语义与统计相结合的中文微博相似度计算方法
2017-05-17李楚贞
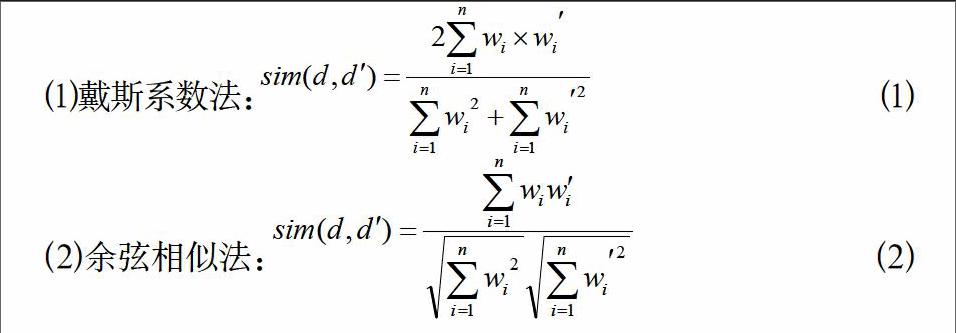

摘要:文本相似度在自然语言处理领域中有着广泛的应用。基于语义的相似度计算方法能比较准确地反映词语之间的复杂关系,而基于统计的相似度计算方法能发掘词语中潜在的相关性。微博文本具有稀疏性、实时性、不规范性等特点,文章在综合两者优势的基础上,提出了一种语义和统计相结合的中文微博相似度计算方法。实验证明该方法在各项指标上都优于单一的相似度计算方法。
关键词:相似度计算;语义;统计
中图分类号:TP391.1 文献标识码:A 文章编号:1007-9416(2017)03-0231-02
文本相似度计算在文本分类、文本聚类、信息检索等自然语言处理领域有着广泛的应用。相比词语相似度计算,文本相似度计算不仅要识别句子结构、语义关系,还要考虑语境问题。针对这一问题,目前许多研究是把文本相似度计算转换为计算文本中词语之间的相似度,它通常是通过抽取出文本中所有的名词和动词,再计算它们之间的相似度。
目前,常用的文本相似性计算方法主要有基于语义的相似度计算方法和基于统计的相似度计算方法。基于语义的相似度计算方法能较准确地反映出词语之间的复杂关系,但它需要借助本体论,而本体论资源的是否完整又决定了这种计算方法的准确性。基于统计的相似度计算方法计算量大,且需要大规模的文本集,而文本集质量的好坏又直接决定计算结果的优劣。微博文本具有稀疏性、实时性、不规范性等特点,导致传统的相似度计算方法都很难适用。因此,本文把基于语义和基于统计的计算方法两者结合起来,提出一种组合相似度计算方法,即语义和统计相结合的相似度计算方法。
1 常见相似度计算方法
1.1 基于语义的文本相似度计算
基于语义的文本相似度计算常以本体论作为背景知识。目前常用的本体论主要有Framenet、Wordnet和Hownet(知网),而Hownet(知网)是最为著名的采用汉语描述的本体论。在知网中,用概念来对词汇语义进行描述,每个词可以表达为几个概念,而概念又由义原来描述。对于同义词、近义词不仅用来表述它的义原是确定的,而且义原的组合形式也是确定的。在计算词汇语义相似度时,较多是采用刘群、李建素提出的基于《知网》的词汇语义相似度计算公式,即,各符号代表详见文献[1]。
1.2 基于统计的文本相似度计算
基于统计的文本相似度计算方法中最常用的是基于向量空间模型的TF-IDF方法。向量空间模型是1975年Salton等人提出,它是被广泛使用的模型之一。它把每一个文本表示成一个向量,向量的每一维表示文本的一个特征[2],形式为:,其中,为特征项在文本中的权值,为特征集的大小[3]。计算特征项的权值使用TF-IDF公式,即,其中,表示特征项在文本中出现的次数,N表示全部文本数目,表示出现特征项的文本数。现假设有两个文本,,则与之间的相似度计算可用下面几种常用的方法:
2 语义与统计相结合的中文微博相似度计算
本文综合基于语义和基于统计两种相似度计算的优势,提出了语义与统计相结合的中文微博相似度计算方法。下面详细介绍其算法。
2.1 算法第一步,即计算基于语义的文本相似度
在计算微博文本的相似度时,必须对每条微博文本进行预处理,如分词、词性过滤、停用词过滤、词频统计。经过预处理后,每条文本只剩下高频的、有实际意义的动词和名词。本文考虑到不同詞性的词语在语义上其相似度比较低,所以在进行语义相似度计算时先进行词性分类表示,即把文本向量中词性为名词的归为一类,词性为动词的归为另一类。假设微博文本用向量表示为={},如果是名词,是动词,则词性分类后该文本向量表示为={},再分别计算文本中名词集合和动词集合的相似度,最后加权平均,得到的就是两条微博文本的语义相似度。
3 实验结果与分析
在验证算法的有效性之前需要先确定它的加权系数,即和的取值。本文抓取新浪微博数据7124条,利用SinglePass算法分别计算和9种不同取值的F值。实验结果证明,为0.4,为0.6时,F值最大,因此,本文提出的组合相似度计算公式中取0.4,取0.6[6]。
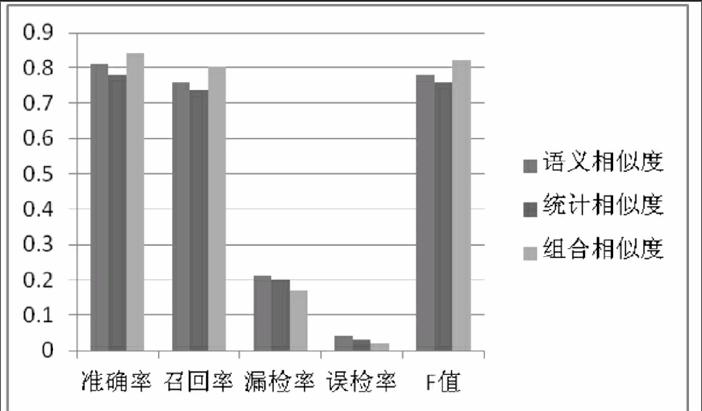
为了验证组合相似度算法的有效性,本文借助SinglePass算法分别比较语义相似度、统计相似度和组合相似度三种不同计算策略的性能,结果如图1所示。
通过图1可以看出,相比语义相似度和统计相似度,采用组合相似度计算策略在各项性能指标上都比较好,这说明引入词汇语义和相关度的相似度策略能够更好地识别相关的主题。
参考文献
[1]刘群,李素建.基于《知网》的词汇语义相似度计算[C]//第三界汉语词汇语义学研讨会.台北,2002:59-76.
[2]Salton G,Wong A,Yang C S. A Vector Space Model for Automatic Indexing[J]. Communication of the ACM, 1975,18(11):613-620.
[3]郑庆华,刘均,田锋,孙霞.Web知识挖掘:理论、方法与应用[M].北京:科学出版社,2010.
[4]赵应秋,罗军,张君艳.基于知网的词语语义相关度计算[J].信息技术,2010(3):90-93.
[5]Peat H J,Willet P.The limitations of term cooccurrence data for query expansion in document retrieval systems.Journal of American Society for Information Science,1991,42(5):378-383.
[6]李楚贞.中文微博主题层次识别方法研究[D].广东技术师范学院,2014.
