基于自适应度量学习的行人再识别
2017-06-05詹敏王佳斌邹小波
詹敏 王佳斌 邹小波

摘要:该文提出了基于自适应度量学习(AML)的行人再识别方法。与正常处理所有负样本的常规度量学习方法不同的是,AML将负样本自适应地分为三组,并对它们给予不同的关注。通过加强负样本的影响,AML可以更好地挖掘正样本和负样本之间的辨别信息,从而生成更有效的度量。此外,我们还提出了探针特定重新排名(PSR)算法来改进由度量学习得到的初始排名列表。对于每个探针,PSR构建相应的超图以捕获探针和其排名前100的图库图像之间的邻域关系。然后基于它们在超图中的邻域亲和力来重新排列这些图像。其中对公共数据集VIPER数据集的实验证明了AML和PSR的良好的鲁棒性和优越性。
关键词:行人再识别;自适应度量学习;负样本;探针特定重新排名
中图分类号:TP391
文献标识码:A
文章编号:1009-3044(2017)10-0159-03
1.概述
行人再识别指的是从给定由一个相机捕获的行人探测图像或从其他相机获取的一组图库图像中识别目标人的任务。由于其在多相机监视中的重要性,近年来该问题已经获得越来越多的关注。然而,同一个人在不同相机下往往具有不同的外观变化和不同行人的视觉模糊性使得行人重识别是一项具有挑战性的任务。
关于行人再识别的现有工作大致可以分为两组。第一组的方法是设计针对交叉相机变化鲁棒的特征表示。其中代表特征的描述符包括SDALF,saliency,SCNCD,MLF和LO-MO。然而,在面对诸如照明,视角,姿势和遮挡等问题时交叉相机变化是不变的,而且对于视觉模糊性而言足够区别的特征描述符是极其困难的。为此,引入旨在寻找任何给定特征的最佳距离度量的第二组方法,以进一步改善其算法性能,提高算法的鲁棒性。
在过去几年中,已经提出并实现了许多基于度量学习的行人重识别方法,例如PRDC,KISSME,LADF,XQDA和MLAPG。一般来说,这些方法试图学习距离度量,其给出正的(匹配的)图像对的小距离值和大的距离值到负的(不匹配的)。通过在训练集中采用标记的成对信息,度量学习方法可以隐式地对相机视图之间的过渡进行建模。
虽然度量学习算法对于行人再识别是有效的,但是现有的度量学习方法仍然具有若干缺点。首先,现有方法常常忽略数据不平衡的问题。由于正样本的数量通常在行人再识别中非常有限,所以大量负样本可能在训练期间削弱正样本的效果,因此使得所学习的度量不具有区别性。其次,不同类型的负样本可以为度量学习提供不同量的辨别信息。然而,大多数现有方法同等对待所有阴性样本,而不考虑它们的多样性。第三,基于度量学习的方法倾向于在高维特征空间中过拟合。在测试阶段盲目相信学习的度量可能会产生不理想的结果。
为了处理前两个缺点,我们提出了一种称为自适应度量学习(AML)的新度量学习方法。与现有的度量学习方法不同的是,AML基于它们与探针的距离将负样品自适应地分类为三种类型。良好可分离的负样本容易被丢弃以减轻数据不平衡并加速学习过程,而接近探测器的较难负样本在度量学习期间被分配以大的权重。通过不同地处理负样品,AML可以更好地利用负样品提供的鉴别信息。此外,由于第三个缺点,我们提出了一个探针特定重新排名(PSR)框架,以细化由学习的度量测量的初始结果。与直接计算成对距离不同,PSR考虑在排名前100的图库图像中的邻域信息以做出鲁棒决定。对于每个探针,重新排名被公式化为具有闭式解的变换超图学习问题。实验结果表明,AML优于先前的方法,PSR可以进一步提高整体性能。
3.探针特异性重排序
3.1超图像架构
由于样本之间的建模群体关系的有效性,超图像已经广泛用于图像检索,并最近被引入行人重识别。与以前的研究不同,本方法侧重于改进度量学习的测试阶段。因此,一些调整已使得构造的超图更适合我们的任务。
其中向量f包含要学习的重新排名分数,向量s是初始标签向量,u是权衡参数L是可以基于H计算的超图拉普拉斯算子,其推导可以参考。方程的第一项(7)是超图上的损失项,保证两个顶点共享的超边越多,它们的分数在f中越相似,而第二项是强迫学习分数逼近s中的标记的正则化项。为了传播标签信息,s中的第一元素被设置为1,其对应于探针,并且所有其他元素被设置为0。其中图1为超图像重排序框架,该框架的PSR仅关注初始列表中的前100个图像,以减少不相关样本的噪声。
4.实验结果及分析
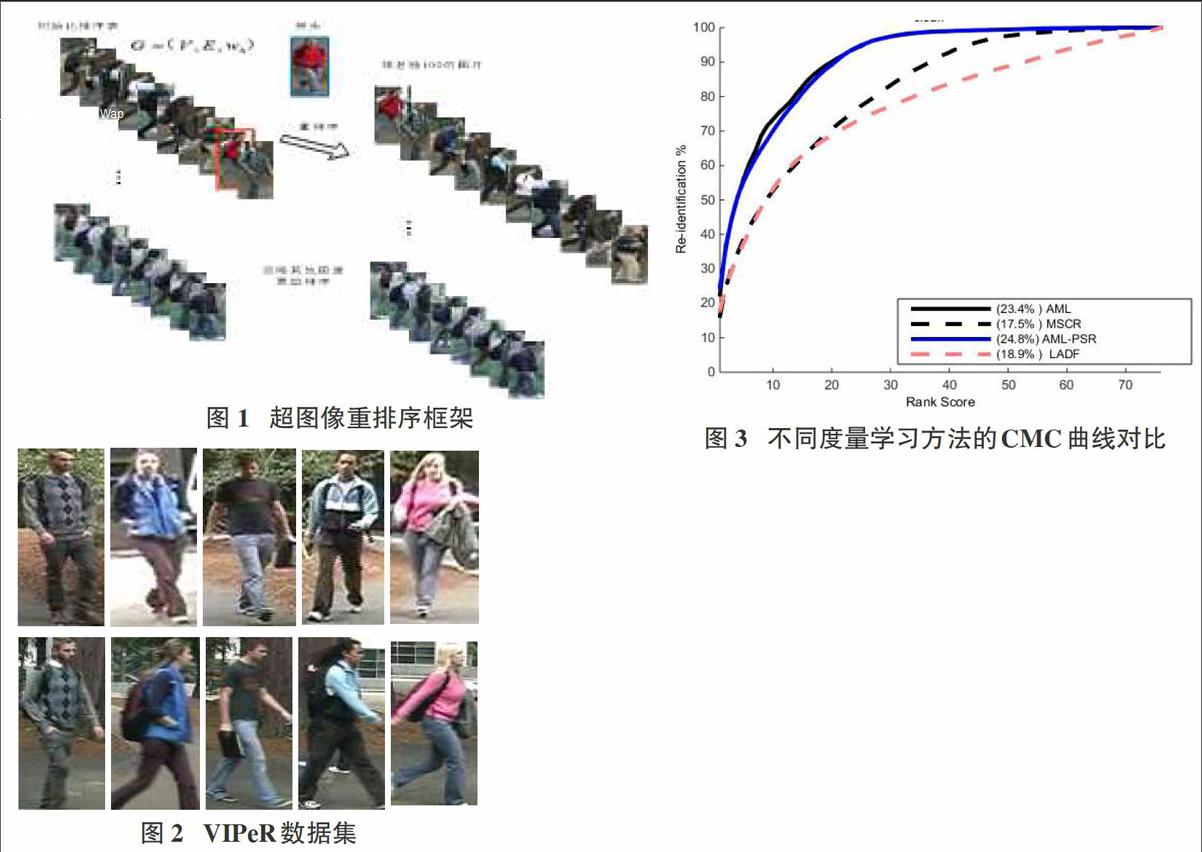
为了评估AML和PSR的有效性,我们在VIPeR数据集上进行实验。最近提出的LOMO特征被用作输入特征,其中将LOMO特征的维数减少到每个数据集上的训练图像的数量。这加快了学习过程,同时保持输入特征的所有能量。在所有实验中,权重Wh和权衡参数u被设置为0.3和10-2,其通過对训练数据的交叉验证来确定。根据广泛使用的协议,所有三个数据集随机分为两个子集,一个用于训练,另一个用于测试。具体来说,VIPER,PRID450S和CUHK01的训练集分别包含316,225和485人。分割重复10次,并描绘平均累积匹配特征(CMC)曲线。
VIPER是最具挑战性的数据集之一,其中包含了632个人不同姿态、不同场景的图像。图2为该数据集中的部分图像。每个人在室外环境中具有由两个不相交的相机捕获的一对图像,其在视点,姿势和照明方面具有显着变化。所有图像缩放为128x48像素。
度量学习方法性能的比较:我们首先评估所提出的现有的度量学习方法,例如KISSME,LADF。所有方法使用相同的LOMO特征进行统一对比。图3显示了VIPER数据分区设置下各算法与基线方法的比较。通过观察图中CMC曲线不难发现显然,AML优于均衡处理负样本的所有度量学习方法。此外,通过联合使用AML和PSR,AML的秩-l精度进一步提高。该结果证明了所提出的重新排名算法的有效性。不同度量学习算法的运行时间如图4所示。本实验在具有Intel i7双核2.8GHz CPU的PC上进行。AML的训练速度(27.1s)比其他方法更快,对于PSR,每个探头的重新排列只需要0.004s。AML和PSR的吸引人的运行时间非常受益于在训练和测试阶段忽略不相关的样品。为了显示仅获取用于重新排名的前100个排名的图像的优点,我们给出了如何相对于在图1中为PSR选择的图像的数量q改变精度和测试时间。结果表明,放大q不会改善性能,但指数地增加重新排序时间。
5.总结
本文提出了一种新颖的度量学习方法AML,以及一种有效的重新排名算法PSR,用于行人重识别。AML处理阴性样本不同,以更好地探索训练期间样本之间的辨别信息,PSR通过考虑测试期间图库图像之间的邻域关系进一步提高了性能。对三个具有挑战性的基准的实验已经证明了AML和PSR在有效性和效率方面的优点。根据其基础数据分布针对每个图像样本学习一个局部特征投影,并且将所有图像特征映射到用于比较的公共辨别空间中.我们采用基于PSR的学习方法与直接计算成对距离不同,PSR考虑在排名前100的图库图像中的邻域信息以做出鲁棒的决定。对于每个探针,重新排名被公式化为具有闭式解的变换超图学习问题。实验结果表明,AML优于先前的方法,PSR可以进一步提高整体性能。所有训练样本的局部预测的联合学习和优化中引入正则化项使我们的模型可以处理来自在训练过程中不存在的照相机的图像。我们的方法优于基线方法,并利用最先进的方法实现竞争性能。
