统计中文口语理解执行策略的研究*
2017-06-15李艳玲颜永红
李艳玲,颜永红
1.内蒙古师范大学 计算机与信息工程学院,呼和浩特 010022
2.中国科学院 声学研究所 语言声学与内容理解实验室,北京 100190
统计中文口语理解执行策略的研究*
李艳玲1+,颜永红2
1.内蒙古师范大学 计算机与信息工程学院,呼和浩特 010022
2.中国科学院 声学研究所 语言声学与内容理解实验室,北京 100190
LI Yanling,YAN Yonghong.Research on execution strategy about statistical spoken language understanding. Journal of Frontiers of Computer Science and Technology,2017,11(6):980-987.
口语理解的语义框架包括两个决策——关键语义概念识别和意图识别,主要针对这两个决策的执行策略进行研究。首先研究了并联型和级联型两种策略;然后在此基础上提出了联合型结构进行中文口语理解,即通过三角链条件随机场对意图以及关键语义概念共同建模,用一个单独的图模型结构共同表示它们的依赖关系。通过与其他几种策略进行比较实验得出结论:该模型可以将两个任务一次完成,在关键语义概念识别任务上性能优于其他的执行策略。
口语理解;三角链条件随机场;关键语义概念识别;意图识别;执行策略
1 引言
口语理解(spoken language understanding,SLU)是口语对话系统(spoken dialog system)的重要组成部分。所谓口语理解是让机器解析出口语语句中的关键信息(包括关键语义概念和意图),然后进行语义框架的填充。口语理解任务通常分解为两个子任务,即关键语义概念识别(key semantic concept recognition,KSCR)和意图识别(intent determination,ID)。关键语义概念识别,又称为语义槽填充(slot filling),主要从输入语句中寻找特定领域相关的关键语义概念及其类别;意图识别,主要为输入语句确定正确的领域类别、动作类别等,意图可以依据不同的应用领域进行定义。例如:在生活领域应用中,用户可以通过口语查询获取不同领域(电影、餐馆、酒店等)的信息,并且对于不同的子领域,用户可以将领域的属性信息具体化(如电影名、电影院;菜肴和参观的营业时间;酒店星级和入住时间)[1]。
Tur等人对口语理解的两个子任务使用的方法进行了综述[2],指出对于意图识别,大间隔分类器(large margin classifier)如支持向量机(support vector machine,SVM)[3]和AdaBoost[4]效果较好,而对于关键语义概念识别,条件随机场(conditional random field,CRF)建模效果较好。韩国学者Jeong等人提出使用基于三角链的条件随机场构建一个联合模型解决韩语口语理解任务[5-6]。本文在此基础上,应用三角链条件随机场解决中文口语理解问题。
传统这两个子任务主要采取的执行策略有并联型和级联型。所谓并联型,即两个子任务分开独立进行,它们之间不会相互影响;而级联型是两个子任务顺序执行,后者可以利用前者的结果作为先验知识改进模型。级联型又分为两种:先进行关键语义概念识别,再进行意图识别[7],或者反过来。这两种组合方式的不足之处在于两个子任务不能借鉴彼此的结果作为先验知识以提高自身的性能。鉴于此,本文提出使用联合型的结构进行中文口语理解,即使用三角链条件随机场将两个子任务整合到一个模型中,通过一遍运算即可得出两个决策的结果。近年来,这种联合方法已经应用于解决某些具体的任务上,如词性标注(part-of-speech)和名词短语分块(noun-phrase chunking)的联合建模[8]、句法分析和信息抽取的联合建模[9]等。三角链结构的模型在一个单独的图模型中联合表示子任务可以解决两个问题:第一,明确表示它们之间的依赖关系;第二,保留它们之间的不确定性。
本文组织结构如下:第2章介绍口语理解执行策略的几种方式;第3章阐述口语理解的几种判别式模型,包括线性链条件随机场模型、最大熵模型和三角链条件随机场模型;第4章介绍实验设置并进行结果分析;第5章是总结及展望。
2 执行策略的几种方式
口语理解的两个子任务:意图识别和关键语义概念识别。这两个子任务的执行策略包括:并联型、级联型和联合型。并联型系统架构如图1(a)所示,关键语义概念识别和意图识别两个任务单独进行,不能互相共享特征。级联型系统架构如图1(b)所示,两个子任务按顺序执行,可以先执行关键语义概念识别再执行意图识别,也可以先进行意图识别再进行关键语义概念识别(图中只给出了级联的一种情况)。联合型系统结构如图1(c)所示,将两个任务整合到一个模型中一起完成。
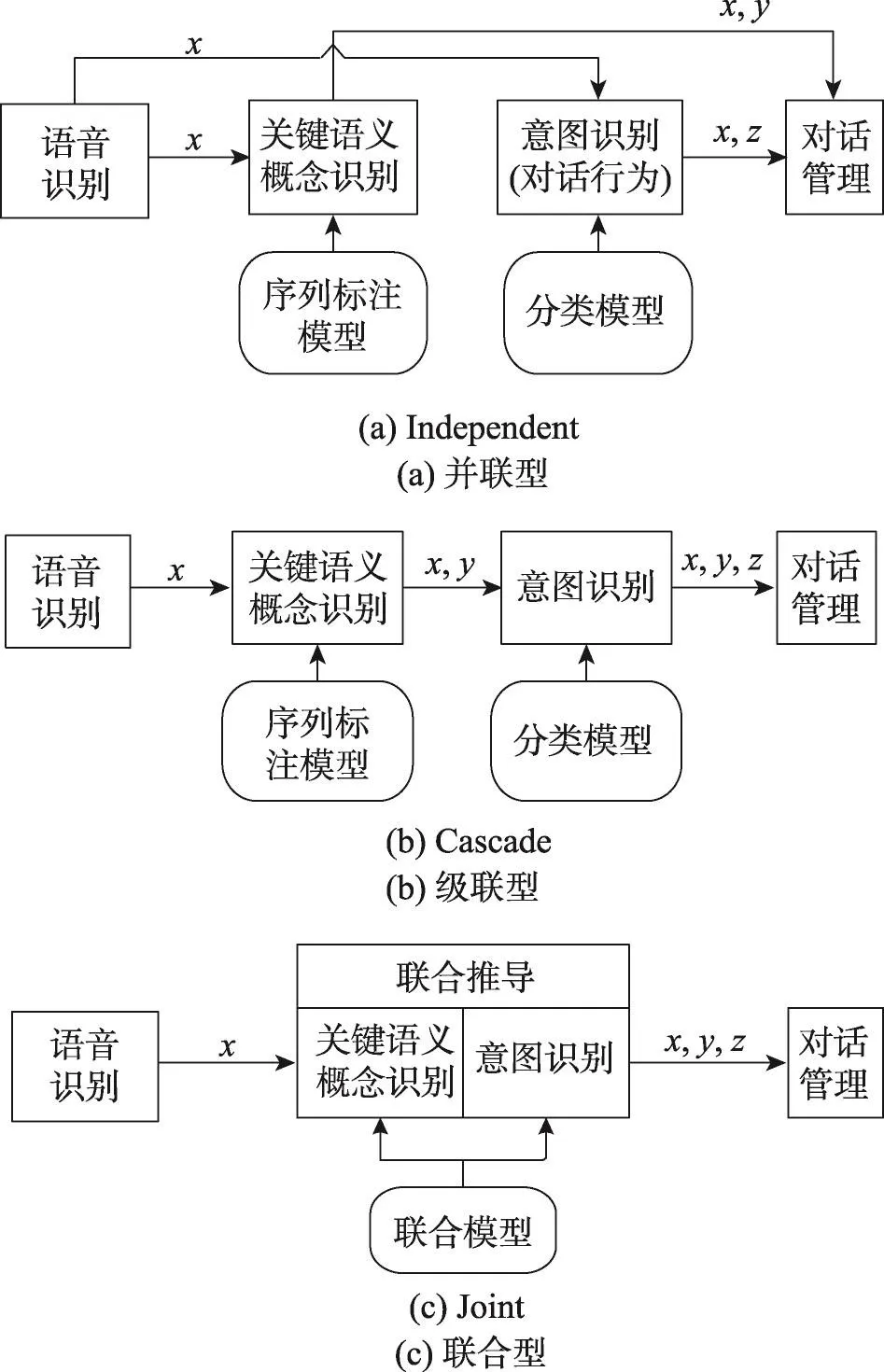
Fig.1 Block diagram about three kinds of execution strategies图1 3种执行策略框图
3 口语理解的条件概率模型
口语理解的两个子任务都可以映射为判别式模型,即条件概率模型。关键语义概念识别任务可以看作序列标注任务,即给定一个序列x,预测其标注序列y的问题。可以假设t时刻的输出yt与t时刻的一个输入xt相对应。概率模型希望通过训练数据(x,y),学习p(y|x)的分布。而意图识别任务则可以看作一个序列分类任务,即对整个输入序列x预测一个类别z的问题。概率模型希望通过训练数据(x,z),预测p(z|x)[5]。而三角链条件随机场的思想是同时解决这两个相关问题,使用联合标注数据训练一个概率模型p(y,z|x)预测最优标注(ŷ,ẑ)。该模型的目标是学习序列标注以及与序列对应的类别之间的依赖关系。
3.1 条件随机场模型
条件随机场模型最早由Lafferty等人提出[9],该模型通常用于解决序列标注问题,可以用一个无向图模型表示。该模型在很多领域都得到了广泛的应用[10-15]。
定义1设x,y为随机向量,Λ∈ℝK为参数向量,特征函数集为实值函数集,则一个线性链状条件随机场p(y|x)的定义为:

由于目标函数是凸函数,存在全局最优解。式(1)给定了模型之后,最优的标注ŷ可以通过如下的决策准则进行求解:

3.2 最大熵模型
最大熵模型(maximum entropy model,MEM)是通过求解一个有条件约束的最优化问题得到概率分布的表达式[16]。假设有n个训练样本(x1,y1)(x2,y2)…(xn,yn),其中xi是由k个属性特征构成的向量xi= {xi1,xi2,…,xik},yi是类别标记yi∈Y={y1,y2,…,yc}。所要求解的问题是,在给定一个新样本x的情况下,求取其最佳的类别标记y。最大熵的参数形式定义为:
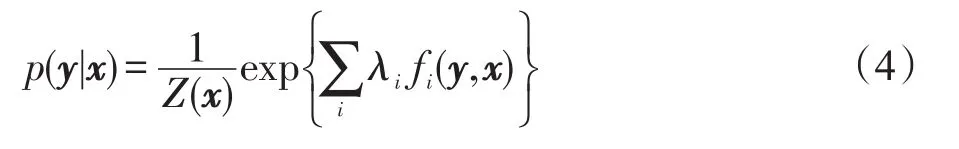
最大熵模型可以使用GIS(generalize iterative scaling)、IIS(improved iterative scaling)和L-BFGS等方法进行参数估计。最大熵模型作为一个判别式模型,可以很好地解决其他领域的问题,应用也很广泛[17-18]。
3.3 三角链条件随机场模型
传统监督学习方法的基本假设是数据独立同分布,然而在很多实际应用中,这种假设通常不完全满足。构建联合模型的主要出发点是为解决建模多意图序列的问题。如果存在这样一个分类问题:有N个训练样本的集合它们可以被分成z个类别,每类数据独立同分布。现在将类别变量z增加到模型中,则数据的输入输出变量可以表示为D=此时的目标是寻找概率分布p(y,z|x),即对序列预测意图z和序列标注y。这里假设意图类别z依赖于整个序列(x,y),而且仅考虑一个意图变量z,即每个序列x只有一个意图。这种表示很自然地构建一个三角链的图模型结构。
三角链条件随机场(triangular-chain CRF)[5]定义为:随机向量x表示输入的观察序列,随机向量y表示输出的标记序列,随机变量z是一个输出变量,表示主题或者意图。在口语理解任务中,用x表示词序列,y表示实体类别,z表示意图类别,x0表示意图z的一个观察特征向量。这种表示可以将其他知识整合到这个模型中。三角链CRF的图模型结构如图2所示。其中图2(a)为最大熵模型,是一个序列分类模型,对应本文的意图识别任务;图2(b)为线性链CRF的图模型结构,是一个序列标注模型,对应本文的关键语义概念识别任务;这两个模型整合到一起,成为三角链CRF模型,如图2(c)所示。
下面形式化定义三角链CRF。
定义2[5]y、x是随机向量,z是随机变量,λ是参数向量,{fk}是实值特征集合。一个三角链CRF模型是一个条件概率分布,有如下的形式:

Fig.2 Graphical model structures of three kinds of conditional probability models图2 三种条件概率模型的图模型结构
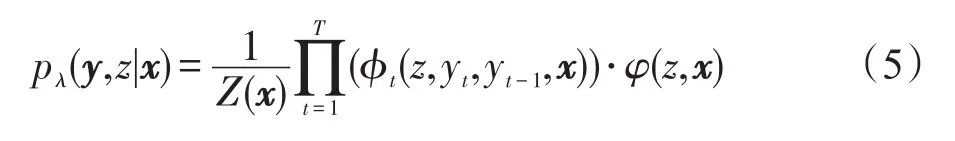
三角链CRF可以分解为时间相关的ϕt和时间不相关的φ因子,ϕt表示序列在t时刻的状态,而φ表示整个序列。一个三角链结构由这两个因子构成,φ对于变量z表现为一个先验分布。假设φ服从均匀分布,那么z仅仅取决于x1:T={x1,x2,…,xT}和y1:T={y1,y2,…,yT}。
三角链CRF可以看作一个线性链CRF和一个0阶CRF的组合。这样变量和势函数可以很自然地来源于两个CRF:(1)对于0阶CRF,x0是观察值,φ是预测z的势函数;(2)对于线性链CRF,{xt},t= 1,2,…,T是观察值,ϕt是势函数用于预测y。这里通过在图模型中增加边的方法将一个线性链CRF和一个0阶CRF结合起来。z和{xt}之间的边表示意图和序列的关系,即序列数据的观察值与意图相关。在介绍三角链CRF模型的因子结构之前,首先介绍一下线性链CRF的因子结构。三角链CRF的因子结构可以参考文献[5]。
假设x表示观察序列,y表示预测的标注序列,则一阶线性链CRF定义为:

其中,ϕt是势函数,表示t时刻的因子;Z(x)为分布函数,为了保证所有状态序列的概率和为1,Z(x)需要满足等式注意:当t=1时,
假设势函数根据特征集{fk}可以分解为:
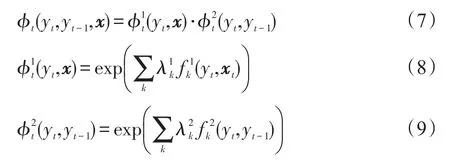
线性链CRF两个常规的推导问题都可以通过动态规划的方法解决。第一,通过计算边缘分布解决,Z(x)在训练过程中通过前向-后向算法得到。第二,计算概率最大的标注通过Viterbi算法进行求解。另外,线性链CRF的参数估计可以通过最大条件似然估计完成,因其为凸函数,可以保证收敛到全局最优。
当不考虑yt和yt-1的依赖关系时,这种特殊情况等同于logistic回归模型(或者称为最大熵分类器)。logistic回归模型可以看作一个非结构化的CRF,不考虑状态转移,而且序列的概率pλ(y|x)可以用每个状态概率pλ(yt|xt)的乘积表示:
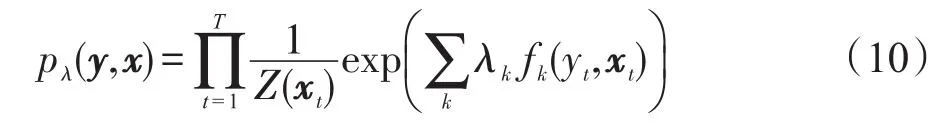
其中,Z(xt)是每个状态的分布函数。为了前后一致,将概率分布pλ(yt|xt)称为0阶CRF。注意0阶CRF可以被应用到前面的序列分类问题上。接下来解决三角链CRF的因子化问题。假设随机变量z不直接影响随机向量x,即z在给定y1:T的条件下与x1:T是独立的,然后因子化ϕt和φ如下:
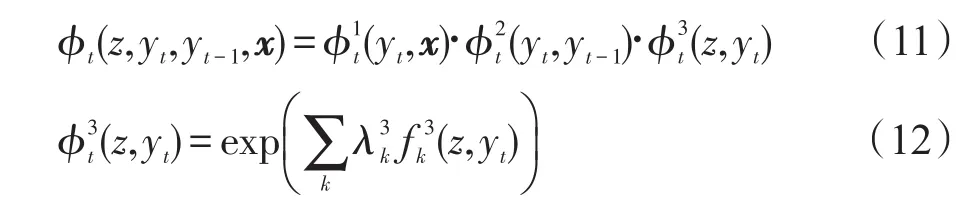

Fig.3 Graphical model and factor graph of triangular-chain CRF图3 三角链CRF的图模型结构及其因子图结构
4 实验部分
4.1 数据集
本文的研究领域限定为影视媒体、电视台、网站和应用,以帮助用户查询想看的视频,或者登录某个感兴趣的网站,或是打开某个应用等。本任务使用的数据为实验室内部收集,其中训练集6 000句,测试集2 039句。数据集的统计如表1所示。数据收集的方法如下:告知用户本系统面向的领域,给用户提供领域词典,由用户根据自己的需求,手工将问句录入。本文的口语理解任务涉及到的意图类别及分布比例见表2所示,关键语义概念类别见表3所示。

Table 1 Description of dataset表1 数据集描述

Table 2 Intent types and its distribution proportion表2 意图类型说明及分布比例
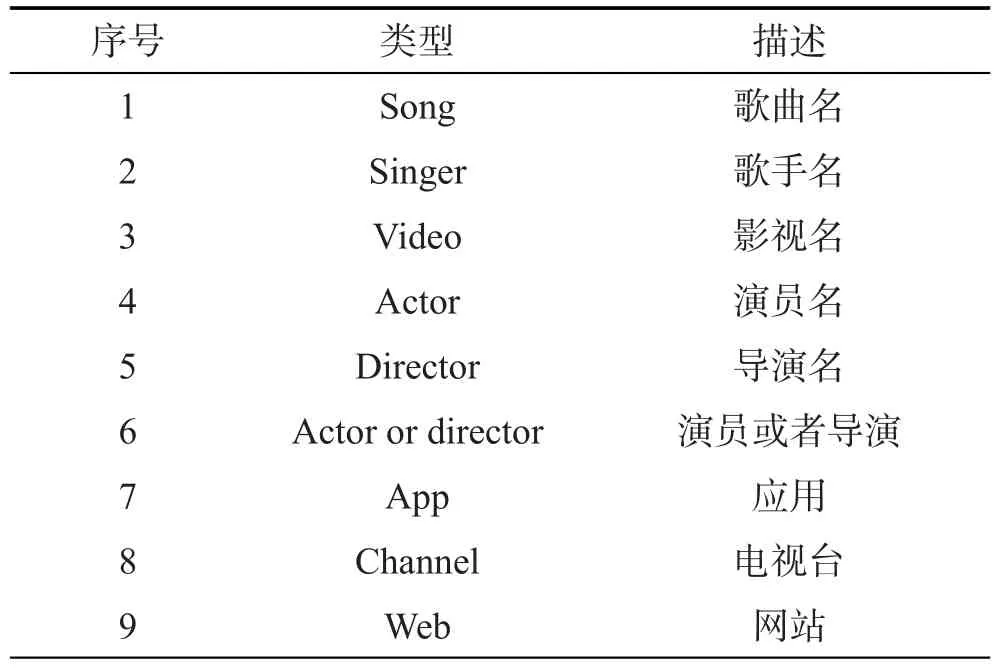
Table 3 Key semantic concept types表3 关键语义概念类型说明
4.2 实验设置
本文将三角链CRF应用到中文口语理解中,将意图识别和关键语义概念识别两个子任务用一个联合模型一次完成。为了验证算法的有效性,还与两个子任务的并联结构、级联结构进行了比较。为了和三角链CRF中的方法一致,这里的并联型和级联型结构中的意图识别使用最大熵模型[19-20],特征使用单字特征;关键语义概念识别使用线性链CRF模型,选择当前字及其前后两个单字作为关键语义概念识别的特征。
4种执行策略的比较如下所示。
(1)并联型:独立训练意图识别和关键语义概念识别两个分类器。这里使用最大熵模型进行意图识别,线性链CRF进行关键语义概念识别。
(2)级联型1:模型先进行关键语义概念识别,再将识别结果作为特征加入到意图识别任务。关键语义概念识别部分和并联型的结果一致。
(3)级联型2:模型先进行意图识别,再将意图识别结果作为特征加入到关键语义概念识别任务。
(4)联合型:将关键语义概念识别和意图识别用一个图模型表示,两个任务可以互相共享特征,一遍即可得到两个任务的结果。
4.3 评价指标及结果
意图识别使用错误率(error rate,ER)进行评价[2],关键语义概念识别使用准确率、召回率和F1值进行评价[2]。具体公式如下:

测试集上使用不同执行策略的实验结果如表4所示,表中的“—”表示该部分的性能与并联型的一致。

Table 4 Comparison of results in test set表4 测试集上的结果对比
由以上4种执行策略得到两个任务的性能,分析实验结果:首先研究关键语义概念识别的性能,级联之后(级联型2)的概念识别结果好于并联型,说明了先进行意图识别确实能为语义概念识别提供有效的特征。而联合型结构得到的关键语义概念识别结果是几个策略中最好的,说明了联合型结构充分利用了意图提供的信息,使关键语义概念识别结果达到最优。接下来分析意图识别的性能。测试集的意图识别结果,并联型得到的结果最好0.59%,其次是联合型0.83%,最后是级联型1.47%。主要原因是该测试集与训练集数据分布比较相似,使用字特征就可以达到较好的性能,而加入来自关键语义概念的特征之后,性能降低,究其原因是过拟合导致。而联合型也是如此。由以上实验结果,本文得到的结论是:三角链条件随机场在关键语义概念识别任务中得到的结果优于其他几种执行策略。
5 总结及展望
本文提出将三角链CRF模型引入中文口语理解中,将关键语义概念识别和意图识别用一个图模型表示,充分利用了两者之间的依赖关系,同时保留了它们之间的不确定性,克服了级联型模型中只能单一地借鉴一个任务结果的局限性。实验结果表明,本文模型与并联结构、级联结构相比,可以使两个子任务一次完成,其中关键语义概念识别性能高于其他执行策略。
下一步工作:因为这种联合型结构的图模型对应的因子图不唯一,而各种不同的因子图对变量之间的影响如何,对最终性能的影响如何,将会继续进行研究和讨论。
[1]Wang Yeyi.Strategies for statistical spoken language understanding with small amount of data—an empirical study [C]//Proceedings of the 11th Annual Conference of the International Speech Communication Association,Chiba,Japan, Sep 26-30,2010.Red Hook,USA:Curran Associates,2011: 2498-2501.
[2]Tur G,Hakkani-Tur D,Heck L P.What is left to be understood in ATIS?[C]//Proceedings of the 2010 IEEE Spoken Language Technology Workshop,Berkeley,USA,Dec 12-15,2010.Piscataway,USA:IEEE,2011:19-24.
[3]Vapnik V N.The nature of statistical learning theory[M]. Berlin,Heidelberg:Springer,1995.
[4]Schapire R E,Singer Y.BoosTexter:a boosting-based system for text categorization[J].Machine Learning,2000,39 (2/3):135-168.
[5]Jeong M,Lee G G.Triangular-chain conditional random fields[J].IEEE Transactions on Audio,Speech,and Language Processing,2008,16(7):1287-1302.
[6]Jeong M,Lee G G.Jointly predicting dialog act and named entity for spoken language understanding[C]//Proceedings of the 2006 IEEE Spoken Language Technology Workshop, Palm Beach,Aruba,Dec 10-13,2006.Piscataway,USA: IEEE,2006:66-69.
[7]Wu Weilin.Robust spoken language understanding across domains and languages[D].Shanghai:Shanghai Jiao Tong University,2007.
[8]Sutton C,McCallum A,Rohanimanesh K.Dynamic conditional random fields:factorized probabilistic models for labeling and segmenting sequence data[J].The Journal of Machine Learning Research,2004,8(3):693-723.
[9]Lafferty J,McCallum A,Pereira F C N.Conditional random fields:probabilistic models for segmenting and labeling sequence data[C]//Proceedings of the 18th International Conference on Machine Learning,Williamstown,USA,Jun 28-Jul 1,2001.San Francisco,USA:Morgan Kaufmann Publishers Inc,2001:282-289.
[10]Wu Qiong,Huang Degen.Temporal information extraction based on CRF and time thesaurus[J].Journal of Chinese Information Processing,2014,28(6):169-174.
[11]Qian Yili,Feng Zhiru.Identification of Chinese prosodic based on chunk and CRF[J].Journal of Chinese Information Processing,2014,28(5):32-38.
[12]Chen Fei,Liu Yiqun,Wei Chao,et al.Open domain new word detection using condition random field method[J]. Journal of Software,2013,24(5):1051-1060.
[13]Zhai Donghai,Cui Jingjing,Nie Hongyu,et al.Research on sensitive topic detection model based on conditional random fields[J].Computer Engineering,2014,40(8):158-162.
[14]Shi Shuicai,Wang Kai,Han Yanhua,et al.Terminology recognition based on conditional random fields[J].Computer Engineering andApplications,2013,49(10):147-149.
[15]Wang Yuanyuan,Wang Bin.The conditional random fields method for human action recognition[J].Journal of Chongqing University of Technology:Natural Science,2013,27 (6):93-99.
[16]Berger A L,Pietra V J D,Pietra S A D.A maximum entropy approach to natural language processing[J].Computational Linguistics,1996,22(1):39-72.
[17]Lun Xiangmin,Hou Yimin.Optimal threshold selection for image segmentation utilizing entropy-max algorithm[J]. Computer Engineering and Design,2015,36(5):1265-1268.
[18]Tu Mei,Zhou Yu,Zong Chengqing.Automatically parsing Chinese discourse based on maximum entropy[J].Acta Scientiarum Naturalium Universitatis Pekinensis,2014,50(1): 125-132.
[19]Nigam K,Lafferty J,McCallum A.Using maximum entropy for text classication[C]//Proceedings of the 16th International Joint Conference on Artificial Intelligence Workshop on Machine Learning for Information Filtering,Stockholm, Sweden,Jul 31-Aug 6,1999:421-426.
[20]Li Ronglu,Wang Jianhui,Chen Xiaoyun.Using maximum entropy model for Chinese text categorization[J].Journal of Computer Research and Development,2005,42(1):94-101.
附中文参考文献:
[7]吴尉林.可移植的稳健口语理解方法研究[D].上海:上海交通大学,2007.
[10]吴琼,黄德根.基于条件随机场与时间词库的中文时间表达式识别[J].中文信息学报,2014,28(6):169-174.
[11]钱揖丽,冯志茹.基于语块和条件随机场(CRFs)的韵律短语识别[J].中文信息学报,2014,28(5):32-38.
[12]陈飞,刘奕群,魏超,等.基于条件随机场方法的开放领域新词发现[J].软件学报,2013,24(5):1051-1060.
[13]翟东海,崔静静,聂洪玉,等.基于条件随机场的敏感话题检测模型研究[J].计算机工程,2014,40(8):158-162.
[14]施水才,王锴,韩艳铧,等.基于条件随机场的领域术语识别研究[J].计算机工程与应用,2013,49(10):147-149.
[15]王媛媛,王斌.人体行为识别的条件随机场方法[J].重庆理工大学学报:自然科学版,2013,27(6):93-99.
[17]伦向敏,侯一民.运用迭代最大熵算法选取最佳图像分割阈值[J].计算机工程与设计,2015,36(5):1265-1268.
[18]涂眉,周玉,宗成庆.基于最大熵的汉语篇章结构自动分析方法[J].北京大学学报:自然科学版,2014,50(1):125-132.
[20]李荣陆,王建会,陈晓云,等.使用最大熵模型进行中文文本分类[J].计算机研究与发展,2005,42(1):94-101.

李艳玲(1978—),女,内蒙古呼和浩特人,中国科学院声学研究所博士,内蒙古师范大学计算机与信息工程学院副教授,主要研究领域为自然语言处理,口语理解,机器学习等。发表学术论文10余篇,主持国家自然科学基金1项、内蒙古自然科学基金1项、内蒙古自治区高等学校科学研究项目1项、内蒙古师范大学校级项目3项。

YAN Yonghong was born in 1967.He is professor and Ph.D.supervisor at Key Laboratory of Speech Acoustics and Content Understanding,Institute of Acoustics,Chinese Academy of Sciences.His research interests include large vocabulary speech recognition,speaker/language recognition and audio signal processing,etc.He published many papers in important journals and conferences,and presided the National Natural Science Foundation of China,863 project and 973 project.
颜永红(1967—),男,江苏无锡人,博士,中国科学院声学研究所研究员、博士生导师,主要研究领域为语音识别,语音信号处理等。在重要的国际会议上发表论文多篇,主持国家自然科学基金、863项目、973项目等。
Research on Execution Strategy about Statistical Spoken Language Understanding*
LI Yanling1+,YAN Yonghong2
1.College of Computer and Information Engineering,Inner Mongolia Normal University,Hohhot 010022,China
2.Key Laboratory of Speech Acoustics and Content Understanding,Institute of Acoustics,Chinese Academy of Sciences,Beijing 100190,China
+Corresponding author:E-mail:cieclyl@imnu.edu.cn
The semantic frame based spoken language understanding involves two decisions—key semantic concept recognition and intent determination.This paper focuses on execution strategies of two decisions.Firstly,this paper studies independent and cascade strategies.Then,it proposes joint model,which is based on triangular-chain conditional random fields to build a joint model between key semantic concept recognition and intent determination to denote their dependence relationship.Experiments about these strategies show that the performance of joint model for key semantic concept recognition is better than other strategies.
g was born in 1978.She
the Ph.D.degree from Institute of Acoustics,Chinese Academy of Sciences.Now she is an associate professor at College of Computer and Information Engineering,Inner Mongolia Normal University.Her research interests include natural language processing,spoken language understanding and machine learning,etc.She published more than ten papers in journals and conferences,and presided several projects includes the National Natural Science Foundation of China,the Natural Science Foundation of Inner Mongolia,the Scientific Researches of Higher Education Institution of Inner Mongolia Autonomous Region and the School Fund of Inner Mongolia Normal University.
A
TP391
*The National Natural Science Foundation of China under Grant No.61562068(国家自然科学基金);the Foundation of Talent Cultivation in Inner Mongolia Normal University(内蒙古师范大学“十百千”人才培养工程项目);the Special Project of Inner Mongolia Ethnic Affairs under Grant No.MW-2014-MGYWXXH-01(内蒙古民委蒙古文信息化专项扶持子项目);the Talent Research Startup Foundation of Inner Mongolia Normal University under Grant No.2014YJRC036(内蒙古师范大学引进人才科研启动经费项目); the Natural Science Foundation of Inner Mongolia under Grant Nos.2013MS0912,2013MS0913,2014MS0617,2015MS0629(内蒙古自然科学基金);the Scientific Research of Higher Education Institution of Inner Mongolia Autonomous Region under Grant No.NJZY028(内蒙古自治区高等学校科学研究项目);the School Fund of Inner Mongolia Normal University under Grant No. 2015YBXM002(内蒙古师范大学校级基金项目).
Received 2016-02,Accepted 2016-04.
CNKI网络优先出版:2016-04-08,http://www.cnki.net/kcms/detail/11.5602.TP.20160408.1642.008.html
Key words:spoken language understanding;triangular-chain conditional random field;key semantic concept recognition;intent determination;execution strategies
