基于语义分析的电子商务产品用户评价分析与研究
2017-07-05董敏王琨
董敏+王琨

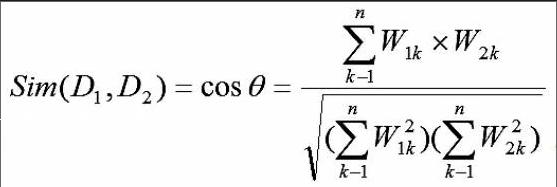
摘 要:随着Web3.0的迅速发展,人们无论在生活上还是工作中,对电子商务的依赖性都不断的增强。因此用户在电子商务平台中对商品的选择上,很大程度上依赖于该商品的用户评价。对于商家来说,在投资产品时也依赖于用户对该商品的评价等级,因此如何建立电子商务平台中产品的用户评价分析模型,为用户和商家提供可靠的决策依据有着重要的作用。本文主要是基于语义分析的模型,采取VSM来得到用户评价总体情感倾向。
关键词:电子商务;语义分析;情感分析;VSM
一、引言
对于电子商务平台中产品的用户等级分析,通常都是采用对本文情感分析技术要进行实现。文本的情感分析可以称作为情感的倾向性计算,主要是对用户的产品、服务、组织机构和事件等进行实时性评价分析。当前对于文本的情感分析是一门较为新兴的技术领域,其目的是利用机器人来对互联网的文本信息进行采集后的数据,通过情感分析来对用户发表信息时的情感心态。在电子商务领域则是体现在对用户关注的产品的情感等级的分析,从而对产品操作得到可信的据测性依据。
二、电子商务产品用户评价情感分析现状
本文的情感分析技术早在上世纪90年代就有许多研究人员开始进行初步的尝试研究,并根据市场的实际需求建立起相关的产品和应用。
哈尔滨工业大学对互联网情感分析现状和动态进行调研、挖掘和探究,提出现有的情感分析中存在的问题,通过对这些问题的阐述和探讨,提出在情感分析领域未来的主要研究方向和目标。同济大学也以新浪微博的平台,对动车事故网友发表的微博和评论进行用户情感分析,他们提出了微博中的六种情感类别,并据此建立了情感分析模型,研究微博文本的影响力和计算网友情感的技术和方法,对该事故之后的公共的情感进行了分析和探讨。清华大学的谢丽星等多人研究了基于层次结构的多策略中文微博情感分析和特征提出的方法。他们通过SVM的监督学习实验,对主题的识别和文本的情感倾向分析取得了不错的效果。
目前对于电子商务平台的文本情感分析,还没有出现较为系统的研究成果,不过根据市场的需要,也出现一些比价平台,通过对多个主流电子商务平台的各项数据采集,特别是对于价格、用户评价,特别是对与好评和差评信息进行动态采集,形成一个多个电子商务平台的价格对比,以引导用户选择高性价比的产品。比如,国内的慢慢买、盒子比价网、琅琅比价网等,提供国内外多个电子商务平台的商品信息的价格和用户评价的对比。
三、电子商务产品用户评价分析算法研究
1.用户评价信息的获取
对于用户评价信息的获取,主要利用网络爬虫来进行采集。因此可以设计一个基于电子商务平台的主题网络爬虫的设计。由于一般的电子商务平台的商品评价页面都是动态呈现的,因此如何解决对用户评价的数据更新是设计该主题网络爬虫的技术关键。
对于动态网站的数据采集,可以建立索引空间,采用哈希表的形式将用户评价信息建立动态索引,利用哈希查找算法,提高采集中查找的效率,从而实现对动态用户评价信息的采集。
由于目前各类型电子商务平台众多,如果需要多全平台的产品用户评价信息进行采集,就需要较大的存储空间和处理器,因此可以利用云计算平台来建立云爬虫,利用云计算的高计算、大存储和高带宽网络的优点实现大数据的用户评价信息的采集,也为后续的情感分析提供庞大的数据集。
2.用户评价信息的特征词处理技术分析
特征词的提出主要分为:文本切词、文本去重和特征词提取三个步骤。
文本切词:将一段词语独立切分为多个独立的词语,这是文本特征词处理的基础技术。当前分词算法有字符串匹配算法、基于理解的算法和基于自动学习的算法等。
字符串匹配算法是最为常见的算法之一,其特点是实现简单,词语的匹配精度性较高。可以建立和维护字符串库,实现不断的自我更新和自我学习。具体的匹配过程是,对文本进行逐一分解后,通过对出现在字符串中的本文块,则匹配成功。为了提高匹配的准确性,可以使用正向最大匹配、逆向最大匹配和双向最大匹配等方法。
文本去重:对于本文切词后,会存在许多重复的词语,这就需要进行对切词后的重复短语进行去重处理。这里主要是研究使用布隆过滤器(Bloom Filter)来进行对文本的去重处理。布隆过滤器是上世纪70年代Howard Bloom提出来的一种二进制向量数据结构,它可以很好的利用空间和时间效率,来验证一個元素在集合中是否重复出现。
Bloom Filter的去重原理是:位数组K个独立HASH函数。将HASH函数对应的值的位数组置1,查找时如果发现所有HASH函数对应位都是1说明存在,很明显这个过程并不保证查找的结果是100%正确的。同时也不支持删除一个已经插入的关键字,因为该关键字对应的位会牵动到其他的关键字。所以一个简单的改进就是counting Bloom filter,用一个counter数组代替位数组,就可以支持删除了。
特征词提取:文本的特征词提出主要是选取文本中的特征项,当前的提取方法比较多,最为常见的是文档词频提取法,也称作为DF。DF是指在整个文本词语集中,包含了所指定的某个或多个特征项,其计算公式为:
在计算公式中,DF(t)是指所包含的特征项t的词频率,通过使用文档词频提取法可以对每个特征项在整个文本出现的频率进行统计,再根据设定的特征项设定的阈值,去掉一些小于阈值的特征项,进而从采集的文本中提取出所需的特征值。在电子商务平台中的用户评价信息,主要是对用户评价信息分词后,提取出用户用于产品的评价特征项,对产品的优良、好坏进行特征项的分析。
3.基于VSM技术的用户评价信息的情感分析
对于电子商务平台中用户评价信息,经过采集、切词、特征值的提取和去重操作后,就剩下对处理后短语进行情感分析,也就是信息相似度的计算。对于目前来说信息相似度技术较为成熟的就是向量空间模型技术(VSM),该中技术就是把两个文本短语简化为向量运算,通过计算向量之间的相似度来衡量文本短语之间的相似度。
本文研究的电子商务平台用户评价研究的VSM情感分析过程如下:
(1)预处理,先对采集的用户评价文本进行中英文切词,并过滤所有停用词。
(2)对用户评价文本中的分词短语的关键词进行選择与加权,对用户评价文本中若干个关键词进行频度的计算。
(3)通过把两个处理后的短语建立向量空间模型、求出向量空间中的余弦值。对于建立向量空间模型的方法就是把短语简化为关键词的权重为分量的N维向量来进行表示。对于D1和D2两个文本来说,要求的之间的相似度Sim(D1,D2),其余弦公式为:■,其中W1k和W2k分别表示D1和D2两个短语第k(1<=k<=n)个关键字的权值。
(4)如果所求的两个用户评价文本的余弦值大于所设定的阈值,那么就说明这两个短语是相似的,否则说明该个短语与评价信息并不相似。
经过对所有切词后的短语进行相似度计算后,得出的余弦值与事先设定好的阈值进行比较后,作为用户评价情感倾向度分析的评价标准,通过把所有评价中的文本短语进行计算后,就可以判断用户评价对于商品的情感,也就可以作为对该商品的评价等级。对于设置的阈值可以在分析过程中,通过对词语出现的频度来不断的进行调整,实现自我学习的能力,从而进一步的提高用户评价情感倾向度分析的准确性。
四、总结
综上所述,对于电子商务平台的用户评价信息的分析中,主要是采取了SVM方法进行分析,通过信息的采集、特征项的提取和情感的分析等来对产品的评价进行分析,为用户和商家提供决策上的有效依据。但是由于目前电子商务平台的迅速的发展,各类电子商务信息量巨大,如何提高对用户评价的采集效率,切词的合理性和对用户评价信息情感分析的准确度方面,还需要进一步提高研究的深度和广度。
因此下一步的研究方向是如何把本文研究的分析平台和当前主流的云计算平台相结合,依托云计算平台的高计算能力、高可靠性和高存储性等众多优点。进一步的提高分析平台的工作效率和对用户评价的情感倾向度的分析能力。
参考文献:
[1]张冬雯,崔志超,许云峰.电子商务产品评论多级情感分析的研究构架[J].网络安全技术与应用,2013-09.
[2]杨彪.面向电子商务的评论文本情感分析研究[D].重庆交通大学,2014-04.
[3]田金灵.B2C电子商务中情感因素与顾客满意及购买行为的关系[J].湖南工业职业技术学院学报,2013-08.
[4]严建援,张丽,张蕾.电子商务中在线评论内容对评论有用性影响的实证研究[J].情报科学,2012-05.
[5]游贵荣,吴为,钱沄涛.电子商务中垃圾评论检测的特征提取方法[J].现代图书情报技术,2014-10.
