基于相位谱的翻录语音攻击检测算法*
2017-09-03李璨王让定严迪群陈亚楠
李璨,王让定,严迪群,陈亚楠
(宁波大学信息科学与工程学院,浙江 宁波 315211)
基于相位谱的翻录语音攻击检测算法*
李璨,王让定,严迪群,陈亚楠
(宁波大学信息科学与工程学院,浙江 宁波 315211)
因与原始语音具有高度相似性,经高保真设备回放的翻录语音常被不法分子用于对说话人认证(ASV)系统进行攻击,以达到非法认证的目的。为提高系统抵抗翻录语音攻击的顽健性,通过研究原始语音与翻录语音产生的实际过程,发现两者在频率域相位上有明显差异,并在此基础上提出了一种基于相位谱的翻录语音检测方法。分析讨论了FFT和不同偷录、回放设备对翻录语音检测率的影响。实验结果表明,该方法能够准确地判断待测语音是否为翻录语音,其检测率达到了99.04%。并且,将该算法加载到说话人识别系统中,使系统的等错误概率(EER)降低了约22%,有效提高了系统抵抗翻录语音攻击的性能。
说话人认证系统;翻录语音检测;相位谱
1 引言
在信息时代,录音设备(如录音笔、智能手机等)日趋低价和高保真,回放设备也越来越精准,为录音造假提供了可能。翻录语音经录音设备偷录、回放设备回放,与原始语音难辨真假,一些说话人认证系统也无法辨别。而且翻录语音因偷录设备体积小、易偷录、成功率高等优势,已成为攻击语音认证系统中最易实施的方法。因此,对翻录语音检测十分迫切且具有现实意义。
近年来,国内外研究学者对翻录语音检测展开研究,并取得了一定的研究成果。其中检测算法主要分为以下两类:一是基于语音产生随机性的检测算法。Shang W等人[1,2]根据语音的随机性,提出了一种基于Peak map特性的录音回放检测算法,该算法通过计算原始语音与翻录语音 Peak map特性的相似度,判断待测语音是否为翻录语音。若相似度大于设定的阈值,判定为翻录语音;反之,判定为原始语音。在此基础上,Jakub G等人[3]对该算法进行了改进,在Peak map特性中加入了各频率点的位置关系,Wu Z等人[4]加入光谱峰作为检测特征,但该算法只能针对文本相关的识别系统,且只针对一种偷录设备,存在较大的局限性。二是基于语音信道的检测算法。张利鹏等人[5]根据信道模式特征,用语音数据的静音段对信道建模,检测待测语音与训练语音的信道是否相同,从而判断是否为回放攻击。王志锋等人[6,7]根据原始语音与翻录语音产生的信道不同,提取信道模式噪声,利用SVM(support vector machine,支持向量机)得到了很好的分类结果。Villalba等人[8,9]依据远距离的录音会受到噪声和混响的影响,提出了针对远距离偷录语音的检测方法。Chen Y N 等人[10]根据设备信道对语音编码过程的影响,提出基于长窗比例因子的回放语音检测算法。但该类方法提取的信道模式噪声并非准确,且录制语音的设备过于单一,且未对多种不同的偷录设备及回放设备进行分析与研究。
伴随着信息化的快速发展,信息安全形势愈加严峻[11,12]。然而,目前针对多种不同偷录设备与回放设备的翻录语音检测的研究关注较少。在现实生活中,各种高质量低价格的高保真录音设备随处可见,如录音笔及各种智能手机。这类偷录设备携带便利且不易察觉,且获得的翻录语音与原始语音相似性较高,因此这种录音设备是目前较为主流的偷录设备。同时,不同的回放设备对翻录语音的产生也有较大的影响。但是,由于偷录设备和回放设备种类繁多,不同的录音设备中传感器和信号采集电路存在差异,产生不同的设备信息。这无疑增加了对不同录音设备的翻录语音攻击检测的难度。
本文通过分析研究原始语音与翻录语音产生的实际过程,发现翻录语音经历了一次偷录与回放过程后,其相位会发生不同程度的变化,根据相位谱的不同,提出了一种基于相位谱的翻录语音检测算法。为提高算法的实用性,弥补现有算法涉及录制设备单一的问题,本文讨论了不同偷录设备和回放设备对检测率的影响,并对影响程度作了分析。实验结果表明,将本文检测方法加载到目前主流的GMM-UBM和i-vector说话人识别系统中后,系统抵抗翻录攻击的性能得到了极大的提高。
2 原始语音和翻录语音产生的实际过程
原始语音和翻录语音产生的实际过程如图 1所示。从说话人处直接得到的语音本文称为原始语音,也称为合法语音。将说话人语音用偷录设备进行偷录,回放设备进行回放得到的语音称为翻录语音。
由图1可知,翻录语音比原始语音多经历了一次高保真音响系统。高保真音响系统原汁原味地还原了原始语音,使得原始语音与翻录语音具有高相似度,但该系统不可避免地对语音信号进行电平调整、A/D转换、编解码等一系列的操作,使得翻录语音与原始语音还是存在着一定的差异。
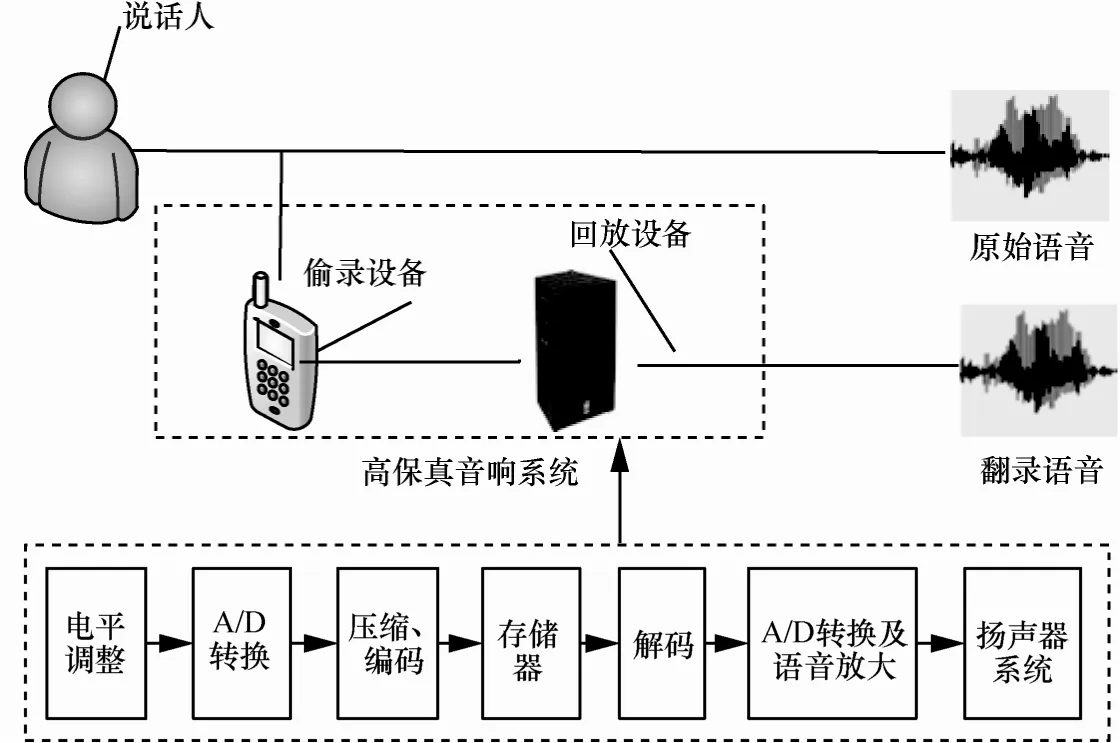
图1 原始语音和翻录语音产生的实际过程
原始语音和翻录语音的波形如图2所示,其中图2(a)是一段经Aigo R6620录音笔原始录制的语音信号的波形图,该语音信号的具体内容为普通话朗读的“开窗 关灯 亮度佳 播放音乐”。图2(b)、图2(c)、图2(d)是对应的翻录语音信号的波形,翻录过程中的偷录设备分别为 iPhone6、Mi4和Sony PX440,回放设备则都选择的是 Huawei AM08。从图2可以看出,翻录语音信号较原始语音还是产生了一些失真,只是针对不同的翻录设备,失真的大小略有区别。例如,在图2所示的3款偷录设备中,iPhone6对应的语音信号失真最小,Sony PX440对应的语音信号失真最大。

图2 原始语音和翻录语音的波形(Huawei AM08)
图3、图4的波形分别与图2一一对应,其回放设备分别为 Philips DTM3115和 Yamaha TSX-140。由图2、图3、图4可以看出,无论是偷录还是回放设备,对翻录语音都有一定的影响,但对翻录语音有何影响且影响程度如何,需要进一步探索。同时,在时域上很难区分原始语音与翻录语音,但翻录语音经过高保真系统的电平调整、A/D转换、编解码等一系列的操作,该系统将对不同频率信号相位产生超前或者滞后的影响,会使得翻录语音的相位产生较大程度的失真。
3 特征提取和翻录语音攻击检测
相位谱检测算法主要由语音预处理、相位谱特征提取、特征选择、分类识别4个部分组成。在特征选择上,本文将相位统计平均作为检测特征,并运用 SVM-RFE算法进行特征筛选,采用LIBSVM分类器进行分类识别。为验证该算法的有效性,本文将该检测算法加载到了说话人识别系统中,并对该系统防御翻录语音的攻击能力进行了检测。

图3 原始语音和翻录语音的波形(Philips DTM3115)

图4 原始语音和翻录语音的波形(Yamaha TSX-140)
3.1 特征提取
相位信息对感知有着不可忽视的作用,相位谱反映信号方向随频率变化的规律,含有大量的信息[13]。本文算法首先根据待测语音提取相应的相位。设待检测语音信号为x,将语音信号分帧处理后,对其进行FFT,得到:
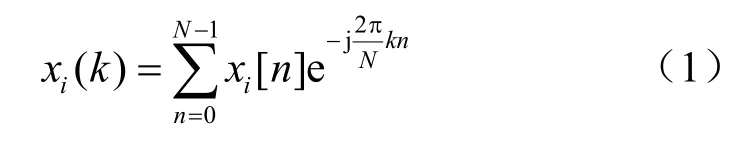
其中,k=0,1,2,…, N−1; i=1,2,…,S,S表示总帧数。
对于语音信号第i帧,求其相位 φi( k):

为表征相位谱的变化程度,本文选取均值统计特性。对于第i帧第j频率点相位 φi,j(k),求其幅值:
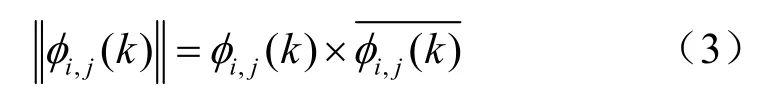
然后求其第j频率点相位的统计平均 ϕj(k):

最后,对 ϕj(k)进行归一化处理,得到语音信号相位谱特征。初步分析可知,相较于原始语音,翻录语音经历了一次高保真系统,该系统会对不同频率信号相位产生超前或滞后的影响。另外,受录音设备的影响,语音在翻录过程中将会引入一定的设备噪声,这种噪声是录音设备所固有的,会使语音的相位谱产生明显的失真。
图5、图6、图7分别是3种不同的回放和偷录设备的原始语音与翻录语音的相位谱特征图。图中FFT采样点数N为1 024,根据实序列离散傅里叶变换的共轭对称性,本文选取前512个值。其中图 5(a)、图 6(a)、图 7(a)表示一段由Aigo R6620录音笔录制的语音内容为“开窗 关灯亮度佳 播放音乐”的原始语音的相位谱,图5(b)、图5(c)、图5(d)、图6(b)、图6(c)、图6(d)、图7(b)、图7(c)、图7(d)分别是偷录设备为iPhone6、Mi4和Sony PX440,回放设备为Huawei AM08、Philips DTM3115和Yamaha TSX-140的翻录语音相位谱。

图5 原始语音与翻录语音相位谱特征(Huawei AM08)

图6 原始语音与翻录语音相位谱特征(Philips DTM3115)
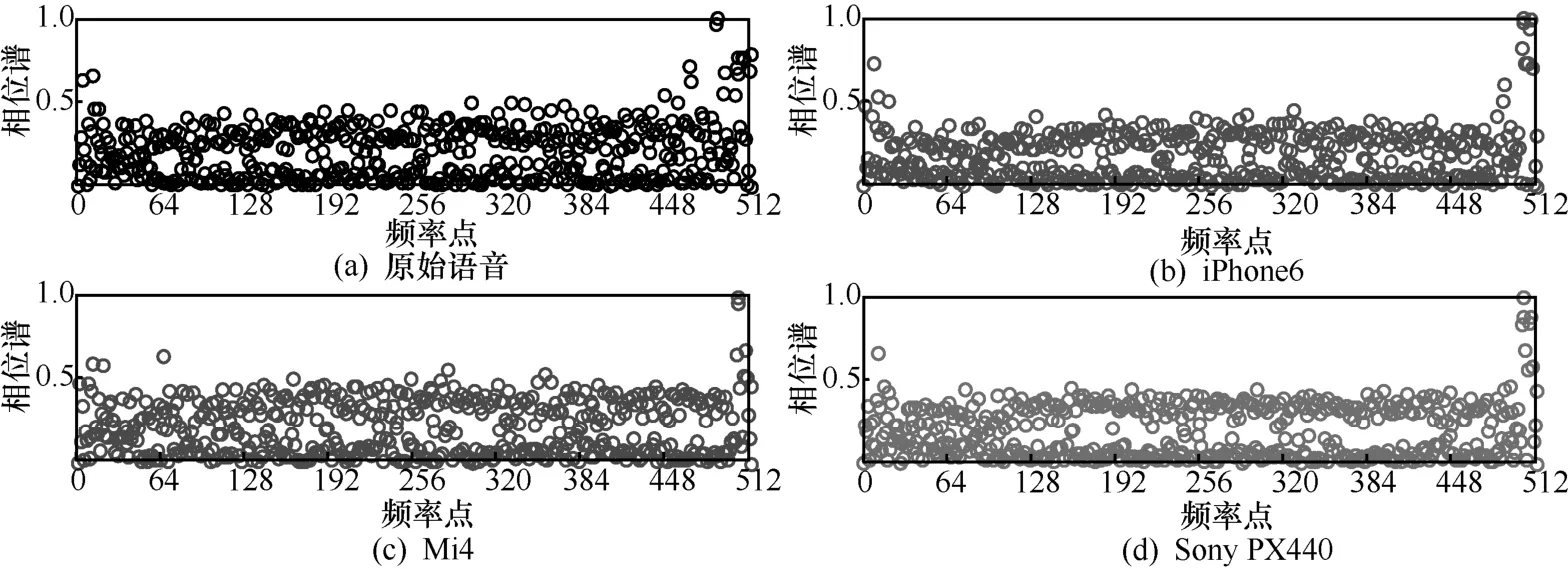
图7 原始语音与翻录语音相位谱特征(Yamaha TSX-140)
由于偷录设备和回放设备均是翻录过程的重要设备,它们均会在翻录语音中留下“痕迹”。当回放设备相同时,图5、图6、图7中的(a)与(b)、(c)、(d)在高频区有明显的不同,(b)、(c)、(d)在高频区相似度较高。当偷录设备相同时,不同的回放设备其相位谱区分较为明显。但是总体来看,针对不同的偷录设备和回放设备的翻录语音,其相位信息与原始语音具有较大的失真。为了实现更好的性能测试,提高运算效率,选择有效的特征维数,本文采用SVM-RFE算法进行特征选择。
SVM-RFE算法[14]的输出结果是按照特征的重要性对特征进行排序的列表。本文将上述所提取的相位特征进行特征筛选。这里使用的 FFT采样点数为1 024,样本数目为14 000(原始语音1 400,翻录语音12 600)。其中,RANK为最终的排列等级,AVG_RANK为5次交叉验证RANK结果的平均值,特征索引N为前512维特征。SVM-RFE对特征排序的结果(前20列)见表1。
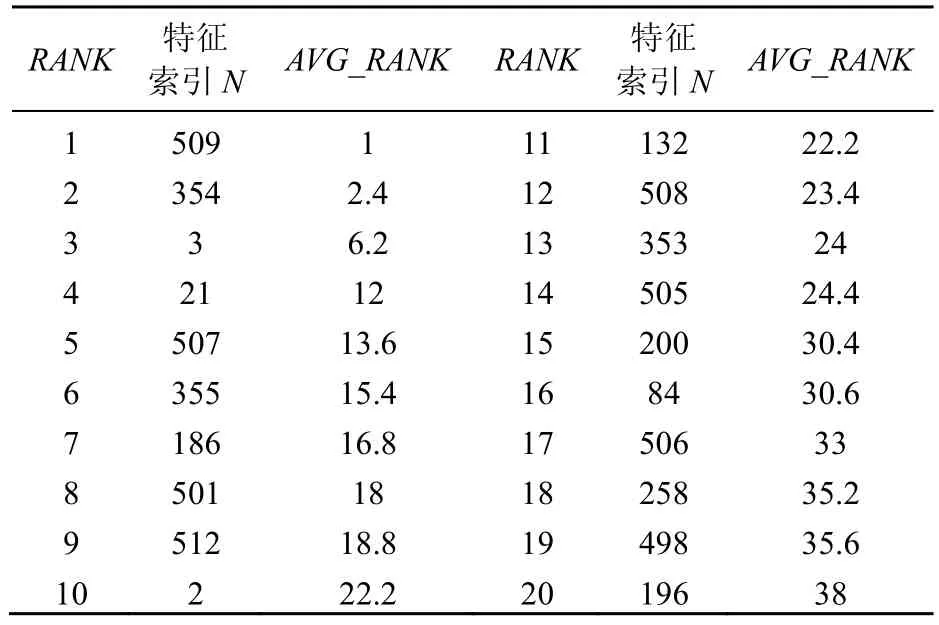
表1 SVM-RFE特征排序的结果
由表1可知,在前20列特征重要性的排序中,特征索引N为509的特征翻录语音失真最大。整体来看,特征索引N较大的值所占的比例较高,即翻录语音较原始语音在高频区失真较为明显。因此,为提高检测效率,选择RANK≥10的10维特征作为最终的有效特征。
3.2 翻录语音攻击检测
为验证基于相位谱的翻录语音检测算法的有效性,本文将该算法加载到了说话人识别系统中,如图8所示。

图8 防翻录语音攻击的识别系统流程
具体的操作步骤如下:语音经采集设备采集,同时输入说话人识别系统和翻录语音检测模块中;在翻录语音检测模块,提取语音信号的相位谱特征,对语音进行分类识别。若输入的语音为翻录语音,则判决1为0;否则,判决1为1;说话人识别系统对输入语音进行判决,若输入语音为说话人语音,则判决2为1;否则,判决2为0;在判决模块,结合判决1和判决2的结果,按表2规则对输入语音进行判断,输出最终结果。
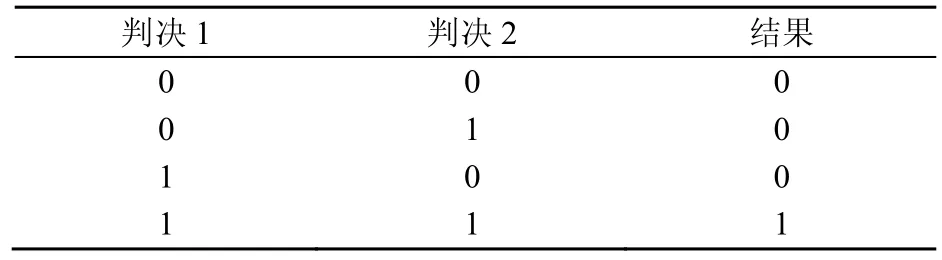
表2 判决规则
4 语音库
为了验证本文方法的有效性,本文构建了一个符合研究目的的语音数据库。数据库的具体设置如下:语料库来源于 863语料库[15];人员分布为:18男14女;设备选取主要涉及语音采集设备、偷录设备、回放设备。设备的详细信息见表3。
实验库的构建环境为安静房间,阅读内容为语料库内容,参与者依据自身朗读习惯用标准普通话进行录音,并使用采集设备进行语音采集,采集设备距参与者大约20 cm,本文将采集设备此次采集到的语音称为原始语音。在参与者阅读以上语料的同时,将偷录设备同时打开到正常录制功能下,录制参与者的语音内容,根据实际情况,将偷录设备距离说话人大约70 cm。在同样的环境下,将偷录设备采集到的语音经音响回放,并使用采集设备录制该回放语音。回放音响距离采集设备20 cm左右。将此次采集设备采集到的语音称为翻录语音。实验样本为14 000个(原始语音1 400个,翻录语音12 600个)。样本详情见表4。

表3 设备信息
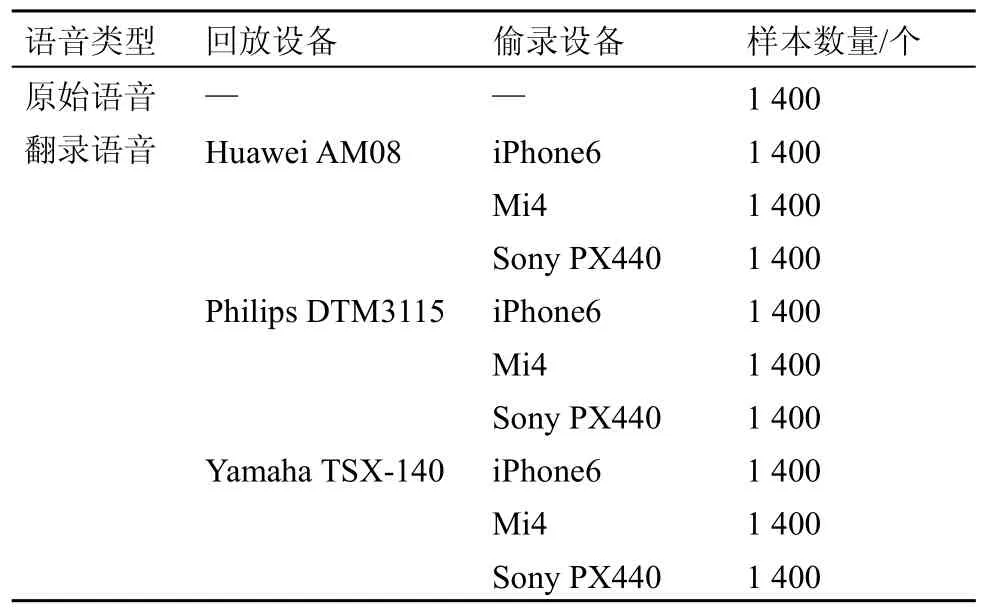
表4 原始语音和翻录语音样本详情
5 实验设置及结果分析
实验中使用 LIBSVM,它是一种监督是学习方法,广泛地应用于统计分类以及回归分析。分类过程如下:先根据第3.1节进行特征提取并使用LIBSVM 进行训练得到模型,将待测语音在LIBSVM模型上进行测试并给出最终判断结果。本文将根据录音过程中的影响变量,分别分析其对检测翻录语音的影响。
5.1 FFT变换点数的影响
相位谱反映信号方向随频率变化的规律,含有大量的信息。不同的FFT采样点数对相位信息产生较大的影响。随着采样点数的增加,语音相位谱所包含的信息越多,翻录语音经过高保真系统后,其相位失真越来越明显。为了寻找最佳的检测效果的采样点数,讨论了基于FFT采样点数为128、256、512、1 024时的翻录语音检测效果。实验采样LIBSVM分类器在weka平台上进行试验。实验样本为原始语音1 400个,翻录语音12 600个。检测效果见表5,其中包括真正类率(true positive rate,TPR)、负正类率(false positive rate,FPR)、准确度(accuracy,ACC)等。

表5 翻录语音检测率
由实验结果可以看出,当FFT采样点数N为1 024时,对翻录语音有较好的检测效果,其检测率达到99.04%。随着FFT采样点数的增大,包含的语音相位信息越多,越能较好地反映语音信号的本质特征。综合考虑,本文选取1 024作为最佳检测率时的FFT采样点数。
5.2 不同录音设备的影响
由第5.1节可知,当FFT采样点数为1 024时,对翻录语音检测效果最优。但不同的偷录设备与回放设备所含有的固有设备信息不同,它对相位谱的影响也就不同。因此,本节通过实验揭示不同偷录设备和不同回放设备对翻录语音检测率的影响。检测结果见表6。

表6 不同偷录设备与回放设备的翻录语音检测
由表 6可以看出,当回放设备为 Huawei AM08时,来源于3种不同偷录设备的翻录语音均能被 100%识别;当回放设备为 Yamaha TSX-140时,偷录设备为Sony PX440和iPhone6的翻录语音检测率为100%,偷录设备为Mi4的翻录语音检测率达到了 99.71%;当回放设备为Philips DTM3115时,识别准确率虽不及以上两种,但其准确率也达到了 99.7%以上。实验结果表明:本文检测算法能够很好地检测翻录语音与原始语音,且对偷录设备与回放设备有较好的顽健性。
5.3 加载翻录语音检测模块后的识别系统
为更好地检验翻录语音对说话人识别系统的攻击情况,本文分别在GMM-UBM和i-vector说话人识别系统上进行了实验。在实验中,提取13维 MFCC基本特征,与一阶、二阶差分构成 39维特征参数。翻录语音检测模块使用FFT点数为1 024。实验中训练了4个用户模型,在测试时用每个用户的翻录语音作为攻击语音,其中每个用户模型使用原始语音130个、翻录语音150个。
科研工作者从20世纪50年代开始进行说话人识别技术研究,至今取得了一定的进展[16]。GMM-UBM和i-vector说话人识别系统是经典和目前主流的两个系统。GMM-UBM[17]主要利用UBM和少量的说话人数据,通过自适应算法得到目标人模型,最后用测试数据分别与模型和UBM进行打分比较;基于i-vector并进行信道补偿的说话人识别系统[18]根据 UBM 和 T子空间提取i-vector,建立GPLDA(Gaussian probabilistic linear discriminate analysis,高斯概率线性判别分析)模型及说话人模型,测试阶段用测试语音对模型进行打分比较,本实验打分方式采用对数似然比。
本实验分别在GMM-UBM和i-vector说话人识别系统上,测试来源不同的回放设备和偷录设备的翻录语音是否能够攻击成功,检测结果如图10(a)和图10(b)所示。在GMM-UBM系统上,未加载翻录语音检测模块的说话人识别系统的EER为46.33%,加载了翻录语音检测模块后,该系统的EER降为6.48%,下降了约40%。在i-vector系统上,系统对翻录语音的攻击有一定的防御性,但并不能完全抵抗攻击,该系统的EER为27.78%,当加载了翻录语音检测模块时,系统EER降为5.56%,下降了约22%。该数据说明本检测算法能够有效地提高GMM-UBM和i-vector识别系统抵抗翻录语音攻击的能力。
5.4 对比实验
将本文算法与典型的3种算法在本文数据库上进行对比,实验结果见表7。参考文献[5]算法采用短时能量法提取静音,利用谱减法进行滤波,提取MFCC特征参数。参考文献[7]方法采用高通滤波器进行去噪,提取信道模式噪声,并提取6个统计特征及6阶Legendre多项式系数。参考文献[10]中算法将语音信号进行MP3编码后,提取比例因子统计特征作为检测特征。表7中,ACC表示准确率,EER表示将检测模块加载到GMM-UBM、i-vector说话人识别系统时,系统的等错误概率。
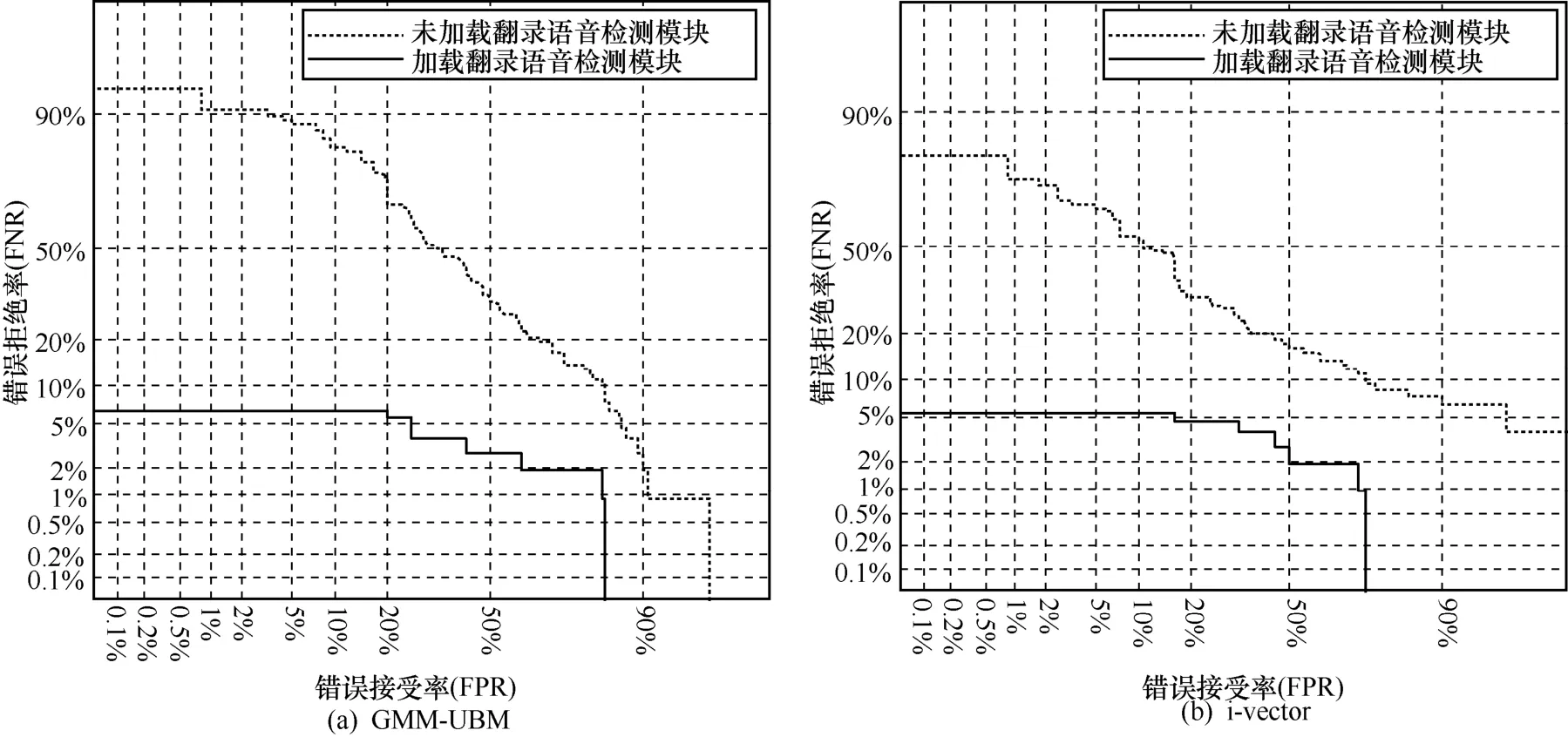
图10 加载翻录语音检测模块前后的等错误概率对比
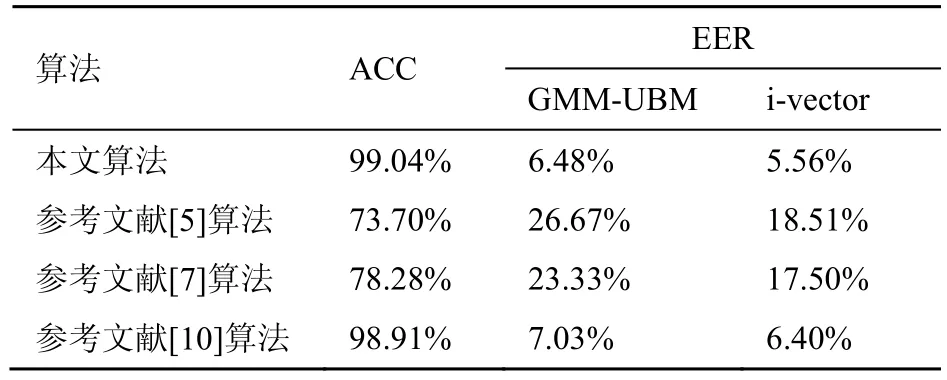
表7 本文算法与参考文献[5,7,10]算法检测结果的对比
由表7可以看出,对于多种偷录及回放设备的翻录语音,本文算法优于参考文献[5,7,10]算法,识别率分别提高了约26%、约21%和约0.1%。解决了参考文献[5,7]中设备过于单一的问题,更具实用性。另外,参考文献[5,7,10]中算法使用特征维数分别为39维、12维和21维,本文算法共计10维特征,维数更低。
6 结束语
本文针对多种偷录设备与回放设备的翻录语音攻击,提出了基于相位谱的翻录语音检测算法。并通过模拟实际翻录语音攻击的整个物理过程,建立了实验语音数据库。本文确定了最佳检测效果的FFT点数,对来源不同录音设备的翻录语音进行了检测,其检测率达到了99.04%,在此基础上,将该检测算法模块加载到说话人识别系统中,其抵抗翻录语音攻击的能力提升了约22%。在今后的研究中,将进一步探究各种录音设备及回放设备对语音的影响,并且在检测方法上进行创新和改进。
[1]SHANG W, STEVENSON M. A playback attack detector for speaker verification systems[C]//2008 IEEE International Symposium on Communications Control and Signal Processing (ISCCSP), March 12-14, 2008, Bordeaux, France. New Jersey: IEEE Press, 2008:1144-1149.
[2]SHANG W, STEVENSON M. Score normalization in playback attack detection[C]//IEEE International Conference on Acoustics Speech and Signal Processing (ICASSP) , March 14-19, 2008, Dallas, USA. New Jersey: IEEE Press, 2010:1678-1681.
[3]JAKUB G, MARCIN G, RAFAL S. Playback attack detection for text-dependent speaker verification over telephone channels [J]. Speech Communication, 2015(67):143-153.
[4]WU Z, GAO S, CLING E S, et al. A study on replay attack and anti-spoofing for text-dependent speaker verification[C]//IEEE 2014 Summit and Conference, Asia-Pacific Signal and Information Processing Association, December 9-12, 2014, Siem Reap, Cambodia. New Jersey: IEEE Press, 2014: 35-45.
[5]张利鹏, 曹犟, 徐明星. 防止假冒者闯入说话人识别系统[J].清华大学学报(自然科学版), 2008, 48(S1): 699-703. ZHANG L P, CAO J, XU M X. Prevention of impostors entering speaker recognition systems[J]. Journal of Tsinghua university (Science and Technology ), 2008 , 48(S1): 699-703.
[6]王志锋, 贺前华, 张雪源, 等. 基于模式噪声的录音回放攻击检测[J]. 华南理工大学学报, 2011, 39(10): 7-12. WANG Z F, HE Q H, ZHANG X Y, et al. Channel pattern noise based playback detection algorithm speaker recognition[J]. Journal of South China University of Technology(Natural Science Edition), 2011, 39(10): 7-12.
[7]WANG Z F, HE Q H, ZHANG X Y, et al. Channel pattern noise based playback detection algorithm speaker recognition [C]// IEEE International Conference on Machine Learning and Cybernetics(ICMLC), July 10-13, 2011, Guilin, China. New Jersey: IEEE Press, 2011: 1708-1713.
[8]VILLABA J, LLEIDA E. Detecting replay attacks from far-field recordings on speaker verification systems[C]//COST 2011 European Conference on Biometrics and ID Management, March 8-10, 2011, Brandenburg, Germany. New York: ACM Press, 2011: 274-285.
[9]VILLABA J, LLEIDA E. Preventing replay attacks on speaker verification systems[C]//IEEE International Carnahan Conference on Security Technology (ICCST), October 18-21, 2011, San Francisco, USA. New Jersey: IEEE Press, 2011: 1-8.
[10]CHEN Y N, WANG R D, YAN D Q, et al. Voice playback detection based on long-window scale-factors[J]. International Journal of Security and Its Application, 2016, 10(12): 299-310.
[11]郑志彬.信息网络安全威胁及技术发展趋势[J].电信科学, 2009, 25(2): 28-34. ZHENG Z B. Overview of mobile communication services security[J].Telecommunications Science, 2009, 25(2): 28-34.
[12]王帅, 汪来富, 金华敏, 等. 网络安全分析中的大数据技术应用[J]. 电信科学, 2015, 31(7): 145-150. WANG S, WANG L F, JIN H M, et al. Big data application in network security analysis [J]. Telecommunications Science, 2015, 31(7): 145-150.
[13]OPPENHERIM A V, LIM J S. The important of phase in signals[J]. Processing of the IEEE, 1981, 69(5): 529-541.
[14]DUAN K B, RAJAPAKSE J C, WANG H Y, et al. Multiple SVM-RFE for gene selection in cancer classification with expression data[J]. IEEE Transactions on Nano Bioscience, 2005, 4(3): 228-234.
[15]王天庆, 李爱军. 连续汉语语音识别语料库的设计[C]// 第六届全国现代语音学学术会议论文集(下), 2003年 10月18-20日, 天津, 中国. 天津: 天津人民出版社, 2003. WANG T Q, LI A J. The design of the continuous Chinese speech recognition corpus[C]//The sixth national conference on modern phonetics learning, October 18-20, 2003, Tianjin, China, Tianjin: Tianjin Remin Chubanshe, 2003.
[16]杨震, 徐敏捷, 刘璋峰, 等. 语音大数据信息处理架构及关键技术研究[J]. 电信科学, 2013, 29(11): 1-5. YANG Z, XU M J, LIU Z F, et al. Study of audio frequency big data processing architecture and key technology[J]. Telecom munications Science, 2013, 29(11): 1-5.
[17]CHAKROBORTY S, ROY A, SAHA G. Improved closed set text-independent speaker identification by combining MFCC with evidence from flipped filter banks[J]. International Journal of Signal Processing, 2007, 4(2): 114-122.
[18]KANAGASUNDARAM A, DEANA D, SRIDHARAN S, et al. I-vector based speaker recognition using advanced channel compensation techniques[J]. Computer Speech and Language, 2014, 28(1): 121-140.
Recapture voice replay detection based on phase spectrum
LI Can, WANG Rangding, YAN Diqun, CHEN Yanan
College of Information Science and Engineering, Ningbo University, Ningbo 315211, China
Due to a high similarity between the recaptured voice recorded by high-fidelity ripping equipment and the original voice, the automatic speaker verification(ASV)system used to be attacked illegally by the recaptured voice. In order to improve the ability of resisting the attack, a recaptured voice detection method was proposed based on the difference of phase spectrum between original and recaptured voices for the ASV system. In addition, the effects of different recording and replay devices, the FFT were discussed. Experimental results show that the proposed method can accurately recognize the recording voice, of which detection rate is 99.04%。Meanwhile, the equal error rate (EER) of the ASV system has dropped about 22% with this method being integrated, which indicates that the system’s ability of resisting playback attack is enhanced.
ASV system, recaptured voice detection, phase spectrum
s: The National Natural Science Foundation of China (No. 61672302, No.61300055), Natural Science Foundation of Zhejiang Province of China (No.LZ15F020010, No.Y17F020051), The Scientific Research Foundation of Ningbo University (No.XKXL1405, No.XKXL1420, No.XKXL1509, No. XKXL1503), K.C. Wong Magna Fund in Ningbo University
TP391
A
10.11959/j.issn.1000−0801.2017126

李璨(1992−),女,宁波大学信息科学与工程学院硕士生,主要研究方向为多媒体通信与信息安全等。

王让定(1962−),男,博士,宁波大学高等技术研究院教授、博士生导师,主要研究方向为多媒体通信与取证、信息隐藏与隐写分析、智能抄表及传感网络技术等。

严迪群(1979−),男,博士,宁波大学信息科学与工程学院副教授、硕士生导师,主要研究方向为多媒体通信、信息安全、基于深度学习的数字语音取证等。

陈亚楠(1990−),女,宁波大学信息科学与工程学院硕士生,主要研究方向为多媒体通信与信息安全等。
2017−01−23;
2017−03−20
王让定,wangrangding@nbu.edu.cn
国家自然科学基金资助项目(No.61672302,No.61300055);浙江省自然科学基金资助项目(No.LZ15F020010,No.Y17F020051);宁波大学科研基金资助项目(No.XKXL1405,No.XKXL1420,No.XKXL1509,No.XKXL1503);宁波大学王宽诚幸福基金资助项目
