基于动态卷积概率矩阵分解的潜在群组推荐
2017-08-31王海艳董茂伟
王海艳 董茂伟
1(南京邮电大学计算机学院 南京 210023) 2(江苏省无线传感网高技术研究重点实验室 南京 210003) 3 (江苏省大数据安全与智能处理重点实验室 南京 210023) (wanghy@njupt.edu.cn)
基于动态卷积概率矩阵分解的潜在群组推荐
王海艳1,2,3董茂伟1
1(南京邮电大学计算机学院 南京 210023)2(江苏省无线传感网高技术研究重点实验室 南京 210003)3(江苏省大数据安全与智能处理重点实验室 南京 210023) (wanghy@njupt.edu.cn)
近年来,群组推荐由于其良好的实用价值得到了广泛关注.然而,已有的群组推荐方法大多都是根据分析用户对服务的评分矩阵直接将个体用户的推荐结果或个体用户偏好进行聚合,没有综合地考虑用户-群组-服务这三者间的联系,导致群组推荐效果欠佳.受潜在因子模型与状态空间模型启发,结合评分矩阵、服务描述文档以及时间因素,共同分析用户-群组-服务间的联系,提出了一种基于动态卷积概率矩阵分解的群组推荐方法.该方法首先利用基于卷积神经网络的文本表示方法获取服务潜在特征模型的先验分布;然后,将状态空间模型与概率矩阵分解模型相结合,获得用户潜在偏好向量与服务特征向量;之后,对用户偏好向量运用聚类算法来发现潜在的群组;最终,对群组中的用户偏好采取均值策略融合成群组偏好向量,并与服务特征向量共同生成群组对服务的评分,实现群组推荐.通过在MovieLens数据集上与同类方法进行对比实验,发现所提方法的推荐有效性与精确性上更具有优势.
卷积神经网络;概率矩阵分解;状态空间模型;聚类算法;群组推荐
随着科学、技术和工程的迅猛发展,近20年来,在诸多领域(如交通旅游、健康医护、互联网和电子商务)都存在海量数据,“信息爆炸”现象日益严峻.据统计:2016年全球Wechat月活跃用户数量已突破8亿,2017年最新公布的天猫“双十一购物狂欢节”产生2.78亿个订单.如何确保用户在海量信息中快速获取所需服务,有效解决“信息过载”问题成为了计算机学术界与产业界的一个热点研究问题.个性化推荐系统作为主动为用户推送信息的一类解决方案,是目前缓解这一问题较为成功的工具之一.
然而,传统的服务推荐系统(如基于协同过滤技术的推荐系统)普遍侧重于向单个用户进行推荐,但在现实生活的许多场景中,用户是以群组形式出现的,例如出行旅游、网上团购、饭店点餐等[1].此外,在一些特殊的应用场景如移动IPTV推送服务,由于带宽等各种各校因素的限制,需要通过临时生成随机群组,降低通讯开销,才能更加有效地实现服务推荐的功能[2].面向群组的推荐研究受到越来越多的关注[3].现有的群组推荐方法大多都是根据用户对服务的评分信息简单地将个体用户的推荐结果或个体用户偏好进行聚合,从而实现群组推荐,较少关注到时间因素对推荐结果的影响.这类方法在实际应用中是不合理的,因为用户的偏好程度很有可能随时间推移发生改变;此外,尽管服务的一些描述信息并不能直接揭示用户、群组、服务间的潜在联系,但这些附属信息对于充分挖掘三者间的关系,提升推荐结果的准确度有很大帮助,而这类附属信息却很少在群组推荐中被关注.
针对上述问题,我们结合服务描述文档、用户配置文件以及时间因素,深入挖掘用户-群组-服务三者间的潜在联系,提出一种融合卷积神经网络的动态概率矩阵分解模型(dynamic probabilistic matrix factorization model integrated with convolutional neural network, DPMFM-CNN),并将DPMFM-CNN融合到群组推荐框架,提出了潜在群组推荐方法(latent group recommendation, LGR),主要工作有:
1) 将卷积神经网络(convolutional neural network, CNN)的文本表示方法融合到潜在因子模型中,提出基于CNN的服务特征模型,使得服务描述文档可以约束服务特征模型的生成.
2) 将状态空间模型融合到潜在因子模型中,提出基于状态空间模型的动态概率矩阵分解模型(dynamic probabilistic matrix factorization model, DPMFM),以此发现用户与服务的潜在关系.
3) 运用多种聚类算法来发现用户偏好空间中的潜在群组,结合均值策略对群组偏好进行融合,根据群组偏好来预测群组对服务的评分,提出一种潜在群组推荐方法LGR,实现群组推荐.
4) 在MovieLens1M数据集上对所提出的方法进行测试,并与现有的群组推荐方法进行对比,验证我们方法的有效性与精确性,同时,我们分析了影响LGR群组推荐性能的重要参数.
1 相关工作
本节将介绍群组推荐相关的研究成果,以及基于卷积神经网络的文本表示方法.
1.1群组推荐
群组推荐研究是建立在个性化推荐系统基础上的,它们将个性化推荐方法获得的输出,采用一定的群组模型融合为群组推荐结果.根据融合对象的不同,群组推荐方法一般分为2类:1)基于个体推荐模型的融合;2)基于个体推荐结果的融合.前者先将组内用户的偏好聚合为群组偏好,再向用户推荐偏好服务;后者先获取群组每个个体用户个性化服务列表,再将推荐列表进行聚合后推送给组内用户.Baltrunas等人[4]将个体用户的推荐列表聚合成群组推荐列表,指出当个体推荐效果不佳时,群组推荐列表更加有效,此外,组内用户偏好越接近,群组推荐效果越好.Boratto等人[5]通过用户-项目评分矩阵建立用户相关性网络,用特定的聚类算法将相似用户聚类为群组,然后采用均值策略融合用户偏好为群组偏好,从而进行群组推荐.Feng等人[2]结合概率主题模型,更加综合地去分析项目特征与用户偏好,运用重启随机游走算法分析用户与群组的关系,采用一定的策略将组内用户偏好融合成群组偏好,进行群组推荐.Boratto等人[6]提出了一种解决群组发现过程中因聚类数据稀疏的而导致维度灾难的群组推荐方法Predict&Cluster,该方法通过传统的协同过滤方法预测用户的评分矩阵的缺失项,对预测补全后的评分矩阵采用K-means方法进行聚类得到潜在群组,并将群组内所有用户评分采用均值策略融合为群组对项目的评分.Zeng等人[7]基于矩阵因子模型,提出了并行化的潜在群组模型PLGM,该方法运用矩阵分解方法获取用户的潜在因素偏好,通过K-means算法将邻近用户聚合为群组,采取均值策略将用户偏好聚合为群体偏好,通过拟合群组对服务评分进行群组推荐.
1.2基于卷积神经网络的文本表示
卷积神经网络[8](CNN)是前馈神经网络的一种,除了输入层与输出层,其所包括的基本结构有2种:卷积层进行特征提取;池化层进行特征映射.两者按照先卷积再池化的成对顺序出现.它早期被用来进行模式分类,在计算机视觉邻域得到了广泛的应用.
近年来,得益于词向量工作的成果[9-10],一些学者将CNN灵活地运用到了自然语言处理.Shen等人[11]提出了一种基于CNN的语义表示的信息检索方法,将需要查询的目标语句与文档表示为向量,经过该方法处理后的语句将被表示成一个向量,拥有相似语义的向量在向量空间中位置相近,以此对用户的查询语句做出快速的反馈.He等人[12]提出了一种基于CNN的多角度句子语义相似度建模的方法,该方法使用词向量将句子表示成矩阵作为输入,卷积后采用不同的池化方法进行池化,以此达到多角度获取句子特征,将句子表示为向量后进行相似度比较.Kim等人[13]在word2vec[9]的工作基础上,提出了一种基于单隐层CNN的句子分类方法,并且该方法使用多通道的思想,设置多组不同卷积窗口,灵活地获取句子多种上下文特征,将文本表示成向量之后再进行分类.
我们将对Kim等人的工作进行改进,使其可以融合到群组推荐系统中去,帮助提高推荐的精确度.
2 基于DPMFM-CNN的潜在群组推荐方法LGR
本节首先基于CNN的文本表示方法、状态空间模型与概率矩阵分解模型,提出动态卷积概率矩阵分解模型(DPMFM-CNN);然后提出一种基于DPMFM-CNN的潜在群组推荐方法(LGR).
2.1动态卷积概率矩阵分解模型
动态卷积概率矩阵分解模型(DPMFM-CNN)的生成模型的图模型如图1所示,其中,Ut为用户偏好矩阵,V为服务特征矩阵,Rt为评分矩阵,θ为服务文档特征矩阵,W为CNN的模型参数,X为服务描述文档集.首先,我们给出CNN服务特征模型怎样将服务描述文档表示服务特征向量(右侧部分)的方法,然后给出CNN服务特征模型结合DPMFM模型(左侧部分)生成的DPMFM-CNN模型,最后给出DPMFM-CNN模型的参数学习方法.
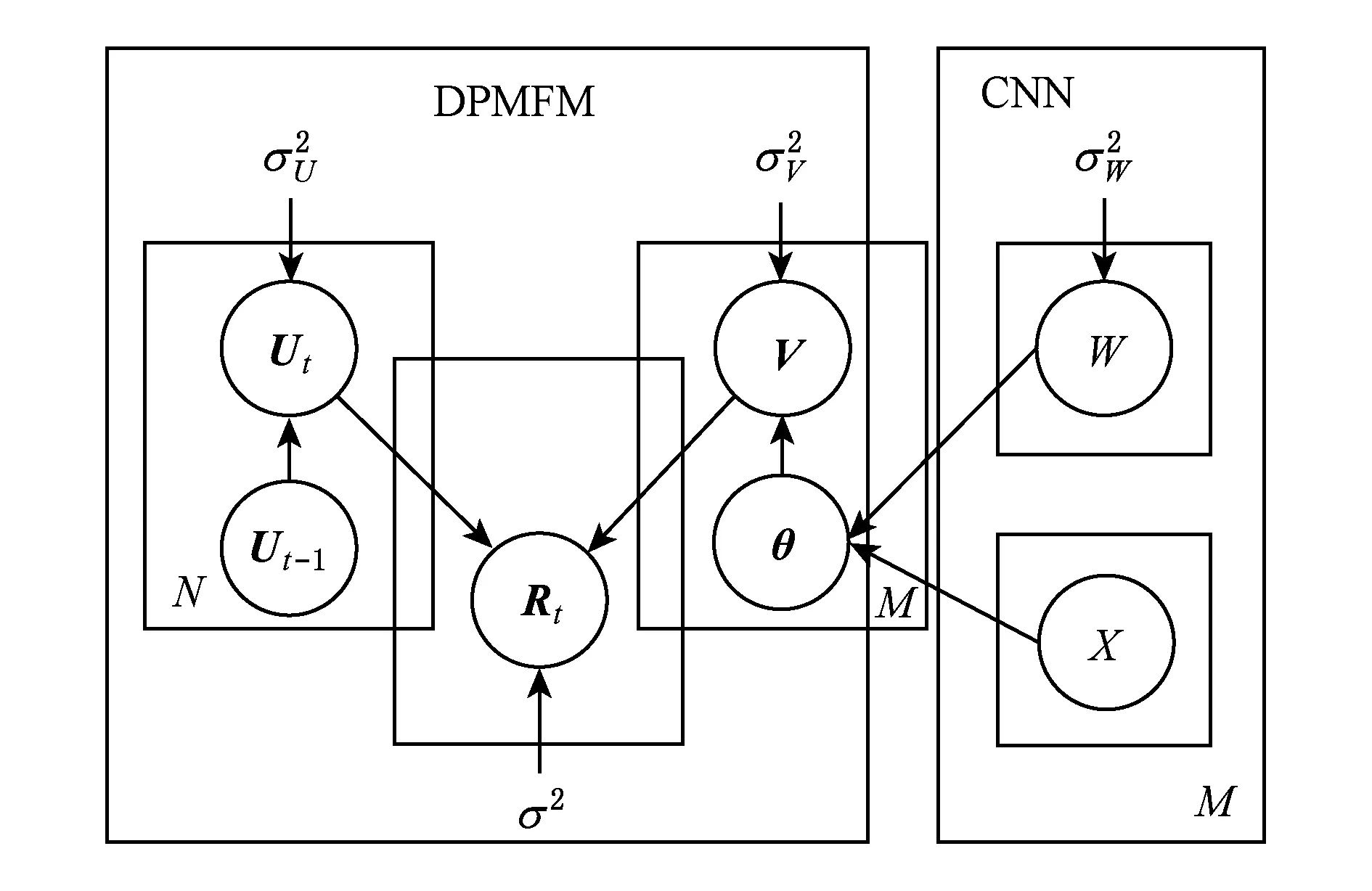
Fig. 1 DPMFM-CNN model图1 DPMFM-CNN模型
2.1.1 CNN服务特征模型
CNN服务特征模型的作用与CTR[14]中服务特征模型类似,结合Kim等人[13]的句子分类方法将服务描述文档表示为服务特征分布向量,并作为DPMFM-CNN中服务特征元素生成的条件概率,提高整个预测模型的精度.CNN服务特征模型如图2所示,整个CNN服务特征模型总共4层:Embedding层、卷积层、池化层和输出层.
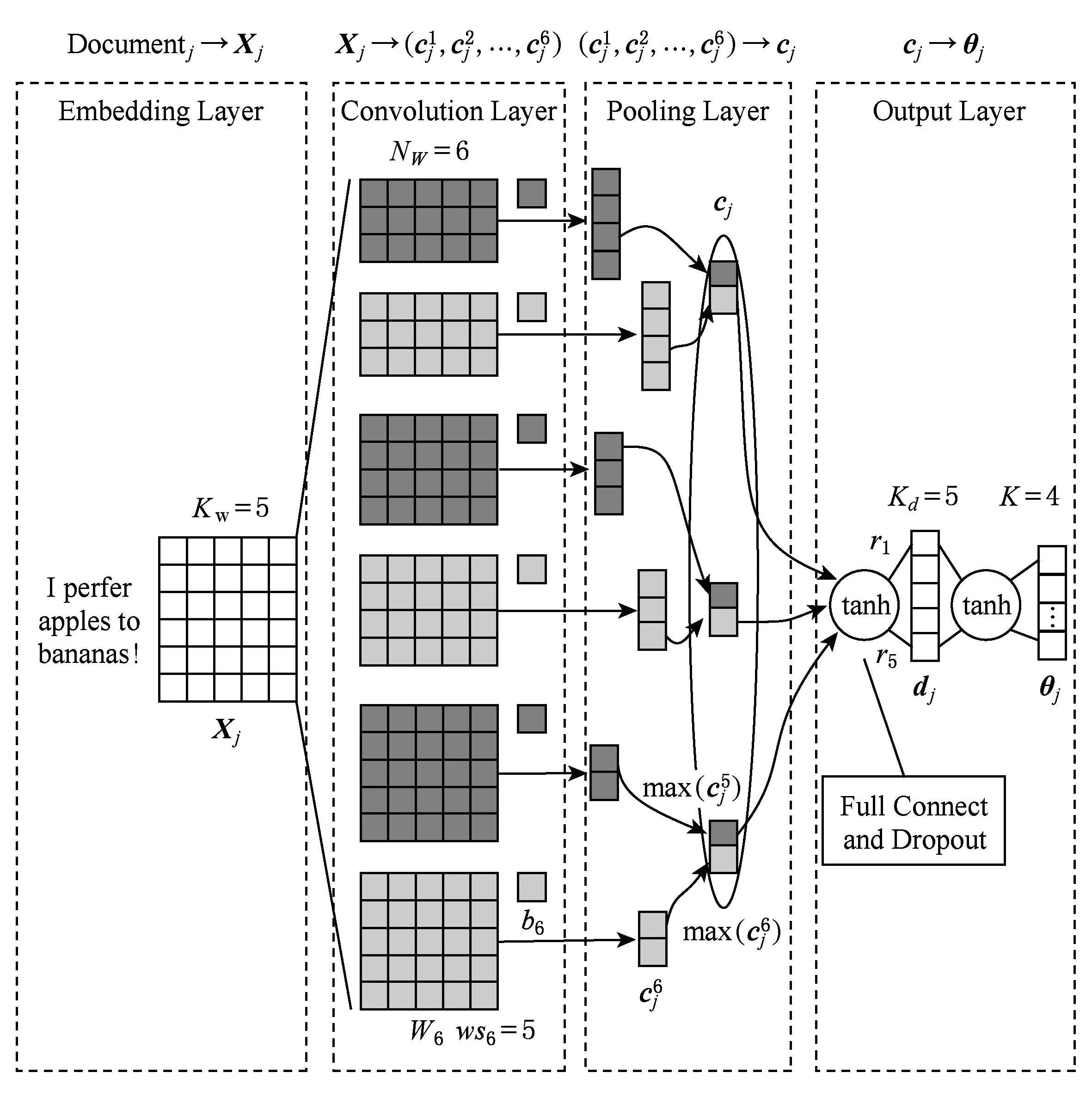
Fig. 2 CNN service feature model图2 CNN服务特征模型
1) Embedding层
Embedding层的任务是将服务描述文档转换为一个由词向量组成的服务描述文档矩阵.第j个服务描述文档可以看做是由nj个词组成的句子,词向量可以对服务描述语料库使用word2vec[9]或glove[10]等工具训练随机初始化的词向量获得,也可以使用它们预先训练好的词向量表进行查表获取,未出现在表中的词向量先随机初始化,然后进行训练获得.经过Embedding层的处理,文档就可以用带顺序的单词向量构成的矩阵表示为
(1)
其中,j∈[1,M],nj为第j个服务描述文档的总词数,wi∈K×1,Kw是词量化维数.
2) 卷积层
卷积层的任务是提取出服务描述矩阵的上下文特征.我们采用[13]中的卷积架构对Xj进行文档的上下文特征提取.假设第l个卷积窗口大小为wsl,意味着每一个上下文特征由连续的wsl个词中提取,提取通过过滤这个窗口的权值矩阵Wl∈ws×K与其偏置项bl∈卷积进行.提取的卷积映射属性值是通过卷积窗口对Xj在第i步时窗口内的内容K×ws进行卷积提取出的,i∈[1,nj-wsl+1],其生成过程如下:
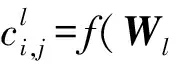
(2)
其中,⊗为卷积操作符,f是一个非线性激活函数,常用的有sigmoid,tanh以及ReLU,我们使用ReLU,相比于其他函数,它可以避免梯度缺失导致收敛速度过慢或者局部最值问题.
这样由文档矩阵Xj经过第l个卷积窗口提取出的全部卷积映射属性值构成的卷积映射属性向量可以表示为
(3)
然而,一个卷积窗口中的权值矩阵Wl与其偏置项bl只能提取一种形式的卷积映射属性向量,采用文献[13]中的多通道方法,设置多组不同的卷积窗口,这里的不同包括窗口大小wsl或者权值矩阵Wl与其偏置项bl.这样就可以提取不同形式的卷积映射属性向量,这里l∈[1,NW],NW为卷积窗口的个数.
3) 池化层
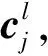
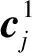
(4)
到这层,第j个服务描述文档可以被表示为维度为NW的服务上下文特征向量cj.
4) 输出层
输出层的任务是将长度为NW的服务上下文特征向量cj映射到K维空间中去.为了防止过拟合,首先为模型添加Dropout层,令dj为Dropout层的输出,则:
dj=tanh(Wdropout·(cj·rdropout)+bdropout),
(5)其中,Wdropout∈K×N为非线性映射矩阵,bdropout∈K×1为偏置向量,Kdropout为Dropout后的向量维度,rdropout∈丢弃控制向量,rdropout中每一个元素rp~Bernoulli(Dropoutrate),p∈[1,Kdropout].从维度为Kdropout的向量dj映射到维度为K的服务特征向量θj,常用的方法是进行非线性映射,整个映射过程如下:
θj=tanh(Wθ·dj+bθ),
(6)
其中,Wθ∈K×K是映射矩阵,bθ∈K×1是它的偏置向量.
CNN服务特征模型完成了从服务描述文档Xj到服务特征向量θj的转换,整个θj的生成过程可以看成函数:θj=fCNN(W,Xj).这样θj就可以作为DPMFM-CNN的服务特征向量vj生成的条件概率,转换公式为
vj=θj+ε,
(7)
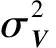

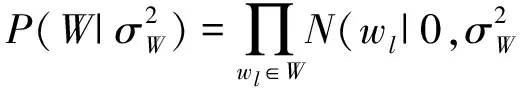
(8)
整个CNN服务特征模型的条件概率为
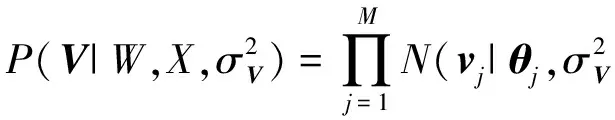
(9)
2.1.2 DPMFM-CNN的生成模型
DPMFM-CNN在除了将CNN服务特征模型融入PMF[15-16],还引入时间信息分析用户偏好,时间信息是学习用户偏好演变的一个重要因素.直接使用物理时间点对用户的偏好进行分析,无论从计算量还是反馈信息数量都不切实际.因此,将时间离散化的工作必不可少,一种直接的方法就是将时间窗口化,窗口的大小可以运用领域知识设定,如周、月、年等,也可以根据用户产生数据量的流量进行自适应.在引入时间窗口后,我们就可以分析用户在不同窗口下的偏好了.
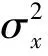
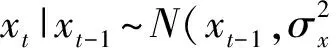
(10)
我们运用高斯时间序列模型作为生成DPMFM模型中用户偏好的动态部分的先验概率.根据式(10),用户i在t时间段的偏好向量的第k个元素uik,t可以这样生成:
(11)
其中,k∈[1,K],K为潜在特征的维数.
对于DPMFM-CNN中用户偏好模型的静态部分,实际上指用户的全局偏好,我们直接采用用户在全部时段的数据来学习全局偏好,工作类似动态部分,唯一不同在于其生成的先验概率为
(12)
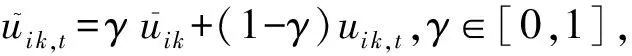
根据上面的工作,用户动态偏好的生成概率模型Ut的条件概率
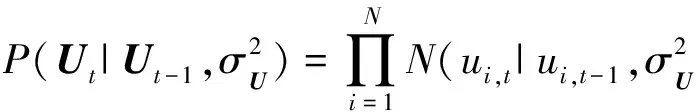
(13)
用户i在时间段t内对服务j的评分的相对期望rij,t可以通过用户动态偏好向量与服务特征向量内积生成,且误差服从均值为0,方差σ2的高斯分布:
(14)
因此整个时间段t内的评分矩阵Rt生成模型的条件概率为
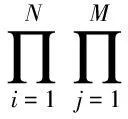
(15)
其中,I为指示矩阵,表示用户与服务是否有评分交互,若Rij>0,Iij=1,否则Iij=0.
2.1.3 参数学习
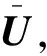
参数学习的过程就是使生成模型可以很好地解释已观察的评分数据的过程,我们使用最大后验(MAP)估计[15]模型中的参数用户动态偏好模型Ut、服务特征模型V,其最大后验概率的对数表达为
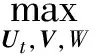
(16)
将式(16)进行处理后会得到一个关于Ut,V,W的函数,并作为损失函数:
(17)
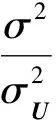
用最优化方法求解,以此获得用户动态偏好模型Ut、服务特征模型V.这里,我们采用SGD[18]方法来增量学习模型参数.因此,当前模型进行训练的每一个样本(i,j,rij,t)相关的损失函数可以简化为
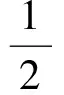
(18)
DPMFM-CNN的用户动态偏好模型Ut,服务特征模型V的参数学习算法步骤是:
1) 初始化λU,λV,η,Itermax,Cendure,Ut←Ut-1,V←θ,W;
2) 输入(i,j,rij,t)∈Rt,X;
3) 更新ui,t与vj:
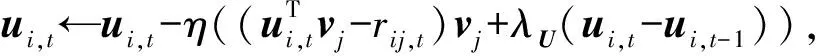
4) 输出Ut∈K×N和V∈K×N.
其中,λU与λV为正则项系数,K为潜在特征维数,η为学习率,Itermax为最大迭代次数,Cendure与C分别为允许的误差回退次数与误差回退次数.
不同于更新用户动态偏好模型Ut与服务特征模型V,W是与CNN模型中每一层相关的参数,包括:每个卷积窗口的权值矩阵Wl与其偏置项bl,以及非线性映射的权值矩阵Wdropout,Wθ与偏置向量bdropout,bθ.这里我们采用反向传播算法训练模型参数,并将
(19)
看作是W的带l2正则项的损失函数,其中,θj=fCNN(W,Xj),j∈[1,M].
2.2基于DPMFM-CNN的潜在群组推荐框架
在2.1节中,我们已经通过DPMFM-CNN模型获取到了用户的动态与静态偏好,与其他基于个体推荐模型融合的群组推荐方法PLGM[7]类似,我们将采用多种聚类算法对DPMFM-CNN的输出的用户偏好向量进行聚类,以此来发现用户集中的潜在群组,结合均值策略进行群组偏好融合,提出一种潜在群组推荐方法(LGR),其结构如图3所示.
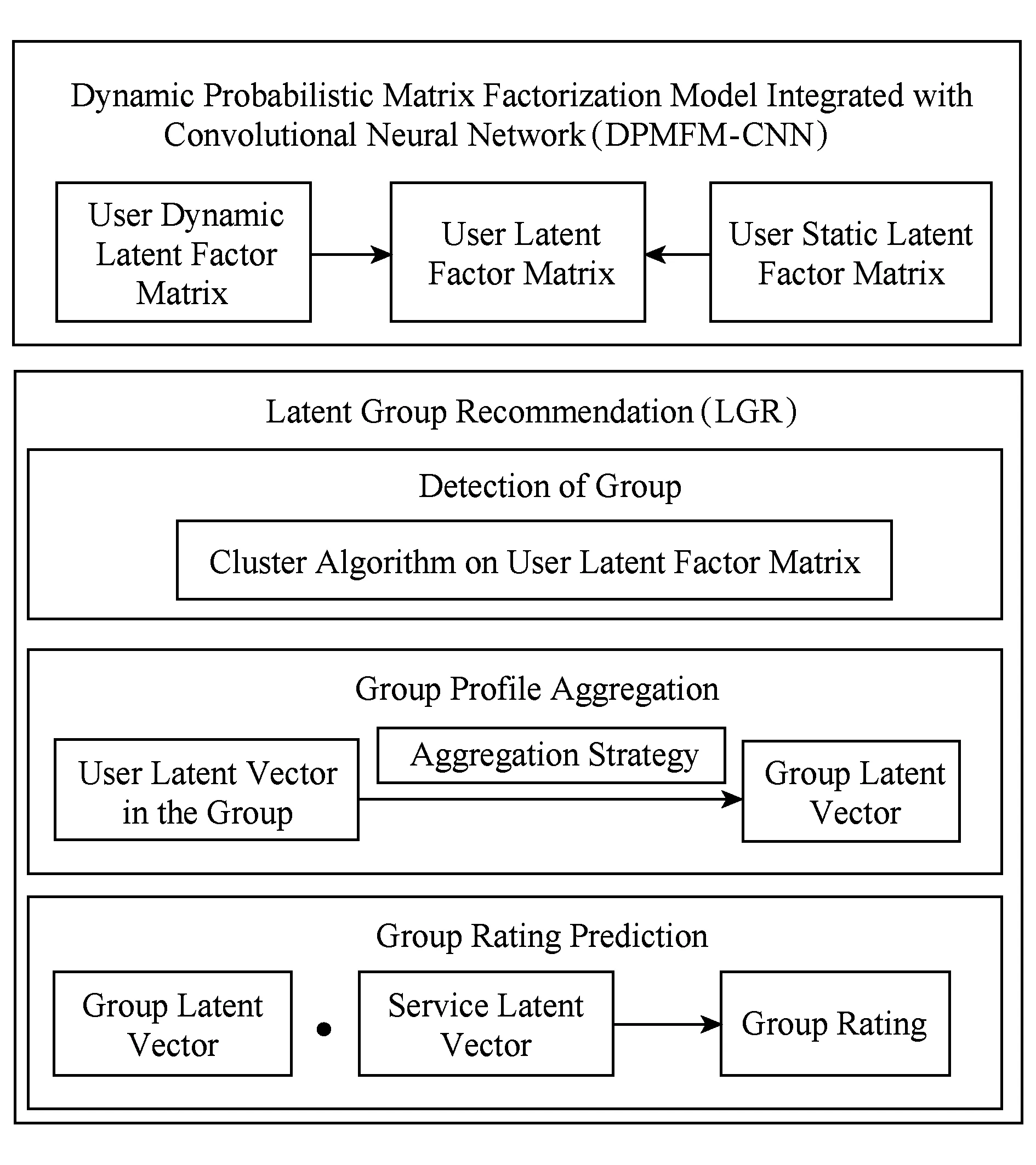
Fig. 3 Structure of latent group recommendation图3 潜在群组推荐结构
整个群组推荐过程主要分为3步,由上到下分别为潜在群组发现、群组偏好融合和群组评分预测.
2.2.1 潜在群组发现
群组可以被认为是对服务有相似特征偏好的用户集合,而从个体用户到群组的过程,我们认为是一个聚类任务.我们将采用4种适合于我们的聚类算法进行潜在群组发现:
1)K-means[19].K-means基本思想是以空间中k个点为中心进行聚类,对最靠近他们的对象归类.通过迭代的方法,逐次更新各聚类中心的值,直至得到最好的聚类结果.
2)K-means++[19].K-means++算法是K-means的演化算法,不同于K-means算法的是,初始中心点不再随机,而是符合一定原则,基本原则是使得各个种子点之间的距离尽可能的大,但是又得排除噪声的影响.
3) Birch[20].Birch算法是层次聚类算法之一,基本思想主要是引入了聚类特征(clustering feature, CF)和聚类特征树(CF Tree),首先通过其他的聚类方法将其聚类成小的簇,然后再在簇间采用CF聚类特征对簇聚类.
4) AffinityPropagation[21].该算法的基本思想是将全部样本看作网络的节点,然后通过网络中各条边的消息传递,计算出各样本的聚类中心.聚类过程中,共有2种消息在各节点间传递,分别是吸引度(responsibility)和归属度(availability).聚类的结果取决于样本间的相似性大小和消息传递.
希望通过不同聚类方法对群组推荐的性能表现的对比,找出最适合于发现用户偏好向量空间中具有内在相似性的用户集合的聚类方法来发现潜在群组.
2.2.2 群组偏好融合
通过发现用户间的内在联系并将用户聚类为群组之后,一个重要的工作就是将群组内用户的偏好融合为群组偏好.均值策略[22]被认为是大规模数据环境下产生群组偏好最精确的融合策略,我们将采用均值策略进行群组偏好
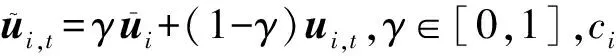
2.2.3 群组评分预测
在获得用户的群组归属后,将群组的偏好向量与服务特征向量进行内积,拟合群组对服务的评分.不同于传统个体用户评分的拟合,这里的群组评分的拟合是群组中具有内在相似性用户的共性偏好与服务特征向量拟合的结果,整个用户对服务的拟合评分为
(21)
3 实验与分析
为了验证LGR的有效性与准确性,我们首先介绍整个实验的实验准备,然后展示实验结果并对其进行分析.
3.1实验准备
本节主要对数据集、实验环境与具体设置、对比方法与评价指标这3个方面进行叙述.
3.1.1 数据集
为了说明我们提出的基于LGR的群组推荐方法的有效性与准确性,我们选取了公开的真实数据集MovieLens1M作为实验数据集,此数据集主要包括用户的显式评分相关的信息.由于MovieLens1M数据集并不包括电影的描述文档,因此,我们将对MovieLens1M数据集中的电影描述信息进行补充,根据MovieLens1M中每部电影名到IMDB中的获取其关联信息,并将每部电影的总结作为电影的描述文档.
类似CTR[14]中对数据的预处理工作,数据预处理主要步骤如下:1)去除没有描述文档的电影记录;2)去除评分次数少于3次的用户信息;3)设置最大描述文档长度为300;4)计算每个词的tf-idf,去除停顿词(tf-idf得分大于0.5);5)选取剩余词中tf-idf得分前8 000个单词作为词汇表;6)将描述文档中不在词汇表中的单词移除.尽管MovieLens1M数据集的一些记录被移除,但并没有对原始数据集的稀疏度产生明显改变.
预处理后的MovieLens1M数据集的数据统计信息如表1所示:

Table 1 Data Statistics of the MovieLens1M Data SetAfter Preprocessing
3.1.2 实验环境与具体设置
实验环境是CPU为Intel酷睿i7 6700HQ处理器,GPU为Nvidia GTX960M独立显卡,内存8 GB,系统为Ubuntu 16.04 LTS.
为了实现DPMFM-CNN,我们主要用python及其一种深度学习框架keras与科学运算库numpy、scipy实现.LGR的聚类算法采用python机器学习库sklearn中的聚类算法.
为了分析时间信息对用户偏好模型的影响,我们对数据集做设置:将MovieLens1M数据集前80%的数据分别按半年为时间窗口分段作为训练集,将最后20%的数据作为测试集.
为了训练CNN的参数W,我们使用基于mini-batch的RMSprop方法,并且使每一个mini-batch包括128条数据.更具体地做了设置:1)服务描述文档最大长度设置为300;2)每一个词向量的维度设置为200,并且采用glove[10]预训练结果作为词向量的初始化输入;3)设置3组不同宽度的卷积窗口(宽度分别为3,4和5);4)每一种宽度的卷积窗口在卷积层的个数都设置为100;5)经过多次实验的调试,设置Dropoutrate=0.2.
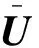
3.1.3 对比方法与评价指标
我们将在预处理后的MovieLens1M数据集上与2个基准方法进行对比.
1) Predict&Cluster[6]方法通过传统的协同过滤方法预测用户的评分矩阵的缺失项,对预测补全后的评分矩阵采用K-means方法进行聚类得到潜在群组,并将群组内所有用户评分采用均值策略融合为群组对项目的评分.
2) PLGM[7]方法通过潜在因子模型获取用户隐式偏好,对用户隐式偏好采用K-means方法进行聚类得到潜在群组,并将群组内所有用户偏好采用均值策略融合为群组偏好,最终通过潜在因子模型预测群组对项目评分.
我们选取了均方根误差(root mean squared error,RMSE)来对群组推荐结果的精确性进行分析.其在群组推荐场景下的表达形式为:
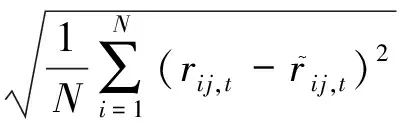
(22)
3.2实验结果与分析
本节将会从2个方向对实验结果进行分析:首先在对比实验结果中分析基于DPMFM-CNN的LGR的精确性与有效性;然后分析模型中影响推荐方法性能的主要参数.
3.2.1 精确性与有效性分析
首先给出LGR与所有预采用的聚类方法在用户偏好拟合系数γ=0.6、正则化系数λU=100与λV=10、潜在特征维数K=50、词向量维数Kw=200、偏好融合策略为均值策略、群组数量Ng=1,20,50,200,500,6 040所展示的RMSE值.LGR随群组数量变化的RMSE值如表2所示.
通过实验结果发现,K-means++算法在LGR推荐结果中的精度较其他算法有着一定的优势,因此,我们也将选取它作为LGR中潜在群组发现算法,并与基准方法进行对比.
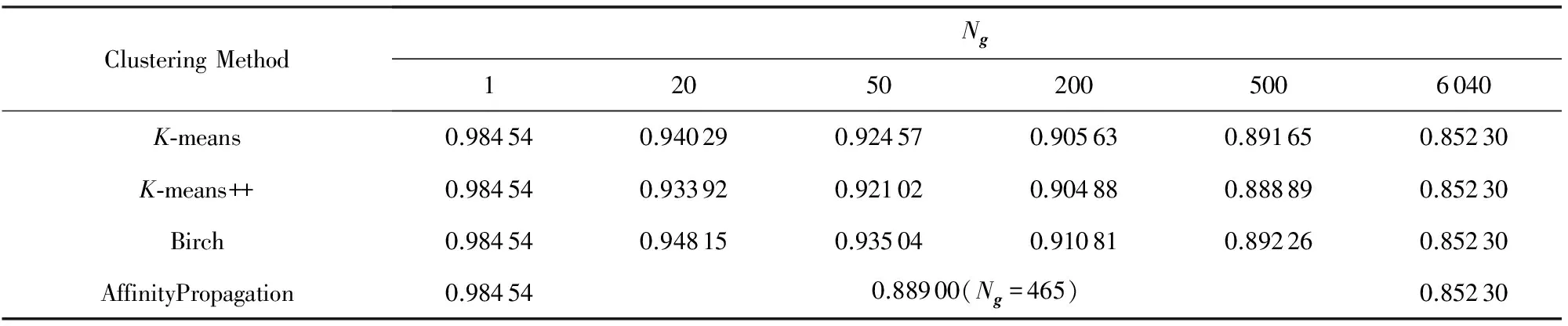
Table 2 RMSE of LGR in Different Group Size表2 LGR在不同群组数量的RMSE值
Predict&Cluster,PLGM以及LGR在MovieLens1M数据集上的RMSE随群组数量Ng变化的效果对比如图4所示:
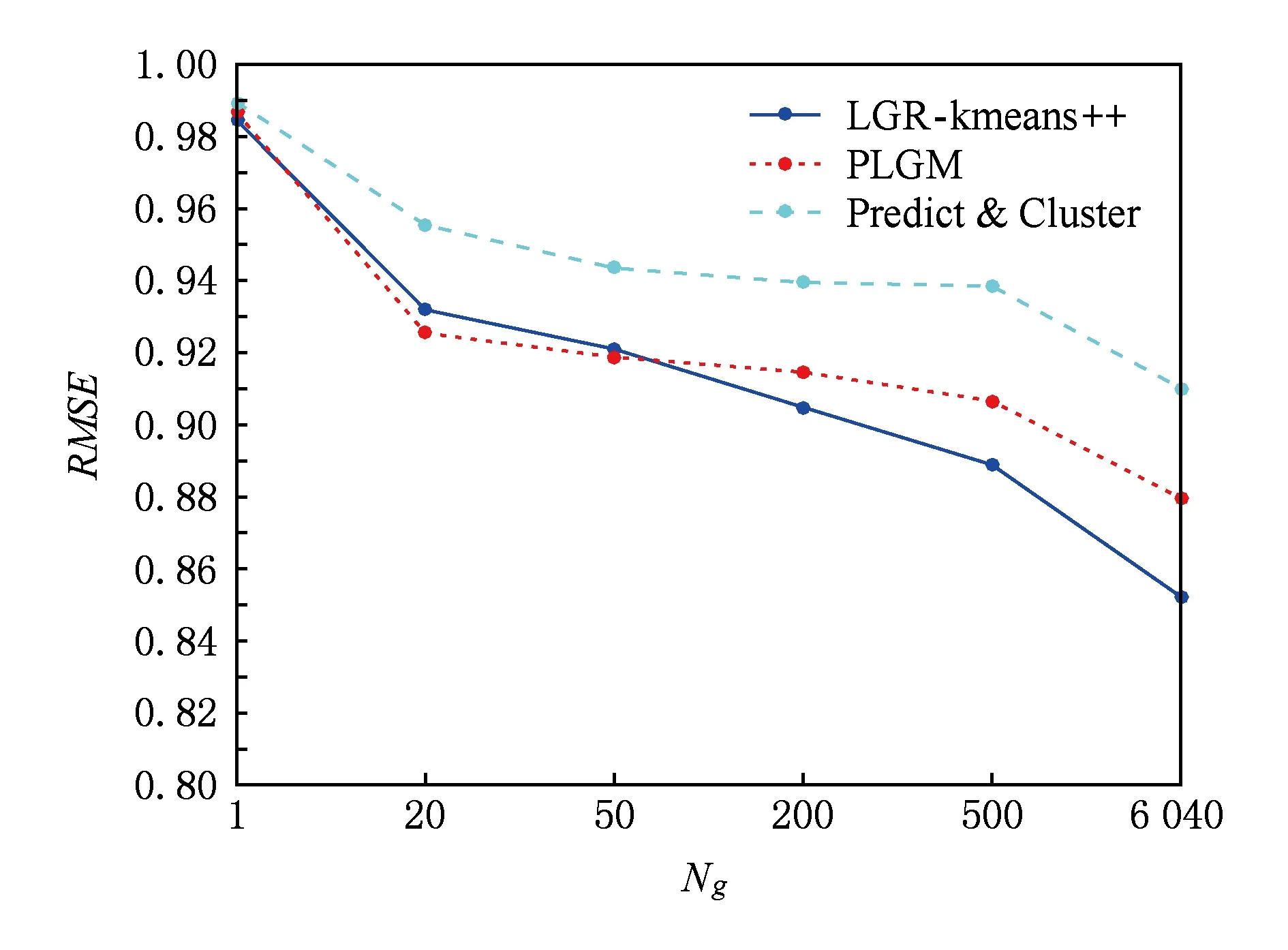
Fig. 4 RMSE in three methods (K=50,Average Strategy)图4 K=50时3种方法均值策略的RMSE
从图4中可以发现,LGR不仅在个体推荐情景下的推荐准确度明显高于Predict&Cluster与PLGM,在群组推荐场景下,也具有一定优势.相对于Predict&Cluster,LGR的精度具有着较大优势,这是因为Predict&Cluster聚合的是个体推荐结果,这些预测的推荐结果维度较大,偏好分布不明显.在与同样是融合个体偏好模型的PLGM的对比过程中,当群组数目Ng≤50时,LGR的精度以微弱的劣势略逊于PLGM,但总体精度上依然存在着一定的优势.
3.2.2 影响推荐方法性能的主要参数分析
根据3.2.1节各聚类算法对LGR的性能表现的对比,选取群组个数Ng=500,并在上述设置的基础上分析用户偏好拟合系数γ、正则化系数λU与λV、潜在特征维数K、词向量维数的变化对RMSE值的影响,在展示一个影响因素的变化趋势时,其他参数为最佳设置.
1) 用户偏好拟合系数γ.设置γ=0,0.1,0.2,…,1,观察其变化对RMSE值的影响如图5所示:
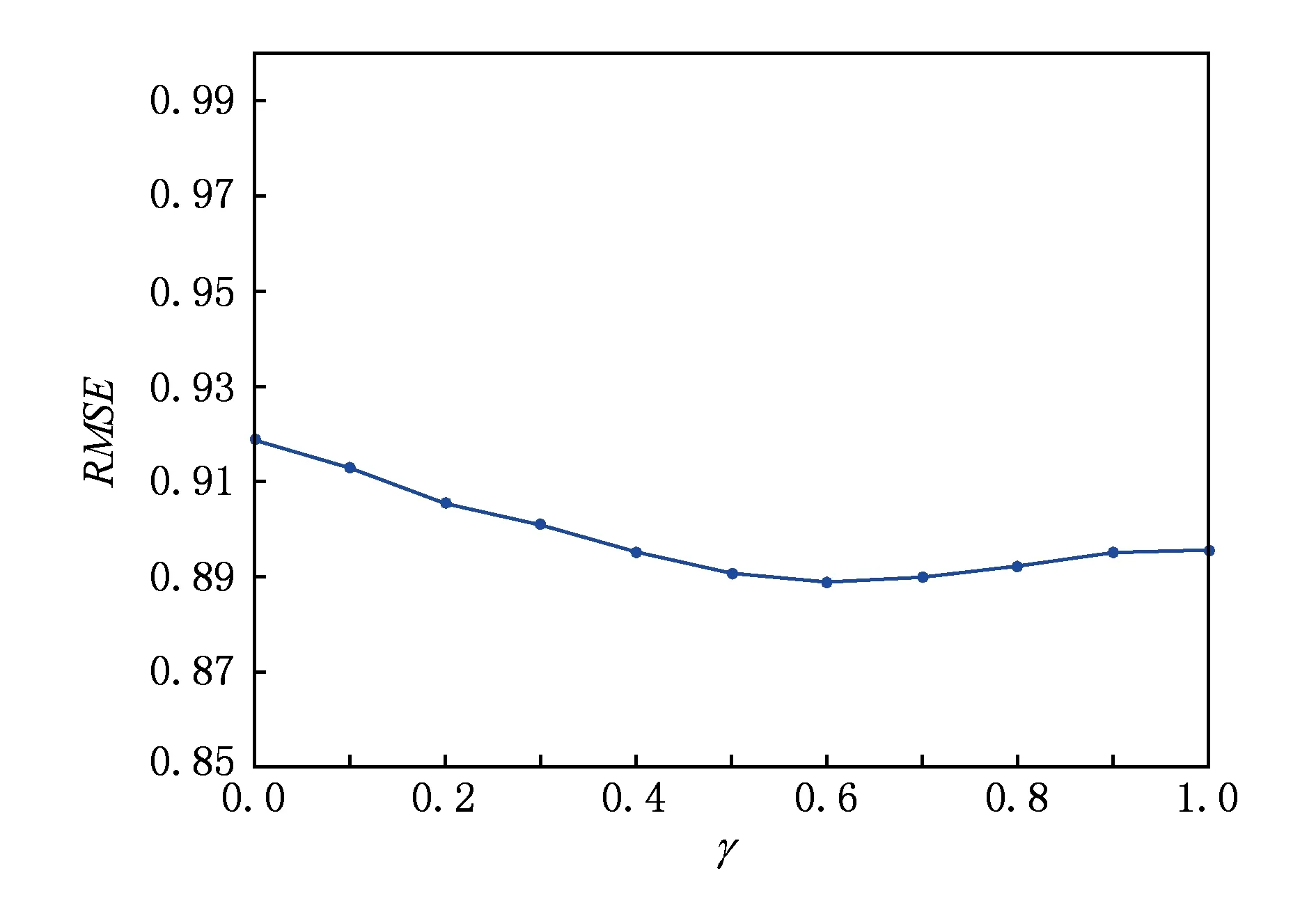
Fig. 5 RMSE in different γ图5 不同γ下的RMSE
2) 正则化系数λU与λV.设置了λU=1,10,100,1 000、λV=1,10,100,1 000,观察其变化对RMSE值的影响如图6所示:
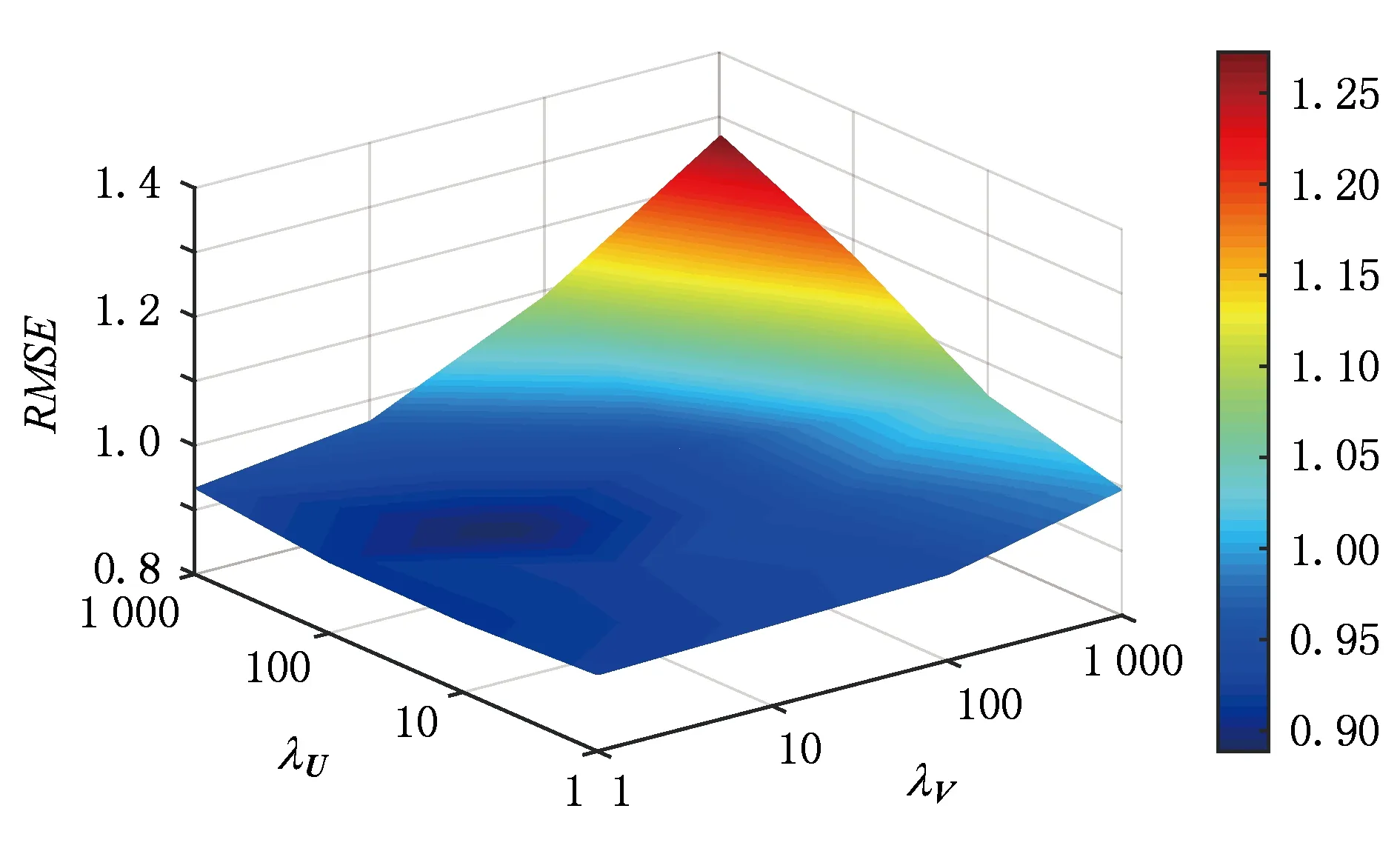
Fig. 6 RMSE in different λU and λV图6 不同λU与λV下的RMSE
3) 潜在特征维数K.设置K=10,20,50,100,观察其变化对RMSE值的影响如图7所示.
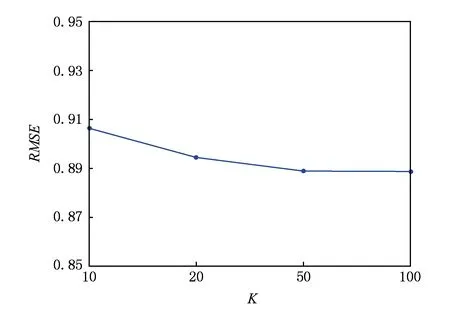
Fig. 7 RMSE in different K图7 不同K下的RMSE
4) 词向量维数Kw.设置Kw=100,200,300,观察其变化对RMSE值的影响如图8所示.
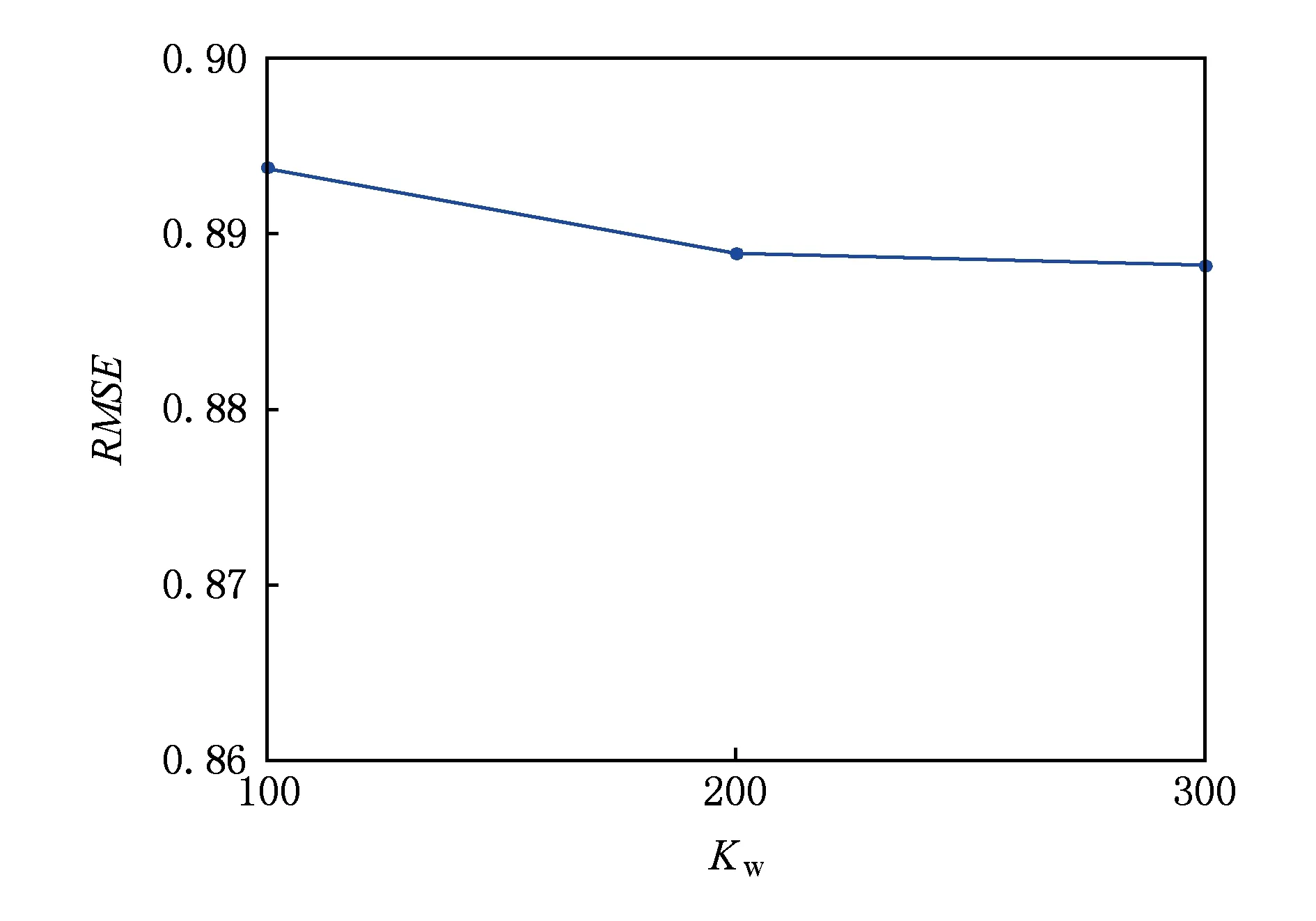
Fig. 8 RMSE in different Kw图8 不同Kw下的RMSE
通过实验结果可以发现,潜在特征维数K与词向量维数Kw在到达一定的数值以后对RMSE值几乎没有影响,用户偏好拟合系数γ取值在0.5~0.7时RMSE有最小值,正则化系数λU与λV分别为100与10时RMSE出现最小值.根据分析得出:我们采用的最佳设置为γ=0.6,λU=100,λV=10,K=50,Kw=200.
4 总 结
我们提出了一种基于动态卷积概率矩阵分解模型(DPMFM-CNN),以及将其融合于群组推荐框架的的潜在群组推荐方法(LGR).DPMFM-CNN模型结合服务描述文档、用户配置文件以及时间因素,综合的分析了用户的静态与动态偏好;LGR通过聚类用户偏好,采用多种聚类算法发现用户集合中的潜在群组,并采取均值策略进行群组偏好融合,完成群组对服务评分的任务.
目前,我们的工作主要关注用户的显式评分数据,而这类数据并不是所有场景都可以获得的,相比于用户的显式数据,用户的隐式反馈如:点击、评论、转发等行为更为容易收集.因此运用用户隐式反馈数据分析用户兴趣将是一个值得关注的方向.此外,用户的兴趣迁移可以通过时间直观地反映出.然而,在这背后可能潜藏着更多的影响因素如:地点、天气、交通、节假日等,因此,将用户的表示扩展到更高维度来分析用户的偏好也是一个值得进一步探讨的研究点.
[1] Zhuang Yujie, Du Yulu. Research on group recommendation system and their application[J]. Chinese Journal of Computers, 2016, 39(4): 745-764 (in Chinese)(张玉洁, 杜雨露. 组推荐系统及其应用与研究[J]. 计算机学报, 2016, 39(4): 745-764)
[2] Feng Shanshan, Cao Jian, Wang Jie, et al. Group recommendations based on comprehensive latent relationship discovery[C] //Proc of IEEE Int on Web Services (ICWS 2016). Piscataway, NJ: IEEE, 2016: 9-16
[3] Boratto L. Group recommender systems[C] //Proc of ACM Confon Recommender Systems (RecSys 2016). New York: ACM, 2016: 427-428
[4] Baltrunas L, Makcinskas T, Ricci F. Group recommendations with rank aggregation and collaborative filtering[C] //Proc of ACM Confon Recommender Systems (RecSys 2010). New York: ACM, 2010: 119-126
[5] Boratto L, Carta S, Chessa A, et al. Group recommendation with automatic identification of users communities[C] // Proc of 2009 IEEE/wic/ACM Int Joint Conf on Web Intelligence and Intelligent Agent Technologies. Piscataway, NJ: IEEE, 2009: 547-550
[6] Boratto L, Carta S. Using collaborative filtering to overcome the curse of dimensionality when clustering users in a group recommender system[C] //Proc of the 16th Int Conf on Enterprise Information Systems (ICEIS 2014). Setubal: Scitepress, 2014: 564-572
[7] Zeng Xuelin, Wu Bin, Shi Jing, et al. Parallelization of latent group model for group recommendation algorithm[C] //Proc of the 1st 2016 IEEE Int Conf on Data Science in Cyberspace (DSC 2016). Piscataway, NJ: IEEE, 2016: 80-89
[8] Lecun Y, Bengio Y, Hinton G. Deep learning[J]. Nature, 2015, 521(7553): 436-444
[9] Mikolov T, Sutskever I, Chen Kai, et al. Distributed representations of words and phrases and their compositionality[C] //Proc of Neural Information Processing Systems (NIPS 2013). Cambridge, MA: MIT Press, 2013: 3111-3119
[10] Pennington J, Socher R, Manning C. Glove: Global vectors for word representation[C] //Proc of Conf on Empirical Methods in Natural Language Processing (EMNLP 2014). New York: ACM, 2014: 1532-1543
[11] Shen Yelong, He Xiaodong, Gao Jianfeng, et al. Learning semantic representations using convolutional neural networks for Web search[C] //Proc of the 23rd Int Conf on World Wide Web (WWW 2014). New York: ACM, 2014: 373-374
[12] He Hua, Gimpel K, Lin J. Multi-perspective sentence similarity modeling with convolutional neural networks[C] //Proc of Conf on Empirical Methods in Natural Language Processing (EMNLP 2015). Stroudsburg, PA: ACL, 2015: 1576-1586
[13] Kim Y. Convolutional neural networks for sentence classification[C] //Proc of the 2014 Confon Empirical Methods in Natural Language Processing (EMNLP 2014). Stroudsburg, PA: ACL, 2014: 1474-1480
[14] Wang C, Blei D M. Collaborative topic modeling for recommending scientific articles[C] //Proc of ACM SIGKDD Int Conf on Knowledge Discovery and Data Mining (SIGKDD 2011). New York: ACM, 2011: 448-456
[15] Salakhutdinov R, Mnih A. Probabilistic matrix factorization[C] //Proc of the 20th Int Conf on Neural Information Processing Systems (NIPS 2007). Cambridge, MA: MIT Press, 2007: 880-887
[16] Zhang Wei, Han Linyu, Zhang Dianlei, et al. GeoPMF: A distance-aware tour recommendation model[J]. Journal of Computer Research and Development, 2017, 54(2): 405-414 (in Chinese)(张伟, 韩林玉, 张佃磊, 等. GeoPMF: 距离敏感的旅游推荐模型[J]. 计算机研究与发展, 2017, 54(2): 405-414)
[17] Roweis S, Ghahramani Z. A unifying review of linear gaussian models[J]. Neural Computation, 1999, 11(2): 305-345
[18] Guang Ling, Yang Haiqin, Irwin K, et al. Online learning for collaborative filtering[C] //Proc of the 2012 Int Joint
Conf on Neural Networks (IJCNN 2012). Piscataway, NJ: IEEE, 2012, 20: 1-8
[19] Arthur D, Vassilvitskii S.k-means++: The advantages of careful seeding[C] //Proc of the 18th Annual ACM-SIAM Symp on Discrete Algorithms (SODA 2007). Philadelphia, PA: SIAM, 2007: 1027-1035
[20] Zhang Tian, Ramakrishnan R, Livny M. BIRCH: An efficient data clustering method for very large databases[J]. AcmSigmod Record, 1996, 25(2): 103-114
[21] Frey B J, Dueck D. Clustering by passing messages between data points[J]. Science, 2007, 315(5814): 972-976
[22] Boratto L, Carta S. Modeling the preferences of a group of users detected by clustring: A group recommendation case-study[C] //Proc of Int Conf on Web Intelligence, Mining and Semantics (WIMS 2014). New York: ACM, 2014
LatentGroupRecommendationBasedonDynamicProbabilisticMatrixFactorizationModelIntegratedwithCNN
Wang Haiyan1,2,3and Dong Maowei1
1(SchoolofComputerScience,NanjingUniversityofPostsandTelecommunications,Nanjing210023)2(JiangsuHighTechnologyResearchKeyLaboratoryforWirelessSensorNetworks,Nanjing210003)3(JiangsuKeyLaboratoryofBigDataSecurity&IntelligenceProcessing,Nanjing210023)
Group recommendation has recently
great attention in the academic sector due to its significant utility in real applications. However, the available group recommendation methods mainly aggregate individual recommendation results or personal preferences directly based on an analysis of rating matrix. The relationship among users, groups, and services has not been taken into comprehensive consideration during group recommendation, which will interfere with the accuracy of recommendation results. Inspired by latent factor model and state space model, we propose a latent group recommendation (LGR) based on dynamic probabilistic matrix factorization model integrated with convolutional neural network (DPMFM-CNN), which comprehensively investigates rating matrix, service description documents and time factor and makes a joint analysis of the relationship among those three entities. The proposed LGR method firstly obtains a prior distribution for service latent factor model with the employment of text representation method based on convolutional neural network (CNN). Secondly, it integrates state space model with probabilistic matrix factorization model and draws user latent vector together with service latent vector. Thirdly, latent groups are detected through the use of multiple clustering algorithms on user latent vectors. Finally, group latent vectors are aggregated with average strategy and group rating can be generated. In addition, simulation on MovieLens is performed and comparison results demonstrate that LGR has better performance in efficiency and accuracy for group recommendation.
convolutional neural network; probabilistic matrix factorization; state space model; clustering algorithms; group recommendation

Wang Haiyan, born in 1974. PhD. Professor. Senior member of CCF. Her main research interests include service computing, trusted computing and big data intelligent processing technology.

Dong Maowei, born in 1993. Master candidate. His main research interests include service computing, deep learning (dongmaowei@gmail.com).
2017-05-23;
:2017-06-21
国家自然科学基金项目(61201163,61373138) This work was supported by the National Natural Science Foundation of China (61201163, 61373138).
TP181; TP183
