基于多Agent的搜索引擎技术的研究
2017-07-31郭文俊乔世东
郭文俊,乔世东
(山西大同大学数学与计算机科学学院,山西大同037009)
基于多Agent的搜索引擎技术的研究
郭文俊,乔世东
(山西大同大学数学与计算机科学学院,山西大同037009)
一直以来人类的发展离不开知识的获取,因此人们需要一种技术可以更容易更准确的获取信息,而搜索引擎便是这样一个导航工具。然而随着Internet的发展和Web搜索技术的不断完善,传统的搜索引擎已很难满足用户的需求。因此在系统地研究了传统搜索引擎和Agent技术后,笔者提出了一种基于多Agent的搜索引擎技术用于Web信息的搜索,它允许用户在特定领域进行搜索,能够有效的地提高搜索质量。
搜索引擎;多Agent;智能搜索
大数据的发展,导致了Web信息量的不断增加,如何更加准确的获取信息成了网络用户日益关注的焦点,而传统的搜索引擎技术已经很难满足用户的专一需求。故此笔者提出了一种基于多Agent的搜索引擎技术,它允许用户在特定领域进行搜索,可以在很短的时间内得到与用户息息相关的结果有效的地提高搜索质量与搜索的精度。
1 搜索引擎
1.1 基本概念
在20世纪90年代初期,麦吉尔大学(McGill University)计算机学院的三名学生研制出了一款可以利用文件名来查找文件的系统Archie,受到该系统的启发内达华州计算服务中心于1993年开发了一个Gopher搜索工具Veronica,至此搜索引擎[1-2]开始得到发展。搜索引擎是指根据一定的策略对收集到的信息进行组织和处理并将处理后的结果存储到索引数据库中以便用户检索,搜索引擎的出现从根本上改变了人们获取信息的方式使得用户查找信息更加方便。
1.2 主要分类
搜索引擎(Search Engine)主要包括垂直搜索引擎、全文搜索引擎、目录式搜索引擎和元搜索引擎。
(1)垂直搜索引擎区别于一般的搜索引擎,它是一种专注于特定领域的搜索引擎系统,主要应用于购物搜索(shopping search)、机票搜索(air search)、旅游搜索(tourism search)等。
(2)全文搜索引擎是利用索引程序对一篇文章中的每一个词都建立一个索引,并指明该词出现的位置和次数。而用户在搜索的时候也可以检索文章中的任何部位,无论是标题或是正文。比较常见的全文搜索引擎有百度、谷歌(Google)。
(3)目录式搜索引擎是以人工或半自动的方式进行信息的搜集,然后再人工形成摘要,以便用户查询。由于加入人的智能,故该搜索引擎检索的信息更加准确,但是检索的信息量确相对较少。Ya⁃hoo就是一款老牌目录式搜索引擎。
(4)元搜索引擎是利用一个统一的搜索界面将用户发来的查询请求转发给各大搜索引擎网站,然后将反馈的结果汇总并返回给用户。360综合搜索就是一款常用的元搜索引擎。
1.3 工作原理
事实上搜索引擎并没有想象中的智能,它不能真正理解用户的需求它所做的只是在机械地匹配用户键入的索引关键字。其基本的流程如图1所示。

图1 搜索引擎流程图
网页搜索即从互联网上抓取网页,搜索的关键在于如何有效地收集用户需要的信息。在搜索引擎技术中信息收集的主要方式有人工收集和自动收集。前者由专属人员负责跟踪和链接相关的Web站点和页面,并按一定规则建立索引数据库;而自动收集则是利用能够从互联网上自动收集网页的蜘蛛(Spider)有时也被成为“机器人”程序进行网页的链接。当然这种爬行也不是漫无目的的,它要遵循一些命令或文件的内容。通过从一个网站爬到另一个网站,去跟踪和访问更多的网页,当然在Spider爬行的过程中新遇到的网站和已经更新的网站会被立刻写入索引数据库中等待搜索。当然,这也是目前最流行的一种搜集信息的方式。
预处理即是将前文中Spider抓取的页面进行分类和建立索引数据库的过程。
查询处理将搜索到的相关网页经过一定的排序算法进行排序后,然后按照一定格式将结果返还给用户。
2 基于多Agent的搜索引擎设计
2.1 Agent技术
Agent一词是由麻省理工学院(Massachusetts Institute of Technology)的Minsky在《思维的社会》一书中提出的,他认为Agent是一种实体,而且是一种存在于某一特定环境中的智能实体。该实体可以与环境中的其它实体进行某种协商从而得到问题的解。这些具有社会交互性和智能性的实体很快便被应用于计算机领域尤其是在基于网络的分布式系统中Agent表现出了明显的实效性。由于Agent的多样性,很难为其定制一个统一的结构,下面仅给出一个适用于本系统的具有感知和交互功能的简单结构模型,其结构如图2所示。

图2 Agent的五层概念结构
2.2 基于多Agent的搜索引擎研究背景
随着Internet的发展及大数据的出现发展,给人们的搜索行为带来极大的不便,怎样从资源广泛的Internet中自动搜索必要的信息,成了搜索用户关心的问题。笔者的此次设计是在传统的搜索引擎中加入了多Agent机制,通过用户和多Agent之间的相互协作,可以使搜索的结果更加的智能更趋向于用户兴趣的变化。
2.3 基于多Agent搜索引擎的主要技术
2.3.1 多Agent模块的设计
客户端多Agent的主要作用是优化用户的兴趣模型,主要有三个部分组成[3-6]:用户兴趣分析Agent,搜索行为分析Agent及兴趣处理Agent。
⑴用户兴趣分析Agent,通过用户键入的关键词在搜索引擎初始化时利用机器学习、智能推理等人工智能技术,总结出用户的兴趣。
⑵搜索行为分析Agent,通过跟踪、链接用户访问过的文档猜测用户的需求,在搜索过程中采用启发式规则来判断用户对一个文档的兴趣程度。
⑶ 兴趣处理Agent,将(1)和(2)处理后的结果提交给云端服务器,并由服务器做最终决定返回与用户兴趣密切相关的文档。
2.3.2 服务器端智能Robot的结构
基于Agent的智能Robot主要负责对相应的万维网(World Wide Web)文档进行访问,Robot的结构[7]如图3所示。
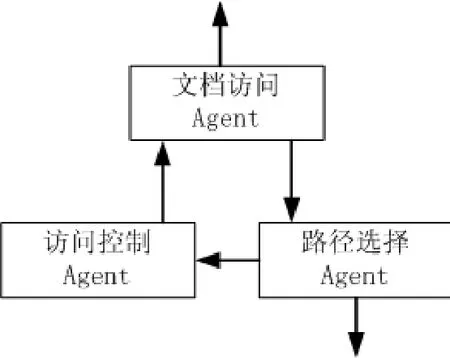
图3 智能Robot结构
文档访问Agent的功能比较简单,它从访问代理引擎那里链接URL,通过HTTP协议去访问相应的WWW文档;路径选择Agent负责提取文档访问Agent访问过的万维网文档内的链接,以选择即将要返回给用户进行浏览的路径;访问控制Agent的主要功能是控制文档访问代理机制对WWW资源的访问,以防止造成服务器和网络的堵塞。
2.4 基于多Agent的搜索引擎结构
基于多Agent的搜索引擎系统由一个或更多检索服务代理组成,每个用户使用一个用户Agent和若干个索引访问Agent。它们是由多Agent模块、页面分析处理Agent、智能Robot等几个部分组成。其基本的引擎结构如图4。

图4 多Agent搜索引擎结构
3 性能分析
为了验证基于多Agent搜索引擎系统模型设计的合理性,构造了实验仿真平台。该实验需要的硬件包括:Intel G550 CPU,4GB内存;软件环境:Mi⁃crosoft Windows XP操作系统,采用Microsoft Visual Studio 2010编程实现基于多Agent的搜索策略,与原来的搜索策略相比较,用户在相同环境下进行搜索,会得到更多更接近自己兴趣目的搜索结果。用户对不同搜索策略的满意程度见图5所示。

图5 不同搜索策略满意程度比较
4 结论
文中提出了一个基于多Agent的搜索引擎模型,详细地描述了这个模型的实现原理。在今后的工作中,我们将继续研究使搜索引擎能够根据比如访问代价、访问速度等因素对网络上的Web做进一步的索引[8-10],当然笔者将进一步改进这种模型使其更易于扩展。
[1]MILLER M E.INTELLIGENT information retrieval from the WWW[C].Canada Banff Centre:UM-999,1999.
[2]SALTON G,MCGILL M J.Introduction to Modern information Retrieval[M].New York:McGraw-Hill,1983.
[3]基于移动Agent技术的网络管理系统研究[J].电脑知识与技术,2010,6(5):1085-1088.
[4]WOOLDRIDGE M,JENNINGS N R.Intelligent agents:Theory and practice[J].The Knowledge Engineering Review,1995,10(2):115-152.
[5]RIDGE E,CURRY E.A Roadmap of Nature-inspired Systems Research and Development[J].Multi-agent and Grid System,2007,3(1):3-8.
[6]张功耀,黄水松,王小栋.基于多Agent的搜索引擎模型[J].计算机工程与设计,2002,23(10):66-69.
[7]王海腾.基于多Agent的搜索引擎优化研究[D].哈尔滨:哈尔滨工业大学,2007.
[8]张义忠,赵明生.基于内容的网页特征提取[J].计算机工程与运用,2001,37(10):1-3.
[9]毛新军,胡翠云,孙跃坤,等.面向Agent程序设计的研究[J].软件学报,2012,23(11):2886-2904.
[10]王汝川,徐小龙,黄海平.Agent机器在信息网络中的应用[M].北京:北京邮电大学出版社,2006.
Research on Search Engine Technology Based on Multi-Agent
GUO Wen-jun,QIAO Shi-dong
(School of Mathematics and Computer Science,Shanxi Datong University,Datong Shanxi,037009)
For a long time,human’s development is inseparable from the knowledge acquisition.As a result,people need a tech⁃nique which can make the access to information more simply and accurately,while search engines provide such an effective navigation tool.However,with the continued development of the Internet and Web search technology.It is more difficult for traditional search en⁃gines to meet the needs of users.Therefore,this paper proposes the concept of intelligent search engines based on multi-agent technolo⁃gy to search the web information after the deeply studying the traditional search engine and Agent technology.It can effectively improve the search engines’search quality by allowing users to perform searches in a particular domain.
search engines;multi-agent;intelligence search
TP391.3
A
1674-0874(2017)03-0004-03
〔责任编辑 高海〕
2016-07-15
郭文俊(1986-),男,山西大同人,硕士,助教,研究方向:图像处理与搜索引擎技术。
