高速互连串行协议RapiIO的性能优化
2017-07-12杨帆,朱峰
杨 帆,朱 峰
(江苏科技大学 电子与信息学院,江苏 镇江 212000)
高速互连串行协议RapiIO的性能优化
杨 帆,朱 峰
(江苏科技大学 电子与信息学院,江苏 镇江 212000)
串行RapidIO是为了满足嵌入式行业对更高总线速度、带宽和可靠性的需求而发展起来的一种高性能分组交换技术。该技术不仅可以实现芯片间高速通信还可以实现板级间通信。在本文中所提出的研究成果是在对集成在数字信号处理器--多核的TMS320C6474中的串行互连协议RapidIO性能优化的基础上提来的。研究结果表明,经过性能优化,Nwrite(写)和Swrite(流式写)这两种操作的传输速度都有所提升。研究结果还显示出,使用中断的方式发送一个数据包,不仅是最简单的方式,它还可以增加系统发送端的的稳定性。
串行RapidIO;片上系统;DSP;芯片间
现今的处理器性能很强大,可以提供很高计算速度,但是对其处理能力的某些应用要求也在不断增加。这就产生了拥有处理器的机器同时工作的概念。但是这种多个机器同时工作的机制需要解决两个基本的相互关联的问题:处理器间通信和处理器与其它信息处理部分之间的通信。为了解决处理器之间的互连问题,并满足嵌入式系统对带宽不断增长的需求,提出了串行RapidIO(SRIO)互连协议[1]。这种结构起初是为嵌入式计算系统设计的,如今应用到边缘网络,存储,军事和工业设备等各个领域。
文中提出的对集成在DSP—TMS320C6474上的串行互连RapidIO的性能优化结果,是以C6474作为实验平台的。这个板子上有两个DSP处理器[2],通过一条串行RapidIO总线上的两个通道相连。
1 RapidIO互连协议的介绍
1.1 RapidIO结构分层
RapidIO标准总共定义了3个层次架构[3]。最低层是物理层,它规定了电信号和链路层的握手机制。在物理层的上面是传输层,这一层规定了数据包是如何路由的。最上面一层是逻辑层,它定义了分组的类型及其功能。
1.2 C6474的RapidIO功能描述
DSP TMS320C6474内部集成了SRIO外设,而且使用了串行差分模拟信号技术[4]。该DSP设备上的点到点互连技术支持波特率1.25Gbps、2.5Gbps、3.125Gbps、5Gbps、6.25Gbps,能够满足不同应用对波特率不同的需求。
1)功能操作
数据存取指令单元(LSU)不仅控制着直接I/O数据包的发送,还控制着维护包的发送[5]。而内存访问单元 (MAU)则控制着直接I/O数据包的接收。TXU和RXU分别负责消息数据包的发送和接收[6]。
LSU,MAU,TXU和RXU这4个单元通过DMA与内存进行数据交互,通过缓存和收发端口与外部设备进行交流。SerDes则可以进行发送所需的并到串的编码操作和接收所需的串到并的解码操作[7]。还能够使得外设具有非常好的适应能力,使外设能够胜 任 5 种 不 同 的 频 率 模 式 (1.25Gbps,2.5Gbps,3.125Gbps,5Gbps,6.25Gbps)。
2)直接I/O模式中的SRIO
直接I/O模块是所有发送出去的直接I/O数据包的来源。通过直接I/O模块,RapidIO数据包就可以在目标设备上存储地址。但是这种模式要求RapidIO数据包的源设备中必须保存有目标设备的内存分配表。一旦这种表创立起来,RapidIO源控制器就可以知道目标设备的地址,并将地址放到数据包的包头中去。
当CPU想发送一个数据给外部处理元件(PE)或者从外部处理元件中读取一个数据时,它必须使用一种方式将RapidIO数据包的包头给填满。加载/存储模块提供了一种通过将一组寄存器作为传输描述符的机制来解决这个问题,如图1所示。CPU可以通过配置总线来访问这些寄存器[8]。一旦对LSUn_REG5寄存器的写操作完成时,数据传输就开始了。

图1 RapidIO加载/存储单元的寄存器
这种模型中存在4个LSU寄存器组[9],能够允许所有的操作提出4个响应请求。一个共享的配置总线就可以访问这4个寄存器组,而一个单核设备也可以利用4个LSU块。一般使用软件来管理LSU块。
2 实验平台
用来评估互连协议SRIO的实验平台是EVMC6474实验板。该板有2个主频在1 GHz的DSP,这两个DSP通过2路1X SRIO总线相连。TMS320C6474在单芯片上集成了3个核[10],且每个核运行速率都在1 GHz,所以可以提供3 GHz的数字信号处理性能。
3 实验结果
为了评估在EVMC6474板子上实现SRIO互连的性能,完成了一系列测试。
3.1 SRIO函数库
在开始性能评估之前,可以先开发一个库来控制TMS320C6470信号处理器的SRIO设备,而不必直接去处理那些配置寄存器。
这个SRIO库是建立于CSL接口之上的。CSL接口是德州仪器公司提供用来配置和控制那些集成在TMS320C6474 DSP上的外设的[11]。
库中开发的C函数有:
1)SRIO_Init() :初始化 SRIO 模块
2)SRIO_Write:填充LSU单元来发送一个写操作
3)SRIO_Write_R:填充LSU单元来发送操作结束前须有响应的写操作
4)SRIO_Read:填充LSU单元来发送一个读操作
5)SRIO_Doorbell:填充LSU单元来发送一个Doorbell操作
为了实现实验平台上两个DSP之间的通信,其中一个DSP必须先初始化传输介质,然后发起一个操作,之后再发送一个Doorbell操作来说明已经传输完成的目标DSP[12]。
3.2 Non-posted操作的性能
RapidIO定义的6种基本操作中的Nread和Nwrite_R都属于Non-posted类型操作[12],因为它们都是有响应的。这些响应可能包含读操作或者非写操作时的数据。
对Non-posted操作的性能评估实验结果是在RapidIO速率为6.25Gbps时,通过改变操作数据的大小得出的。利用MATLAB可以绘出了1路1X和2路1X时Non-posted操作的性能,如图2所示。
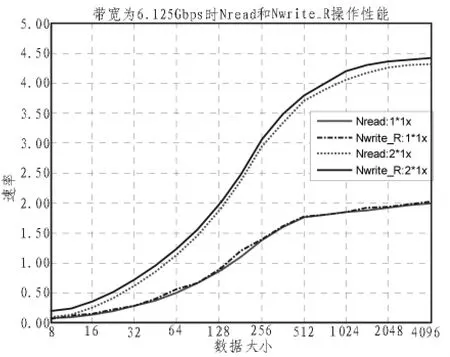
图2 带宽为6.125Gbps时Nread和Nwrite_r操作性能
从图中可以看出,Nread操作和Nwrite_R操作都没有达到理想的数据率。最大数据率时1个1X端口只达到了2.12 Gbps的速率,而2个1X端口也就达到了4.38 Gbps的速率。由此看来Nread和Nwrite_R这两种操作仅仅利用串行RapidIO可提供带宽的48%而已,优化空间很大。
3.3 Posted操作的性能
在RapidIO的6种基本操作中,Nwrite和Swrite操作不需要返回完成响应包或者是确认包,所以这两种操作是属于Posted操作的[13]。
图3显示了分别使用1个1X端口和2个1X端口时Posted操作的性能试验结果。
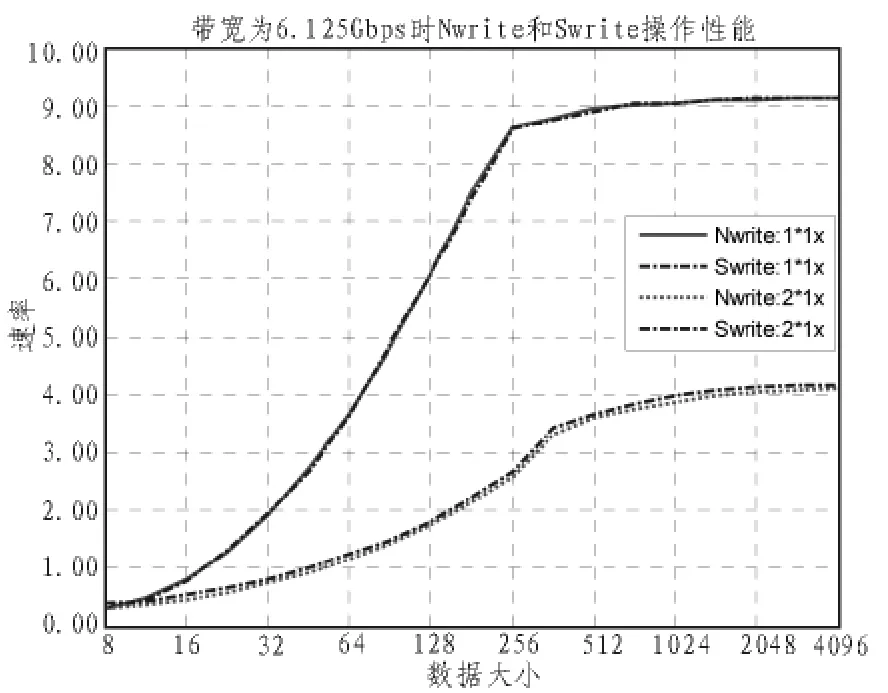
图3 带宽为6.125Gbps时Nwrite和Swrite操作性能
如图所示,Nwrite和Swrite操作都达到了很高的数据率。那么这些操作能达到的理论数据率是多少呢?可以通过下面这个公式计算出来:
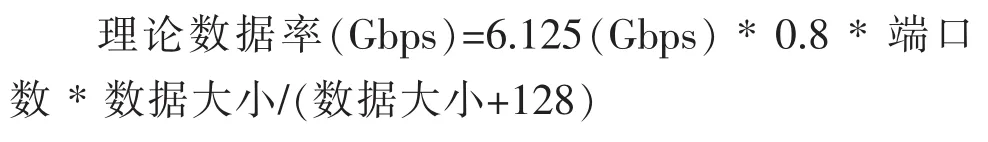
1) 6.125Gbps:TMS320C6474 所能 达到 的最 大数据率
2)0.8:8b/10b编码器的效率
3)128:发送操作所需要的头的大小(按bit计算)
在使用1个1X端口的情况下,当数据大小超过512字节时,理论上的传输速率是4.32 Gbps。而实验时测得,当数据大小超过512字节时,传输速率是4.15 Gbps,非常接近理论值。
3.4 发送大于4KB的数据
LSU单元能够发送的最大数据是4 096字节,但是很多实际应用中的嵌入式系统要求的传输数据大小都超过了4 096字节。如何解决这个问题呢,文中提出了3种方法。
1)中断方法
为了发送大于4 KB的数据流,必须在RapidIO传输结束时立即填充LSU单元。当需要需要发送的数据大于4 KB时,可以分N次来完成,但是LSU也必须填充N次。例如我们需要发送的数据大小是32 KB时,可以将32 KB的数据分成8次发送,每次发送4 KB。
LSU有6个寄存器需填充,在第五个寄存器填充完成时,传输开始。以上这些工作可以用中断控制器(INTRC)来完成。每次RapidIO传输结束时,CPU都会产生一个中断。在中断程序中,CPU会填充LSU并且发起一个新的传输操作。在传输结束时再次产生中断,进入中断操作,如此反复N次,直到将所有数据传输完成。
2)在手动模式中使用EDMA
第二种发送大于4 KB数据流的方法需要使用EDMA设备来填充LSU。EDMA是一种存储器控制器,它能够将数据从一个存储器位置直接拷贝到另外一个存储器中,不需要CPU的干预,效率高。在当前实验中,另一个存储器位置当然是LSU单元了。使用EDMA方法时,每一次的传输操作都必须根据LSU的配置来完成,总共需要做N次传输操作(数据大小:4 KB*N)。配置LSU需要配置6个32位的寄存器,也就是说每次传输操作,RapidIO都必须从存储器中拷贝192 bit的配置信息到LSU中。
第一次传输操作是CPU发起的,在传输操作结束时,CPU启动手动模式中的EDMA来填充LSU,从而发起另外的RapidIO传输。
3)在RapidIO事件的同步模式中使用EDMA
最后一种方法是在同步模式中使用EDMA设备操作。在这种模式中,当RapidIO传输结束时,自动启动EDMA设备操作,这就大大减少了CPU的干预。正如前面所解释的每一次的传输操作都需要192bit的配置信息。所以执行N次传输,必须将N次的配置文件放到存储器中。
在EDMA的事件同步表中没有RapidIO事件,但是它却有CIC(中断路由)[14],可以将RapidIO中断,路由到EDMA。
4)3种方法的性能比较
之前提出的3种方法都可以发送大于4KB的数据流而不对数据率有所影响。图7显示了,使用不同方法时Swrite操作的性能评估实验结果。
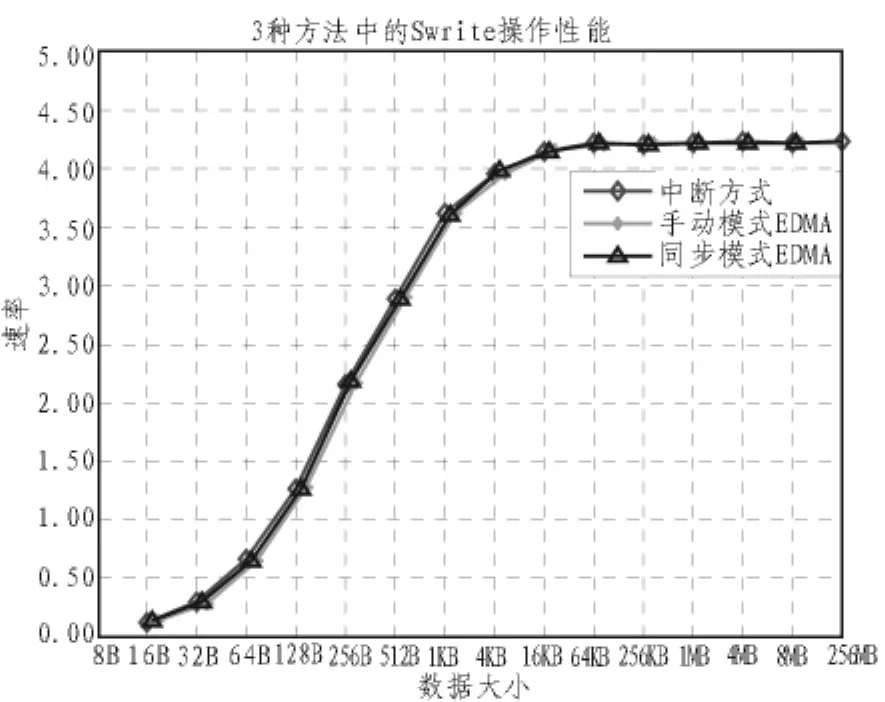
图4 3种方法中的Swrite操作性能
下面的条形图显示了,在不同方法中CPU干预所占的百分比。
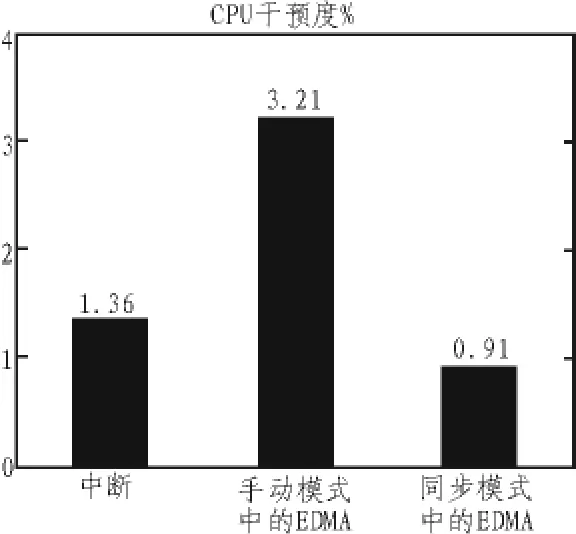
图5 3种方法中的CPU干预度
根据这张图我们可以知道,在同步模式中CPU干预最小。所以同步模式就是发送大于4KB数据流的最有效的方式。但是这种方式有一个缺点,就是它比较难以实现,而且它还需要使用EDMA。相比之下,中断模式是最简单的方法,比较容易实现,也不需要任何的外围设备。介于同步方法难以实现,那么中断方法稍低的性能也是可以接受的,毕竟它简单又易实现。
4 结束语
文中提出了RapidIO互连,更确切的说集成在TMS320C6474上外围设备SRIO的互连。评估了Rapidio互连协议中3个主要逻辑层规范的性能[15]。测试了Nwrite,Nread,Nwrite_R和 Swrite等操作。实验结果表明:Nwrite和Swrite操作的性能要比其他操作的性能更好。正因为如此,推荐使用这两种操作来解决处理器间互连的问题,也能够满足嵌入式系统对更高带宽、更高效信号处理和数据传输速率不断增长的需求。在最后提出3种传输大数据流的方法,中断方法,手动模式中的EDMA方法和同步模式中的EDMA方法。并通过对3种方法的性能对比,得出了结论:中断方法不仅是3种方法中最简单的方法,它还能增加系统传输的稳定性。
[1]施春辉,柴小丽,宋慰军,等.基于SoPC的前端RapidIO接口设计 [J].计算机工程,2011,37(21):235-244.
[2]田泽,郭海英.RapidIO传输性能测试分析[J].电脑知识与技术,2010(28):8122-8124.
[3]Sam Fuller.RapidIO The embedded System Interconnect[M].Trade Association,USA John Wiley&Sons,Ltd.
[4]李少龙,高俊,娄景艺.基于SRIO总线的数字信号处理系统的实现[J].通信技术,2012,45(5):100-104.
[5]Zhang Yong,Wang Yong.Research on Physical LayerTraffic ManagementSchemesin Serial RapidIOInterconnect [J]. Joumal of China Universities of Posts and Telecommunication.2011(1):65-70.
[6]梁广胜,刘倩茹,姚海洋.RapidIO应用系统及其验证模型的设计与测试 [J].电子设计工程,2011(23):60-64.
[7]Bin Ji.Design and Implementation of High-speed Serial RapidIO Based on PowePC[J].In TelelcommunicationEnginering, 2011,51(3):74-78.
[8]刘琳.基于RapidIO的高速数据传输系统设计[D].哈尔滨:哈尔滨工程大学,2013.
[9]PrzemyslawWlodarczyk, SzymonPustelny, Dmitry Budker.Multi-channeldata acquisition with absolute time synchronizaton[J].Nuclear Inst and Methods in PhysicsResearch,A, 2014:763.
[10]陈宏铭,李蕾,姚益武,等.基于AXI总线串行RapidIO端点控制器的FPGA实现[J].北京大学学报,2014,50(4):697-703.
[11]尹亚明,李琼,郭御风,等.新型高性能RapidIO互连技术研究[J].计算机工程与科学,2014:26(10):26-32.
[12]陈程.串行RapidIO总线在存储系统中的应用研究[D].西安:西安电子科技大学,2013.
[13]PILLI-SIHVOLA E, RANTASILA K,HINKKA V,et al.The European approach to addressing RFID privacy [J].International Journal of Radio Frequency Identification Technology and Applications,2014,4(3):258-272.
[14]吴峰峰.一种低时延的串行RapidIO端点设计方案[J]. 北京大学学报:自然科学版,2013,49(4):570-578.
[15]陈强.串行RapidIO互连系统的设计与实现[D].南京:南京理工大学,2013.
Performance optimization of high-speed interconnect serial protocol RapidIO
YANG Fan,ZHU Feng
(School of Electronics and Information ,Jiangsu University of Science and Technology,Zhenjiang 212000,China)
Serial RapidIO is high performance packet switching technology,it can meet the embedded industry demand for higher bus speed,bandwidth and reliability.The technology can not only achieve communication between chips within high-speed,but also can implement inter-plate communication.In this paper,the proposed research results are on the base that performance optimization of interconnect serial RapidIO which is integrated in the digital signal processor multi-core TMS320C6474.The results show that ,through performance optimization,the transfer speed of Nwrite transaction and Swrite transaction has improved.And from the results, we also know that if we want to send a data packet, the interrupt method is the simplest and it can improve the stability of transfer system.But compared to the method of EDMA(Enhanced Direct Memory Access),it's performance is not so good.
serial RapidIO;Soc;DSP;between chips
TP399
B
1674-6236(2017)12-0134-04
2016-05-25稿件编号:201605241
杨 帆(1989—),男,江苏淮安人,硕士研究生。研究方向:雷达信息理论与技术应用。
