改进的关联规则挖掘算法在个性化推荐系统中应用
2017-08-16崔苹宋丽张振雷上海师范大学
崔苹 宋丽 张振雷 上海师范大学
改进的关联规则挖掘算法在个性化推荐系统中应用
崔苹 宋丽 张振雷 上海师范大学
本文采用改进的Apriori聚类算法进行用户兴趣模型的建立,对于用户阅读杂志的行为进行收集并行分析建模,依据Apriori聚类算法实现推荐方法,为用户感兴趣的杂志进行推荐。并对数据库进行优化提高运行效率,取得了很好的推荐效果。
推荐系统 Apriori 数据库优化 关联规则
1 引言
随着互联网技术的快速发展,推荐系统目前已广泛应用于商业领域。常用的推荐算法有协同过滤推荐、内容推荐、关联规则推荐和混合推荐。在个性化推荐上,WebWatcher是最早开始个性化推荐服务的。2004年,Kevin创办了Digg新闻网站,Digg对用户的兴趣进行了研究,通过历史数据对用户的兴趣相似度进行了计算,通过个性化的推荐,提升了Digg网站的浏览量。同年Findory建立,实现了用户的定制新闻。
2 Apriori算法改进思想
在对数据进行关联的挖掘时,需要对其中的互斥项进行约束,降低生成频繁项集的速度,因此要避免互斥项的连接,利用互斥的标志是否相等来判断项目之间是否互斥,若相等则为互斥项,则不进行连接。算法的具体步骤为:
①扫描数据库,生成布尔矩阵以及1阶频繁项集,扫描一次数据库之后,生成布尔型矩阵,布尔型矩阵的第i行就是原事务数据库的项目,第j列就是原事务数据库的项目Tj,若Tj包含,则布尔型矩阵对应的位置为1,否则置为0。并统计事务中项目出现的次数,若满足最小支持度计数,则项目为 1阶频繁项集。
③产生K阶频繁项集,利用(k-1)阶频繁项集的最后一项与事务数据库中的相容项目进行扩展,获得k阶频繁项集。具体的步骤为:取出(k-1)阶频繁项集的最后一项,从项目集中取出项目进行扩展,若且量项目为相容项目时,则扩展为k阶频繁项集。然后对该k阶频繁项集的k个项与布尔型矩阵的行向量进行“与”运算,若得到的1个数满足最小支持度计数,则加入到项目中。
3 数据库优化方法
3.1 归档报表数据
在数据的统计阶段,需要对数据进行归档,若数据较大时,归档的时间就很多,则等待反馈结果需要确保较少的时间。因此需要规定好存储过程,降低工作量,提升响应的速度。
3.2 创建索引
当系统的数据量很大时,用户在操作数据库时用到的数据量也比较大,此时又不便进行归档时,则可以创建索引进行解决,降低工作量,提升响应的速度。
3.3 建立缓存机制
建立缓存机制,对于经常使用的数据保存在缓存中,用户再次使用时,在缓存中获取,而不去对数据库进行操作,提升了查询的速度,减少了响应时间,提声了用户的体验感。
4 实验及结果分析
以某杂志网站的1000名用户为例,对各种杂志文章浏览信息进行挖掘,设定80分以上的最小支持度为0.04。输出用户浏览行为的关联性分析如表所示:
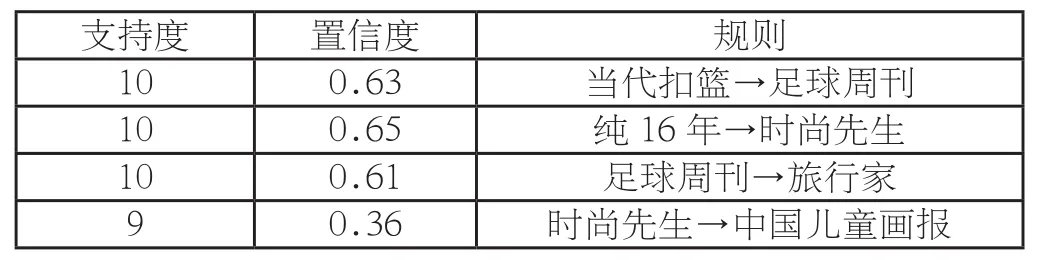
0 . 3 6 时尚先生→中国儿童画报支持度 置信度 规则1 0 0 . 6 3 当代扣篮→足球周刊1 0 0 . 6 5 纯1 6年→时尚先生1 0 0 . 6 1 足球周刊→旅行家9
当代扣篮对足球周刊的置信度为0.63,也就是说,如果这名用户浏览了当代扣篮,则他浏览足球周刊的可能性很大。纯16年对时尚先生的置信度为0.65,即若该用户浏览了纯16年,则他浏览时尚先生的可能性很大。综上所述,用户之间的浏览行为是有关联的,因此针对用户的浏览行为,利用Apriori算法对用户兴趣信息进行挖掘,对杂志进行合理的配置,增加杂志的浏览量与销量。
[1]Balabanovic M,Shoham Y.Fab:content-based,collaborative recommendation[J].Communications of the ACM.1997,40(3):66 72
[2]花青松.个性化推荐系统用户兴趣建模研究与实现[D].北京:北京邮电大学,2013
[3]闫艳.基于多Agent技术的电子商务个性化推荐系统的设计与实现[D].北京:首都师范大学,2009
[4]张恒玮.基于协同过滤技术的电子商务推荐系统的研究与实现[D].北京:华北电力大学,2012
[5]刘建国,周涛,汪秉宏.个性化推荐系统的研究进展[J].自然科学进展,2009(01)
