一种基于图归约的XPath高性能流数据查询方法*
2017-09-03廖湖声高红雨
陶 杰,廖湖声,高红雨
(北京工业大学 信息学部,北京 100124)
一种基于图归约的XPath高性能流数据查询方法*
陶 杰,廖湖声,高红雨
(北京工业大学 信息学部,北京 100124)
作为网络数据交换和数据共享的标准,XML数据越来越多地用于表示应用系统的流数据。然而,受制于流数据处理有限空间开销等特征,如何高效地实现这种查询成为值得探讨的问题。与传统的基于自动机或层次栈方法不同,文中提出了一种基于图归约的XML查询自动机(GRAT),采用一种图结构来表示针对不同XML流元素的子查询任务之间的关系,通过图的归约变化来实现XPath查询。实验结果表明,基于GRAT的查询算法能够高效地完成复杂的XML查询,流数据处理的吞吐量达到了较高水平。
XML;图归约;流数据
0 引言
网络中有如传感器网络、气象监控、金融服务和网络监控等很多应用系统会持续地自动产生大量的数据。这些数据是一个随着时间延续而无限递增的动态集合,称为流数据。不同于传统数据处理,流数据[1]无法控制自身到来的顺序,并且到来的数据一经处理,就不能再次被取出或者耗费昂贵的代价取出,除非特意将数据保存。因此,流数据的处理需要满足一次存取、持续处理、有限存储和快速响应的特点。网络上用于传输和共享的数据的标准以半结构化数据为准[2],而标记扩展语言 (eXtensible Markup Language, XML)因其自描述、半结构化等特征,已经成为了互联网上主导的数据交换和数据共享的标准[3]。随着近年来网络数据吞吐量以及各行各业的网络应用的爆炸性增长,数据量也在不断地增加,以XML为主的流数据处理已成为研究人员普遍关注的一个热点[4-5]。为了能够快速高效地从海量持续不断的数据中找出用户需求的少量数据[6],需要流数据处理的方法具备丰富的查询功能和强大的查询处理能力[7]的同时,也要避免占用过多的资源。
处理XML流数据的理论和技术已经成为流数据领域中的一个重要分支[8]。在XML流数据的处理方法中,数据会以事件进行驱动,以开始标签、内容和结束标签的形式进行处理,用户的查询则主要使用XML路径语言(XML Path language, XPath)表示查询。如何对XML流数据在一次扫描之后获得所有正确的结果是个富有挑战的问题[9]。目前已经出现了很多有关XML流数据查询处理的方法和成果[10-11]。BFilter[12]使用向后匹配的算法,有效地处理了查询,但是该方法只支持订阅-发布这一类单一的系统,并不支持流数据处理;PFilter[13]采用基于序列的方法,支持值谓词的查询,也能够应对祖先后代关系等的复杂谓词查询,但是处理过程相对复杂,并且不支持嵌套谓词的查询处理,不能满足当今的复杂查询;EFilter[14]使用查询引导的方法,支持流数据查询和twig查询模式,然而该方法对于缓存要求比较高,而且实现相对复杂;HadoopXML[15]能够高效处理大量数据,但是采用的是批处理形式,并不满足流数据的实时性;宏森林自动机[16]有效提高了XML的查询,并且支持复杂谓词的查询,但是文章中并没有给出实现自动机的方法;Feng X在宏森林自动机的基础上实现了基于XPath的查询方法[17],满足流数据的查询处理和复杂谓词的处理,但是实现的步骤复杂,不够灵活,不容易扩展。
以上这些方法基本上都采用自动机[18-20]和复杂层次栈的方法[21]实现流数据处理。与上述所采用的方法不同,本文提出一种基于图归约的XML查询技术——GRAT。该方法既可以避免预处理的时间开销,又使得查询复杂性保持线性增长,同时也足够灵活,具备强大的加工能力来应对更复杂的谓词处理。本文提出的算法针对持续不断产生的XML流数据进行查询处理,以XPath查询作为查询任务,能够高效快速地查询以XML为主的流数据。
1 预备知识
1.1 XML森林[22]
XML数据是由多个标签和文本遵循严格的嵌套规则组成的,具有树形结构。所谓XML流数据由多个XML元素组成,其中每个XML元素可以表示成顺序遍历的树。这种连续的XML片段序列数据被称为XML森林。
定义1:一个XML森林是序列t1,t2…tn,其中n≥0并且t1,t2…tn都是XML树。一棵树由一个带有标记的根节点和子树序列组成。XML森林的形式化表示如下:
forest ::=ε| tree forest
tree ::= tag
其中,forest代表XML森林,tree代表XML树,tag代表XML标签,∑代表输入字母表,是所有XML标签的集合,ε表示空序列。
1.2 XML查询语言
XPath是用来确定XML文档中节点位置的语言。XPath面向XML数据的树状结构,使用路径表达式寻找节点或节点集。
本文支持的XPath子集语法如下:
path ::= step | step path
step ::= axis::test preds
preds ::= nil | [step] preds
axis ::= child | descendant-or-self
test ::= tag
其中path代表查询路径,step代表查询步,preds代表查询谓词,axis代表轴类型,test代表节点测试,tag代表标签。可以看出,一个XPath查询路径可以包含一个或多个查询步,每个查询步包含三个部分:轴类型、节点测试和查询谓词。
2 基于GRAT的XPath查询原理
一个XPath查询请求中包含了查询步和谓词等多个子查询。多个子查询可能是针对同一个XML片段的查询。但是流数据处理的特殊性要求查询处理不能保存所有这些XML子元素,导致这些子查询必须同时进行。每当XML流数据元素到达时,将有一组子查询进行处理,处理中将产生新的子查询;与此同时也有一组子查询在等待后续XML元素的到来。
通过对XML流数据和XPath查询特征的分析,笔者发现XPath查询过程的每个时刻,后续查询任务的关系可以表示为图的结构。针对每个XML元素的处理,查询可以表示为图的变换,并且这种变换可以表示为一组图的归约操作,从而形成一种高效的查询自动机:图归约方法转换机(Graph Reduction Approaching Transducer, GRAT)。
2.1 XPath查询任务图
如上所述,图1的2个XML流元素可以用2个XML树来表示。为了描述方便,本文扩展了一个虚根元素rt作为这些流数据元素的根,为了便于区分元素,元素添加了序号。
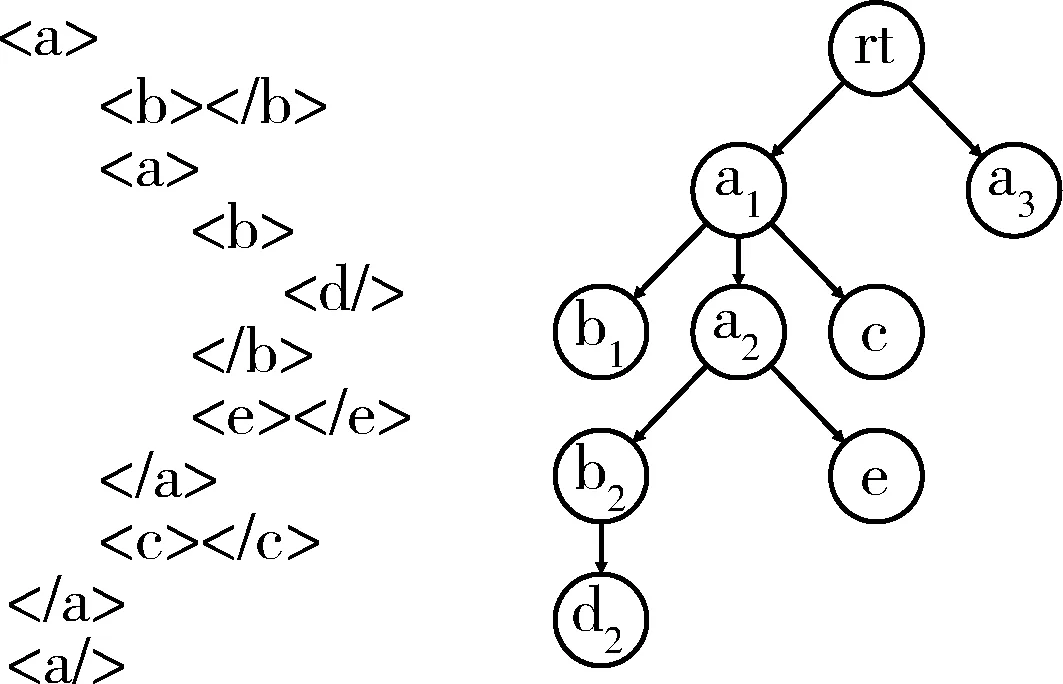
图1 XML流数据元素表示成XML树
本文将查询任务task定义为子查询query和XML森林forest组成的二元组。查询开始时,只有一个针对整个XML流的XPath全路径查询任务。随着节点事件的发生,查询任务转换和新生成多个查询任务。GRAT将这些任务看作任务节点,按照XPath的路径查询规则连接起来,就形成了XPath的查询任务图。例如,针对图1所示的XML流数据的XPath查询//A[//B[/C]][//D]//E的处理过程中,查询任务图初始只有一个任务节点:
t0= ( //A[//B[/C]][//D]//E, {a1,a3… } )
随后,按照标签的到达顺序,也就是深度优先的顺序依次进行处理,当处理完节点b1,准备处理节点a2时,针对其子孙节点、后续兄弟以及其他未处理的树节点也需要进行一系列的查询。此时,由于节点a1已经被处理,说明XPath已经识别了//A的信息,还需要针对子孙节点进行[//B[/C]]、[//D]和//E等的查询;同时,鉴于AD轴“//”的存在,后续查询还要针对a1的后续兄弟节点和其余子孙节点进行展开。这些查询可以表示为一个查询任务图,如图2所示,其中每个查询任务包含了一个XML节点序列及其子查询,t1,t2…tn记作查询任务节点。

图2 a2节点到来时的查询任务图
2.2 查询任务图的归约
当一个标签到来时,如果有某个查询满足这个标签,GRAT按照对应的XPath子查询进行图归约转换。根据不同的归约规则,就可以转换成不同的图,这个归约的过程称为图归约。一个XPath查询匹配标签之后,根据规则,任务图生成新的子查询任务图,这些节点可能包含多个谓词查询任务和至多一个路径选择查询,此时原来的查询任务图需要组合新的查询任务节点,与之前未匹配的查询结合。例如上述例子中,XPath在a2匹配结束后,会在下一个事件遇到标签。这时t1的查询与a2匹配成功,需要进行图归约操作,得到3个新的子查询,要用来匹配a2的子孙b2、e。图3展示了匹配a2结束之后的归约结果。
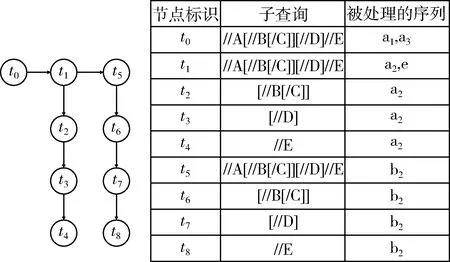
图3 查询a2结束后的查询任务图
在图归约过程中,XPath查询被逐步分解成各个子查询,处于叶节点的子查询处理完成后,GRAT将根据各个谓词查询的结果进行筛选,得到最终正确的查询结果。
3 基于GRAT的XML流数据查询
基于GRAT的XML流数据查询由以下几步组成:
(1)将XPath查询请求翻译为一种查询树;查询任务图最开始只有一个节点(入口),就是查询树的根节点。
(2)按照依次输入的XML标签,针对入口节点使用GRAT规则进行归约操作,完成节点规定的任务,产生新的入口节点。
这些查询树节点与GRAT规则组成了一个查询自动机。
3.1 GRAT翻译规则
从XPath查询到查询树的翻译分为三种:查询路径选择的规则F1(path→N)、谓词组的翻译规则F2(preds→N)、单个谓词的翻译规则F3(step→N)。
每个XPath查询根据这些规则转换成一棵二叉树。以下是详细的翻译规则:
其中,node代表GRAT的查询任务节点,q代表生成的查询树的入口,nil代表无规则。每个node包含3个属性:查询树的入口即q,节点测试成功规则,和节点测试失败规则。根据以上规则,针对查询//A[//B[/C]][//D]//E,GRAT翻译成如图4的查询树,其中每个节点对应查询标记q及其对应的标签。
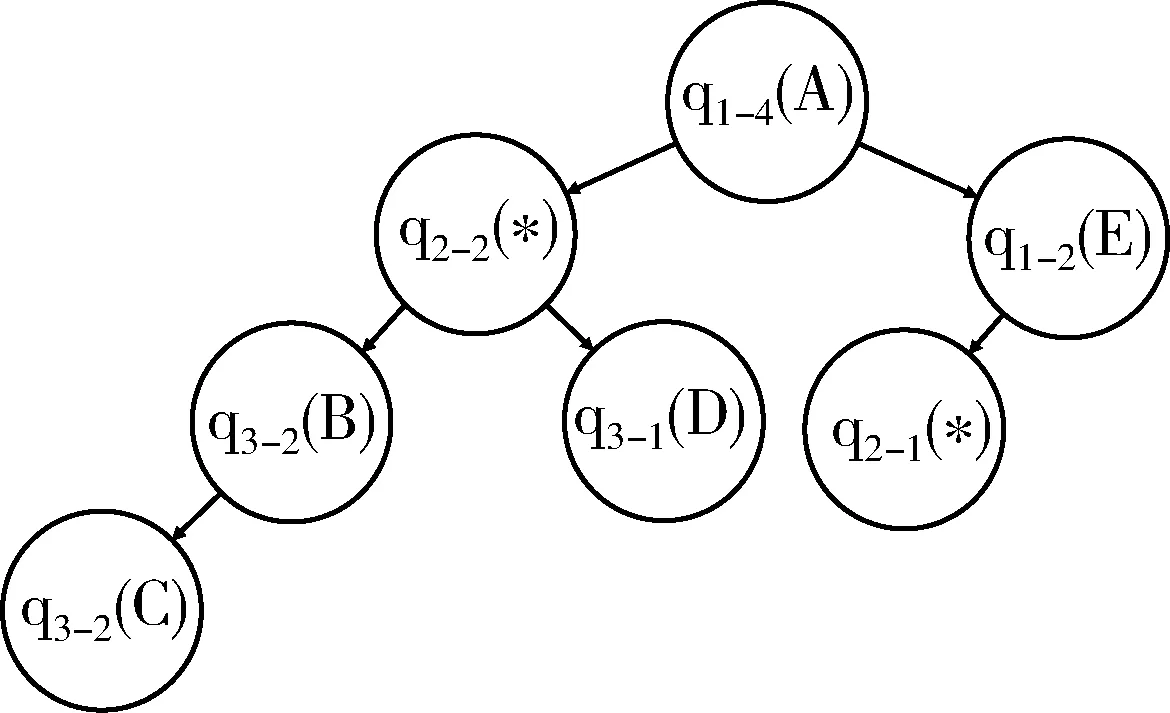
图4 //A[//B[/C]][//D]/E查询树节点
3.2 查询任务图的归约规则
定义2:查询任务图是一个三元组有向无环图Dag=(N,I,H),其中:
(1)N=Q+{skip, output, end},是任务集合,Q是子查询集合;
(2)I∈N,是入口列表;
(3)H:H→H是任务之间有向弧的集合。
定义中skip任务用来跳过无需匹配的XML元素;end任务用于结束匹配;output任务用来暂存未筛选的结果。
GRAT的图归约规则分为两大部分:需要根据标签事件进行归约的规则和不需要标签事件进行归约的规则。查询任务图的初始形态只有一个节点,表示XPath全路径查询。例如//A[//B[/C]][//D]//E的查询的初始状态只有一个包含了q1-4的任务节点;大部分查询任务图的归约是按照XML流数据标签开始、结束和内容作为事件驱动进行处理执行的。当触发事件时,GRAT会匹配入口列表I中的每一个节点。如果GRAT查找到对应的标签信息,就会按照规则将这个节点缓存到output任务中,并且只有当触发了对应标签的结束事件后,结果才会根据谓词的筛选规则决定是否满足查询请求而输出;如果流数据标签和I中的节点不匹配,GRAT会包裹成skip任务,直到触发对应标签的结束事件。GRAT保留这些节点为后续任务服务,但skip任务不处理对应标签的结束事件以外的事件;一部分查询任务图的归约规则是不需要任何事件触发的,当出现当前任务会立即归约成新的任务图。
图5和图6给出了输入tag标签和输入其他标签的完整的GRAT图归约规则。其中,空心箭头所指的节点是I列表中的节点;out代表output任务;q代表当前图节点对应的查询树节点,规则中给出了输入标签匹配目标状态和不匹配目标状态这两种情况的图归约规则;q′和q″分别是树节点q的谓词查询和路径选择查询;y1和y2分别表示当前查询结束后需要查询的任务,若没有后续任务,则y1为空。

图5 有条件的GRAT归约规则
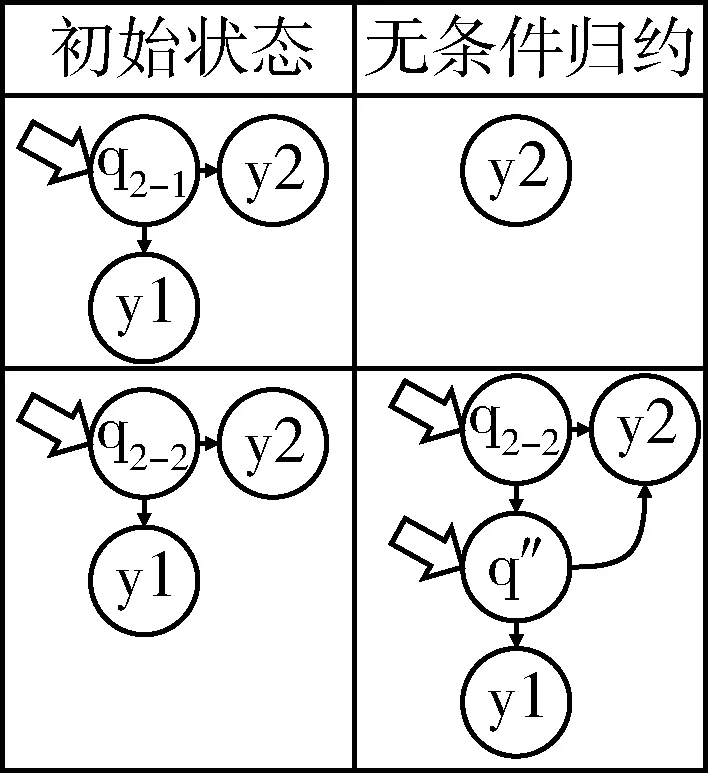
图6 无条件的GRAT归约规则
当XML流数据触发开始标签时根据以上规则进行归约;当触发结束标签时,普通的入口任务节点会指向右侧连接的节点。skip任务会检查是否是右侧节点对应的结束标签,若不是,则不需要更改状态;否则,和其他任务一样,入口指向右侧连接的节点。
无条件归约的节点不会长时间存在于任务图中,每当发现这些不需要事件触发的任务,立即执行规则归约成新的任务图,直到不出现任何无条件归约的任务节点为止。例如,图4查询树上q2-2和q1-2是q1-4的子节点。如果输入标签是目标状态,则GRAT会生成q2-2、q1-2和q1-4这3个节点,按照以上规则连接起来之后发现存在无条件归约的节点,那么立即根据规则进行再次归约。
3.3 GRAT定义
定义3:一个GRAT查询自动机被定义为一个四元组M=(Q,R,T,q0),其中:
(1)Q是自动机所有的状态集合,也就是所有查询任务的集合;
(2)T是XML节点开始标记和结束标记的集合;
(3)R是归约规则的集合,一个查询任务有向无环图Dag:Dag×T→Dag;
(4)q0∈Q,是起始状态,是由XPath查询请求和查询树的根节点组成的查询任务。
综上,查询通过翻译规则得到查询树;由树根和给定的XPath组成的查询任务,作为唯一的节点,形成了任务图;然后GRAT按照XML数据流标签和当前任务,对任务图进行归约,参照查询树建立子查询的任务,形成另一个任务图;据此,每一个标签事件的到来反复归约这个任务图,通过skip任务跳过无关的元素,通过output任务来缓存或输出查询结果。
4 GRAT自动机的实现算法和实验结果
4.1 实现算法
GRAT的实现算法包括开始标签算法和关闭标签算法。算法的参数包括查询任务节点node,输入标签tag,当前标签层数layer以及当前节点对应的规则集rule。算法处理的是上一状态的入口节点列表QL,返回的结果是入口节点列表QLNEW。
算法迭代处理入口列表。首先通过第3行RuleF方法进行GRAT查询任务图的归约,RuleF和RuleFUncon分别是图5和图6的具体实现;每个已经归约之后的新入口节点进行下一步的处理:判断这些节点中是否存在q2-1或q2-2这类不需要条件进行归约的节点,如果存在,使用RuleFUncon方法对节点再次归约。这个归约过程是一个递归的过程,会检查所有的节点直到没有无条件归约的节点为止。之后将这些节点列表合并到结果队列QLNEW中;最后,返回新的节点列表,为下一个标签到来做准备。
对于处理结束标签的过程中,需要在处理之前判断node节点是否是output缓存结果任务,如果是,则需要输出结果。
由于文献[17]所述的XML流数据查询结果要优于其他的一些查询方法,因此本文选择GRAT与文献[17]的方法进行对比。
4.2 实验方案
GRAT使用Java和Scala语言实现了GRAT自动机和面向XPath的流数据查询。测试环境为一台HP Z400台式工作站,配置4核CPU、4G内存、64位Windows 10操作系统,运行环境为 Java(JRE)版本1.8。
测试使用了真实的数据集DBLP和Tree Bank,以及比较数据集XMark,如表1所示。其中,测试使用了不同大小的6组XMark数据集,如表2所示。

表1 3个XML基准数据集

表2 不同大小的XMark数据集(XMark Benchmark 集合)
测试使用的查询如表3,分为5组,其中,Q1.1~Q1.3是DBLP上的查询,Q2.1~Q2.3 是Tree Bank上的查询,Q3.1~Q5.3是XMark上的查询;Q3.1~Q3.3包含AD关系而不包含谓词,Q4.1~Q4.3包含带有PC轴的谓词,Q5.1~Q5.3包含嵌套谓词和并列谓词。

表3 测试使用的XPath查询(XPath 测试集)
4.3 实验结果
图7反映了表3中各个测试用例在表2中编号为6的XMark 测试用例上的执行时间。其中Q3.1、Q3.2、Q3.3的用例不包含谓词,Q4.1和Q4.2包含一个PC关系的谓词,Q4.3包含多个谓词。测试用例Q5.1、Q5.2和Q5.3包含多个复杂谓词,因此所需的时间也最多。

图7 不同查询在XMark数据集上的表现
图8反映了表3中Q1、Q2和Q3这三组查询在表2中不同的XMark测试用例上对Q1.1、Q2.1、Q3.1的平均运行时间。可以得出Q1、Q2、Q3在路径选择平均步数相同时,谓词的数量越多,查询越快。

图8 查询不同大小的XMark上的表现
图9反映了GRAT算法在不同数据集上运行时间,图10展示了GRAT算法和文献[17]的对比实验结果。该实验采用表2中编号为6的测试数据。如图10所示,存在简单谓词的情况下GRAT的查询效果更好。
根据以上测试结果,可以得出GRAT算法的吞吐量,通过数据量与运行时间的比值,得出最高吞吐量达到1 073 MB/s,平均为876 MB/s。也得出,数据量越多,吞吐量越趋于稳定。
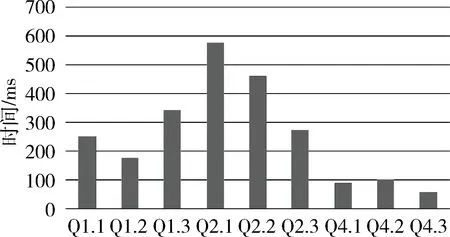
图9 查询在不同数据集上的运行时间
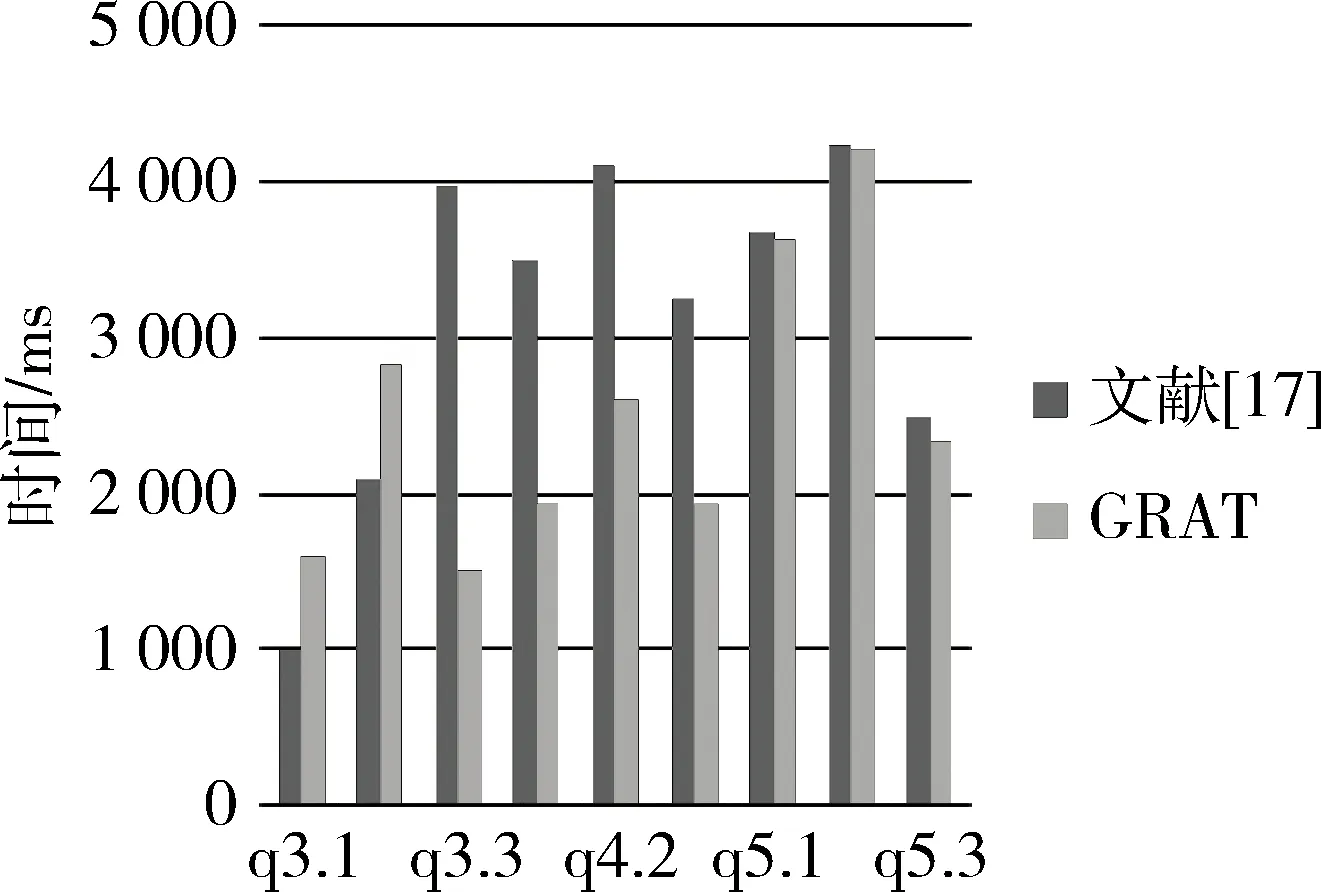
图10 GRAT与文献[17]对比结果
5 结论
本文提出了一种基于图归约的XPath高性能流数据查询的方法。该方法支持在流数据上的多层多谓词的嵌套查找。通过图的数据结构使得该方法保证了查询的灵活性,又由于该方法产生的状态图以及图的归约步骤都是在系统内存中运行的,因此保证了数据的高效性。通过以上介绍本文所使用的GRAT算法和测试的结果,可以得出基于GRAT的XPath查询满足高性能和嵌套查询。下一步工作是将此查询方法应用到分布式系统中以及改善XPath的复杂查询[23]。
[1] NISHIZAWA I, IMAKI T. Stream data processing system and stream data processing method[P]. US, US7644110. 2010.
[2] 路瑶, 廖湖声, 苏航, 等. 面向XML流数据的树模式匹配方法[J]. 软件工程与应用, 2016, 5(2): 103-113.
[3] DAMIGOS M, GERGATSOULIS M, KALOGEROS E. Distributed evaluation of XPath queries over large integrated XML data[C]. Panhellenic Conference on Informatics, 2014:1-6.
[4] ENK A, VALENTA M, BENN W. Distributed evaluation of XPath axes queries over large XML documents stored in MapReduce clusters[C]. International Workshop on Database and Expert Systems Applications, 2014:253-257.
[5] MULLANGI P R, PENEMATSA G, RAMASWAMY L. Scalable XPath evaluation on large-scale continuously evolving XML repositories[C]. International Congress on Big Data. IEEE, 2014:546-553.
[6] BELYAEV K, RAY I. Towards efficient dissemination and filtering of XML data streams[C]. International Conference on Dependable, Autonomic and Secure Computing. IEEE, 2015:1870-1877.
[7] KIM S H, LEE Y J, LEE J J. Matrix-based XML stream processing using a GPU[C]. International Congress on Big Data. IEEE, 2015:694-697.
[8] 张鹏, 李鹏霄, 任彦,等. 面向大数据的分布式流处理技术综述[J]. 计算机研究与发展, 2014(S2):1-9.
[9] BARROS E G. Parallelizing multiple keyword queries over XML streams[C]. International Conference on Data Engineering Workshops. IEEE, 2016:169-172.
[10] OLTEANU D. SPEX: streamed and progressive evaluation of XPath[J]. Transactions on Knowledge and Data Engineering. IEEE, 2007, 19(7):934-949.
[11] CONG G, FAN W, KEMENTSIETSIDIS A, et al. Partial evaluation for distributed XPath query processing and beyond[J]. ACM Transactions on Database Systems, 2012, 37(4):2498-2501.
[12] DAI L, LUNG C H, MAJUMDAR S. BFilter-a XML message filtering and matching approach in publish/subscribe systems[C]. Global Telecommunications Conference.IEEE,2010:1-6.
[13] SAXENA P, KAMAL R. System architecture and effect of depth of query on XML document filtering using PFilter[C]. Sixth International Conference on Contemporary Computing, 2013:192-195.
[14] HSU W C, LI C F, LIAO I E. EFilter: An efficient filter for supporting twig query patterns in XML streams[C]. International Conference on E-Business. IEEE, 2013:1-8.
[15] CHOI H, LEE K H, KIM S H, et al. HadoopXML: a suite for parallel processing of massive XML data with multiple twig pattern queries[C]. Conference on Information and Knowledge Management, 2012:2737-2739.
[16] HAKUTA S, MANETH S, NAKANO K, et al. XQuery streaming by forest transducers[C]. International Conference on Data Engineering. IEEE, 2014:952-963.
[17] FENG X, LIAO H, SU H. Construction of macro forest transducers from XPath[J]. Transactions on Computer Science and Technology. IEEE, 2015, 4(3):50-58.
[18] BOU S, AMAGASA T, KITAGAWA H. Filtering XML streams by XPath and keywords[C]. Iiwas′14 Proceedings of the International Conference on Information Integration and Web-Based Applications and Services, 2014:410-419.
[19] ALRAMMAL M, HAINS G. Forward XPath stream processing: end-to-end confidentiality and scalability[C]. International Conference on Innovations in Information Technology, 2014:24-29.
[20] 陈冲, 蒋夏军. 一种支持通配符查询的XML模式匹配算法[J]. 计算机与现代化, 2016(4):65-73.
[21] 李文珠, 廖湖声, 苏航. 基于下推转换机的XML流数据处理方法[J]. 计算机工程与应用, 2016, 52(8):49-55.
[22] PERST T, SEIDL H. Macro forest transducers[J]. Information Processing Letters, 2004, 89(3):141-149.
[23] 郭金磊, 张玉生, 胡爱兰. 基于NIO的高速数据传输技术的实现[J]. 微型机与应用, 2016, 35(13):19-20.
A high-performance XPath query streaming approach by graph reduction
Tao Jie, Liao Husheng, Gao Hongyu
(Faculty of Information Technology, Beijing University of Technology, Beijing 100124, China)
As a standard of network data exchanging and sharing, XML data is increasingly used to represent streaming data of an application system. However, it is a challenging task that implements efficiently the querying approach for limited by various features such as cost of space while handling the streaming data. Distinguished from the traditional approach which based on transducers or level stacks, this paper put forward an approach of querying XML based on graph reduction, which is called Graph Reduction Approach Transducers (GRAT). It uses a graph structure to represent the relationship between the sub query tasks for different XML stream elements, and the XPath query is implemented by the reduction of the graph. The experimental results show that this algorithm is able to accomplish complex querying XML with high-performance, and the throughput has been reached a higher level.
XML; graph reduction; streaming data
北京市自然科学基金项目(4122011) ;国家自然科学基金青年基金项目(61202074)
TP31
A
10.19358/j.issn.1674- 7720.2017.15.005
陶杰,廖湖声,高红雨.一种基于图归约的XPath高性能流数据查询方法[J].微型机与应用,2017,36(15):16-21.
2017-03-21)
陶杰(1990-),通信作者,男,硕士研究生,主要研究方向:流数据查询技术。E-mail:315090132@qq.com。
廖湖声(1954-),男,硕士,教授,主要研究方向:软件自动化方法、数据集成技术等。
高红雨(1968-),男,硕士,副教授,主要研究方向:软件自动化、编译技术与程序理论等。
