基于借阅信息的图书个性化推荐算法研究
2017-05-17刘高军李越洋
刘高军++李越洋

摘要:随着出版行业日益发展,高校图书馆图书同样日益增多,然而高校图书馆目前存在个性化图书推荐不精确甚至没有个性化图书推荐的现象。本文通过我校图书馆近十年的借阅记录,提出一种新的个性化图书推荐方案,考虑读者的借阅特征以及时间相关因素,最终提高推荐精确度。该方案的核心主要分为两个部分,首先利用基于用户的协同过滤算法对推荐结果进行粗召回。第二步利用特征提取算法对借阅记录进行特征提取,除了用户的基本特征,例如年级、专业、性别等信息之外,还包括了读者借阅图书的类别、借阅时间点、借阅时长、借阅次数、近一段时间借阅了哪些书等特征维度。根据提取的特征对数据进行训练,确定用户的偏好模型,从而预测读者对图书的评分,根据评分排序进行精确推荐。
关键词:图书推荐;借阅特征;协同过滤;特征提取
中图分类号:G250.71 文献标识码:A 文章编号:1007-9416(2017)03-0156-03
1 引言
目前高校图书馆的馆藏资源通常成千上万,而且种类繁多,因此读者会花费大量的时间用于寻找自己感兴趣的图书。而随着图书行业的繁荣,书目与种类日益增多。传统的搜索引擎已经不能完全的满足读者对图书的辨识。因此,针对这种信息获取的困难,出现了许多针对于个性化图书推荐系统的相关研究。
目前高校图书馆的推荐系统存在以下一些问题。第一,推荐系统不够个性化,一些高校的图书推荐模块仅仅是依靠于借阅量以及根据借阅记录基于图书本身的内容进行推荐。第二,许多个性化图书推荐系统虽然采用协同过滤的技术,实现了个性化,但是协同过滤算法本身依赖于用户对项目的评分,而大部分高校图书馆的借阅记录中都没有读者对图书的评分这一项。第三,由于数据稀疏性的原因,导致一些没有借阅过的或被借阅次数很少的图书无法被有效的推荐给其他人。
如之前所说,协同过滤依赖于用户对物品的评分,而对于高校图书馆,如何根据读者的借阅记录将其特征转化为对图书的评分,从而提高推荐的准确性。是本文研究的重点。同时,本文也将根据借阅记录提取与时间相关的特征,考虑时间因素,例如图书借阅的先后顺序,或者在某些大型综合考试如英语四、六级考试前为读者推荐相关的图书。
本文的核心步骤主要分为两大类:
(1)利用基于用户的协同过滤算法对推荐结果进行粗召回。
(2)利用特征提取算法对用户及借阅记录进行特征提取,构建读者偏好模型。
本文第2节介绍了个性化推荐方法的研究工作,第3节详细阐述本文提出方案的具体原理;第4节是关于本文提出的推荐方案在真实数据集上的实验分析与讨论;最后第5节给出结论和未来的工作。
2 方案原理
该方案主要分为两个部分,第一部分利用基于协同过滤算法对借阅记录进行推荐,得出一个粗召回的结果集。第二部分利用特征提取算法对借阅记录进行特征提取,将提取的特征以向量的形式作为读者偏好模型的维度,训练读者的偏好模型。
2.1 推荐算法比较
推荐算法比较,当前,个性化推荐方法通常采用三类核心推荐算法[1]:(1)基于关联规则的推荐算法(Association Rule-based Rcommendation);(2)基于内容的推荐算法(Content-based Rcommendation);(3)基于协同过滤的推荐算法(Collaborative Filtering Rcommendation)下面闡述三类推荐算法的原理以及优缺点。
基于关联规则的推荐算法是以关联规则为基础,研究的核心问题即项目集A与其他项目集的关联关系。直观的意义就是对图书A偏好的读者又借阅了图书B和C,那么可以说B与C和A存在关联关系。比如借阅了大数据相关图书的读者一般还会借阅hadoop相关的图书。基于关联规则的推荐算法优点在于算法的复杂程度,因此可以深度挖掘读者的兴趣偏好,提高推荐精准度。缺点在于算法实现较为复杂,如何在成百上千万的项目中计算每个项目之间的关联规则是算法的核心和难点,因此生成个性化推荐结果较为耗时。
基于内容的推荐算法,是以产生关系的项目为中心,提取项目的特征,寻找与该项目相似的其他项目推荐给用户,例如读者借阅了朱自清的散文集,可能也会对冰心的散文感兴趣。基于内容的推荐算法在图书推荐方面优点在于,不存在冷启动问题,即对新书以及新读者都比较容易产生推荐,缺点在于不够个性化,不能挖掘出读者深度的兴趣偏好。
基于协同过滤的推荐算法是当前个性化推荐领域中最流行的推荐算法。它包括两大类,一是基于用户的协同过滤,二是基于项目的协同过滤[2]。以基于用户的协同过滤为例,它的原理就是利用用户与项目之间的评分计算目标用户与每个用户的相似度,根据相似度的排序选定最近邻用户[3],将近邻用户中所产生关系的项目中选取目标用户没有产生关系的项目作为推荐项目推荐给目标用户。同理,基于项目的协同过滤是计算项目间[4]的相似度从而产生项目间的近邻,生成推荐。基于协同过滤的推荐算法优点很明显,就是与内容无关,通过计算用户的相似度,来深度挖掘用户的潜在兴趣,真正的可以实现个性化推荐。由于算法的基础是依赖于用户与项目之间的作用关系,因此基于协同过滤的推荐算法缺点在于冷启动问题,即对新用户或新项目的推荐不够好。
2.2 基于用户的协同过滤算法
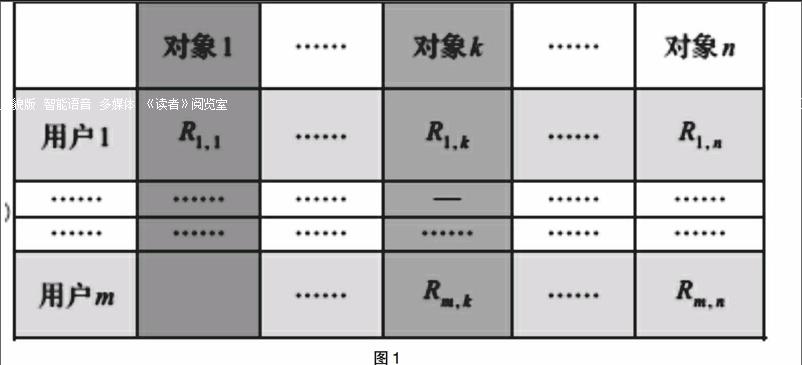
综合上一小节,由于基于协同过滤的推荐算法是目前推荐领域的主流,而且它可以实现真正的个性化推荐,因此本文中提出的推荐方案第一部分选取基于协同过滤的推荐算法。基于用户的协同过滤算法第一步是生成用户-项目的评分矩阵,如图1所示是一个m x n的二维矩阵。其中m表示用户数,n表示项目数,Rm,n表示用户m对项目n的评分。由于本文的研究背景是高校图书馆的借阅记录,没有读者对图书的评分项,因此只记录其作用关系,即借阅过的记为1,未借阅的记为0。
基于用户的协同过滤第二步是生成根据用户-项目矩阵生成最近邻用户,这个过程的本质相当于为目标用户在矩阵R中计算一个相似性的排序集合。计算用户相似度的方法主要有2种:
(1)余弦相似性(Cosine):设用户i 和用户j 在m维对象空间上的评分表示为向量i,j,则sim(i,j)的相似性计算方法如下:
(2)相关相似性(Correlation):设用户i 和用户j 共同评分的对象集合用Iij 表示[5],则用户i 和用户j 之间的相似性通过Pearson 相关系数度量,方法如下:
基于用户的协同过滤第三步是生成推荐结果,由第二步计算得出目标用户的最近邻集合,设用户u的最近邻用户集合为Su,则用户u对项目i的预测评分Pu,i可以通过用户u对最近邻用户集合Su中的项目评分得到[6]。计算公式如下:
其中sim(u,n)表示用户u与用户n之间的相似性,Rn,i表示用户n对项目i的评分,Rn分别表示用户u和用户n对项目的平均评分。
2.3 利用特征提取算法对借阅记录进行特征提取
上一小节阐述了本文中推荐方案的第一部分,即利用协同过滤算法对推荐结果集进行粗召回,可以对阈值进行设置,产生大量的可能的推荐对象。而研究背景的借阅数据中,存在很多的可以描述用户兴趣偏好的特征,因此,本节阐述的是推荐方案中的第二部分,即利用特征提取算法对借阅记录进行特征提取,建立用户偏好模型。通过实际数据对模型进行训练,最终产生更精确的推荐结果。
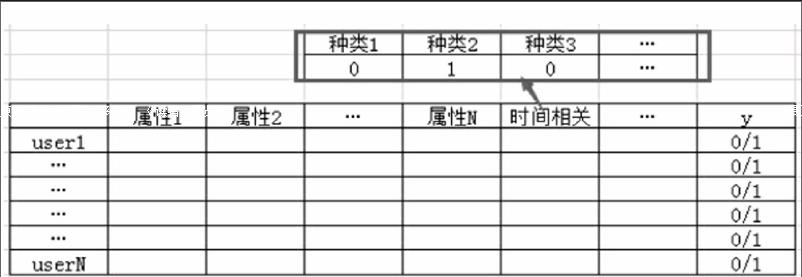
本文的研究背景是基于高校图书馆的借阅记录,而借阅记录是表示读者兴趣偏好的直接来源。因此,如何对读者的借阅记录进行特征提取,建立兴趣偏好模型,是提高推荐精确度的关键。也是本文中推荐方案的第二部分的核心。以我校图书馆的借阅数据分析,其中包括三类特征信息,第一类是用户的基本信息,第二类是图书的特征信息,第三类是关于借阅行为的特征信息。包括的特征可以整理为:
通过上述整理的特征构建读者-特征矩阵,如图2。
y值表示user(i)最终是否借阅了图书,利用读者每一年的数据中第一学期的和第二学期的一部分作为训练集,余下的部分作为测试集。建立读者偏好模型。利用偏好模型,对该推荐方案中第一部分粗召回结果集进行评分拟合。按照拟合评分的排序结果,产生最终优化的推荐结果。
目前,利用机器学习技术领域中相关的有监督学习算法,可以对数据进行建模,并训练模型。最终根据兴趣偏好模型拟合推荐结果集。
GBDT(Gradient Boosting Decision Tree) 又叫 MART(Multiple Additive Regression Tree),GBDT模型是一种解决回归问题的树模型,本质是一种迭代的决策树算法。该算法由多棵决策树组成,所有树的结论累加起来做最终结果。它在被提出之初就和SVM一起被认为是泛化能力较强的算法。GBDT主要有三个部分组成:
(1)DT:回归树 Regression Decision Tree。GBDT的核心在于累加所有树的结果作为最终结果,而分类树的结果显然是没办法累加的,所以GBDT中的树都是回归树,不是分类树。
(2)Boosting,迭代,即通过迭代多棵树来共同决策。GBDT的核心就在于,每一棵树学的是之前所有树结论和的残差,这个残差就是一个加预测值后能得真实值的累加量。
(3)Shrinkage即缩减。Shrinkage的思想认为,每次走一小步逐渐逼近结果的效果,要比每次迈一大步很快逼近结果的方式更容易避免过拟合。即它不完全信任每一个棵残差树,它认为每棵树只学到了真理的一小部分,累加的时候只累加一小部分,通过多学几棵树弥补不足。
目前来说,GBDT几乎可用于所有回归问题(线性/非线性),相对logistic regression仅能用于线性回归,GBDT的适用面非常广。亦可用于二分类问题(设定阈值,大于阈值为正例,反之为负例)。
3 实验
3.1 实验数据
本文的研究背景是高校图书馆,因此本文实验数据采用北京市某高校的图书馆借阅记录作为本文所提出方案的实验数据。数据涵盖了近10年200万条借阅记录,20万条图书信息以及17000的读者信息。
3.2 实验评价
对于推荐领域而言,对于推荐结果的评价标准一般从如下几个方面考虑:推荐准确度、推荐结果的多样性以及推荐结果的覆盖性等。由于本文的研究背景是面向高校读者的图书个性化推荐,因此选取当前推荐领域普遍采取的评价标准,即准确度指标。
准确度是当前推荐领域对推荐算法结果评价中最常用、最基础也是最普遍的指标。大部分的推荐算法都采用准确度指标来衡量一个推荐算法的好坏。准确度指标的原理是通过描述预测打分与用户实际打分的相似程度来评估结果。目前,对于准确度指标的衡量方法最常用的是平均绝对误差(Mean Absolute Error , MAE)。MAE通过计算预测用户评分和实际用户评分之间的偏差来度量预测的准确性[5]。MAE越小,推荐质量越高。平均绝对误差(MAE)的计算公式如下:
其中,c为用户i所产生关系的项目数量,ria为用户的实际评分,via为推荐算法的预测评分。
3.3 实验结果
为了检验本文所提出方案中的推荐算法,我们将以传统的仅仅依靠于协同过滤算法作为对照,在传统的协同过滤算法中,分别以余弦相似性和相关相似性作为相似性的度量标准,分别计算其MAE。并设置近邻个数从20增加到40,间隔为5。然后与本文提出的推荐算法作比较,由数据可以看出,本文提出的推荐方案,即在基础的协同过滤算法之上对借阅记录进行特征提取,根据实际情况提取更能代读者兴趣偏好的特征,构建读者偏好模型,最终得到的推荐结果,相比仅仅依靠于协同过滤算法得到的推荐结果。具有较小的MAE。因此,本文提出的推荐算法可以针对于高校图书馆的研究背景得出更精准的推荐结果。
4 结语
随着图书行业的繁荣,读者需要在浩瀚的图书海洋中选择自己感兴趣的图书。因此一个好的推荐系统起着至关总要的作用。本文所阐述的推荐方案能够根据现有的数据进行有效的推荐,但是仍存在着一些其他问题,例如冷启动、数据稀疏等问题。这些问题也是整个推荐领域需要进一步研究的问题。
参考文献
[1]Hofmann,T.Latent Semantic Models for Collabora—tive Filtering[J].ACM Transactions on Information Systems,2004,22(1).
[2]陳梅.图书馆知识服务新模式——个性化推荐系统问题和算法实现研究[J].图书情报工作网刊,2012,(05):6-12.
[3]李烁朋.基于大众标注和HOSVD的推荐系统研究[D].江苏科技大学,2013.
