科技政策术语自动识别技术初探
2017-07-18李智杰王小玉
曾 文 李智杰 王小玉 董 诚
(中国科学技术信息研究所,北京 100038)
科技政策术语自动识别技术初探
曾 文 李智杰 王小玉 董 诚
(中国科学技术信息研究所,北京 100038)
在对科技政策领域术语的特点分析基础上,提出一种适用于科技政策领域的术语识别方法,即结合科技政策术语的语言特点,采用统计计算的方法进行两次术语过滤过程,实现科技政策术语的自动识别。实验结果表明,本文提出的基于科技政策术语语言特点和统计计算相结合的科技政策术语自动识别的方法具有一定的可行性,将用于科技政策词典的构建和科技政策文本内容的深层次语义分析。
科技政策;科技政策术语;术语特点;统计计算;自动识别
1 引言
随着网络的发展和应用普及,国家和各级政府的科技政策通过网络进行实时发布,例如:科学技术部、中国科学院和各省市科技厅(委)均设有科技政策相关网站,并建有科技政策数据库,如全国科技创新政策数据库(http://www.kjcxzc.com/contentlist.asp?parentid=4)、万方数据的政策法规知识服务平台(http://s.wanfangdata.com.cn/Claw.aspx?f=claw.Cateogory&q=effectlevel%3a司法解释),可按时间排序提供科技政策信息浏览和全文下载功能。科技政策的数据量日益增长,科技政策涉及的内容广泛而复杂,如何准确快速地挖掘科技政策中的核心信息,急需对科技政策进行深层的内容分析,而其基础工作是科技政策术语的识别。所谓科技政策术语是指科技政策文本中的词语。本文拟对科技政策术语的自动识别进行初步探讨。
术语自动识别方法主要分为3类:基于规则的方法、基于统计的方法以及统计与规则相结合的方法。除此以外,还有一些新颖但应用相对较少的方法[4]。其中,基于规则的方法主要利用术语词典和规则模板进行术语抽取,即把一些常用的术语收入词典作为基础,对于词典中没有的术语,则通过构建规则模板的方法来识别[5]。该方法对特定领域和特定类型的术语识别具有良好的效果,但该方法需要掌握术语的构词规则,其适应性及可移植性较低。基于统计的方法是以统计理论为基础,利用术语已经在语料库中的分布统计属性来识别术语,即从概率意义上衡量多字单元是否为术语[6]。比较经典的方法是词频统计方法、互信息和信息熵方法、基于统计机器学习的方法等。基于统计的方法相对于基于语言学的方法来说不需要特定专业知识或资源,因此可移植性较好,但是其统计计算需要依靠大规模的语料库。单独地使用基于规则的方法或基于统计的方法进行术语自动识别,或多或少会存在较大的误差,而将两者结合起来使用,则会提高术语自动识别的准确度。因此,使用两者结合的方法进行术语自动识别是目前的主要方法,其具有代表性的方法是C-value方法及其改进的方法。此外,其他新方法还有扩展法。其主要思想是通过种子术语[7]、中心词串、术语部件等术语核心部分进行扩展,以抽取术语。如,文献[8]设计了一种串扩展算法,对一个中心串集的每一个中心串,需在领域语料中找出包含这个中心串的句子集合,并对其中每一个句子进行单句串扩展操作。这种算法用于密码学领域的术语识别,取得了不错的效果。文献[9]提出一种术语部件扩展算法来自动识别术语。术语部件是特定领域中构成术语能力较强的单词或语言片段,通过对领域文本分词后,判断每一分词串是否包含术语部件,若包含则对其向左向右进行扩展,扩展时结合词性及词语长度的规则进行判断,向左扩展时若到了符合首词规则的词时则终止,向右扩展时若到了符合尾词规则的词时则终止,两者都终止即得到了候选术语。该方法的不足之处是随着术语的不断更新变化,无法保证构建出一个完整的术语部件库,同时很多术语并不包含所谓的术语部件。
因此,本文首先从科技政策的术语特点和语言规则入手,分析适用的术语识别方法。
2 科技政策术语的语言规则与统计分析
科技政策术语主要有以下5方面的语言特点。
(1)中心词普遍存在。中心词指科技政策文本中频繁出现的基本术语,多数非单个词的术语是由中心词组成的名词性结构或谓词结构等。
(2)连接结构。科技政策术语中存在一些专有术语,它们的词素和词素之间通过符号连接,如协议标准GB/T19596-2004。
(3)数据存在稀疏现象。科技政策中有些术语只出现一次或少数几次。
(4)术语存在嵌套。多个词组成的术语由单个术语组合而成,使这些术语存在嵌套关系。
(5)停用词表内容不同。科技政策文本用词较为严谨,政策领域的停用词和通用停用词表相比,没有“哦”“哈”等语气词,没有拟声词,没有相对白话的转折词,没有人物代词,没有相对特殊的符号,但是有部分公文领域常用词。
在科技政策文本中,作为反复使用且形式较为固定的、表达某一特定概念的词语,术语的组成结构一般具有词性特点。能够构成术语的词一般为名词、动词、形容词等,有些词性的词是不能作为术语出现的,如连词、介词、副词、语气词等。考虑到科技政策中术语的特点,保留部分动词性成分、形容词性成分和前后缀。相关词性如表1所示。
此外,在科技政策文本中,领域专业术语用词较为严谨,同时对比已有的公文术语词典,发现其构词长度大部分是单个词、2个词和3个词,所以本文选择识别长度在1~3个词的术语。可以发现:多数科技政策术语的语言规则为二元术语及三元术语,如汽车节油率、资源节约型等,也含有少量单词术语和四元及其以上的术语。针对这些科技政策术语的词性构成,构造科技政策术语常用的语言规则模板如表2、表3和表4所示。其中,一元指一个词性标记代表一个术语;二元指两个词性标记代表一个术语;三元指三个词性标记代表一个术语等。
经语言规则过滤处理可得到初次的候选术语集,其中还会包含非术语的普通词语搭配、无意义的词语搭配。为了进一步得到正确的术语,本文采用统计计算进行二次过滤候选术语的策略。由于科技政策术语存在嵌套现象,因此本文基于C-value的统计方法进一步过滤候选术语。C-value方法是一种实现多词语自动术语识别,且与领域无关的方法,其综合运用了统计学和语言学的信息,目的是改进嵌套术语(nested terms)的识别。由于C-value方法充分考虑了术语长度的问题和嵌套术语的问题,可以在一定程度上改进嵌套术语的抽取准确率。
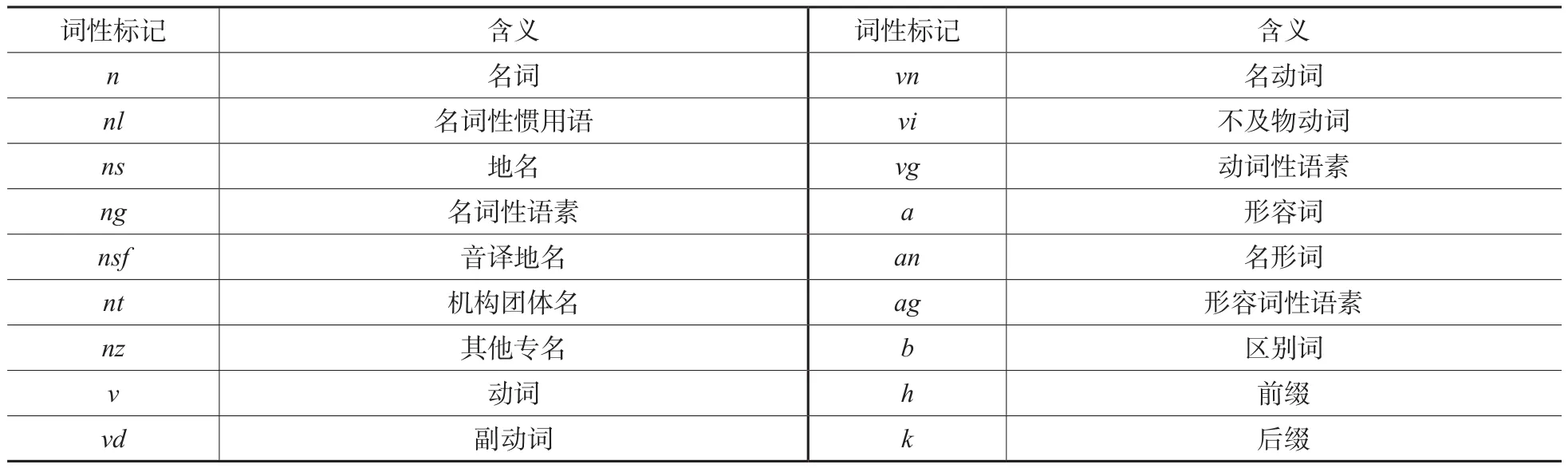
表1 词性释义

表2 科技政策术语一元语言规则
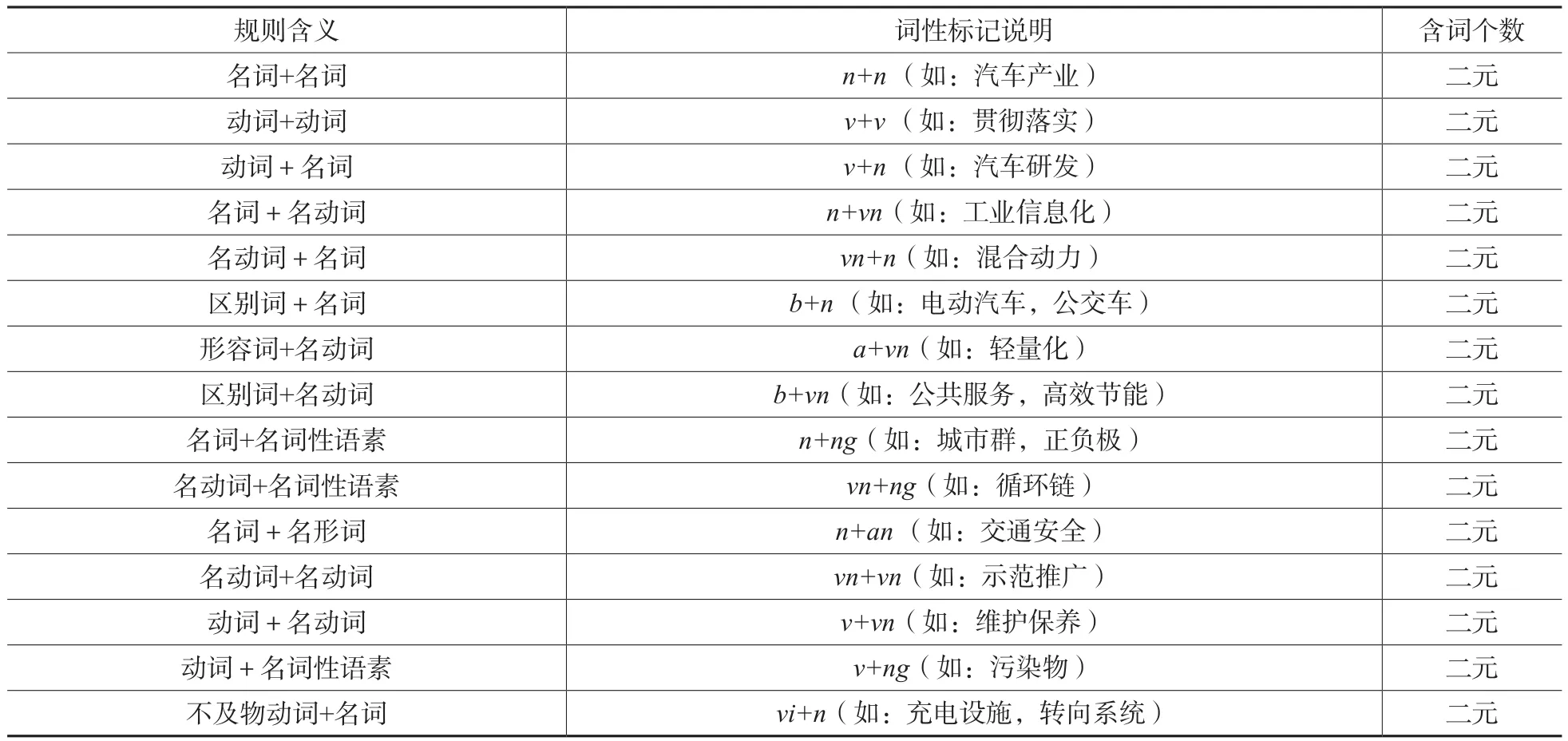
表3 科技政策术语二元语言规则
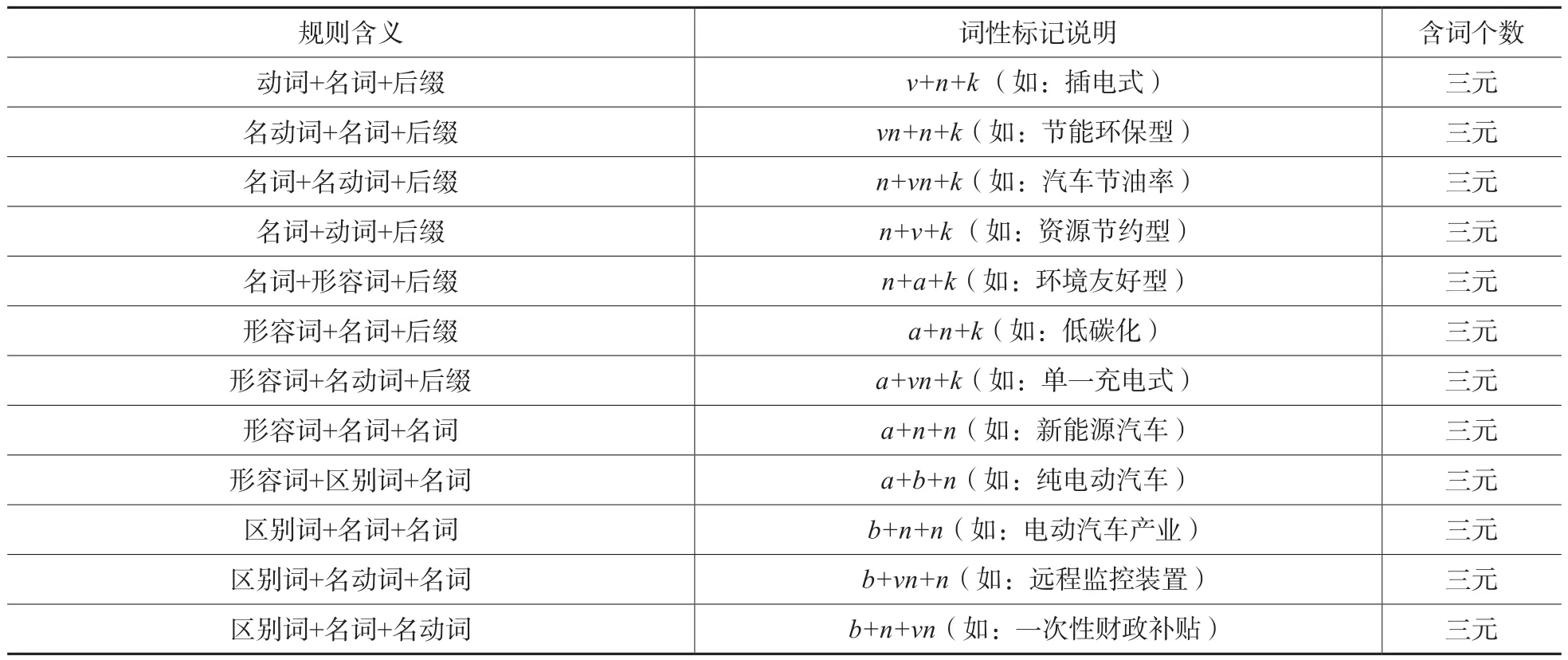
表4 科技政策术语三元搭配规则
C-value算法的基本思想是:(1)如果一个字符串作为子串出现在长的多词术语中的频率很高,而它作为单独术语出现的频率很低,那么尽管这个字符串的整体词频很高但其很有可能不是术语;(2)如果一个字符串经常作为子串出现在多个不同的多词术语中,那么这个字符串是术语的概率更大;(3)如果两个长短不同的候选术语具有相同的词频,那么长字符串是术语的可能性更大。一个候选术语的C-value值的大小与其在语料中的词频和长度成正比,如果候选术语是其他词语的子串即候选术语被嵌套,其C-value值会相应降低。其计算公式如下:
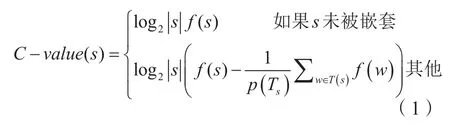
其中:s表示一个候选术语;|s|表示候选术语s的长度;f (s)表示候选术语s的词频。
如果s被嵌套,TS指以s为子串的候选术语,指以s为子串的候选术语总个数,w指TS中任意的以s为子串的候选术语,为w在候选s的上下文中出现的次数。通过以上公式计算每个候选术语的C-value值。C-value值越高,该候选术语成为术语的可能性就越大。把C-value小于某个阈值的术语去掉,则可得到二次过滤后的术语结果。
3 科技政策术语的停用词表与自动识别的算法设计
与其他领域术语的停用词相似,科技政策术语停用词表也包含符号、数字和无实际意义的某些词。为了找到停用词,需要依据一定的标准计算得到。最基本的计算标准是利用词频的大小判断。词频评估函数的理论假设是,通常高频词与高噪声值具有相关性,即当一个词的词频非常高时,很有可能是噪声词。本文利用中国科学院NLPIR-ICTCLAS 2014分词系统对所搜集的科技政策进行分词,统计经过分词及词性标注后的政策文本中所有词的词频,可以发现,一些没有实际意义的词,如“的”“是”“和”等虚词、连词(即停用词)出现次数非常多,这些词不能出现在术语中。同时,一些频繁出现的常用词,如“服务”“推广”“加快”“我们”等,虽然有实际意义,但不包含领域专业信息,同样不能出现在术语中。所以,对于停用词,直接将它们存入停用词表中;对于常用词,对照相应公文领域及科技领域主题词表,以词频及主题词表判断作为依据,选择不是术语的常用词,存入停用词表文件中。如表5所示。
为提高科技政策术语自动识别的准确性,本文将科技政策术语的自动识别过程分为3部分:一是利用停用词表过滤科技政策文本数据;二是利用科技政策术语语言规则识别候选科技政策术语;三是利用统计计算实现科技政策术语的再识别和过滤,以形成整个科技政策术语的自动识别过程。具体算法流程见图1。
图1中的数据预处理主要指实现分词和词性标注,以实现后续的组词过程。经过停用词表去除科技政策中的停用词,使用科技政策术语的语言规则进行术语的第一次过滤,将不满足条件的词语删除。之后,采用统计计算进行候选术语的第二次过滤,最终得到科技政策术语集。

表5 科技政策领域停用词表(部分)
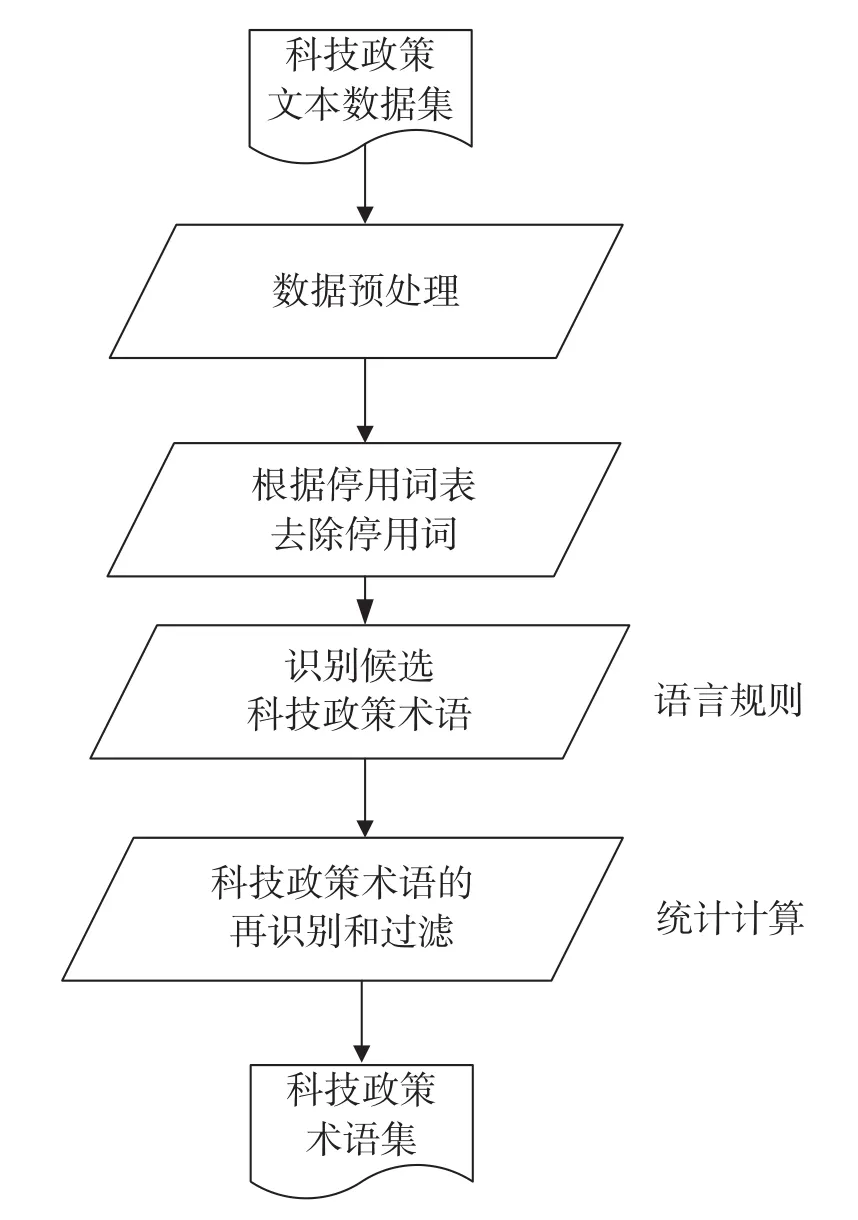
图1 科技政策术语自动识别算法流程图
4 实验分析
本文选取1426条科技政策作为实验数据,通过开发JAVA编程语言程序实现上述科技政策术语的自动识别算法,并进行术语识别效果的检验。利用科技政策术语的语言规则进行术语的过滤。第一次过滤后得到科技政策术语69720个,第二次统计计算过滤后得到科技政策术语83745个,并对识别后的术语进行排序。通过对比,可以发现第二次统计计算解决了术语的嵌套问题,增加了识别后术语的数量。由于目前国内外尚无有关中文科技政策术语的抽取算法及相关科技政策主题词表或词表用于术语结果的对比,因此对文中经过算法识别的术语结果只能通过人工方法来判断是否正确。由于数据集较大,同时为了保证人工判断的相对客观性,本文分别在83745个术语集中随机选取前端1000个术语(T1000,统计计算值较高),中间1000个术语(M1000,统计计算值中等),后部1000个术语(B1000,统计计算值较低),并对这3000个经过算法识别的术语进行人工判断,分别计算T1000、M1000、B1000术语的准确率,最后通过取平均值得到本文术语识别方法的准确率。准确率计算方法如下:

准确率的计算结果如表6所示。
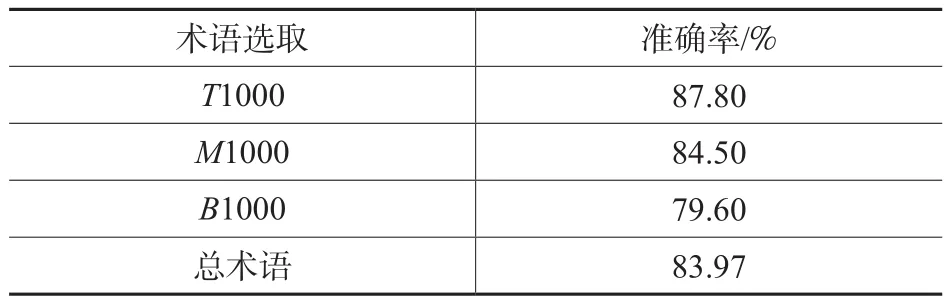
表6 术语识别准确率
根据实验结果可知,本文设计的科技政策术语识别方法具有一定的可行性,
5 结论
科技政策术语既是构建科技政策领域词表的词汇基础,也是对科技政策进行深层次数据挖掘的基础。本文提出的基于科技政策术语语言特点和统计计算相结合的术语自动识别方法,可以应用于科技政策词表的构建过程和科技政策语义分析过程。实验结果表明,该方法具有一定的术语抽取效果,但将受到数据集选择规模的大小或数据集内容质量的高低的影响,术语识别的准确度达不到人工识别的精确度和智能性。此外,实验结果有效性的对比问题仍有待进一步的研究。因此,在科技政策术语自动识别的具体算法设计和实现有待进一步的深入研究[10]。
[1] BERNIER-COLBORNE G,DROUIN P.Creating a test corpus for term extractors through term annotation[J].Terminology,2014,20(1):50-73.
[2] 袁劲松,张小明,李舟军.术语自动抽取方法研究综述[J].计算机科学,2015(8):7-12.
[3] 张二艳.术语自动抽取技术研究[D].哈尔滨:哈尔滨工业大学,2009:20-50.
[4] 杨雅娜,刘胜奇.基于TValue融合领域度的术语抽取法[J].情报工程,2015(5):25-31.
[5] 闫琪琪,张海军.中文领域术语自动抽取方法进展研究[J].电脑知识与技术,2014(28):6716-6718.
[6] 季培培,鄢小燕,岑咏华.面向领域中文文本信息处理的术语识别与抽取研究综述[J].图书情报工作, 2010(16):124-129.
[7] MEIJER K,FRASINCAR F,HOGENBOOM F.A semantic approach for extracting domain taxonomies from text[J].Decision Support Systems,2014,62:78-93.
[8] 陈士超,郁滨.面向科技领域的术语自动抽取模型[J].系统工程理论与实践,2013(1):230-235.
[9] 闫琪琪,张海军.一种混合策略的领域术语自动抽取方法[J].电子制作,2015(8):50-51.
[10] 曾文,李颖,韩红旗,等.海量数据的组织与管理方法研究[J].情报工程,2016,2(1):109-113.
Research on Automatic Recognition Technology of Science and Technology Policy Term
ZENG Wen, LI Zhijie, WANG Xiaoyu, DONG Cheng
(Institute of Scienti fi c and Technical Information of China, Beijing 100038)
The paper proposed an automatic recognition method based on characteristics and statistical computing of term. The method fully combined language characteristics and statistical information of terms.And the method of statistical calculation is adopted to carry out the two fi ltering process of terms. Experimental results showed that the proposed method had certain feasibility. It will have certain application value. In the next step, the method will be used for constructing the dictionary and deep semantic analysis of science and technology policy.
science and technology policy, science and technology policy term, term characteristic, statistical calculations, automatic recognition
TP391
A
10.3772/j.issn.1674-1544.2017.03.004
曾文(1973—),女,中国科学技术信息研究所副研究员,研究方向:智能信息处理、情报分析和知识组织等(通讯作者);李智杰(1992—),男,中国科学技术信息研究所硕士研究生,研究方向:知识组织;王小玉(1992—),女,中国科学技术信息研究所硕士研究生,研究方向:科技资源管理;董诚(1970—),男,中国科学技术信息研究所研究员,研究方向:科技管理与科技创新。
国家社会科学基金项目“基于事实型科技大数据的情报分析方法及集成分析平台研究”(14BTQ038)。
2017年1月16日。
