基于创业者信息挖掘的创业成功倾向分析
2017-06-01黄燕黄慧颖汪瑞嵘丁志刚
黄燕, 黄慧颖, 汪瑞嵘, 丁志刚
(上海计算机软件技术开发中心,上海 201112)
基于创业者信息挖掘的创业成功倾向分析
黄燕1, 黄慧颖2, 汪瑞嵘3, 丁志刚4
(上海计算机软件技术开发中心,上海 201112)
在创新创业大环境下,为了帮助创业服务机构更准确地识别具有成功倾向的创业项目,探讨了用数据挖掘这种自动化方法对创业者的信息进行分析,从而提供指导与建议。对Apriori算法和ID3决策树算法进行研究,并根据创业成功预测这一特殊目标,对Aprior算法进行了改进,提出了一种创业成功倾向预测分析模型,为对创业者进行客观的、可定量信息评估提供了依据。
创业成功; 挖掘; Apriori; 决策树
0 引言
近年来,随着全面深化改革、继续扩大开放和创新驱动发展战略的实施,我国迎来了世界科技创新格局调整时期,在960万平方公里土地上掀起了“大众创业”、“万众创新”的新浪潮。在这创新创业大环境下,一批类似创客空间、创业咖啡、创新工场等形式的创新创业服务载体应运而生,旨在通过提供环境支持、技术支撑、政策引导、资源对接等方面的服务,助力创业者成功创业。但面对各种需求不同、层次不齐的创业者,如何挖掘有潜力的、可能成功的创业者,成为创业服务机构十分关注的问题。
对于创业扶持和投资对象的选择,国内外都有不同的选择模式。美国爱荷华大学学生创业孵化器主要通过挖掘学校实验室的技术发明创新,配合概念试验和市场情报分析技术的可行性和市场成功潜力,以此选拔扶持的创业企业[1]。硅谷主要依靠斯坦福大学提供了智力、技术和人才诸多方面的强大支撑,尤其是全美首屈一指的斯坦福电子工程专业[2]。在国内,有的创业投资机构通过考察项目的成长性、技术含量、管理层的综合素质等因素,选择创业项目进行投资[3];有的通过创业大赛选拔优秀的创业项目;有的主要考评创业者的智力资本和未来价值[4]。以上这些机构,主要凭借自身经验以及对行业的预判进行创业项目挑选,是一种基于主观意念的评估方式,而本文将对创业者本身的信息进行定量分析,以此作为创业项目主观评估的补充。文章将基于应用场景对Apriori算法进行改进,并结合ID3决策树算法,对创业者样本信息进行关联分析和决策树构建,分析具有哪些特质的创业者容易创业成功或创业失败。
1 创业成功倾向预测流程及相关算法
1.1 整体流程
本文以某创业者公共实训基地采集的入驻创业者信息为样本,经过对数据进行筛选、清洗、转化等预处理,通过属性与创业结果的关联规则分析,建立决策树预测模型,为新的创业者创业成功概率分析提供参考依据,整个流程如图1所示。
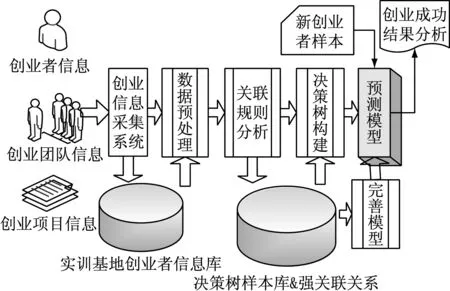
图1 创业者成功倾向预测流程图
由图1可见,首先数据来源于基地入驻的创业者个人信息、创业团队信息以及创业的项目信息,通过创业信息采集系统进行数据搜集。由于搜集获得的数据存在干扰项、信息缺失、属性取值连续等问题,需要经过清理、整合、转化等预处理才能进行进一步的分析。预处理后的数据需要进行2个分析步骤:第一步是基于Apriori算法的关联规则分析,通过关联规则分析提取与创业成功与否之间存在强关联关系的属性,同时能对数据进行进一步的筛选,以提高模型构建的准确性;第二步是根据分析得到的关联关系以及样本库构建决策树,得到的决策树即是预测模型。对于新的创业者信息可以通过预测模型迅速得到创业成功与否的判断,作为指导建议。当然预测模型的优劣与否取决于样本的质量,在数据量较小的时候,产生的结果会有偏差,需要在建立后不断用新的可信的样本数据进行调整完善,以获得更准确的结果。
1.2 数据采集
在数据采集中,首先结合实训基地创业者入驻流程、服务模式以及调查跟踪频度,搭建系统进行创业者创业数据采集,从入驻、信息变更、注册企业、成长调查、退出等阶段收集各入驻企业/团队负责人、团队转化企业、企业成长发展以及退出等方面信息,经分析与创业成功有关的信息,如表1所示。
表1数据分别为创业者在入驻基地时和入驻后不同阶段采集获得,上表只是通过归纳将数据内容合并在一起。
1.3 数据预处理
通过采集系统获得了数据样本,但是采集到的数据往往存在不完整、冗余、离散值等问题,无法直接用于数据挖掘和分析,因此需要对数据进行预处理,以提高后期挖掘和分析的效率和准确度,预处理方式包括以下几种:
(1) 数据清理
在数据采集时,为了减少用户主观填写造成的不一致,尽可能采用选择题的方式让用户填写,但收集的数据仍然存在部分属性值缺失的现象。数据清理的目的是删除出现多处空属性的数据。由于空值对关联分析无意义,且分析是基于一定的存在潜在规律的样本进行规律挖掘,部分数据的删除不会影响分析结果,因此清理时删除属性缺失3个及以上的记录,缺失少于属性的记录予以完善补充。

表1 创业成功相关主要属性
(2) 数据整合
被分析数据往往存在不同数据表中,为了防止分析过程中频繁跨表分析造成运算效率降低以及复杂度增大,将要分析的目标数据通过视图方式从不同数据表中抽取整合。整合不仅能有效去除冗余内容还能在整合的同时完成数据的清理和转化。
(3) 数据转化
数据转化的过程主要是将连续的数据转化成离散的数据,字符串形式转化成有限的离散型的数值。如表1中的负责人年龄属性,取值为正整数,统计时数据值较分散无法形成有效分析,因此需要进行转化。同时创业者一般年龄都分布在20-60岁之间,年龄值可转化成20-30岁、30-40岁、40-50岁、50-60岁、其他5种取值范围,并用0、1、2、3、4四种数值进行表示,大大简化了连续型数据带来的复杂度。数据转化可以在数据整合的同时进行,除了将连续型的数据进行转化,还包括将字符型的离散型的数据转化成对应的整形数字。
(4) 增加创业结果判断属性
数据采集时,记录了创业者的基本信息以及发展情况,但是对于判断哪些属于创业成功的创业者并未明示。因此,在数据预处理时,需要对创业成功者进行预定义,并增加字段进行标识。根据数据源内容以及公共实训基地服务入驻创业者周期为3月-1年的特点,通过创业团队转化企业情况、营业额、带动就业效应、知识产权产生情况等方面综合评定,评定标准,如表2所示。

表2 创业成功评分标准
表2为对所有信息库中的创业者进行评分的标准,60分及以上标识为成功创业者,否则为失败。此定义规则可根据最后输出结果、创新发展情况及成功创业者特性进行调整与不断完善。
1.4 基于Apriori算法的关联规则挖掘
对创业成功因素建模,首先需要分析创业者身上各种特质与创业成功的联系,诚然通过预处理后的数据可以得到创业者信息与创业成功之间的联系,并通过决策树建立创业成功的模型,但预处理后的数据属性过多,且含有很多低概率出现的数据,因此我们采用关联规则挖掘算法,过滤那些先关性较低的属性和相关性小的样本,以增加决策树建立的可信性。
Apriori算法是最成熟、最具有影响力的关联规则挖掘算法之一,其挖掘过程一般包括两个阶段[5],第一阶段为从信息库中找出所有频繁项集,即支持度不低于预定义阈值的所有项集;第二阶段则利用频繁项集找出强关联规则,即满足既定置信度的频繁项的关联关系。它利用频繁集的子集一定是频繁集,非频繁集的超集必定不是频繁集这一原理,通过迭代方式获得所有频繁集。
Apriori算法由频繁k-1项集进行自连接生成的候选频繁k项集数量巨大,且在验证候选频繁k项集的时候需要对整个数据库进行扫描[6],鉴于本文使用关联规则分析并非找出创业者信息库中的所有频繁集和强关联关系,只需找出和是否创业成功之间的关系,因此对Apriori进行如下改进:
(1) 开始于寻找含有创业结果的2-项频繁集
由于本次关联规则查询的目的是为了查找各条件与创业结果之间的关联,因此频繁集中必然包含创业结果这一项,所以1-频繁集的查找无任何意义。同时查找的2-项候选集必定含有创业结果一项,因此搜索时只需将创业结果项与其他各进行连接,获得2-项频繁项集。
(2) 及时删除不含有频繁项的事务
由于非频繁项的超级必定为非频繁项,因此如果某个事务,在扫描过程中发现不含有任何频繁项,可以将其删除,不再进行下一次扫描。
根据本文所求关联规则的特殊性,对Apriori算法进行了改进,其流程,如图2所示。

图2 基于Apriori的关联规则分析流程图
算法描述:
(1) 扫描样本数据库,将创业结果与各项连接,寻找搜有2-项候选项;
(2) 根据设定的最小支持度,删除非频繁项,得到2-项频繁集;
(3) 判断频繁项集,为空,则结束;若不为空,则生成;
(4) 通过K-1项的连接,生成K项候选项(初始K=3);
(5) 如果K项候选项的某项是非频繁项的超集,则删除;
(6) 计算所有候选项的支持度和置信度,删除非频繁项,以及不含有频繁项的事务;
(7)K+1,返回3),将6)生成的频繁集作为基础频繁集,生成新的频繁集。
通过此算法,可以找到与创业成功与否存在强关联的属性,以作为后续决策树构建的主要分支。
1.5 ID3决策树算法
决策树着眼于从一组无规则、无次序的实例中推理出决策树表示形式的分类规则[7],并根据此规则判断未知类别数据所属类别,以此达到预测的目的[8]。ID3算法,是最经典的决策树挖掘算法[9],构造决策树的关键在于分裂属性,即在某个节点按照属性的不同取值进行分支。在构造时,需要选择尽可能“纯”的属性进行分裂,即让分裂后在同一区域的数据尽可能得到相同的结果[10]。ID3算法将信息熵(entropy)和信息增益(information gain)作为选择分裂属性的标准。
假设S为用类别对样本库进行的划分,则S的熵表示,如式(1)。
(1)
其中Pi表示S中第i个取值出现的概率,它表示为S中各取值的平均信息量。
假设S样本库用属性A进行划分,则A对S划分的期望信息,为式(2)。
(2)
其中|S|是S中元素的个数,|Sj|是样本S中是属性A取值j时的个数,Entropy(Sj)为属性A取值j时的条件熵。
属性A在样本S上的信息增益,为式(3)。
Gain(A)=Entropy(S)-EntropyA(S)
(3)
在决策树构造过程中,树根从Gain(A)值最高的属性开始分裂,如果对应分支得到的结果纯度很高,则不继续分裂,对应的高纯度的结果为叶子节点;如果无法得到纯度高的结果,则继续按照信息增益高的属性进行分裂,直至无属性分裂,选择相对取值多的结果作为叶子节点。在使用决策树预测新样本时,从树的根节点开始按照样本的值选择分支,直至到叶子节点,得到最终结果。
2 创业成功倾向预测分析应用
基于对创业成功预测模型搭建的流程介绍以及相关算法的分析,本文选取了100个的经数据预处理的创业者样本,对负责人年龄、学历、创业经历、专业类别、性别、是否海归这六个类别进行分析建模。我们以按照Apriori算法进行关联规则分析,设定最小支持度为2%,最小置信度为50%,得到的部分2项频繁集和3箱频繁集的置信度,如表3所示。
在A→B时,置信度表示A发生时B发生的概率,计算方式,如式(4)。
Support(A→B)=P(AB)/P(A)
(4)
提升度表示A与B是否正向相关,计算方式见式(5)
Lift(A,B)=Support(A→B)/P(B)
(5)
当置信度越大,表示A发生时B发生的概率越大;提升度>1且值越大时,表示A和B的之间的正向相关性越强,彼此的关联关系也越强。根据上述理论,得到了学历、年龄、创业经历、专业类别、海归&工科这5个属性与创业成功与否关系最强烈,我们将根据这几个属性构建决策树。
按照决策树信息熵的定义,42人创业成功,58人失败的创业结果的信息熵结果,如式(6)。
(6)
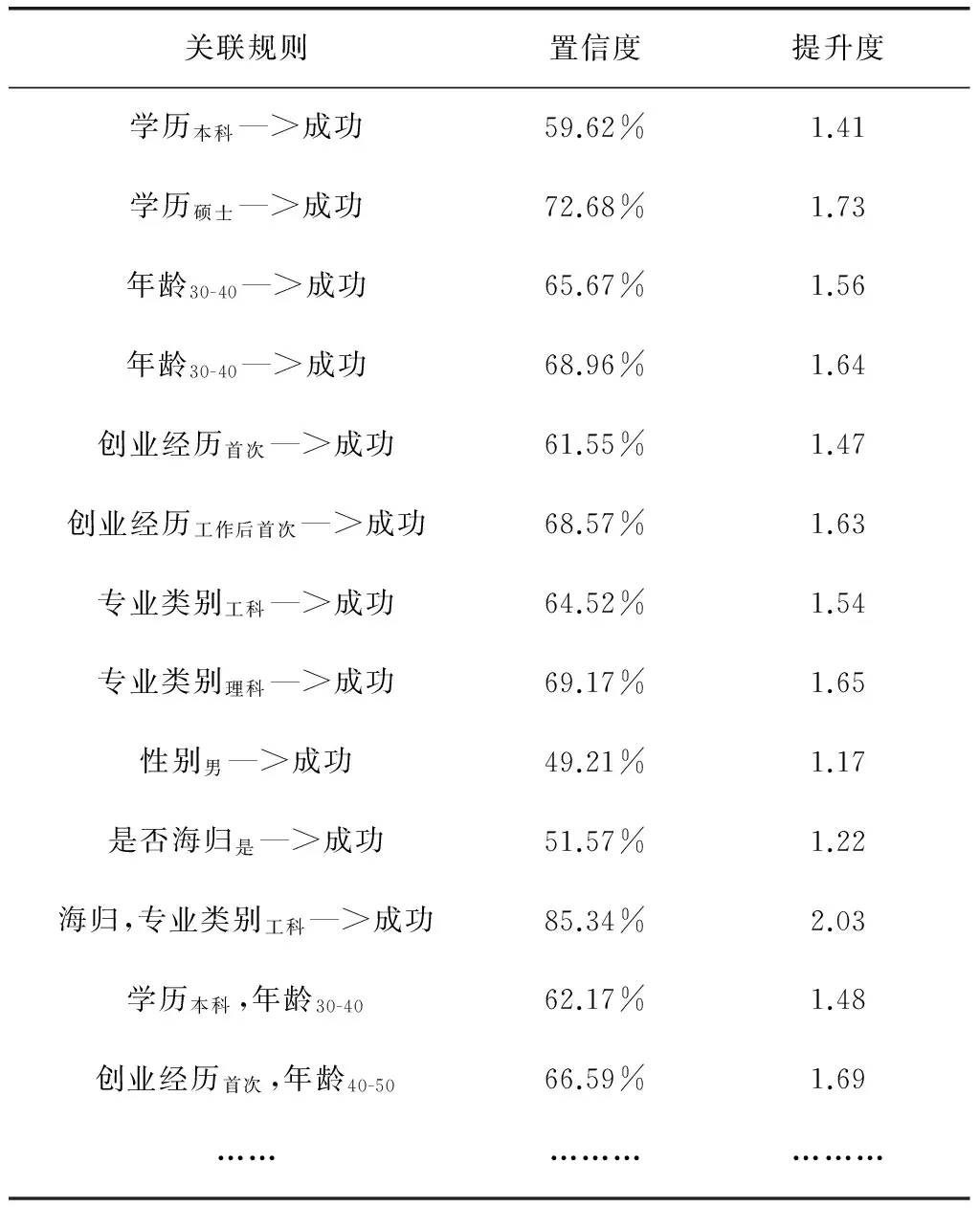
表3 2项、3项部分频繁集置信度和提升度
各关键属性的条件熵结果,为式(7)~式(11)。


(7)

(8)


(9)


(10)

(11)
按照信息增益理论,“学历”为决策树的根节点。以学历中三个与创业成功与否强关联的三个取值“20—30岁”、“30—40岁”、“其他”作为新的树分裂的划分准则,并计算信息熵、条件熵以及信息增益以得到其子结点,直至到叶子结点。按此方法逐级构造,如图3所示。
图3是基于样本库以及负责人年龄、学历、创业经历、专业类别、性别、是否海归这些属性对创业者成功与否预测构建的决策树,新的创业者样本可以根据此树进行成功创业与否的判断。当然本文只列举了一小部分考量的成功相关因素,实际考虑的因素更多,如是否已经享受投融资、创业的领域方向、创业团队的其他人员情况等等,将形成一个更复杂更庞大的决策分析树。
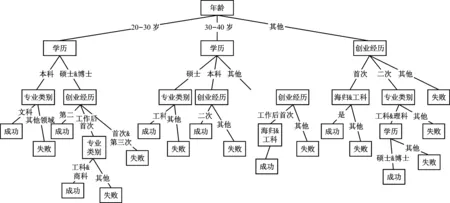
图3 创业成功倾向判断决策树
3 总结
在双创大趋势下,众多创业服务机构希望通过他们的扶持,帮助创业者成功创业。文本对数据挖掘方法中的关联规则算法与决策树算法进行了研究,并将两种算法结合构建了创业成功倾向预测模型,应用于创业服务机构在对创业者不熟悉情况下的考察分析中,通过科学、客观的方式和机器学习分析的手段为决策者决策时提供了参考依据。
当然,对创业者是否成功创业的预测,还与创业项目的可行性、市场前景,创业主要负责人的领导能力、表达能力、决策能力,创业团队主要成员的工作能力等需要主观评判的因素有关,本文只是对与创业者相关的客观因素进行了模型搭建,如何更好地结合主观因素以及外界环境因素,建立更完善的模型是今后研究的方向。
[1] 侯典牧,郑云.美国大学生技术创业典型模式探析 [J].经济视角,2013(12):122-125.
[2] 李向辉,李艳茹.美国硅谷科技创业经验研究 [J].江苏科技信息,2014(2):11-13.
[3] 杨春华,熊勤竹,莫琼玉,周威.李保婵创业投资项目评估相关问题研究 [J].合作经济与科技,2015(3):66-67.
[4] 汪志华,尹国俊.创业投资项目决策模型文献综述 [J]. 商场现代化,2014(25):111-112.
[5] 朱惠.关联规则中Apriori算法的研究与改进[D].合肥:安徽理工大学,2014.
[6] 丁丽.基于Apriori 算法的用户行为数据挖掘研究[J].科技通报,2013,29(12):214-215.
[7] 潘永丽.决策树分类算法的改进及其应用研究[D].昆明:云南财经大学,2012.
[8] 黄宇达,范太华.决策树ID3算法的分析与优化[J] .计算机工程与设计,2012,33(8):3088-3092.
[9] 李瑞,许旭睿.决策树ID3算法的分析与优化[J].大连交通大学学报,2015(2):91-95.
[10] 瞿花斌.数据挖掘的决策树技术在高校毕业生管理中的应用[D].济南:山东大学,2014.
Analysis of Entrepreneurial Success Tendency Based on Entrepreneur's Information Mining
Huang Yan, Huang Huiying, Wang Ruirong, Ding Zhigang
(Shanghai Development Center of Computer Software Technology, Shanghai 201112, China)
Under the environment of innovation and entrepreneurship, in order to help the entrepreneurial service institutions more accurately identify the entrepreneurial projects with success tendency, this article discusses the method of using data mining to analyze the information of entrepreneurs to provide guidance and advice. After researching the Apriori algorithm and ID3 decision tree algorithm, we improve the Apriori algorithm based on the specific objective of entrepreneurial success prediction, and propose an entrepreneurial success tendency analysis prediction model, and it provides a base for an objective and quantitative information evaluation for entrepreneurs.
Entrepreneurial success; Mining; Apriori; Tree prediction
上海大数据科技成果转化平台(16DZ1110101)
黄 燕(1982-),女,上海计算机软件技术开发中心,工程师,硕士,研究方向:大数据。 黄慧颖(1983-),女,上海计算机软件技术开发中心,工程师,学士,研究方向:科研管理。 汪瑞嵘(1980-),女,上海计算机软件技术开发中心,工程师,硕士,研究方向:大数据。 丁志刚(1962-),男,上海计算机软件技术开发中心,研究员,学士,研究方向:计算机应用。
1007-757X(2017)05-0008-05
TP311
A
2016.12.01)
