微博内容自动抽取方法研究
2017-07-18冯海涛黄炎一余小婷
冯海涛,李 琳,黄炎一,余小婷
(1.武汉理工大学 计算机科学与技术学院,湖北 武汉430070;2.空军预警学院黄陂士官学校,湖北 武汉430021;3.华中科技大学 管理学院,湖北 武汉430074)
微博内容自动抽取方法研究
冯海涛1,2,李 琳1,黄炎一3,余小婷1
(1.武汉理工大学 计算机科学与技术学院,湖北 武汉430070;2.空军预警学院黄陂士官学校,湖北 武汉430021;3.华中科技大学 管理学院,湖北 武汉430074)
在采用分类机器学习算法的基础上,提出有效的特征集,实现不同微博平台上内容的自动抽取。根据对微博页面的预处理粒度不同,讨论了token和line两种粒度。在特征选取方面沿用了传统的Text-to-Tag Ratio,并结合微博内容文本的相关特性,提出了Text-to-Text Relation和Post-Social特征。实验结果表明,支持向量机与Text-to-Tag Ratio、Text-to-Text Relation和Post-Social 3个特征相结合的抽取结果最佳。
微博内容抽取;机器学习;特征选择
微博是互联网时代的主要信息传播途径,对其进行文本内容分析和检索成为研究热点[1-3]。微博内容抽取主要是从一个HTML页面中提取微博的主要文本内容的过程。传统的方法通过人工分装器(handcrafted wrapper)从HTML页面中提取内容的方法十分脆弱,一旦网页的格式发生变化就无法工作[4]。Finn等[5]提出了Body Text Extraction(BTE)算法,通过识别文本比标签出现更频繁的区域来抽取一个单独连续的块。为解决BTE只能识别单一连续文本块的问题,Gottron[6]应用了Document Slope Curves(DSC)算法。BTE和DSC的要旨在某种程度上与基于line的CETR方法[7]相似,二者都考虑了标签和文本的相关性。Pasternack等[8]介绍了Maximum Subsequence Segmentation(MSS),结合了token级别的朴素贝叶斯分类器和最大得分序列(maximum scoring sequence)来预测文档的主要内容区域。
Weninger等[7]提出了Content Extraction via Tag Ratios(CETR),使用Text-to-Tag Ratio(TTR)和k-means聚类方法从web页面中抽取文本内容。但是在微博领域,用户发布的微博内容都很简短,跟非主要内容区域的TTR的值可能重叠得很多,因此不能单一地根据每一行的TTR来判断是否是文本块。Debnat等[9]提出了FeatureExtractor(FE)和K-FeatureExtractor(KFE)。KFE方法采用了k-means聚类来选择多个内容块,弥补了FE只能选取一个单一的内容块的缺点。微软亚洲学院提出了Vision-based Page Segmentation(VIPS)。基于视觉的分块方法的思想是通过分析页面的可视布局获知内容的相干性,将一个web页面划分成块[10]。Gibson等人[11]将内容识别视为一系列标注问题,这些序列即HTML块。条件随机场(CRF)[12]、最大熵分类器和最大熵马尔可夫模型(MEMM)[13]这3个序列标注模型也被应用于抽取web页面的内容。
当前的内容抽取技术较依赖于web页面的结构与内容,导致适应性较差[14]。因此,本文提出了Text-to-Text Relation和Post-Social特征,并结合分类机器学习算法实现微博内容自动抽取,可以应用于不同页面结构的微博平台。
1 Text-To-Tag Ratio特征
Text-to-Tag Ratio(TTR)是和计算每一行的文本与标签的比率。在文献[15]中结合了TTR与K-means方法,用于从web页面中抽取文本信息。它不考虑网页的多媒体形式,着重考虑文本-标签的关系。特征计算方法如下。

计算TTR之前,需要将HTML文档中的script、remark标签,否则这些标签中的内容会被当作非标签文本计算,从而影响抽取结果。HTML文档中的空行也要清除,以免给算法的性能带来不好的影响。在计算过程中,如果存在某行的标签数量为0,那么将比率的值设为该行的文本的长度。
2 Text-To-Text Relation特征
Text-to-Text Relation描述的是微博正文内容(即post)与其上下文的关系。上下文就是指跟随在post后面的发布时间和“来自…….(客户端)”的属性信息和“转发”、“评论”、“赞”、“收藏”等功能标签。Text-to-Text Relation的取值为0或1。在一个样本页面中,若某个文本块后面邻近的文本块中分别出现“来自”、“转发”、“评论”、“赞”、“收藏”等关键字至少4次,那么该行的Text-to-Text Relation特征值为1。之所以设置为4次,是因为在新浪、腾讯、网易的3种页面中,post后面所跟随的上下文的具体内容存在差异。
3 Post-Social特征
考虑到微博的特有社会属性,提出了Post-Social的特征,也就是判断一个文本块是否具有post文本的特有属性。Post文本的特有属性在不同的微博平台表现的形式也略有差异。总体来说,post文本的特有属性就是包含“@”、“#.......#(话题标签)”等特殊符号。若当前文本块中包含特有符号,则标记该Post-Social属性的值为1,否则该特征值为0。本文主要围绕Text-to-Tag Ratio、Text-to-Text-Relation和Post-Social这3个特征讨论抽取算法的精度。
4 自动抽取方法
对于微博内容自动抽取,不管是基于token,还是基于line,其算法的基本流程是相似的。主要概括为:
(1)获取微博页面集,并对其做预处理,过滤HTML标签并完成人工标注。
(2)选取特征,构建特征向量。
(3)构建训练集和测试集
(4)通过相应的机器学习的方法来对训练数据进行学习得到模型。
(5)对测试数据进行类别预测,获取属于数据。
考虑的数据粒度不同,本文对基于token的微博内容抽取分别应用了朴素贝叶斯(NB)[15-16]和条件随机场(CRF)[17-19]2个方法。基于line的微博内容抽取方法主要使用了朴素贝叶斯和支持向量机(SVM)[18]2种方法。
5 实验结果与分析
5.1 实验数据集
本文的实验数据来自新浪、腾讯和网易三大平台,分别按照板蓝根、奔跑吧兄弟、习大大、快递小哥、广场舞大妈、Google解封等100个热门话题来采集微博页面。然后获得纯文本数据集,选取相应的特征,组成特征向量。对于每一条数据,都事先进行人工标注,标记其类别(post或则non-post)。
实验数据集按照训练和测试的用途分别放入各自的文件夹。源数据在划分训练样本集以及测试样本集的时候,依据相应的比例随机划分训练样本集及测试样本集。本文中采用了40%~60%,60%~40%和80%~20%3类比例各异的训练-测试样本集作为实验数据。在同一种比例下,随机生成5组不同训练-测试样本集。最终每个方法所对应的各项指标是取5组实验结果所得的平均值。这样可避免个别因素的影响,对算法的评估更具有可靠性。
5.2 基于Token的实验结果
表1~表3中涉及到3种特征集,其中单个特征的1F-1是指Text-to-Tag Ratio,1F-2是指Text-to-Text Relation,而2F是指Text-to-Tag Ratio和Text-to-Text Relation 2个特征的组合。从表中的数据来看,在同一个机器学习方法的条件下,采用不同特征集进行分类,2个特征组合的分类效果会比单个特征的好。在CRF中,相比较1F-1、1F-2以及2F特征下的类别预测的结果,准确率和召回率都逐一提高了,呈现阶梯形变化,而且基于两个特征2F的分类效果明显超越了单个特征1F-1和1F-2,表现出的分类性能最佳。在朴素贝叶斯分类器中,若只用Text-to-Tag Ratio和Text-to-Text Relation中的1个特征作为分类依据,分类效果不好。正如表中记录的结果,其准确率和召回率都的值为0。
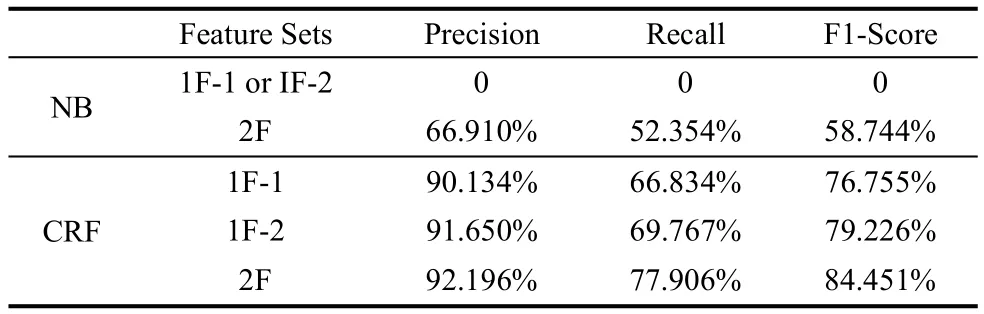
表1 基于Token的算法实验结果(40%~60%)
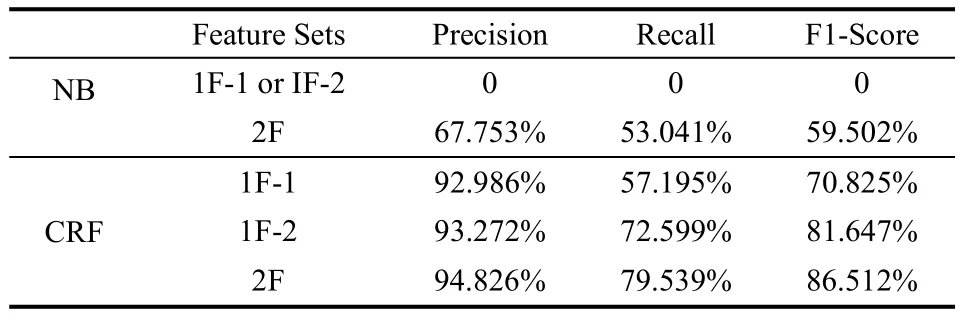
表2 基于Token的算法实验结果(60%~40%)
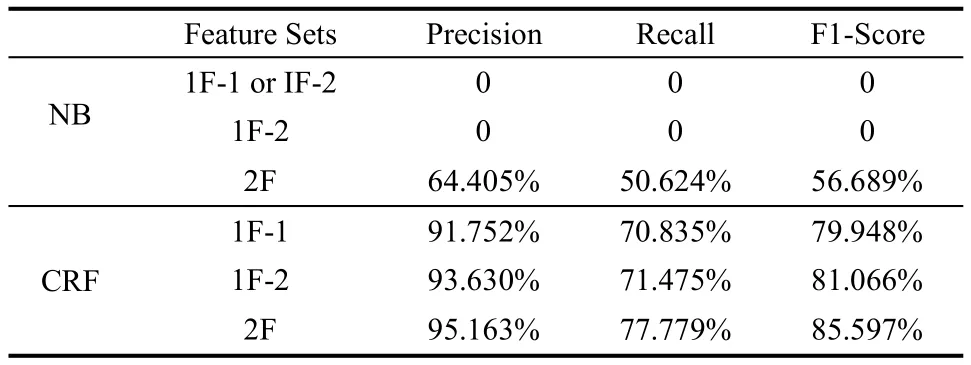
表3 基于Token的算法实验结果(80%~20%)
因此对于朴素贝叶斯分类器,2个特征才能对类别预测效果起作用。比较2F特征情况下朴素贝叶斯和条件随机场的分类性能,从表中数据可知,条件随机场表现的准确率、召回率都比朴素贝叶斯的高出25%左右。可见在同一特征条件下,选用条件随机场算法比基于token的微博分类效果好。
5.3 基于Line的实验结果
在表4~表6中3F是指将social-post特征与前面2种特征融合。从实验结果可以看到,基于3F特征的分类所表现的性能明显优于2F。而对于同一个特征集为算法输入的条件下,基于支持向量机方法的2F和3F表现出的性能分别高于朴素贝叶斯的2F和3F的分类效果。在3组不同比例的实验中,采用基于3F的SVM算法,准确率都超过90%,召回率都接近于88%,F1值也达到了90%左右,表现出较好的识别精度。
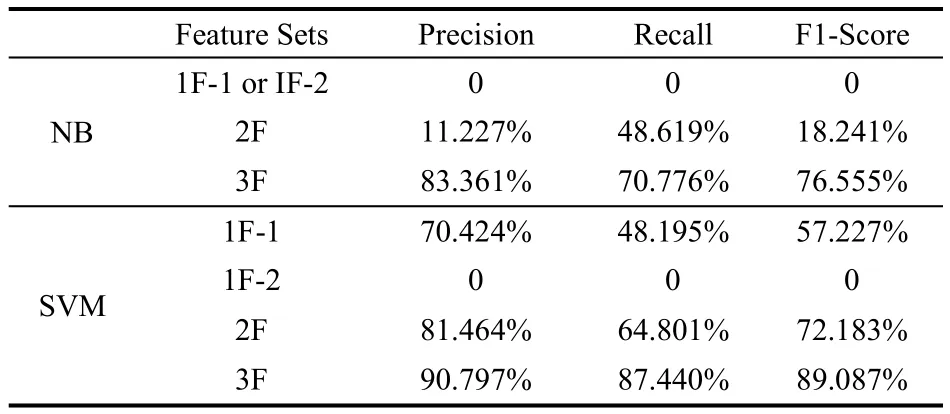
表4 基于Line的算法实验结果(40%~60%)
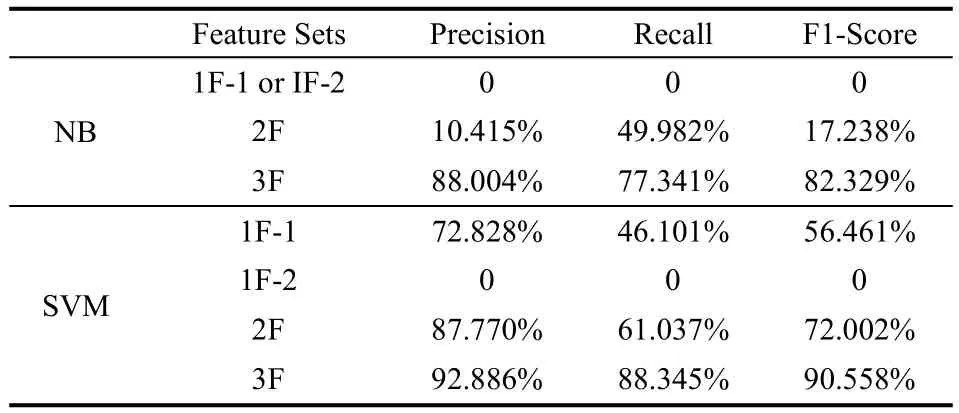
表5 基于Line的算法实验结果(60%~40%)
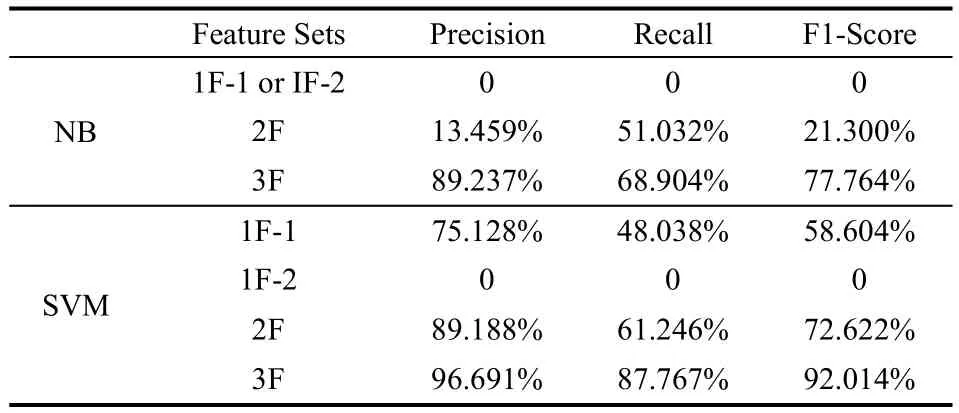
表6 基于Line的算法实验结果(80%~20%)
总之,在基于Line的内容抽取中,采用80%~20%的训练-测试集,结合传统的Text-to-Tag Ratio特征和提出的Text-to-Text Relation和Post-Social特征,将3个特征和SVM算法结合,能够得到最好的内容提取精度。同时由于token粒度偏细小,无法提取post-social特征,整体精度不如line粒度的处理方法。
6 结论
本文将对不同微博平台帖子内容的抽取问题转化成对微博页面纯文本块的分类问题,从而减少了页面结构不同对抽取算法的影响[20]。对于基于Token的数据集,条件随机场表现出的对微博页面中post的识别性能较好,特别是它与Text-to-Tag Ratio、Text-to-Text Relation特征相结合的效果。而基于Line的数据集,采用支持向量机,使用Text-to-TagRatio、Text-to-TextRelation和Post-Social这3个特征的分类结果最佳。本文实验的范围有限,只是针对新浪、腾讯和网易3个微博平台,而且由于人工标记难度大,所采用的微博数据量也相对较少。以后可以进一步拓宽微博样本数据,提高算法的可靠性。
[1]张剑峰,夏云庆,姚建民.微博文本处理研究综述[J].中文信息学报,2012,26(4):21-27,42.
[2]文坤梅,徐帅,李瑞轩,等.微博及中文微博信息处理研究综述[J].中文信息学报,2012,26(6):27-37.
[3]王灿辉,张敏,马少平.自然语言处理在信息检索中的应用综述[J].中文信息学报,2007,21(2):35-45.
[4]刘军,张净.基于DOM的网页主题信息的抽取[J].计算机应用与软件,2010,27(5):188-190.
[5]Finn A,Kushmerick N,Smyth B.Fact or fiction:Content classification for digital libraries[C].DELOS Workshops, 2001:110-115.
[6]Gottron T.Content extraction-identifying the main content in HTML documents[J].Universität Mainz,2008:I-XII, 1-252.
[7]Weninger T,Hsu W H,Han J.CETR:content extraction via tag ratios[C].International Conference on World Wide Web, 2010:971-980.
[8]Pasternack J,Dan R.Extracting article text from the web with maximum subsequence segmentation[C].International Conference on World Wide Web,WWW 2009,Madrid, Spain,April,2009:971-980.
[9]Debnath S,Mitra P,Giles C L.Automatic extraction of informative blocks from webpages[C].ACM Symposium onApplied Computing,2005:1722-1726.
[10]Liu W,Meng X,Meng W.ViDE:A Vision-Based Approach for Deep Web Data Extraction[J].IEEE Transactions on Knowledge&Data Engineering,2010, 22(3):447-460.
[11]Gibson J,Wellner B,Lubar S.Adaptive web-page content identification[C].ACM International Workshop on Web Information and Data Management,2007:105-112.
[12]Sutton C,Mccallum A.An Introduction to Conditional Random Fields[J].Foundations&Trends®in Machine Learning,2015,4(4):93-127.
[13]Rosenberg D S,Dan K,Taskar B.Mixture-of-Parents Maximum Entropy Markov Models[C].the Twenty-Third Conference on Uncertainty in Artificial Intelligence,2007: 317-325.
[14]Weninger T,Hsu W H.Text Extraction from the Web via Text-to-Tag Ratio[C].DEXAWorkshops,2008:23-28.
[15]李志义,沈之锐,义梅练.贝叶斯分类算法在社交网站信息过滤中的应用分析[J].图书情报工作,2014,58(13): 100-106.
[16]林江豪,阳爱民,周咏梅,等.一种基于朴素贝叶斯的微博情感分类[J].计算机工程与科学,2012,34(9): 160-165.
[17]Yu D,Wang S,Deng L.Sequential Labeling Using Deep-Structured Conditional Random Fields[J].IEEE Journal of Selected Topics in Signal Processing,2010, 4(6):965-973.
[18]张传岩,洪晓光,彭朝晖,等.基于SVM和扩展条件随机场的Web实体活动抽取[J].软件学报,2012,23(10): 2612-2627.
[19]张春元.基于条件随机场的文本分类模型[J].计算机技术与发展,2011,1(7):77-80.
[20]罗一纾.微博爬虫的相关技术研究[D].哈尔滨:哈尔滨工业大学,2013.
责任编校:孙 林
Automatically Extracting Microblog Posts From Different Service Platforms
FENG Hai-tao1,2,LI Lin1,HUANG Yan-yi3,YU Xiao-ting1
(1.School of Computer Science and Technology,Wuhan University of Technology,Wuhan 430070,China; 2.Air Force Early Warnming Academy,Wuhan 430021,China; 3.School of Management,Huazhong University of Science and Technology,Wuhan 430070,China)
This paper aims at studying efficient algorithms to extract the microblog posts in a HTML page,based on machine learning algorithm.According to the different granularities of the web page prepossessing,we consider token and line based text blocks.Then in terms of feature selection,we propose the Text-to-Text Relation and Post-Social features that are combined with the traditional Text-to-Tag Ratio feature.Our experimental results show that SVM with the three features has the best performance in terms of precision.
microblog content extraction;machine learning;feature selection
TP31
A
1674-3261(2017)01-0013-04
2015-06-26
国家社会科学基金(15BGL048);国家863计划项目(2015AA015403)
冯海涛(1980-),男,吉林辽源人,助教,硕士。
10.15916/j.issn1674-3261.2017.01.004
