基于改进K均值算法的滚动轴承故障诊断
2017-07-19吴德浩陈茂银周东华
吴德浩,陈茂银,周东华,2
(1.清华大学 自动化系,北京 100084;2.山东科技大学 电气与自动化工程学院,山东 青岛 266590)
基于改进K均值算法的滚动轴承故障诊断
吴德浩1,陈茂银1,周东华1,2
(1.清华大学 自动化系,北京 100084;2.山东科技大学 电气与自动化工程学院,山东 青岛 266590)
滚动轴承的故障诊断对于确保机械设备的安全可靠性有着十分重大的意义。本文采用模式识别的方法,借助振动数据对滚动轴承进行故障诊断。为了改善K均值算法极易陷入局部最优解的情况,利用粒子群算法与K均值算法进行混合聚类,设计了一种基于自适应粒子群的K均值算法,它在惯性权重的调整和学习因子的设置等方面有别于传统的混合聚类算法。提取滚动轴承振动信号的28个时域和频域特征,采用主成分分析方法进行降维处理,再分别利用三种聚类算法对滚动轴承进行故障诊断。仿真表明,基于自适应粒子群的K均值算法能够增强K均值算法的寻优能力,可以改善传统混合聚类算法容易早熟、收敛速度较慢等缺点。
滚动轴承;故障诊断;主成分分析;K均值算法;粒子群算法
滚动轴承是旋转机械设备的关键基础部件,在诸多工业领域中扮演了举足轻重的角色,其正常运行对于保障机械设备的安全可靠性至关重要。所以,滚动轴承的故障诊断在工业生产中有着非常重大的意义。
近年来,模式识别方法在滚动轴承故障诊断领域引起了很多学者的关注。该方法不需要建立系统的数学模型,而是根据轴承的振动数据来判断其工作状态,属于数据驱动的故障诊断方法[1]。从某种意义上说,对滚动轴承进行故障诊断就是对其特征模式进行识别和分类的过程[2]。
K均值算法作为一种经典的模式识别算法,凭借其简单高效的优点,在学术界和工业界都得到了广泛的应用。该方法总是沿着梯度下降的方向寻找目标函数的最优解,不同的初始聚类中心往往对应着不同的搜索路径,因此获得的最终聚类结果也不尽相同。当数据样本的维数较高、数量较大时,目标函数往往存在许多局部极小值点。若初始聚类中心未能选取得当,一般情况下只能获得局部极小值而非全局最小值。为解决此问题,许多科研人员提出了各种不同的改进方法,主要可以分为以下两类。
第一类是调整初始聚类中心的选择方法。文献[3]通过改进的非加权组平均法和最大最小距离法获得初始聚类中心,能够防止初始聚类中心的选取太过密集,从而降低初值随机选择带来的不利影响;文献[4]在数据样本密度较高的区域选取距离最远的点作为初始聚类中心,取得了不错的聚类结果,但是时间花销较大;文献[5]在充分考虑密度因素的基础上,提出一种基于最近邻相似度的方法选择初始聚类中心,可以获得良好且稳定的聚类结果,但是该方法要根据经验事先确定阈值。
第二类是基于优化算法的改进方法。文献[6]把K均值算法与模拟退火算法结合起来,充分借助了后者的强大寻优能力,显著提高了入侵检测系统的检测正确率;文献[7]将遗传算法与自适应权重结合后运用在K均值算法上,能够降低初始聚类中心对聚类效果的干扰,但算法的参数设置、操作较为复杂;部分学者将粒子群算法与K均值算法结合后进行混合聚类,取得了较好的聚类效果,但仍然存在早熟、收敛速度较慢等问题[8-9]。
在上述优化算法中,粒子群算法操作简便,收敛速度较快,拥有较好的研究与应用前景。如何有效地借助粒子群算法的优势来弥补K均值算法的不足,是本文的研究方向。在综合前人工作的基础上,设计了一种基于自适应粒子群的K均值算法,并利用美国凯斯西储大学轴承实验中心发布的滚动轴承振动数据进行仿真,良好的实验效果证明了该算法的有效性。
1 预备知识
1.1 K均值算法
K均值算法又称为K-means算法,由Lloyd于1957年首次提出,是一种经典的基于划分的聚类算法。该方法简单快捷,在数据样本较大时具有明显的优势,目前已发展成为一种成熟的聚类算法,在科研、工业等领域应用广泛[10]。
作为一种基于距离的聚类算法,K均值算法以距离来度量数据对象之间的相似性。该算法通常以误差平方和函数作为优化目标函数,其计算公式为

(1)
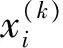
K均值算法的主要步骤和流程[11]如图1所示。
1.2 粒子群算法
粒子群(particle swarm optimization, PSO)算法是Kennedy和Eberhart等[12]开发的一种智能仿生算法,其灵感来自于对鸟群觅食行为的探究,该方法通过群体之间的协作搜索获得最优解。


图1 K均值算法流程图Fig.1 Flow chart of the K-means algorithm
粒子的属性通过迭代进行更新。对于第i个粒子,它在第t+1次迭代中的速度分量和位置分量[12]分别为

(2)
xij(t+1)=xij(t)+vij(t+1)。
(3)

以上即是基本粒子群算法。为了增强基本粒子群算法的搜索能力,学者们在此基础上提出了标准粒子群算法[13],二者的不同之处在于后者在速度更新公式中增加了惯性权重w。改进后的速度更新公式为
(4)
在大部分文献中,普遍使用的“惯性权重线性递减策略”来更新惯性权重w,即

(5)
其中,t表示当前迭代次数,tmax表示算法的最大迭代次数,wmax、wmin分别表示惯性权重w的最大值和最小值。
2 基于自适应粒子群的K均值算法
为了改善K均值算法极易陷入局部最优解的缺陷,同时也为了解决基于传统粒子群的K均值算法存在的容易早熟和收敛速度较慢等问题,本文综合文献[14]和[15]的工作,设计了一种基于自适应粒子群的K均值算法。
2.1 算法设计
1)适应度函数
根据聚类的实际需求,选用误差平方和准则函数作为粒子的适应度函数[14],即
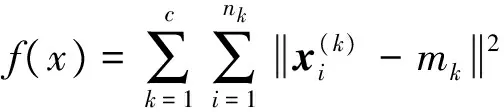
(6)
聚类的效果与f(x)有着紧密的联系,粒子的适应度值(误差平方和)越小,对应的聚类效果越好。
2)惯性权重
惯性权重是粒子飞行速度的系数,能够使粒子群的全局搜索能力与局部搜索能力维持较好的平衡。目前很多的文献都是采用式(5)所示的“惯性权重线性递减策略”对惯性权重进行更新。在这种策略之下,每次迭代中惯性权重的变化量都是固定的,不利于算法尽快地收敛。
在本文中,采取一种自适应调整策略[15]对惯性权重进行更新。对于第i个粒子,它在第t次迭代中的惯性权重为

(7)

根据式(7)调整惯性权重,一方面,惯性权重会随着迭代次数的增加而逐渐减小,初期较大的惯性权重有助于防止算法陷入局部极值点,后期较小的惯性权重有助于算法尽快地收敛;另一方面,该策略还会根据全局最优解和个体最优解的适应度值自适应地更新惯性权重,可以进一步加快算法的收敛速度。
3) 学习因子
为了使算法较快地收敛于全局最优解,获得更快的收敛速度和更高的收敛精度,可以让学习因子c1、c2随着迭代次数的增加进行动态调整。学习因子c1、c2的具体设置如下

(8)
其中,t表示当前迭代次数,tmax表示算法的最大迭代次数,cmax、cmin分别表示学习因子的最大值和最小值。
在算法初期,c1的值较大,c2的值较小,有助于粒子在各自附近的区域进行广泛搜索,避免种群陷入局部极值点;在算法后期,c1的值较小,c2的值较大,有助于粒子朝着种群最佳位置进行搜索,从而有效地改善算法的收敛速度及精度。
4) 飞行时间因子
借鉴鸟群在飞行的过程中飞行时间不断变化的特点,在位置更新公式中引入飞行时间因子。改进后的位置更新公式[14]为
xij(t+1)=xij(t)+s(t)×vij(t+1)。
(9)
式(9)中s(t)表示飞行时间因子,是调整粒子搜索步长的重要系数,其更新公式为
(10)
其中,s0称为飞行时间常数,t表示当前迭代次数,tmax表示最大迭代次数。
根据式(10)可以知道,随着迭代次数的增加,飞行时间因子不断减小,粒子搜索步长也会相应地减小,这有利于加快算法的收敛速度。
2.2 算法的步骤和流程图
基于自适应粒子群的K均值算法的具体步骤为:
1)算法参数初始化,即设置粒子数、最大迭代次数、惯性权重、学习因子、粒子的速度和位置、个体最优解以及全局最优解等参数的初始值;
2)根据适应度函数求出每个粒子的适应度值,并以此为依据更新粒子的个体最优解和种群的全局最优解;
3)按照式(4)和式(9)分别更新各个粒子的速度和位置,其中惯性权重、学习因子和飞行时间因子分别按照式(7)、式(8)和式(10)进行计算;
4)依据粒子的位置获得聚类中心,对各个数据样本进行聚类分析,并依据新的划分结果重新计算聚类中心;
5)如果满足终止条件(聚类中心不再变化或达到最大迭代次数)则结束算法迭代,否则返回步骤(2)进行下一轮迭代。
基于自适应粒子群的K均值算法的流程图如图2所示。
3 仿真实验
3.1 特征提取
本文使用的数据是由美国凯斯西储大学轴承实验中心发布的滚动轴承振动数据[16]。实验的滚动轴承是6205-2RS JEM SKF深沟球轴承,转速为1 797 rpm,故障直径设置为0.177 8 mm,存在正常、内圈故障、外圈故障或滚动体故障等四种不同状态的轴承。对这四种不同状态的滚动轴承,以12 kHz的采样频率采集其振动数据,每种状态各截取100个样本,每个样本的数据点数为1 024点,共计400个样本。

图2 基于自适应粒子群的K均值算法流程图Fig.2 Flow chart of the adaptive PSO-K-means algorithm
当滚动轴承产生故障时,其振动信号的波形特征、能量大小以及频率分布都有可能发生改变。因此,从轴承振动信号中提取的一些时域和频域特征,可以用于指示它是否发生了故障。
为了能够全方位地获取滚动轴承的振动信息,从滚动轴承的振动信号中提取了14个时域特征参数及14个频域特征参数[17-18],特征表达式见表1和表2。其中,xi表示时域信号序列,i=1,2,…,n,n是样本点数;y(k)表示时域信号xi的频谱,fk表示第k条谱线的频率值,k=1,2,…,K,K代表谱线条数。p1~p14为信号的时域特征参数,其中既包括均值、方差等有量纲参数,又包括脉冲因子、波形因子等无量纲参数。p15~p28为信号的频域特征参数,其中包括均值频率、重心频率等,这些参数分别从振动能量、频谱位置等方面对信号的频域特征进行描述[18]。


(11)
式中,max(pi)表示轴承数据特征参数pi的最大值,min(pi)表示轴承数据特征参数pi的最小值。

表1 时域特征参数Tab.1 Time-domain characteristic parameters

表2 频域特征参数Tab.2 Frequency-domain characteristic parameters
3.2 特征降维
表1和表2中的28个特征参数构成了高维数据集,它们能比较全面地反映轴承的运行状况。但由于各个特征参数之间具有一定的相关性,导致该数据集存在一些冗余。如果直接利用此高维数据集进行聚类分析,算法的计算量相当大,而且特征冗余会使算法不能把握本质信息,进而造成算法聚类准确率的下降。因此本文利用主成分分析(principal comporent analysis, PCA)的方法对标准化之后的参数进行特征降维,获得的最终结果记录于表3中。

表3 主成分分析结果Tab.3 Results of principal component analysis
一般情况下,如果前k个主成分的累计贡献率超过80%,可以认为它们能够较好地表征原始数据。从表3中的结果可知,前2个主成分的累计贡献率已经达到89.61%。所以,本文中选取前2个主成分来表征由28个特征参数组成的高维数据集,从而达到了降低维数和消除冗余的目的。
3.3 故障诊断
在MATLAB环境下进行仿真实验,对降维之后的数据集进行聚类分析和故障诊断。对于四种不同状态的轴承振动信号特征数据集,每个状态包含100个样本,选择其中50个样本当作训练样本,另外50个样本当作测试样本。在MATLAB中,分别利用K均值算法、基于传统粒子群的K均值算法和基于自适应粒子群的K均值算法对轴承振动信号特征数据集进行聚类分析和故障诊断。
基于传统粒子群的K均值算法的参数设置为:粒子数m=5,最大迭代次数tmax=50,学习因子c1=c2=2;采用惯性权重线性递减策略,其中wmax=0.9,wmin=0.2。
基于自适应粒子群的K均值算法的参数设置为:粒子数m=5,最大迭代次数tmax=50;根据式(8)更新学习因子c1、c2,其中cmax=2,cmin=1;根据式(7)更新惯性权重w,其中wmax=0.9,wmin=0.2;根据式(10)更新飞行时间因子s(t),飞行时间常数s0=1.5。
多次运行K均值算法及其两种改进算法,统计这三种算法的各项数据指标,并计算其平均值,记录于表4中。

表4 三种算法的性能比较Tab. 4 Performance comparisons of three algorithms
从上表可以看出,相对于K均值算法而言,上述两种改进算法的时间开销都有所增加,但训练和测试的正确率有了明显的提高。这说明上述两种改进算法都继承了粒子群算法的优点,能够在全局搜索与局部搜索之间达到较好的平衡,有助于改善K均值算法极易陷入局部最优解的缺点。
同时也可以看到,相比于基于传统粒子群的K均值算法,所设计的基于自适应粒子群的K均值算法的收敛速度更快,并且训练和测试的正确率都有较大的提高。所以,本文设计的基于自适应粒子群的K均值算法,能够改善传统的混合聚类算法存在的容易早熟和收敛速度慢等情况。
4 结论
主要针对K均值算法容易陷入局部最优解的缺陷,同时也为了解决基于传统粒子群的K均值算法存在的容易早熟和收敛速度较慢等问题,设计了一种基于自适应粒子群的K均值算法。该方法主要在以下三个方面与传统的混合聚类算法有所区别:一是采用一种自适应惯性权重调整策略,综合考虑迭代次数、个体最优解和全局最优解的适应度值等因素来计算惯性权重;二是学习因子不再设为定值,而是随着迭代次数进行动态调整;三是从飞行时间不断变化的角度,在位置更新公式中引入飞行时间因子。
将基于自适应粒子群的K均值算法应用于滚动轴承的故障诊断中。仿真表明使用该方法聚类的正确率较高,原因在于它能够在一定程度上避免陷入局部最优解;且相比于基于传统粒子群的K均值算法,该方法不易早熟,收敛速度有所提高,可以获得更好的故障诊断效果。
[1]欧璐,于德介.基于拉普拉斯分值和模糊C均值聚类的滚动轴承故障诊断[J].中国机械工程,2014,25(10):1352-1357. OU Lu,YU Dejie.Rolling bearing fault diagnosis based on Laplacian score and fuzzy C-means clustering[J].China Mechanical Engineering,2014,25(10):1352-1357.
[2]杨宇,王欢欢,曾鸣,等.基于变量预测模型的模式识别方法在滚动轴承故障诊断中的应用[J].湖南大学学报(自然科学版),2013,40(3):36-40. YANG Yu,WANG Huanhuan,ZENG Ming,et al.Application of pattern recognition approach based on VPMCD in roller bearing fault diagnosis[J].Journal of Hunan University (Natural Sciences),2013,40(3):36-40.
[3]张永晶.初始聚类中心优化的K-means改进算法[D].长春:东北师范大学,2013:15-23.
[4]李宇泊.K均值算法初始聚类中心选取相关问题研究[D].兰州:兰州交通大学,2012:28-45.
[5]孙可,刘杰,王学颖.K均值聚类算法初始质心选择的改进[J].沈阳师范大学学报(自然科学版),2009,27(4):448-450. SUN Ke,LIU Jie,WANG Xueying.K mean cluster algorithm with refined initial center point[J].Journal of Shenyang Normal University (Natural Science Edition),2009,27(4):448-450.
[6]胡艳维,秦拯,张忠志.基于模拟退火与K均值聚类的入侵检测算法[J].计算机科学,2010,37(6):122-124. HU Yanwei,QIN Zheng,ZHANG Zhongzhi.Intrusion detection algorithm based on simulated annealing and K-mean clustering[J].Computer Science,2010,37(6):122-124.
[7]李婷婷.改进K-means聚类算法的研究[D].合肥:安徽大学,2015:27-31.
[8]崔红梅.基于改进粒子群算法的C-均值聚类算法研究[D].南京:南京师范大学,2007:18-27.
[9]陈小全,张继红.基于改进粒子群算法的聚类算法[J].计算机研究与发展,2012,49(增1):287-291. CHEN Xiaoquan,ZHANG Jihong.Clustering algorithm based on improved particle swarm optimization[J].Journal of Computer Research and Development,2012,49(S1):287-291.
[10]李卫军.K-means聚类算法的研究综述[J].现代计算机,2014(8):31-32. LI Weijun.Summary of K-means algorithm for clustering[J].Modern Computer,2014(8):31-32.
[11]欧陈委.K-均值聚类算法的研究与改进[D].长沙:长沙理工大学,2011:19-20.
[12]JAMES K,RUSSELL E.Particle swarm optimization[C]//Proceedings of IEEE International Conference on Neural Networks,IEEE Press, 1995:1942-1948.
[13]SHI Y,EBERHART R.Modified particle swarm optimizer[C]//Proceedings of IEEE International Conference on Evolutionary Computation IEEE Press,1998, 1998:69-73.
[14]周虹.基于自适应粒子群的k-中心聚类算法研究[D].长沙:长沙理工大学,2012:25-28.
[15]刘悦婷,李岚.基于自适应权重的粒子群和K均值混合聚类算法研究[J].甘肃科学学报,2010,22(4):106-109. LIU Yueting,LI Lan.K-Means and particle swarm optimization cluster algorithm based on adaptive inertia weight[J].Journal of Gansu Sciences,2010,22(4):106-109.
[16]LOPARO K A.Bearing Data Center of Case Western Reserve University[DB/OL].http://csegroups.case.edu/bearingdatacenter/pages/download-data-file.
[17]孙建.滚动轴承振动故障特征提取与寿命预测研究[D].大连:大连理工大学,2015:24-26.
[18]LEI Y,HE Z,ZI Y.A new approach to intelligent fault diagnosis of rotating machinery[J].Expert Systems with Applications,2008,35(4):1593-1600.
(责任编辑:傅 游)
Fault Diagnosis of Rolling Bearing Based on Improved K-means Algorithm
WU Dehao1, CHEN Maoyin1, ZHOU Donghua1,2
(1. Department of Automation, Tsinghua University, Beijing 10084, China;2. College of Electrical Engineering and Automation, Shandong Universityof Science and Technology, Qingdao, Shandong 266590, China)
Fault diagnosis of rolling bearings is significant to the safety and reliability of mechanical equipment. In this paper, the pattern recognition method is used to diagnose faults of the rolling bearing based on its vibration data. Since the K-means algorithm easily falls into the local optimal solution, we design the adaptive PSO-K-means algorithm by combining particle swarm optimization (PSO) with the K-means algorithm, which is different from the traditional hybrid-clustering algorithm in inertia weight and learning factor. We extract twenty-eight characteristics of the vibration signal in time domain and frequency domain, adopt principle component analysis (PCA) to reduce the dimension of the characteristics, and then use three clustering algorithms to diagnose faults of the rolling bearing. Simulations show that the adaptive PSO-K-means algorithm can improve the searching capability of the K-means algorithm. Compared with the traditional hybrid-clustering algorithm, the adaptive PSO-K-means algorithm can partly overcome the shortcomings of premature convergence and slow convergence.
rolling bearing; fault diagnosis; principal component analysis; the K-means algorithm; particle swarm optimization
2017-02-25
国家自然科学基金项目(61490701,61210012,61290324,61473164)
吴德浩(1993—),男,江西崇义人,博士研究生,主要从事动态系统故障诊断与剩余寿命预测的研究. 周东华(1963—),男,江苏江阴人,教授,博士生导师,主要研究方向为动态系统的故障诊断与容错控制、故障预测与最优维护技术,本文通信作者. E-mail: zdh@mail.tsinghua.edu.cn
TP277
A
1672-3767(2017)04-0001-08
10.16452/j.cnki.sdkjzk.2017.04.001
