产品平台参数化模型间包含性分析
2017-07-03曾莎莎彭卫平玮武汉大学动力与机械学院武汉430072
曾莎莎 彭卫平 闫 玮武汉大学动力与机械学院,武汉,430072
产品平台参数化模型间包含性分析
曾莎莎 彭卫平 闫 玮
武汉大学动力与机械学院,武汉,430072
基于Apriori算法,研究了参数化模型间包含性关系,结合包含性关系在数据库中的隐藏形式,利用一种可以克服经典Apriori算法两个瓶颈的事务数据库构建方法,减少了扫描事务数据集的次数,并通过对频繁项集置信度的比对,输出了包含性关系的结果。以高中压阀门产品为数据对象,应用Weka数据挖掘软件的Explorer模块进行实例验证,输出了阀门各个参数化模型间的包含性关系。
产品平台;参数化模型;包含性关系;事务数据库
0 引言
产品平台是实现面向大批量定制设计的重要基础,是企业实施大批量定制产品策略的关键,产品平台参数化模型间包含性关系的研究具有重要的意义。研究尺度参数变化下的同构类间/非同构聚类间的包含关系、等效类间/非等效聚类间的包含关系、等价类间/非等价聚类间的包含关系、以及等效类/非等效聚类分别与同构类/非同构聚类的包含关系、等价类/非等价聚类分别与同构类/非同构聚类的包含关系,有利于产品与工艺资源的快速检索和再利用,提高设计制造效率,降低生产成本。例如,同构类模型及其包含关系面向的是结构与结构的关系,设计时通过对结构及其子结构进行快速检索可实现产品快速变型和精确配置;功能等效模型及其包含关系、功能与结构模型间包含关系面向的是功能与功能、功能与结构的关系,设计时通过功能的快速分解,迅速了解功能与其子功能、子结构的包含关系,可实现产品创新与精确配置;工艺等价模型及其包含关系、工艺与结构模型间包含关系面向的是工艺与工艺、工艺与结构的关系,安排工艺时通过对工艺的分解,迅速得到其对应的子工艺、子结构,反过来从结构入手,又可以快速查找到与其对应的工艺方法,可实现直接面向工艺的规划。这里的包含关系不仅是逻辑上的包含关系,而且是参数和参数域的继承关系。
国内外学者在面向大批量定制设计产品平台的研究中,提出了许多关于功能、结构和工艺之间的映射关系。文献[1-3]采用功能到中间过程再到结构的路径,虽然建立了功能与结构之间的联系,但增加了系统的复杂性。文献[4-6]采用网络方法,建立了功能与结构、结构与结构之间联系的模型,但对象都是传统的物理对象。文献[7-8]以结构到结构之间的映射模型为研究对象解决了一部分产品多样化的扩展问题,但对象较为单一,没有建立起结构与功能、工艺之间最广泛的联系。文献[9-13]以不同的方法实现了功能与结构之间的映射关系,但没有设计出参数化模型,难以实现产品的快速变形与创新。文献[14]没有将工艺的包含关系映射到结构上去。由以上文献可以看出,目前整合功能、结构、工艺等参数化模型的包含性分析方法还鲜有人研究。
在参数化模型方面,CHEN等[15]提出基于聚类分析和信息熵理论的多平台参数化产品族设计方法,使用信息熵理论在聚类分析中划分可能的平台变量共享,进一步使用优化算法决定平台变量和差异性变量的最佳取值。WANG[16]提出将参数化平台与模块化平台集成的方法。LOPEZ-HERREJON等[17]提出依据功能需求参数重构产品特征,并定义了8种模型,描述了如何提取特征元素。SCHÖNSLEBEN[18]提出了面向DTO(design to order)的参数化定制方法。SURAJ[19]提出了一种参数化模糊网络方法,并将此方法用于参数化产品族。李戬等[20]提出了基于广义机械产品的参数化技术。杨金勇[21]提出了概念设计过程中功能的广义定位表达,弥补了传统功能表达方式的不足,并用矢量的数目量化了产品功能。ASADI等[22]进行特征模型配置问题研究,提出了特征模型的自动选择方案,并引入了功能参数和非功能参数。上述文献虽然用不同方法将参数化方法与产品平台和产品族进行了结合,但并没有表现出参数化模型的内在关系,也就是说,参数化模型的研究与应用已十分广泛,但参数化模型间的内在关系却少有人涉及。
在算法研究方面,黄勇等[23]提出了一种基于结构化查询语言SQL的多值多层关联规则挖掘新方法。谢亮等[24]从主从关系数据集角度开展关联规则挖掘,提出了一种基于元组ID逆传输的关联规则挖掘算法。纪怀猛[25]为解决Apriori算法产生大量候选项目集,导致计算量过大的缺陷,提出了一种基于频繁2项集支持矩阵的Apriori 改进算法。甘超等[26]将AGM频繁子图挖掘算法应用到故障诊断研究中,提供了算法的实例应用。产品平台参数化模型间的包含性分析涉及频繁子图挖掘的问题。频繁子图挖掘算法是当前数据挖掘领域中一个非常活跃的研究课题,INOKUCHI等[27]将Apriori算法应用到频繁子图挖掘中,提出了AGM算法,但AGM算法在性能方面仍存在两个瓶颈:候选子图的生成;候选子图的支持度计算。前者主要是如何快速生成候选子图,避免产生冗余的子图;后者就是解决子图同构问题。为克服这两个瓶颈,本文对AGM算法做出一些改进,即采用邻接矩阵作为图的存储结构,在生成候选子图前加入矩阵正规形判别算法,减少冗余子图的产生,提高算法的效率。
虽然国内外学者提出了很多方法用于发现功能、结构、工艺之间的内在联系,但是他们的研究对象多是物理模型之间的包含性关系,而参数化产品平台中的包含性关系极少涉及,因此本文对产品平台参数化模型间包含性关系的研究是十分必要的。
1 产品平台及其参数化模型
本文研究的产品平台是分布式参数化智能产品平台(distributed parameterized intelligent product platform, DPIPP),该产品平台是一种基于分布式智能体(Agent),以参数化产品最小近似自治子系统(广义模块)为基本单元,通过个体Agent模型组装完成建模的产品平台。该平台具有分布式、参数化和智能化的特征,能集成制造商和供应商的产品及过程资源或知识,支持企业面向大批量定制设计(design for mass customization, DFMC)的产品变型和配置设计、自组织设计和协同设计等。其组成可用公式表示为
DPIPP=DMAS{(M,E)|M=
{Mi(tij)|tij∈Dij};E={(Mi,Mk)};
i,k=1,2,…,6;j=1,2,…,mj}
其中,DMAS指分布式多智能体系统(distributed multi-Agent system);M为模型集;Mi(tij)是M中的参数化模型,即最小近似自治子系统(广义模块);tij和Dij分别为Mi的参数向量和定义域;E是指M中的包含关系;(Mi,Mk)表示Mi包含Mk,且tij包含tkj。
在DPIPP的参数化模型中,存在结构相同的模型,也存在结构不同的模型,前者称为同构类,后者称为非同构类。同构类的功能和工艺信息可能不同,如同一零件可能有不同的加工工艺,并且其尺度参数的变异对产品生命周期的其他阶段(功能、性能、工艺等)存在着影响;而非同构类在许多参数域范围内,它们的功能、工艺也可能一致,如同一功能可由不同结构模块来实现,不同的零件可能具有相同的加工工艺,不同的部件的装配工艺也可能相同;并且非同构类在功能与工艺上更多的是相似关系。因此,产品平台参数化模型包括6类,分别是:参数化产品模块的同构类模型M1(t1j);参数化产品模块的非同构聚类模型M2(t2j);参数化产品模块的等效类模型M3(t3j);参数化产品模块的非等效聚类模型M4(t4j);参数化产品模块的等价类模型M5(t5j);参数化产品模块的非等价聚类模型M6(t6j)。
本文所研究的DPIPP模型将数据层分为3个层次,即数据表层、逻辑层及物理层,其具体结构和组成如图1所示。
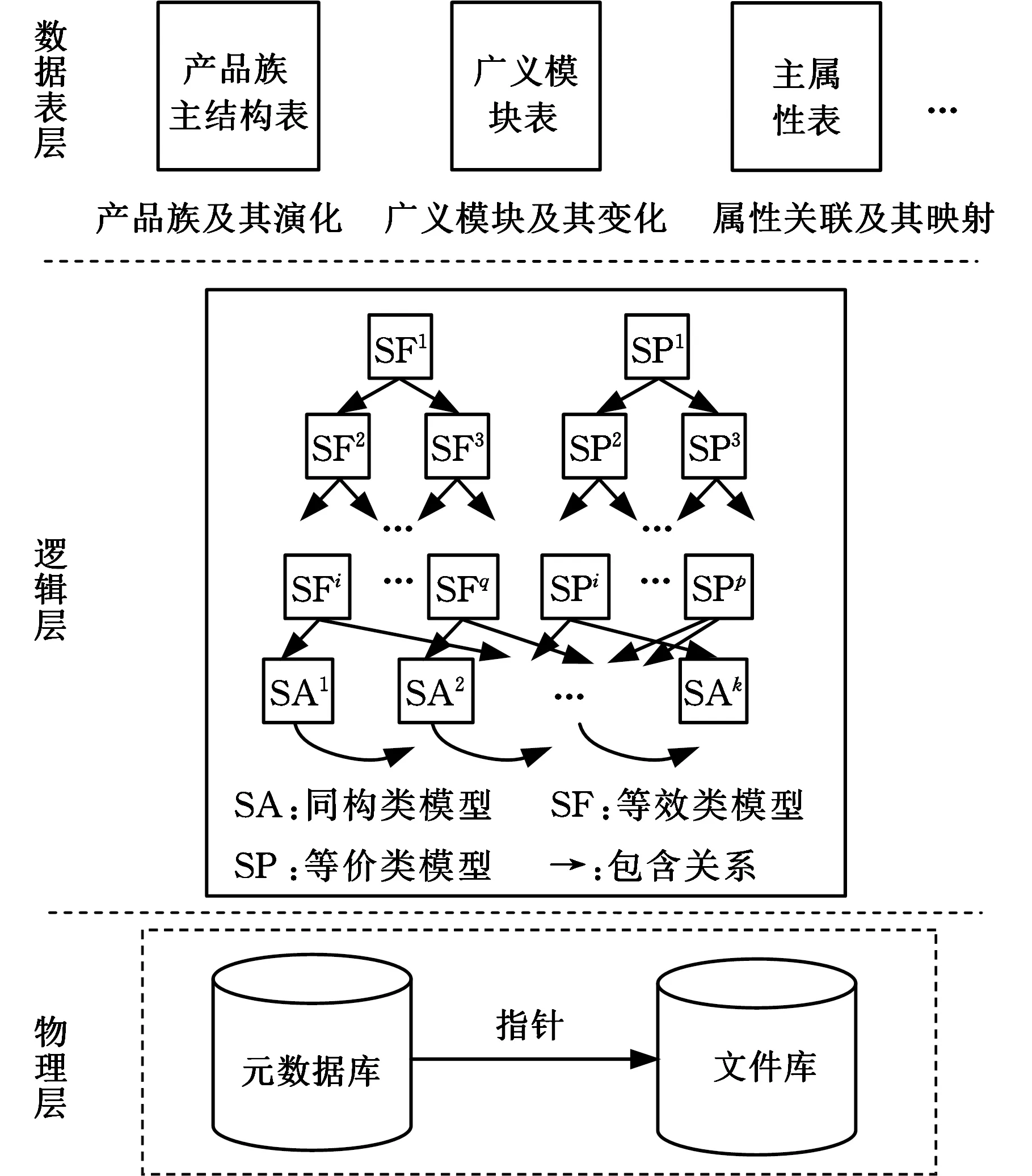
图1 DPIPP体系结构图Fig.1 Architecture diagram of DPIPP
DPIPP组织模型可以采用树形结构来表示,如图2所示,其基本组成单元是产品族广义模块,节点信息包括广义模块主属性表、参数表、参数驱动模型、工艺卡片、数据字典和Agent程序等各种属性数据。本文采用数据库表存储DPIPP树状模型节点中的结构化数据,而非结构化数据则存储在文件库中。这样的存储方法能完整表示DPIPP模型,并且能够直观地反映广义模块的结构属性、功能属性、工艺属性及其模块关联规则,存在于企业产品数据中隐含的许多产品及过程资源和知识也能够在平台中得到表达。

图2 DPIPP树形组织模型Fig.2 Tree organization model of DPIPP
在实现对产品族(产品族结构、广义模块)及其主属性的分析和提取之后,将对这些模块进行参数化表示,进而将其抽象成参数化模型。阀门产品一般可以划分为驱动模块、传动模块、启闭模块和连接支承模块。
(1)驱动模块由驱动装置实现其功能,主要分为齿轮驱动、蜗轮驱动、电动和液动几种形式。湖北高中压阀门公司的阀门驱动装置均通过外购获取,因此可以直接通过外购驱动装置的铭牌提取其性能参数、结构参数等,作为驱动模块的主属性参数。
(2)传动模块将输入动力传递到阀门内部,主要由阀杆组件组成,阀杆组件与驱动装置、阀盖、阀体和启闭件均存在孔轴配合,因此可将阀杆组件在这几个配合中的轴径作为传动模块主属性参数。
(3)启闭模块是阀门实现流体控制的模块,其断流结构和密封圈材料是影响其结构的主要属性参数,如闸阀和蝶阀的断流结构分别是闸板和蝶板;又如在上装式偏心半球阀产品族中,以其密封圈材料的不同又可将其启闭模块区分为硬密封模块和软密封模块。
(4)连接支承模块是阀门的主体部分,阀门的结构形式以及与管道的连接形式均受其结构的影响,因此可以直接将连接形式与结构形式作为连接支承模块的主要属性参数。以球阀为例,根据连接形式可将连接支承模块分为内螺纹连接模块、法兰支承模块和焊接支承模块等,根据结构形式可分为浮动直通式、浮动三通式和固定直通式模块等。
将上述提取的模块主属性分别用参数标识,记录到模块信息模型中,利用模块编码及其主属性特征来表示广义模块(即参数化模型),实现广义模块的参数化表示。进而可将模块的属性参数特征存储在模块属性表中,表1截取了高中压阀门产品族部分模块属性参数。
2 基于Apriori算法的参数化模型间包含性分析
2.1 关联规则算法描述
关联规则是从一个事务数据集中推导发现的,该问题可以描述为:令I={i1,i2,…,im}表示一个项集,D表示一个事务集,其中每一个事务t即为一个项集,即t⊆I。在这个事务集D中,关联规则X⟹Y的支持度s(0≤s≤1)是指包含X∪Y的事务占全体事务的百分比。关联规则X⟹Y的置信度c(0≤c≤1)是指包含项集X的事务中出现包含项集Y的事务的条件概率。对于一个给定的事务数据集D,同时满足用户设定的最小支持度(min_sup)和最小置信度(min_conf)的规则即为强关联规则。

表1 高中压阀门广义模块属性表
项的集合称为项目集,简称项集(itemset)。包含k个项的项集称为k项集。在本文的包含性分析中,包含k种参数化模型的模型集称为k-项集。例如{SF1,SF2}表示一个2-项集。
参数化模型集的支持度即为该模型集出现的频度,是指整个事务数据集D中包含的该模型集的事务数的概率,即Support(A⟹B)=P(A∪B)。
最小支持度(min_sup)表示项目集在统计意义上的最低重要性。若k-项集的支持度大于或等于最小支持度,则称该k-项集为频繁k-项集,记为Lk。
候选项集是待检测的潜在频繁项集,是频繁项集的超集。含有k项的候选项集记为Ck,频繁k-项集从候选项集Ck中筛选检查得到。
Apriori算法使用的是逐层迭代的算法,即其中的k-项集被用于探索(k+1)-项集。在包含性研究中,算法首先扫描事务数据集D,统计每个参数化模型标识的频数,并收集满足最小支持数的模型标识,找出所有频繁1-项集的集合。该集合记为L1。以此为起点,再利用递推关系,直到不能再找到频繁k-项集为止。在频繁项集的挖掘过程中,每找出一个频繁k-项集就需要扫描一次事务数据集D,同时产生大量的候选项集。为了减少候选项集的产生,需要用到频繁项集的两个性质:①一个频繁项集的任何子集必然是频繁项集;②一个非频繁项集的任何超集必然是非频繁项集。
Apriori算法通过减少候选项集的数目获得了较好的性能,但在频繁项集数目过多或者最小支持数过小时,算法会生成数量庞大的候选项集,会反复扫描事务数据库,使得计算代价很高。这两个性能瓶颈一直制约着Apriori算法的应用。多次扫描事务集,需要很大的I/O负载,对于每次k循环,候选项集Ck中的每个候选项集元素都必须通过扫描一次数据集来验证其是否符合最小支持数。另外,通过频繁(k-1)-项集产生的候选k-项集是以指数形式增长的,面对如此庞大的候选项集,对时间和存储空间都形成了巨大的压力。
为了在一定程度上克服这两种弊端,该算法自1994年提出以来,许多学者提出了Apriori算法的变形思想,以提高该算法的计算效率,主要包括基于映射的技术、划分法、抽样法、动态项集计数法。这些改进算法在大多数情况下都能帮助Apriori算法压缩大量的候选项集生成数量,但并不能从根本上解决这两种极大开销对算法的影响:①依然会生成庞大的候选项集。例如,如果频繁1-项集的个数达到104,那么Apriori算法生成候选2-项集的个数将达到107。②依然需要重复扫描数据库。模式匹配方法确定候选项集需要扫描数据集中的每个事务,通过模式匹配筛选一个庞大的候选项集集合的代价十分高昂。
由于多数算法依旧没有解决需要多次扫描数据库的瓶颈,而用于挖掘的参数化模型间包含性分析的事务数据集十分庞大,如果多次扫描数据库则会造成算法时间和存储空间上的巨大压力。为了克服以上弊端,在构建事务数据库时就应该将候选项集过大的问题和多次重复扫描数据库的问题考虑进去,合理构建预处理事务数据库。
2.2 事务数据库的构建
由于包含性关系的研究对象是六类产品平台参数化模型,而这六类参数化模型的存储方式并没有蕴含包含性关系,因此需要重新构建事务数据库。产品平台中的广义模块,有结构相同的,也有结构不同的,其中,结构相同、仅在尺寸上有差异的广义模块集合称为同构类模型,结构不同的称为非同构类模型。本文中,将非同构类广义模块中能实现同一功能的模块称为功能等效类。以等效类与等效类模型间的包含性分析为例,假设产品族部分结构如图3所示。
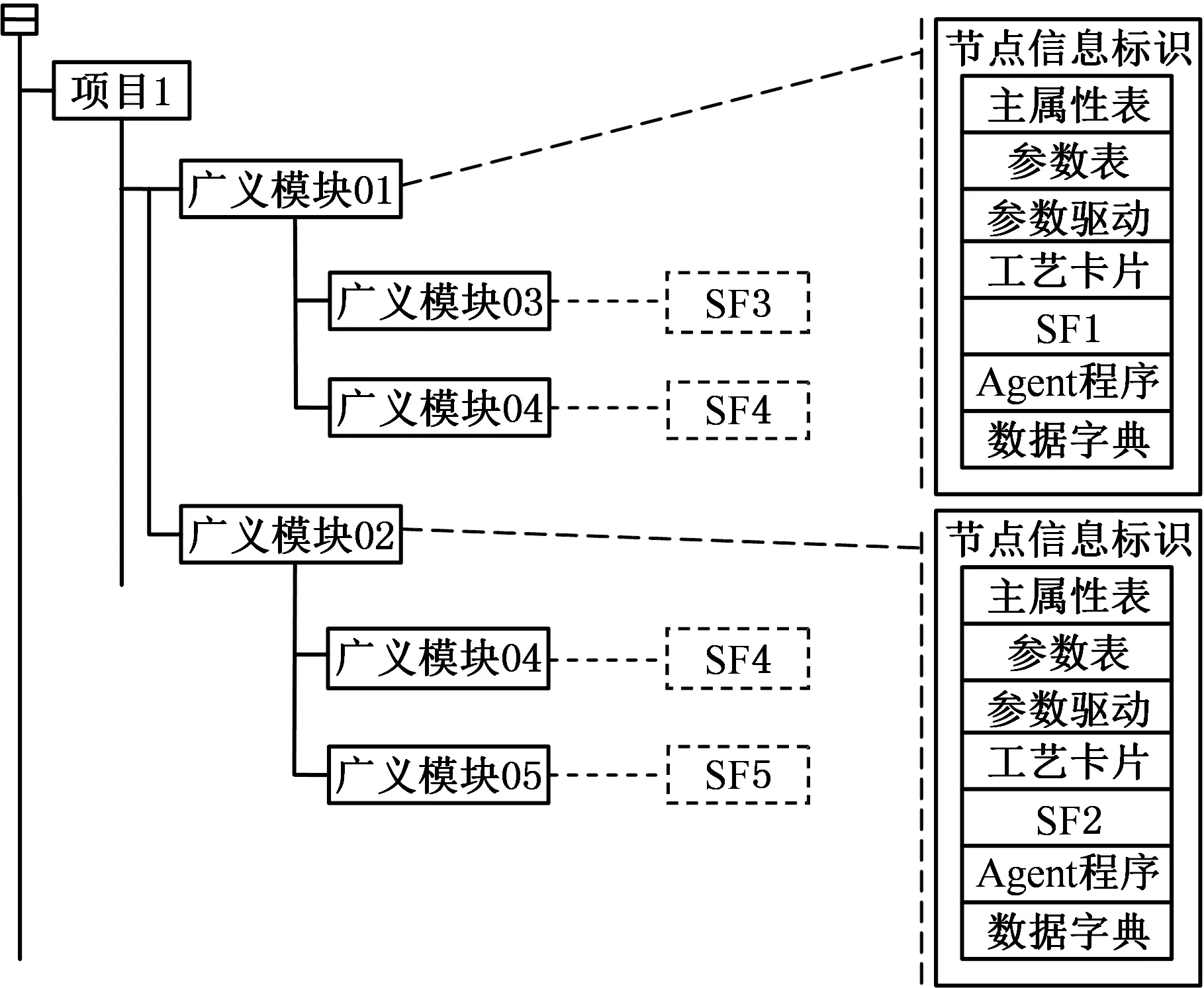
图3 产品族部分主结构Fig.3 Main structure of product family(part)
从广义模块表(表2)中抽取字段名为Gmodule ID(模块标识)和SF_Identify(等效类标识)的广义模块,如表3所示,再以六类DPIPP参数化模型的各类功能代码、工艺代码、结构代码作为数据表的字段,各类零部件的序号作为数据表的记录或事务,构建事务数据表A,如表4所示,其中0表示值为空。

表2 广义模块表

表3 功能数据字典(部分)

表4 事务数据表A
在产品族组织结构表(表5)中,查找每一个Node ID(Gmodule ID)的Fa_Node ID(父节点标识),再抽取广义模块表中与这些Fa_Node ID相同的Gmodule ID及其SF_Identify。最后同事务数据表A的字段和记录形式构建事务数据表B,如表6所示,若无父节点,则整条记录记为空。

表5 产品族组织结构表

表6 事务数据表B
将事务数据表A和事务数据表B分别转化为0-1矩阵,并将两个矩阵相加得到最终用于挖掘的事务数据表D,如表7所示。
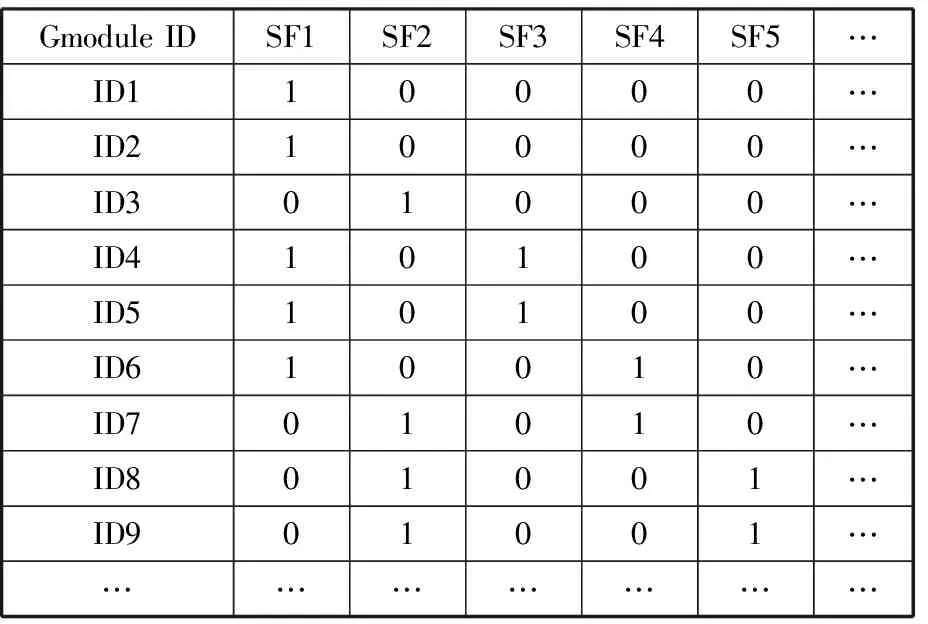
表7 事务数据表D
通过观测最终被用于挖掘的事务数据表可以发现,该事务数据表的每个事务仅包含1对项目的关联关系。因此,候选项集和频繁项集的生成只需进行到二阶,即只需生成候选1-项集、频繁1-项集、候选2-项集和频繁2-项集。这种特征的好处是既规避了由频繁(k-1)-项集生成候选k-项集时,候选项集呈指数增长的状态,又克服了需要多次扫描数据库的弊端。
2.3 项集的生成
在产品平台参数化模型间包含性分析中,候选项集的具体含义就是具有潜在关联关系的参数化模型,候选1-项集集合是由每一个参数化模型(项目)构成的,不具有实际意义,只作计算使用;候选2-项集集合由各个参数化模型(项目)两两组合而成。频繁项集的具体含义就是在候选项集中挖掘出的具有确定关联关系的参数化模型,频繁1-项集集合是由满足最小支持度设定的候选1-项集构成,频繁1-项集只作为生成候选2-项集的中间数据;频繁2-项集集合由满足最小支持度设定的候选2-项集构成,具有确定的参数化模型间的两两关联关系。
在实际的数据分析中,支持度需要根据分析的事务而设定。支持度过大或过小都不会得出理想的结果。从算法性能考虑,支持度取较小值容易造成候选项集偏多,牺牲算法性能;反之支持度取较大值会丢失部分潜在关系。
对于参数化模型间的包含性问题,若支持度取较大值,则有利于得到主要的包含性关系。在功能-结构方面,可以更加清晰地获得产品的主要配置,突出产品的必选结构与功能组成;在工艺方面,可以使用户更加快速地了解加工制造企业的加工能力与特色;若支持度取较小值,则有利于得到完整的包含性关系。在功能-结构方面,既可以得到主体结构和主要功能,又可以得到用于功能与结构扩展的可选结构、可选功能;在工艺方面,全面的包含性关系有利于发掘一个企业的生产潜力,扩大企业的生产范围和加工能力。
将表7作为事务数据库D,等效类与等效类模型间的包含性分析具体步骤如下:
(1)将事务数据表D转化为0-1矩阵,即

(2)生成候选1-项集C1={{SF1},{SF2},{SF3},{SF4},{SF5}}。
(3)分别对行(项目)和列(事务)求和,列求和即为支持数,行求和即为项目数。将项目的支持数按降序排列,得到矩阵如下:
(4)设最小支持数为1,求频繁1-项集L1,则频繁项集L1={{SF1},{SF2},{SF3},{SF4},{SF5}}。
(5)求频繁2-项集L2,删除M0中项目数小于2的行,保留其余行,得到剪枝后的矩阵M1:
(6)对频繁1-项集中的项进行组合,得到候选2-项集C2={{SF1,SF2},{SF1,SF3},{SF1,SF4},{SF1,SF5},{SF2,SF3},{SF2,SF4},{SF2,SF5},{SF3,SF4},{SF3,SF5},{SF4,SF5}}。
(7)计算候选2-项集的支持数:
Support_Count( SF1*SF2) = 0 Support_Count( SF1*SF3) = 2 Support_Count( SF1*SF4) = 1 Support_Count( SF1*SF5) = 0 Support_Count( SF2*SF3) = 0 Support_Count( SF2*SF4) = 1 Support_Count( SF2*SF5) = 2 Support_Count( SF3*SF4) = 0 Support_Count( SF3*SF5) = 0 Support_Count( SF4*SF5) = 0
(8)找出不小于最小支持数的项,则频繁项集L2={{SF1,SF3},{SF1,SF4},{SF2,SF4},{SF2,SF5}}。
2.4 强关联规则的生成
前文有针对性地对事务数据库D进行了构建,在频繁项集的生成过程中,较好地规避了经典Apriori算法可能生成过于庞大的候选项集及多次扫描数据库这两个瓶颈。但这样处理事务数据集也会存在弊端,即频繁2-项集虽然明确表示出了两个参数化模型之间具有包含性关系,但并没有体现出包含与被包含的关系,也不能直接通过设定最小置信度来判断。
通过分析事务数据集D可以发现一个规律,即在包含性关系的层次结构中,每个频繁2-项集的两个项目中,处于较高层级的参数化模型具有更高的置信度。因此,可以通过比较频繁2-项集内部的两个置信度大小,得到两个参数化模型之间的强关联关系(包含与被包含问题)。
以表7作为事例事务数据库D,比较每组频繁项集置信度的大小关系:
Support_Count(SF1*SF3)/ Support_Count(SF1)=2/5
Support_Count(SF1*SF3)/ Support_Count(SF3)=1
Support_Count(SF1*SF4)/ Support_Count(SF1)=1/5
Support_Count( SF1*SF4)/ Support_Count(SF4)=1/2
Support_Count( SF2*SF4)/ Support_Count(SF2)=1/4
Support_Count( SF2*SF4)/ Support_Count(SF4)=1/2
Support_Count( SF2*SF5)/ Support_Count(SF2)=1/2
Support_Count( SF2*SF5)/ Support_Count(SF5)=1
输出强关联规则:
{SF3}⟹{SF1} {SF4}⟹{SF1}
{SF4}⟹{SF2} {SF5}⟹{SF2}
得到强关联关系以后,最终的包含性关系可以输出为
{SF1}⊃{SF3,SF4} {SF2}⊃{SF4,SF5}
2.5 算法流程图
产品平台参数化模型包含性分析的算法可以用流程图来表示,如图4所示。
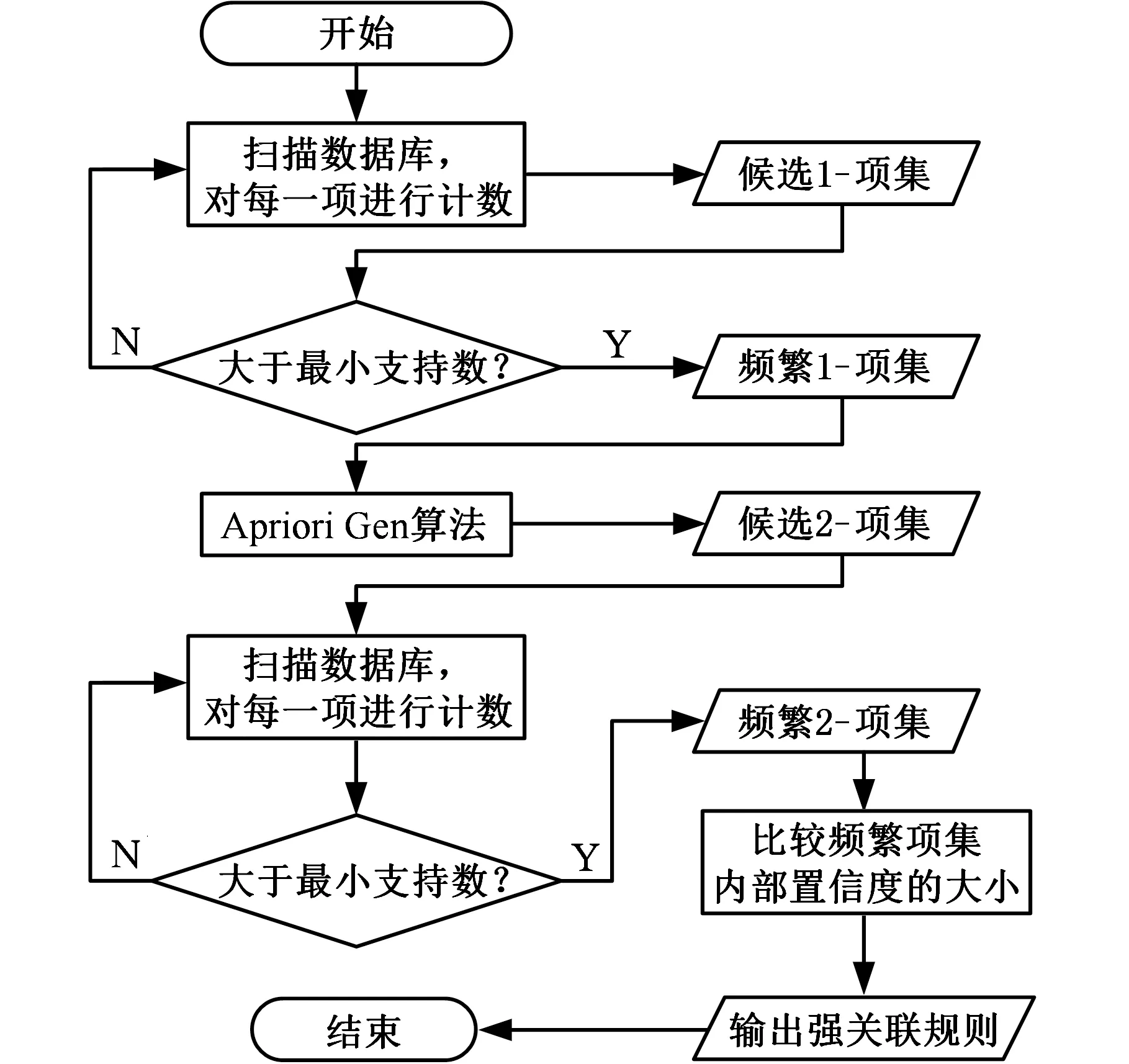
图4 算法流程图Fig.4 Flow chart of the algorithm
3 高中压阀门实例分析
Weka的全称为Waikato Environment for Knowledge Analysis(怀卡托智能分析环境),它是由Waikato大学自主开发的基于Java的公开数据挖掘平台,这个平台包含了大量的机器学习方法用以实现数据挖掘的功能。通过Weka接口,可以在Weka上实现自己的数据挖掘算法。根据本文研究的内容,选用软件Weka 的Explorer(探索)功能接口中的Associate(关联规则)选项卡。
利用部分高中压阀门产品结构数据,验证高中压阀门产品平台模型间包含性关系分析结果。经过对部分阀门数据的分析,得到部分阀门的产品族挖掘结果,同构类、等效类和等价类挖掘结果以及层次聚类部分结果如表8所示。
以蝶阀(图5)某个产品族为例,对等效类与等效类模型间的包含性关系进行分析,其阀门功能模块与其子功能模块、子结构模块的映射关系如图6所示。该映射关系用于阀门产品的创新及精确配置。将处理好的数据集导入Weka中,运行得到结果,部分结果如图7所示。从图7中可以得出最终的包含性关系为:{SF5}⊃{SF1,SF6},{SF10}⊃{SF2,SF3,SF4},{SF13}⊃{SF7,SF8,SF9},{SF14}⊃{SF5,SF11,SF12},该结果与实际是相符的。
以蝶阀和闸阀某个产品族为例,其阀门产品结构模块与其子结构模块间的映射关系如图8所示,该映射关系用于阀门产品快速变形及精确配置。将处理好的数据集导入Weka中,运行得到结果,部分结果如图9所示。

表8 模块标识

图5 蝶阀示意图Fig.5 Illustration of butterfly valve
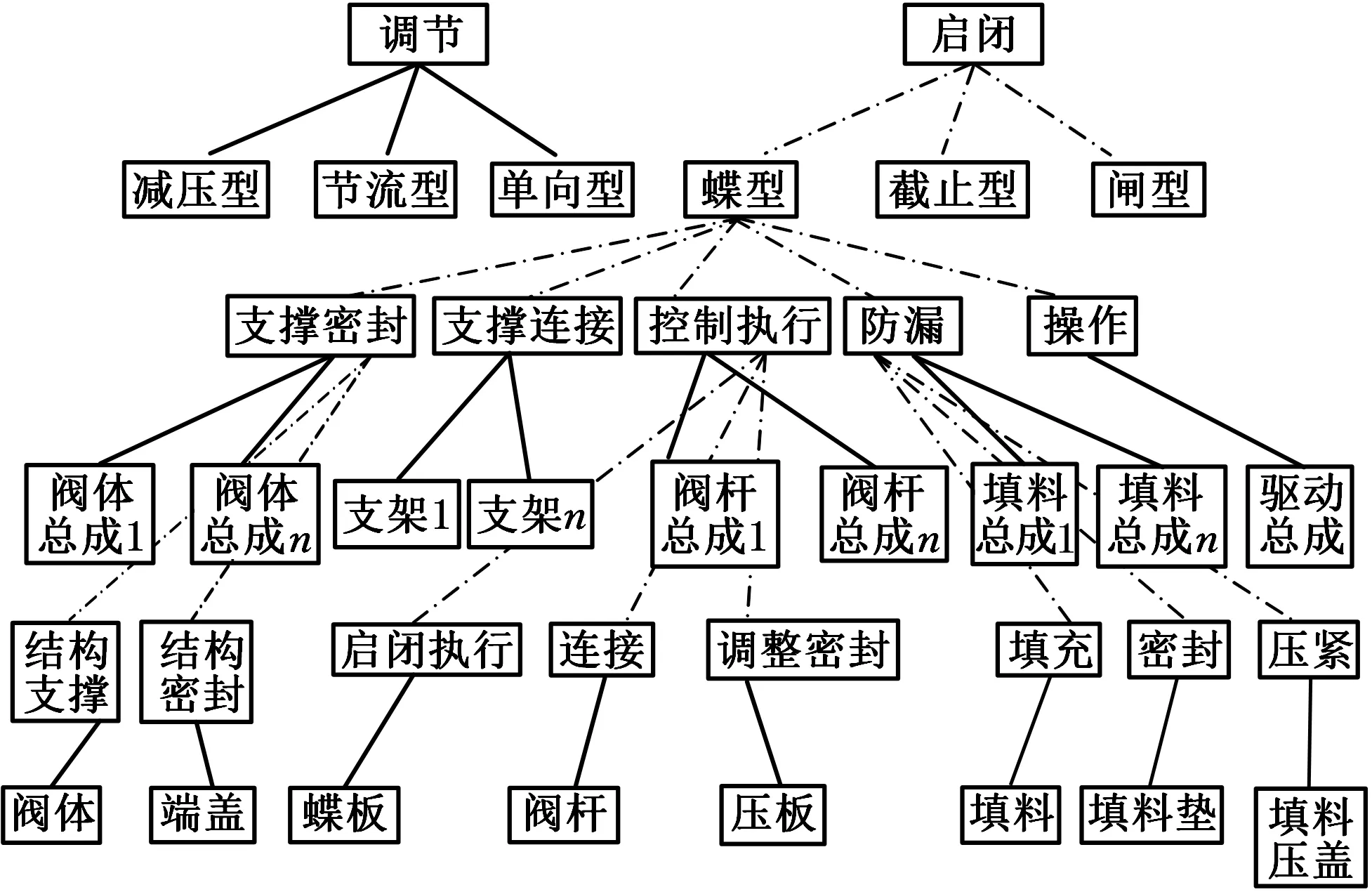
图6 功能类包含性关系Fig.6 Inclusion relation of function class
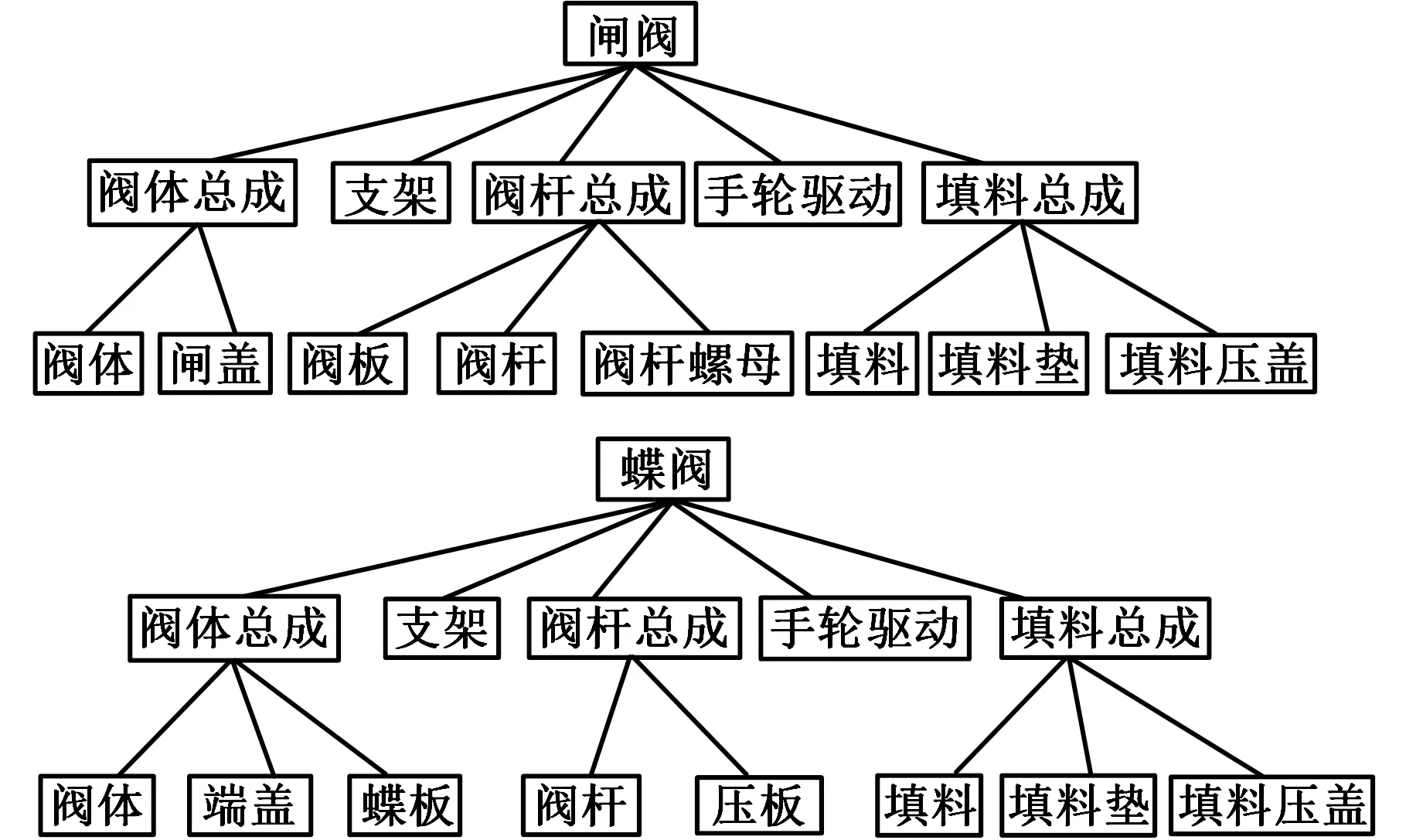
图8 结构类包含性关系Fig.8 Inclusion relation of structure class
以蝶阀的某个产品族为例,工艺与子工艺、子结构的映射关系如图10所示。该包含性关系直接面向的是工艺规划。将处理好的数据集导入Weka中,运行得到结果,部分结果如图11所示。

图10 工艺类包含性关系Fig.10 Inclusion relation of process class
4 结论
本文以结构同构类和非同构聚类模型、功能等效类和非等效聚类模型、工艺等价类和非等价聚类模型这六类参数化模型为研究对象,基于经典Apriori算法对这六类模型间的潜在关系进行研究,得到了一种挖掘出这六类模型间包含性关系的方法,并以高中压阀门数据为实例进行了验证。
[1] GOEL A K, RUGABER S, VATTAM S. Structure, Behavior, and Function of Complex Systems:the Structure, Behavior, and Function Modeling Language[J]. Artificial Intelligence for Engineering Design, Analysis and Manufacturing, 2009, 23(1):23-35.
[2] 马军,祁国宁,樊蓓蓓. 基于本体的零件资源通用分类技术[J].机械工程学报,2010,46(9):150-157. MA Jun, QI Guoning, FAN Beibei. Parts Resource General Classification Technology Based on Ontology[J]. Journal of Mechanical Engineering, 2010, 46(9):150-157.
[3] ZENG F, LI B, ZHENG P, et al. A Modularized Generic Product Model in Support of Product Family Modeling in One-of-a-Kind Production[C]∥2014 IEEE International Conference on Mechatronics and Automation. Tianjin:IEEE, 2014:786-791.
[4] XIA S S, WANG L Y. Customer Requirements Mapping Method Based on Association Rules Mining for Mass Customisation[J]. International Journal of Computer Applications in Technology, 2010, 37(3/4):198-203.
[5] 鲁玉军,雷呈瑜,顾新建,等. 基于最大适应度优化算法的订单产品模块化设计方法[J]. 计算机集成制造系统,2013,19(5):909-917. LU Yujun, LEI Chengyu, GU Xinjian, et al. Modular Design of Order Product Based on Improved LFM Algorithm[J]. Computer Integrated Manufacturing Systems, 2013, 19(5):909-917.
[6] 樊蓓蓓,祁国宁,俞涛. 基于网络分析法的模块化产品平台中零部件模块通用性分析[J]. 计算机集成制造系统,2013,19(5):918-925. FAN Beibei, QI Guoning, YU Tao. Network Analysis Method for Commonality Analysis of Parts Modules in Modular Product Platform[J]. Computer Integrated Manufacturing Systems, 2013, 19(5):918-925.
[8] 毛新华,侯志松,徐君鹏. 基于复杂产品智能化数字设计系统研究[J]. 组合机床与自动化加工技术,2010(8):100-104. MAO Xinhua, HOU Zhisong, XU Junpeng. Research on the Intelligent Digital Design System Based on Complex Products[J]. Modular Machine Tool & Automatic Manufacturing Technique, 2010(8):100-104.
[9] ALBLAS A, ZHANG L L, WORTMANN H. Representing Function-technology Platform Based on the Unified Modelling Language[J]. International Journal of Production Research, 2012, 50(12):3236-3256.
[10] 陈子顺,张鹏,檀润华. AFD和功能结构分解在PSM中的应用[J]. 机械设计,2010,27(12):92-96. CHEN Zishun, ZHANG Peng, TAN Runhua. Applying AFD and the Functional Structure Decomposition in PSM[J]. Journal of Machine Design, 2010, 27(12):92-96.
[11] 张广军,唐敦兵. 基于改进型功能方法树的公理化设计[J]. 工程设计学报,2009,16(1):1-6. ZHANG Guangjun, TANG Dunbing. Axiomatic Design Based on Improved Function-means Tree[J]. Journal of Engineering Design, 2009, 16(1):1-6.
[12] 唐文献,吴春燕,马宝,等. 基于模糊聚类分析的锚绞机模块划分方法研究[J]. 机械设计,2012,29(10):24-28. TANG Wenxian, WU Chunyan, MA Bao, et al. Modular Division Method of Anchor and Windlass Based on Illegible Clustering[J]. Journal of Machine Design, 2012, 29(10):24-28.
[13] 王美清,王彬,唐晓青. 基于组件失效知识的结构组件优选方法[J]. 计算机集成制造系统,2011,17(2):267-272. WANG Meiqing, WANG Bin, TANG Xiaoqing. Optimal Component Subset Selection Method Based on Component-failure Knowledge[J]. Computer Integrated Manufacturing Systems, 2011, 17(2):267-272.
[14] 李湉,陈五一. 基于加工特征分类的整体叶轮加工工艺研究[J]. 机械设计与制造,2010(5):105-107. LI Tian, CHEN Wuyi. Machining Process Technology for Blisk Based on Manufacture Feature Taxonomy[J]. Machinery Design & Manufacture, 2010(5):105-107.
[15] CHEN C, WANG L. Product Platform Design through Clustering Analysis and Information Theoretical Approach[J]. International Journal of Production Research, 2008, 46(15):4259-4284.
[16] WANG Z. Research on Planning Method of Adaptable Modular Product Platform[C]∥2011 International Conference on Control, Automation and Systems Engineering (CASE). Singapore, 2011:1-4.
[17] LOPEZ-HERREJON R E, MONTALVILLO-MENDIZABAL L, Egyed A. From Requirements to Features:an Exploratory Study of Feature-oriented Refactoring[C]∥Software Product Line Conference (SPLC), 15th International. Munich:IEEE, 2011:181-190.
[18] SCHÖNSLEBEN P. Methods and Tools that Support a Fast and Efficient Design-to-order Process for Parameterized Product Families[J]. CIRP Annals—Manufacturing Technology, 2012, 61(1):179-182.
[19] SURAJ Z. Parameterised Fuzzy Petri Nets for Approximate Reasoning in Decision Support Systems[C]∥International Conference on Advanced Machine Learning Technologies and Applications. Cairo:Springer,2012:33-42.
[20] 李戬,杨媛媛. 基于广义参数化技术的机械产品设计方法研究[J]. 矿山机械,2012,40(12):104-108. LI Jian, YANG Yuanyuan. Design Method of Machanical Products Based on Generalized Parameterization Technology[J]. Mining & Processing Equipment, 2012, 40(12):104-108.
[21] 杨金勇. 概念设计过程中产品功能的广义定位表达[J]. 机械设计,2014,30(6):6-12. YANG Jinyong. Generalized Positioning Expression of Product Function in Conceptual Design Process[J]. Journal of Machine Design, 2014, 30(6):6-12.
[22] ASADI M, SOLTANI S, GASEVIC D, et al. Toward Automated Feature Model Configuration with Optimizing Non-functional Requirements[J]. Information and Software Technology, 2014, 56(9):1144-1165.
[23] 黄勇,刘锋. 基于SQL的多值多层关联规则挖掘[J]. 计算机技术与发展,2008,18(6):101-103. HUANG Yong, LIU Feng. SQL-Based Multi-value Multilayer Mining Association Rules Excavation[J]. Computer Technology and Development, 2008, 18(6):101-103.
[24] 谢亮,张晶,胡学钢. 主从关系数据库中关联规则挖掘算法研究[J]. 合肥工业大学学报,2009,32(5):663-666. XIE Liang, ZHANG Jing,HU Xuegang. Research on the Algorithms for Mining Association Rules in the Master-slave Relationship Database[J]. Journal of Hefei University of Technology, 2009, 32(5):663-666.
[25] 纪怀猛. 基于频繁 2 项集支持矩阵的 Apriori 改进算法[J]. 计算机工程,2008,39(11):183-186. JI Huaimeng. Improved Apriori Algorithm Based on Frequency 2-item Set Support Matrix[J]. Comuter Engineering, 2008, 39(11):183-186.
[26] 甘超,陆远,李娟,等. 基于Apriori算法的设备故障诊断技术的研究[J]. 组合机床与自动化加工技术,2014(1):100-103. GAN Chao, LU Yuan, LI Juan, et al. Equipment Fault Diagnosis Technology Based on Apriori Algorithm[J]. Modular Machine Tool & Automatic Manufacturing Technique, 2014(1):100-103.
[27] INOKUCHI A, WASHIO T, MOTODA H. An Apriori-based Algorithm for Mining Frequent Substructures from Graph Data[C]∥European Conference on Principles of Data Mining and Knowledge Discovery. Lyon, France:Springer, 2000:13-23.
(编辑 苏卫国)
Analysis of Inclusion Relation of Parameterized Models for Product Platforms
ZENG Shasha PENG Weiping YAN Wei
School of Power and Mechanical Engineering,Wuhan University,Wuhan,430072
Based on Apriori algorithm, inclusion relations of parameterized models and their concealing database were studied. A method which might avoid the two performance bottlenecks of Apriori algorithm was used. This method may reduce the times of scanning database. The results of inclusion relations were ouPSut by comparing the confidence of frequent itemsets. Taking the data of high pressure valves as the target, the theory of inclusion relation was confirmed by the Explorer module of Weka and the inclusion relations of high pressure valves were ouPSut.
product platform; parameterized model; inclusion relation; transaction database
2017-01-03
国家自然科学基金资助项目(51505343,51275362);中国博士后科学基金资助项目(2015M572192);中央高校基本科研业务费专项资金资助项目(2042015kf0048)
TH16
10.3969/j.issn.1004-132X.2017.12.014
曾莎莎,女,1987年生。武汉大学动力与机械学院讲师。研究方向为数字化设计与制造。发表论文5篇。E-mail:sszeng@whu.edu.cn。彭卫平(通信作者),男,1964年生。武汉大学动力与机械学院教授、博士研究生导师。E-mail:wppengwhu@163.com。闫 玮,男,1989年生。武汉大学动力与机械学院硕士研究生。
