基于多源数据的供应链协同预测研究
2017-06-06梁士全

摘 要:经济全球化进程的加快促使新经济时代下的市场竞争转变为供应链之间的整体竞争。需求成为供应链的起点和动力源泉,实时、精准的需求预测和供应链内部企业的高效协同成为供应链管理模式下的两个重要问题。互联网的快速深入发展使大数据成为一种战略资源,也使捕获多源用户行为数据成为可能,有利于供应链内部企业合理调整计划,也带了数据选择和融合的挑战。本文提出一种基于多源数据信息的供应链协同需求预测框架,该框架以多源数据信息的集成共享为基础,其模型库采用因素选择因素指标,通过灰色马尔科夫和BP神经网络的组合供应链协同预测,以弱化供应链环境下的牛鞭效应问题。
关键字:牛鞭效应;多源数据;供应链协同预测;组合预测
1 引言
全球化进程的加快和市场需求的多变性周期变短促使新经济出现。在新经济时代,市场竞争已经转变为供应链与供应链之间的竞争,需求已经成为供应链的起点和动力源泉。因此,对多变的需求进行预测已经成为重要问题,实时、精准的需求预测也成为非常热门的研究方向。张文惠[1]总结了供应链需求预测和牛鞭效应定量研究的方法,验证了基于一次平滑的需求预测方法下的牛鞭效应,得出需求预测方法对牛鞭效应有重要影响。高军锋[2]基于某天然气公司的需求历史数据,将离散灰色系统模型与神经网络模型相结合,进行需求预测研究。
传统模式下,消费者在进行购买决策过程中主要通过自身经验、向亲朋好友打听等方式进行。这也使得很多需求预测方法大都以历史数据为基础,不能实时捕获用户多变的需求,导致需求预测准确率和实效降低。互联网的快速发展使消费者可以很方便地在网上进行信息搜索、社交咨询等购前调研行为,也使得捕获跨平台的多源数据进行分析与预测成为可能。Ginsberg等[3]首次通过分析大量的Google搜索请求研究了流行感冒病症的发展轨迹,称某些搜索请求的相对频率与带有流感症状的病人接诊比例相关,能够准确估计美国各地区每周的流感的活动情况。贾建民等[4]也提出网络搜索行为是一个衡量消费者购买意愿的指标,能够用于购买行为的预测。这些说明基于网上行为数据可以把握消费者需求现状和变化轨迹,对其进行合理的挖掘分析,可以更好地服务用户。
供应链是围绕核心企业,通过对信息流、物流、资金流的控制,从采购原材料开始,制成中间产品以及最终产品,最后由销售网络把产品送到消费者手中的将供应商、制造商、分销商、直到最终用户连成一个整体的功能网链结构模式[5]。供应链管理的核心是以客户的需求为前提,通过供应链内各企业间的紧密合作,有效地为客户创造更多附加价值[6]。因此,围绕供应链管理模式进行的牛鞭效应、需求预测和供应链协同等方面的研究成果也很多。彭志忠[7]指出市场预测是供应链管理中具有战略性和规划性的问题,建立了基于协作计划预测预测(CPFR)数据库的供应链需求预测的流程框架,并在此基础上提出基于BP神经网络的供应链需求预测模型。张志清[8]以牛鞭效应的存在对企业和社会资源造成浪费为起点,针对如何进行高质量的需求预测问题,构建了供应链协同需求预测的基本理论和模型,并对供应链需求预测的信息协同和方法进行了研究,探讨了供应链需求预测的组织协同和流程协同问题。
综合以上对目前多源数据应用、供应链管理和需求预测等成果的分析。为弱化供应链中的牛鞭效应的影响,提高整体服务效率,本文针对供应链管理模式下的协同需求预测问题,提出一种以多源信息共享为基础的供应链协同预测框架,不仅以多源数据信息的集成共享为基础,对框架中调用的模型库采用因素选择因素指标,通过灰色马尔科夫和BP神经网络的组合供应链协同预测。
2 牛鞭效应成因与供应链协同问题分析
2.1 牛鞭效应成因分析
在新经济时代,为了更好地协作分工,高效满足用户需求,降低成本,相关行业的企业与企业之间组成了供应链结构。整个供应链成为一个体系,其中的企业大都是独立的经营体,有着不同的目标市场、技术与运作水平。因此,这些或多或少会加大供应链在运作过程中的不确定性,供应链管理也变得比较特殊。
牛鞭效应也就是需求放大效应,即供应链中的企業节点如果只根据下游需求信息进行生产和供应决策,需求信息的扭曲在传递的过程中每经过一层企业节点会逐级放大,最终获取的需求信息与真实的用户需求信息之间也就出现很大偏差。所以,对牛鞭效应的成因进行分析有助于深层次理解供应链,从而找到弱化牛鞭效应的方法,提高供应链整体效率,降低整体供应成本。
Lee等[9]将牛鞭效应产生的主要成因总结为:需求预测更新、批量订货决策、价格波动和短期博弈。但是,进一步探究可以发现,牛鞭效应存在的深层次原因在于需求信息在传递过程中每经过一层供应链企业节点,需求信息波动就会放大,这种波动其实是供应链中的内部企业从自身考虑出发,为了应付供应链的不确定性而导致的结果。另外,需求之所以存在不确定性,是因为其相关影响因素多变,而供应链中广泛存在信息传递的停滞。供应链中的不确定性可以归结为:
(1)供应链中的企业之间衔接不确定性大,即企业之间的信息共享程度低,信息在传递过程中容易失真。
(2)供应链中的企业运作不确定性大,即各职责部门之间和企业之间的沟通协调起来不便,没有从全局对运作进行协同控制。
由此可知,供应链中的不确定性原因集中在信息共享程度较低,其中的企业协同率不高。因此,弱化牛鞭效应的有效方法为:实现信息资源的集中共享,基于多源的共享数据信息,进一步加强供应链协同运作。
Simchi-Levi等[10]通过对比分析集中需求信息和分散需求信息两种情况下供应链第K阶段发出订单的方差验证了信息资源的集中共享可以弱化牛鞭效应。其模型公式对比过程如下:
其中,表示订单观察值个数;表示零售商,分销商,制造商和供应商等供应链的不同阶段;表示第阶段与第阶段的提前期;表示供应链中第阶段发出订单的方差;表示顾客需求的方差。
上述两式分别表示集中共享需求信息和分散需求信息的供应链中第阶段发出订单的方差相对于顾客需求的方差。通过分析可知,牛鞭效应在供应链中是一直存在的,只能弱化,很难完全消除。另外,在集中共享需求信息的供应链结构中订单方差以累加和的方式增加,而在分散式需求信息的供应链结构中订单的方差以積的方式增加。由此可以知晓实现信息资源的集中共享,有助于弱化牛鞭效应。
2.2 供应链协同问题分析
供应链协同立足其内部企业作为合作伙伴的协同工作,是比供应链数据信息共享和集成更高层次的阶段。在这一阶段,供应链中的企业在共享需求信息、库存信息、销售信息等业务信息的基础上,根据外界需求和环境的变化实时调整计划,提供服务,满足用户需求。供应链协同按照层次划分可以分为战略协同、技术协同和业务协同。具体如下:
1)战略协同。处于指导整个供应链高效运作的协同层次,主要包括供应链竞争战略与运作战略协同,以及供应链节点企业的内部战略与其他企业节点的战略协同。在这个层次上,由于信息较少,主要靠经验与分析,以及对外界环境发展趋势的掌握。
2)技术协同。处于战术和操作层面的供应链协同,即供应链企业节点基于信息共享,以支持其他企业节点掌握信息,合理安排库存、销售等计划工作。在这个层次上,主要是以信息资源的集成共享为基础实现供应链的同步运作和信息协同。
3)业务协同。处于具体业务运作层面的供应链协同,可以是供应链企业内部的业务协同,也可以是供应链企业节点间的业务协同,涉及的业务主要包括:采购、库存、需求预测等。
由此可知,做到供应链协同状态有两个关键之处。第一是从简单的信息共享技术层面出发,到构建成真正的供应链合作伙伴关系;第二是业务协同程度由基础业务慢慢加深扩展,形成自定而下的各层次协同。鉴于需求预测是供应链的起点和源泉,能帮助供应链中企业合作伙伴合理安排生产、库存、销售等资源的配置,本文针对以多源共享的数据信息为基础,对供应链协同需求预测业务进行研究,来探究如何进一步弱化牛鞭效应对供应链的影响。
3 基于多源数据的供应链协同预测框架
3.1 供应链协同预测多源数据信息
本文提出的供应链协同需求预测以供应链中企业合作伙伴的信息、竞争对手信息、环境政策等信息以及与消费者网上行为相关的多源信息融合为基础,借助需求预测技术与方法和供应链多个企业之间协同进行需求预测。多源的数据信息是基础必备条件,具体如下:
1)供应链企业合作的多源数据信息,即来自供应链中不同的企业节点的多方面数据信息,主要包括零售商的POS数据和促销计划等信息,制造商的产品信息,以及新产品或产品变更等信息,供应商的材料资源信息,库存等信息。
2)竞争对手的多源数据信息,即来自行业其他供应链对手或企业的相关数据信息,主要包括竞争对手的相关产品,服务信息,竞争战略等信息。
3)环境政策的多源数据信息,即来自与行业相关的宏观环境形势或政府公布的相关政策信息,主要包括市场信息、政策信息,宏观经济等相关信息。
4)消费者网上行为相关的多源数据信息,主要包括网上搜索数据,行业社交论坛等数据信息。
针对上述几方面多源数据的获取,则需要根据不同的数据信息采用不同的搜集方式,从而建立集成数据信息共享库。供应链中企业节点数据的获取则需要其中的企业合作伙伴们进行信息共享和系统集成;竞争对手的多源数据获取则只能根据其公开的相关数据,以及对竞争对手在行业进行相关的战略措施等信息,获取后对数据信息进行筛选、标注、分类;环境政策的多源数据信息的获取可以通过爬取与行业相关的需求,销量和产品信息,以及政府公布的相关政策信息和宏观经济等相关信息;消费者网上行为数据的获取百度搜索指数或谷歌搜索指数来代表网络搜索因素,以及行业社交论坛数据。
综合上述分析可知,基于以上多源数据,对分散的供应链信息进行共享和集成,改善供应链结构,然后结合需求预测方法,进行供应链协同预测,更好地弱化牛鞭效应给供应链带来的负面影响,最终提高供应链整体服务用户的效率。
3.2 供应链协同预测框架
(1)供应链协同预测框架运作流程
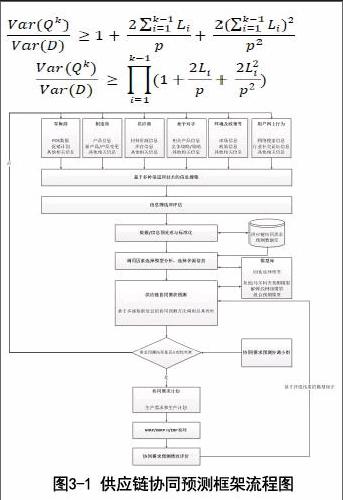
基于上文对牛鞭效应成因和供应链协同问题的分析,以及对供应链协同预测所需多源数据信息的列举分析,为了使供应链中的企业合作伙伴达到更好的供应链协同效果。本文提出了一种基于多源数据信息的供应链协同预测框架,该框架具体流程如图3-1所示:
对图3-1的协同预测框架流程进行梳理可知,本文提出的供应链协同预测框架主要流程过程如下:
1)基于多种渠道和技术获取相关多源数据信息,即从供应链中包括零售商、制造商、供应商的合作伙伴,竞争对手,环境及政策以及消费者用户留在网上的行为数据相关数据。这些数据不仅来自多个渠道,而且大都是跨平台的多源大数据,其数据信息的存在形式是复杂多样的。
2)信息筛选和评估,将搜集到的多源数据进行必要的甄别和筛选。
3)将筛选评估后的数据和信息进行对应的预处理和标准化,对于复杂数据则需要进行基于语义的相关处理,使数据形成统一的形式,并将其存入供应链协同预测数据库。
4)调用模型库中因素选择模型,对多源数据指标进行分析与选择,对于对最终协同需求预测关联度较小的数据指标,在模型修正的时候可以不予考虑。
5)调用模型库中的模型方法,分别使用灰色马尔科夫和BP神经网络模型预测方法,从时间序列和多种影响因素两方面进行预测,然后基于时间序列和多因素进行供应链协同组合预测。
6)由供应链中多个企业合作伙伴组成的协同需求预测小组对协同预测结果进行分析,对不同模型方法进行对比分析,判定预测结果的合理性是否达标。如果协同预测结果的合理性达标,则根据需求预测结果进行生产与需求计划。如果协同预测结果的合理性不达标,则会从数据指标,需求预测方法出发,以及参考零售商等企业的意见,进行必要的修正。另外,如果感应到外界环境及政策,竞争对手和消费者偏好趋势方面的变化,将会把协同预测的结果反馈到上层协同需求预测模型,进行必要的修正,以此来保证供应链中的企业合作伙伴能协同地根据外界变化进行相应的调整。
对以上提出的供应链协同预测框架及其主要流程步骤的梳理分析可知,该框架具有如下特征:
1)基于多源的数据信息进行协同预测,预测的信息来源具有多源和多向性,涵盖了供应链中的企业节点,市场政策,以及消费者用户的网上行为数据信息。
2)充分利用了信息融合技术,数据挖掘和数据库以及数据仓库技术的思想,在供应链的多个层次进行有效协同。
3)组合预测方法兼顾了时间序列和多种影响因素,BP神经网络又具有自学习特点,因此,这样的组合策略可以提高提高协同预测精度。
4)预测结果的评价,由于对不同的协同预测结果进行对比协调,由来自供应链中不同企业合作伙伴组成的评定小组联合确定最后的预测量,这样有助于更好的预测结果被采纳。
5)在协同预测结果通过合理性检验后,将预测直接转化为生产与需求计划,兼顾了流程的完整与实用性。
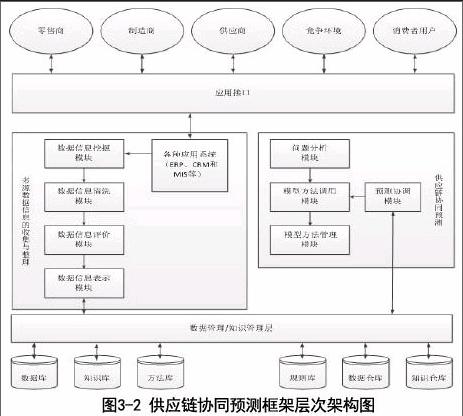
(2)供应链协同框架层次架构
根据上述对协同框架流程特点和模型库方法建模的分析,可知基于多源数据的供应链协同预测框架需要兼顾数据层、方法处理层和应用层三个方面。因此,从三个层次的角度来看,本文提出的基于多源数据信息的协同预测框架具体如图3-2所示:
对图3-2中的协同预测框架层次图进行梳理分析可知:
1)数据层主要用来存储与协同预测相关多源的数据信息,信息主要来自供应链中的不同企业合作伙伴、竞争环境与消费用户,并存储了一些必要的知识库和知识仓库,以及方法、规则库。
2)在数据层与方法处理层之间构建了一层数据和知识管理层,用来衔接数据层和方法处理层,使得方法处理时可以访问相关数据,处理后的结果可以进行有效存储。
3)方法处理层主要一部分用来处理多源数据信息的挖掘、清洗、评价与统一表示,负责将标准化的数据存储到数据层;另一部分用来进行供应链协同预测,协同预测模块中主要由问题分析模块和模型方法调用与管理模块,以及预测调用模块组成。
4)方法处理层以上的均可称为应用层,主要通过应用层接口衔接供应链中的各个协同企业主体的管理应用系统,从而保证可以从供应链中的企业合作伙伴,竞争环境以及消费者留下的网上行为等系统平台上搜集获取多源数据。
综合上述内容分析可知,本文提出的基于多源数据的供应链协同预测框架,不仅兼顾了框架在流程上的运作分析,模型库需求预测方法建模过程,还给出了基于分层次的框架分析。通过分析基于多源数据的供应链协同预测框架可知,该框架不仅做到了基于集中式的信息共享改善供应链信息流结构,还基于框架运作更好地控制了供应链中的企业合作伙伴,使其更好地进行供应链协同预测,在实践中对于弱化牛鞭效应的影响有一定的优势与参考价值。
3.3 供应链协同预测框架模型库方法
如上述框架图中所示,本文提出的供应链协同预测框架模型方法基于多源数据,首先通过因素选择模型分析选择出关联性强的的数据因素指标作为模型的输入。由于灰色马尔科夫基于时间序列进行预测,而BP神经网络可以基于多种关联影响因素来进行预测,因此,采用灰色马爾科夫和神经网络预测方法进行组合预测,综合考虑时间序列和多源数据影响因素进行预测。整体思路如图3-3:
(1)因素选择模型
需求具有一定的偶然性和模糊性,从系统角度来看存在着确定性因素和未知因素,可以认为是灰色系统。因此,本文基于灰色理论构建因素选择模型,其主要步骤如下:
10)利用转移矩阵进行出状态转移,根据转移概率计算出修正值,即作为灰色马尔科夫模型最终预测值。
BP神经网络,即多层前馈式误差反向神经网络,由一个输入层、一个或多个隐层,以及一个输出层构成。每层都由若干神经元组成。整个网络的输入对应每个样本数据的自变量属性,通过输入层加权后传给各个隐层,最后一个隐层的加权输出作为输出层的输入,最后,输出层计算出关于给定样本的网络预测。BP神经网络模型的构建具体如下图:
如图3-4所示,模型方法包括正向传播和反向误差传播过程。在正向传播过程,多种数据因素代入输入层,经过隐层的非线性映射,输出层计算出初步预测结果,然后对误差进行计算优化权重,这样反复迭代,直到学习训练出可以输出接受误差范围的预测值。
综上所述,将灰色马尔科夫和BP神经网络预测出的预测值进行组合预测,作为模型库最终得到的供应链协同预测结果。
4. 总结与展望
本文为弱化供应链中的牛鞭效应的影响,提高整体服务效率,提出一种以多源信息共享为基础的供应链协同预测框架。该框架不仅以多源数据信息的集成共享为基础,对框架中调用的模型库采用因素选择因素指标,通过灰色马尔科夫和BP神经网络的组合供应链协同预测,对弱化牛鞭效应和供应链协同需求预测具有一定的理论意义和实践参考价值。本文模型库中的组合预测方法虽然可行,还需要进一步研究,对比论证。另外,本文因素选择分析模型对数据选择和融合有一定的实践意义,可面对复杂多样的多源数据,还需深入细化研究数据选择和融合问题。
参考文献
[1] 张文惠. 浅析供应链需求预测与牛鞭效应[J]. 当代经济, 2009(22):150-151.
[2] 高军锋. 灰色神经网络模型DGNNM(1,1)及其在供应链需求预测中的应用[J]. 科技、经济、市场, 2007(1):34-35.
[3]Ginsberg J., Mohebbi M. H., Patel R. S., et al. Detecting Influenza Epidemics Using Search Engine Query Data[J]. Nature, 2009, 457(7232):1012-14.
[4]王炼, 宁一鉴, 贾建民. 基于网络搜索的销量与市场份额的预测:来自中国汽车市场的证据[J]. 管理工程学报, 2015, 29(4):56-64.
[5] 陈志祥, 马士华, 陈荣秋. 供应链企业间的合作对策与委托实现机制问题[J]. 科研管理, 1999, 20(6):98-102.
[6] Manthou V, Vlachopoulou M, Folinas D. Virtual e-Chain (VeC) model for supply chain collaboration[J]. International Journal of Production Economics, 2004, 87(3):241-250.
[7] 彭志忠. 供应链需求预测中的神经网络预测技术应用分析[J]. 中国流通经济, 2007, 21(12):16-18.
[8] 张志清. 面向不确定需求的供应链协同需求预测研究[D]. 哈尔滨工业大学, 2010.
[9] Lee H L, Padmanabhan V, Whang S. Information Distortion in a Supply Chain: The Bullwhip Effect[J]. Management Science, 1997, 43(4):546-558.
[10] 大卫·辛奇-利维, 菲利普·卡明斯基, 伊迪斯·辛奇-利维,等. 供应链设计与管理:概念、战略与案例研究[M]. 中国人民大学出版社, 2010.
作者简介
梁士全(1989-),男,河南商丘人, 硕士研究生,研究方向为物流系统设计与优化。
