查询结果可用性研究综述
2017-06-23高云君
柳 晴 高云君,2
1(浙江大学计算机科学与技术学院 杭州 310027)2(浙江省大数据智能计算重点实验室(浙江大学) 杭州 310027)
查询结果可用性研究综述
柳 晴1高云君1,2
1(浙江大学计算机科学与技术学院 杭州 310027)2(浙江省大数据智能计算重点实验室(浙江大学) 杭州 310027)
(liuq@zju.edu.cn)
数据库可用性研究在数据库领域受到了广泛的关注.其目标在于帮助用户更加高效、方便地使用数据库,从而提高用户对数据库的满意度.主要关注查询结果可用性研究.当前的数据库查询仅仅向用户返回查询结果.如果查询结果不是用户想要的,现有的数据库系统既不能向用户解释为什么会得到这样的结果,也无法给出有效的建议以帮助用户得到满意的查询结果.查询结果可用性研究正是针对当前数据库系统的这一不足而展开.在数据库可用性的视角之上,以查询结果为中心,对当前查询结果可用性工作的最新动态进行了综述.梳理了当前查询结果可用性相关研究中问题的类型及其特点,并从Causality & Responsibility问题、Why-not & Why问题、Why-few & Why-many问题这3个方面对该领域的研究工作现状进行了分类、介绍和总结.最后对该研究领域未来可能的研究方向进行了展望,为相关研究提供参考.
数据库可用性;why-not问题;why问题;causality与responsibility;why-few问题;why-many问题
随着信息技术的不断发展,近几十年来数据库性能(capability)得到了大幅度的提升,例如:数据库所能支持的查询类型越来越丰富,如多媒体查询、关键字查询、基于路网查询等;数据库所能处理的数据量越来越大,能够支持TB甚至更高的数据量.尽管如此,但用户有时候还是觉得数据库难以使用.究其原因,一方面是数据库的性能还有待进一步提高(特别是处理大数据的能力),另一方面是数据库的可用性(usability)还没有满足用户的需求.
通常,可用性指的是用户是否能很好地使用系统的功能.ISO 9241-11国际标准对可用性作了如下定义:产品在特定使用环境下为特定用户用于特定用途时所具有的有效性、效率和用户主观满意度[1].其中有效性指用户完成特定任务和达到特定目标时所具有的正确和完整程度;效率指用户完成任务的正确和完整程度与所使用资源(如时间)之间的比率;主观满意度指用户在使用产品过程中所感受到的主观满意和接受程度.
文献[1]中可用性的定义是一个广义上的概念.在IT领域内可用性定义的对象包括计算机软硬件.数据库作为计算机领域必不可少的一部分,其可用性问题也受到了广泛的关注.根据ISO 9241-11的定义,可以对数据库可用性作如下定义:数据库可用性是指数据库为用户提供数据管理等功能时所具有的有效性、效率和用户主观满意度.通俗地讲,数据库可用性指的是数据库对用户来说有效、易学、高效和令人满意的程度,即用户能否用数据库完成他的任务、效率如何、主观感受怎样.实际上这是从用户角度所看到的数据库质量.这表明数据库可用性是以用户为中心的,更是直接决定了数据库的好坏.由于数据库可用性有着如此重要的作用,近年来受到了专家学者的广泛关注.ACM Fellow、密西根大学的Jagadish教授指出:“当前的数据库仍不完美,可用性是完善数据库的关键点之一[2]”.另外,数据库领域三大顶级国际学术会议:数据管理国际会议(ACM SIGMOD)、超大型数据库会议(VLDB)、数据工程国际会议(ICDE),都关注了数据库可用性.譬如从2016年开始,SIGMOD会议将数据库可用性作为其主题之一.
数据库可用性贯穿数据库生命周期的各个阶段,其研究内容包括查询构造、即时查询、查询结果可用性等[2-3].例如:1)通常用户必须掌握查询语言才能写查询语句.然而,对于非专业人员就很难写出正确、完整的查询语句,因而无法进行查询.为了解决这个问题,查询构造研究旨在能够使用户无需掌握查询语言也能进行查询.2)当前的查询往往需要提交完整的查询语句,等它全部执行完毕后才能得到查询结果,即“所见非所得”模式.但用户往往希望在写查询语句时,即使没有写完全部的语句,也能看到当前语句的查询结果,即“所见即所得”模式.针对这种问题,即时查询结果研究旨在及时帮助用户了解查询结果.3)由于查询的参数设置不当或者对数据集不了解,有时候查询所得到的结果并不是用户想要的.在这种情况下,查询结果可用性研究旨在帮助用户得到想要的查询结果.
数据库可用性研究涵盖众多方面,本文将综述视角放在查询结果可用性研究,内容紧密围绕查询结果可用性所涉及的3个问题,即Causality & Responsibility问题、Why-not & Why问题、Why-few & Why-many问题.对于数据库可用性其他方面的相关研究工作,由于篇幅问题,本文不作涉及.下面首先介绍查询结果可用性研究所涉及的3个问题;再针对每个问题讨论分析最新的研究进展;接着介绍相关的查询结果可用性分析系统;最后在综合分析现有工作的基础上展望未来研究工作.
1 查询结果可用性问题描述
从系统来看,数据库的底层是各种数据源,如地理空间数据、社交数据、多媒体数据等;数据层上面是查询层,用户可以根据不同的需求进行各种查询,如偏好查询、SQL查询等;查询层再往上则是查询结果分析层,这一层根据查询返回的结果并结合用户的反馈意见进行相应分析;最上层是各种实际应用.图1给出了数据库工作基本框架.由图1可知,查询结果可用性研究属于查询结果分析层.具体来说,查询结果可用性研究的研究对象是预料之外的查询结果(unexpected query results).当查询返回相应的查询结果时,如果当前的结果跟用户预先期望的结果有所出入(即预料之外),那么就需要对现有的结果进行相关分析.根据对预料之外的查询结果的分类,查询结果可用性研究可以分为3类问题,即Causality & Responsibility问题、Why-not & Why问题以及Why-few & Why-many问题.下面作具体介绍.
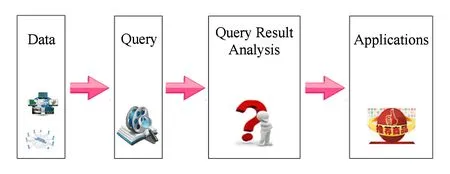
Fig. 1 The basic framework of database图1 数据库工作基本框架
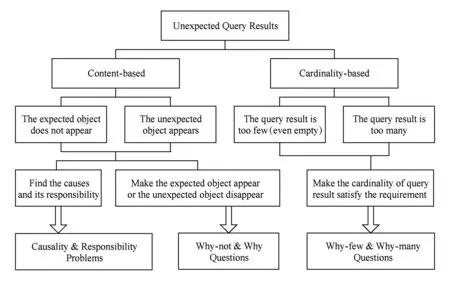
Fig. 2 The analysis of usability problems for unexpected query results图2 对预料之外的查询结果可用性问题分析
如图2所示,查询结果可用性研究所针对的预料之外的查询结果主要可以分为2类:1)基于内容的预料之外的查询结果(content-based unexpected query results);2)基于数量的预料之外的查询结果(cardinality-based unexpected query results).基于内容的预料之外的查询结果是指用户想要的对象没有出现在查询结果中,或者不想要的对象出现在查询结果中.针对这种情况,首先,用户可能想要知道导致现有查询结果产生的原因以及它们相应的责任大小,从而能更好地理解原有的查询.那么,这所对应的就是查询结果可用性研究的第1类问题,即Causality & Responsibility问题研究.其次,除了相应的解释外,用户还可能会让想要的对象出现在查询结果中或者让不想要的对象不出现在查询结果中,从而得到满意的查询结果.查询结果可用性研究的第2类问题,即Why-not & Why问题,正是帮助用户得到他们满意的查询结果.
基于数量的预料之外的查询结果是指用户得到的答案对象个数太少(甚至为空集)或者答案对象个数太多.为此,用户可能想要让查询返回的答案对象个数满足用户指定的要求(既不能太少又不能过多).这就是查询结果可用性研究的第3类问题,即Why-few & Why-many问题,旨在减少或增加查询结果中的答案对象个数.下面具体结合反Top-k查询来进一步说明这3类问题.
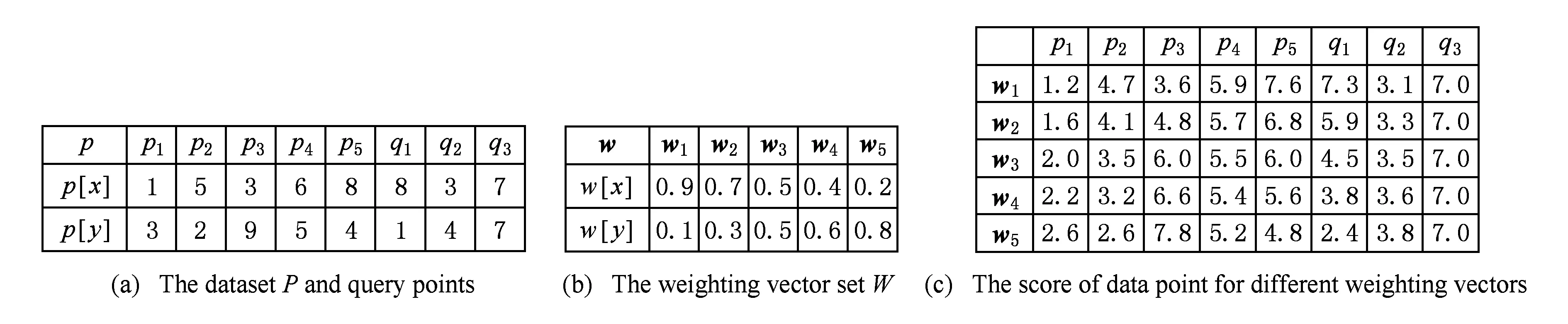
Fig. 3 Example of reverse Top-k queries图3 反Top-k查询示例
给定一个数据集P、一个向量集W、一个参数k和一个查询点q,反Top-k查询从向量集W中返回其Top-k结果包含查询点q的所有向量.如图3所示,图3(a)为数据集P={p1,p2,p3,p4,p5}和3个查询点{q1,q2,q3};图3(b)为向量集W={w1,w2,w3,w4,w5};图3(c)为数据集P中所有数据点在不同向量下的得分值(假设值越小越好).如果用户以q1为查询点进行反Top-3查询,根据图3(c)可以得到q1的反Top-3查询结果(记作RTOP3(q1))为RTOP3(q1)={w3,w4,w5}.假设向量w1是用户期望的查询结果之一,但它却没有出现在查询结果中.这时,用户可能想知道是什么原因导致了向量w1没有出现在查询结果中,这就可以通过Causality & Responsibility问题进行分析.此外,如果用户想要让向量w1成为反Top-3查询结果,那么Why-not问题分析就可以给出合理的建议.同样,假设查询结果中向量w4是用户不想要的,但它却返回给了用户.这时,用户可以通过Causality & Responsibility问题分析向量w4成为结果的原因,并通过Why问题寻求合理的建议以使得向量w4排除在反Top-3查询结果中.
另外,假设用户以q2和q3为查询点进行反Top-3查询,根据图3(c)可以得到q2和q3的反Top-3查询结果分别为RTOP3(q2)={w1,w2,w3,w4,w5},RTOP3(q3)=∅.可以看到,q2的反Top-3查询结果等于整个向量集,这结果对于用户来说太多;而q3的反Top-3查询结果等于空集,这个结果对于用户来说又太少.这2种情况都不能为用户提供足够有效的信息以帮助用户作决策支持.这时,用户可以指定期望的答案对象个数(如大于等于2且小于等于4),并利用Why-few(对于q2)和Why-many(对于q3)问题分析以使得查询返回用户想要的查询结果对象个数.
针对上述描述的预料之外的查询结果,如果数据库系统能够向用户提供相应的解释和建议来帮助用户得到满意的查询结果,这能够使用户免于通过人工方式寻求答案从而帮他们节省大量的时间.这样就能让用户更加方便而有效地使用数据库,提高用户使用数据库的满意度,进而提高数据库的可用性.下面分别介绍查询结果可用性分析的3类问题.
2 Causality & Responsibility问题研究现状
2.1 问题定义
当查询结果中包含了用户不想要的对象或者用户想要的对象没有出现在查询结果中,如果用户想知道是哪些原因导致了现有的查询结果,这些原因的影响有多大,便可以利用Causality和Responsibility问题来分析.
Causality研究源于哲学领域,具有很长的研究历史[4-5].直到如今,其在哲学(philosophy)、人工智能(AI)、认知科学(cognitive science)等领域仍被广泛地研究.Halpern和Pearl[6]首次形式化定义了Causality的概念,它能够对一些具有因果联系的事物进行精确的建模.Chockler和Halpern[7]对Causality的概念进行了进一步扩展并提出了Responsibility来量化Causality的作用,从而对Causality提供了更深层次的分析.从此Causality与Responsibility在包括计算机领域在内的各个领域得到了广泛的研究.
Meliou等人首次将Causality与Responsibility的概念引入到数据库领域.在文献[8]中,Meliou等人针对输入数据定义了查询结果的Causality.具体地说,如果一个输入数据p的存在与否会导致查询结果的改变,那么输入数据p就是查询结果的一个原因(cause).Responsibility的大小则根据p所对应的集合(contingency set)进行计算.接着,在文献[9]中,Meliou等人结合Halpern和Pearl的工作对Causality定义进行了进一步细化.下面的定义1和定义2给出了文献[9]中Causality与Responsibility的形式化定义以便更好地理解这一问题.

定义2. 假设p′是p的Causality,Γ是p′所对应的Contingency set,那么p′对于p的Responsibility,记作ρ(p′,p),可计算得到[9]:
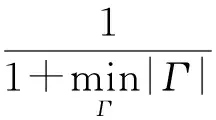
(1)
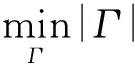
2.2 研究现状
自从Causality与Responsibility被引入数据库领域,便引起了众多研究者的关注.Meliou等人还在数据库领域顶级国际学术会议VLDB 2014上举行了Causality与Responsibility相关的Tutorial对其进行了系统地介绍[10].下面对数据库领域中的Causality与Responsibility问题研究进展进行全面地介绍.图4总结了近年来所发表的Causality与Responsibility研究论文数量.
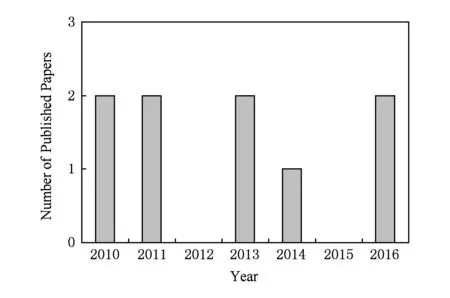
Fig. 4 The statistics of studies on Causality & Responsibility图4 Causality & Responsibility研究工作统计
文献[11]首次探讨了带有等式的连接查询(conjunctive queries with equalities)上的Causality与Responsibility.作者研究了2种情况的Causality与Responsibility,即“Why so”和“Why no”.其中“Why so”是对查询结果研究它们的Causality与Responsibility,“Why no”则是对非查询结果研究它们的Causality与Responsibility.此外,作者还分析了针对连接查询计算Causality与Responsibility的复杂度.针对带有不等式的连接查询(conjunctive queries with inequalities)的溯源信息(即Causality),文献[12]研究了如何计算其Responsibility的大小.为了减少计算Responsibility的代价,文献[12]首先将溯源信息转换成相应的矩阵,从而将Responsibility的计算转换成最短路径问题并通过动态规划算法来解决.文献[13]研究了概率反Skyline查询上的Causality与Responsibility问题.给定一个对象p(p不是概率反Skyline查询结果),文献[13]从概率数据集中找到导致p成为非概率反Skyline查询结果的数据(即p的Causality),并计算它们的Responsibility大小.为了找到p的所有Causality,文献[13]提出了基于过滤-精炼框架的CP算法.值得一提的是,文献[13]同时考虑了离散和连续2种概率模型,并扩展了CP算法以处理反Skyline查询上的Causality与Responsibility问题.在社交网络中,2个对象之间的信息传播(diffusion)可能存在着多条路径.文献[14]利用Causality与Responsibility对所有的历史传播路径进行排序,以方便用户了解自己在信息传播过程中所处的位置以及重要性(即如果把自己从社交网络中删除,2个对象之间的信息传播是否还能顺利进行).
上述工作都是针对传统的Causality与Responsibility定义进行研究.此外,一些研究者根据具体的应用和查询对传统的Causality与Responsibility定义进行相应的扩展.例如,传统的Causality与Responsibility仅仅判断一个数据对象是否是查询结果的Causality.文献[15]则判断多个数据对象是否是查询结果的Causality,并提出了P树来有效地计算Responsibility大小.在数据转换应用中,结合数据转换后的错误信息,文献[16]提出了View-Conditioned Causality以及相应的Responsibility以定位源数据集中的错误.为了有效地找出View-Conditioned Causality并计算相应的Responsibility,文献[16]将View-Conditioned Causality查找和Responsibility计算分别转换成可满足性问题(SAT problem)和最大可满足性问题(MAX-SAT problem),而这2个问题目前都有有效的算法来解决.Lian和Chen首次将Causality与Responsibility引入了基于离散概率模型的概率数据库.在原来的Causality与Responsibility定义的基础上,根据概率数据库特性,文献[17]提出了预期的Responsibility的概念.具体而言,在离散概率模型下,概率数据库可以看成是一系列可能世界(possible world)的集合.假设p1是p2的Causality,可以利用原有的Responsibility定义来计算每个可能世界下p1对p2的Responsibility大小.预期的Responsibility则是对所有可能世界中p1对p2的Responsibility大小的累加之和.在文献[17]中,预期的Responsibility被用来协助概率最近邻查询处理并同时鉴别出数据集中的低质量或者可能有误的概率数据.
3 Why-not & Why问题研究现状
3.1 Why-not & Why问题定义
现有的查询仅仅返回查询结果,如果查询结果包含了用户不想要的结果或者用户想要的结果没有出现,却不能提供一些建议以帮助用户得到其想要的查询结果.Why-not与Why问题研究正是针对数据库中这一不足展开.下面,定义3和定义4分别给出了Why-not问题和Why问题的定义.
定义3. 给定一个原始查询Q和一个Why-not集合W1(W1不是Q的查询结果),Why-not问题研究如何使W1成为Q的查询结果.
定义4. 给定一个原始查询Q和一个Why集合W2(W2是Q的查询结果),Why问题研究如何使W2不成为Q的查询结果.
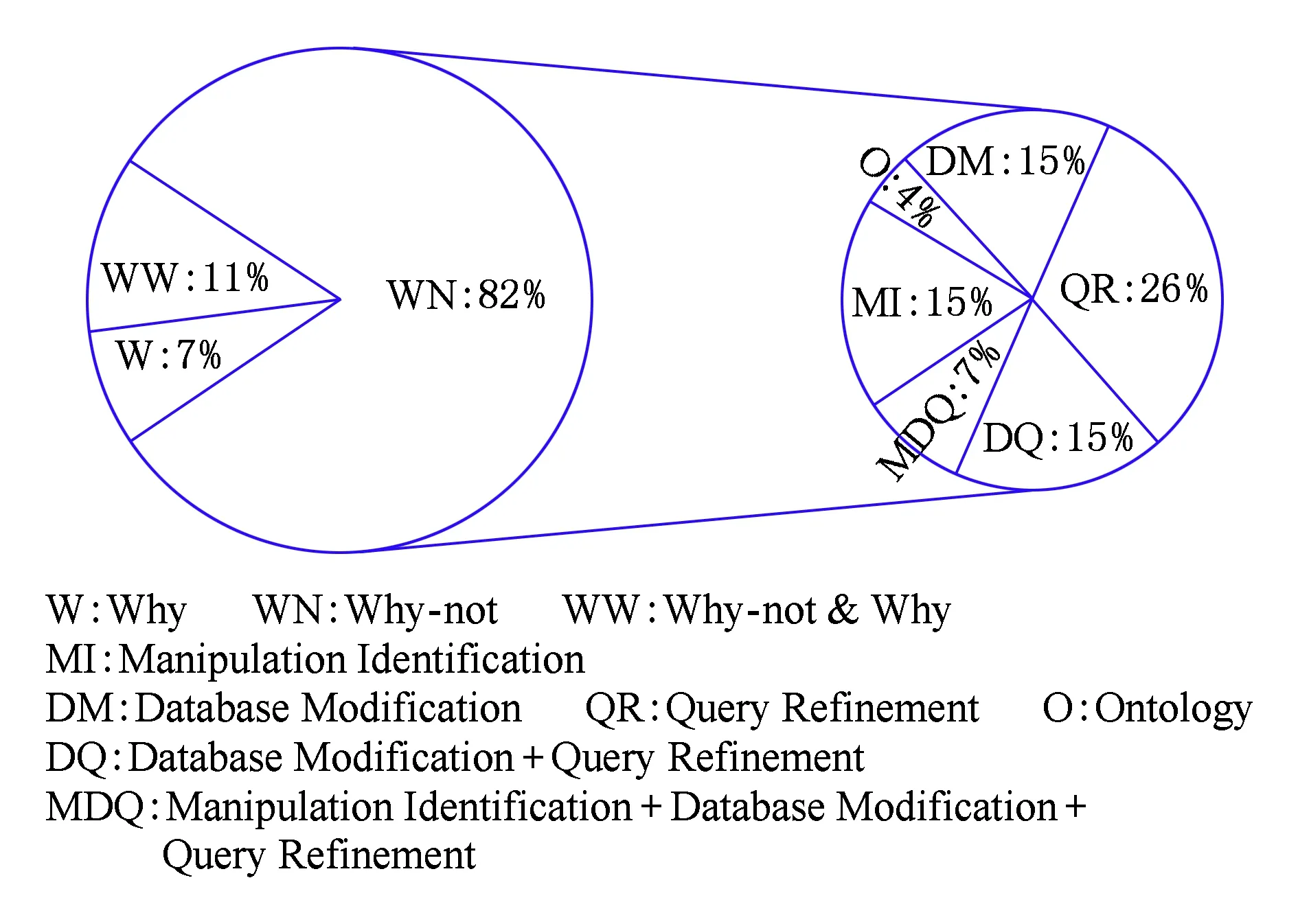
Fig. 5 The statistics of studies on Why-not and Why questions图5 Why-not问题和Why问题研究工作统计
简而言之,Why-not问题就是帮助用户把想要但是没出现在查询结果中的对象包含在查询结果中;Why问题就是帮助用户把不想要但是却出现在查询结果中的对象排除.当前,Why-not问题和Why问题研究工作可以分为3类:1)单独研究Why-not问题;2)单独研究Why问题;3)同时研究Why-not问题和Why问题,即既把用户想要但是没出现在查询结果中的对象包含在查询结果中,又把用户不想要但是却出现在查询结果中的对象排除.图5中左边的饼图所示的就是目前这3类工作所占的比例.由图5可知,Why-not问题相关的工作占了绝大多数,另外2类的相关研究较少.下面一一介绍这3类工作的研究现状,首先介绍Why-not问题的研究现状.
3.2 Why-not问题研究现状
为了有效地回答Why-not问题,研究者们提出了多种不同的策略,包括操作定位(manipulation identification)、数据修改(database modification)、查询修改(query refinement)、基于本体论(ontology)的方法以及混合方法等.图5中右边的饼图显示了各种策略在当前研究工作中所占的比例.另外,表1总结了Why-not问题的研究工作并根据其所采用的策略对它们进行了分类.
如果用户想要的对象(即Why-not对象)没有包含在当前的查询结果中,一种最直接的方法就是找到导致Why-not对象成为非查询结果的操作,即操作定位法.文献[18]首次提出用操作定位策略来回答SPJU(select-project-join-union)查询上的Why-not问题.文献[18]先利用数据溯源相关技术找到与Why-not对象相关的数据,而后从查询中定位是哪些操作把这些相关的数据排除在查询结果中.然而,文献[18]所返回的操作定位存在着错误.文献[19]重新定义了基于操作定位的解释并给出了更高效的算法,从而大大降低了操作定位的错误率.以上2项工作都是利用查询树(query tree)产生相应的操作定位解释.这就导致了得到的解释依赖于给定查询树的拓扑结构.换句话说,对于同一个查询语句,如果给定的查询树不一样,返回的查询解释也不一样.更糟糕的是,根据查询树计算得到的查询解释甚至可能是不完整的.为此,文献[20]提出了以多项式(polynomial)的形式返回操作定位解释并给出了最基本的算法Ted.基于多项式的操作定位解释不仅独立于查询树,而且能够保证解释的完整性.但文献[20]所提出算法Ted的计算代价相当大.为此,文献[21]利用空间划分、并行计算等技术提出了一个更有效的算法Ted++.
另外,文献[22]提出了基于本体论的解释方法,它们所针对的查询是连接查询(conjunctive queries).根据所针对的本体类型的不同,又可将所产生的解释分为基于内本体的解释方法和基于外本体的解释方法.
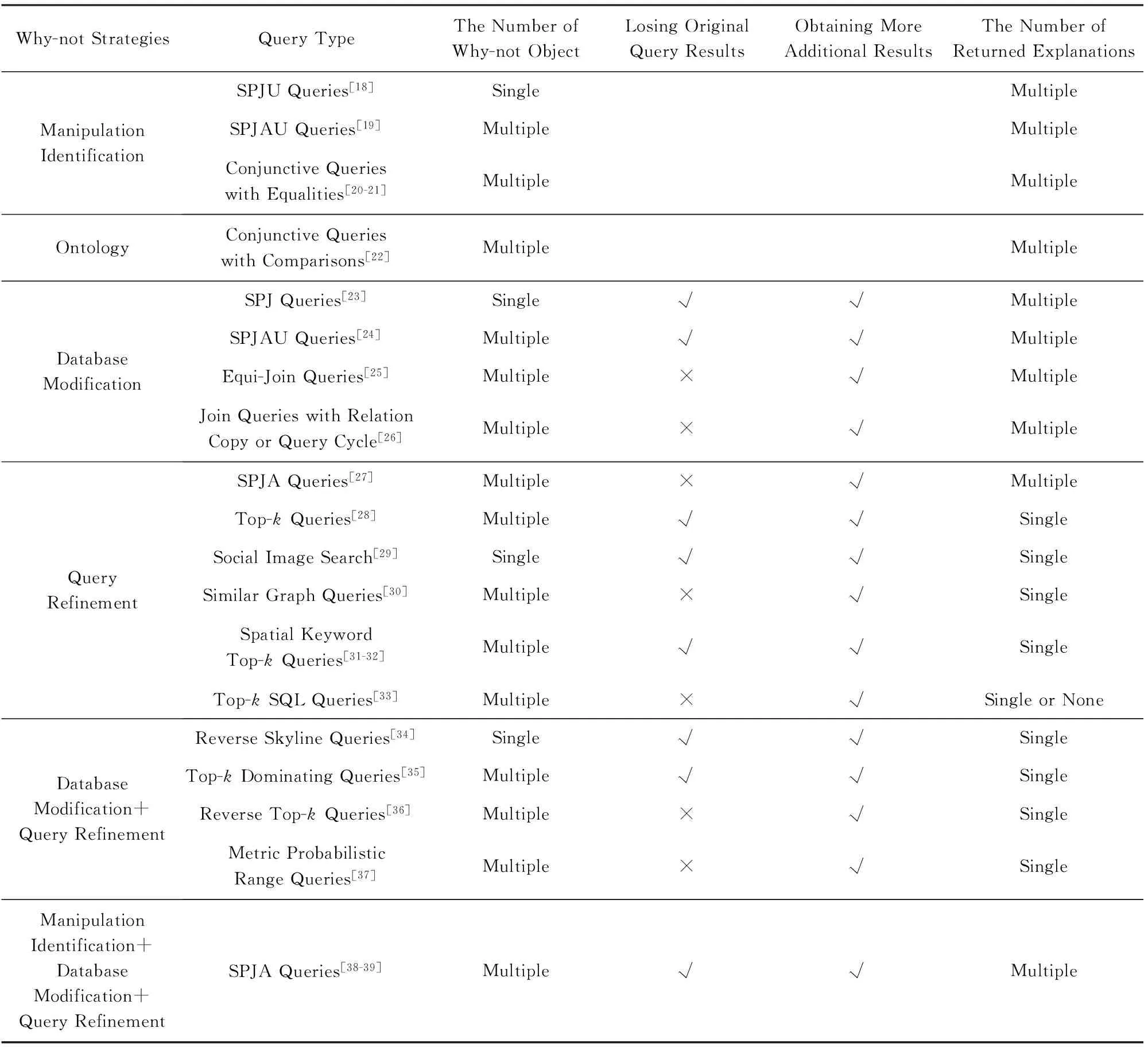
Table 1 The Summary of Studies on Why-not Questions表1 现有Why-not问题工作总结
Notes:“√” means yes; “×” means no.
操作定位和基于本体论的解释仅仅将导致Why-not对象成为非查询结果的操作或数据找出来.但这往往还无法使Why-not对象成为查询结果.于是,一些研究者提出了通过修改数据使得Why-not对象成为查询结果.文献[23]通过插入新的数据或修改现有的数据来使Why-not对象成为查询结果.该工作所针对的查询是SPJ(select-project-join)查询,并且只考虑一个Why-not对象.文献[24]针对SPJAU(select-project-join-aggregation-union)查询和多个Why-not对象研究了Why-not问题.但是,文献[23-24]返回的数据修改建议都存在着一些不足之处,如返回的修改建议中包含不正确、不合理的修改建议,或者返回的修改建议太多使得用户无法选择.为此,文献[25]提出了新的技术来提高数据修改建议的正确性并降低返回修改的个数.尽管文献[25]返回结果的正确性提高了且数量也减少了,但它所针对的查询仅仅是等值连接查询(equi-join queries).当查询中带有关系复制语句(relation copy)或循环语句时(query cycle),返回的结果还是不正确的.因此,文献[26]探讨了带有关系复制语句或循环语句的等值连接查询上的Why-not问题,使得返回的数据修改建议不仅正确且尽可能少.值得注意的是,文献[23-26]均将数据分为可信数据(trusted data)和非可信数据(untrusted data).数据修改操作只针对非可信数据,而对于可信数据则不允许修改.
很明显,如果数据库的数据允许被任意修改的话,数据修改这一策略是比较灵活有效的.然而,在实际应用中,用户一般很难直接接触到数据库中的数据,更不用说修改数据了.此外,数据库中的数据通常是固定的,都不允许直接修改的.鉴于此,数据修改的方法在很多应用中无法使用.所以,研究者提出了一种更加可行的策略,即修改原始查询.文献[27]首次通过修改原始查询来回答Why-not问题.它所针对的查询是SPJA(select-project-join-aggregation)查询.文献[27]提出了2种标准来衡量修改查询的好坏:第1个标准是相似性(similarity),即和原查询相比,修改查询对于选择谓词的修改越少则与原查询越相似;第2个标准是精确性(precision),即除原有的查询结果和Why-not对象外,修改查询结果所包含的其他对象越少则越精确.随后的工作也基本采用了这2个标准来判断修改查询的好坏.
文献[28,35]研究了Top-k查询(Top-kqueries)上的Why-not问题.该工作通过同时修改Top-k查询的输入参数k和向量w使得Why-not对象成为Top-k查询结果.文献[28,35]在判断修改查询的好坏时,仅仅使用了相似性.文献[33]扩展了文献[28]中的工作,研究了Top-kSQL查询(即基于SQL的Top-k查询)上的Why-not问题.其所提出的方案包括同时修改SQL语句(如修改、增加Where语句中的选择谓词,增加、减少Where语句中的联接谓词,增加、减少From语句中的关系等)和修改Top-k查询所涉及的参数(包括参数k和向量w).同样,文献[33]采用了相似性和精确性2个标准来衡量修改后的Top-kSQL查询并最终返回相似性和精确性最优的修改查询.值得注意的是,文献[33]最终有可能无法得到相应的修改查询以使得查询结果包含所有的Why-not对象.
另外,一些研究者利用查询修改策略探讨了图像查询和关键字查询上的Why-not问题.文献[29]研究了社交图像查询(social image search)上的Why-not问题.给定一组查询标签(query tag),社交图像查询返回与标签最匹配的图片.对于用户在返回的结果里面没有看到自己想要的图片,文献[29]提出了3种模型来修改查询:1)对原查询结果进行重排序.该模型针对的情况是用户想要的图片已经在返回的结果中,但是它们的排序很靠后.这样,只要对返回的图片进行重排序便能让用户尽早看到想要的图片.2)对某些查询标签进行删除,这些被删除的标签都导致用户想要的图片没有出现.3)用1组新的标签来替代原有的查询标签从而使得用户想要的图片出现.其中模型2和模型3所针对的情况是用户想要的图片并没有返回给用户.文献[30]探讨了相似图查询(similar graph queries)上的Why-not问题.给定一个查询图,相似图查询返回与查询图(query graph)最相似的图.针对用户想要的图没有出现在查询结果中,文献[30]通过对查询图进行修改以使得用户想要的图出现在查询结果中.其中,查询图的修改只限于对图中的边进行增加或删除,而对顶点则不作任何修改.
文献[31-32]研究了空间关键字Top-k查询(spatial keyword Top-kqueries)上的Why-not问题.空间关键字Top-k查询同时考虑了查询对象的空间位置信息和关键字信息,根据与查询点的空间位置距离和文本相似性来计算每个数据对象的得分,最终返回得分最小的k个数据对象.针对空间关键字Top-k查询的特点,文献[31]对空间关键字Top-k查询中的得分计算函数进行修改,使Why-not对象的得分变小从而达到让它们成为查询结果的目的.但该文作者认为,与关键字信息相比,这种方法并不能很好地反映用户真正的偏好.因此,在文献[32]中,作者对空间关键字Top-k查询的输入关键字信息进行修改(如增加或减少输入的关键字信息),从而使得Why-not对象出现在查询结果中.值得注意的是,文献[31-32]中用来衡量修改查询好坏的标准仅仅考虑了原查询与修改查询的相似性,并没有考虑精确性.此外,文献[31-32]所得到的修改查询不仅可能会丢失原有的查询结果,还可能会包含其他新的查询结果.
以上工作均采用了一种策略来回答Why-not问题.另外,一些研究者结合了上述3种已有的策略来回答Why-not问题.文献[34-37]针对反Skyline查询(reverse skyline queries)、Top-k支配查询(Top-kdominating queries)、反Top-k查询(reverse top-kqueries)查询、概率度量区域查询(metric probabilistic range queries)分别研究了Why-not问题,它们均采用了数据修改和查询修改2种策略来回答Why-not问题.通过2种策略的不同组合,文献[34,36]均提出了3类方案来回答Why-not问题:1)通过单独修改数据来回答Why-not问题.如文献[34,36]都通过修改Why-not对象使得修改后的Why-not对象出现在查询结果中.2)通过单独修改查询(即修改查询所涉及的参数)来回答Why-not问题.如针对反Skyline查询的Why-not问题,文献[34]修改的是查询点q;针对概率度量区域查询的Why-not问题,文献[36]同时修改查询点q、查询半径r和概率阈值θ这3个参数.3)对上述2种方案的集成,即同时修改Why-not对象和查询所涉及的参数,以回答Why-not问题.文献[35]仅给出了方案3来回答Top-k支配查询上的Why-not问题,即同时修改Why-not对象和Top-k支配查询参数k.结合反Top-k查询上Why-not问题的实际应用,文献[37]仅提出了方案1(即修改查询点q)和方案3(即修改参数k和Why-not对象,或修改查询点q、参数k和Why-not对象),并没有单独修改数据.值得一提的是,文献[34-37]中数据修改这一策略仅仅限制于对Why-not对象的修改,其他数据对象则不允许被修改.
另外,文献[38-39]集成了操作定位、数据修改、以及查询修改3种策略来回答SPJA查询上的Why-not问题.然而,文献[38-39]所考虑的场景是:1)数据不完整;2)原查询中存在错误.该场景在实际应用中不是很常见,从而限制了文献[38-39]所提出算法的应用范围.
3.3 Why问题研究现状
本节介绍现有的Why问题研究工作.目前,Why问题研究工作还很少.文献[40]研究了在信息提取(extraction)过程中,根据用户反馈的提取错误信息(即用户不想要的信息)对提取规则进行修改,从而使这些错误的信息不再被提取.对提取规则进行修改的时候,文献[40]保证了用户所反馈的正确信息不丢失.另外,文献[41]探讨了反Top-k查询上的Why问题.该文作者结合了数据修改和查询修改2种策略来回答Why问题.在回答Why问题时,文献[41]首先尽可能地保证原有的查询结果不丢失.如果保证原有查询结果不丢失的解决方案不存在,那么就仅仅考虑如何使用户不想要的对象排除在查询结果外.同样,文献[41]利用了相似性来衡量修改查询的好坏,最终返回相似性最好的修改查询.
虽然当前的Why问题研究工作较少,但是现有的数据溯源(data provenance,data lineage)技术可以用来帮助解决某些查询(如SQL查询)上的Why问题.数据溯源是根据追踪路径重现数据的历史状态和演变过程,以实现数据历史档案的追溯[42].其方法主要有标注法[43-44]和非标注法[45-46].给定Why对象(即用户不想要的查询结果对象),首先可以利用数据溯源技术计算出Why对象是如何产生的;再对导致Why对象产生的数据或操作进行相应的修改,便可使Why对象排除在查询结果外.当然,这其中还涉及一些其他问题,譬如:如何根据数据溯源得到的结果来修改数据或操作;修改的时候如何保证不丢失其他现有的查询结果等,这都有待进一步研究.
3.4 Why-not & Why问题其他研究现状
3.2节和3.3节工作都是单独研究Why-not问题或Why问题.对用户来说,如果既能帮助他们把想要但是没出现在查询结果中的对象包含在查询结果中,又能把他们不想要但却出现在查询结果中的对象排除,这将会更加有用.文献[47]同时考虑了SPJ查询上的Why-not问题和Why问题.该文作者利用决策树(decision tree)来对原查询进行修改,从而得到用户想要的结果.然而,决策树实际上是一种基于信息增益理论的线性分类器(linear classifier).它的好坏很大程度上取决于数据的分布.对于关系型数据,决策树的效果不是很好.因此,文献[48-49]利用Skyline操作来找到可行的查询修改方案.该方法的优势在于它不仅和数据的分布无关,而且该方法返回的修改方案能让用户根据自己的偏好进行权衡.
同时回答Why-not问题和Why问题最基本的方法就是先依次回答Why-not问题和Why问题,而后两类问题返回答案的交集便是最终的结果.但是,这种方法的效率肯定不高,因为中间可能存在着冗余的计算或操作.当前同时考虑Why-not问题和Why问题的研究还很少,所以,该工作也尚待进一步研究.
4 Why-few & Why-many问题研究现状
第2节和第3节分别总结了Causality & Responsibility问题和Why-not & Why问题的研究现状.这两大块工作都是基于内容的预料之外的查询结果可用性研究.本节将回顾基于数量的预料之外的查询结果可用性研究工作.首先分别定义Why-few问题和Why-many问题;接着介绍Why-few问题和Why-many问题的现有研究工作.
4.1 Why-few & Why-many问题定义
由于对数据集不了解,在构造查询时用户可能会过分严苛(over-specify)或过分宽松(under-specify).如果查询过分严苛,返回的结果可能会很少甚至为空集,这样用户就得不到足够的信息;如果查询过分宽松,返回的结果可能会太多.同样,过多的信息对用户来说用处也不大.针对以上2种情况,如果系统能够帮助用户把查询结果大小控制在用户的期望范围之内,这样就能让用户得到适量的信息,以便于他们利用返回的信息进行相应的决策.这恰恰就是Why-few & Why-many问题研究所要解决的.下面定义5和定义6分别给出了Why-few问题和Why-many问题.
定义5. 给定一个原始查询Q(Q的查询结果太少甚至为空)和一个用户期望的查询结果大小,Why-few问题研究如何使Q的查询结果变大以满足用户期望.
定义6. 给定一个原始查询Q(Q的查询结果太多)和一个用户期望的查询结果大小,Why-many问题研究如何使Q的查询结果变小以满足用户期望.
目前,Why-few & Why-many问题的研究工作主要可以分为三大类:1)能够单独解决Why-few问题,即原查询结果太少,研究如何使查询结果变大;2)能够单独解决Why-many问题,即原查询结果太多,研究如何使查询结果变小;3)既能解决Why-few问题又能解决Why-many问题.图6显示了这3类工作所占的比例.下面分别阐述这3类工作.
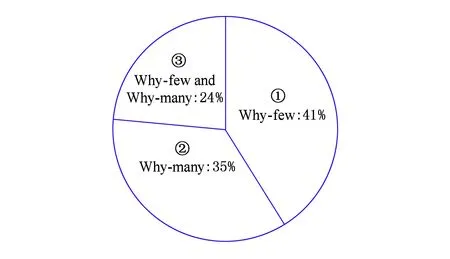
Fig. 6 Statistics of studies on Why-few and Why-many questions图6 Why-few问题和Why-many问题研究工作统计
4.2 Why-few问题研究现状
现有的Why-few问题研究主要采用查询修改这一方法来增加查询结果大小.具体而言,查询修改主要是对查询所涉及的参数或查询中的条件进行修改,从而使查询结果变大.根据不同的修改方式,查询修改可进一步分为基于机器学习的查询修改、非交互式的查询修改以及交互式的查询修改.
基于机器学习的查询修改方法中,文献[50]给出了一个基于数据驱动的算法LOQR来修改查询.LOQR通过发现不同域属性之间的潜在联系来对原查询中的限制条件进行放松.具体地说,LOQR首先从数据库中随机抽取小部分数据进行判定规则(decision rules)的学习;接着,LOQR利用最近邻技术找到与原查询最相近的判定规则,并用该规则对原查询进行修改.LOQR的不足之处在于当数据集较小时,其修改的查询与原查询会相差很大(即相似性不高).为此,文献[51]提出了基于贝叶斯网络(Bayesian network)的方法TOQR对查询进行修改,从而解决了上述的缺点.TOQR首先初始化一个不带任何限制条件的查询;接着,再往其中逐渐增加限制条件直至查询结果大小满足要求.其中这些限制条件均来自于原查询,而添加的顺序是通过贝叶斯分类算法TAN(tree augmented Bayes network)在小数据集上学习获得.
除了基于机器学习的查询修改方法外,文献[52-54]提出了非交互式的查询修改方法.文献[52]研究了如何修改连接查询和选择查询使得空查询结果不为空.为此,文献[52]提出了一种基于点阵(lattice)的算法.首先,算法将可能的放松条件映射成点阵中的节点,那么每一节点就代表对查询的某一处修改;接着,算法对点阵进行遍历,并最终得到一种修改方案使得查询不为空.文献[53]探讨了区域查询(range query)上的Why-few问题,通过对给定区域的放缩以及位置的变化来增加查询结果.另外,文献[54]研究了子图查询上的Why-few问题.当子图查询结果为空集时,作者通过对查询图的修改,如点/边的插入、删除操作,使得子图查询不为空.此外,文献[54]还给出了基于数量的图形编辑距离(cardinality-based graph edit distance)来衡量查询图的修改代价.
非交互式的查询修改方法的不足之处在于该方法可能会返回大量的查询修改方案.这对用户来说显然不是他们想要的.所以,文献[55-56]提出了一种交互式的框架对连接查询进行修改以使得其结果不为空.具体而言,当查询结果为空时,系统一步步引导用户对查询进行修改,每一次对查询的修改都是比较细微的.这过程一直持续下去直至查询结果不为空,或者无论怎么修改,查询均不可能返回结果为止.此外,文献[55-56]所提出的框架还允许集成不同的目标函数.在系统引导用户进行查询修改时,根据实际应用中的目标函数,将最优的修改建议(即对应目标函数值最大或最小的修改方案)返回给用户.
4.3 Why-many问题研究现状
Why-few问题研究主要针对的是查询结果少的情况.相反,Why-many问题研究则是针对查询结果太多的情况.现有的Why-many问题研究工作可以分为基于分面搜索(faceted navigation)的方法和基于排序(ranking-based)的方法.
一般地,事物包含多个属性,这些属性即称为分面(faceted).分面搜索是指通过事物的这些属性不断筛选、过滤搜索结果的方法,可以将分面搜索看成搜索和浏览的结合.分面搜索过程中,用户选择某个条件后,分面结果会在该条件限定下的结果集中动态获取,从而能够从不同的角度对数据进行归类整合,以帮助用户进一步了解需要获取的数据信息.然而,事物的分面可能有很多,如何向用户提供合适的分面是需要重点解决的挑战之一.为此,文献[57]先通过向用户提问,而后根据用户的反馈向用户提供相应的分面.文献[58]根据代价模型选择一部分分面给用户,以使得分面搜索的代价尽可能小.文献[59]在维基百科中实现了分面搜索.该工作利用了维基百科中的协同词汇库(collaborative vocabulary)来向用户提供合适的分面.
另一类的Why-many问题研究利用的是排序的方法,即利用相应的排序函数对所得到的查询结果进行排序,并返回前k个结果给用户.一种最直接的方法就是让用户提供相应的排序函数,再利用Top-k查询得到排序最靠前的k个对象.然而,用户的排序函数往往很难得到,有时甚至连用户自己也无法给出正确的排序函数.所以,一些研究者研究了如何自动地对查询结果进行排序.文献[60]扩展了信息检索与数据挖掘的常用加权技术TF-IDF(term frequency-inverse document frequency),并提出了一种用于数据库查询结果排序的函数.该函数同时考虑了数据分布和系统负荷(workload)两个因素.另外,文献[61-62]提出了用2种得分来决定查询结果的排序,即全局得分(global score)和条件得分(conditional score).其中,全局得分反映了某属性的全局重要性,而条件得分则体现了指定属性与非指定属性之间的关联度.
4.4 Why-few & Why-many问题其他研究现状
以上2方面工作都是单独研究了Why-few问题或者Why-many问题.另外,一些研究者也同时考虑了Why-few问题和Why-many问题.文献[63]探讨了模糊查询(fuzzy queries)上的Why-few问题和Why-many问题.为了得到适量的查询结果,该文作者提出了通过修改查询中所涉及的模糊条件(fuzzy conditions)的方法.文献[64]研究了如何修改SPJ查询来满足查询结果大小约束.该文作者提出了一种统一的框架SnS(StretchnShrink)来对查询进行修改.其中,Stretch是指对查询的条件进行放松,以增加查询结果;Shrink是对查询的条件进行紧缩,以减少查询结果.通过n次的修改与用户的反馈来最终得到满足查询结果约束条件的查询.文献[65]研究了如何找到与原查询相似度高又能满足查询结果约束的新查询,而原查询的查询结果可能太多也可能太少.该工作从2方面来考虑新查询的好坏:1)考虑查询结果对查询结果大小约束条件满足的情况;2)考虑新查询与原查询的相似性.为此,该文作者提出了算法SAQR来有效地找到满足条件的最优新查询.文献[66]探讨了子图查询上的Why-few问题和Why-many问题.该工作试图从图数据中找到查询图的最大相似子图来解释为什么会产生太多或太少的查询结果.文献[66]的工作只是向用户给出相应的解释,却并没有向用户提供修改建议来消除查询结果太多或太少的现象.
5 查询结果可用性分析系统
当前有一些系统实现了查询结果可用性分析的若干功能.这些系统可以分为2类:1)基于内容的查询结果可用性分析系统;2)基于数量的查询结果可用性分析系统.表2总结了现有的查询结果可用性分析系统.下面分别介绍这2类系统.
基于内容的查询结果可用性分析系统包括:Artemis[67],EFQ[68],YASK[69].这3个系统的工作流程比较相似.首先,用户向系统提交一个原始查询,用户得到查询结果后进行分析.若自己想要结果没有出现,则指定相应的Why-not对象并向系统触发Why-not问题.当系统收到Why-not问题后进行处理,并最终向用户返回2类信息:1)解释为什么Why-not对象没有出现在查询结果中;2)提供不同的建议,以使得Why-not对象出现在查询结果中.根据查询的不同和回答Why-not问题策略的不同,系统所提供的建议也不一样.Artemis实现的是SPJU查询上的Why-not问题,它向用户提供的修改建议是如何对数据集进行修改.EFQ实现的是连接查询上的Why-not问题,它向用户提供的修改建议是如何对原查询中的操作算子或条件进行修改.YASK实现的是空间关键字Top-k查询上的Why-not问题,它向用户返回的建议是如何对用户偏好函数和查询关键字进行修改.
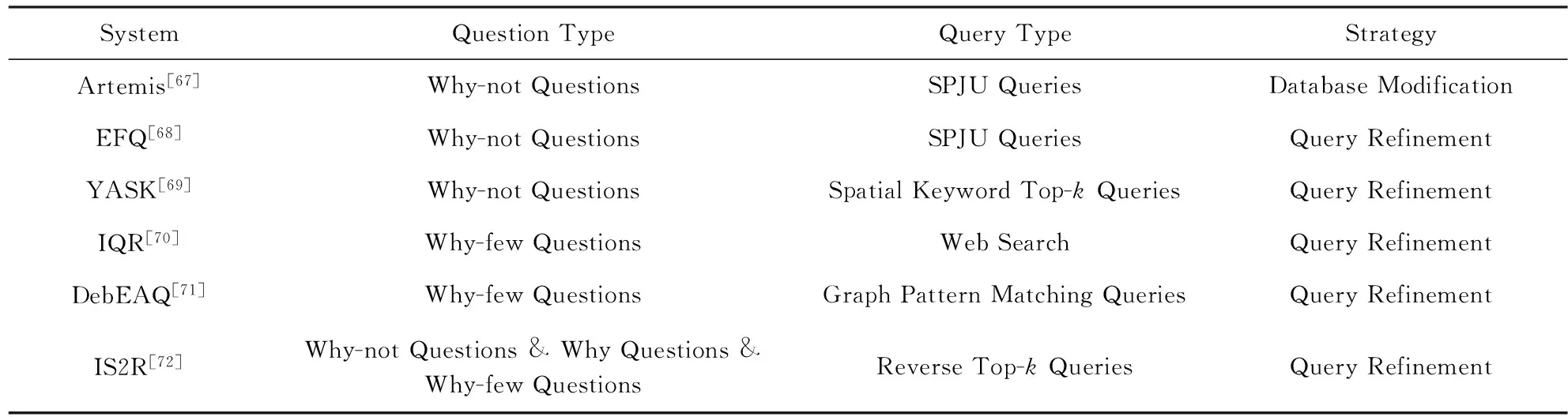
Table 2 The Summary of Systems of Database Usability for Query Results表2 查询结果可用性分析系统总结
基于数量的查询结果可用性分析系统包括IQR[70]和DebEAQ[71].这2个系统都是针对查询结果为空集的情况.IQR渐进式地对查询进行修改,每一次系统向用户返回细小的查询修改;而后根据用户的反馈意见(同意或不同意修改)再进行下一次修改.这种过程一直持续下去,直到查询不为空或者再怎么修改查询也不可能返回结果为止.DebEAQ解决了图模式匹配查询上的Why-few问题.如果图模式匹配查询为空,DebEAQ会向用户解释为什么查询结果为空,并提供相关的建议对查询图进行修改,以使得图模式匹配查询结果不为空.
最近,IS2R[72]同时集成了基于内容和基于数量的查询结果可用性分析.具体地说,IS2R能够有效地回答反Top-k查询上的Why-not问题、Why问题以及Why-few问题(即查询结果为空这一情况).
当前的这些系统仅仅实现了查询结果可用性分析的部分功能,还没有一个系统能够完整地实现查询结果可用性分析的全部功能,即同时集成Causality & Responsibility问题分析、Why-not & Why问题分析和Why-few & Why-many问题分析.因此,查询结果可用性分析系统的实现还有待进一步展开.
6 未来工作展望
学术界围绕查询结果可用性这一主题展开了多层次、多方位的理论与技术探索,并取得了一定的研究成果.但是实现全面提高数据库查询结果可用性的目标,依然存在着许多挑战.下面,对未来在数据库查询结果可用性研究领域有待进一步突破的研究问题进行展望.
1) 对不同查询类型进行查询结果可用性研究
目前,查询结果可用性研究主要集中在SQL查询.其他如Top-k查询、反Skyline查询、反Top-k查询、空间关键字Top-k查询、度量查询等也有研究.然而,数据库领域的查询类型繁多,现有查询结果可用性研究所针对的查询只是冰山一角.而其他的查询在实际应用中也会碰到预料之外的查询结果.此外,查询结果可用性技术往往是查询依赖的.不同查询之间的查询结果可用性技术是不能通用的.所以,有必要对其他的查询(如不完整数据查询、图查询等)展开查询结果可用性研究.
2) 大数据环境下的查询结果可用性研究
随着以博客、社交网络、基于位置的服务LBS为代表的新型信息发布方式的不断涌现,以及云计算、物联网等技术的兴起,数据正以前所未有的速度在不断地增长和累积.增长迅速、庞大繁杂的数据资源,不仅给传统的数据分析、处理技术带来了巨大的挑战,同时也给查询结果可用性研究带来了挑战.现有的查询结果可用性研究都针对常规大小的数据集,这些技术在大数据环境下通常无法有效地使用.因此,在大数据平台(如Hadoop,Spark等)上探索查询结果可用性也显得尤为重要.
3) 查询结果可用性分析系统研发
目前许多的数据库系统(如MySQL,SQL Server,Oracle等)主要向用户提供数据的存储和管理功能,但它们几乎没有向用户提供查询结果可用性分析.这不仅对用户来说非常有实际用途,而且对于提高数据库的可用性来说也至关重要.所以,在现有的数据库系统基础上集成查询结果可用性分析功能或者开发新的查询结果可用性分析系统也是未来研究工作的重点之一.
7 总 结
数据库可用性研究在数据库领域受到了越来越多的关注,而查询结果可用性研究就是数据库可用性研究的一个重要方面,这对于改善用户使用数据库的情况以及提高数据库的可用性都是至关重要的.本文介绍了查询结果可用性研究的背景;系统地对查询结果可用性研究问题进行了阐述;从Causality & Responsibility问题、Why-not & Why问题以及Why-few & Why-many问题3方面将现有的工作进行了归类分析比较;同时对现有的查询结果可用性分析系统进行了介绍;最后在综合分析现有工作的技术基础上给出了3个未来的研究方向.
[1]ISO/DIS 9241-11. Ergonomic requirements for office work with visual display terminals-Part Ⅱ guidance on usability[S]. London: International Organization for Standardization, 1998
[2]Jagadish H V, Chapman A, Elkiss A, et al. Making database systems usable[C] //Proc of ACM SIGMOD’07. New York: ACM, 2007: 13-240
[3]Li Fei, Jagadish H V. Usability, databases, and HCI[J]. Bulletin of the IEEE Computer Society Technical Committee on Data Engineering, 2012, 35(3): 37-45
[4]Lewis D. Causation[J]. The Journal of Philosophy, 1973, 70(17): 556-567
[5]Menzies P. Counterfactual theories of causation[OL]. 2014 [2016-11-07]. http://stanford.library.sydney.edu.au/entries/causation-counterfactual/#Bib
[6]Halpern J Y, Pearl J. Causes and explanations: A structural-model approach. Part Ⅰ: Causes[J]. The British Journal for the Philosophy of Science, 2005, 56(4): 843-887
[7]Chockler H, Halpern J Y. Responsibility and blame: A structural-model approach[J]. Journal of Artificial Intelligence Research, 2004, 22: 93-115
[8]Meliou A, Gatterbauer W, Halpern J Y, et al. Causality in databases[J]. Bulletin of the IEEE Computer Society Technical Committee on Data Engineering, 2010, 33(3): 59-67
[9]Meliou A, Gatterbauer W, Moore K F, et al. WHY SO? or WHY NO? Functional causality for explaining query answers[C] //Proc of MUD’10. New York: ACM, 2010: 3-17
[10]Meliou A, Roy S, Suciu D. Causality and explanations in databases[C] //Proc of ACM VLDB’14. New York: ACM, 2014: 1715-1716
[11]Meliou A, Gatterbauer W, Moore K F, et al. The complexity of causality and responsibility for query answers and non-answers[C] //Proc of ACM VLDB’11. New York: ACM, 2011: 34-45
[12]Qin Biao, Wang Shan, Zhou Xiaofang, et al. Responsibility analysis for lineages of conjunctive queries with inequalities[J]. IEEE Trans on Knowledge and Data Engineering, 2014, 26(6): 1532-1543
[13]Gao Yunjun, Liu Qing, Chen Gang, et al. Finding causality and responsibility for probabilistic reverse skyline query non-answers[J]. IEEE Trans on Knowledge and Data Engineering, 2016, 28(11): 2974-2987
[14]Wang Zheng, Wang Chaokun, Pei Jisheng, et al. Causality based propagation history ranking in social networks[C] //Proc of IJCAI’16. Menlo Park, CA: AAAI, 2016: 3917-3923
[15]Qin Biao, Wang Shan, Du Xiaoyong. Efficient responsibility analysis for query answers[C] //Proc of DASFAA’13. Berlin: Springer, 2013: 239-253
[16]Meliou A, Gatterbauer W, Nath S, et al. Tracing data errors with view-conditioned causality[C] //Proc of ACM SIGMOD’11. New York: ACM, 2011: 505-516
[17]Lian Xiang, Chen Lei. Causality and responsibility: Probabilistic queries revisited in uncertain databases[C] //Proc of ACM CIKM’13. New York: ACM, 2013: 349-358
[18]Chapman A, Jagadish H V. Why not?[C] //Proc of ACM SIGMOD’09. New York: ACM, 2009: 523-534
[19]Bidoit N, Herschel M, Tzompanaki K. Query-based why-not provenance with NedExplain[C] //Proc of ACM EDBT’14. New York: ACM, 2014: 145-156
[20]Bidoit N, Herschel M, Tzompanaki K. Immutably answering why-not questions for equivalent conjunctive queries[C/OL] //Proc of TAPP’14. New York: ACM, 2014 [2016-11-07]. https://www.usenix.org/conference/tapp2014/agenda/presentation/bidoit
[21]Bidoit N, Herschel M, Tzompanaki K. Efficient computation of polynomial explanations of why-not questions[C] //Proc of ACM CIKM’15. New York: ACM, 2015: 713-722
[22]ten Cate B, Civili C, Sherkhonov E, et al. High-level why-not explanations using ontologies[C] //Proc of ACM PODS’15. New York: ACM, 2015: 31-43
[23]Huang Jiansheng, Chen Ting, Doan A H, et al. On the provenance of non-answers to queries over extracted data[C] //Proc of ACM VLDB’08. New York: ACM, 2008: 736-747
[24]Herschel M, Hernandez M. Explaining missing answers to SPJUA queries[C] //Proc of ACM VLDB’10. New York: ACM, 2010: 185-196
[25]Zong Chuanyu, Yang Xiaochun, Wang Bin, et al. Minimizing explanations for missing answers to queries on databases[C] //Proc of DASFAA’13. Berlin: Springer, 2013: 254-268
[26]Zong Chuanyu, Wang Bin, Sun Jing, et al. Minimizing explanations of why-not questions[C] //Proc of DASFAA’14 Workshops. Berlin: Springer, 2014: 230-242
[27]Tran Q T, Chan C Y. How to ConQueR why-not questions[C] //Proc of ACM SIGMOD’10. New York: ACM, 2010: 15-26
[28]He Zhian, Lo E. Answering why-not questions on top-kqueries[C] //Proc of IEEE ICDE’12. Piscataway, NJ: IEEE, 2012: 750-761
[29]Bhowmick S S, Sun A, Truong B Q. Why not, WINE?: Towards answering why-not questions in social image search[C] //Proc of ACM MM’13. New York: ACM, 2013: 917-926
[30]Islam M S, Liu Chengfei, Li Jianxin. Efficient Answering of why-not questions in similar graph matching[J]. IEEE Trans on Knowledge and Data Engineering, 2015, 27(10): 2672-2686
[31]Chen Lei, Lin Xin, Hu Haibo, et al. Answering why-not questions on spatial keyword top-kqueries[C] //Proc of IEEE ICDE’15. Piscataway, NJ: IEEE, 2015: 279-290
[32]Chen Lei, Xu Jianliang, Lin Xin, et al. Answering why-not spatial keyword top-kqueries via keyword adaption[C] //Proc of IEEE ICDE’16. Piscataway, NJ: IEEE, 2016: 697-708
[33]Xu Wenjian, He Zhian, Lo E, et al. Explaining missing answers to top-kSQL queries[J]. IEEE Trans on Knowledge and Data Engineering, 2016, 28(8): 2071-2085
[34]Islam M S, Zhou Rui, Liu Chengfei. On answering why-not questions in reverse skyline queries[C] //Proc of IEEE ICDE’13. Piscataway, NJ: IEEE, 2013: 973-984
[35]He Zhian, Lo E. Answering why-not questions on top-kqueries[J]. IEEE Trans on Knowledge and Data Engineering, 2014, 26(6): 1300-1315
[36]Chen Lu, Gao Yunjun, Wang Kai, et al. Answering why-not questions on metric probabilistic range queries[C] //Proc of IEEE ICDE’16. Piscataway, NJ: IEEE, 2016: 767-778
[37]Gao Yunjun, Liu Qing, Chen Gang, et al. Answering why-not questions on reverse top-kqueries[C] //Proc of ACM VLDB’15. New York: ACM, 2015: 738-749
[38]Herschel M. Wondering why data are missing from query results?: Ask conseil why-not[C] //Proc of ACM CIKM’13. New York: ACM, 2013: 2213-2218
[39]Herschel M. A hybrid approach to answering why-not questions on relational query results[J]. Journal of Data and Information Quality, 2015, 5(3): 10:2-10:29
[40]Liu Bin, Chiticariu L, Chu V, et al. Automatic rule refinement for information extraction[C] //Proc of ACM VLDB’10. New York: ACM, 2010: 588-597
[41]Liu Qing, Gao Yunjun, Chen Gang, et al. Answering why-not and why questions on reverse top-kqueries[J]. The VLDB Journal, 2016, 25(6): 867-892
[42]Tan W C. Provenance in databases: Past, current, and future[J]. Bulletin of the IEEE Computer Society Technical Committee on Data Engineering, 2007, 30(4): 3-12
[43]Bhagwat D, Chiticariu L, Tan W C, et al. An annotation management system for relational databases[J]. The VLDB Journal, 2005, 14(4): 373-396
[44]Chiticariu L, Tan W C, Vijayvargiya G, et al. A post-it system for relational databases based on provenance[C] //Proc of ACM SIGMOD’05. New York: ACM, 2005: 942-944
[45]Buneman P, Khanna S, Tan W C. Why and where: A characterization of data provenance[C] //Proc of ICDE’01. Berlin: Springer, 2001: 316-330
[46]Cui Yingwei, Widom J. Lineage tracing for general data warehouse transformations[J]. The VLDB Journal, 2003, 12(1): 41-58
[47]Islam M S, Liu Chengfei, Zhou Rui. On modeling query refinement by capturing user intent through feedback[C] //Proc of ADC’12. New York: ACM, 2012: 11-20
[48]Islam M S, Liu Chengfei, Zhou Rui. User feedback based query refinement by exploiting skyline operator[C] //Proc of ER’12. Berlin: Springer, 2012: 423-438
[49]Islam M S, Liu Chengfei, Zhou Rui. FlexIQ: A flexible interactive querying framework by exploiting the skyline operator[J]. Journal of Systems and Software, 2014, 97: 97-117
[50]Muslea I. Machine learning for online query relaxation[C] //Proc of ACM KDD’04. New York: ACM, 2004: 246-255
[51]Muslea I, Lee T J. Online query relaxation via bayesian causal structures discovery[C] //Proc of AAAI’05. Menlo Park, CA: AAAI, 2005: 831-836
[52]Koudas N, Li Chen, Tung A K H, et al. Relaxing join and selection queries[C] //Proc of ACM VLDB’06. New York: ACM, 2006: 199-210
[53]Kadlag A, Wanjari A V, Freire J, et al. Supporting exploratory queries in databases[C] //Proc of DASFAA’04. Berlin: Springer, 2004: 594-605
[54]Vasilyeva E, Thiele M, Mocan A, et al. Relaxation of subgraph queries delivering empty results[C] //Proc of ACM SSDBM’15. New York: ACM, 2015: 28:1-28:13
[55]Mottin D, Marascu A, Roy S B, et al. A probabilistic optimization framework for the empty-answer problem[C] //Proc of ACM VLDB’13. New York: ACM, 2013: 1762-1773
[56]Mottin D, Marascu A, Roy S B, et al A holistic and principled approach for the empty-answer problem[J]. The VLDB Journal, 2016, 25(4): 597-622
[57]Basu Roy S, Wang Haidong, Das G, et al. Minimum-effort driven dynamic faceted search in structured databases[C] //Proc of ACM CIKM’08. New York: ACM, 2008: 13-22
[58]Kashyap A, Hristidis V, Petropoulos M. Facetor: Cost-driven exploration of faceted query results[C] //Proc of ACM CIKM’10. New York: ACM, 2010: 719-728
[59]Li Chengkai, Yan Ning, Roy S B, et al. Facetedpedia: Dynamic generation of query-dependent faceted interfaces for Wikipedia[C] //Proc of ACM WWW’10. New York: ACM, 2010: 651-660
[60]Agrawal S, Chaudhuri S, Das G, et al. Automated ranking of database query results[C/OL] //Proc of CIDR’03. New York: ACM, 2003 [2016-11-07]. http://www-db.cs.wisc.edu/cidr/cidr2003/program/p9.pdf
[61]Chaudhuri S, Das G, Hristidis V, et al. Probabilistic ranking of database query results[C] //Proc of ACM VLDB’04. New York: ACM, 2004: 888-899
[62]Chaudhuri S, Das G, Hristidis V. Probabilistic information retrieval approach for ranking of database query results[J]. ACM Trans on Database Systems, 2006, 31(3): 1134-1168
[63]Bosc P, HadjAli A, Pivert O. Empty versus overabundant answers to flexible relational queries[J]. Fuzzy Sets and Systems, 2008, 159(12): 1450-1467
[64]Mishra C, Koudas N. Interactive query refinement[C] //Proc of ACM EDBT’09. New York: ACM, 2009: 862-873
[65]Albarrak A, Sharaf M A, Zhou X. SAQR: An efficient scheme for similarity-aware query refinement supporting exploratory queries in databases[C] //Proc of DASFAA’14. Berlin: Springer, 2014: 110-125
[66]Vasilyeva E, Thiele M, Bornhövd C, et al. Answering “Why Empty?” and “Why So Many?” queries in graph databases[J]. Journal of Computer and System Sciences, 2016, 82(1): 3-22
[67]Herschel M, Hernandez M A, Tan W C. Artemis: A system for analyzing missing answers[C] //Proc of ACM VLDB’09. New York: ACM, 2009: 1550-1553
[68]Tzompanaki K, Bidoit N, Herschel M. EFQ: Why-not answer polynomials in action[C] //Proc of ACM VLDB’15. New York: ACM, 2015: 1980-1991
[69]Chen Lei, Xu Jianliang, Jensen C S, et al. YASK: A why-not question answering engine for spatial keyword query services[C] //Proc of ACM VLDB’16. New York: ACM, 2016: 1501-1504
[70]Mottin D, Marascu A, Basu Roy S, et al. IQR: An interactive query relaxation system for the empty-answer problem[C] //Proc of ACM SIGMOD’14. New York: ACM, 2014: 1095-1098
[71]Vasilyeva E, Heinze T, Thiele M, et al. DebEAQ-debugging empty-answer queries on large data graphs[C] //Proc of IEEE ICDE’16. Piscataway, NJ: IEEE, 2016: 1402-1405
[72]Liu Qing, Gao Yunjun, Zhou Linlin, et al. IS2R: A system for refining reverse top-kqueries[C] //Proc of IEEE ICDE’17. Piscataway, NJ: IEEE, 2017: 1371-1372

Liu Qing, born in 1988. PhD candidate. His main research interests include spatial databases, database usability, and data provenance.

Gao Yunjun, born in 1977. PhD. Professor, PhD supervisor in the College of Computer Science and Technology, Zhejiang University, China. Member of ACM and IEEE, and senior member of CCF. His main research interests include spatial and spatio-temporal databases, database usability, metric and incompleteuncertain data management, and geo-social data processing.
Survey of Database Usability for Query Results
Liu Qing1and Gao Yunjun1,2
1(CollegeofComputerScienceandTechnology,ZhejiangUniversity,Hangzhou310027)2(KeyLaboratoryofBigDataIntelligentComputingofZhejiangProvince(ZhejiangUniversity),Hangzhou310027)
Database usability has
much attention in the database community because of its importance. The goal of database usability is to help users utilize database more efficiently and conveniently, and thus improving the user’s satisfaction for the database. In this survey, we focus on the database usability for query results. Currently, the queries only return the query results to users. If the query result is unexpected for the users, it will frustrate users. However, the database system neither gives explanations for the unexpected query results, nor offers any suggestion on how to get the expected results for users. The users only can debug the queries by themselves, which is cumbersome and time-consuming. If the database system can offer such explanations and suggestions, it helps the users understand initial query better, and know how to change the query until the satisfactory results are found, hence improving the usability of the database. Towards this, the studies on unexpected query results have been explored. In this paper, we provide a comprehensive survey of the most recent research on database usability for query results. The paper first analyses the unexpected query results, and introduces the corresponding three problems, i.e., causality & responsibility, why-not & why questions, and why-few & why-many questions, and highlights the importance of these three problems. Then, the state of the art progresses of the unexpected query result research have been surveyed and summarized. Finally, the paper raises some directions for the future work.
database usability; why-not questions; why questions; causality & responsibility; why-few questions; why-many questions
2016-11-10;
2017-03-22
国家“九七三”重点基础研究发展计划基金项目(2015CB352502);国家自然科学基金优秀青年科学基金项目(61522208);国家自然科学基金项目(61379033,61472348);NSFC-浙江两化融合联合基金重点项目(U1609217) This work was supported by the National Basic Research Program of China (973 Program) (2015CB352502), the National Natural Science Foundation of China for Excellent Young Scientists (61522208), the National Natural Science Foundation of China (61379033, 61472348), and the Key Project of the NSFC-Zhejiang Joint Fund (U1609217).
高云君(gaoyj@zju.edu.cn)
TP311.13
