基于潜语义主题加强的跨媒体检索算法
2017-06-27黄育,张鸿
黄 育,张 鸿
1.武汉科技大学 计算机科学与技术学院,武汉 430065;2.智能信息处理与实时工业系统湖北省重点实验室(武汉科技大学), 武汉 430065)(*通信作者电子邮箱zhanghong_wust@163.com)
基于潜语义主题加强的跨媒体检索算法
黄 育1,2,张 鸿1,2*
1.武汉科技大学 计算机科学与技术学院,武汉 430065;2.智能信息处理与实时工业系统湖北省重点实验室(武汉科技大学), 武汉 430065)(*通信作者电子邮箱zhanghong_wust@163.com)
针对不同模态数据对相同语义主题表达存在差异性,以及传统跨媒体检索算法忽略了不同模态数据能以合作的方式探索数据的内在语义信息等问题,提出了一种新的基于潜语义主题加强的跨媒体检索(LSTR)算法。首先,利用隐狄利克雷分布(LDA)模型构造文本语义空间,然后以词袋(BoW)模型来表达文本对应的图像;其次,使用多分类逻辑回归对图像和文本分类,用得到的基于多分类的后验概率表示文本和图像的潜语义主题;最后,利用文本潜语义主题去正则化图像的潜语义主题,使图像的潜语义主题得到加强,同时使它们之间的语义关联最大化。在Wikipedia数据集上,文本检索图像和图像检索文本的平均查准率为57.0%,比典型相关性分析(CCA)、SM(Semantic Matching)、SCM(Semantic Correlation Matching)算法的平均查准率分别提高了35.1%、34.8%、32.1%。实验结果表明LSTR算法能有效地提高跨媒体检索的平均查准率。
跨媒体检索;潜语义主题;多分类逻辑回归;后验概率;正则化
0 引言
当前,现实世界中的很多应用都涉及多模态文件,在多模态文件里信息由不同模态的数据组成,例如一篇新闻文章由图片和相应的文字描述组成。在近几年来,与多媒体相关的研究发展迅速,其中跨媒体检索成为一个研究的热点。在跨媒体检索中,如何挖掘不同类型数据之间的内在联系,进而计算跨媒体数据之间的相似度,是跨媒体检索需要解决的关键问题[1]。
为了解决这个问题,典型相关性分析(Canonical Correlation Analysis, CCA)、核典型相关性分析(Kernel Canonical Correlation Analysis, KCCA)[2]、稀疏典型相关性分析(Spase Canonical Correlation Analysis, SpaseCCA)、结构稀疏典型相关分析(Structured Spase Canonical Correlation Analysis, Structured Spase CCA)等围绕CCA的算法被提出用来实现不同模态数据之间的相互检索[3]。它们的主要思想是将不同模态的数据通过某种映射,使得映射后的向量之间的皮尔逊相关系数最大。但是它们都没有有效利用不同模态数据的类别信息。为了利用数据的类别信息,可以将图像特征或文本特征表达成视觉词袋(Bag of Visual Words, BoVW)或者单词词袋(Bag of Words, BoW),一些通过隐狄利克雷分布(Latent Dirichlet Allocation, LDA)[4]来实现不同模态数据的关联建模的方法也相继被提出。为了进一步探究文本图像所蕴含的相关联语义[5-6],多模态文档随机场等概率图模型方法也被用来对不同模态数据之间的关联关系建模[7]。最近由于深度学习[8]的兴起,很多与深度学习相关的模型也被用于跨媒体检索[9-10],如玻尔兹曼机[11]和卷积神经网络等深度学习模型。同时为了实现海量数据的高效检索,一些基于哈希(Hash)[12]的算法也被用于跨媒体检索的研究[13-15],如局部敏感哈希(Locality Sensitive Hashing, LSH)算法、多视图哈希索引等。
本文为了探究不同模态数据之间的语义相关关系以及如何有效地利用数据的标签信息,提出了一种新的基于潜语义主题加强的跨媒体检索算法。算法的主要流程如下:
1)利用多分类逻辑回归对图像和文本进行分类,得到分类模型,然后利用分类模型计算图像和文本基于多分类的后验概率,使用该后验概率向量表示图像和文本的潜语义主题。
2)由于文本的潜语义主题比图像潜语义主题更加明晰,为了使文本和图像的潜语义主题的相关性最大,用文本潜语义主题正则化图像潜语义主题,使图像和文本的潜语义主题趋于一致。
3)利用皮尔逊相关系数来度量文本和图像向量之间的相似性,实现图像和文本之间的相互检索。
实验结果表明,本文方法能够有效地提高跨媒体检索的准确率。
1 提取图像和文本的潜语义主题
利用多分类逻辑回归模型提取图像和文本的潜语义主题,该模型也称softmax回归。Softmax回归是有监督学习算法,通过训练数据建立模型,然后利用模型估算测试数据基于每一个类别的后验概率。将m个已标记训练数据样本表示为{(x(1),y(1)),(x(2),y(2)),…,(x(m),y(m))},其中输入样本特征x(i)∈Rn+1,n+1为输入文本或图像特征的维度;y(i)∈{1,2,…,k}为对应类别的标记值,不同的标签值对应不同的类别信息,k为总类别数。对于给定的测试输入X,用假设函数针对每一个类别j估算出后验概率值p(y=j|x),也就是计算x基于每一种分类结果出现的概率。因此,假设函数会输出一个k维向量(向量的各个元素之和为1)来表示测试数据基于k个类别的估算概率值,可用如下公式表示:

(1)
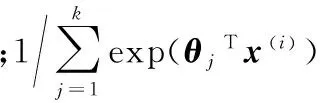
求解θ,需要设置一个代价函数,如果能够使用优化算法求解代价函数的最小值,即可得到θ。通过在代价函数中添加一个权重衰减项,Softmax模型的代价函数可以表示为:
(2)
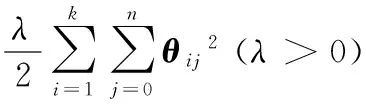
求解得到θ后,就可以得到文本和图像基于各个类别的后验概率,用该后验概率向量表示图像和文本的潜语义主题。
2 基于正则化的潜语义主题加强
本文提出的基于潜语义主题加强的跨媒体检索算法,就是在提取图像和文本潜语义主题的基础上,为了使图像和文本的潜语义主题之间的相关性最大,用正则化的方法对图像潜语义主题进行加强。算法流程如图1所示。
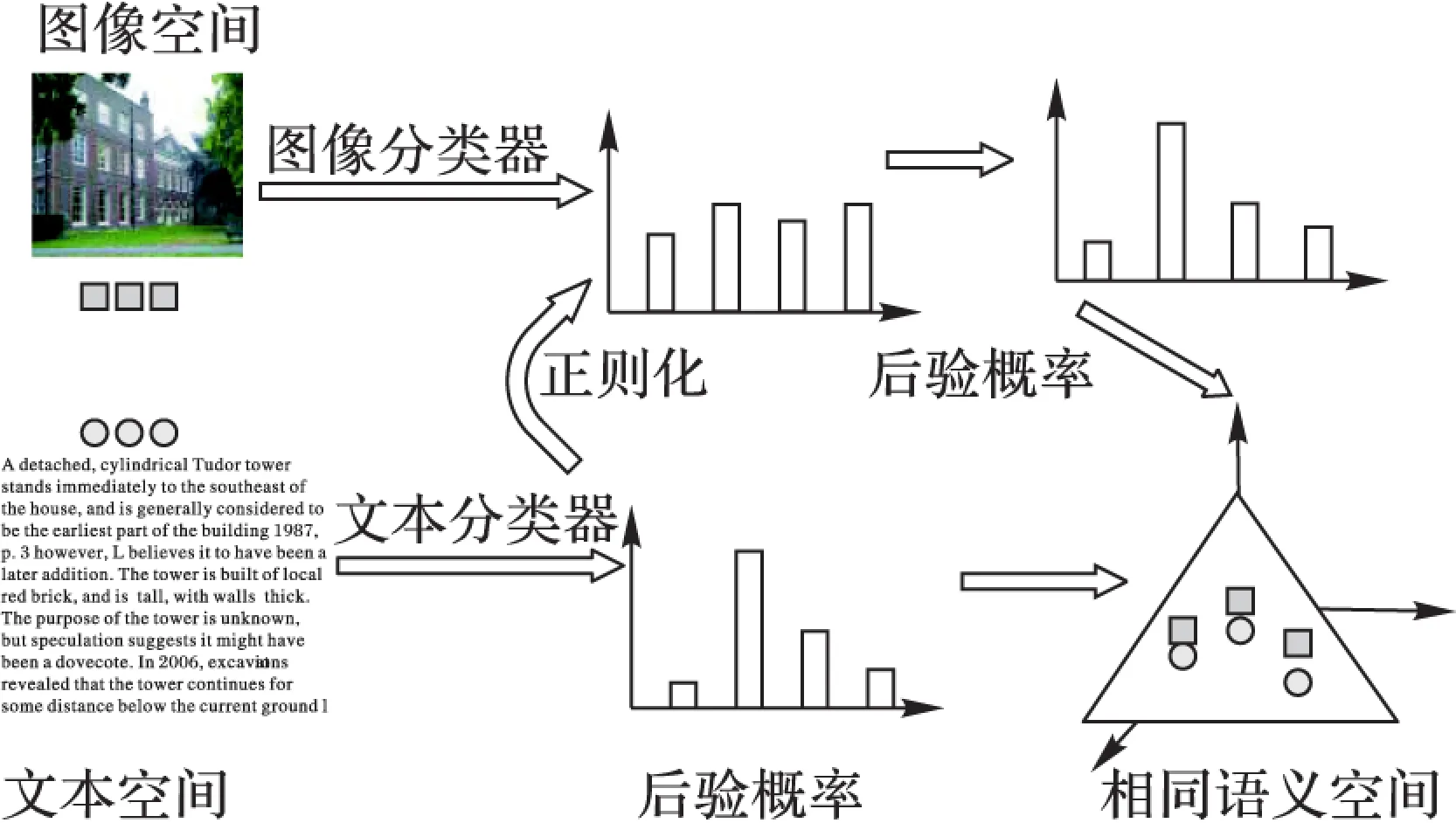
图1 基于潜语义主题加强的跨媒体检索算法
由于图像是在像素级别上的语义抽象,通过多分类逻辑回归模型得到的潜语义主题并不明晰,而文本得到潜语义主主题较为明确,因此可用文本的潜语义主题来正则化图像的潜语义主题,使图像的潜语义主题得到加强,同时也使图像和文本的潜语义主题之间的关联性最大化。图像的潜语义主题用X=[x1,x2,…,xn]T∈Rn×k表示,文本的潜语义主题用T=[t1,t2,…,tn]T∈Rn×k表示。正则化图像就是使图像的潜语义主题X与文本的潜语义主题T所表达的语义主题尽可能地趋于相近,即:
H:xi→ti
(3)
H为一个线性转换矩阵:
T=XH
(4)
把式(4)展开来为:
(5)
其中:hi为H的列向量。用最小二乘算法来求得最优的H,其约束条件为:
xiThk≥0;∀i=1,2,…,N;∀k=1,2,…,K
(6)
∑xiTH=1;∀i=1,2,…,K
(7)
式(6)~(7)是根据文本特征和图像特征,经过多分类逻辑回归得到的基于各个类别的后验概率向量的元素之和为1,且每一个的概率都大于0得来的。式(4)可以转换为最小二乘法的规范形式:
b=Mx
(8)
其中:b∈RNK,x∈RK2为列向量,M∈RNK×K2为稀疏矩阵。将式(8)展开为:
(9)
为了表达成最小二乘的规范形式,引进矩阵S∈RN×K2如下:
(10)
则式(4)在式(6)、(7)的约束条件下可以表达为求解:
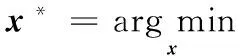
(11)
s.t.Mx≥0;Sx=1
根据式(11)即可求解得到正则化因子H。
整个算法的流程如下。
算法1 基于潜语义主题加强的跨媒体检索算法。
输入:带有类别信息的图像和文本,统一表示为{(x(1),y(1)),(x(2),y(2)),…,(x(m),y(m))}。
1)根据式(1)、(2)求解得到图像和文本的潜语义主题。
图像的潜语义主题:X=[x1,x2,…,xn]T
文本的潜语义主题:T=[t1,t2,…,tn]T
2)对每一个类别(i=1,2,…,L)求解:
s.t.Mx≥0;Sx=1
根据式(9)、(10)中M、b、S的定义计算正则化矩阵。
输出:正则化矩阵H=[H1,H2,…,HL]。
图像的潜语义主题乘上正则化因子,即可得到初步正则化的图像,使用文本每一个类别的后验概率乘上初步正则化图像的每一类别的后验概率,即可实现图像和文本的潜语义主题之间的关联最大化。
3 实验分析
3.1 实验数据集和数据表示
为了验证本文算法的有效性,实验在Wikipedia和TVGraz这两个跨媒体检索常用的数据集上进行。Wikipedia数据集包含2 866个文本图像数据对,这些文本图像数据对属于10个不同的类别,实验随机选取2 173个文本图像数据对作训练,剩余693个图像文本数据对作测试。TVGraz包含2 058个图像文本数据对,这些图像文本数据对同样属于10个不同的类别,实验采用1 588个文本图像数据对做训练,500个图像文本数据对测试。在所有实验中,图像表示基于词袋(BoW)模型,即用1 024个视觉词码量化图像提取的SIFT(Scale-InvariantFeatureTransform)特征;文本表示基于LDA模型,即计算每个文本基于100个隐含主题的概率。
3.2 度量标准
实验采用皮尔逊相关系数来度量特征向量之间的相似性,通过相似性对检索结果进行排序,将排序后的检索结果作为查询返回的结果。其计算公式如下:
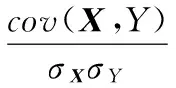
3.3 实验结果的评价
实验采用平均查准率(mean Average Precision, mAP)和召回率对算法的性能进行评价。查准率(Average Precision,AP)的计算公式如下:
其中:L为查询返回的结果中相关结果的个数;R为查询返回的结果总数;prec(r)表示返回的结果在r处的排名精度;δ(r)=1表示返回的结果相关;δ(r)=0则表示返回的结果不相关。本文实验中R=10。
3.4 实验结果与分析
在Wikipedia和TVGraz两个数据集上实验,将本文提出的LSTR算法与主流跨媒体CCA算法、SM(SemanticMatching)算法、SCM(SemanticCorrelationMatching)算法的平均查准率(mAP)进行对比,mAP为文本检索图像和图像检索文本的AP的平均值。对比情况如表1所示。

表1 Wikidedia和TVGraz数据集中算法性能对比
从表1可以看出,本文算法性能明显高于对比算法的性能,尤其是文本检索图像的平均查准率。其次,从表1不同数据集的对比可以看出,在TVGraz数据集上各个算法的性能明显高于Wikipedia数据集。这是由于TVGraz数据集的图像都是一个特定的物体或动物类别比较明显,而Wikipedia图像反映的内容则比较抽象,类别属性模糊。
实验不仅对整体数据的平均查准率进行了分析,还比较了不同类别的样例在Wikipedia数据集上的平均查准率。
图2为图像检索文本的不同类别样例的平均查准率,图3为文本检索图像的不同类别样例的平均查准率(),图4为不同类别样例平均查准率。对比图2~4可看出,本文算法的性能大幅度高于对比算法的性能,特别是文本检索图像。这是因为文本检索图像时,图像是被文本正则化之后的图像,它的潜语义主题与文本的潜语义主题相近,而图像检索文本时,图像只是利用多分类回归模型提取的潜语义主题,没有经过相应文本的正则化。
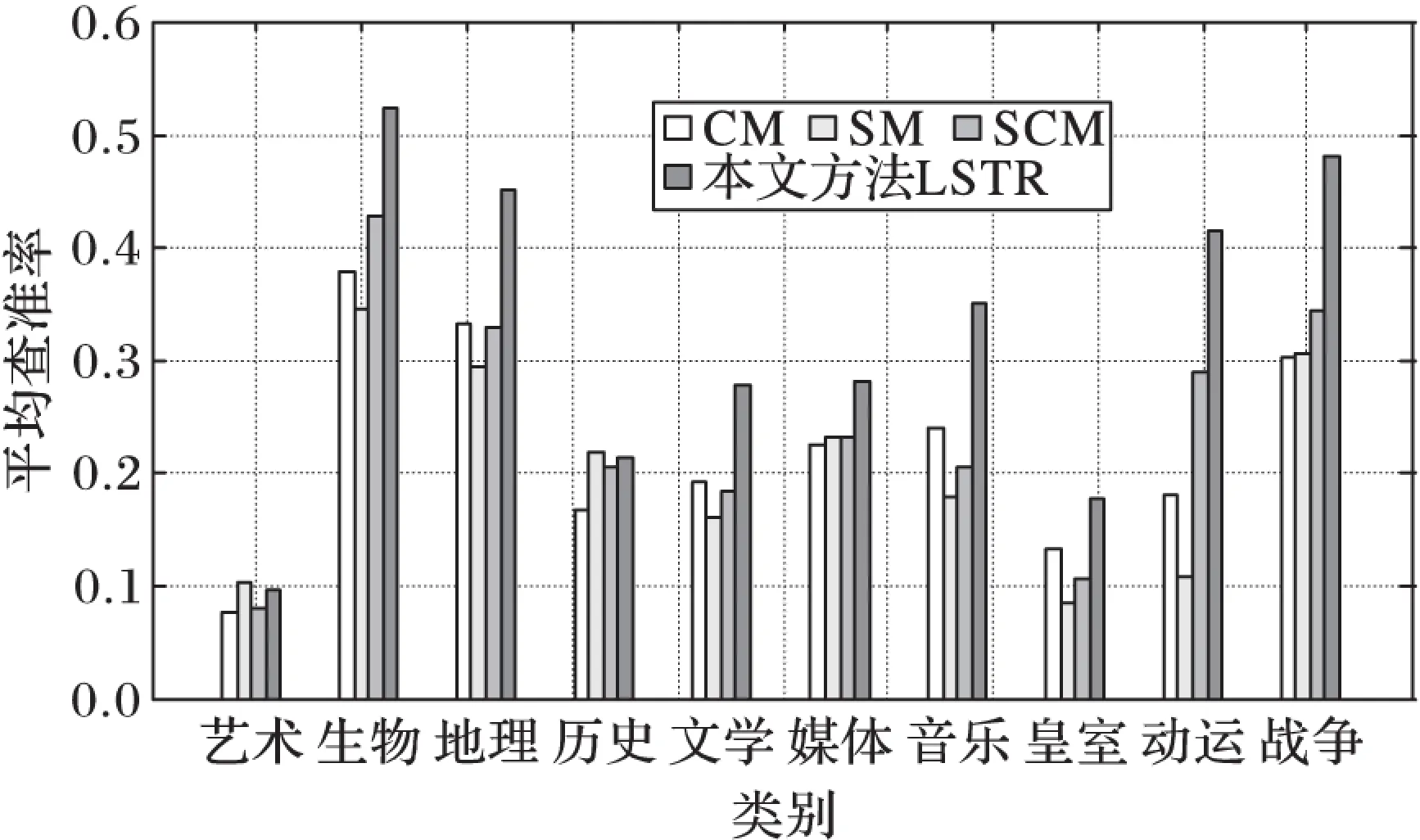
图2 不同类别样例的平均查准率(图像检索文本)

图3 不同类别样例的平均查准率(文本检索图像)

图4 不同类别样例的平均查准率
平均查准率只是信息检索算法性能评价的一个标准,除了平均查准率,实验还在Wikipedia数据集上对文本检索图像和图像检索文本的检索结果的准确率-召回率曲线进行了分析,如图5~6所示。
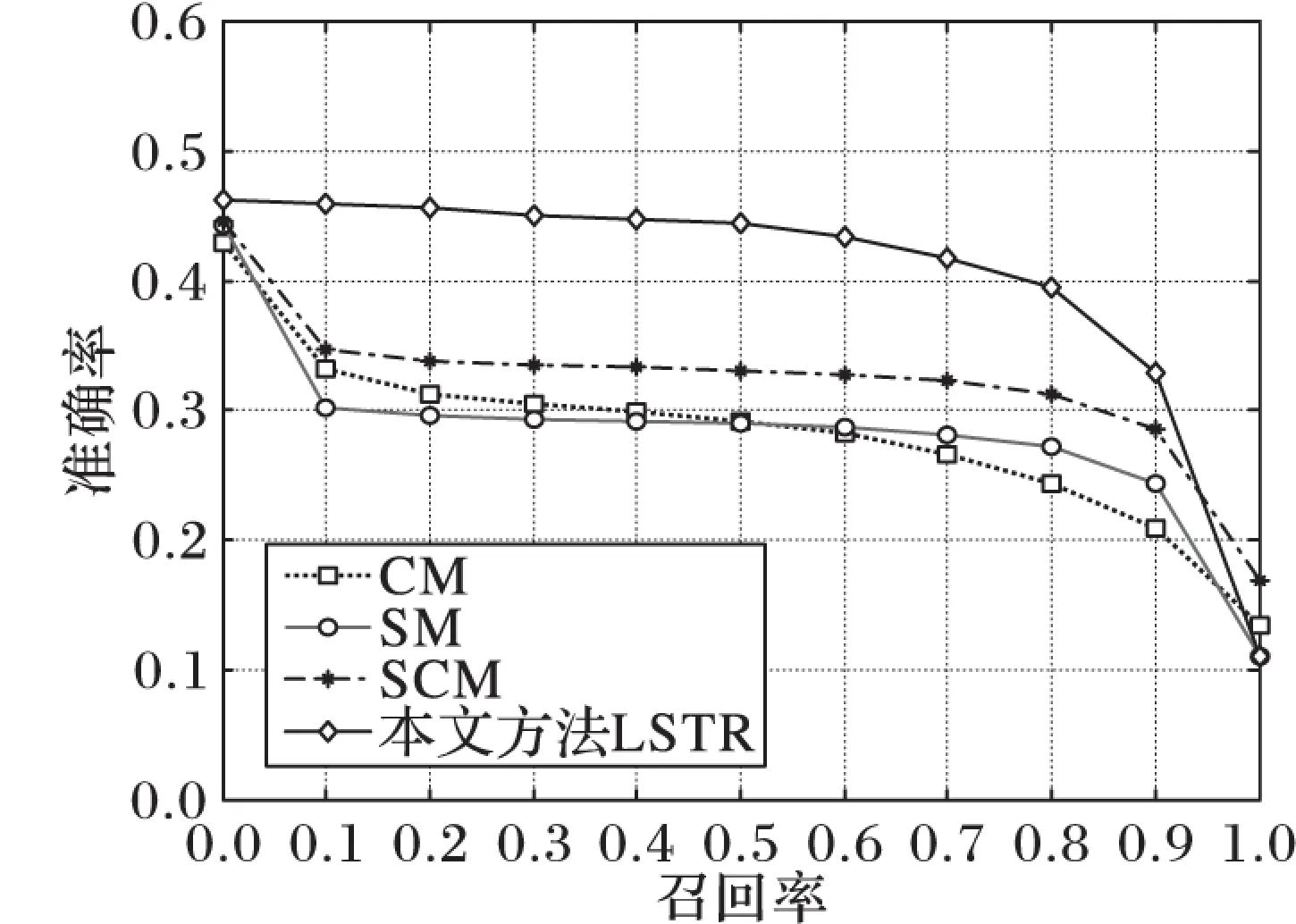
图5 图像检索文本的准确率-召回率曲线
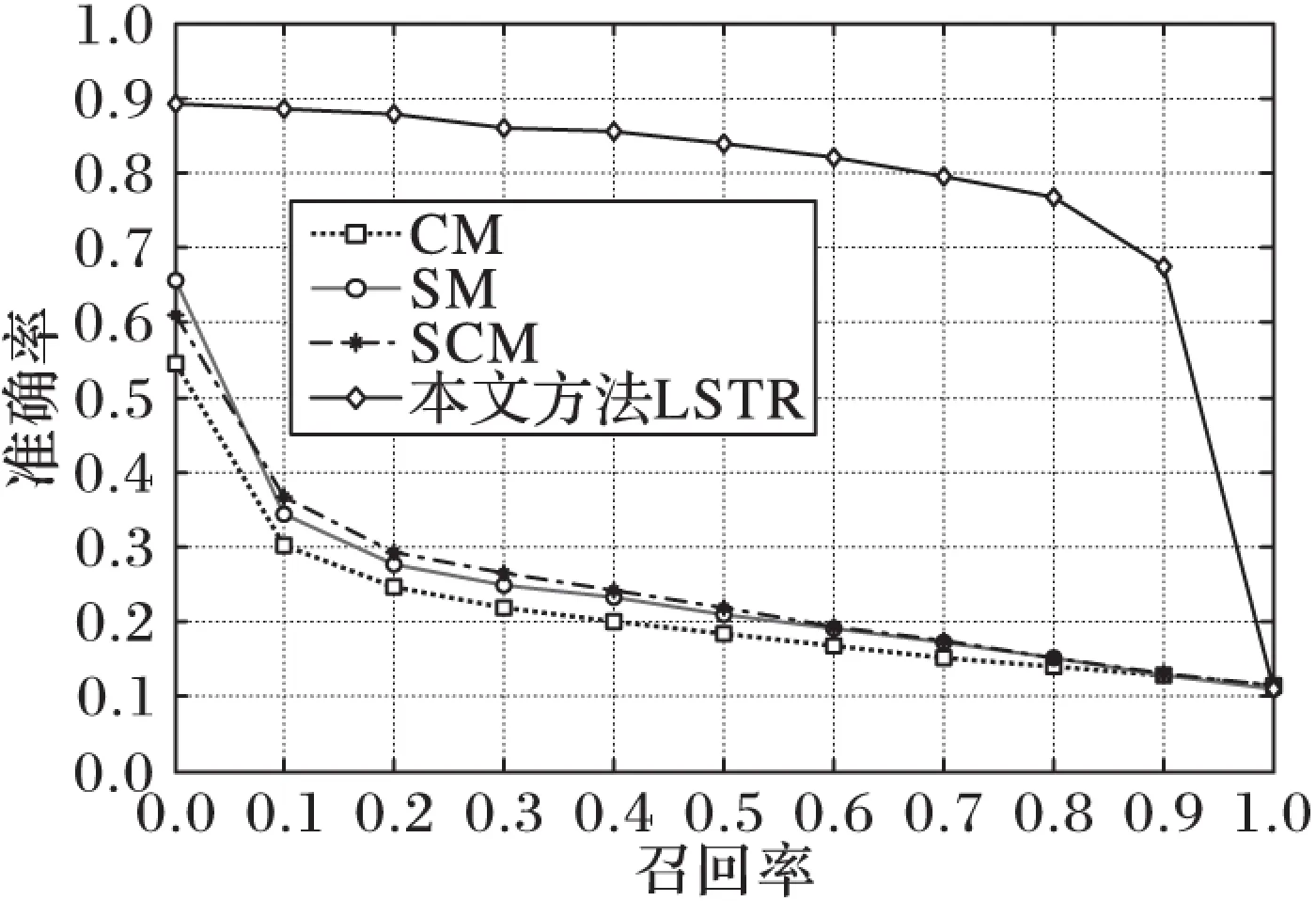
图6 文本检索图像的准确率-召回率曲线
从图5~6可看出:本文提出的LSTR算法随着召回率的增大,其检索结果准确率的下降幅度比CCA、SM、SCM等跨媒体检索算法的下降幅度要平缓,即本文算法的准确率受召回率的影响较小,也就是当检索结果的召回率增大时,本文算法仍能保持较高的准确率。
4 结语
本文提出的基于潜语义加强的跨媒体检索算法,在Wikipedia和TVGraz两个数据集上的实验,验证了本文算法能有效提高跨媒体检索的查准率,尤其是文本检索图像的查准率,为跨媒体检索提供了一种新的思路:使用文本的语义去强化图像的语义,使图像和文本的潜语义主题达到一致,来实现图像和文本的相互检索。但另一方面,本文算法在图像检索文本时查准率提高的幅度不大,这是因为没有相应的文本对查询的图像进行语义加强,图像和文本的关联没有最大化,所以如何对无文本注释的图像加强其潜语义主题还有待进一步的探索。
)
[1] 吴飞, 庄越挺.互联网跨媒体分析与检索:理论与算法 [J]. 计算机辅助设计与图形学学报, 2010, 22(1):1-9.(WUF,ZHUANGYT.CrossmediaanalysisandretrievalontheWeb:theoryandalgorithm[J].JournalofComputer-AidedDesignandComputerGraphics, 2010, 22(1):1-9.)
[2]CHENX,LIUH,CARBONELLJG.Structuredsparsecanonicalcorrelationanalysis[EB/OL]. [2016- 03- 10].https://www.cs.cmu.edu/~jgc/StructuredSparseCanonicalCorrelationAnalysisAISTATS2012.pdf.
[3] 张鸿, 吴飞, 庄越挺, 等.一种基于内容相关性的跨媒体检索方法[J]. 计算机学报, 2008, 31(5):820-826.(ZHANGH,WUF,ZHUANGYT,etal.Cross-mediaretrievalmethodbasedoncontentcorrelation[J].ChineseJournalofComputers, 2008, 31(5):820-826.)
[4]PUTTHIVIDHYD,ATTIASHT,NAGARAJANSS.Topicregressionmulti-modallatentDirichletallocationforimageannotation[C]//Proceedingsofthe2010IEEEConferenceonComputerVisionandPatternRecognition.Piscataway,NJ:IEEE, 2010: 3408-3415.
[5]WUF,JIANGX,LIX,etal.,Cross-modallearningtorankvialatentjointrepresentation[J].IEEETransactionsonImageProcessing, 2015, 24(5): 1497-1509.
[6]GONGY,KEQ,ISARDM,etal.Amulti-viewembeddingspaceformodelingInternetimages,tags,andtheirsemantics[J].InternationalJournalofComputerVision, 2014, 106(2):210-233.
[7] ZHEN Y, YEUNG D Y. A probabilistic model for multimodal hash function learning[C]// KDD 2012: Proceedings of the 18th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining. New York: ACM, 2012: 940-948.
[8] SHANG X, ZHANG H, CHUA T-S. Deep learning generic features for cross-media retrieval[C]// MMM 2016: Proceedings of the 22nd International Conference on MultiMedia Modeling, LNCS 9516. Berlin: Springer, 2016: 264-275.
[9] FROME A, CORRADO G, SHLENS J, et al. DeViSE: a deep visual-semantic embedding model[EB/OL]. [2016- 03- 10]. https://papers.nips.cc/paper/5204-devise-a-deep-visual-semantic-embedding-model.pdf.
[10] MA L, LU Z, SHANG L, et al. Multimodal convolutional neural networks for matching image and sentence[C]// Proceedings of the 2015 IEEE International Conference on Computer Vision. Piscataway, NJ: IEEE, 2015: 2623-2631.
[11] SRIVASTAVA N, SALAKHUTDINOV R. Multimodal learning with deep Botzmann machines[EB/OL]. [2016- 03- 10]. http://jmlr.org/papers/volume15/srivastava14b/srivastava14b.pdf.
[12] WU F, YU Z, YI Y, et al. Sparse multi-modal hashing[J]. IEEE Transactions on Multimedia, 2014, 16(2):427-439.
[13] ZHUANG Y, YU Z, WANG W, et al. Cross-media hashing with neural networks[C]// MM 2014: Proceedings of the 22nd ACM International Conference on Multimedia. New York: ACM, 2014: 901-904.
[14] RAFAILIDIS D, CRESTANI F. Cluster-based joint matrix factorization hashing for cross-modal retrieval[C]// SIGIR 2016: Proceedings of the 39th International ACM SIGIR Conference on Research and Development in Information Retrieval. New York: ACM, 2016: 781-784.
[15] ZHAO F, HUANG Y, WANG L, et al. Deep semantic ranking based hashing for multi-label image retrieval[C]// Proceedings of the 2015 IEEE Conference on Computer Vision and Pattern Recognition. Piscataway, NJ: IEEE, 2015: 1556-1564.
This work is partially supported by the National Natural Science Foundation of China (61003127, 61373109).
HUANG Yu, born in 1991, M. S. candidate. His research interests include machine learning, cross-media retrieval.
ZHANG Hong, born in 1979, Ph. D., professor. Her research interests include cross-media retrieval, machine learning, data mining.
Cross-media retrieval based on latent semantic topic reinforce
HUANG Yu1,2, ZHANG Hong1,2*
(1. School of Computer Science and Technology, Wuhan University of Science and Technology, Wuhan Hubei 430065, China;2. Hubei Province Key Laboratory of Intelligent Information Processing and Real-time Industrial System (Wuhan University of Science and Technology), Wuhan Hubei 430065, China)
As an important and challenging problem in the multimedia area, common semantic topic has different expression across different modalities, and exploring the intrinsic semantic information from different modalities in a collaborative manner was usually neglected by traditional cross-media retrieval methods. To address this problem, a Latent Semantic Topic Reinforce cross-media retrieval (LSTR) method was proposed. Firstly, the text semantic was represented based on Latent Dirichlet Allocation (LDA) and the corresponding images were represented with Bag of Words (BoW) model. Secondly, multiclass logistic regression was used to classify both texts and images, and the posterior probability under the learned classifiers was exploited to indicate the latent semantic topic of images and texts. Finally, the learned posterior probability was used to regularize their image counterparts to reinforce the image semantic topics, which greatly improved the semantic similarity between them. In the Wikipedia data set, the mean Average Precision (mAP) of retrieving text with image and retrieving image with text is 57.0%, which is 35.1%, 34.8% and 32.1% higher than that of the Canonical Correlation Analysis (CCA), Semantic Matching (SM) and Semantic Correlation Matching (SCM) method respectively. Experimental results show that the proposed method can effectively improve the average precision of cross-media retrieval.
cross-media retrieval; latent semantic topic; multiclass logistic regression; posterior probability; regularization
2016- 09- 23;
2016- 12- 22。 基金项目:国家自然科学基金资助项目(61003127,61373109)。
黄育(1991—),男,湖北武汉人,硕士研究生,主要研究方向:机器学习、跨媒体检索; 张鸿(1979—),女,湖北襄阳人,教授,博士,主要研究方向:跨媒体检索、机器学习、数据挖掘。
1001- 9081(2017)04- 1061- 04
10.11772/j.issn.1001- 9081.2017.04.1061
TP391.41
A
