基于传感网络对公共安全风险的数据融合及预测
2017-08-30宋华明
宋华明
(湖北省咸宁市公安局,湖北 咸宁 437000)
基于传感网络对公共安全风险的数据融合及预测
宋华明
(湖北省咸宁市公安局,湖北 咸宁 437000)
利用传感网络对公共安全进行实时监测与风险预警,已成为公安信息化重要的一环。围绕公共交通网络中的诸多传感器,收集了海量的监测数据,并将其上传到服务器端进行监测及公共安全风险预测。但其传感数据庞大且密度低,对传输网络带宽及服务器端造成了不小的压力。本文在传感网络的节点端及中继处分别利用加权局部融合和约简融合,消除数据噪声,提高数据密度,剔除冗余属性;在服务器端利用基于遗传算法的BP神经网络进行分析预测,加速收敛速度,降低预测误差6%以上。
传感网络;OWA算子;加权融合;基于遗传算法的BP神经网络
1.引言
随着城市化战略格局的部署,城市内部的交通网络越发密集。在交通网络上密布的众多传感器收集包括烟雾,温度,声音,人流等诸多属性的数据,构建了传感网络进行实时监控。密集的传感网络作为公安信息化[1]的一部分,不仅保证了对各大交通枢纽中公共安全的实时监控,也提供来海量的数据供公安部门预测不同地区的公共安全风险态势。但随着部署的节点越来越密集,监控数据的信息量不断提升,将节点数据全部上传到云端,集中式分析预测,对现有的带宽,机房造成了不小的压力。而且现有各类传感器数据,规模庞大但价值不高,整体信息密度低,且会因为监测地区广而导致不同程度的噪声数据。另外现有的预测算法如神经网络等,在处理这些数据时,因运算量过大,导致收敛时间过长,预测误差大等。对此本文提出了以下创新点:
(1)在传感网络的节点端进行局部数据融合,将同类型的传感数据进行加权融合,降低数据噪声。再利用模糊集的知识,在中继节点处,定义不同类型传感数据的重要程度。配合OWA算子约简掉部分与预测对象无关的数据属性,提高数据密度。
(2)在传感网络的终端进行数据预测,将已被约简的传感数据利用BP神经网络进行预测,配合遗传算法“优胜劣汰”加快其算法的收敛速度,提高预测的精准度。通过实验证明经约简之后的数据预测相对误差在2%以内,相比原有的BP神经网络,预测精度提高了6%。
2.国内外相关工作
传感器网络由众多的传感器节点组成的,各个节点实时检测收集多维度,多种类的数据[2],在整个网络中利用分步路由将数据汇总上传。为了减少带宽占用,消除单个传感器的不稳定,提高整体性能。我们将众多监测数据按时间序列进行收集汇总[3],按一定规则拼合使用。这就是传感器的数据融合。传感器融合技术不仅提升了同源数据的共性优势,还从综合信息的角度提高了多种信息的观测精度[4],现已被广泛应用于智能监测和自动化控制等专业领域[5]。
现有的传感器融合技术或依赖于证据推理、统计决策理论的统计学理论知识[6];或利用加权平均、贝叶斯估计等数学原理上的知识。近来也有利用人工智能的神经网络,利用神经网络的权值协作,过滤冗余数据等[7]。本文首先利用基础的数学理论进行同组数据的局部融合,再利用模糊集约简属性,配合OWA算子进行数据融合。
将经过融合之后的传感数据传到云端的数据中心来进行数据挖掘,提取其中的价值,分析潜在的公共安全风险并及时进行预警。BP神经网络作为人工智能的优秀算法之一,被广泛应用于数据压缩、模式识别、数据挖掘之中。BP神经网络一般具有三层或者三层以上的网络结构。利用输出误差反传,即将输出后一层的误差来估计输出前一层的误差,按照网络层级,一层层的反传回去[8],并由此获得所有层的误差估计。通过不断修正和训练,达到较好的预测效果。
在利用BP神经网络进行数据挖掘的过程中,会因为隐层节点过多,造成预测效果不好,学习时间长,或因节点数量过少造成整体网络难以收敛。为此有对BP神经网络引入训练函数,例如比例梯度共轭减少搜索时间,提高训练精度[9];或利用Fletcher-Reeves算法降低训练时间[10]。或将BP神经网络与其他算法结合,如模拟退火算法用于缓解选择压力[11]。本文中利用遗传算法,对BP神经网络中连接权进行改进调优。
3.传感数据的融合
3.1传感器数据的局部融合
将整个传感网络的数据全部传输到云端,除了大量的带宽能耗的消耗,也可能导致后一步预测过程中较长的收敛时间。我们选择在节点端对传感数据先进行局部融合,将同组传感器中的数据通过简单的加权方式进行合并。这可使得传感数据被进一步的优化,有效地屏蔽掉环境中的噪声污染,节约带宽与能耗。
传感数据的局部融合是将根据同组传感器中的数据方差大小来分配权数的。数据变化程度低的方差小,分配的权数小,传感数据变化差值大表明数据存在异样,分配权数较大[12]。

(1)
因为某时间段内,同一类型的传感器测值方差不大,证明这段时间内无明显情况变化,数据显示趋同性,证明其公共安全风险较低[13]。所以可以合并对应测量数据,提高数据密度。同时也能降低噪声,方便之后我们在中继节点对传感数据进行约简融合。
3.2传感器数据的约简融合
在中继节点中,我们获得经局部融合的同组传感器监测数据。首先假设整个传感网络中一共有若干种传感器,这若干种传感器总计收集回m种不同的数据属性,定义传感器中数据属性A包含m种不同属性,表示为{a1,a2,…,am}。针对每个不同的数据属性,我们会根据其对于后期预测对象的重要程度,来进行约简。
这里我们根据模糊集的知识定义:该属性在预测对象中出现的次数越多,说明该属性在知识表达系统中越重要[14]。定义属性a对于预测对象的重要程度T。并利用OWA算子[15―16](Ordered Weighted Averaging operator)来聚合属性,表达其对象的重要度。则OWA算子描述如下:
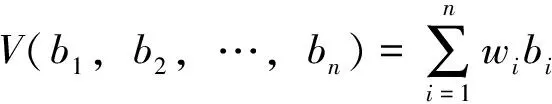
为了获得属性aj对于预测对象的重要度的加权向量,我们定义模糊量词Q来获取:

(2)
其中Q(l)会根据参数α和β,有多种不同的取值。当l小于α时,Q(l)为0;当l大于β时,Q(l)为1。α和β∈[0,1],对应不同取值时可以表示这是模糊量词的多寡范围,比如,当(α,β)取(0.5,1)表示,尽可能多的意思。对应的我们就能定义经过有序加权之后的向量h
(3)
根据上述的公式,我们可以定义预测对象的重要度IM:在经局部融合后的数据,其中每个属性A{a1,a2,…,an}对应为:
(4)
其中j的取值[1,m],Tj表示属性aj对所有对象的重要度的由大到小的排列,V是OWA算子;Hj是根据公式2,3来确定的加权后n维向量h。
之后根据IM来对重要度进行从小到大的排序,根据预测对象的要求,筛掉较小的IM。若IMj=0,证明该属性对于预测对象重要程度为空,属于冗余属性,即可约简该属性。
4.基于遗传算法的BP神经网络预测
我们利用BP神经网络对传感器数据,进行公共安全的风险预测,提取公共安全风险因子。但是由于原有的BP神经网络在确定学习速率和记忆因子时,会因规则的好坏造成学习速率选择过大或过小。这会导致训练中出现跳跃现象或收敛速度较慢。其次在利用BP神经网络进行挖掘分析时,如果选择不合适的初值权重,则可能在训练中出现跳跃现象,或陷入局部最优。为解决上述问题,我们引入遗传算法的“优胜劣汰”思想对BP神经网络进行优化,使其更适合传感数据的进行预测。其具体操作步骤如下:
步骤1:对阈值进行编码,用随机生成的一组分布对应一组阈值。
步骤2:将训练样本的误差平方和倒数定义为适应度,令适应度与误差负相关,并以此评判阈值好坏。
步骤3:在训练样本内挑选出适应度大的个体,遗传至下一代,保留优质属性。
步骤4:利用交叉、变异令群体完成进化,得到下一代群体。
步骤5:重复步骤2—4,令阈值不断进化直到满足预设条件。
在参数初始阶段,我们首先对神经网络的网络层数进行设置。尝试隐层数目为一层或三层,因为单隐层网络可以对任一非线性函数进行拟合;而三层遗传学习更优。
之后,定义各层神经元数目,输入层神经元数根据所预测的属性种类设定,输出层神经元数由预测对象决定。然后利用“试凑法”来确定隐层神经元数的大致范围,计算公式如下:
(5)
其中,k为隐层神经元数,m、n分别为输入输出神经元数,a为1到10间常数。之后各层神经元数目按经验公式设定:
(6)
其中m为输入层神经元数,n为输出层神经元数。
之后我们定义遗传算法的种群规模及迭代次数。种群规模过大将加大计算量进而降低学习效率,规模过小将容易导致遗产算法收敛于局部极小点。同理,迭代次数过小将有可能导致算法无法找出最优解,多大将扩大计算时间。经过反复测试,我们将迭代次数和种群规模都设置为50。
在遗传算法中的交叉概率过大将导致个体充分交叉从而生成不必要的解空间,过小将导致算法搜索能力的降低,我们定义好交叉概率设置为0.3。对于变异概览来说,过大的变异概率有可能破坏种群模式,过小则会降低种群进化速度。故最终设定变异概率设置为0.1。
5.实验结果及分析
在BP神经网络训练样本的数目选择上,若样本数过少,BP神经网络难以捕获其中包含的信息,导致较大的预测误差。而过大的样本数量则会延长训练时间,预测代价高。考虑到其直接影响模型预测的准确度,为保证训练效果,本节选取了600个样本作为训练样本。原有的传感器属性种类有14种,这里我们使用了经过降噪局部融合,和约简融合之后的6个属性,故输入层神经元可以设置为4个。预测对象设定为单一的风险因子,故输出层神经元设置为1个。则根据公式(5)(6)隐含层神经元为2或更多。
我们通过实验,分别对比在隐含层数为1,3时,计算整体预测对象的均方误差mse,利用设定好的参数对模型进行训练和预测。
(7)
其中,n为总体的预测样本数量,这里我们选取约简数据的中30个为预测样本。由图1可以看出,隐含层数为1时在训练到14次时即达到收敛,隐含层数为3时在11次时达到收敛。两者的训练曲线如下:
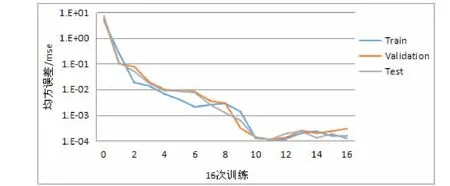
Figure2 The mean square error of the hidden layer number is 3
图2 隐含层数为3时的均方误差
由图可以发现,在处理约简后的传感器数据时,隐含层选为3层时,预测的收敛速度更快。在第十次训练之后可以认为其收敛。所以我们之后我们用隐含层数为3的基于遗传算法的BP神经网络与原有的BP神经网络进行对比。验证在数据融合之后,在公共安全的预测上精准程度。我们利用相对误差Rerror和来判定预测后的误差大小,公式如下:
(8)
其中xi为预测数据,xj为真实数据。
对比两者预测结果,按公式(8)计算出相对误差,如图3。
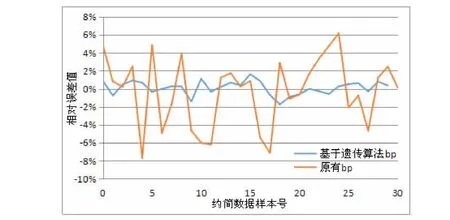
Figure3 The comparison of the relative error of two kinds of BP neural network prediction
由图3可以看出基于遗传算法的BP神经网络预测的传感器数据,总体的相对误差在±2%内,充分说明利用该模型预测经约简后的传感器数据是可行的。而原有的BP神经相对误差在±8%内,可以证明经遗传算法优化的BP神经网络预测效果更加精准。
6.总结
庞大的传感网络所带来的海量传感数据,已给网络传输造成了不小压力。本文在传感网末端节点利用局部融合消除噪声,提高数据密度;在中继节点利用模糊集知识,配合OWA算子进行约简融合,简化无关数据属性,降低传输数据量,减缓网络带宽压力。在分析传感数据,预测公共安全风险上,本文利用遗传算法优化了BP神经网络中连接权,进行数据预测,加快了收敛速度;经实验证明,经优化后的BP神经网络预测的相对误差在2%以内,相比原有的BP神经网络提高了6%。
[1] Liu A H, Bunn J J, Chandy K M. Sensor Networks for the Detection and Tracking of Radiation and Other Threats in Cities[C]// International Conference on Information Processing in Sensor Networks. 2011:1―12.
[2]杨李博.基于Wi-Fi的无线传感器网络节点设计与实现[D].上海:上海交通大学硕士学位论文, 2014.
[3]孔繁强.基于传感网的大楼火源定位及预警算法的研究[D].哈尔滨:黑龙江大学硕士学位论文, 2012.
[4] Song Guo, Chen Zhang, Liu Xihui. Software development and data processing of tool wear based on mapping measurement[J].AdvancedMaterialsResearch, 2012,(383―390):4971―4976.
[5]郭键.一种模糊神经网络在矿井胶带机火灾探测中的应用[J].兰州理工大学学报,2007,33(3):88―91.
[6]涂国平,邓群钊.多传感器数据的统计融合方法[J].传感器与微系统,2001,20(3):28―29.
[7]王萌萌.氯气无线传感网监测的数据挖掘与融合研究[D].哈尔滨:哈尔滨理工大学硕士学位论文,2014.
[8] Wu W, Wang J, Cheng M, et al. Convergence analysis of online gradient method for BP Neural Networks[J].NeuralNetworks, 2011, 24(1):91―98.
[9]史春朝,张国山.基于改进BP神经网络的PID控制方法研究[J].计算机仿真,2006,23(12):156―159.
[10] Jiang M, Gielen G, Bo Z, et al. Fast Learning Algorithms for Feedforward Neural Networks[J].AppliedIntelligence, 2003, 18(1):37―54.
[11]郭晓婷,朱岩.基于遗传算法的进化神经网络[J].清华大学学报(自然科学版),2000,40(10):116―119.
[12]杨万海.多传感器数据融合及其应用[M].西安:西安电子科技大学出版社,2006
[13]司鹄,贾文梅.城市公共安全风险评估指标敏感性分析[J].中国安全生产科学技术,2014(11):71―76.
[14]苗夺谦.粗糙集理论、算法与应用[M].北京:清华大学出版社,2008.
[15] Yager R.On ordered weighted averaging aggregation operators in multicriteria decisionmaking[J].IEEETransactionsonSystems,Man,andCybernetics,1988,8(1):183―190.
[16] Ronald R.Families of OWA operators[J].FuzzySetsandSystems,1993,59(1):125―148.
(责任编辑 李志虹)
Data Fusion and Forecast of Public Safety Risks Based on Sensor Network
SONG Huaming
(PublicSecurityBureau,Xianning, 437000,HubeiProvince)
The application of sensor network to monitor and forecast public safety risks has become an important part of public security informationization. The large quantities of sensors of public transportation are used to collect data, and then upload to the servers to monitor and forecast public safety risks. However, problems do exist, such as large data with lower density on the sensors. As a result, great pressure is imposed on both bandwidth and the servers of the network. This paper is devoted to the application of local weighted fusion and leaning fusion at the node ends and the trunk offices to reduce noise, increase data density and eliminate redundancy. Meanwhile, the application of the BP neural network based on the genetic algorithm at the server ends can increase convergence rate and lower the forecast error rate by 6%.
sense network, OWA (ordered weighted averaging) operator, weighted fusion, BP neural network based on the genetic algorithm
2017 - 03 - 04
宋华明(1978―),男,湖北省咸宁市公安局网络工程师,研究方向:计算机网络。
TP212
A
1671 - 7406(2017)03 - 0063 - 05
