基于K-均值聚类分析的风力机功率曲线统计应用
2017-07-10宋聚众兰杰林淑莫尔兵
宋聚众,兰杰,林淑,莫尔兵
(东方电气风电有限公司,四川德阳,618000)
基于K-均值聚类分析的风力机功率曲线统计应用
宋聚众,兰杰,林淑,莫尔兵
(东方电气风电有限公司,四川德阳,618000)
风力机相关数据的处理对风力机能否正常发电无影响,但对风力机性能的分析却至关重要。文章以风力机的功率曲线为研究对象,把SCADA数据记录分为两类,采用模式识别的K-均值聚类分析方法排除掉无效数据点,能够以统一的算法处理不同类型的散点图,通过.NET平台有效地结合EXCEL的数据统计功能和VB语言的逻辑和流程控制功能,准确、快速地开发出可视化软件,绘制好的功率曲线有助于用户直观地分析风力机的发电性能,为用户在风电场发电性能改进方面提供重要依据。
功率曲线,聚类分析,K-均值,数据处理,.NET平台,VB
0 引言
随着化石能源日益稀缺,全球环境的恶化,风能作为一种储量大、分布广、绿色环保的新能源和可再生能源,目前被世界各国大力利用。我国疆域辽阔,多数地区的风能资源丰富,陆上和海上能开发利用的风能储量近似为10亿千瓦。近年来,风力发电技术迅速发展,风电机组的功率曲线,对风电场的运行经济效益有着至关重要的影响。
风力发电机组在运行过程中的数据会通过SCADA系统记录到远程数据库中,以便进行相应统计分析,其中功率曲线是常用到的统计结果,它是风力机发电性能的直接表征。因此需要通过原始记录数据提取有效数据,以便进行功率曲线绘制。但是在SCADA系统中记录的数据,往往包含受风力机起停机过程、风湍流过大、限功率运行等影响的数据点,使风力机实际发电功率与风速不匹配,造成对应该条数据记录无效,从而导致SCADA系统在统计功率曲线时,常使统计结果有偏差,难以准确评价风力机发电性能。若对单台风力机进行人工处理,手动剔除无效统计数据点,理论上是可行的,但不同风力机无效数据记录情况不尽相同,难以采用统一的定量方法进行处理,因此在面临多台风力机、大量数据的情况下,人工处理的办法是不可取的。故针对风电场,研究功率曲线处理办法,实现快速、准确、有效地绘制风力机功率曲线是十分必要的。
本文以风电场实测数据为基础,把SCADA功率曲线数据记录分为两类,采用模式识别的K-means聚类分析方法,通过.NET平台有效地结合EXCEL的数据统计功能和VB语言的逻辑和流程控制功能,快速开发出可视化软件,准确、快速地绘制出风力机功率曲线。
1 风力机功率曲线意义
根据IEC61400-12-1标准的定义,风力发电机组的功率曲线是机组输出功率随10 min平均风速变化的关系曲线,表示风力机在不同的风速下有多大的功率输出[1-2]。
功率曲线确定了风力发电机组的发电性能,是风力发电设备整机厂商(厂家)进行机组研发设计时的重要性能指标,也是设备运行商(业主)招标、计算经济性和投资回报率的重要参考指标。机组进行型式认证时,其也是认证的主要内容之一。在风电场投运以后,功率曲线是厂家进行评估和后期优化的依据,也是业主进行产品考核、质保交机验收的重要内容。因此,如何准确、快速统计风力机功率曲线是十分重要的。
2 K-means聚类分析
聚类分析常用于模式识别、数据挖掘等人工智能领域,其基本思想是把数据对象按照一定的标准划分为几类,使同类数据具有相同的特性,不同类数据特性不同。目前常用的聚类分析算法有:K-means聚类算法、凝聚型层次聚类算法、神经网络聚类算法[3-4]。
本文采用的K-means算法是比较经典的聚类算法,只要数据对象具有比较明显的区域特征,均可采用此方法。该算法具有效率高、实现简单、运行速度快的特点,在大规模样本分析方面,具有广泛的应用[5]。
K-means算法的主要思想是:首先选定分类数目K,指定对应的K个初始中心,再将其余的数据对象按照一定的优化准则划分到某一类中,其划分原则以减小目标函数为依据。其目标函数常采用样本对象到聚类中心的欧几里得距离,则可定义为:
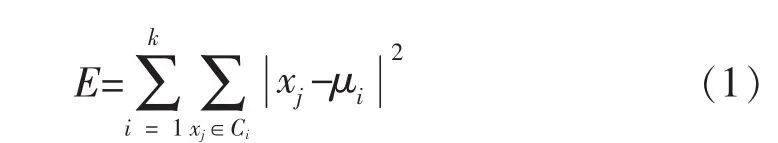
其中:k为聚类类数;Ci为第i个聚类;xj为类Ci中的数据对象;μi为类Ci的质心。
K-means的算法可以分为两个阶段:
第一阶段为批量计算阶段,基本流程如下:
(1)指定初始K个聚类中心;
(2)把每个数据归到距离中心最近的一类;
(3)重新计算该类的中心;
(4)重复步骤2、3一定次数,获得较合理的初始聚类中心;
第二阶段为单独计算阶段,基本流程如下:
(1)选取上一阶段计算的结果,将其作为初始聚类中心;
(2)循环计算每个点所属分类,以减小优化准则函数为标准,重新确定该点分类,并更新该类中心;
(3)重复第2步,直至每一类不再发生改变或优化函数值趋于收敛。
3 数据处理应用
本文以国内某个风电场实测数据为基础进行分析,得到如图1、图2所示的结果。
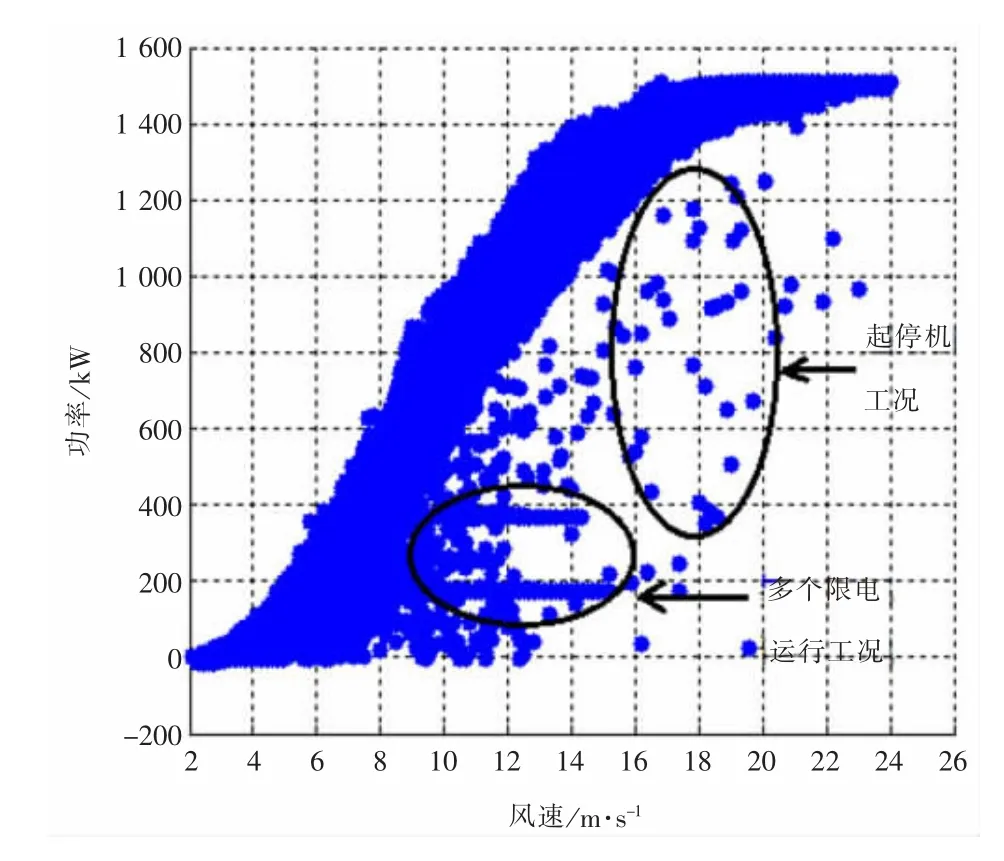
图1 含有起停机、不同限功率运行状态(1#机组)
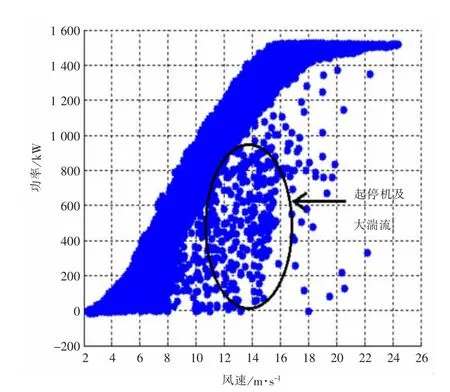
图2 含有起停机过程及湍流强度过大(2#机组)
从图1、图2可以看出,同一风电场两台风力机一年的功率散点图却含有不同类型的无效数据点组合,从而很难进行统一定量分析。用户很难根据图形直观地评价风力机发电状况的好坏。
本文通过分析功率曲线散点图可以发现具有如下特点:
(1)有效数据点具有聚合性,即都在一定范围内分布;
(2)有效数据点远远多于无效数据点。
从(1)可以得出具有聚类分析所定义的特点,数据具有聚合性,相同特性聚集在一定范围内;从(2)可以看出无效数据点的存在对有效数据点的聚合性影响不大,因此可以把整个数据分为两个集合{有效数据点集合}、{无效数据点集合}。集合划分依据采用有效数据点集合均值一定半径内的点为有效数据点集合,半径之外为无效集合。而初始集合的选取,由于有效数据点远远多于无效数据点,因此可以简单设置初始有效数据点集合为全部数据点、无效数据点集合为空集,当迭代到两个集合数据点稳定以后即可得到结果,而有效半径可以通过风电场选址数据的湍流强度,通过仿真计算得出合理值。因此采用K-means聚类分析方法可以获得具体程序流程图(见图3)。

图3 K-means程序流程图
按照图3所示的方法,考虑到常见的数据库系统可以导出EXCEL格式的数据记录,虽然EXCEL具有良好的数据统计能力和广泛的应用基础,但却没有很好的逻辑和流程控制能力,因此,采用.NET平台[6-7],编译了相应程序。.NET平台是微软公司推出的新一代软件开发平台,其主要特点是运行于.NET框架下,各种编程语言只要支持.NET编译器,就可以和其他类型.NET编程语言之间相互调用,其内建提供了良好的EXCEL操作方法,能够集EXCEL的数据统计功能和VB的逻辑和流程控制功能于一体,快速开发出所需软件,且很容易编写出可视化图形界面,便于操作,开发完成的软件界面如图4所示。
图4 功率曲线可视化图形界面
4 数据处理结果
通过已得的可视化图形界面很容易得到图5~图8所示的结果。

图5 1#机组处理后散点图
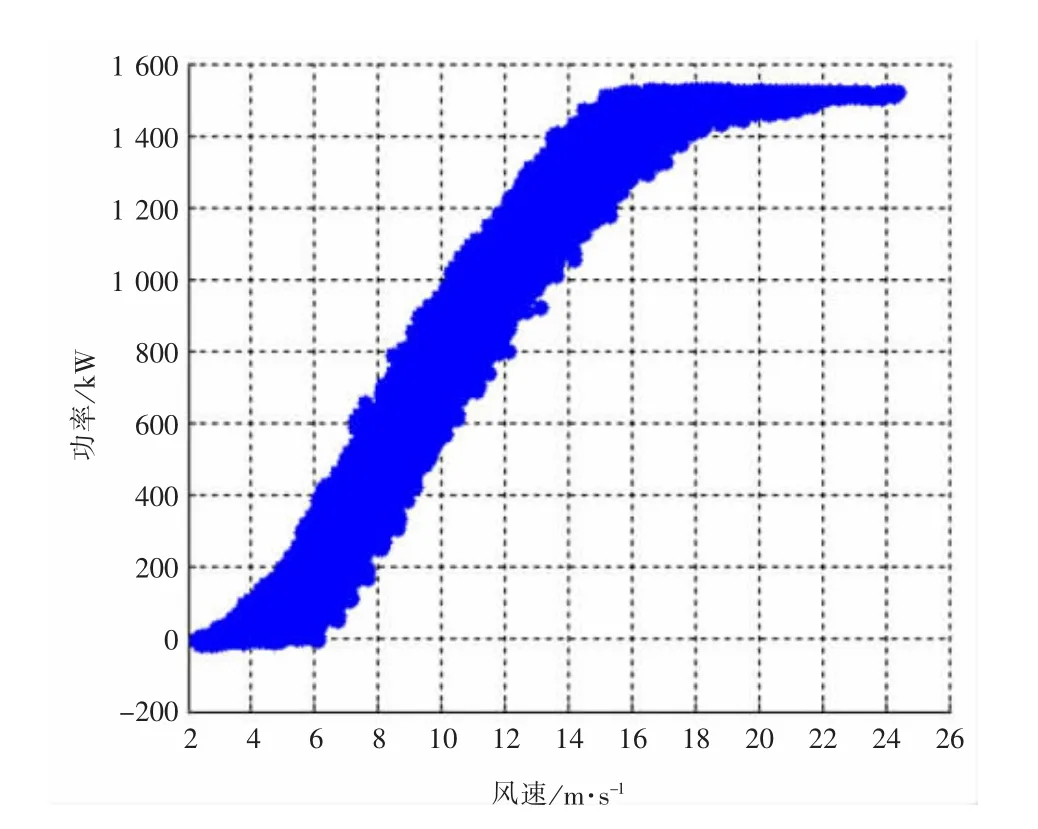
图7 2#机组处理后散点图
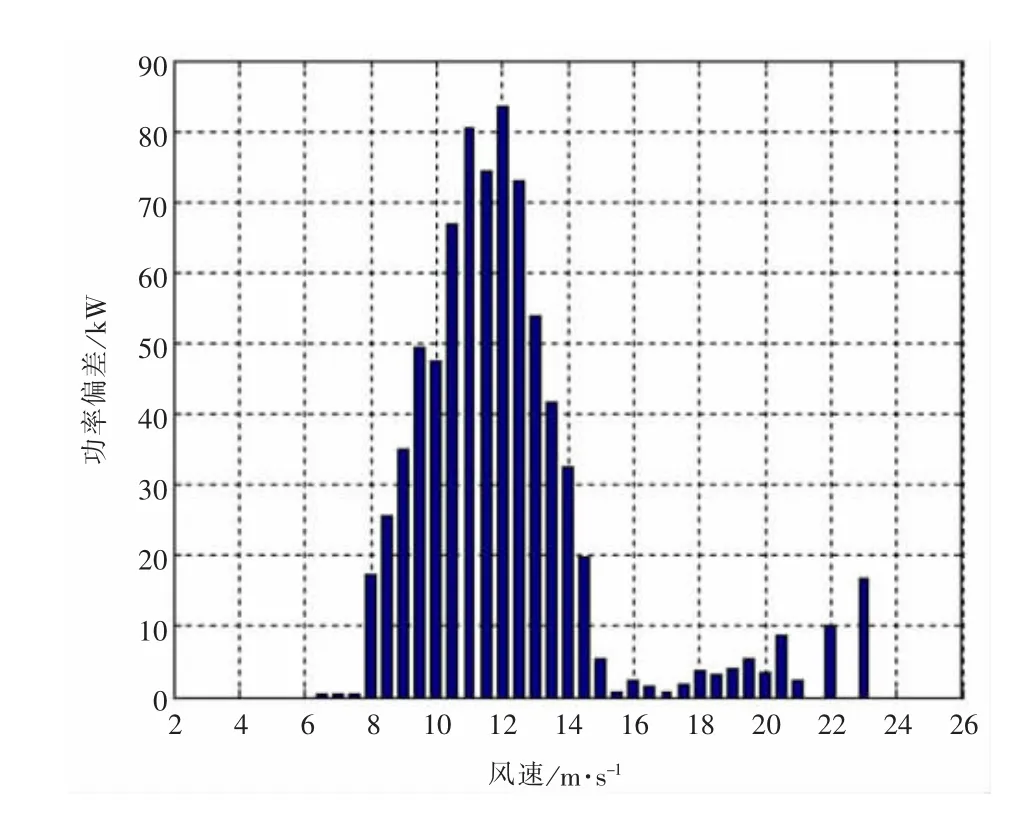
图6 1#机组处理前后功率曲线偏差
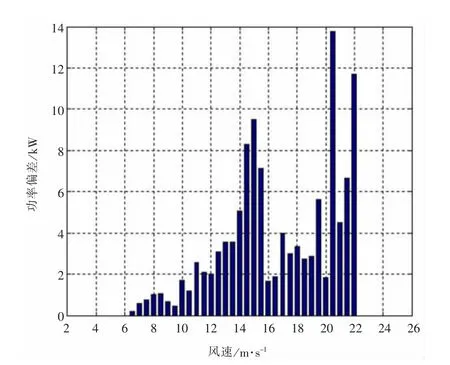
图8 2#机组处理前后功率曲线偏差
通过对以上图形的分析,可知采用本文所提出的方法进行处理后的功率曲线散点图能够有效剔除掉无效数据点,有助于用户直观、快速地分析风力机的发电状况,有效地提高工作效率。
5 结论
本文采用K-means聚类分析方法对风电场SCADA记录的功率曲线数据进行处理,通过可视化图形界面,可以快速、准确、有效地绘制出风力机功率曲线,用户可以很直观地分析风力机的发电状况,也为用户在风电场发电性能改进方面提供了重要的依据。
[1]郎斌斌,穆刚,严干贵.联网风电机组风速-功率特性曲线的研究[J].电网技术,2008,32(12):70-74.
[2]Wind turbine generator systems-Part 12:Wind turbine power performance testing[S].International Electro Technical Commission,2005.
[3]J F Manwell,J G McGowan,A L Rogers.Wind energy explained[M].British:John Wiley&sons,Ltd.,2002.
[4]李楠.基于强化学习算法的多智能体学习问题的研究[D].无锡:江南大学,2006.
[5]李永森,杨善林,马溪骏.空间聚类算法中的K值优化问题研究[J].系统仿真学报,2006,18(3):573-576.
[6]周羽明,刘元婷..NET平台与C#面向对象程序设计[M].北京:电子工业出版社,2010.
[7]严月浩.基于.NET平台的web开发[M].北京:北京大学出版社,2011.
Application of Wind Turbine Power Curve Based on K-means Clustering Analysis
Song Juzhong,Lan Jie,Lin Shu,Mo Erbing
(Dongfang Electric Wind Power Co.,Ltd.,Deyang Sichuan,618000)
Data processing of wind turbine has no effect on wind turbine normal power generation,but it is critical to wind turbine performance analysis.This paper takes the power curve of wind turbine as the study object,the SCADA data records are divided into two categories,the pattern recognition of K-means clustering analysis method is used to exclude invalid data points,and the different types of scatter plots can be handled by the unified algorithm.Through.NET platform which effectively combines with the statistic function of EXCEL and the logic and flow control function of VB language,the visual software is developed accurately and rapidly,the power curve is plotted to help users analyse the power generation performance of wind turbine,and provide an important basis for users to improve the performance of wind farm.
power curve,clustering analysis,K-means,data processing,.NET platform,VB
TP311
A
1674-9987(2017)02-0046-05
10.13808/j.cnki.issn1674-9987.2017.02.011
基金编号:四川省科技支撑计划项目资助项目(2014GZ0084)
宋聚众(1978-),男,工学硕士,工程师,2007年毕业于汕头大学机械设计专业,现从事风电电控设计工作。
