基于DFT的嵌入式普通话语音快速识别
2017-07-05梁向东
邓 力, 梁向东
(桂林理工大学 南宁分校,南宁 530001)
基于DFT的嵌入式普通话语音快速识别
邓 力, 梁向东
(桂林理工大学 南宁分校,南宁 530001)

基于选定的频率普通话发音识别技术,由定义的输入普通话语音拾取的普通话语音识别腔共振曲线,通过对中文分词、韵母声母频谱识别,对中文语音的声母、韵母、声调集成、输出的中文拼音词序列组合,形成句子的中文拼音序列。通过韵母分析方法进行单音节,频域幅频特性分析技术,不需要学习或培训事先要用于一个特定的人的声音,能够识别非特定的单词和句子的普通话语音,采用速率自适应梳状(Discrete Fourier Transform,DFT)谱分析算法,只需极少量的计算,就能够确定地包含4个声调的普通话,具有响应速度快,所需存储空间小,能方便的移植到嵌入式设备的应用程序中。
语音识别; 频谱分析; DFT算法
0 引 言
当前语音识别的主要有基于语音知识和声道模型、基于模板匹配和人工神经网络3种方法[1]。
(1) 基于语音知识和声道模型方法。语言是有限数量的不同语言基元,并可以通过它们的声音信号在频率域和时间域的特征来区分工作。此方法分为两个阶段: ① 取时间为纵轴,对语音进行离散处理,得到不同的语音段,每个语音段信号其声学特性对应于一个或多个语音,每个语音的信号的声学特性都会有其对应的信号标签[2]。② 将前面通过语音离散得到的每个时间段的信号标签转换成对应的语音信号基础网格[3]。
(2) 基于人工神经网络方法。人工神经网络是自适应非线性动态系统,人工神经网络通过模拟人的神经活动[4],可实现语音识别,但系统训练所需时间较长,而且也不能很好地描述语音信号的时间动态[5],当前该技术还未进入应用阶段。
(3) 模板匹配方法成熟,现已达到实用阶段[6]。模板匹配有以下步骤:特征提取、 模板培训、 模板分类、 判断[7]。常用的有动态时间规整 (DTW)、 隐马尔可夫 (HMM) 理论、 矢量量化(VQ)技术[8]。
在实际的应用过程中,目前几乎所有成功的语音识别方法都是基于统计的、概率的或信息理论的方法。但是这些识别方法需要的计算复杂,数据库庞大,对系统硬件的要求高,难以在便携式设备上使用。
针对现有技术的不足,本文的普通话语音识别方法根据音频特点并结合时域频谱特征[9-10],可以判断普通话发音的声母、韵母、声调,声母、韵母经算法组合后输出对应的中文拼音,从而实现语音识别。
本文提出的普通话语音识别技术,能提供一种不需要在使用前对特定人声进行学习,能识别出非特定人的普通话语音单字和句子的普通话语音识别方法。该方法运算量小,识别速度快,对硬件要求较低,适用于嵌入式系统。
1 语音识别的方法
1.1 输入的语音信号预处理
过AD转换使输入的语音成为对应的数字语音信号,然后对转换得到的数字语音信号序列音节界定[11]。
(1) 普通话语音输入后通过AD转换生成数字语音信号序列,对语音信号预加重,提升高频部份,其系统传输公式为:
设s(n)为输入的语音信号,对信号预加重后所得的信号为:

(2) 对预加重后得到的信号加汉明窗。利用语音信号具有短时平稳特性的特征[12],将截取的一段语音信号进行分帧[13],通过将窗函数加入语音信号来实现,


w(n)=
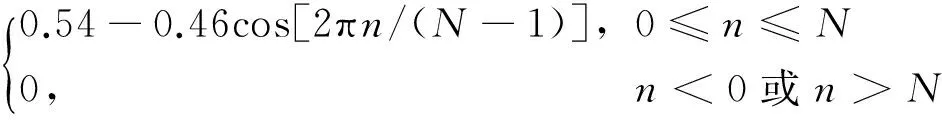
(3) 对语音信号进行离散傅里叶变换[14]。DFT(Discrete Fourier Transform)获得语音信号的离散傅立叶变换为:
其中:X(n)为输入的语音信号;N表示DFT的点数。
(4) 将信号能量谱通过一组三角形滤波器组[15]。定义一个有M个滤波器的滤波器组,采用的滤波器为三角滤波器,中心频率为f(m),m=1,2,…M。
三角滤波器的频率响应定义为:
Hm(k)=

(5) 对每个滤波器组输出的能量累加后取对数:
(6) 经离散余弦变换(DCT)得到MFCC系数:
MFCC系数阶数取12。
1.2 音节界定
音节是听觉的基本单元,普通话每个音节的共性是可分为声母、 韵母、 声调3个部分。将普通话交谈信号每个音节的停顿或突变作为提供音节定义的条件,同时还需将当前背景噪声或无声音信号分离,通过信号强度和时间的周期趋势来确定音节信息。
音节定义方法。将第1次提取到的语音数字信号中无周期性的信号和背景噪声分离,序列中使用固有的音节停顿或突变、明确开始和结束每1个音节来获取语序的数字语音信号。
算法所用参数的定义。对数字语音信号序列的标定出这个词的数字语音信号序列频率稳定阶段的开始和结束。对基波稳定阶段的波型周期定义,以相邻波峰为1个周期,计算出基本频率、 周期和标定出这个词的数字语音信号序列的前端信息段。前端信息段,指数字语音信号序列的开头部分至稳定部份之间的信号波形。
(1) 声调识别。根据词的序列变化标识基本频率的音调、音节,声调识别方法设计的描述的步骤:
如果语音信号序列周期的基本频率的信号在周期中保持稳定,基调的第一声;如果连续上升,第二声;下降后再上升,第三声;下降,第四声。
(2) 声母识别 (见图1)。对发音的数字语音信号序列的时域动态分析,根据分析瞬态响应上升时间和超调量的大小参数,识别声母,按以下方法进行声母的识别:① 校准发音声腔数据段。在词语数字语音信号序列的信息前段,通过校准频率稳定阶段的起始点; 计算第1 B序列之间的0~7位数据位。② 将发音声腔数据段的持续时间与系统设定的门阈值对比,将其分类为有气声或无气声,判断为无气,跳转至③,当判断为有气声,跳转至④;③ 根据前面部分的数字语音信号序列的字包络线的瞬态响应上升时间,识别声母w、 m、 n、 r 或l,然后根据上升响应时间,依数值大小,排列为m、 w、 n、 r、 l;④ 对该单字的语音数字信号序列的前端信息进行检波处理,计算上升时间和超级可调节量;将超级可调节音量大小和系统设定的门阈值对比,划分为有爆鸣声(超级可调节量大) 或无爆鸣声(超级可调节量小):有爆鸣声,跳转至⑤;无爆鸣声,跳转至⑥;⑤ 由超级可调节量大小作为识为 p、 t、 g或 k的根据; 超级可调节量大小排列序列为 p、 t、 k 和 g;⑥ 气声腔长度。将声音的气声腔长度的区分短气和长气声腔两种:当我们判断短气声腔,对包络线的瞬态响应上升时间和系统设定的门阈值对比,区分声母为 b或 d;如上升时间数值为关键阈值标准参考值范围内,加入超级可调节量辅助参与判断。短上升时间/超级可调节量数值大于关键阈值标准考参值 的判断是d;由气声腔长度来识别声母 f、 h、 z、 c、 s、 j、 q、x、zh、ch,气声腔长度最大的是 f。同样,由气声腔长度临界阈值时的上升时间用于判断其他声母。
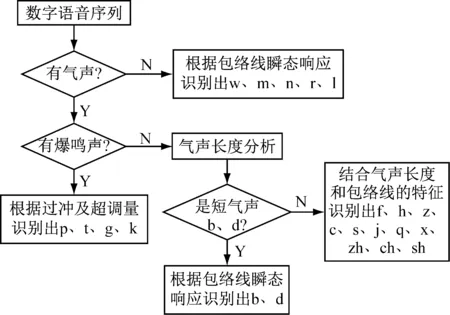
图1 声母识别的方法及过程
(3) 韵母识别(见图2)。用数字语音信号序列中的单词前端信息段外其余信息段作为识别处理的信息源,由基频数据分析出信息的频率特性,在频率特性变化周期的选定频率的带宽和矩形系数曲线对应于为发音谐振腔的体积大小和张紧程度,然后收集统计信息的发音共振腔体积大小和张紧程度的统计数值进行比对,可以识别出韵母。
在测试中通过对数字语音信号序列分析发现,韵母发音谐振腔的体积大小和张紧程度和相应的频率特性的数字语音信号序列的选定频率的带宽和矩形系数曲线存在相对简单的对应关系:共振腔(口腔和咽部)体积大时对应的数字语音信号序列的频率特性带宽大,谐振腔的肌肉更紧张,对应的数字语音信号序列的频率特征矩形系数较大。韵母的发音,如 a、o、e、共鸣腔的形状和张力有显著不同,所以根据系统中存储共振频率曲线,做出对应的判断。例如,窄带宽(例如440 Hz),表明 u,或 ü,和收集统计的实际值比较,选择最接近的就判断是该韵母。

图2 韵母识别的方法及过程
1.3 设计自适应 DFT 算法应用于韵母识别方法
韵母识别采用离离散傅里叶变换来实现:
(1) 对数字语音信号中的每个单词序列中前端部分的声音信息排除,对其余部分的数字序列中按周期T分为多段数据,对每1周期T内的数据进行统计后自适应动态生成sin(2kπ/N)及cos(2kπ/N)k=0,1,2,…,N,N为自然数;
(2) 对在前面分析所得的基本频率进行DFT计算,得出该声音1~10次谐波幅值,对大于等于最大振幅的谐波-30 dB的所有谐波的频率最高值来界定带宽,其实现过程如下:
采样率为44 KB/s,采样1帧时长T=20 ms,采样所得数据为Dcn,n=0,1,…,879。提取转换数据Dt(n)=D(44nT),n=0,1,…,63,进行梳状转换。
奇点提取算法:

余弦提取算法:

对s(n)分奇偶点:
奇点a(n)=s(2n+1) (n=0,1,…,7)
偶点a(n)=s(2n) (n=0,1,…,7)
余弦转换:
正弦转换:
交叉算法(余弦):
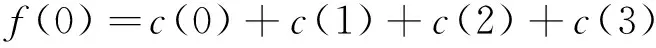

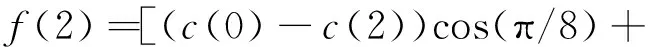
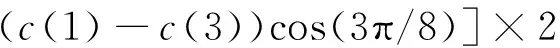


交叉算法(正弦):






确定带宽:
(1) 大于或等于1 040 Hz的带宽,初列为a;当带宽是小于或等于440 Hz,初列为i、 u,或 ü,同时跳转至 (3);当带宽为440~1 040 Hz,初列为e或o同时跳转至(2);
(2) 对高频谐波进行DFT分析,界定出1 000T、1 500T谐波幅度声音,如果有1 000~1 500T谐波,该韵母被定义为e,T为语音数字序列周期;
(3) 对高频谐波进行DFT分析,如有3~3.5 kHz语音谐波,该韵母被定义为i。
(4) 对高频谐波进行DFT分析,如有1.7~2.5 kHz波段语音谐波计算,语音谐波,该韵母被定义为u,如果无此频率的谐波,韵母被定义为 u。
(5) 以上确定的中文语音的声母、韵母、音调,输出对应字的中文拼音;
(6) 对从语音信号中识别的每个字的音频序列进行组合,得出其对应的普通话拼音。
2 语音识别的实例
2.1 语音信号的AD转换步骤和音节界定步骤
图3是语音“跳”原始序列数字语音信号波形图,该图是由拾音器输入,采用固定采样速率(20、44 KB/s等)将声音进行AD转换后生成的数字语音信号序列的“跳”波形图。数字语音信号序列中的所有数据都表示每个采样点大小的声音级别,该信号为无周期性的信号和背景噪声。

图3 未经任何处理的数字语音信号序列的“跳”波形图
查看图中“跳”其波形的声平变化随着时间的变化,看到波形可以分为清晰、周期趋势信号中间及无明显的周期性信号共三段。去除无周期性的信号和部分去除背景噪声,就得到了字“跳”数字语音信号。
2.2 声调、声母、韵母识别
(1) 声调识别。根据词的数字语音信号序列周期变化的信号周期的基本频率的变化特征识别出音节的声调:如果基本频率保持稳定,是第一声;如果是连续的升高,是第二声;如果频率先低后高,是三声;如果频率降低,是第四声。观察频率数据如图3所示,该语序的数字语音信号基本频率稳定在173与119 Hz中,并保持继续下降趋势的变化,因此,可以确定为第四声的声调。
(2) 声母识别。对数字语音信号序列的时域动态分析,包括瞬态响应上升时间和超调量的大小参数,识别声母。① 确定气声腔数据段。数字语音信号序列的前沿信息中0B,校准的波形平稳后的起始点(见图4);② 测量声音的声音时间为60 ms,判断为有气声,可以初步确定该声母不是w、m、n、r或l。③ 对这个词的数字语音信号序列的前端信息段0B进行包络检波,测量出其上升时间23 ms,超级可调节量是17%,判断有爆鸣声,判断该声母不是b,d, f,h,z,c,s,j,q,x,和zh和ch或sh;④ 对前面的词检波处理,得出该词信息的数字语音信号序列,测量上升时间和超调量,将超调量的大小由阈值分为爆鸣声和无爆鸣声:当我们判断爆鸣声,跳转至E);无爆鸣声,跳转至F);⑤ 由超调量大小来识别出声母可能性依次为t、p、g或k;⑥ 气声腔长度。将气声腔长度区分为短气声腔和长声腔。
当判断为短气声腔,包络线的瞬态响应上升时间和经验阈值相比,区分声母b或d;结合数据的长度确定声母f、h、z、c、s、j、q,和x和zh,ch,和sh。再根据外部包络解调处理的信息,声音数据段的长度显示上升时间和超调数据量,其首字母应该是t。
(3) 韵母识别方法。用单词的数字语音信号序列中除了说前端信息段外其余信息段作为识别处理的信息源。
图4中分析了普通话单字“跳”的声音信息周期发生期T频率特性的变化(如带宽和峰值点),在频率特性的选定频率的带宽和矩形系数曲线对应于声母发音谐振腔的体积大小和和张力水平的数据库值(韵母特征),然后找出韵母。① 从数字语音信号序列 0B 外截取后面顺序编号的数据段的长度 T中的其余部分的统计数据包含,在每个数字的n、自适应动态生成sin(2kπ/N)及cos(2kπ/N)k=0,1,2,…,N,N为自然数;T为每个基波周期;k=0,1,2,…,N,N是一个自然数。② 使用自适应梳状DFT等效采样率分析算法,计算声音1~10的次谐波幅值,以最大谐波振幅的-30 dB为所有谐波的最高频率定义带宽:其带宽大于或等于1 040 Hz的带宽,初列为a;分析该段作为韵母识别处理的信息源的各周期变化时段的幅频特性,在前述韵母a对应时段的前后,另可观察到还各包括一段带宽符合条件区间,其带宽分别为312和725 Hz。根据本文的技术方案,可初步界定带宽为312 Hz时韵母为i、u、或ü,带宽为725 Hz时韵母为e或o;进而进行高次谐波的DFT分析,分别对前者计算出3~3.5 kHz及1.7~2.5 kHz所对应的语音谐波幅度、对后者计算出1.0~1.5 kHz的语音谐波幅度,根据计算结果可知:由于后者不存在1.0~1.5 kHz的谐波,因而确认对应韵母为o;由于前者存在3~3.5 kHz的谐波,因而确认对应韵母为i。

图4 普通话单字“跳”的声音电平随时间变化的波形图(已进行周期界定)
2.3 拼音识别集成步骤
把声母t,3个韵母i,a,o和声调(第四声)组合,输出该字的中文拼音tiao(第四声)。
3 结 语
此方法的普通话语音识别方法基于频率域特性和时域特点相结合,可进行单音节识别,算法简洁,计算量小,所需存储单元少,可以在嵌入式设备应用程序上使用。
[1] 刘宇红, 刘 桥, 任 强. 基于模糊聚类神经网络的语音识别方法[J]. 计算机学报, 2006, 29(10): 1894-1900.
[2] 张 辉, 杜利民. 汉语连续语音识别中不同基元声学模型的复合[J]. 电子与信息学报, 2006, 28(11): 2045-2049.
[3] 唐 赟, 刘文举, 徐 波. 基于后验概率解码段模型的汉语语音数字串识别[J]. 计算机学报, 2006, 29(4): 635-641.
[4] 朱恒军,于泓博,王发智.小波分析和支持向量机相融合的语音端点检测算法[J].计算机科学,2012,39(6):244-246.
[5] 李如玮,鲍长春.一种基于分带谱熵和谱能量的语音端点检测算法[J].北京工业大学学报,2007,33(9):920-924.
[6] 刘志伟,卢文科.孤立词的语音识别[J].微计算机信息,2011,27(6):181-182.
[7] 刘长明,任一峰,语音识别中DTW 特征匹配的改进算法研究[J].中北大学学报:自然科学版,2007,27(1):37-40.
[8] 赵 峰.遗传神经网络在语音识别中的研究 [J]. 电脑知识与技术,2008,3(4):774-776.
[9] 刘俊华,颜运——荆琦.遗传算法与神经网络在语音识别中的应用 [J].机电工程,2007,24(12):20-24.
[10] 韩志艳,王 健, 伦淑娴. 基于遗传小波神经网络的语音识别分类器设计 [J].计算机学,2010,37(11):243-246.
[11] 严斌峰, 朱小燕, 张智江, 等. 基于邻接空间的鲁棒语音识别方法[J]. 软件学报, 2007, 18(11): 878-883.
[12] 刘宇红, 刘 桥, 任 强. 基于模糊聚类神经网络的语音识别方法[J]. 计算机学报, 2006, 29(10): 1894-1900.
[13] 唐 赟, 刘文举, 徐 波. 基于后验概率解码段模型的汉语语音数字串识别[J]. 计算机学报, 2006, 29(4): 635-641.
[14] 张 辉, 杜利民. 汉语连续语音识别中不同基元声学模型的复合[J]. 电子与信息学报, 2006, 28(11): 2045-2049.
[15] 刘耦耕, 贺素良, 龙永红. 语音信号变速算法及其TMS320C5402 实时实现[J]. 中南大学学报(自然科学版),2004, 35(1): 117-121.
Fast Recognition of Embedded Mandarin Speech Based on DFT
DENGLi,LIANGXiangdong
(Guilin University of Technology at Nanning, Nanning 530001, China)
Based on the Mandarin pronunciation recognition technology, by the frequency selected from Mandarin speech input cavity resonance curve defined by the pickup, the Chinese word, vowel and consonant Pinyin word sequence can be identified. Combination of Chinese speech consonants, vowels and tones forms Chinese Pinyin sentence sequence. By the syllable by syllable analysis method, the frequency domain analysis technique of amplitude frequency does not need to learn or train for a particular person's voice, words and sentences. The adaptive DFT (Discrete Fourier Transform) spectral analysis algorithm only occupies a very small amount of calculation. The method can determine the four tones of Mandarin, have fast response speed, small storage space, and can easilybe embedded to other devices.
speech recognition; spectrum analysis; DFT algorithm
2016-10-20
广西科学研究与技术开发计划项目(桂科攻12118017-10);2016年度广西职业教育教学改革研究立项项目(重点)(桂教职成〔2016〕26 号);广西高等学校优秀中青年骨干培养工程第一期(桂教人[2013]16号
邓 力(1971-),男,瑶族,广西梧州人,硕士,教授,研究方向为嵌入式系统、EDA技术。
Tel.:13367815798;E-mail:dldl021@163.com
TP 311
A
1006-7167(2017)06-0128-05
