最近最远得分的聚类性能评价指标
2017-06-01冯柳伟常冬霞邓勇赵耀
冯柳伟,常冬霞,邓勇,赵耀
(1. 北京交通大学 信息科学研究所,北京 100044;2. 北京交通大学 计算机与信息科学学院,北京 100044; 3.中国科学院 软件研究所,北京 100190)
最近最远得分的聚类性能评价指标
冯柳伟,常冬霞,邓勇,赵耀
(1. 北京交通大学 信息科学研究所,北京 100044;2. 北京交通大学 计算机与信息科学学院,北京 100044; 3.中国科学院 软件研究所,北京 100190)
聚类算法是数据分析中广泛使用的方法之一,而类别数往往是决定聚类算法性能的关键。目前,大部分聚类算法需要预先给定类别数,在很多情况下,很难根据数据集的先验知识获得有效的类别数。因此,为了获得数据集的类别数,本文基于最近邻一致性和最远邻相异性的准则,提出了一种最近最远得分评价指标,并在此基础上提出了一种自动确定类别数的聚类算法。实验结果证明了所提评价指标在确定类别数时的有效性和可行性。
最近邻一致性;最远邻相异性;K-means聚类算法;评分机制;评价指标;层次聚类
聚类算法作为数据分析中广泛使用的主要方法之一,已经广泛应用于模式识别、机器学习、图像处理和数据挖掘等方面[1-4]。简单来说,聚类就是根据数据的特征将数据划分为几类,使得同一类别数据间的相似度尽可能大,而不同类别数据间的相似度则尽可能小。目前,常用聚类算法可以分为划分法、层次法、基于密度的方法、基于网格的方法和基于模型的方法。事实上,很多聚类算法往往需要预先知道聚类问题的类别数。然而,在很多实际情况下,很难根据数据特征获得有效的类别数。因此,为了获得有效的类别数,很多学者基于聚类的不同性质分别提出了一系列评价聚类结果的评价指标。对给定范围的类别数依次对数据集进行聚类,并采用评价指标对每次的聚类结果进行评价,然后选择一个使评价指标最优的类别数。目前,常用有效性评价指标大致可以分为3种类型,分别是基于数据集模糊划分的指标、基于数据集样本几何结构的指标和基于数据集统计信息的指标。其中,1991年,Xie等[5]利用模糊聚类的目标函数,同时考虑数据集本身的结构和模糊隶属度的性质,提出了Xie-Beni指标。之后,很多学者基于数据集模糊划分提出了一系列改善的评价指标[6-9],但这些指标不适合对硬聚类算法的聚类结果进行评价。另外一类是基于数据集样本几何结构的评价指标[10-16]。1974年,Caliński 和 Harabasz提出了基于全部样本的类内离差矩阵和类间离差矩阵测度的 Caliński-Harabasz(CH)指标[12]。1979年,Davies和 Bouldin提出了基于样本的类内散度与各聚类中心间距离测度的 Davies-Bouldin(DB)指标[13],以及随后提出的基于最大化类内相似度和最小化类间相似度目标的Weighted inter-intra(Wint)指标[14]、基于样本类内离差矩阵的Krzanowski-Lai(KL)指标[15]、周世兵等提出的基于样本间的最小类间距离与类内距离的Between-Within Proportion(BWP)指标[16]。但是这些评价指标均具有一定的局限性,对数据结构无法完全分离的数据集进行评价得到的结果并不理想。2007年,Kapp等基于数据集统计的思想,使用类内数据点的in-group比例来评价聚类结果,提出了In-Group Proportion(IGP)评价指标[17]。该评价指标使用样本与其最近邻样本划分到同一类的比例来衡量聚类结果的质量。但是由于IGP只关注最近邻一致性,使得IGP指标值会随着聚类数的增加而减少,导致在很多实际情况下,利用IGP指标得到的类别数往往比实际的类别数小。针对这种情况,本文基于最近邻一致性和最远邻相异性的原则,提出了一种最近最远得分指标(NFS),并基于此指标,提出了一种基于NFS指标自动确定类别数的聚类算法。实验结果验证了本文所提的评价指标的有效性和可行性。
1 已有评价指标
众所周知,很多聚类算法需要用户根据先验知识给出算法所需要的类别数。但是,在很多实际应用中很难获得有效的先验知识,因此,确定聚类问题的类别数成为了聚类分析的一个研究的热点。目前传统的确定类别数的方法是根据评价指标来确定类别数。至今提出的评价指标包括CH指标、BWP指标和IGP指标等。
1.1 Calinski-Harabasz(CH)指标
CH指标是Caliński和Harabasz提出的确定最佳聚类数的评价指标[12]。该指标是一种基于样本的类内距离和类间离差矩阵的测度,其判断函数为
式中:n为数据集样本数,K为类别数。且
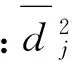
CH指标值越大表示聚类结果的类内距离越小而类间距离越大,聚类结果性能越好。但是随着类别数搜索范围的变化,CH指标得到的最佳聚类数会发生变化,并且随着搜索范围增大,CH指标得到的最佳聚类数有逐渐增大的趋势[18]。
1.2 BWP指标
BWP指标是周世兵等人提出的一种基于样本的几何结构设计的确定聚类类别数的评价指标[16],该指标利用聚类结果的类内紧密性和类间分离性来衡量聚类结果。指标的最大值对应的类数作为聚类数。该指标的判断函数为
式中:K是类别数,bwp(i,j)为
式中:b(i,j)是第j类中的第i个样本到其他每类中样本平均距离的最小值,称为最小类间距;w(i,j)是第j类中的第i个样本的类内距离。且
BWP指标值越大则表示聚类结果的类内越紧密而类间越远离,聚类结果性能越好。但是该评价指标不适合非完全分离的数据集。
1.3 IGP指标
IGP指标是Kapp提出的评价指标[17]。此指标的设计思想是:当对新的样本进行分类时,新样本应该被划分到与其最相似的样本所在类别。因此该指标使用样本与其最近邻样本划分到同一类的比例来衡量聚类结果的质量。该指标的评价函数为
式中:K是类别数;igp(u,X)表示数据集X中的第u类的指标值,且

IGP指标的值越大表示样本和其最近邻划分到同一类的概率越高,聚类结果越好。但是IGP指标只关注了最近邻一致性,使得IGP指标值不适合判断非完全分离的数据集。
2 最近最远得分评价指标
为了能准确地得到聚类问题的类别数,本文在基于最近邻一致性和最远邻相异性的原则上,提出了最近最远得分(nearest and furthest score,NFS)评价指标。
2.1 相关概念定义
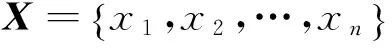
定义1 最近得分。定义ns(i)是第i个样本的最近得分,第j个样本是距离其最近的样本,若样本i与样本j属于同一类别,则第i个样本的最近得分值为1;否则其最近得分值为-1,即
式中:sc(i)代表第i个样本所属的类别,sc(j)代表距离样本i最近的样本j所属的类别。
定义2 最远得分。定义fs(i)是第i个样本的最远得分,第l个样本是距离其最远的样本,若样本i与样本l属于不同类别,则第i个样本的最远得分值为1,否则其最远得分值-1,即
式中:sc(i)代表第i个样本所属的类别;sc(l)代表距离样本i最远的样本l所属的类别。
定义3 样本得分。定义s(i)是第i个样本的得分值,则第i个样本的最近得分和最远得分的平均值为第i个样本的得分,即
定义4 每类的得分。定义cs(j)为第j类的得分,其定义为属于第j类的所有样本的得分的平均值,即
式中nj为第j类中的样本总数。
定义5 NFS。定义nfs(K)为在类别数为K下聚类结果的最近最远得分,定义为所有类得分的平均值,即
式中K是类别数。
2.2 NFS指标的分析
NFS指标的设计原则是每个样本应该和距离其最近的样本划分到同一类别中,而与距离其最远的样本划分到不同类别中。因此,每个样本拥有两个影响评分的因子,分别是最近得分因子和最远得分因子。对于最近得分因子,如果某个样本与距离其最近的样本划分到同一类中,则得1分,表示对此聚类结果的支持,而如果划分到不同类中,则得-1分,表示对此聚类结果的反对。最远得分因子的规定也是如此。
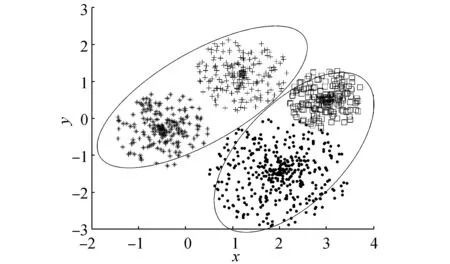
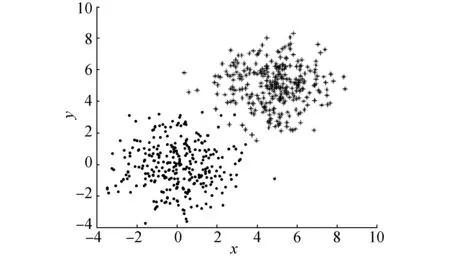
随着类别数的增加,样本和其最近邻样本被划分到不同类别中的概率将会增加,从而导致了最近得分累积和的减少;然而随着类别数的增加,样本和其最远邻样本被划分到同一类的概率将会减少,从而导致了最远得分累积和的增加。因此,在评价聚类结果时仅采用最近得分或最远得分将很难得到正确的类别数,需要综合利用这两个得分才能获得好的聚类结果。为了说明这个问题,我们将利用图1所示的数据集在不同类别数下的聚类结果来说明同时考虑最近得分和最远得分的必要性。观察图1所示数据集,可知此数据集的最佳类别数为4。如果只考虑最近邻得分时,如图1(a)所示,当K=2时,所有样本和其最近邻样本都在同一类中,而如图1(b)和图1(c)所示,当K=3或K=4 时,样本和其最近邻划分到不同类的比率就会增大,聚类结果的最近得分值会下降,因此K=2时,使最近得分值达到最大,故采用最近得分准则所得到的最佳类别数为2。而如果只考虑最远得分时,如图1(a)所示,当K=2时,样本和其最远邻样本被划分到同一类的比率很大,而如图1(b)和图1(c)所示,当K=3或K=4 时,样本与其最远邻样本划分到同一类的比率下降,而且当K=3时,样本和其最远邻样本分别划分到不同类中,此时聚类结果的最远得分值达到最大,因此,采用最远得分准则所得到的最佳类别数为3。为了选择出正确的类别数,评价指标应该综合考虑最近得分和最远得分这两个因素。基于以上的理论,在NFS评价指标中每个样本的得分设计为最近得分和最远得分的均值。
(a)K=2

(b)K=3

(c)K=4图1 不同聚类数下的聚类Fig.1 Clustering under different cluster number
NFS指标值衡量的是样本对聚类结果的满意度,NFS指标值越大聚类结果就越好。因此,依据NFS选取最佳类别数的公式为
3 基于NFS的自动聚类算法
3.1ACNFS算法
基于NFS的自动聚类算法(automatic clustering algorithm based on the NFS,ACNFS)主要包括3个主要步骤。第1步确定类别数的搜索范围,第2步计算在不同类别数下的NFS评价指标值,第3步是根据评价指标得到使聚类结果达到最好的类别数。该算法具体步骤如下。
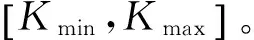
① 利用K-means[20]算法对数据集进行聚类;
②根据式(4)~(8)计算聚类结果的NFS指标值;
③根据式(9)得到最佳聚类数Kopt。
ACNFS算法流程如图2所示。
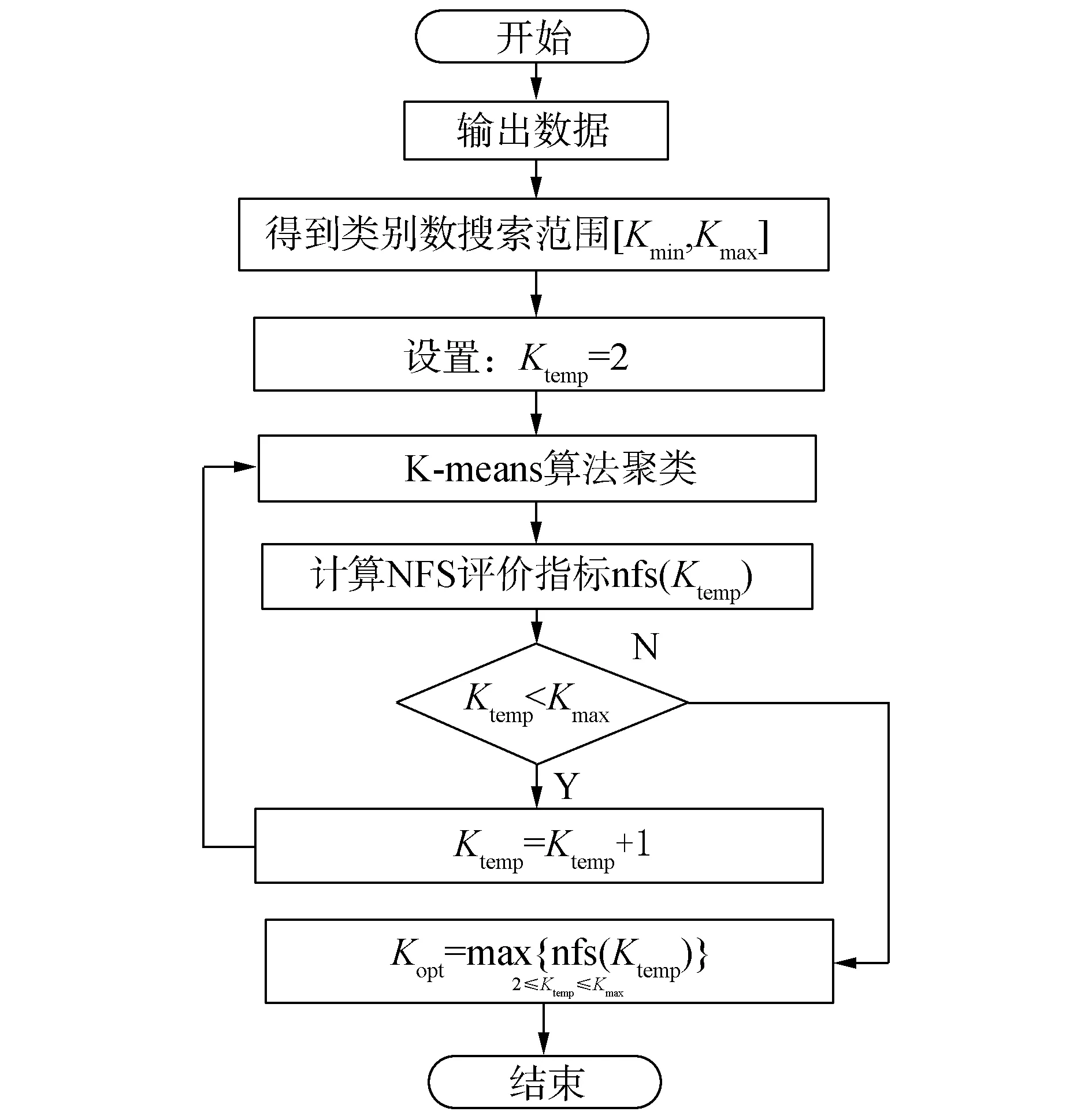
图2 ACNFS算法流程图Fig.2 The flow chart of ACNFS algorithm
3.2ACNFS时间复杂度分析
假定数据集有n个样本,则ACNFS算法的时间复杂度分析如下。
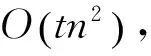
2)算法第二步中使用K-means算法进行聚类,其时间复杂度为O(nKl),其中l为迭代次数,K为类别数,且l≪n,K≪n。
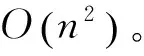
为了获得类别数,需要重复K-means和计算NFS指标值Kmax-Kmin+1次,因此2)和3)的总的时间复杂度为O((n2+nkl)×(Kmax-Kmin+1)),且(Kmax-Kmin+1)≪n。
4 实验
为了验证本文所提NFS指标和ACNFS算法的有效性,我们进行了仿真实验。在实验中我们将采用6个人工数据集和4个UCI真实数据,对CH指标、BWP指标、IGP指标和NFS指标确定类别数的性能进行比较。实验证明,基于NFS指标所提出的ACNFS算法可以有效地确定数据集的类别数,实现类别中心和类别数的自动估计。
在仿真实验中,我们所采用的人工数据集如图3所示,而真实数据集则为UCI数据库中的IRIS,Balance Scale,Wine以及Soybean-small数据集。为了方便,我们将上述所有数据集的特征总结到表1中,其中n表示数据集中样本点的个数,K表示数据集中样本点的类别数,d表示数据集中样本点的特征维数,最后一列表示各类别中样本点的个数。
(a)Dataset 1
(b)Dataset 2
(c)Dataset 3
(d)Dataset 4
(e)Dataset 5
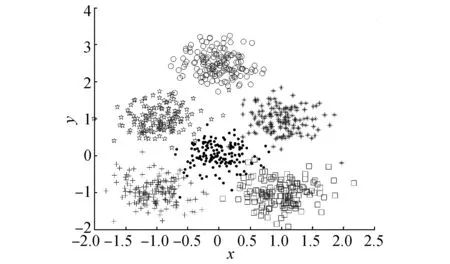
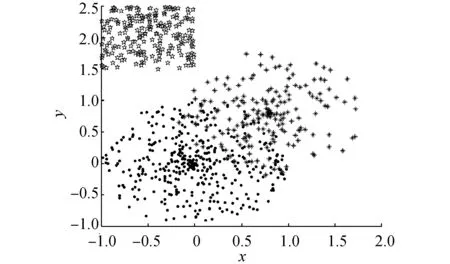
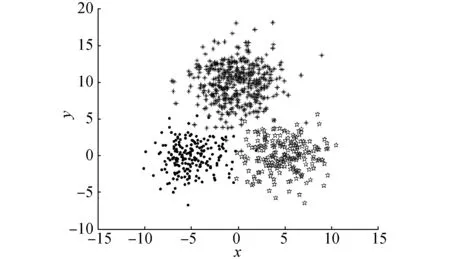
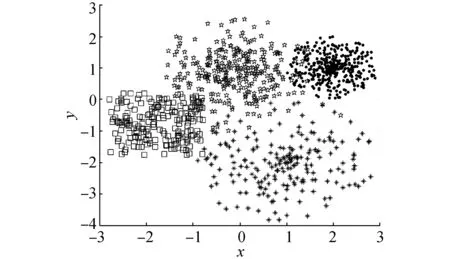
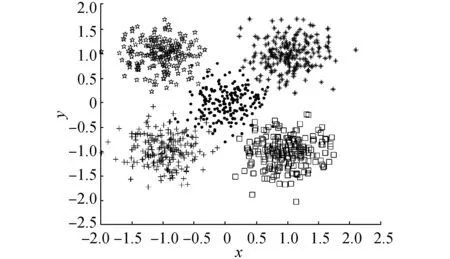
(f)Dataset 6图3 人工数据集Fig.3 Artificial dataset
Table 1 The characters of the ten data sets used in our experiments
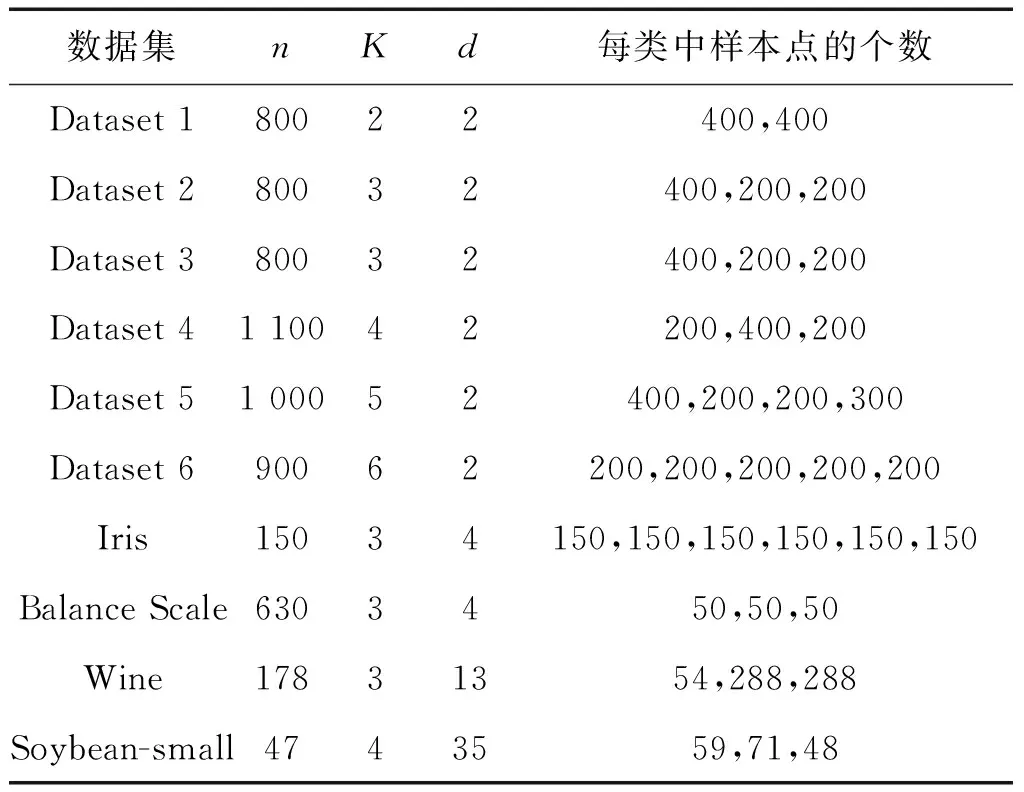
数据集nKd每类中样本点的个数Dataset180022400,400Dataset280032400,200,200Dataset380032400,200,200Dataset4110042200,400,200Dataset5100052400,200,200,300Dataset690062200,200,200,200,200Iris15034150,150,150,150,150,150BalanceScale6303450,50,50Wine17831354,288,288Soybean-small4743559,71,48
首先,分别采用CH指标、BWP指标、IGP指标和NFS指标估计人工数据集Dataset 1~Dataset 6的类别数,实验结果如表2~7所示。
表2中给出了对数据集Dataset 1采用不同评价指标得到的类别数和各类别数出现的百分比。第2列到第8列的数据是百分数值,而百分数值代表算法在运行N次,得到相应的类别数的次数与N的比值。实验中取N=20。表2中的最后1列表示通过投票准则获得的数据集的类别数。从表2可以看出,对人工数据集Dataset 1采用这4种评价指标均能得到正确的类别数,而且评价结果稳定,每次都能得到正确类别数。
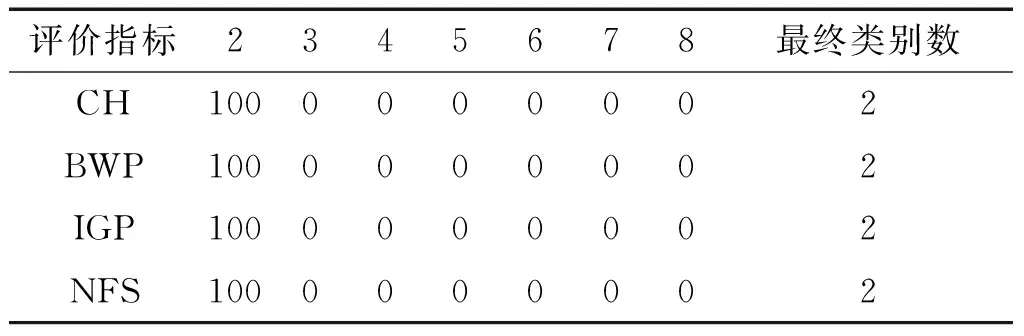
表2 Dataset 1的类别数
表3给出了对数据集Dataset 2采用不同评价指标得到的类别数和各类别数出现的百分比。从Dataset 2的散点分布图中可以看出,有两类数据无法完全分离。因此,只有采用NFS指标得到的类别数是正确的类别数,而且评价结果稳定,每次都能得到正确的类别数;而采用其他的评价指标却无法得到正确的类别数。
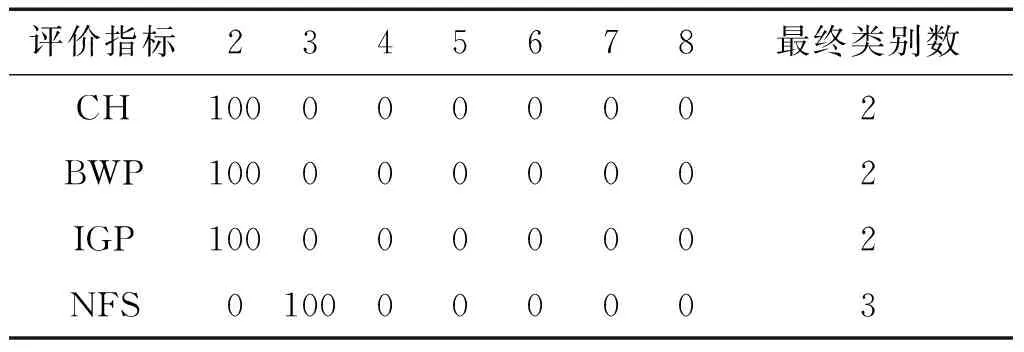
表3 Dataset 2的类别数
表4给出了对数据集Dataset 3采用不同评价指标得到的类别数和各类别数出现的百分比。由于在数据集Dataset 3中,不同类之间是完全可分的,因此采用这4个评价指标,均可以得到正确的类别数,而且评价结果稳定。
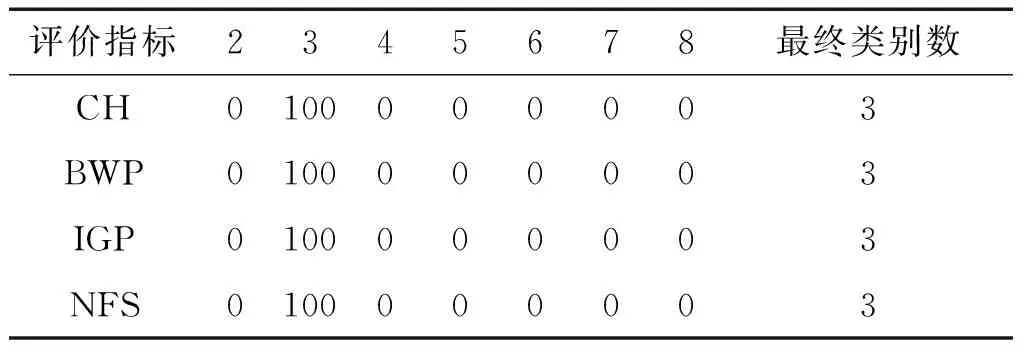
表4 Dataset 3的类别数
表5给出了对数据集Dataset 4采用不同评价指标得到的类别数和各类别数出现的百分比。采用NFS指标、CH指标和BWP指标均可以得到正确的类别数,而采用IGP指标却无法得到正确的类别数。从具体情况分析,NFS指标和CH指标性能较好,评价结果稳定,每次都可以得到正确的类别数;而BWP指标差一点,正确率只有71.3%。
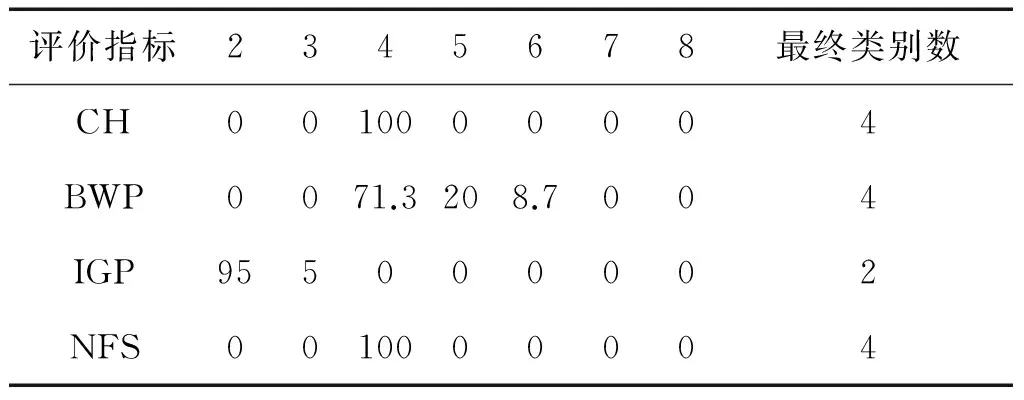
表5 Dataset 4的类别数
表6给出了对数据集Dataset 5采用不同评价指标得到的类别数和各类别数出现的百分比。采用NFS指标、CH指标和BWP指标均可以得到正确的类别数,而采用IGP指标却无法得到正确的类别数。

表6 Dataset 5的类别数
表7给出了对数据集Dataset 6采用不同评价指标得到的类别数和各类别数出现的百分比。采用四种评价指标均能得到该数据集的正确类别数。其中NFS指标、BWP指标和CH指标的性能较好,评价结果稳定;而IGP指标性能差一点,正确率为90%。
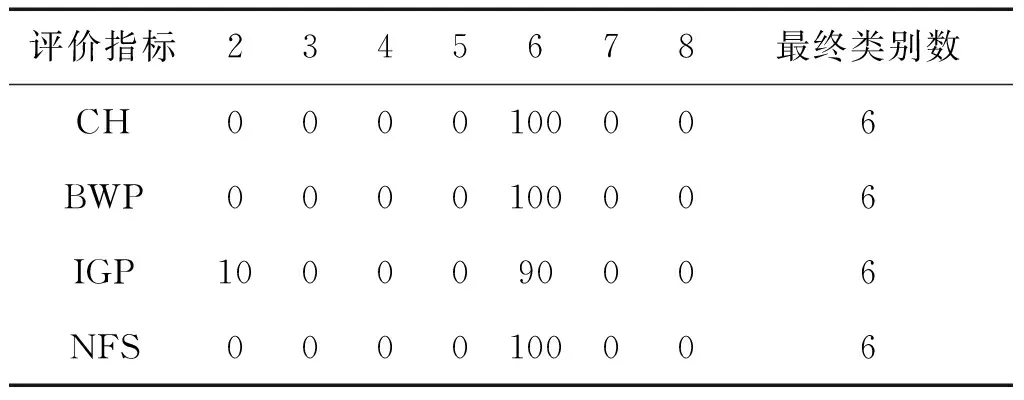
表7 Dataset 6的类别数
由表2~7所示的实验结果可如,对于可分性较好的人工数据集,CH指标、BWP指标和NFS指标均能获得正确的类别数。下面将采用UCI中的真实数据集IRIS、Balance Scale、Wine以及Soybean-small来验证CH指标、BWP指标、IGP指标和NFS指标在确定类别数时的性能。
表8给出了数据集Wine在采用不同评价指标时,在不同的类别数下的指标值,其中带下划线的数据是该指标下的最大值。NFS指标和BWP指标在类别数K=3时取最大值,而其他指标在类别数K=2时取最大值,但是由于数据集Wine的真实类别数为3,因此采用NFS指标和BWP指标可以得到正确的类别数,而采用其他评价指标则无法得到正确的类别数。
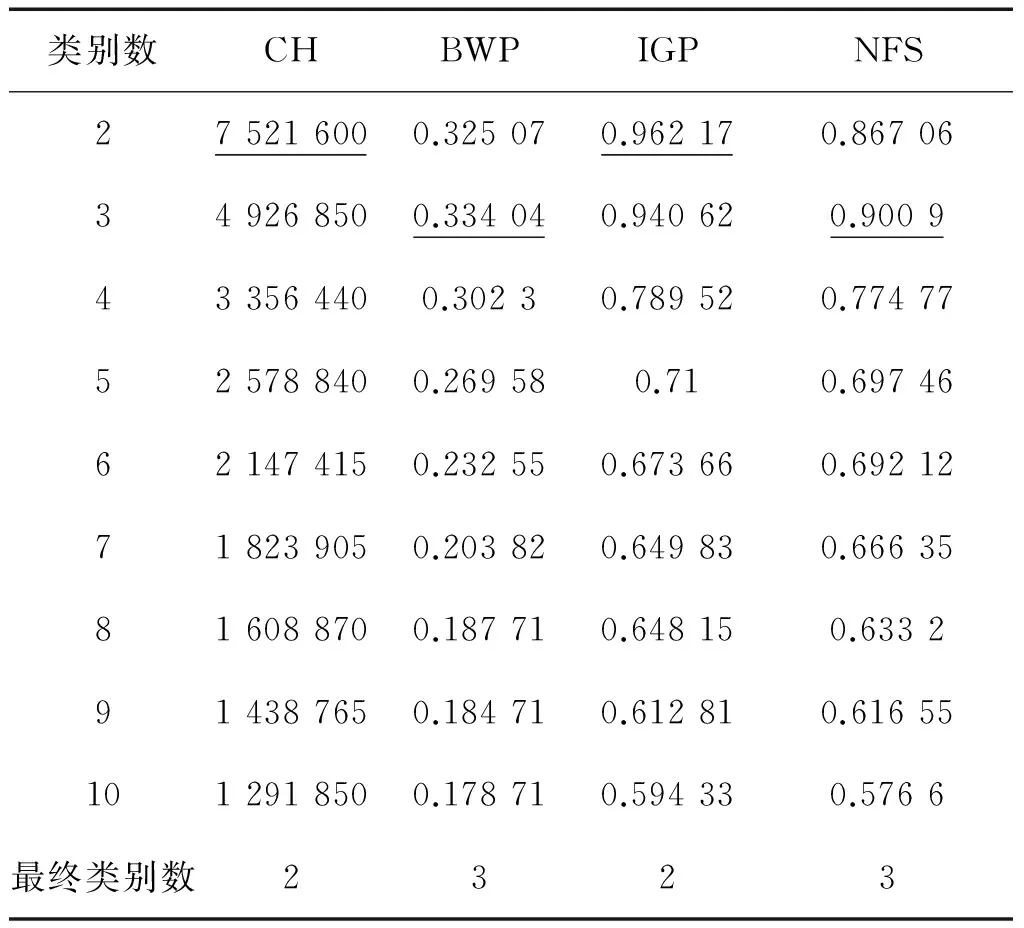
表8 Wine的指标值
表9给出了4组真实数据集分别在采用不同评价指标下得到的类别数,这里依然是运行多次实验通过投票准则确定最终的类别数,括号中的数据表示类别数出现的百分比。参考表1中各数据集的真实类别数,可以得到如下结论:采用NFS指标可以得到所有真实数据集的正确的类别数,其中对于Balance Scale和Wine数据集,评价结果稳定,效果较好,而对于IRIS和Soybean-small数据集,评价结果差一点,只有60%和45%的正确率;然而采用BWP指标只可以得到数据集Wine的正确类别数,而且评价结果稳定;但是采用CH指标和IGP指标则无法得到数据集的正确类别数。

表9 真实数据集的类别数
5 结束语
众所周知,很多聚类算法需要根据先验知识给出算法所需要的类别数。但是,在很多实际应用中很难获得有效的先验知识,因此确定聚类问题的类别数成为了一个研究的热点。本文首先基于最近邻一致性和最远邻相异性的原则,提出了一种最近最远得分评价指标(NFS),并在此基础上提出了一种基于NFS自动聚类算法,实现了对类别数和类别中心的自动估计。与已经提出的评价指标相比,NFS指标是基于数据集统计信息的指标,而且NFS指标考虑了最近样本和最远样本两个方面,通过评分机制还保证了每个样本都对评价指标产生影响。从而使NFS指标在IRIS等数据集中呈现较好的结果。但是NFS指标并不是最完美的,因此还需要继续进行相关研究。
[1]刘恋, 常冬霞, 邓勇. 动态小生境人工鱼群算法的图像分割[J]. 智能系统学报, 2015, 10(5): 669-674. LIU Lian, CHANG Dongxia, DENG Yong. An image segmentation method based on dynamic niche artificial fish-swarm algorithm[J]. CAAI transactions on intelligent systems, 2015, 10(5): 669-674.
[2]NIKOLAOU T G, KOLOKOTSA D S, STAVRAKAKIS G S, et al. On the application of clustering techniques for office buildings’ energy and thermal comfort classification[J]. IEEE transactions on smart grid, 2012, 3(4): 2196-2210.
[3]CHANG Hong, YEUNG D Y. Robust path-based spectral clustering with application to image segmentation[C]//Proceedings of the Tenth IEEE International Conference on Computer Vision. Beijing, China, 2005, 1: 278-285.
[4]SHI Jianbo, MALIK J. Normalized cuts and image segmentation[J]. IEEE transactions on pattern analysis and machine intelligence, 2000, 22(8): 888-905.
[5]XIE X L, BENI G. A validity measure for Fuzzy clustering[J]. IEEE transactions on pattern analysis and machine intelligence, 1991, 13(8): 841-847.
[6]PAL N R, BEZDEK J C. On cluster validity for the fuzzy c-means model[J]. IEEE transactions on fuzzy systems, 1995, 3(3): 370-379.
[7]郑宏亮, 徐本强, 赵晓慧, 等. 新的模糊聚类有效性指标[J]. 计算机应用, 2014, 34(8): 2166-2169. ZHENG Hongliang, XU Benqiang, ZHAO Xiaohui, et al. Novel validity index for fuzzy clustering[J]. Journal of computer applications, 2014, 34(8): 2166-2169.
[8]岳士弘, 黄媞, 王鹏龙. 基于矩阵特征值分析的模糊聚类有效性指标[J]. 天津大学学报: 自然科学与工程技术版, 2014, 47(8): 689-696. YUE Shihong, HUANG Ti, WANG Penglong. Matrix eigenvalue analysis-based clustering validity index[J]. Journal of Tianjin university: science and technology, 2014, 47(8): 689-696.
[9]卿铭, 孙晓梅. 一种新的聚类有效性函数: 模糊划分的模糊熵[J]. 智能系统学报, 2015, 10(1): 75-80. QING Mei, SUN Xiaomei. A new clustering effectiveness function: fuzzy entropy of fuzzy partition[J]. CAAI transactions on intelligent systems, 2015, 10(1): 75-80.
[10]王开军, 李健, 张军英, 等. 聚类分析中类数估计方法的实验比较[J]. 计算机工程, 2008, 34(9): 198-199, 202. WANG Kaijun, LI Jian, ZHANG Junying, et al. Experimental comparison of clusters number estimation for cluster analysis[J]. Computer engineering, 2008, 34(9): 198-199, 202.
[11]王勇, 唐靖, 饶勤菲, 等. 高效率的K-means最佳聚类数确定算法[J]. 计算机应用, 2014, 34(5): 1331-1335. WANG Yong, TANG Jing, RAO Qinfei, et al. High efficient K-means algorithm for determining optimal number of clusters[J]. Journal of computer applications, 2014, 34(5): 1331-1335.
[13]DAVIES D L, BOULDIN D W. A cluster separation measure[J]. IEEE transactions on pattern analysis and machine intelligence, 1979, PAMI-1(2): 224-227.
[15]KRZANOWSKI W J, LAI Y T. A criterion for determining the number of groups in a data set using sum-of-squares clustering[J]. Biometrics, 1988, 44(1): 23-34.
[16]周世兵, 徐振源, 唐旭清. K-means算法最佳聚类数确定方法[J]. 计算机应用, 2010, 30(8): 1995-1998.
ZHOU Shibing, XU Zhenyuan, TANG Xuqing. Method for determining optimal number of clusters in K-means clustering algorithm[J]. Journal of computer applications, 2010, 30(8): 1995-1998.
[17]KAPP A V, TIBSHIRANI R. Are clusters found in one dataset present in another dataset[J]. Biostatistics, 2007, 8(1): 9-31.
[18]周世兵. 聚类分析中的最佳聚类数确定方法研究及应用[D]. 无锡: 江南大学, 2011. ZHOU Shibing. Research and application on determining optimal number of cluster in cluster analysis[D]. Wuxi: Jiangnan University, 2011.
[19]Gower J C, Ross G J S. Minimum spanning trees and single linkage cluster analysis[J]. Journal of the royal statistical society, 1969, 18(1):54-64.
[20]MACQUEEN J. Some methods for classification and analysis of multivariate observations[C]//Proceedings of the 5th Berkeley Symposium on Mathematical Statistics and Probability. Berkeley, USA, 1967: 281-297.
A clustering evaluation index based on the nearest and furthest score
FENG Liuwei1,2,3,CHANG Dongxia1,2,3, DENG Yong4, ZHAO Yao1,2,3
(1. Institute of Information Science, Beijing Jiaotong University Beijing 100044, China; 2. School of Computer and Information Technology, Beijing Jiaotong University, Beijing 100044, China; 3. Institute of Software, Chinese Academy of Sciences, Beijing 100190, China)
The clustering algorithm is one of the widely-used methods in data analysis. However, the number of clusters is essential to determine the performance of the clustering algorithm. At present, the number of clusters usually need to be specified in advance. In most cases, it is difficult to obtain the valid cluster number according to a priori knowledge of the dataset. To obtain the number of clusters automatically, a Nearest and Furthest Score (NFS) index was proposed based on the principles of the nearest neighbor consistency and the furthest neighbor difference. Moreover, an Automatic Clustering NFS (ACNFS) algorithm was also proposed, which can determine the number of clusters automatically. The experimental results prove the index is reasonable and practicable to determine the cluster number.
the nearest neighbor consistency; the furthest neighbor difference; K-means clustering algorithm; scoring mechanism; evaluation index; hierarchical clustering

冯柳伟,女,1992年生,硕士研究生,研究方向为聚类算法。

常冬霞,女,1977年生,副教授,硕士生导师,主要研究方向为进化计算、非监督分类算法、图像分割以及图像分类。发表学术论文10余篇,其中SCI检索5篇,EI 检索2篇。

邓勇,男,1974年生,副研究员,博士,主要研究方向为智能信息处理、数据库系统技术及应用等。 主持和参与国家“863”计划1项,北京市自然科学基金项目1项。发表学术论文20余篇,其中收录10余篇。
10.11992/tis.201611007
http://kns.cnki.net/kcms/detail/23.1538.TP.20170227.2211.022.html
2016-11-07.
日期:2017-02-27.
国家自然科学基金“重点”项目(61532005).
常冬霞. E-mail:dxchang@bjtu.edu.cn.
TP391
A
1673-4785(2017)01-0067-08
冯柳伟,常冬霞,邓勇,等.最近最远得分的聚类性能评价指标[J]. 智能系统学报, 2017, 12(1): 67-74.
英文引用格式:FENG Liuwei, CHANG Dongxia, DENG Yong,et al. A clustering evaluation index based on the nearest and furthest score [J]. CAAI Transactions on Intelligent Systems, 2017, 12(1): 67-74.
