分布式移动网络用户行为分析系统
2017-05-18陈友
陈 友
(上海理工大学 光电信息与计算机工程学院,上海 200093)
分布式移动网络用户行为分析系统
陈 友
(上海理工大学 光电信息与计算机工程学院,上海 200093)
为使移动互联网企业能够对用户提供更好的个性化服务,文中提出了一个基于数据预处理、上下文、C4.5决策树和分布式数据处理的分布式移动网络用户行为分析系统。该系统主要通过分布式的开源框架Zookeeper、Kafka、Storm进行实现。通过对系统的实现表明,该系统能够较为精确地分析出移动网络用户的兴趣分类,即使面对海量的移动用户行为数据也并不会影响系统性能。
数据预处理;上下文;决策树;分布式;用户行为分析
随着移动网络技术的快速发展,移动网络公司通过移动网络累积了海量的用户上网行为数据。对这些数据进行分析能预测用户的兴趣及其需求从而使移动网络公司对用户提供更好的个性化服务,提高用户的满意度。然而与传统数据相比,这些数据具有数据量大、数据多样性、增长快速、价值密度低等特点。因此,提出一种有针对性的移动用户行为分析方法已成为移动网络公司拓展业务过程中亟待解决的问题。目前,移动网络用户的行为分析方法主要有K-means聚类、决策树算法、贝叶斯网络建模方法和神经网络建模方法等[1-3]。但是这些方法在对用户兴趣提取过程中忽略了移动网络上下文[4]对于用户行为的影响。
本文提出了一个分布式的系统架构用于对海量数据的处理,并且通过数据预处理排除噪声数据,提高了算法的分类效率,并且在决策树算法中引入了上下文信息,从而提高了移动网络用户行为分析的可靠性和准确性。
1 移动网络上下文
网络上下文是用来描述用户、网络环境和上网设备的状态的信息,它包括用户,时间,地点,用户状态和相互关系等。在本文中,将移动网络上下文分成3类,分别是移动网络用户上下文和上网智能设备上下文和移动网络环境上下文。
具体定义如下:
移动用户上下文(Mobile User Context, MUC)=
MUC描述了用户的一些基本信息,它包括了用户的年龄,性别,职业和学历,这些用户的基本信息是用户在注册上网时主动提提供的。
上网智能设备上下文(Device Context, DC)=
DC描述了用户使用的上网设备的基本信息,它包括了设备的唯一标识mac地址,还有设备的种类比如手机、平板电脑等,设备的品牌,设备的长宽高。
移动网络环境上下文(Mobile Network Context, MNC)=
MNC描述了用户所处的移动网络环境状态及可能影响用户行为的因素,包括用户在哪个地点上网、用户的IP地址、用户上网时间以及当前的网络文化。
2 移动网络用户行为分析
2.1 数据预处理
面对大量的移动网络用户,移动网络用户行为数据是爆炸性的增长。然而这些数据里面充斥了大量的无用数据,比如:重复的数据、空值的数据等。因此,获得到的数据通常是不完整的、噪声的并且是矛盾的数据[5]。
针对这一系列的问题,基于数据预处理[6]的概念,本文设计了对移动网络用户行为数据的预处理步骤。首先,对于每个移动网络运营商提供的不同格式的用户行为数据进行数据格式转换;其次,对Dmac值进行判断如果是空则表明它是无效数据并直接丢弃掉;最后,对重复数据进行判断,这里定义一个时间阈值(threshold),一个用户在这个阈值内的行为是不可能发生改变的。所以当同一用户的行为数据的前后时间相隔不大于时间阈值时,只取第一条,后一条到来的数据直接丢弃掉,计算公式
Idate1-Idate2≤threshold
(1)
通过这3个步骤的处理,一方面可以减少不必要的计算和数据存储空间,减轻系统的负担;另一方面可以提高系统的分析准确性。
2.2 决策树
在机器学习和数据挖掘中决策树也是一种最普遍的分类算法,它是易于实现和理解的并且能够在较短时间内能够对大量的数据做出可行和良好的结果[7]。通常情况下,决策树通过启发式信息从基于特征的例子中进行学习和推理[8-9]。C4.5算法是被使用最多的并且是最广泛的创建决策树的算法,所以选择C4.5来进行决策树的创建[10]。C4.5使用一种更为准确方法去寻找最优属性去做分裂,因为寻找一致性最小的决策树问题与训练集是NP-完全的[10-11],这是一个结果在接近最优的树的重要特征。
本文使用C4.5决策树算法对移动网络用户行为数据进行兴趣分类,该算法根据信息增益率来选择测试属性。该算法的主要步骤为:假设已知用户行为样本集为T,集合的类型为:{C1,C2,C3,…,Ck}。选择一个属性V去分割样本集T,属性V有不连续值{v1,v2,v3,…,vn},因此将样本集T分成了n个数据子集,分别为T1,T2,…,Tn。所以|T|就为样本集T的例子的数量,然后|Ti|是属性V=vi的例子的数量。|Cjv|是种类Cj在V=vi的例子中的数量。所以
(1)种类Cj出现的概率
P(Cj)=|Cj|/|T|=freq(Cj,T)
(2)
(2)属性V=vi出现的概率
p(VI)=|tI|/|T|
(3)
(3)类别Cj在V=vi中出现的条件概率
P(Cj|vt)=|(Cjv|/|Ti|)
(4)
(4)信息类型熵的计算公式
(5)
(5)条件熵的类型
(6)
(6)信息增益
I(C,V)=H(C)-H(C/V)=Info(T)-
Infov(T)=gain(v)
(7)
(7)以属性V分割后得到的信息熵
(8)
(8)信息增益率
gain_ratio(v)=I(C,V)/H(V)=
gain(v)/split_Info(v)
(9)
3 移动网络用户行为分析系统架构
3.1 系统整体架构
传统的移动用户行为分析工具并具备分析海量的移动用户行为数据,同时要求所有数据都在单一的服务器上处理,硬件能力造成了数据处理的瓶颈。针对这一问题,本文提出了分布式的系统架构,增加了系统的伸缩性和扩展性,当系统集群出现处理瓶颈时,可以通过增加机器节点从而提高系统的数据存储能力和处理能力。
在分布式的移动网络用户分析系统中,采取了分布式的Zookeeper来协调分布式应用服务程序。利用Kafka系统集群实现信息的接收和存储,其是一种高吞吐量分布式发布订阅的消息系统,即使有TB级的数据它也能够保持高速和稳定的性能。Storm是一个开源的分布式实时处理框架,可以高效的处理大量的流式数据[12]。图1展示了整个系统的架构。
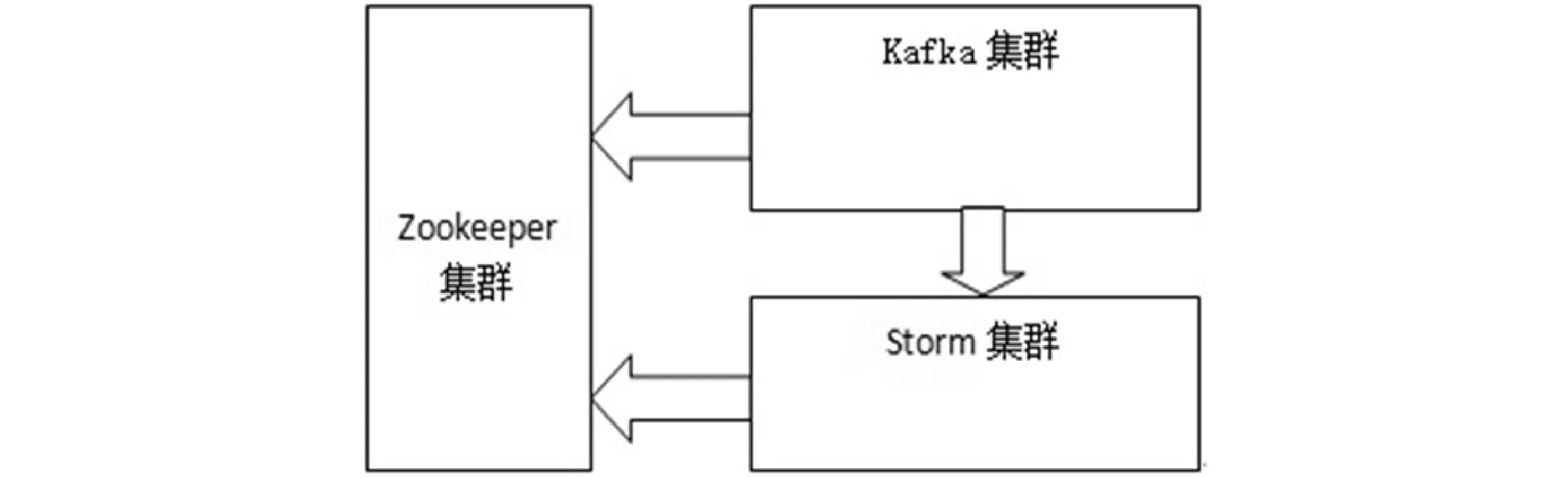
图1 系统整体架构图
3.2Zookeeper集群
在大规模的分布式应用场景下,容易出现服务协调应用问题。针对这一问题,在分布式移动网络用户分析系统中采用了Zookeeper来解决。Zookeeper是为分布式应用提供协调管理的服务[13]。它为该系统中的Kafka和Storm提供了统一配置服务、集群管理和分布式同步服务等。在Zookeeper服务中,包含了两个角色分别是leader和follower,其中leader主要负责写服务和数据同步,follower主要提供读服务。
Zookeeper的系统架构如图2所示,其中客户端可以连接到每个server,每个server的数据完全相同,其中每个follower都和leader有连接,它们接收leader的数据更新操作。Server记录事务日志和快照到持久存储,其中如果有(2n+1)个服务的集群,则集群允许n个服务失效。

图2 Zookeeper集群架构图
3.3 Kafka集群
对于传统的数据收集方式,当随着数据的爆炸性增长时,会产生新的数据存储问题、扩容困难并且随着数据量的增大数据接收的速度会大幅度变慢。针对这个问题,本文采用了分布式的Kafka对用户行为数据进行收集和存储。Kafka是一个分布式的消息系统,使用了发布-订阅的模式去收集和分发数据[14]。系统架构由生产者(producers)、消费者(consumers)和代理人(brokers)组成。为了提高系统性能,它分布在多台的计算机上[15]。生产者采用推送模式去发布消息到brokers中,同时,消费者采用拉取模式从brokers中订阅消息[16]。在Kafka集群中,每个broker的状态都是相同的,所以容易从Kafka集群中添加和删除一个broker[17]。Kafka的集群架构如图3所示。
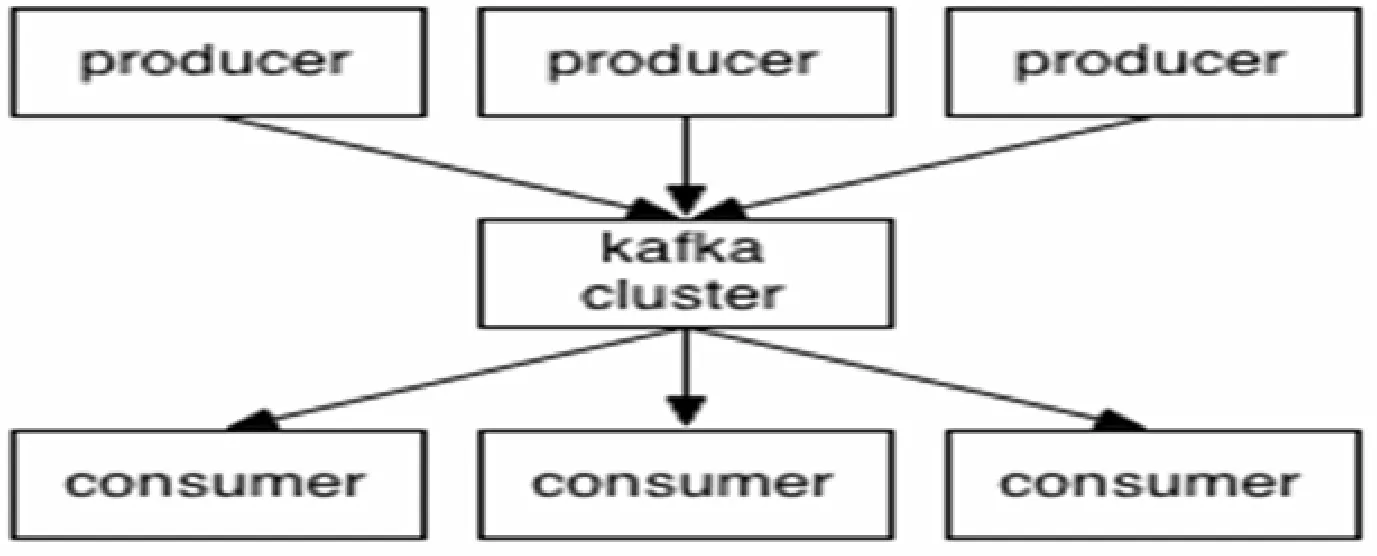
图3 Kafka集群架构
3.4 Storm集群
针对传统用户行为分析架构将数据放在单一的服务器上,这样会限制系统的性能并且不容易对整个系统进行扩展,因此本文中采取了分布式的Storm框架对用户行为数据进行分析。Storm是最流行的实时流处理框架,提供了基本的原语,并且在高容量和关键任务的应用程序中能够保证一定的容错的分布式计算[18]。一个Storm集群由一个主(nimbus)节点和一个或者多个的工作节点(supervisors)组成,架构如图4所示。

图4 Storm集群架构
Storm集群中每个任务是被分配到不同的组件中执行的,每个组件执行特定的任务。集群中产生源数据的组件被称为spout,在本文提出的系统中,从Kafka集群读取数据。然后spout发送一连串的tuple给执行处理的组件,tuple是一次消息传递的基本单元。其中执行处理的组件叫做bolt,数据预处理和C4.5决策树分类处理逻辑就写在bolt中。Spout和bolt组合成了一个topology,是在Storm集群中一个实时应用程序,其中可以是一个或者多个的spout和bolt。
以本文为例,设计了一个适用的topology。包括了一个读取数据组件kafkaSpout,数据预处理写在两个组件中,一个distributeBolt进行格式转换和去除空数据,一个deduplicationBolt进行用户行为数据去重。对用户行为数据进行分类写在classficationBolt,图5展示了本文设计的完整的topology结构。

图5 topology结构
4 系统实现
为了验证分布式移动网络用户行为分析系统的可行性和性能,分别使用3台计算机用于系统的搭建,3台计算机配置相同,均为8 GB内存和1 TB硬盘。然后按上述系统架构在3台计算机中搭建和配置Zookeeper、Kafka和Storm集群。
系统启动成功后,将准备好的用户行为的样本数据输入到系统中,最后通过集群的监控界面统计系统运行情况。图6是系统中数据存储和消费情况,logsize表示系统接收到了多少数据量,lag表示系统中还有多少数据没有被消费,offset表示消费了多少数据。从图6结果中可以知道,当系统存储数据增多时并不会影响它的接收速度,同时当系统开始对数据进行处理后,消费速度和生产速度基本相同,表明系统运行良好并且较为稳定
表1显示了本文设计的topology在集群中的运行状态,通过结果可以看出,使用Storm集群处理用户行为数据时,在短时间内可以处理大量数据,并且失败数较小,达到了设计系统的预期效果。

图6 系统中数据存储和消费情况
表1 topology状态表
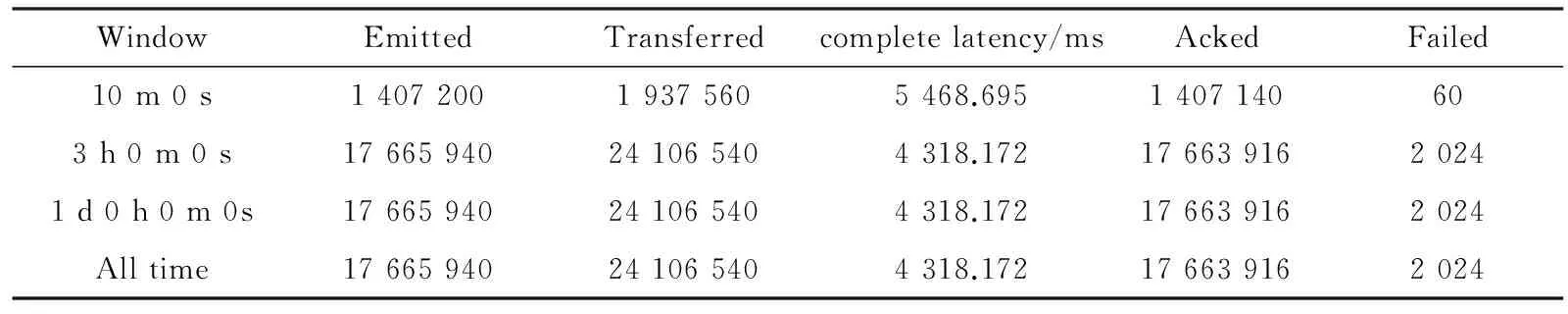
WindowEmittedTransferredcompletelatency/msAckedFailed10m0s140720019375605468.6951407140603h0m0s17665940241065404318.1721766391620241d0h0m0s17665940241065404318.172176639162024Alltime17665940241065404318.172176639162024
如表2所示,当仅使用C4.5决策树算法对用户行为数据进行分类时,当数据量较小时,准确率较高,但是数据量增大时,准确率开始下降。当在C4.5决策树算法之前加入数据预处理后能够明显地去除噪声等无效数据对分类效果的干扰,但是分类效果并不理想。最后使用数据预处理并且在C4.5决策树种增加了移动网络上下文,随着数据量的不断增大,分类效果也越来越准确,达到了设计的预期效果。
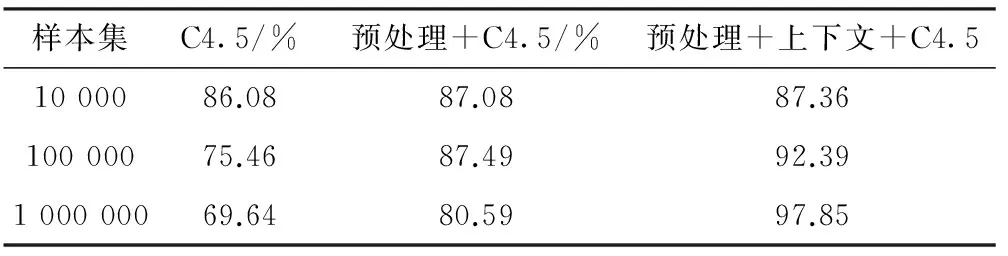
表2 3种方法的准确率比较
5 结束语
本文提出了一个分布式移动网络用户行为分析系统,与传统的用户行为分析相比,该系统引入了移动网络上下文同时对海量数据进行数据预处理,最后利用C4.5决策树算法进行兴趣分类,得到了更为可靠和准确的分析结果。并且在面对呈现爆炸性增长的移动网络用户行为数据,通过采用分布式框架对系统进行设计,提高了系统处理大数据的能力,并且提高了系统的可扩展性。最后通过实验数据表明,移动网络用户行为分析系统是一个切实可行的方案。
[1] 王攀,张顺颐,陈雪娇.基于动态行为轮廓库的Web用户行为分析关键技术[J].计算机技术与发展,2009,19(2):20-23.
[2] 王继民,李雷明子,孟凡,等.基于用户日志的移动搜索行为分析[J].图书情报工作,2013,57(19):102-106,120.
[3] 马安华.基于用户王继民行为分析的精确营销系统设计与实现[D].南京:南京邮电大学,2013.
[4] Anind K Dey.Understanding and using context[J].Personal and Ubiquitous Computing, 2001,5(1):4-7.
[5] 刘明月.基于Web日志的用户行为分析[D].北京:北京交通大学,2008.
[6] Sanjay Kumar Dwivedi,Bhupesh Rawat.A review paper on data preprocessing:A critical phase in web usage mining process[C].Noida:Green Computing and Internet of Things, IEEE,2015.
[7] Amany Abdelhalim,Issa Traore.A new method for learning decision trees from rules[C].Miami Beach:International Conference on Machine Learning and Applications,IEEE,2009.
[8] Quinlan J R.Induction of decision trees[J].Mach Learn,1986(1):81-106.
[9] Breiman L,Friedman J H,Olshen R A,et al.Classification and regression trees[M]. California:Wadsworth,1984.
[10] Kotsiantis S B.A review of classification techniques[J].International Journal of Computing and Informatics,2007,31(3):249-268.
[11] Quinlan J R.C4.5:programs for machine learning[M].San Francisco:Morgan Kaufmann,1993.
[12] Anderson Q.Storm real-time processing cookbook[M].Birmingham:Packet Publishing,2013.
[13] Patrick Hunt,Mahadev Konar,Flavio P,et al.Zookeeper:wait-free coordination for internet-scale systems[C].Boston:USENIX Annual Technical Conference,2010.
[14] Kreps J,Narkhede N,Rao J,et al.Kafka:a distributed messaging system for log processing[C]. Athens:Workshop on Networking Meets Databases,ACM SIGMOD,2011.
[15] Bellavista P, Corradi A, Reale A.Quality of service in wide scale publish/subscribe systems[J].Communications Surveys and Tutorials,2014(16):1591-1616.
[16] Zhao J,Sun Z,Liao Q.Implementation of k-means based on improved storm model[C].Guilin: Proceedings of ICCT2013,IEEE,2013.
[17] Skeirik S, Bobba R B,Meseguer J.Formal analysis of fault-tolerant group key management using zookeeper[C].Delft:2013 13th IEEE/ACM International Symposium on Cluster,Cloud and Grid Computing,IEEE,2013.
[18] Brian O’Neill,P Taylor Goetz.Storm blueprints:patterns for distributed real-time computation[M].UK:Pacekt Publishing Ltd,2014.
Distributed Mobile Network User Behavior Analysis System
CHEN You
(School of Optical-Electrical and Computer Engineering, University of Shanghai for Science and Technology, Shanghai 200093, China)
A distributed mobile network user behavior analysis system based on data preprocessing, context and C4.5 decision tree is proposed to provide better personalized service for mobile Internet users. The system is implemented by the distributed open source framework zookeeper, kafka and storm. Implementation of the system shows the proposed system offers accurate analysis of user interest classification without affecting system performance even in the face of massive user behavior data.
preprocessing; context; decision tree; distributed; user behavior analysis
2016- 08- 09
陈友(1991-),男,硕士研究生。研究方向:数据挖掘。
10.16180/j.cnki.issn1007-7820.2017.05.042
TP393.07
A
1007-7820(2017)05-154-05
