基于用户的协同过滤算法的改进研究
2017-06-05苏林宇陈学斌
苏林宇,陈学斌
基于用户的协同过滤算法的改进研究
苏林宇1,2,陈学斌1,2
(1. 华北理工大学理学院,河北唐山 06300;2. 河北省数据科学与应用重点实验室,河北唐山 06300)
本文针对传统的基于用户协同过滤算法的稀疏性大,推荐效率,精度低等问题,提出了一种改进的算法。在计算“用户-评分”矩阵时,通过建立“项目-用户”倒查表,忽略无相同评分项的用户间相似性的计算,降低了用户评分矩阵的稀疏性,以及传统方法中对所有用户两两计算相似度的工作量。在计算用户相似度时,考虑到项目热门程度对推荐结果的影响,通过“惩罚”用户共同兴趣列表中的热门项目,避免了传统算法中由于赋予所有项目相同权重给个性化推荐结果带来的负面影响。最后,通过和数据集检验该算法,并且用十折交叉方法验证结果。结果表明,改进后的算法节约了运行时间,提高了推荐算法的效率和个性化。
基于用户的协同过滤;个性化推荐;相似度计算;十折交叉验证;项目-用户倒查表
1 引言
个性化推荐是一种通过研究用户的兴趣或购买行为,主动向用户推荐感兴趣的信息或商品的算法。它的提出缓解了日益增长的互联网信息量与用户的个性化需求间的矛盾。协同过滤是目前应用最广泛,也是最成功的个性化推荐算法。它的基本思想是依据用户的兴趣相似性进行建模,根据该模型,把与当前用户相似的其他用户行为推荐给该用户。该技术的优点是不需关注行为的具体表现形式,只需要关注推荐行为本身。然而,协同过滤算法在实际应用中也存在着稀疏性、效率、精确性、冷启动和可扩展性等问题[1]。
在大型的电子商务系统中,如淘宝、亚马逊,它们有成千上万的商品,但其中被用户评价过的只占不到1%。这导致了“用户-评分”矩阵的过度稀疏。此外,传统的协同过滤算法在计算用户间相似度时,需逐个计算两个用户对同一个项目的评分,这使得算法的时间复杂度达到了,当用户数量较多时,将耗费大量的时间,且难以找到最近邻居,进而影响到推荐的效率与精确性。
最后,传统的基于用户的协同过滤算法在计算用户相似度时,赋予所有项目相同权值,并没有考虑项目的热门程度对推荐结果的影响。John S. Breese曾提出[2],即使两个用户购买或关注过同一热门项目,也不能因此认定他们有相似的兴趣。所以,将热门项目当成普通项目处理将会对个性化推荐的结果造成负面影响。
2 改进的用户协同过滤算法
2.1 建立“项目-用户”倒查表解决矩阵稀疏性问题
如表1,“—”表示用户对该商品无评价,这种现象在电子商务系统中普遍存在。
表1 “用户-项目”矩阵的稀疏性
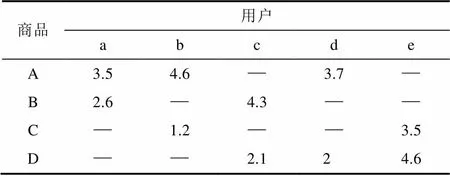
Tab.1 Data sparseness of user-rating-data matrix
基于此,本文建立“项目-用户”表,即每个项目对应该项目评分过的用户列表,并且忽略用户相似度为0(即两个用户之间没有对任何一个项目同时评分)的情况。例如用户A和用户B同时评论过s个项目,就有,从而可以倒查每个项目对应的用户列表,进而得到所有用户间不为0的。以表1的数据为例,建立的“项目-用户”表如下:
表2 “项目-用户”倒查表
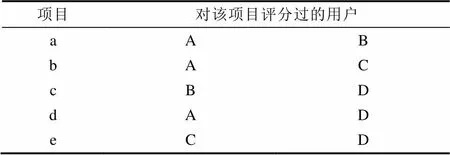
Tab.2 Items-users inversion table
2.2 用户相似度公式改进
在传统的基于用户的协同过滤算法中,计算用户相似度时,赋予所有项目相同权值。并没有考虑项目的热门程度不同对推荐结果的影响。例如,在采用余弦相似度公式来计算用户A和B的兴趣相似度,C(A)表示用户A曾经评分过的项目集合,|C(A)|表示集合C(A)中元素个数,C(B)表示用户B曾经评分过的项目集合,|C(B)|表示集合C(B)中元素个数,计算公式[3]如(1)所示:
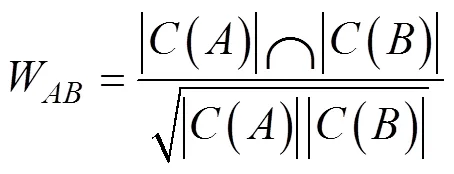
John S. Breese曾提出[1],即使两个用户购买过同一热门项目,也不能因此认为他们有相似的兴趣。因此,赋予热门项目相同权重将会对个性化推荐的结果造成负面影响。例如,两个用户都买过自行车,但不能说明他们都喜欢骑自行车,因为自行车作为基本的交通工具,每个人都会有需求,但如果两个人都买过昂贵的自行车配件,则可以认为他们兴趣相似。C(i)表示所有评分项目中包含项目i的集合,|C(i)|表示集合C(i)中元素个数,利用John S. Breese提出的思想,对用户相似度的公式进行改进:
(2)
公式(2)中对项目个数|C(i)|求对数后取倒数,有效地降低了热门项目对用户相似度计算的影响,“惩罚”了用户、共同兴趣列表中,热门项目对他们相似度的影响,提高了推荐结果的精度。
2.3 改进的用户协同过滤算法流程
(1)将数据集平均分为S份,选出其中的一份作为测试集,把剩下的S-1份作为训练集。为了保证评测指标不是过拟合的结果,采用十折交叉法进行交叉对结果进行验证。需要进行S次试验,每次使用不同的测试集,然后将S次试验测出的评测指标均值作为最终的评测指标[4]。
(2)进行基于用户的协同过滤算法[5]:找到和用户A有相似兴趣的其他用户,然后把其他用户喜好的、而用户没有的项目推荐给用户:
1:找到和目标用户兴趣相似的用户集合。
2:给用户推荐和他兴趣最相似的个用户评价过的项目。以下公式计算用户对项目的感兴趣程度:
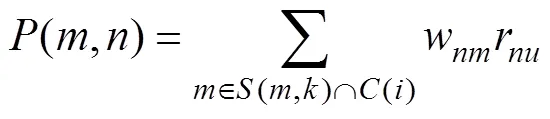
3 实验验证结果及分析
3.1 Movielens100K和HetRc2011-movielens-2k实验数据集
本文采用Movielens100K数据集,包括了700个用户对9000部电影的100,000条评分记录,评分范围是1-5,数值越大表示评价越高。其中u.data表格如表3所示:
表3 u.data表格式

Tab.3 Format of the u.data table
本文主要对其中的UserId,MovieId,Rating三个字段进行计算。
HetRec2011-movielens-2k数据集2,其中包括了2113个用户对10197部电影的85559条评分记录,其中的user_ratedmovies表信息如3:下页表4所示。
和Movielens100K数据集一样,主要对UserID,MovieID,Rating三个字段进行计算。
3.2 精度与个性化评价指标
设向用户推荐的个电影集合为R(m),测试集中用户评分过的电影集合为T(m)。推荐系统的个性化评测指标一般有召回率、准确率、覆盖率和新颖度[7]等。
表4 user_ratedmovies表的格式
Tab.4 Format of the user_ratedmovies table
召回率:也称“查全率”,指在最终的推荐列表中“用户-电影”评分记录所占的比例,其计算公式为:
2)准确率:也称“精度”,指已经发生过的“用户-电影”评分记录在最终的推荐列表中有所占比例。准确率的计算公式为:
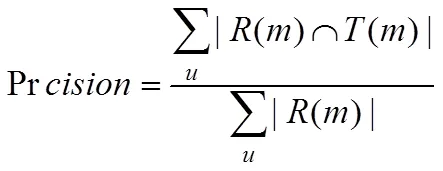
3)覆盖率:指最终的推荐列表中,电影所占的比例,反应了算法发现长尾电影的能力,覆盖率越高,说明算法越能将长尾(长尾:边缘化)电影推荐给用户。覆盖率的公式为:
(6)
其中,M代表全部电影的集合,R(m)为向用户推荐的电影集合。
4)流行度:即评价某项目的用户数。计算公式为:

其中为平均流行度,为推荐的电影数。
3.3 实验参数介绍
因为重点是对隐反馈数据进行分析,所以预测用户会不会对某部电影评分,而不是预测用户在准备评分的前提下会评多少分,进行离线实验[8]。实验的评价指标:有召回率、准确率、覆盖率、流行度4个指标。利用十折交叉法[9]进行交叉验证,对实验次数取M = 8。
4 实验结果及分析
4.1 不同值对推荐效果的影响
值表示与目标用户相似的其他用户数量。不同值对推荐结果产生不同的影响[10],通过赋予不同的取值,可以找到该算法中效果最好的值。
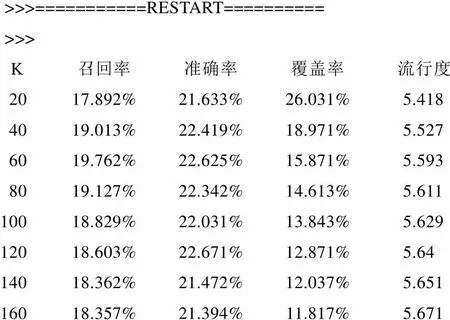
>>>===========RESTART========== >>> K召回率准确率覆盖率流行度 2017.892%21.633%26.031%5.418 4019.013%22.419%18.971%5.527 6019.762%22.625%15.871%5.593 8019.127%22.342%14.613%5.611 10018.829%22.031%13.843%5.629 12018.603%22.671%12.871%5.64 14018.362%21.472%12.037%5.651 16018.357%21.394%11.817%5.671
从图1可以看出,不同的值得到的召回率、准确率、覆盖率和流行度都不相同,且不构成线性关系。
召回率和准确率:值在60左右会得到较高的召回率和准确率。因此,合适的值对于获得高推荐精度起到重要的作用。
覆盖率:随着值增大,覆盖率总体呈下降趋势。这是因为随着值的增大,流行度越也随之增大,被参考的用户(这里指和目标兴趣相似的用户)就越多,结果就越趋近于热门电影,从而对长尾电影的推荐就越少,造成了覆盖率的降低。
流行度:因为值决定了在推荐电影时参考的和目标用户兴趣相似的用户的数量,越大,说明参考的人越多,结果也就越来越趋近于全局热门的电影。
4.2 传统用户相似度与倒查表计算方法运行时间的对比
从图2和图3可以计算出,传统方法计算用户相似度的时间为166秒,而采用倒查表所用时间为132秒,说明采用倒查表计算用户相似度能有效提高效率,这是因为减少了对没有相同评分项的用户之间相似度的计算,所以提高了时间上的效率。另一方面,该方法在一定程度上也解决了“用户-项目”矩阵的稀疏性问题。

>>>===========RESTART========== >>> K召回率准确率覆盖率流行度 2017.783%20.971%26.031%5.471 4019.232%22.582%18.829%5.541 6019.411%22.547%16.715%5.593 8019.154%22.325%14.774%5.609 10018.842%22.031%13.809%5.63 12018.423%21.573%12.617%5.641 14018.361%21.491%12.016%5.658 16018.179%21.311%11.054%5.672 程序运行初始时间:2017-02-20 11:03:27 程序运行结束时间:2017-02-20 11:06:13

>>>===========RESTART========== >>> K召回率准确率覆盖率流行度 2017.80%20.97%26.03%5.471 4019.23%22.58%18.83%5.541 6019.41%22.55%16.88%5.593 8019.19%22.38%14.77%5.609 10018.84%22.03%13.82%5.63 12018.45%21.60%12.62%5.641 14018.36%21.49%12.02%5.658 16018.18%21.31%11.05%5.672 程序运行初始时间:2017-02-20 11:10:14 程序运行结束时间:2017-02-20 11:12:26
4.3 采用用户相似度改进方法后的对比
对比图2的运行结果,采用公式(2)后,有效降低了热门项目对用户相似度计算的影响。从图4可看出,召回率由原来的最高19.411%提升到19.433%,准确率由原来的最高22.582%提升到22.870%、覆盖率由原来的26.031%提升到26.713%。这说明采用改进的用户相似性方法能更好地实现推荐系统的个性化。
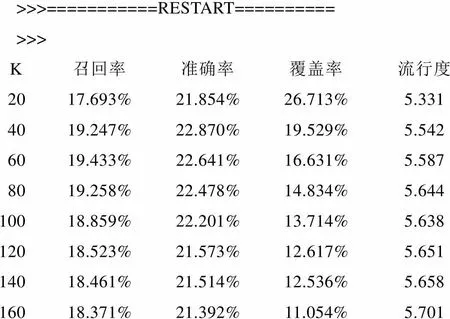
>>>===========RESTART========== >>> K召回率准确率覆盖率流行度 2017.693%21.854%26.713%5.331 4019.247%22.870%19.529%5.542 6019.433%22.641%16.631%5.587 8019.258%22.478%14.834%5.644 10018.859%22.201%13.714%5.638 12018.523%21.573%12.617%5.651 14018.461%21.514%12.536%5.658 16018.371%21.392%11.054%5.701
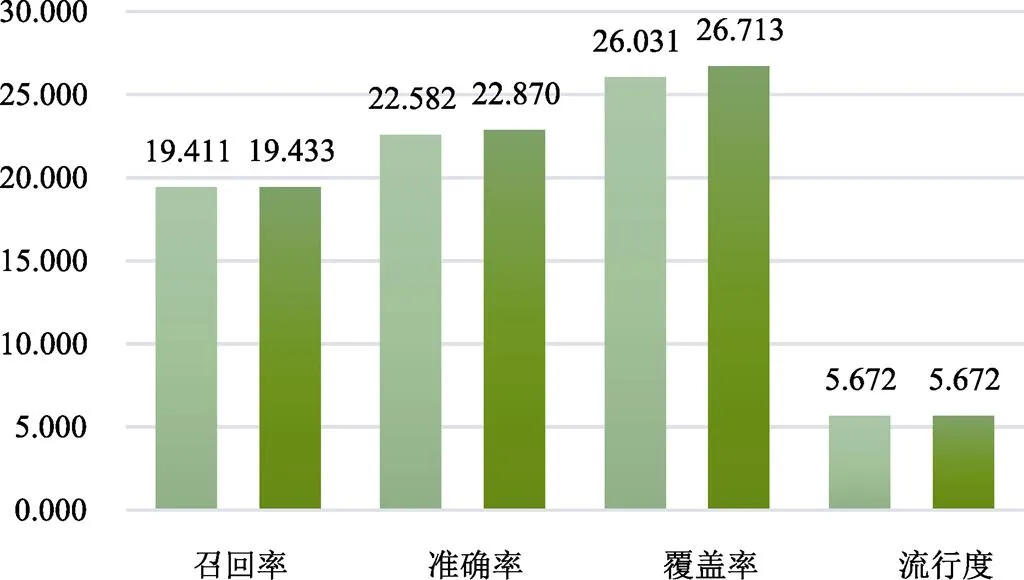
图5 采用用户相似度改进方法后与改进前的对比
4.4 Movielens100K与HetRec2011数据集对比
从图1与图5的结果可以发现:使用不同的数据集,推荐效果最优时对应K值不同,Movielens100K在K=50左右获得较好的推荐,而HetRec2011数据集在K=150左右获得较好的推荐效果。
从Het Rec 2011数据集的运行结果来看,相比Movielens100K数据集,召回率有所下降,但准确率有了较大的提高。如果希望推荐的内容数量越多越好,则是在追求高召回率;如果希望推荐的内容中,真正想要的越多越好,则是在追求高准确率。根据本文的实验结果,两者无法同时实现。但是在较大数据集上,基于用户的协同过滤推荐算法较为有优势.这是因为使用大数据集后,项目覆盖率降低,流行度增加,表明算法所推荐的项目随着数据集的增大,越来越接近热门项目。
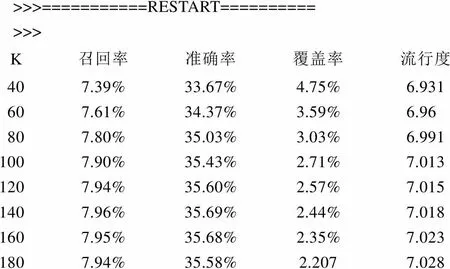
>>>===========RESTART========== >>> K召回率准确率覆盖率流行度 407.39%33.67%4.75%6.931 607.61%34.37%3.59%6.96 807.80%35.03%3.03%6.991 1007.90%35.43%2.71%7.013 1207.94%35.60%2.57%7.015 1407.96%35.69%2.44%7.018 1607.95%35.68%2.35%7.023 1807.94%35.58%2.2077.028
4.5 采用不同计算相似度结果的方法对比
本文采用Jaccard系数、欧式距离和Pearson系数计算用户的相似度,得出召回率、准确率,覆盖率和流行率四个指标的值,并将三种方法的结果与改进后的算法结果相对比,通过图7-图10的对比可以看出,改进后的算法在召回率、准确率,覆盖率方面比其他方法要高,但流行度较低。

图7 不同相似度计算方法对比-准确率
5 结论
本文给出了一种改进的协同过滤算法,通过引入“项目-用户”,只计算有相同评分项的用户间的相似度,相比传统计算方法,有效节约了运行时间。另一方面,利用“惩罚”用户的方法,避免了用户共同兴趣列表中,项目对用户相似度的影响,改进了用户相似度的计算,进而更好地实现推荐系统的个性化。最后,本文比较了在不同数据集下推荐算法的评价指标,分析了对算法质量的影响因素,以及产生影响的原因,并对比了不同计算相似度的方法,得出采用余弦相似度方法,获得的推荐结果的平均效果最好的结论。
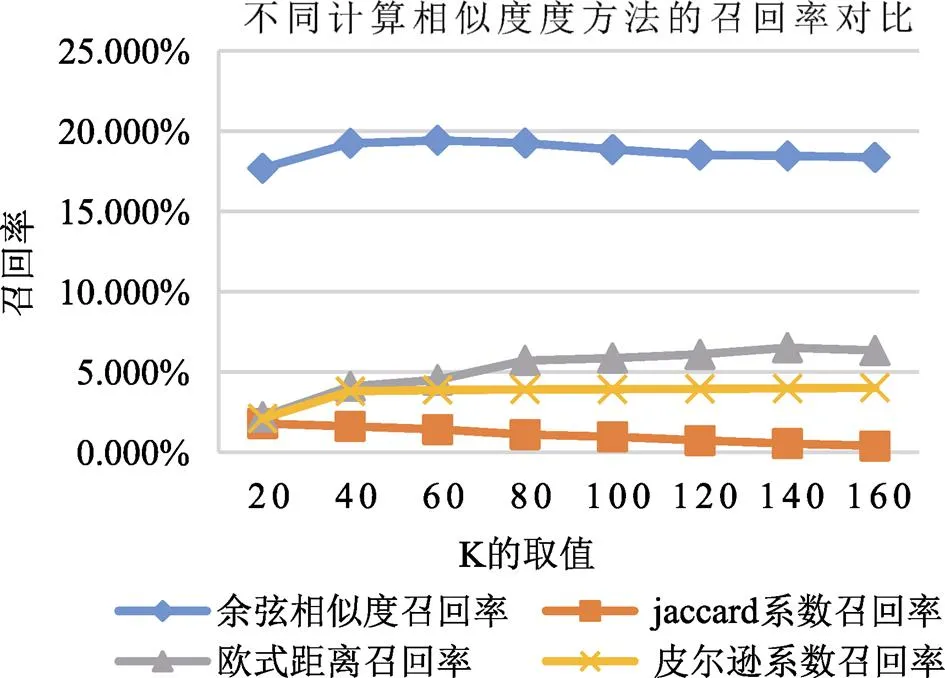
图8 不同相似度计算方法对比-召回率
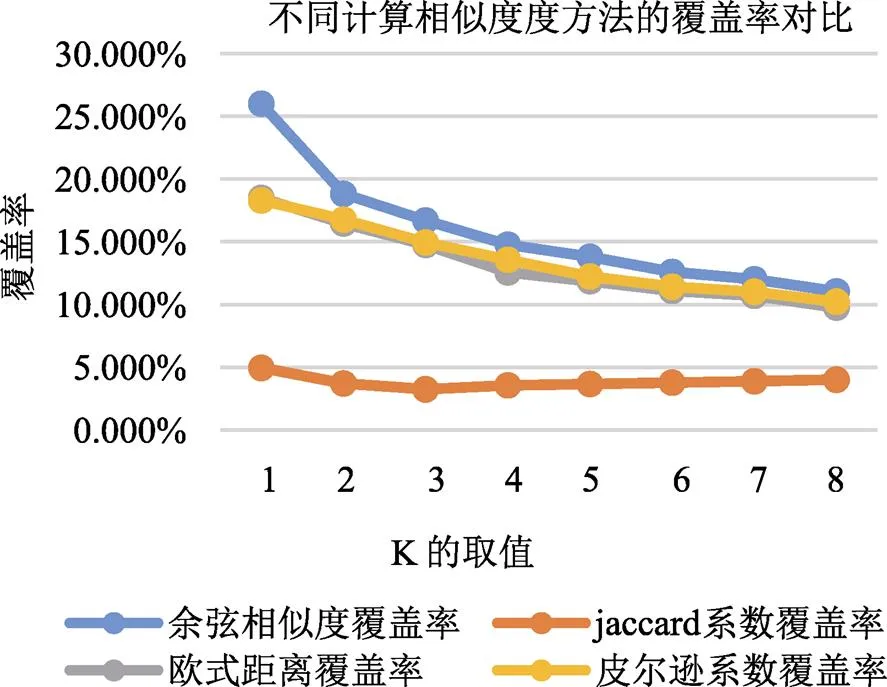
图9 不同相似度计算方法对比-覆盖率
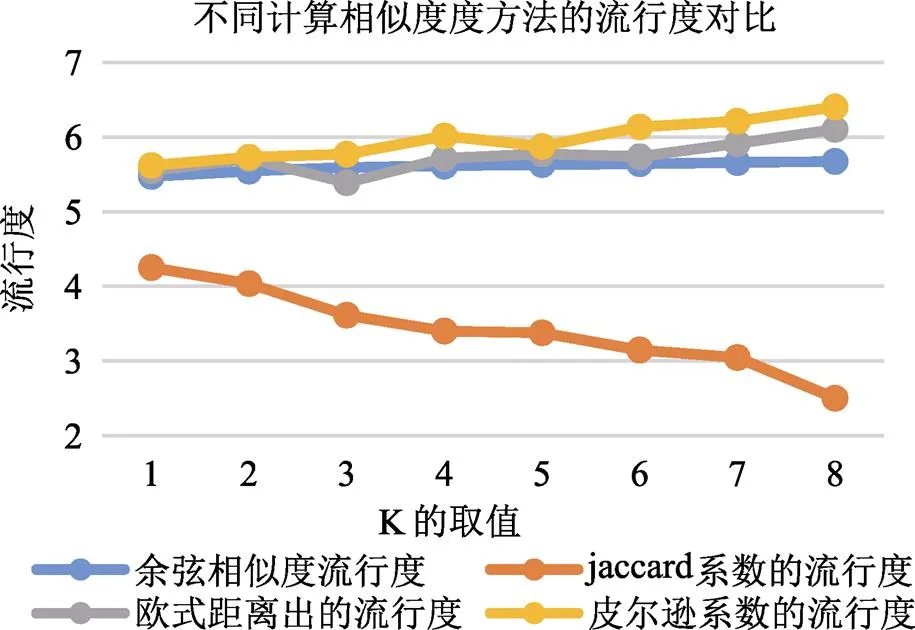
图10 不同相似度计算方法对比流行度
[1] Wen Wu, Liang He, Jing Yang. Evaluating recommender systems[C]. Digital Information Management (ICDIM), 2012 Seventh International Conference on, 2012: 56-61.
[2] John S Breese, David Heckerman, Carl Kadie. Empirical analysis of predictive algorithms for collaborative filtering[M]. Morgan Kaufmann Publishers, 1998.
[3] Zhang Jin. Collaborative filtering algorithm analysis and research in E-commerce recommendation system[D]. Beijing: Capital University of Economics and Business, 2012.
[4] Leng Ya-jun, Lu Qing, Liang Chang-yong. Survey of recommendation based on collaborative filtering[J]. Pattern Recognition and Artificial Intelligence, 2014, 27(8): 720-734.
[5] Shi Feng-xian, Chen En-hong. Combining the Items' discriminabilities on user interests for collaborative filtering[J]. Jounal of Chinese Computer Systems, 2012, 33(6): 1533- 1536.
[6] Yin Jian, Wang Zhi-sheng, Li Qi, et al. Personalized recommendation based on large-scale implicit feedback[J]. Journal of Software, 2014, 25(9): 1953-1966.
[7] Liu Jian-guo, Zhou Tao, Guo Qiang, et al. Overview of the evaluated algorithms for the personal recommendation systems[J]. Complex Systems and Complexity Science, 2009, 6(3): 1-10.
[8] Chen Nuo-yan. The design and implementation of recommadation system based on personalized recommendation engine combination[D]. Guangzhou: South China University of Technology, 2012.
[9] Liu Bei-lin. A study of personalized recommendation evaluation based on customer satisfaction in E-commerce[J]. Computer Science and Service System (CSSS), 2011 International Conference, 2011: 129-135.
[10] Zhang Jin-bo, Lin Zhi-qing, Xiao Bo, et al. An optimized itembased collaborative filtering recommendation algorithm[C]. Network Infrastructure and Digital Content, 2009, IC-NIDC 2009, IEEE International Conference on, 2009: 414-418.
Improvement and Research of User-based Collaborative Filtering Algorithm
SU Lin-yu1,2, CHEN Xue-bin1,2
(1. College of Science North China University of Science and Technology, 063000, China; 2. Province Key Laboratory for date science, He'bei 063000, China)
Aiming at data sparseness of matrix, low efficiency and precision of recommendation existing in traditional user-based collaborative filtering algorithm, an improvement recommendation algorithm is put forward in this paper. The algorithm introduces item-user inversion table and calculates users' similarity of whom with the same rating items in user-rating-data matrix. Therefore, it can reduce data sparseness of matrix and avoid huge workload, which is brought by the calculation of pair-wise users' similarity in traditional algorithm. Considering the impact of different hot degree of items in users' similarity calculation, the improvement algorithm punishes the negative influence of popular projects on users' common interest lists. Therefore, it gets around negative impact of popular projects in the results of personalized recommendation. The experiment results of 10-fold cross-validation in Movielens100K and Het Rec 2011open dataset shows that improved algorithm could save running time,increase efficiency and personalization of recommendation.
User-based collaborative filtering;Personalized recommendation;Similarity calculation; 10-fold cross-validation; Items—users inversion table
TP301.6
A
10.3969/j.issn.1003-6970.2017.04.024
本文著录格式:苏林宇,陈学斌. 基于用户的协同过滤算法的改进研究[J]. 软件,2017,38(4):127-132
