基于神经网络的微博话题预测及分析
2017-05-17张琳
张琳
摘要:提出了基于神经网络的微博话题预测与分析系统,介绍了此系统的整体结构与流程,并说明了该系统具有抓取话题信息及其相关内容、建立数据库、热门话题预判等功能,从各个角度表明该系统对商业情报分析、行业调研、信息安全、网络舆情预警十分具有研究意义,本文对系统其中的数据处理和分析这一流程进行了重点阐述,并法分别阐述了固定权重、函数构建和神经网络这三种算法的主要内容、公式以及它们优缺点,并且对神经网络训练这一过程进行了仿真结果分析。我们采取三种算法相结合的方法来进行数据处理,对话题热度进行预判,可以综合三种方式的优点,避免一些缺点。系统将这三种方式相结合,使其更加贴近人类思考方式,提高预测准确度。
关键词:话题热度;权重;神经网络
中图分类号:TP393 文献标识码:A 文章编号:1007-9416(2017)03-0082-02
1 引言
近几年,社交网络飞速发展,各大社交媒体的用户量呈指数性上升,微博也成为人们获取和发布信息的重要渠道,其热门话题也已经成为了网络热点的风向标。微博话题预测与分析,可向用户提供了解热门信息的渠道,还能节省时间;对于网络社交媒体网站的管理人员来说,可以帮助他们更好的了解用户群体的喜好;对于企业来说,能帮助他们迅速了解市场动向,为业务决策提供数据支持和指导[1];对于政府来说,有助于了解民众关注点与文化道德倾向,为施政方向提供参考等等。本文提出了将神经网络的思想应用在话题预测中,使微博话题更有预见性,提高预测准确度。
2 系统结构
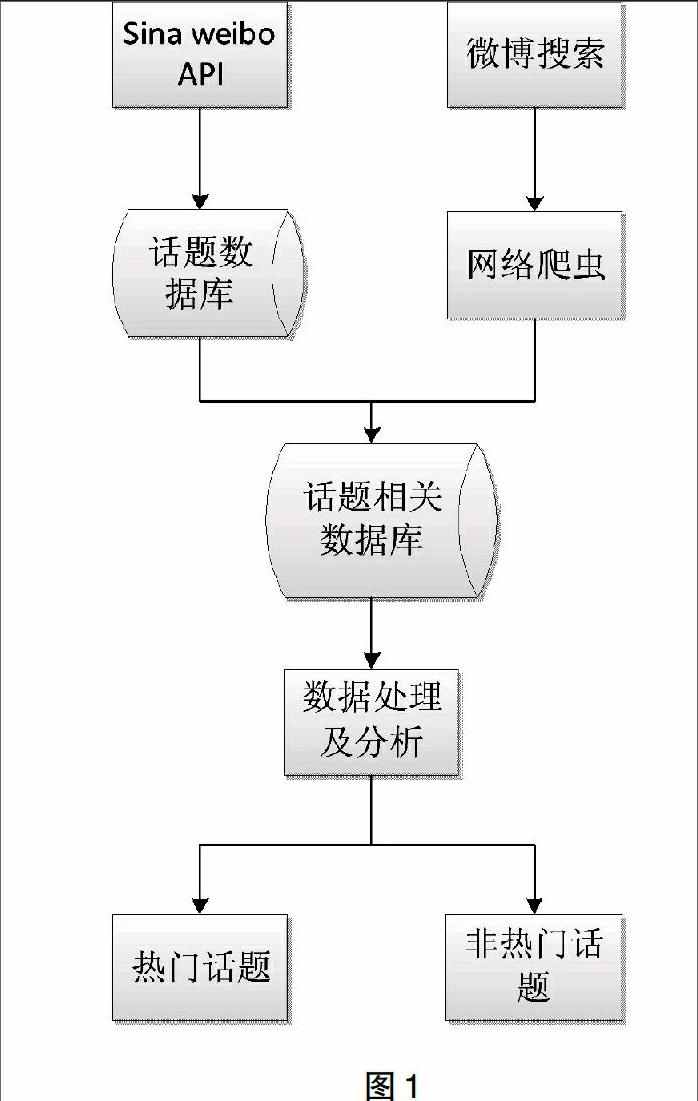
系统的整体结构如图1所示。首先从新浪微博开放接口中获取并识别出话题信息,建立话题数据库,并通过网络爬虫技术从微博搜索中抓取到与话题有关的微博数据,均进行特征提取[2]后分类存入话题相关数据库中,对这些数据处理和分析后作出预判哪些话题为热门话题,哪些为非热门话题。本文将主要阐述数据处理分析这一过程中用算法实现对热门话题的预判这一流程。
3 神经网络
3.1 固定权重计算
权重,即将话题热度分为阅读量、转发量、增长率等影响因子,为其中每种影响因子分配各自的系数。最终将各项影响因子与其系数相乘再进行累加可得到话题热度。这种方式的优点是划分精细,可根据测试后数据增减影响因子,改动系数,但其缺点明显,自适应能力差,所需数据量太过庞大。其计算公式为:
(1)
式(1)中,T表示话题热度,表示权重,表示影响因子。
3.2 构建函数计算
根据各项数据之间的关系,可以简单地抽象为一个热度得分与权重的线性关系,得分越高,对应权重在有限范围内同比上升。这种方式需要在前期获取大量数据进行测试和构建函数模型,最后得到话题热度。利用这种方式,我们可以在一定程度上进行简单的话题预测模拟。其具有较为清晰的逻辑,编程较为简单的优点,缺点是需要大量的真实数据来构建函数模型。其计算公式为:
(2)
式(2)中,T表示话题热度,表示权重上限,表示权重下限,表示此话题下内容条数上限,此话题下内容条数下限,表示当前内容条数。
3.3 神经网络算法
神经网络算法是指让机器模拟逻辑性的思维,根据逻辑规则进行推理的过程。人工神经网络按照一定的学习准则,自发发现环境特征和规律性,减少下次犯错的可能性,达到高准确度的理想状态[3]。其优点是模拟人类思考的方式,对话题热度预测的方式更加人性化,自适应力强,通过大量的训练课提高预测的准确性,但它的编程比较困难,逻辑比较复杂。神经网络训练公式:
(3)
式(3)输入样本X根据误差e对权重A不断调整,直到e接近零;表示权重变化率,其取值不能过大或过小,过大会影响权重的稳定,过小会使调整权重时收敛太慢。
3.4 概述
我们的方法综合利用了以上三种思想。我们首先将话题的阅读量、评论数、粉丝数按照一定比例赋予固定的权重,存入基本库,得到热度基值;而对于一些比较抽象的影响因子,例如名人效应、时效性、内容生动性、国家政策等没有明显划分标准的因素,我们首先利用一些少量的数据来构建一个简单的函数,提取内容特征来并建立附加库,再通过神经网络算法思想利用训练数据来不断调整权重,丰富并完善附加库,最终得到热度附加值。最后,将热度基值与热度附加值相加得到话题热度。
4 测试结果与分析
4.1 神经网络算法应用
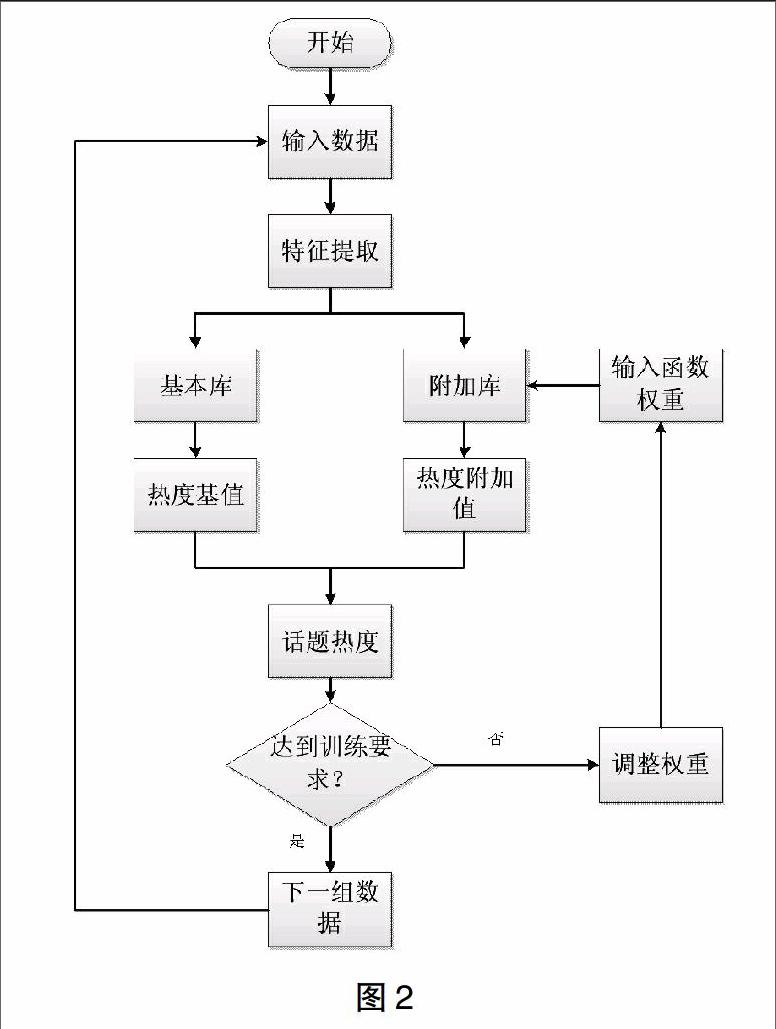
输入训练数据,先根据当前的权重计算,看误差是否達到训练要求,若没有则对权重进行调整,直到误差接近于零,计算出的结果与训练数据的结果一样,然后再进行下一组数据的读取,重复以上步骤,直到所有结果达到训练要求。其神经网络算法流程图如图2。
4.2 模拟结果与分析
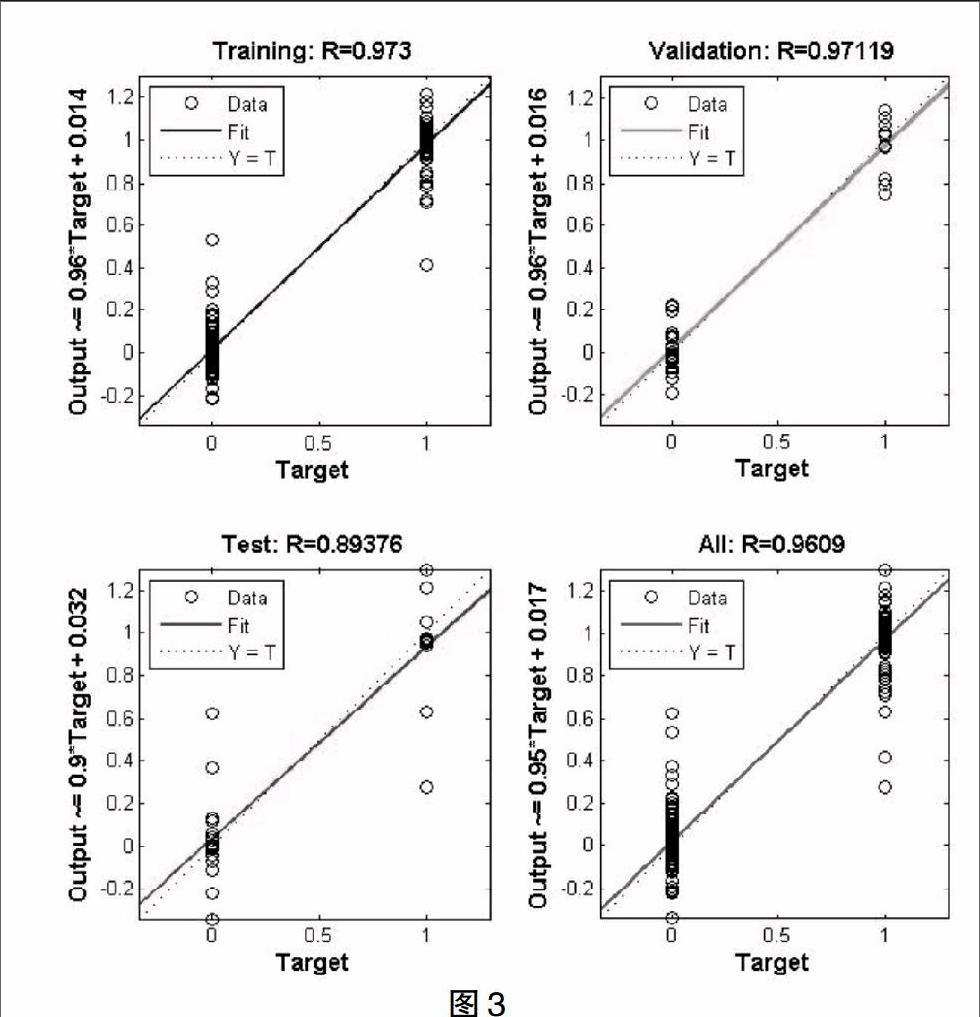
如图3,在做神经网络训练预测时,我们采取两个点做回归分析。横坐标为目标值target,纵坐标神经网络输出。为防止过拟合,我们运用matlab对数据划分成三分,trainning表示训练,validation表示验证,test表示测试,最后统计了整体状况all,只有trainning数据参加训练,其他两组数据不参加训练,用于检验。训练进行时,目标target和训练test数据之间的误差会越来越小,validation数据和目标之间的误差也越来越小,曲线也越来越接近对角线。
5 结语
本文对微博热门话题预测进行了分析,针对数据处理及分析这一过程中的算法问题进行研究,综合应用了固定权重法、构建函数法和神经网络算法这三种算法。若要提高预测的准确度,我们还需考虑更多影响因子与划分标准,需要更多数据加以测试与改进,优化我们的算法,使其有更多的应用价值和更加广泛的应用平台。
参考文献
[1]姚婧.中文微博的话题检测和预警[D].上海:上海交通大学,2012:1-2.
[2]刘月杰.基于中文微博的话题趋势预测[D].北京:北京邮电大学,2013:1-3.
[3]梁野.郭宁宁.基于机器学习的网络媒体热点话题预测研究方法与实现[J].微型机与应用.2014.33(15).
