基于直觉模糊集的术语相似度方法研究
2017-07-18李战军闫绍惠
李战军,闫绍惠
(河北软件职业技术学院 软件工程系,河北 保定 071000)
基于直觉模糊集的术语相似度方法研究
李战军,闫绍惠
(河北软件职业技术学院 软件工程系,河北 保定 071000)
直觉模糊集的术语相似度方法基于直觉模糊集进行术语相似度评估,首先采用TFIDF方法提取特征项,然后定义特征项之间的直觉模糊相似度,最后根据直觉模糊集相似度的计算结果,进行术语相似度评估。该方法符合真实评估思维,评估结果接近实际。
直觉模糊集;相似度;特征项;术语
0 引言
随着大数据与云计算技术的大规模应用,在翻译领域实现了翻译技术与云计算技术的结合,建立了新型的中日对译云端语料库。通过翻译数据的规模化处理,进一步促进翻译产业的技术进步和迅猛发展。在构建中日对译云端语料库的过程中,术语之间的相似度评估是一项基本任务。术语相似度计算对海量的中日大数据处理、信息提取,收集、整理对译语料具有重要意义。
相似度计算方法研究是信息处理过程中的一项基础性工作。相似度计算方法在信息处理领域的应用比较广泛,例如信息提取与分析[1,2]、文本挖掘与聚类[3-4]、机器翻译[5]等。刘宏哲等人[6]对基于本体的语义相似度和相关度计算研究做了综述。分析并总结了树和图中影响概念相似度或者相关度的因素,系统地分析了语义相似度和相关度计算方法。盛秋艳[7]给出了一种基于本体的语义相似度计算方法,提出了利用本体来表示概念之间的关系,根据概念之间的相关性构建本体结构层次网络图通路,并且计算语义相似度实现检索。陈海燕[8]提出了基于搜索引擎的词汇语义相似度计算方法,这种计算方法可以去除计算过程中的噪音和冗余,并且不需要任何先验知识与本体就可以计算语义相似度。范雪雪、王志荣等人[9]依据医学本体的层级结构和语义关系,提取出术语的深度、距离等语义参数,利用概念密度加权得到深度系数和距离系数,构造相似度函数,计算术语相似度。
目前术语相似度计算方法研究都是基于本体进行的。本文的术语相似度算法研究是基于直觉模糊集的。直觉模糊集[10]包含三个方面,即隶属度、非隶属度和犹豫度。在实际生活中,人们对于大部分事物的分析与研究往往带有不确定性和模糊性,直觉模糊集的概念符合人们对事物的评估准则。本文首先根据TFIDF方法提取特征项,构建特征矩阵,然后定义特征矩阵的直觉模糊集,最后根据直觉模糊集相似度计算方法评估术语相似度。
1 直觉模糊集理论
Zadeh[11]在1965年提出模糊集理论之后,模糊集被广泛应用到各个领域,例如数据挖掘、信息处理、控制论、运筹学、军事应用等。随后Atanassov[10]对模糊集进行了扩展,提出了直觉模糊集,并将直觉模糊集划分为隶属度、非隶属度和犹豫度三个方面。定义1给出了直觉模糊集的概念。
龚艳冰,丁德臣等人[12]对模糊集理论进行了扩充,依据直觉模糊集相似度[13],提出了基于直觉模糊集相似度的多属性决策方法。
定义2 已知映射S:IFS(X)×IFS(X)→[0,1],称S(A,B)为直觉模糊集A∈IFS(X)与B∈IFS (X)的相似度,如果S(A,B)满足下列性质:
(1)0≤S(A,B)≤1;
(2)如果A=B,则S(A,B)=1;
(3)S(A,B)=S(B,A);
(4)如果A⊆B⊆C,A,B,C∈IFS(X),则S(A,C)≤S(A,B),S(A,C)≤S(B,C)。
对于论域X={x1,x2,…,xn,}上的任意两个直觉模糊集可以设:
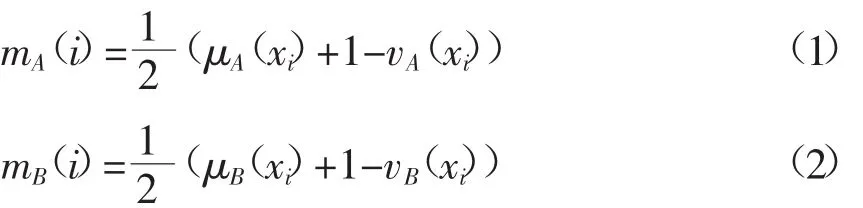
那么令:
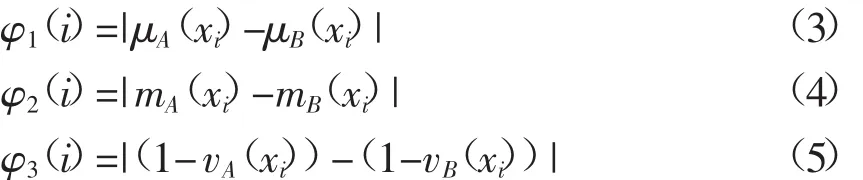
则定义直觉模糊集相似度的计算公式为:
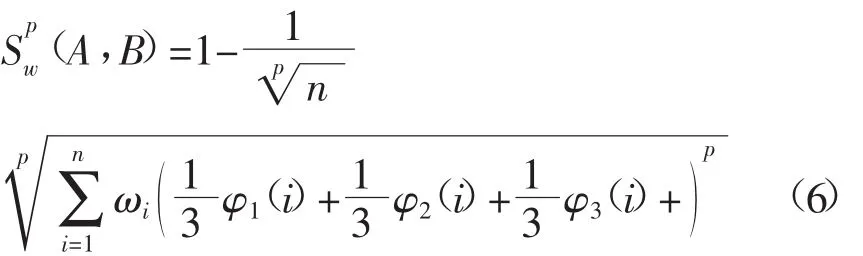
其中,ωi≥0为xi在论域X中的权重,且满足
2 基于直觉模糊集的术语相似度算法
术语相似度可以根据术语所在的知识领域不同进行评估。通常来说,两个术语在不同的上下文环境中可以相互替换而不影响语法,语义结构越大,术语相似度越大。术语相似的评估没有确定性的标准,术语之间的相似度具有模糊性,根据选取的角度不同,得到的相似度值不同。本文首先基于TFIDF方法提取特征项,然后根据特征项与选取的术语计算相关性,最后根据术语相似度直觉模糊集公式计算相似度值。具体步骤如下:
(1)根据TFIDF方法提取特征项。根据评测术语所在的知识领域,使用TFIDF方法提取上下文中的相关词。
(2)构建特征项矩阵。使用TFIDF方法提取上下文中的相关词,根据接续指数计算词语的权重,依据权重选取特征项,并构建特征矩阵。其中,矩阵值为权重值。
(3)将特征项矩阵转换为直觉模糊集。特征项的权重值越大,说明该特征项与术语接续指数越大,那么特征项与术语具有更高的组合程度。本文将权重值作为直觉模糊集的隶属度
(4)根据直觉模糊集相似度公式(6)计算术语相似度值。为了计算权重ωi,这里假设vi,同时满足
3 实验结果分析
首先下载由复旦大学计算机信息与技术系国际数据库中心自然语言处理小组提供的公开中文文本分类语料库,以该语料库为依托提取特征项,并进行术语相似度分析。该语料库包括测试语料(共9 833篇文档)和训练语料(共9 804篇文档),分为20个类别。本文以其中100篇教育技术领域的文档作为数据集,采用TFIDF方法进行特征项提取,并计算特征隶属度,选取其中前200个特征项作为评估指标。
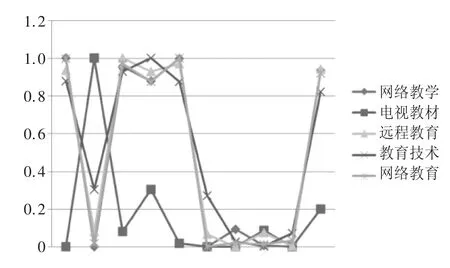
图1 相似度曲线图
在特征项矩阵中,术语作为行数据,特征项作为列数据,隶属度作为矩阵元素值。然后利用直觉模糊集相似度公式计算术语相似度值。图1为部分测试数据的相似度曲线图。根据曲线图可以看出,除电视教材外,其他曲线图近似。那么网络教学、远程教育、教育技术及网络教育具有较高的相似度。
4 结语
本文提出基于直觉模糊集的术语相似度计算方法。根据TFIDF方法构建特征项矩阵,并运用直觉模糊集相似度计算方法计算术语相似度值。该算法利用直觉模糊集理论评估术语相似度符合实际生活中对事物的评估方式。对于精确值的选取是今后需要进一步研究的工作。
[1]Chen M Y,Chu H C,Chen Y M.Developing a Semantic-Enable Information Retrieval Mechanism[J].Expert Systems with Application,2010,37(1):322-340.
[2]Stevenson M,Greenwood M A.A Semantic Approach to IE Pattern Introduction[C].In:Proceedings of the 43rd Annual Meeting on Association for Computational Linguistics.Association for Computational Lin guistics,2005:379-386.
[3]Asservatham S,Bennani Y.Semi-Structured Document Categorization with a Semantic Kernel[J].Pattern Recognition,2009,42(9):2067-2076.
[4]Batet M,Valls A,Gibert K.Improving Classical Clustering with Ontologies[C].In:Proceedings of the 4th World Conference of the IASC,Yokohama,Japan,2008:137-146.
[5]Cilibrasi R L,Vitanyi P M B.The Google Similarity Distance[J].IEEE Transactions on Knowledge and Data Engineering,2007,19(3):370-383.
[6]刘宏哲,须德.基于本体的语义相似度和相关度计算研究综述[J].计算机科学,2012,39(2):8-13.
[7]盛秋艳.一种基于本体的语义相似度计算方法[J].情报科学,2012,30(8):1238-1241.
[8]陈海燕.基于搜索引擎的词汇语义相似度计算方法[J].计算机科学,2015,42(1):261-267.
[9]范雪雪,王志荣,徐晤,等.基于医学本体的术语相似度算法研究[J].现代图书情报技术,2015,265(12):57-62.
[10]Atanassov K T.Intuitio nist ic fuzzy sets[J].Fuzzy Sets and Systems,1986,20(1):87-96.
[11]Zadeh L A.Fuzz y sets[J].Information and Control,1965,8(3):338-356.
[12]龚艳冰,丁德臣,何建敏.一种基于直觉模糊集相似度的多属性决策方法[J].控制与决策,2009,24(9):1398 -1401.
[13]Li D,Cheng C.New similarity measures of intuitionistic fuzzy sets and application to pattern recognition[J]. Pattern Recognition Letters,2002,23(1):221-225.
Research on Term Similarity Method based on Intuitionistic Fuzzy Sets
LI Zhan-jun,YAN Shao-hui
(Department of Software Engineering,Hebei Software Institute,Hebei Baoding 071000,China)
The term similarity method of intuitionistic fuzzy sets is based on the evaluation of intuitionistic fuzzy sets. Firstly,the TFIDF method is used to extract the feature items,and then the intuitionistic fuzzy similarity between the feature items is defined;finally,according to the calculation results of the intuitionistic fuzzy set similarity to evaluate the similarity of term.The method is consistent with the real evaluation thinking,and the evaluation results are close to the actual situation.
intuitionistic fuzzy set;similarity;feature;term
TP319
A
1673-2022(2017)02-0039-03
2016-12-16
2015年度河北省科技计划自筹经费项目“基于大数据和云计算技术的科技翻译语料库创建及应用研究”(15210145);河北软件职业技术学院2013年院立课题“外贸电子商务‘云翻译平台’建设可行性研究”(YL2013L002)
李战军(1975-),男,河北徐水人,副教授,硕士,主要从事日语教学及日语语料库研究;闫绍惠(1988-),女,河北承德人,助教,硕士,主要从事数据挖掘、数据分析。
