一种大数据智能分析平台的数据分析方法及实现技术
2017-05-17蓝科李婧
蓝科+李婧
摘要:文章介绍了一种用于大数据智能分析平台的数据分析方法及实现技术,介绍了这种方法的需求和意义;和该方法的总体架构,以及在数据传输、数据清洗和数据分析的实现;概述了这种技术高并发、大数据量的优化措施和跨平台的实现。
关键词:大数据;数据分析;数据挖掘
中图分类号:TP311 文献标识码:A 文章编号:1007-9416(2017)03-0104-02
1 综述
1.1 简介
在数字化时代,需要新一代系统架构提升业务创新能力。在新一代系统架构中,大数据是核心要素。业务应用能否自主发现与自助获得高质量的大数据,就成为业务创新成败的关键。这就要在搭建大数据平台时,就着手大数据治理相关建设。
1.2 需求和意义
从某种意义上说大数据治理架构需要以元数据为核心、提高大数据质量、透明化大数据资产、自助化数据开发、自动化数据发布、智能化数据安全,提升大数据平台服务能力,让大数据平台变得易使用、易获得、高质量。
但是,目前很多技术解决方案存在诸多安全和效率隐患:业务系统多,监管力度大;数据量庞大且呈碎片化分布,急需提升大数据质量;数据格式不规范、难以在短时间内找到所需数据;数据在各阶段的应用角度不同,需要降低系统间的集成复杂度。
2 功能设计
2.1 总体架构
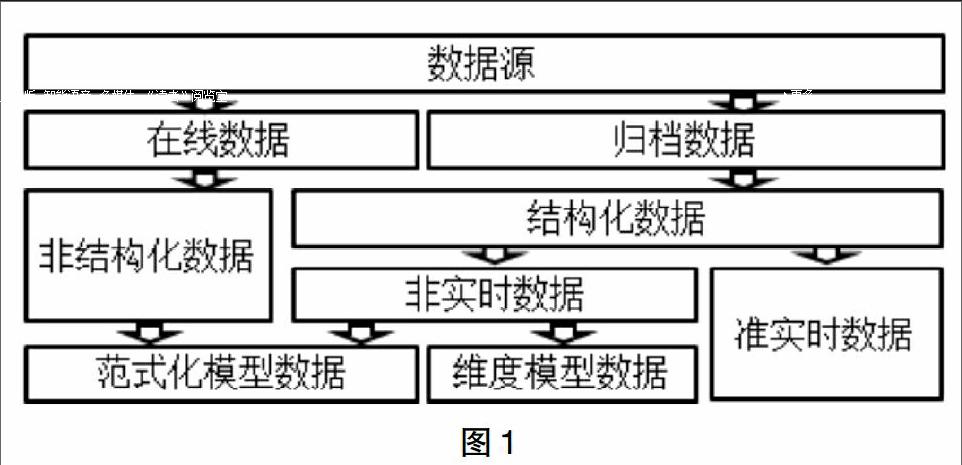
本文讲述的数据分析方法及实现技术是建立在Hadoop/Spark技术生态圈的基础之上,以实现用户集成处理、、清理、分析的一个统一的数据处理平台;按数据类别分为线数据、归档数据;按数据格式分为非结构化数据、结构化数据;按数据模型分类为范式化模型数据、维度模型数据;按数据采集频度分为非实时数据、准实时数据处理架构;并提供数据中心平台与安全管理方案,为企业级用户建立一个通用数据处理和分析中心。如图1所示。
2.2 在线数据
在线数据在线通过接口去获得的数据,一般要求为秒级或速度更快。首先应当将数据进行区分:在线数据、或归档数据。本平台中采用:Storm或Spark Streaming框架进行实现。Spark Streaming将数据切分成片段,变成小批量时间间隔处理,Spark抽象一个持续的数据流称为DStream(离散流),一个DStream是RDD弹性分布式数据集的micro-batch微批次,RDD是分布式集合能够并行地被任何函数操作,也可以通过一个滑动窗口的数据进行变换。
2.3 归档数据
归档数据是在线存储周期超过数据生命周期规划的数据,处理的要求一般在分钟级或速度更慢。通常归档数据的计算量、数据量、数据复杂度均超过试试数据处理。本平台中采用:Hadoop、Spark技术生态体系内的框架进行计算,这里不详细阐述。
2.4 非结构化数据
通常非结构化的数据不一定具备字段,即使具备字段其长度也不固定,并且字段的又可是由可不可重复和重复的子字段组成,不仅可以包含结构化数据,更适合处理非结构化数据。常见的非结构化数据包括XML、文本、图象、声音、影音、各类应用软件产生的文件。
针对包含文字、数据的为结构化数据应当先利用数据清洗、数据治理工具进行提取,这项工作目前仍依赖技术员进行操作,由于格式的复杂性所以难以使用自动化方式进行较为高效的批处理。在治理数据的过程中,需要根据情况对数据本身额外建立描述数据结构的元数据、以及检索数据的索引服务,以便后续更佳深度利用数据。
2.5 结构化数据
结构化数据具备特定的数据结构,通常可以转换后最终用二维的结构的数据,并且其字段的含义明确,是挖掘数据价值的主要对象。
本平台中主要使用Hadoop Impala和Spark SQL来进行结构化数据的处理。Impale底层采用C++实现,而非Hadoop的基于Java的Map-Reduce机制,将性能提高了1-2个数量级。而Spark SQL提供很好的性能并且与Shark、Hive兼容。提供了对结构化数据的简便的narrow-waist操作,为高级的数据分析统一了SQL结构化查询语言与命令式语言的混合使用。
结构化数据根据采集频度可以继续分类为:非实时数据、准实时数据。
2.6 准实时数据
通常准实时数据是指数据存储在平台本身,但更新频率接近于接口调用数据源的数据。适合用于支持数据和信息的查询,但数据的再处理度不高,具有计算并发度高、数据规模大、结果可靠性较高的特点。通常使用分布式数据处理提高数据规模、使用内存数据进行计算过程缓冲和优化。本平台主要采用Spark SQL结合高速缓存Redis的技术来实现。Spark SQL作为大数据的基本查询框架,Redis作为高速缓存去缓存数据热区,减小高并发下的系统负载。
2.7 非实时数据
非实时数据主要应用于支持分析型应用,时效性较低。通常用于数据的深度利用和挖掘,例如:因素分析、信息分类、语义网络、图计算、数值拟合等。
非实时数据根据数据模型可继续分类为:范式化模型数据、维度模型数据。
2.8 范式化模型
范式化模型主要是针对关系型数据库设计范式,通常數据是采用第三范式3NF或更高范式。面向近源数据查询、数据主题的整合。范式化模型数据的数据存储区,建议使用并行MPP数据库集群,既具备关系型数据库的优点,又兼顾了大数据下的处理。
2.9 基于维度模型
维度模型数据主要应用于业务系统的数据挖掘和分析。过去多维度数据处理主要依赖OLAP、BI等中间件技术,而在大数据和开源框架的时代下,本技术平台采用Hadoop Impala来进行实现。Impala并没有使用MapReduce这种不太适合做SQL查询的范式,而是参考了MPP并行数据库的思想另起炉灶,省掉不必要的shuffle、sort等开销,使运算得到优化。
3 应用效果
本系统在不同的业务领域上都可以应用,以2016年在某银行的应用案例为例:该银行已完成数据仓库建设,但众多数据质量问题严重影响了数据应用的效果,以不同的数据存储方式,以更高的要求去进行数据的统一管理。通过组织、制度、流程三个方面的实施,以元数据、数据标准、数据质量平台为支撑,实现了数据管控在50多个分支,60个局,1000余处的全面推广,实现了全行的覆盖;管理了120个系统和数据仓库,显著提升了新系统的快速接入能力;通过14个数据规范和流程明确了数据管控的分工;数据考核机制的实施,使其在数据质量评比中名列前茅。
4 结语
本文介绍了大数据下数据分析方法及实现技术的大体设计和思路,从需求分析、总体架构和数据处理以及数据分析这几个方面来介绍。文章在最后介绍出了这种平台的应用效果。笔者相信这些思路和技术能够在业务中能得到很好的应用。
参考文献
[1]孙明,李素蕊.高性能计算机的海量数据处理平台实现与评测[J].电子技术与软件工程,2015(04).
[2]李学龙,龚海刚.大数据系统综述[J].中国科学:信息科学,2015(01).
