基于多标记ML—kNN算法的食用植物油检测研究
2017-06-01周海琴张红梅靳小波
周海琴 张红梅 靳小波


摘要:随着信息科学技术的发展,多种智能处理方法已凸显出自己的优势。食用植物油高效液相色谱法与支持向量机、AdaBoost.RMH、ML-LVQ算法相结合的食用油检测方法已有所应用。本文将甘油三酸脂组成成分指纹谱数据与多多标记ML-kNN算法相结合,用于食用植物油的分类识别与掺伪检验。首先进行甘油三酸脂组成成分指纹谱特征提取,然后构建多标号分类器,接着进行试验并评价其系统的性能。通过8种食用植物油及其混合油的测试结果表明,该算法能有效的应用于食用植物油的定性分类与定量分析。
关键词:多标记学习;ML-kNN算法;甘油三酸脂组成成分指纹谱;食用植物油脂鉴别
中图分类号:TPl81 文献标识码:A 文章编号:1009-3044(2017)08-0265-04
食用油脂不仅是人体生理代谢所需的能量和碳来源,也是必需脂肪酸、甾醇、维生素等营养素的来源。长期以来,学者们致力于食用油脂研究,并取得了大量的研究成果。而且,各种研究成果对指导农业种植、工业生产、合理膳食起到了积极的作用。但是,油脂作为重要的食品及食品原料,因产品质量与安全引发的一系列问题,对油脂品种鉴别和掺伪检验方法的要求越來越高。
从食用油脂品种鉴别和掺伪检验方法的相关文献报道来看,2004年之前,利用油脂品种特有成分或物性检测的方法较多。2004年以后,陆续有关于利用质谱、核磁共振谱、X-衍射等技术以及拉曼光谱、红外光谱、近红外光谱等光谱与化学计量学结合方法的报道。2008年以后,陆续有关于色谱分析方法与化学计量学结合方法的报道。其中,化学计量学方法主要有主成分分析法(PCA)、判别分析法(DA)、聚类分析法(CA)、SIMCA法、人工神经网络法以及常用来于定量分析的偏最小二乘法(PLS)、多元线性回归法(MLR)等。
近年来,多标号学习算法在文本分类、图像识别、蛋白质功能分类及食用油脂品种鉴别方面的应用已有报道。Qua-gong Huo,Xiao-Bo Jin and Hong-mei Zhand采用多标号Ada-Boost.RMH算法和带元标号分类器的改进多标号AdaBoost.RMH算法,对食用油脂的高效液相色谱指纹图信息进行处理,9种246份纯油脂样和124份混合样分类结果表明,该方法能有效地对食用植物油定性分析,还能有效地对其定量分析。陈景波采用多标号学习矢量化算法对食用油进行分类,也取得了理想的效果。
本文将多标号学习ML-kNN算法应用于食用植物油检测中,ML-kNN算法将贝叶斯定理与kNN算法相结合构建分类器,通过最大化后验概率(MAP)的方式推理未见事例的标记集合。最终的分类器是T个弱分类器的加权平均。每一次迭代,都要对权重进行更新,更新的规则是:根据分类效果减小弱分类器分类效果较好的数据的权值,增大弱分类器分类效果较差的数据的权值,能简单而有效的应用于多标签分类问题。与AdaBoost.RMH方法相比,具有错误率低且方法简单的特点。
1实验材料与方法
1.1食用植物油脂样品
大豆油35份、菜籽油59份、花生油39份、芝麻油37份、棉籽油16份、玉米油20份、葵花籽油32份、棕榈油27份。花生/大豆混合油9份、花生/葵花混合油9花生/玉米混合油2份、花生/棕榈混合油9份、芝麻/花生混合油20份、大豆/玉米混合油3份、大豆/葵花混合油3份、大豆/棕榈混合油8份、芝麻/大豆混合油21份、芝麻/葵花混合油21份、芝麻/菜籽混合油9份、芝麻/棕榈混合油9份。
1.2高效液相色谱分离方法
C18色谱柱;乙腈-二氯甲烷流动相,流速1ml/min,梯度洗脱;蒸发光散射检测器,漂移管温度70℃,氮气流量0.71/min;色谱数据处理方法面积归一法。
1.3多标记算法
1.3.1多标记学习结构
Adaboost是一种迭代算法,其核心思想是针对同一个训练集训练不同的分类器(弱分类器),然后把这些弱分类器集合起来,构成一个更强的最终分类器(强分类器)。其算法本身是通过改变数据分布来实现的,它根据每次训练集之中每个样本的分类是否正确,以及上次的总体分类的准确率,来确定每个样本的权值。将修改过权值的新数据集送给下层分类器进行训练,最后将每次训练得到的分类器最后融合起来,作为最后的决策分类器。使用adaboost分类器可以排除一些不必要的训练数据特徵,并将关键放在关键的训练数据上面。
该算法其实是一个简单的弱分类算法提升过程,这个过程通过不断的训练,可以提高对数据的分类能力。整个过程如下所示:
1)先通过对N个训练样本的学习得到第一个弱分类器;
2)将分错的样本加权后和新数据一起构成一个新的N个的训练样本,通过对这个样本的学习得到第二个弱分类器;
3)将第二个弱分类器都分错了的样本加上其他的新样本构成另一个新的N个的训练样本,通过对这个样本的学习得到第三个弱分类器,依次类推;
4)使用加权的投票机制代替平均投票机制,将弱分类器联合起来,让分类效果好的弱分类器具有较大的权重,而分类效果差的分类器具有较小的权重。即某个数据被分为哪一类要通过T个弱分类器多数表决,最终经过提升的强分类器。
1.3.2评价准则
多标记学习问题中,评价指标可分为两种类型,即基于样本的评价指标和基于类别的评价指标,对分类问题来说采用基于样本的评价指标较合适,对于检索问题来说采用基于类别的评价指标较合适。故本文采用基于样本的五个指标如下:
(1)Hammingloss:该指标旨在考察样本在单个标记上的误判率,其值越小则该分类器性能越优,最优值为hlosss(h)=0。
(2)One-error:该评价指标旨考察在训练样本类别标记序列中,排在最前端的类别标记不属于相关标记集合的情况。其值越小则该分类器性能越优,最优值为one-errors(h)=0。
(3)Coverage:该评价指标旨在考察覆盖所有在样本类别标记排序过程中的搜索深度的情况。其值越小则该分类器性能越优,最优值为。
(4)Ranking loss:该评价指标旨在考察在样本类别标记排序序列中出现排序错误的情况,即无关标记排在相关标记之前的情况。其值越小则该分类器性能越优,最优值为rlosss(h)=0。
(5)Averageprecision:该评价指标旨在考察训练样本的类别序列中,排在相关标记前的标记也是相关标记的情况。其值越小则该分类器性能越优,最优值为avgprecs(h)=1。
1.3.3多标记ML-KNN算法
其中x、y为训练样本集和类别标记集,T为循环次数,
2结果与讨论
2.1甘油三酸脂组成成分指纹谱处理方法
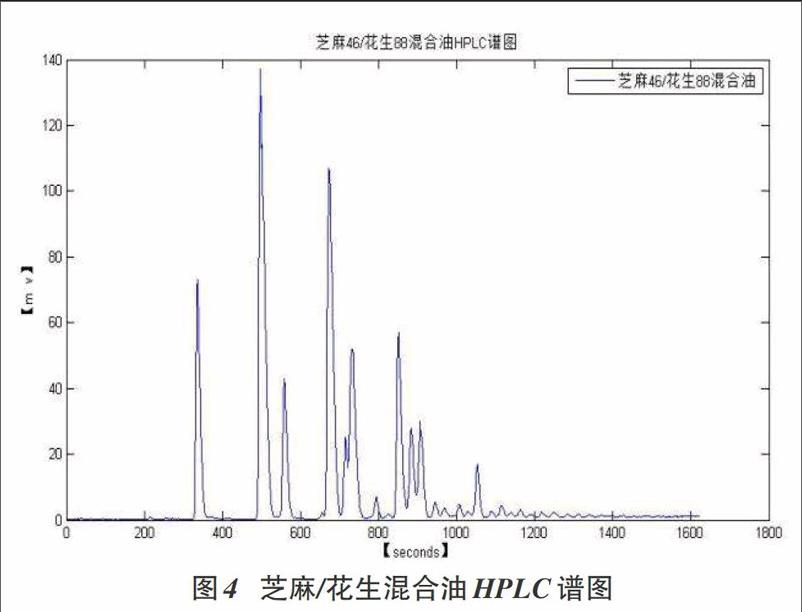
按照高效液相色谱分离方法,采集各类油脂样品的甘油三酸脂组成成分指纹谱,结果如图1、2、3、4所示。由于油脂的甘油三酸脂成分非常复杂,而高效液相色谱的分离效能有限,甘油三酸脂成分的同分异构体达不到完全分离,甚至达不到基本分离。为了保证不同样品指纹谱中特征峰保留时间的稳定性,比较各种油脂样品的HPLC谱图,确定甘油三酸脂色谱峰定性窗口为1%。甘油三酸脂成分含量计算方法为峰面積归一法。
2.2实验和结果
本文的实验是基于Motlab实现的,随机抽取实验样本中的2/3(即纯油样本数目为171、混合油样本数目82)作为训练样本,剩余的作为测试样本。下表1以检测花生油掺混有大豆油为例,其混合大豆油百分比不同其检测率稍有差别。
本实验k的选择是通过在训练集上采用2折交叉检验法,所得最优值k=15,迭代次数T取50时,对数据集运行10次,取其平均值各评价准则如表2所示。
表2的实验数据表明,ML-kNN算法与AdaBoost.RMH算法相比较,有四个指标优于后者只有覆盖所有在样本类别标记排序过程中的搜索深度不如AdaBoost.RMH算法好;Hammingloss是样本在单个标记上的误判率,ML-kNN算法分类识别准确率为纯油98.90%、二元91.58%,能有效的应用于食用植物油的定性分类与定量分析;运行时间比AdaBoost.RMH节约了近1/3。
3结论
针对当今社会存在的调和油成分检测困难、地沟油滥用、油脂掺伪以及食用油质量监督管理问题,本文采用多标记ML-kNN算法用于食用植物油分类识别与掺伪检验,该方法是结合食用油的甘油三酸脂的高效液相指纹谱信息分类识别准确率为(纯油98.90%、二元91.58%),可以在快速地进行有效检测,与市场监管需求相契合。本文是首次将多标记ML-kNN算法应用于食用油检测中,其对二元检测精准度还有待提高,算法运行时间复杂度还有待降低,下一步工作着重于对系统的进一步优化和应用于对多元的鉴别。
