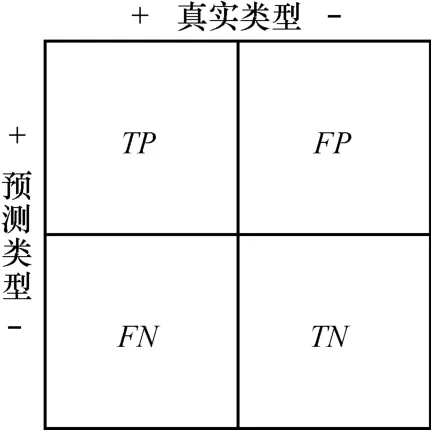
图3 分类器功能指标示意
假设共有检测样本数量为M,则M=TP+FP+ FN+TN,其中每一项的含义如下。
TP(true positive): 被判决为正的正样本的数量。
FP(false positive): 被判决为正的负样本的数量。
TN(true negative): 被判决为负的负样本的数量。
FN(false negative): 被判决为负的正样本的数量。
根据这样的样本分类方式,有如下几个评价指标,来全面衡量恶意网页检测系统的功能。
准确率(ACC, accuracy rate):指分类正确的样本个数(包含分类正确的正样本和分类正确的负样本)占总样本个数的比重。主要用于衡量检测系统总体的准确程度。其中,T表示所有正样本的个数,F表示所有负样本的个数。
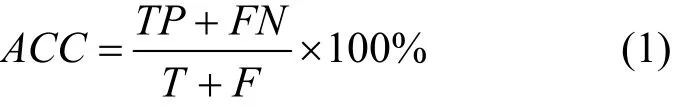
真正率(TPR, true positive rate):指分类正确的正样本占正样本总数的比重。主要用于衡量系统对恶意样本的检测能力。
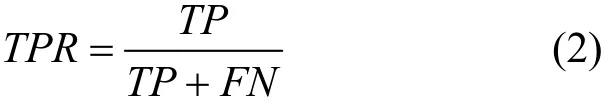
假正率(FPR, false positive rate):指被误判为正样本的负样本占负样本总数的比重。主要用于衡量检测系统对于正常样本的误判水平。
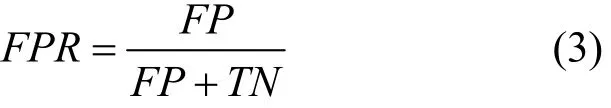
精确率(P, precision):指被正确分类的正样本占所有被分类为正样本的样本总数的比重。主要用于衡量检测系统对于恶意样本的查准率。
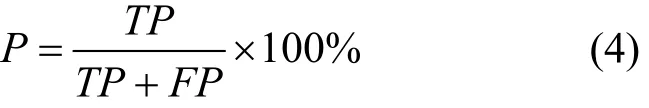
召回率(R, recall):含义同TPR,主要与精确率进行对比,衡量系统对于恶意样本的检测能力。
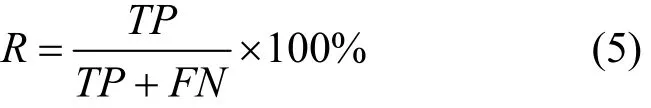
对于检测系统的性能指标,主要包括处理一个网页所需要消耗的时间、单位时间内所能处理的网页个数等。
3 TSMWD系统的设计与实现
3.1 TSMWD总体框架
如图4所示,基于机器学习的恶意网页检测系统(TSMWD)包含4个模块:数据采集模块、特征提取模块、数据处理模块和分类判决模块。数据采集模块主要用于训练样本和待测样本的获取,其正样本和负样本由于数量上的差异,获取方式有所不同。特征提取模块用于对输入的训练或待测网页内容进行解析,该模块主要由2个子模块构成,分别对应于2个不同的特征提取策略,即服务于TSMWD-I性能优先的特征提取方案和服务于TSMWD-II功性优先的特征提取方案。数据处理模块的主要功能是将特征提取模块中提取出的样本特征进行归一化、格式化等一系列处理,在分类器的训练阶段,该模块还负责将样本与其所属类别的标签进行一一对应,将提取出的特征和属于该样本的类别标签以分类器需要的数据结构和数据格式进行输入。最后是分类判决模块,在经过训练集中不同类别的样本训练后,根据待测样本的特征分布,给出最终的分类判决结果。在TSMWD中,分类判决模块主要由2个部分组成,第一部分为用于对大量未知样本进行初步筛选的TSMWD-I,该分类器模块的主要特点是对于恶意样本十分敏感,恶意样本的检出率很高,因此对该模块分类为正常的样本可以直接作为最终结果而无需进行后续的任何操作。高TPR的同时也意味着对正常样本有较高的误判率,即FPR也较高,因此对于TSMWD-I分类为恶意的样本,本系统暂作为未知样本进行考虑,转交TSMWD-II检测模块进行最终判决。因此根据不同的使用环境和检测需求,选择不同的分类算法以及各种分类算法的参数优化是这个模块的重点。本节围绕每个模块的方案设计与实现方法进行详细讨论。
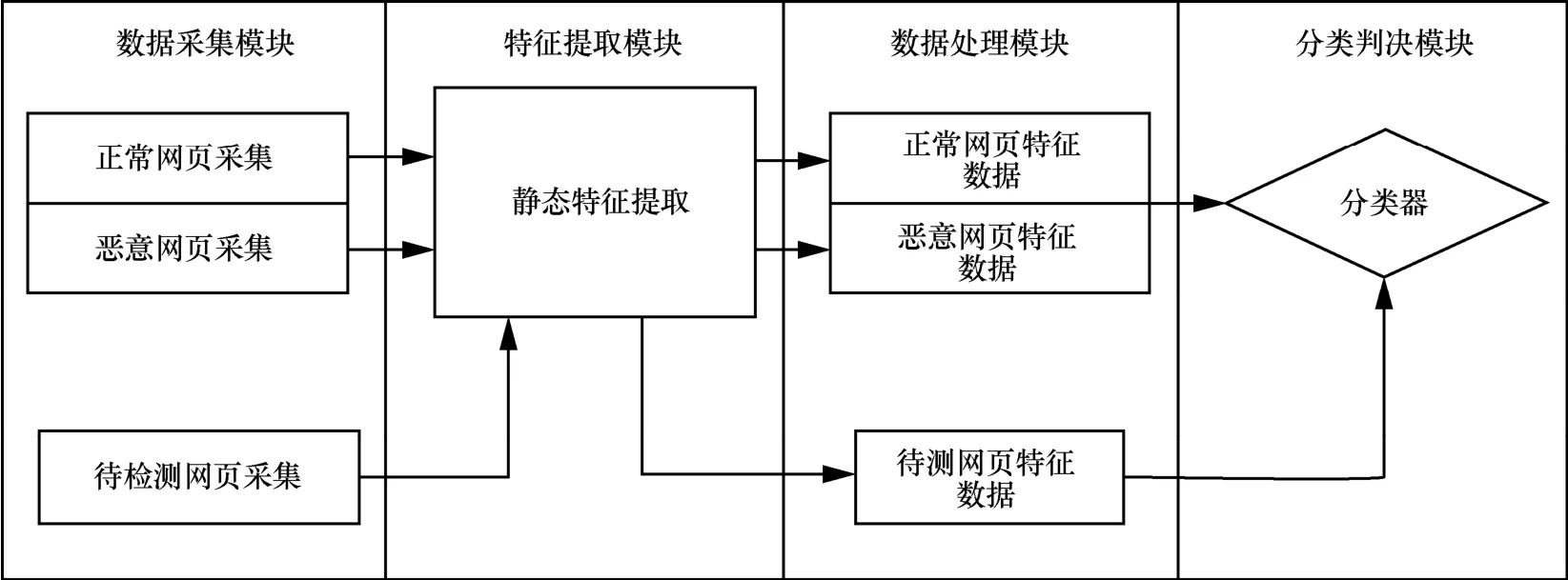
图4 TSMWD框架
TSMWD系统的工作流程如图5所示,首先,需要对大量的待测样本由TSMWD-I的特征提取方案进行特征提取,经过数据处理模块的归一化、格式化处理后,由分类器TSMWD-I进行分类判决。若判决结果为负,即该样本为正常样本,则检测全过程结束,该结果就是这个待测样本的最终判决结果。若判决结果为正,即该样本为未知样本,则需要对当前的这个样本进行相对耗时的二次检测,需要再次通过TSMWD-II的特征提取方案进行特征提取,该部分的特征除了包含有TSMWD-I的相关特征外,对于混淆、正则、敏感词出现频率等提取相对复杂和耗时的特征有了进一步补充。经过数据处理模块的归一化、格式化处理后,由分类器TSMWD-II给出最终的判决结果。
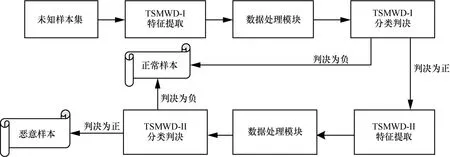
图5 TSMWD工作流程
TSMWD的整个工作流程大致包含2次侧重点不同的检测。其中,TSMWD-I的特征提取和分类判决更加注重效率,追求速度;而TSMWD-II则追求精确率和召回率。对于每日新增的待测样本来说,由于正常样本的占比远高于恶意样本,因此大多数的待测样本都将会在TSMWD-I进行判决后就完成了整个检测过程,只有少量表现出了相关恶意样本特征的待测样本,需要进行后续的第二模块的检测。因为TSMWD-I的检测速率较高,能够有效过滤大多数的正常样本,因此系统总体的检测时间会明显缩减。在这样的系统架构下,为了保证检测系统的功能指标不受影响,必须最大限度地减少TSMWD-I造成的误判,由于TSMWD-I中判定为正的样本还会继续进行检测,所以负样本的误检率(FPR)(即将正常样本判定为未知样本比率)并不会最终影响整个系统的功能指标。但是对于正样本的误检率(FNR)(即将恶意样本判定为正常样本的比率),会导致待测样本在未经过TSMWD-II分类判决的情况下直接得出错误的判决结果,从而影响整个检测系统的准确率。为此,对TSMWD-I的分类算法进行了相应的校正,使其在整体最优边界的基础上向负样本一侧偏移,则其TPR和FPR会同时增高,FNR降低,对整个系统检测率的影响达到最低。有关分类器算法的优化和参数调整,本节给出更加全面的阐述。
3.2 TSMWD特征提取方案
基于静态方法的特征匹配检测中必不可少的环节之一就是要能够观察并总结出恶意网页所具有的特征,所以,通过分析从Metasploit[22]中提取出来的不同类别的恶意样本,从多个角度和方面总结归纳恶意网页所具有的特征。在设计的特征提取方案中,有些特征属于强特征,即在正常样本和恶意样本中出现的频率有较大差距。有些特征属于弱特征,即在正常样本和恶意样本中都有出现的可能,但是基于某些统计规律,在正常样本和恶意样本中出现的频率分布有一定的区别,这样的特征也可以作为最终判决的一个参考因素。例如,对于注释的使用,正常网页中也会使用大量注释,但注释出现的位置一般存在于脚本代码开始之前或结束之后,极少出现交替穿插于脚本代码之间的情况;因此对于类似注释这样的弱特征,经过一定的修饰之后,也能够对于系统的最终分类判决产生一定的正向影响。对于不同特征权重的平衡,将通过大量样本的训练由分类器完成。由于恶意脚本的表现形式灵活多变,普通的精确字符串匹配算法无法涵盖所有形式的恶意脚本,在大量待测样本环境中的匹配效率也不高,所以利用基于有限状态机的正则表达式对恶意代码特征进行匹配就成为特征片段抓取的有效方法。根据系统设计的总体布局可知,网页源码的内容及其整体的结构布局是对一个网页进行评判的重要因素。因为本文采用静态代码检测的方式对未知网页的属性进行判断,因此在上文分析了多种不同的EK攻击方式后,需要在了解其攻击原理的基础上,提炼其源码的表面特征,这些特征大致需要具有以下特点。
1) 特征之间要尽可能相互独立,将彼此间的相互作用降低到最小。
2) 特征的选取要基于正则、字符串匹配、关键字查找等相对速度较快的查询操作,而不应该涉及页面脚本代码运行后的行为数据。
3) 特征选取的覆盖面要尽可能广泛。对大量的恶意代码研究发现,恶意的代码片段不仅会出现在JavaScript的脚本中,即便是解释性的HTML或相对小众的VBScript中也有可能出现。
4) 特征的选取要尽量具有代表性。因为提取出的恶意网页特征,最终会用于训练分类器,所以每一个设计出的特征,都需要在恶意样本中出现的频率和在正常样本中出现的频率有一定的区别,否则如果正常样本中的出现频次和恶意样本中相近,则认为该特征的设计有一定缺陷,对于分类器的训练并不能起到正向的帮助,并且是大量误判产生的源头,要尽可能将特征在设计时就做好区分度的调研,并且对容易造成误判的敏感特征做进一步的优化和修饰。
同时,由于静态恶意代码检测的最大优点在于系统运行的速度优于动态检测,所以,在设计特征提取方案时,要考虑性能的最优化。特征提取模块的总体框架如图6所示,TSMWD系统特征提取主要分为三大块,分别是HTML模块、JavaScript模块和VBScript模块,其中JavaScript脚本中嵌入的恶意代码片段最为频繁,因此设计时对应的特征数量也最多。为避免网页的多次读取、相应关键数据可以先保存在内存中,以供不同的特征和方法进行调用。最后将所有待测网页的特征写入相应文件中,供后续模块进行分析处理。
3.3 TSMWD-I分类算法优化
TSMWD的整个工作流程大致包含2次侧重点不同的检测,其中TSMWD-I的特征提取和分类判决更加注重检测效率,追求速度,对于每日新增的待测样本来说,由于正常样本的占比远高于恶意样本,因此大多数的待测样本都会在TSMWD-I进行判决后就完成整个检测过程,只有少量表现出相关恶意样本特征的待测样本需要进行后续的第二模块的检测。因为TSMWD-I的检测速率较高、能够有效过滤大多数的正常样本,因此系统总体的检测时间会明显缩减。在这样的系统架构下,为了保证检测系统的功能指标不受影响,必须最大限度地减少TSMWD-I造成的误判,由于TSMWD-I中判定为正的样本还会继续进行检测,所以负样本的误检率(即将正常样本判定为未知样本比率)并不会最终影响整个系统的功能指标。但是对于正样本的误检率(即将恶意样本判定为正常样本的比率),会导致待测样本在未经过TSMWD-II分类判决的情况下直接得出错误的判决结果,从而影响整个检测系统的准确率。
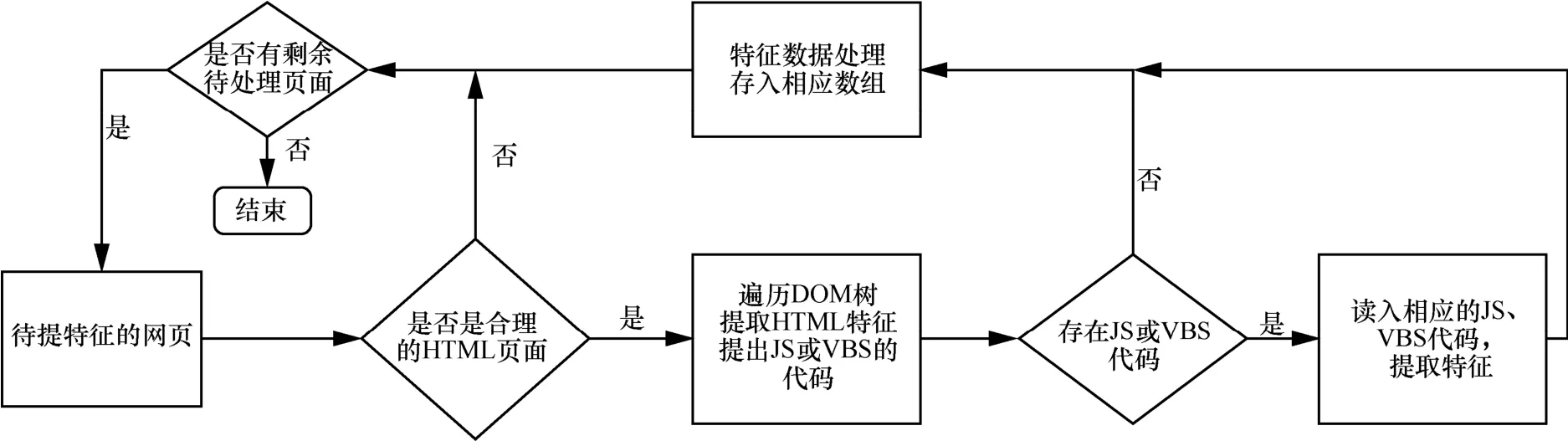
图6 特征提取模块的总体框架
因此,对于该模块的分类,需要选择在数据量较大的情况下运算量相对较小、速率相对较快的算法,且要具备相应的矫正因子。在该使用场景下,需要牺牲FPR,优先保证TPR,因为对于“疑似”的恶意样本,尽管TSMWD-I分类器的结论更加倾向于该样本属于正常网页,但从整个系统准确率的角度出发,不能接受在第一层判决模块将恶意样本误判为正常样本。反之,将正常样本误判为恶意样本时,由于还要经过第二层检测系统得出最终结论,所以这样的情况只会造成运算效率上的一点影响,是在可接受的范围内的。因此,对于这样的“疑似”恶意样本,更加希望TSMWD-I能够给出未知的判决结果,这就需要将原算法给出的最优分隔线向正常样本一侧偏移。在这样的情况下,恶意样本的检出率会得到提高,与此同时,被误判为恶意样本的正常样本数量也会随之上升。
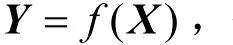
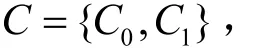
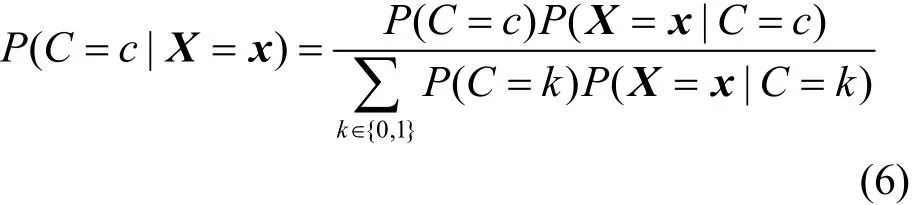
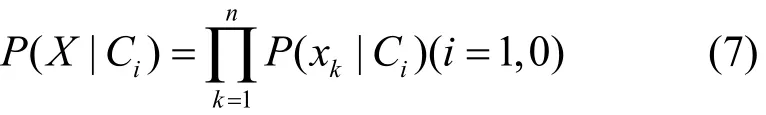
将式(6)代入式(7)中可以得到拥有特征向量X的未知样本d属于类别c的概率转化为
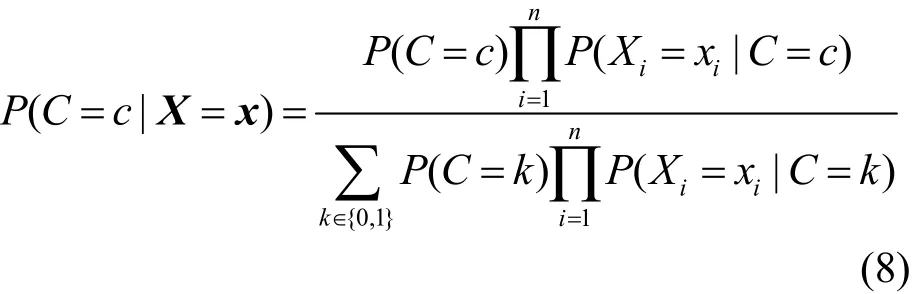
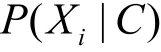
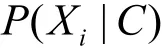
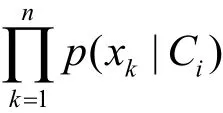
根据以上的训练和预测方案,能够构建一个基于最优分界线的朴素贝叶斯算法分类器。如图7所示,在简化的二维空间中,数目相对较少的深色点为恶意样本,数目相对较多的浅色点为正常样本。当采用标准的朴素贝叶斯分类算法时,完全根据概率的大小来选择所属的类别,则图7中的黑色分隔线一定会出现在正常样本和恶意样本的交汇处。这会使整个系统的准确率相对较高,除了个别不符合特征分布规律的噪声样本外,主要的误判都集中在分隔线两侧,即当属于2个类别的概率比较接近时,容易造成分类的错误。在这种情况下,既有可能将正常样本误判为恶意样本,也有可能将恶意样本误判为正常样本。
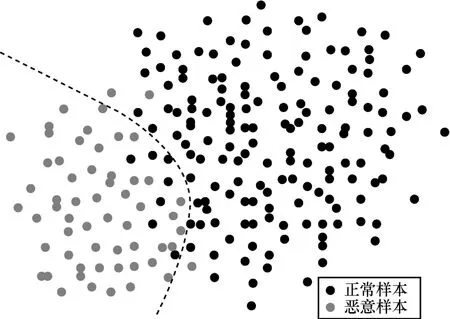
图7 最优分隔线模型
根据本节开头的描述可以知道,TSMWD-I除了追求检测效率以外,不能接受其将恶意样本误判为正常样本。反之,将正常样本误判为恶意样本时,由于还要经过第二层检测系统得出最终结论,所以这样的情况是在可接受范围内的。因此对于这样的“疑似”恶意样本,更加希望TSMWD-I能够给出未知的判决结果,这就需要将原算法给出的最优分隔线向正常样本一侧偏移。在这样的情况下,恶意样本的检出率会得到提高,与此同时,被误判为恶意样本的正常样本数量也会随之上升,但从整个TSMWD系统的角度来说,其检测准确率不会受到影响。因此需要对上述的朴素贝叶斯算法进行一些修正,使之能够满足人们的使用需求。在式(9)中引入一个矫正参数λ,在假设C0代表恶意样本类别、C1代表正常样本类别的情况下,将最终的预测模型转变为
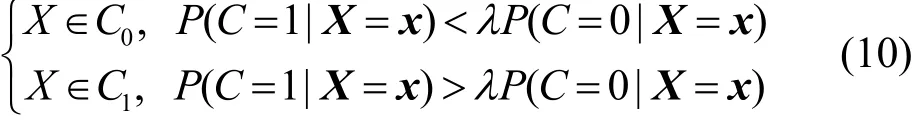
当λ>1时,会导致待测样本被判别为恶意样本的概率增加,图7中的分隔线向正常样本一侧偏移,如图8所示。在这样的情况下,TSMWD-I的恶意样本检出率升高,与此同时,伴随着一批正常样本被判定为恶意样本,正常样本的误检率也随之升高,符合在该场景上的分类需要。因此需要结合第二部分检测模块,通过对不同大小λ的尝试,在检出率和误检率间进行权衡,以找到能够最大程度地提高系统检测性能,同时又不影响系统检测准确率的λ。

图8 矫正分隔线模型
3.4 TSMWD-II 分类算法选择
在TSMWD-I对海量待测样本进行分类的基础上,对于那些直接被分类为正常的待测样本,不需要再经过该模块的判决。对于TSMWD-I检测模块分类结果为恶意的待测样本,本系统继续视为未知样本作为TSMWD-II的输入,在TSMWD-I中提取的相关特征,已经保存在相应的中间文件中,所以可以直接通过读取与之对应的特征信息获取第一模块中既有的特征数据,该待测样本再经过TSMWD-II的特征提取模块获取一系列相对耗时的基于混淆加密、正则表达式匹配、比例计算等行为的高级特征,生成更为全面的特征文件,由TSMWD-II的分类判决模块对该待测样本给出最终的判决结果。与TSMWD-I模块相比,TSMWD-II的分类算法主要有以下两点不同。
1)由于TSMWD-I检测模块对海量正常样本的过滤,TSMWD-II检测模块需要分类的待测样本的数量是有限的,待测样本相对较少,所以对于检测率的敏感度没有那么高,因此在TSMWD-II检测模块中可以不必过多地考虑算法优化对系统性能的影响,只需要关注如何提升该模块的功能指标。
2) 在TSMWD-I中,需要保证恶意样本的检出率TPR足够高,这样才能将该模块对系统总体性能的影响降到最低。因此,选择了修正的朴素贝叶斯算法,在牺牲FPR的情况下提高了TPR,对于TSMWD-I的整体准确率会造成影响;而在TSMWD-II中,由于该模块给出的判决结果已经是系统的最终分类结果,因此分隔线需要选取在最优位置,保证系统总体的准确率达到最高,而不再单一地关注恶意样本的检出率,忽略正常样本的误判率。
在上述2个原则的基础上,本文调研了目前主流的机器学习分类算法,对不同类型的算法都进行了尝试,从准确率、真正率、假正率这3个方面综合比较了各分类算法的优势和缺点,从而选择出最适合该应用场景和特征提取方案的分类算法及参数模型。
在系统训练和测试的整个流程中,由于恶意样本数据集中的样本个数相对较少,没有足够多恶意的样本在保证训练分类器迭代完成后,还能提供一套完整的恶意样本测试集。为了消除噪声及数据集划分不具代表性对检测系统测试结果的影响,采用交叉验证(cross-validation)[24]的方式对检测系统进行训练与测试,其主要思想是将数据集随机分成k个同样大小的子集,依次选取其中的一个子集作为测试集,其余k−1个集合作为训练集,经过k次训练和测试后,将k次结果的平均值作为检测系统最终的实验数据。依次对KNN算法、决策树算法(C4.5)、分类回归树(CART, classification and regression tree)算法和支持向量机(SVM, support vector machine)算法进行了十字交叉验证,其中线性核函数的SVM算法表现最好,将其用于TSMWD-II检测模块的分类算法。对于该模块不同分类算法实验结果的对比和整个TSMWD系统的相关性能指标和功能指标与已有系统的对比及其应用场景,将在第4节系统实验评测中进行详细分析。
4 系统实验测评
4.1 实验环境
1) 硬件环境
CPU:Intel(R) Core i3-4130;
内存:DDR3 12 G;
硬盘:1 T,7 200转/秒。
2) 开发环境
开发操作系统:Windows 7 旗舰版(64 bit);
机器学习开源框架:Scikit-learn、LibSvm;
开发语言及工具:C/C++、Python2.7.14、STL标准模板库、boost C++库、Visual Stidio2013、Pycharm、VMware、QT Creator 5.5。
4.2 TSMWD-I实验结果
3.3 节提出了加入矫正因子λ的朴素贝叶斯分类算法,在λ>1的情况下,对于λ取不同的值,分隔线偏向正常样本一侧的程度不同,可以根据TPR与FPR的权衡选择最适合当前需求的参数值。对已经采集到的1 428个恶意样本与30 000个正常样本,采用10次交叉验证的方法,对于每个设定的λ进行10次实验,将142个恶意样本和3 000个正常样本作为测试集,1 286个恶意样本和18 000个正常样本作为训练集,经过10次实验后,将实验结果进行平均。如2.4节中的描述,从系统检测的准确率、真正率、假正率3个方面对系统的整体检测能力进行评估。实验对比了不同λ取值下,TSMD-I的检测能力,结果如表1所示。
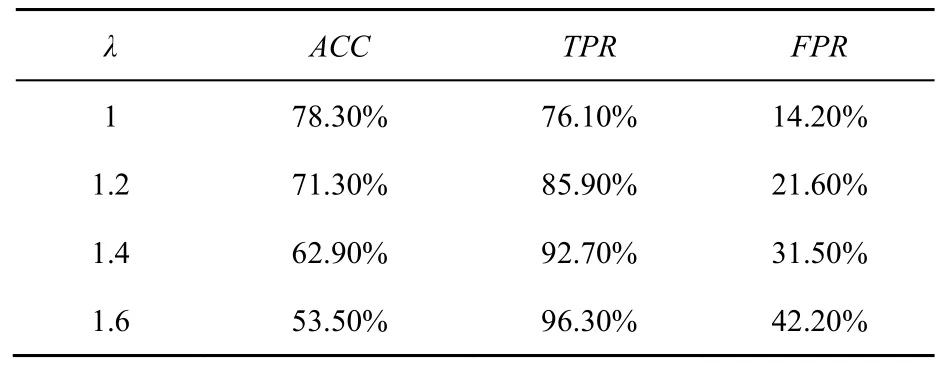
表1 不同λ取值下TSMWD-I检测能力对比
通过表1可以看到,当λ=1时,此时的TSMWD-I的分类算法就是传统的未经修正的朴素贝叶斯算法,其准确率为78.30%,但是对于恶意样本的检出率只有76.10%,这意味着如果直接使用未经修正的朴素贝叶斯算法作为第一层检测系统的分类算法,将会有23.90%的恶意样本在TSMWD-I对正常样本进行过滤时就已经被误判,即便TSMWD-II的检测性能再强大,也无法改变整个系统检测性能不佳的事实。随着矫正因子λ的增加,分隔曲线向正常样本一侧偏移,对于恶意样本的检测成功率也越来越高,即TPR不断上升,但同时也有更多的正常样本被误判为恶意样本,即FPR也随之上升;由于正常样本的数目相对庞大,所以模块整体的准确率逐渐下降。但正如3.3节中描述的那样,整体的准确率并不是该模块追求的目标,TSMWD-I最重要的职责是为后续检测系统过滤掉大部分的正常样本,同时避免对恶意样本的误判。因此注意到,当λ=1.6时,恶意样本的真正率已经高达96.30%,这意味着只有3.7%的恶意样本会因为第一层检测系统而被误判。同时,假正率也已经高达42.20%,这意味着仅有57.80%的正常样本会被第一模块快速过滤,有42.20%的正常样本依旧会被当作未知样本交由后续检测系统进行判决,在这样的情况下,对于整个系统而言,速度的提升幅度受到了限制,因为有近一半的待测样本最终还是需要被检测相对耗时的第二模块处理。本文对更多的λ取值进行了实验,并根据实验结果做出了在不同λ取值下,TPR和FPR之间相互权衡的经验曲线,如图9所示。随着TPR的升高,恶意样本的漏判率会降低,系统整体的检测性能会变好;但与此同时,FPR会随之升高,意味着有更多的正常样本不能被过滤,需要由第二模块给出最终判决结果,系统整体的检测时间会变长。
因此,选择合适的λ取值,也是系统整体对检测效率和检测速度之间的平衡,是功能指标与性能指标之间的平衡。4.3节将重点介绍TSMWD-II的分类器算法的选择,然后将2个模块相结合,对于TSMWD检测系统整体的检测速度和检测性能在不同的λ取值下给出更为全面的评估和测试。
4.3 TSMWD-II实验结果
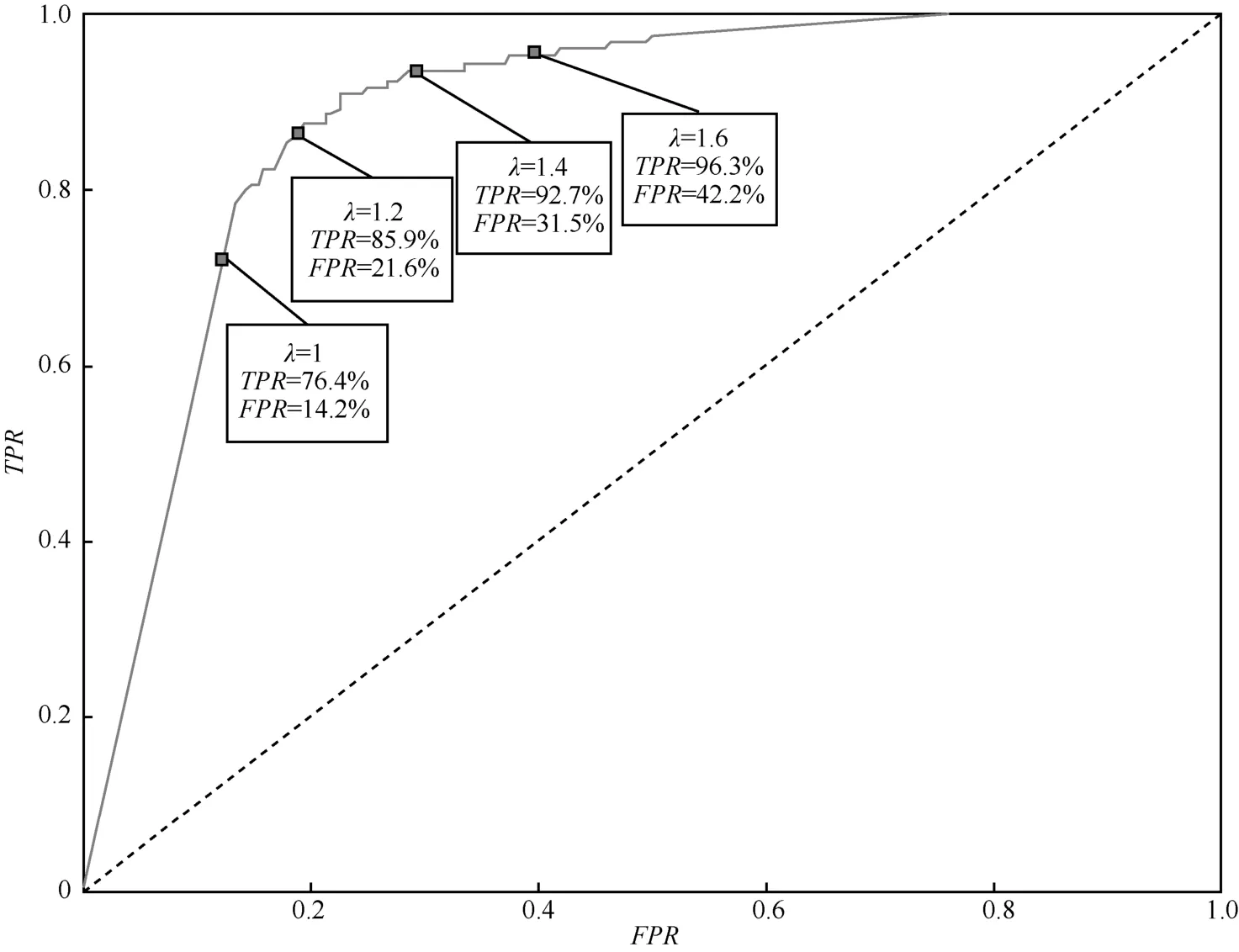
图9 不同λ取值下TPR与FPR的平衡曲线
在TSMWD的第二层检测模块中,分别对KNN算法(k=3、5、7取最优)、决策树算法C4.5、分类回归树算法CART、和线性核函数的支持向量机SVM算法对TSMWD-II的特征提取方案所提取出的更为详尽的特征向量进行最终的分类判决,其中训练集和测试集的选取继续选用与TSMWD-I相同的十字交叉验证的方法,此处不再详述。将分别从检测的准确率、精准率(precision)和召回率(recall)这3个维度对不同分类算法的分类性能进行衡量,其中检测的准确率用于衡量该模块做出的判决中总体的正确率情况,精准率主要用于衡量该模块对检出的恶意样本的查准率,召回率等同于真正率,用于衡量模块对于恶意样本的检测能力。其实验结果如表2所示,分类结果比较直方图如图10所示。
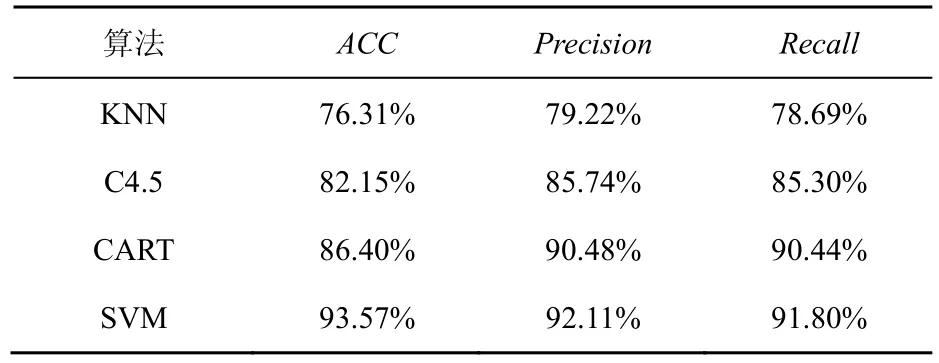
表2 TSMWD-II不同分类算法分类结果均值比较
根据该实验结果发现,基于线性核函数的支持向量机分类算法在该模块中对恶意样本的检出率、恶意样本的查准率、整体判决结果的正确率都要优于其他3种分类算法,因此可以得出结论,TSMWD系统所使用的基于五大类的恶意网页内容特征提取方案更加适用于SVM算法的分类器,且90%以上的准确率基本已经达到目前静态恶意网页代码检测前沿水平,因此选择SVM算法作为TSMWD-II模块的分类算法。
4.4 TSMWD系统整体性能评测
在评测整个TSMWD系统时,从系统判决的准确率、恶意样本检出率、正常样本的误判率这3个维度对系统的检测能力进行评价。同时对于系统的检测效率,通过对测试集中的样本(恶意样本142个,正常样本3 000个)进行判决的时间进行测量,时间越短,则检测效率越高。随着TSMWD-I中λ参数的不同,整个系统的检测效率也会发生变化,同4.2节一样,对不同取值的λ进行多次测量后,给出其变化曲线。
在两层检测系统同时使用开始前,首先让TSMWD-I和TSMWD-II对训练集中的3 142个样本进行独立检测,了解每个模块独立的检测效率。通过10次实验求平均后发现,TSMWD-I对该测试集完成分类所需要的时间为0.91 s,而TSMWD-II对该测试集完成分类所需要的时间为3.47 s,在完全各自独立运行的情况下,TSMWD-I的检测效率比TSMWD-II快了近3.5倍,这主要是源于前者简易的特征提取方案,同时易于实现的朴素贝叶斯算法也为分类判决节省了大量时间。然后对整个系统进行了检测能力和检测效率的测试,其测试结果如表3所示,比较直方图如图11和图12所示。
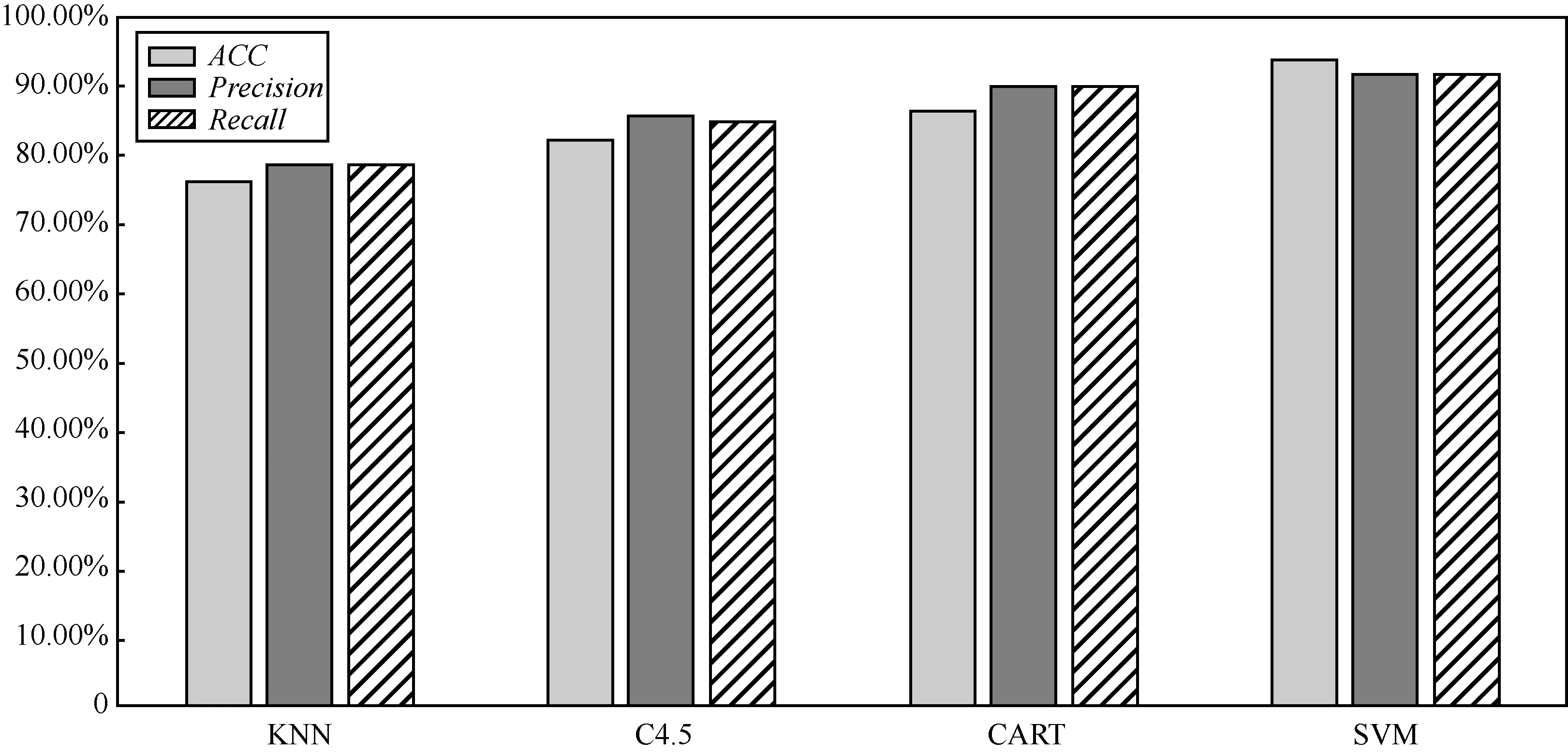
图10 TSMWD-II不同分类算法分类结果均值比较
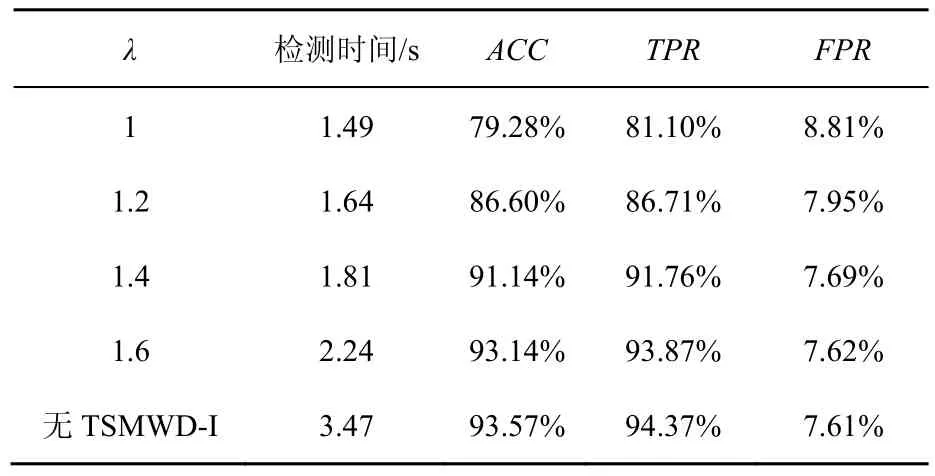
表3 不同λ取值下的TSMWD综合性能
通过表3可以发现,当TSMWD-I模块不存在时,意味着此时的λ趋向于无穷大,即第一检测模块将所有的样本都判定为未知样本交由第二模块进行处理,此时TSMWD系统的检测效率最低,时间开销最大,为3.47 s,但是系统对于恶意样本的检测能力最强、准确率最高。当λ为1时,即TSMWD-I的朴素贝叶斯算法不进行任何修正,这时绝大多数的正常样本都不再经过第二检测模块进行判决,整个系统的检测效率得到显著提升,检测时间缩短为1.49 s。但是由于未经修正的第一检测模块对于恶意样本存在大量的误判,因此系统整体的检测能力受到影响,准确率下降了近15%。引入了矫正因子λ后,随着λ的不断增加,被TSMWD-I过滤的正常样本不断减少,检测时间有所上升;但是整个系统的检测能力不断提高,检测准确率所受影响越来越小。当λ达到1.6时,可以发现,TSMWD系统相比于传统的只有TSMWD-II的检测系统在检测效率上由3.47 s缩短为2.24 s,检测效率提升约35%,且在系统检测能力方面由于TSMWD-I的TPR很高,所以所受的影响非常少,仅由原先的93.57%下降为93.24%,检测能力仅下降0.4%,依然维持在目前静态恶意网页检测的前沿水平。
综上所述,本文提出的基于机器学习的两层恶意网页检测系统可以在几乎不影响传统检测系统检测能力的前提下,显著提升原恶意网页检测系统的检测效率,使之更加符合当前每日新增网页数量井喷式的使用环境。
4.5 TSMWD与现有方案的对比
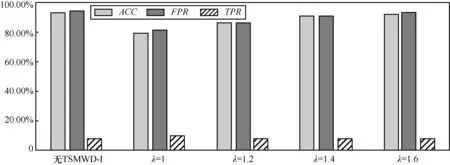
图11 不同λ取值下的TSMWD检测能力
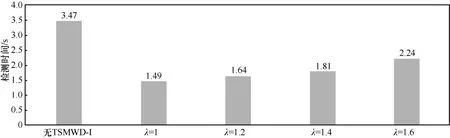
图12 不同λ取值下的TSMWD检测效率
经过上述实验可知,本文所提出的两层恶意网页检测系统,能够根据不同的使用环境与使用需求,通过调整参数λ进行检测能力和检测效率之间的相互转换。本节将本文提出的检测系统与现有的其他静态恶意网页检测系统进行比较,由于本系统在注重检测率的同时更加注重性能上的提升,而很多现有的研究方案仅给出了检测能力上的评价指标,而没有给出相应的检测速率和检测效率,所以对比主要在两个维度上进行:一方面与现有解决方案进行检测能力上的对比;另一方面与给出相应检测速度的解决方案进行检测效率上的对比。
将TSMWD恶意网页检测系统分别与Pawan等[25]提出的钓鱼网页检测系统PhishNet、Sangho等[26]提出的恶意URL准实时检测系统WarningBird、Likarish等[27]提出的恶意网页检测系统、Justin等[28]提出的恶意URL检测系统Beyond Blacklists、Liu等[29]提出的钓鱼网页检测系统进行对比。
在检测效率方面,根据文献[25]的描述,Google Safety Browser API大约需要80 ms的时间为每个恶意网页URL在其数据库中进行查询,这其中还需要包括查询数据分组和结果数据分组在网络中传输所消耗的时间,而PhishNet将其检测速率提升了约80倍,检测出每个恶意URL的平均消耗时间为1 ms,该方案在启发式规则提出的恶意URL检测方案的基础上进行改进,准确率能够保证在90%以上。在WarningBird的项目中,系统消耗的时间主要分为3个部分,即域名分类、特征提取和分类模块,主要时间消耗占比如图13所示,其中对于每个URL检测所消耗的时间少于3.6 ms,由于本文的系统是没有域名分类模块的,并且是根据网页内容对其属性进行判定,搜集网页的数据采集模块所消耗的时间是不计算在检测系统的检测时间内的,所以为了给出更合理的对比,除去图13中耗时占比近一半的域名分组时间,从而平均每个URL的耗时大约在1.5 ms左右,与PhishNet相差无几。对于WarningBird方案的准确率,文献[26]中有相关数据,其系统检测的准确率为91.53%,假正率为1.23%。
选择TSMWD中λ=1.4时的测试结果与PhishNet和WarningBird的检测效率及检测准确率进行横向对比,对比结果如表4所示。可以看到,在检测速度方面,TSMWD相较于较快的PhishNet而言提升了约40%,相较于WarningBird提升了超过150%;在检测能力方面,PhishNet提供的检测数据有限,WarningBird检测能力与TSMWD相当,准确率方面WarningBird略高一点点,真正率方面相对较弱,但总体属于同一个水平,都已经达到了目前静态检测系统的较高水平。
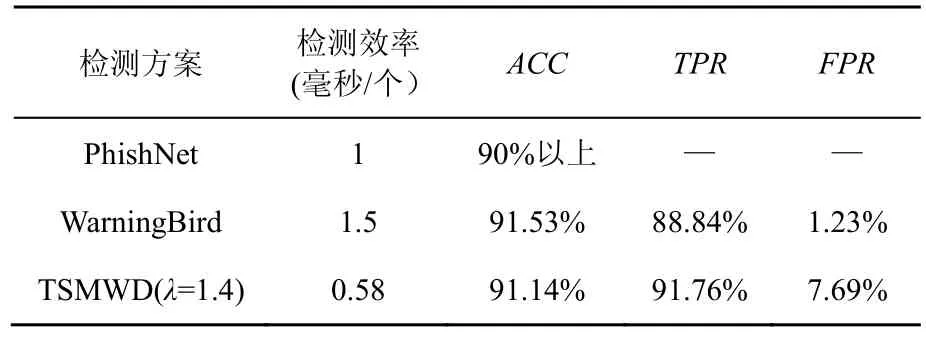
表4 TSMWD与现有检测方案检测效率对比
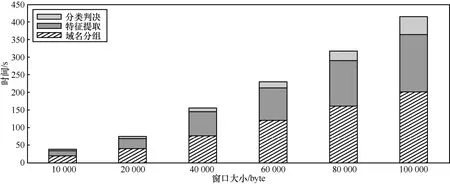
图13 WarningBird方案中检测时间开销
在检测能力方面,将TSMWD与Justin等[28]提出的Beyond Blacklists、Likarish等[27]提出的混淆检测系统、Liu等[29]提出的自动化检测系统进行了对比,由于这些系统在其文献中没有提及到相关的性能参数,所以无法与之做检测效率方面的对比。TSMWD与它们检测能力的对比如表5所示。Justin的方案由于提出的时间较早,所以检测能力上不如其余三者。其余3种方案的检测总体准确率均维持在91%~92%,虽然说对于恶意样本和正常样本的检出率各有所长,但对于未知网页样本的总体分类能力是非常接近的。
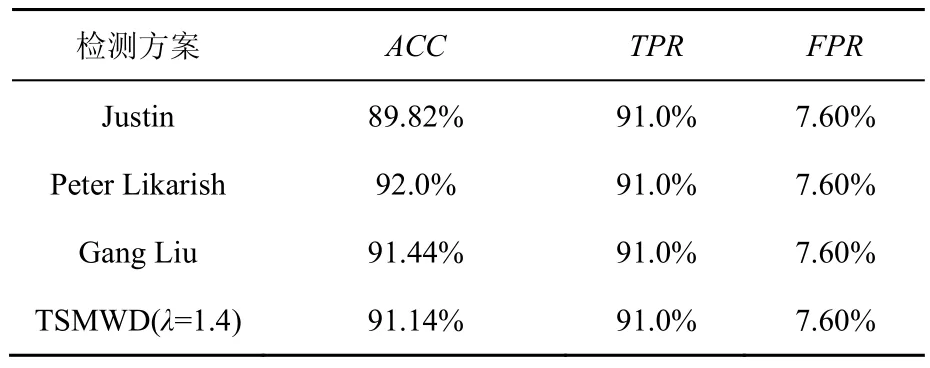
表5 TSMWD与现有检测方案检测能力对比
通过与现有静态检测方案在检测效率和检测能力指标上的对比可以发现,本文所提出的基于机器学习的两层恶意网页检测系统TSMWD,能够在检测能力达到当今静态检测前沿水平的同时,显著提高检测的速度和效率,并且能够通过对参数λ的调整,实现检测时间和检测效率的相互转换。
5 结束语
随着互联网的不断发展和普及,网页数量正以井喷式的速度快速增加,这也为恶意网页的产生提供了温床。如何能够在最短的时间内从大量的新增网页样本中筛选出恶意样本,为恶意网页检测系统的研究提出了新的值得研究的课题。本文针对恶意网页检测中所遇到的各类问题进行了研究,针对当前传统静态恶意网页检测方案在面对海量的新增网页时面临的压力,引入了两段式的分析检测过程,并依次为每段检测提出相应的特征提取方案,通过层次化地使用优化的朴素贝叶斯算法和支持向量机算法,设计并实现了一种兼顾效率和功能的恶意网页检测系统TSMWD。第一层检测系统用于过滤大量的正常网页,其特点为效率高、速度快、更新迭代容易,真正率优先。第二层检测系统追求性能,对于检测的准确率要求较高,时间和资源的开销上适当放宽。实验结果表明,该架构能够在整体检测准确率基本不变的情况下,提高系统的检测速度,在时间一定情况下,接纳更多的检测请求。
[1] 中国互联网信息中心. 第37次中国互联网络发展状况统计报告[R].北京: CNNIC, 2016.
CNNIC. The 37th report of China Inter development statistics[R]. Beijing: CNNIC, 2016.
[2] [EB/OL].http://www.securelist.com/en/analysis/.
[3] PROVOS N, MAVROMMATIS P, RAJAB M A, et al. All your iFRAMEs point to us[C]//Conference on Security Symposium. 2008:1-15.
[4] SHENG S, WARDMAN B, WARNER G, et al. An empirical analysis of phishing blacklists[C]//The Sixth Conference on Email and Anti-Spam (CEAS). 2009.
[5] ESHETE B, VILLAFIORITA A, WELDEMARIAM K. Malicious website detection: effectiveness and efficiency issues[C]//SysSec Workshop. 2011: 123-126.
[6] Making the Web safer[R/OL]. http://www.google.com/ transparencyreport/safebrowsing/?hl=en.
[7] Malware domain list[EB/OL]. http://www.malwaredomainlist. com.
[8] OpenDNS, PhishTank[EB/OL]. http://www.phishtank.com.
[9] PRAKASH P, KUMAR M, KOMPELLA R R, et al. Phishnet: predictive blacklisting to detect phishing attacks[C]//INFOCOM. 2010: 1-5.
[10] CHRISTODORESCU M, JHA S. Testing malware detectors[J]. ACM Sigsoft Software Engineering Notes, 2004, 29(4):34-44.
[11] CHOU, NEIL, ROBERT LEDESMA, YUKA TERAGUCHI, et al. Client-side defense against Web-based identity theft[C]//The 11th Annual Network & Distributed System Security Symposium (NDSS). 2004:1-16.
[12] HOU Y T, CHANG Y, CHEN T, et al. Malicious Web content detection by machine learning[J]. Expert Systems with Applications, 2010, 37(1):55-60.
[13] ROESCH M. Snort-lightweight intrusion detection for networks[J]. Lisa, 1999:229-238.
[14] LIN S F, HOU Y T, CHEN C M, et al. Malicious webpage detection by semantics-aware reasoning[C]//The Eighth International Conference on Intelligent Systems Design and Applications. 2008: 115-120.
[15] ZHANG Y, HONG J I, CRANOR L F. Cantina: a content-based approach to detecting phishing web sites[C]//The 16th International Conference on World Wide Web. 2007: 639-648.
[16] HOU Y T, CHANG Y, CHEN T, et al. Malicious Web content detection by machine learning[J]. Expert Systems with Applications, 2010, 37(1):55-60.
[17] JUSTIN M, SAUL L K, SAVAGE S, et al. Beyond blacklists: learning to detect malicious Web sites from suspicious URLs[C]//The 15th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining. 2009: 1245-1254.
[18] YOO S, KIM S, CHOUDHARY A, et al. Two-phase malicious web page detection scheme using misuse and anomaly detection[J]. International Journal of Reliable Information and Assurance, 2014, 2(1).
[19] CANALI D, COVA M, VIGNA G, et al. Prophiler: a fast filter for the large-scale detection of malicious web pages[C]//The 20th International Conference on World Wide Web. 2011: 197-206.
[20] The German honeyclient project[EB/OL].http://www. chicagohoneynet.org/german-honeypot-holz.
[21] The Honeynet Project. Know your enemy: honeynets[EB/OL]. http://old.honeynet.org/papers/honeynet/.
[22] MAYNOR D. Metasploit toolkit for penetration testing, exploit development, and vulnerability research[M]. Elsevier, 2011.
[23] HAUTUS M L J. The formal Laplace transform for smooth linear systems[M]//Mathematical Systems Theory. Berlin:Springer, 1976: 29-47.
[24] GOLUB G H, HEATH M, WAHBA G. Generalized cross-validation as a method for choosing a good ridge parameter[J]. Technometrics, 1979, 21(2): 215-223.
[25] PRAKASH P, KUMAR M, KOMPELLA R R, et al. Phishnet: predictive blacklisting to detect phishing attacks[C]//INFOCOM. 2010: 1-5.
[26] LEE S, KIM J. Warningbird: a near real-time detection system for suspicious URLs in twitter stream[J]. IEEE Transactions on Dependable and Secure Computing, 2013, 10(3): 183-195.
[27] LIKARISH P, JUNG E, JO I. Obfuscated malicious javascript detection using classification techniques[C]//The 4th International Conference on Malicious and Unwanted Software (MALWARE). 2009: 47-54.
[28] MA J, SAUL L K, SAVAGE S, et al. Beyond blacklists: learning to detect malicious Web sites from suspicious URLs[C]//The 15th ACM SIGKDD international conference on knowledge discovery and data mining. 2009: 1245-1254.
[29] LIU G, QIU B, WENYIN L. Automatic detection of phishing target from phishing webpage[C]//The 20th International Conference on Pattern Recognition (ICPR). 2010: 4153-4156.
Study of high-speed malicious Web page detection system based on two-step classifier
WANG Zheng-qi1,2, FENG Xiao-bing1,2, ZHANG Chi1,2
(1. University of Science and Technology of China, Hefei 230026,China; 2. Key Laboratory of Electromagnetic Space Information, Chinese Academy of Sciences, Hefei 230026,China)
In view of the increasing number of new Web pages and the increasing pressure of traditional detection methods, the naive Bayesian algorithm and the support vector machine algorithm were used to design and implement a malicious Web detection system with both efficiency and function, TSMWD , two-step malicious Web page detection. The first step of detection system was mainly used to filter a large number of normal Web pages, which was characterized by high efficiency, speed, update iteration easy, real rate priority. After the former filter, due to the limited number of samples, the main pursuit of the second step was the detection rate. The experimental results show that the proposed scheme can improve the detection speed of the system under the condition that the overall detection accuracy is basically the same, and can accept more detection requests in certain time.
malicious Web page detection,network security,machine learning,feature extraction
The National Natural Science Foundation of China (No.61202140, No.61328208)
TP393
A
10.11959/j.issn.2096-109x.2017.00186

王正琦(1992-),男,江苏镇江人,中国科学技术大学硕士生,主要研究方向为网络安全。

冯晓兵(1992-),女,山东聊城人,中国科学技术大学硕士生,主要研究方向为网络安全。

张驰(1977-),男,中国科学技术大学副教授、博士生导师,主要研究方向为计算机网络、信息安全。
2017-05-27;
2017-07-22。通信作者:王正琦,wzqwzq@mail.ust.edu.cn
国家自然科学基金资助项目(No.61202140, No.61328208)
