基于数据挖掘的暂态电力斜坡均衡聚类算法研究
2017-05-23彭勇黄梦兰姜祖明魏华勇刘煜
彭勇,黄梦兰,姜祖明,魏华勇,刘煜
(国网河南省电力公司信阳供电公司,河南信阳 464000)
功率斜坡的准确估算对风力发电站极其重要。由于风速的间歇性变化,风力发电站的功率水平也会随之产生随机性变化。功率水平的即时波动性变化被定义为斜坡事件,即功率斜坡率(变化率)(PRR)是指功率水平的瞬时变化,由电力产生的一阶导数异常识别的功率生产梯度表示。电力上涨和下降分别称为正负斜坡问题,负斜坡影响电力系统的安全性,其会造成意外事故。同时,影响储备电力市场的财务后果[1-2]。发电站发电量总是正值或是零值,但由于电力方向的改变,PRR可能是负值和正值。PRR的绝对值越高,功率激增(下降)越快。
功率斜坡率相关的应用程序通过使用可用的历史数据,如SCADA和气象桅杆数据来创建预测模型。在这些海量数据中,可通过数据挖掘方法来发现并解决问题。网格服务基础设施,始终是数据挖掘方法的实现之一[3]。在功率斜坡事件的分析中,存在具有物理参数,空间参数和时间参数的数据。本文将重点研究采用其中高频率出现的大数据集来帮助数据挖掘形成相关预测规则,进而为操作室的决策制定提供参考。为了理解产生功率斜坡间的关系,文献[4~5]根据空间和时间效应研究了每个涡轮机的位置,这将在本文中进一步扩展为具有物理和时间参数的相关预测规则,这些规则将被应用到电力系统运行室的决策过程中。
文献[6]针对时间物理参数空间研究,证明了从历史SCADA数据中获取的一些大气物理参数对于产生电力斜坡比其他大气物理参数更重要。在该文中,作者为控制室操作员推导出辅助关键集。控制室操作员面临与功率斜坡相关的2个主要问题,首先是当风电出现意外冲击时,由于风速呈现正的上升趋势,在短时间内出现意外冲击,可能导致电网不平衡,操作员必须平衡负荷,降低其他发电站的风电产量;其次是,对于负斜坡情况,操作员应有足够的备用电力。在文献[7]的研究中,采用Apriori算法对中国河西走廊地区风速预测值提出相应的修正方案。在这项研究中,影响风速预测的气象变量,如温度、压力和湿度,按照这些参数之间的规则进行聚类。进而发现每个小组的聚类方法,以减少其预测误差。
1 聚类算法的关联规则
聚类算法旨在优化目标函数F函数值随C1,C2,C3,...,Ck定义的聚类数k的分割而变化

式中:Qk(Ω)是K非空聚类中数据Ω=ω1,ω2,ω3,...,ωm的所有分区的集合。
1.1 K-均值聚类算法
K-均值算法通过聚类准则F创建一个求解局部最优值的解决方案,该聚类准则取决于每个元素与其最近的聚类中心(质心)之间的距离之和[8-9]。可以用以下公式表示,式中:K是聚类数量;Ki是聚类i的对象数量国;ωij是第i个聚类的第j个对象;-ωi是每个聚类的质心。聚类算法优化目标函数F函数值随C1,C2,C3,...,Ck定义的聚类数k的分割而变化

Qk(Ω)是K-非空聚类中所有数据分区Ω=ω1,ω2,ω3,...,ωm的集合。F的目标函数可扩展为[10]

传统的K-均值算法伪码[11]可以概括如下:
1)聚类方法需要实现最佳聚类大小的决策。聚类大小代表有意义的分区,不会丢失大聚类中的信息或创建过多的小聚类。当下已有多种方法来解决这一问题,其中之一是熵计算[12];第二种方法是在文献[12]中讨论的指标计算和优化。在该研究中,采用R程序中的nbclust包,基于文献[12]中所提的几个指标来执行该优化任务;
2)通过Forgy算法[11]执行数据库的初始化分区(C1,C2,...,Ck);
3)计算每个聚类的质心;
4)重新分配ωi到最近的聚类质心;
6)重新进行一次完整的迭代,直到没有进一步的聚类成员变化则停止。
下面介绍Apriori算法,其将对每个涡轮机的聚类数结果的输出进行处理,以生成用于运营决策的关联规则。
1.2 Apriori算法的关联规则
为了说明Apriori算法的3层过程,定义一个数组表示下面的矩阵。其中,矩阵每一行的单个条目是一组二进制特征,t表示时间步长,l表示涡轮机编号,k表示聚类标签。因此,在本例中总是有15个项目,式中项目集合15由I表示。
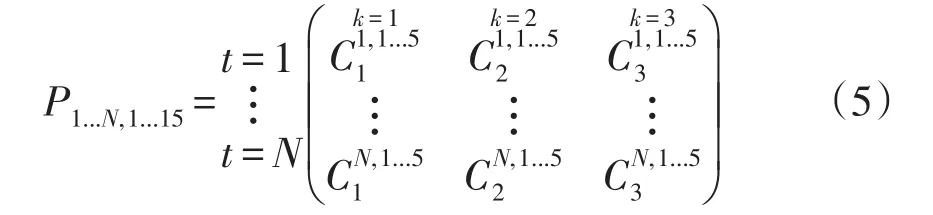
Pt,1...15的每一行条目均是一个转换,表明转换个数和时间步骤一样多。每行转换包含涡轮机在每个时间步骤的每个二进制形式的斜坡K均值聚类标签的分析。每一行条目表示新的转换将具有诸如X和Y的项目的子集,2个项目子集的大小均<15,且X,Y⊂I,X⋂Y=∅。因此,可定义具有定向规则的关联规则,即X→Y。关联规则是根据每个原始行条目在每个转换中定义的,每个原始行条目将定义一个新的关联规则。但这将会创建多个关联规则,因此需要对关联进行更多的过滤。
支持是一种用户定义的限制,用于过滤那些候选关联规则的不相关事件,这些事件对于决策的重要性相对较小。这个功能将由函数supp(·)来定义,该函数统计了关联规则发生的频率。在关联规则中,表示该关联规则在所有行中发生的次数或大小。在数学上,项目集X规则的支持数σ(X→Y)可表示为[13-14]
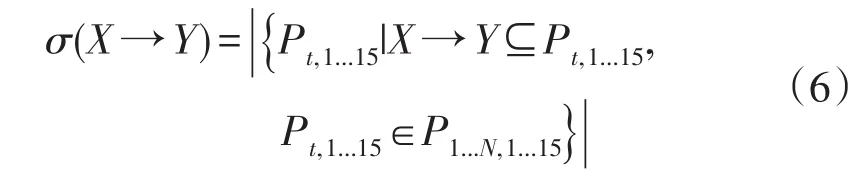
式中:符号|·|表示一个集合中元素的个数。若将转换总数或时间步长定义为N,则X→Y的支持可以定义为
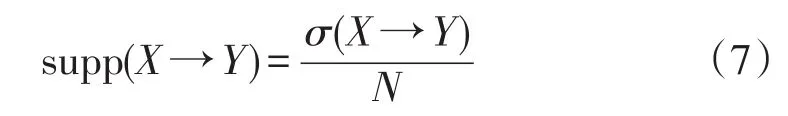
置信度用来定义一个候选的关联规则的支持比例,即用supp(X→Y)除以一个子集的支持supp(X),其表达为
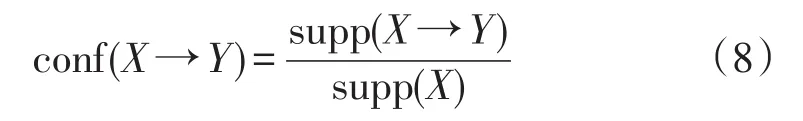
置信度和支持之间的区别是,置信度是衡量关联规则的强度,而支持则象征其统计意义。
升力是由函数lift(·)所表示的另一个标准。当有多个关联规则时,这用于加强过滤器
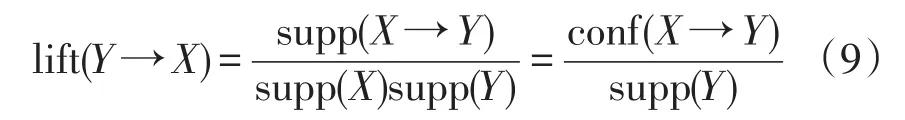
生成项目组后,计数阶段将识别每个项目组类别中项目组的频率。对于理想的X和Y之间的关系,支持必须较大,且置信度必须高,更大的升力值则意味着项目之间具有更强的关联。根据候选规则在计数中出现的次数,其支持值是通过候选规则的重复次数与观察组之间的比率来计算的。在最后一步,每个候选规则将与其自身的支持值进行比较,然后与预先定义的支持值阈值进行比较,若超过这个门槛的候选规则将被选中。
这里讨论的数据挖掘和发现规则查找方法,依赖于输入转换数据类型的性质。转换是以下行为的数据形式:即不能将其分解为代表数据库(DB)中所显示的任何更改的较小部分,且每个转换均是一组二进制值项目。在关联规则处理中,输入数据是具有时间维度的转换数据,该时间维度是该数据的转换计数。也可以使用不同的对象,例如物理变量、空间或时间维度。基于转换数据,关联规则处理,尤其是采用Apriori算法,通过多次迭代计算数据库中转换的频繁对象组。
2 实际案例研究
本文研究福建平潭的是一座风力发电场,在80m处有5台VESTASV90-3.0MW风机。如图2所示,该风电场的主要风向是从北到南,该风电场5台风机的发电量每10 min记录一次。文中采用其2013年电力生产值来进行PRR分析,而数据按需要进行单位换算。
根据该风电场功率记录计算得出的功率爬坡率(PRR)值,是文献[15]中离散功率导数的比率
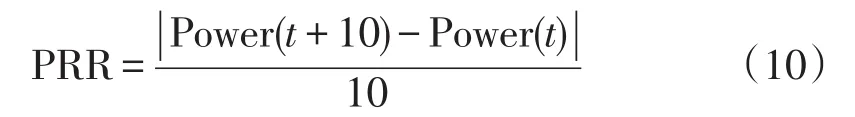
该PRR值作为K-均值算法的输入。
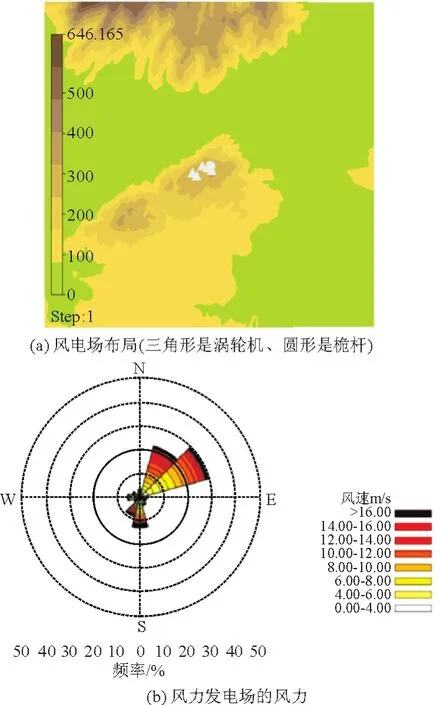
图1 平潭风力发电厂细节信息Fig.1 Detailed information of Pingtan Wind Power Plant
3 结果分析
采用R程序的NbClust包来分析优化的聚类数[12]。通过分析,将最大聚类大小定义为3,聚类结果如图2所示。图2(a)显示了,数据协方差矩阵的2个主要主成分轴上时间尺度的聚类结果。这里主成分分析(PCA)结果仅用于定义聚类数据二维可视化的2个主要方向,聚类分析通过理论部分定义的K-均值算法来执行。在PCA和K-均值之间的关系与相似性也已在算法层面被利用,同时使用PCA进行K-均值模型的优化[16]。在图2(a)中使用了PCA的主要方向,即dc1和dc2,可视化结果清楚地显示了聚类PRR的时间数据围绕3个聚类。
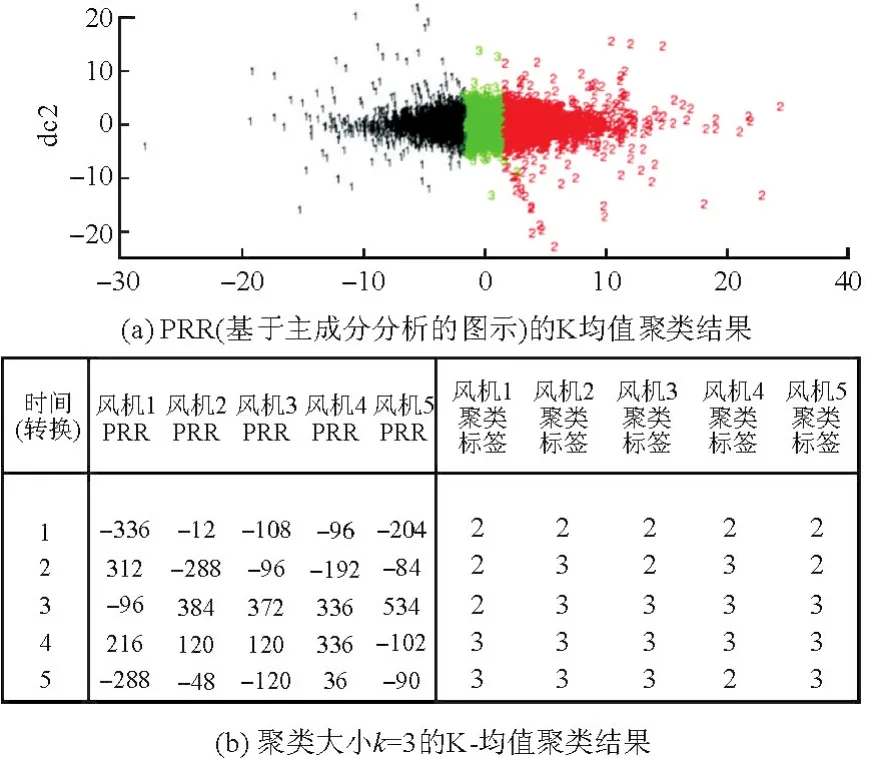
图2 聚类结果Fig.2 Clustering results
图3给出了Apriori算法关联规则的结果。
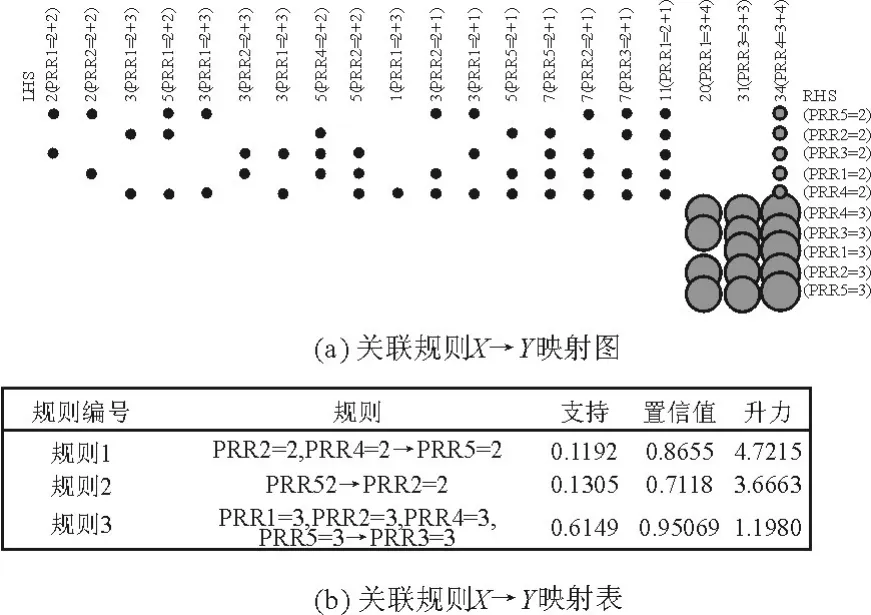
图3 一些关联规则Fig.3 Some of the association rules
图3(b)总结了X→Y之间的某些规则。根据图3(b)中定义的置信度,最有力的规则是规则1:X→Y:{PRR2=2,PRR4=2}→{PRR5=2}。这种关系也在图3(a)中的视觉辅助中被证明。例如X={PRR2=2,PRR4=2},其是左上角的第一个条目,从左到右的索引2(PRR2=2+2)表示在第一个条目2中。这表明对于LHS的不同关联规则而言,出现次数是2次。括号中的第一项是PRR2=2,表示第二个涡轮斜坡是PRR2,聚类标号等于PRR2=2,最后一项表示还有一个类似于第一个的项目。在表示RHS的行是Y的情况下,可看到对于X→Y,Y={PRR5=2}。将图 3(b)关联到图 3(a),其他规则也可以观察到同样的关系。
4 结语
本文基于数据挖掘的聚类和关联规则算法,生成了一套针对电力斜坡的运行规则。首先,根据风电场数据的功率斜坡率将风力涡轮机分组,这是通过使用K-均值聚类规则来实现的。再将Apriori算法引入这些聚类关联规则后,发电场运营商可以实施新的运营决策规则,本文所提出的方法可以应用于一般情况。未来的研究中,还可通过聚类算法与机器学习应用的结合,发现这些风电场大数据的复杂数据参数之间的隐藏规则,从而用于风电场的运营决策。
参考文献
[1]姜晨,高亮.基于负序功率方向比较与聚类算法的改进继电保护算法研究[J].电力系统保护与控制,2016,44(8):92-98.JIANG Chen,GAO Liang.Research on improved relay protection algorithm based on negative sequence power direction comparison and clustering algorithm[J].Power System Protection and Control,2016,44(8):92-98.
[2]杨甲甲,赵俊华,文福拴,等.智能电网环境下基于大数据挖掘的居民负荷设备识别与负荷建模[J].电力建设,2016,37(12):11-23.YANG Jiajia,ZHAO Junhua,WEN Fushuan,et al.Data mining residents load equipment identification and load modeling under smart grid environment[J].Electric Power Construction,2016,37(12):11-23.
[3]陆惠斌,徐勇,伍宇翔,等.基于换相技术的三相不平衡治理装置研究[J].电力电容器与无功补偿,2016,37(6):64-69.LU Huibin,XU Yong,WU Yuxiang,et al.Three phase unbalanced control device based on commutation technolo⁃gy research[J].Power Capacitor and Reactive Power Com⁃pensation,2016,37(6):64-69.
[4]卢伟国,方慧敏,杨异迪,等.Boost PFC变换器的动态斜坡补偿策略分析与设计[J].电力自动化设备,2017,37(5):1-6.LU Weiguo,FANG Huimin,YANG Yidi,et al.Analysis and design of Boost PFC converter dynamic slope compen⁃sation strategy[J].Power Automation Equipment,2017,37(5):1-6.
[5]苏舟,李灿,姚李孝,等.电力负荷数据预处理研究及应用[J].电网与清洁能源,2017,33(5):40-43.SU Zhou,LI Can,YAO Lixiao,et al.Research and appli⁃cation of power load data preprocessing and research and application[J].Power System and Clean Energy,2017,33(5):40-43.
[6]杨飞,朱志祥.基于特征和空间信息的核模糊C-均值聚类算法[J].电子科技,2016,29(2):16-19.YANG Fei,ZHU Zhixiang.Kernel fuzzy C-mean cluster⁃ing algorithm based on feature and spatial information[J].Electronic Science and Technology,2016,29(2):16-19.
[7]马小慧,阳育德,龚利武.基于Kohonen聚类和SVM组合算法的电网日最大负荷预测[J].电网与清洁能源,2014,30(2):7-11.MA Xiaohui,YANG Yude,GONG Liwu.Based on koho⁃nen clustering and SVM combination algorithm for daily maximum load of power grid[J].Power System and Clean Energy,2014,30(2):7-11.
[8]贾瑷玮.基于划分的聚类算法研究综述[J].电子设计工程,2014(23):38-41.JIA Aiwei.Partition clustering algorithm research based on divide[J].ElectronicDesignEngineering,2014(23):38-41.
[9]张宇献,刘通,董晓,等.基于改进划分系数的模糊聚类有效性函数[J].沈阳工业大学学报,2014,36(4):431-435.ZHANG Yuxian,LIU Tong,DONG Xiao,et al.Fuzzy clustering effectiveness function based on improved parti⁃tion coefficient[J].Journal of Shenyang University of Tech⁃nology,2014,36(4):431-435.
[10]刘飞,唐雅娟,刘瑶.K-means聚类算法中聚类个数的方法研究[J].电子设计工程,2017,25(15):9-13.LIU Fei,TANG Yajuan,LIU Yao.Study of the K-means clustering algorithm to cluster the number of methods[J].Electronic Design Engineering,2017,25(15):9-13.
[11]OHBA M,KADOKURA S,NOHARA D.Impacts of synoptic circulation patterns on wind power ramp events in East Japan[J].Renewable Energy,2016,96(3):591-602.
[12]CORNEJO BUENO L,AYBAR RUIZ A,CAMACHO GÓMEZ C,et al.A hybrid neuro-evolutionary algorithm for wind power ramp events detection[J].2017.
[13]FAN Yaju,KAMATH Chandrika.Detecting ramp events in wind energy generation using affinity evaluation on weather data[J].Statistical Analysis and Data Mining,2016,9(3):155-173.
[14]LI Y,DAI C,WANG T,et al.Separate wind power and ramp predictions based on meteorological variables and clustering method[C].Morben:IEEE International Confer⁃ence on Power Systems,IEEE,2016.
[15]ZHANG J,CUI MINGJIAN,BRI MATHIAS HODGE,et al.Ramp forecasting performance from improved shortterm wind power forecasting over multiple spatial and tem⁃poral scales[J].Energy,2017,122(8):528-541.
[16]YILDIRIM N,UZUNOGLU B.Data mining via association rules for power ramps detected by clustering or optimiza⁃tion[M].Berlin Heidelberg:Springer,2016.
